In this third part of the series on structured concurrency (Part-I, Part-II, Part-IV, Swift-Followup), I will review GO and Rust languages for writing concurrent applications and their support for structured concurrency:
GO
GO language was created by Rob Pike, and Ken Thompson and uses light-weight go-routines for asynchronous processing. Go uses channels for communication that are designed after Tony Hoare’s rendezvous style communicating sequential processes (CSP) where the sender cannot send the message until receiver is ready to accept it. Though, GO supports buffering for channels so that sender/receiver don’t have to wait if buffer is available but channels are not designed to be used as mailbox or message queue. The channels can be shared by multiple go-routines and the messages can be transmitted by value or by reference. GO doesn’t protect against race conditions and shared state must be protected when it’s accessed in multiple go-routines. Also, if a go-routine receives a message by reference, it must be treated as transfer of ownership otherwise it can lead to race conditions. Also, unlike Erlang, you cannot monitor lifetime of other go-routines so you won’t be notified if a go-routine exits unexpectedly.
Following is high-level architecture of scheduling and go-routines in GO process:
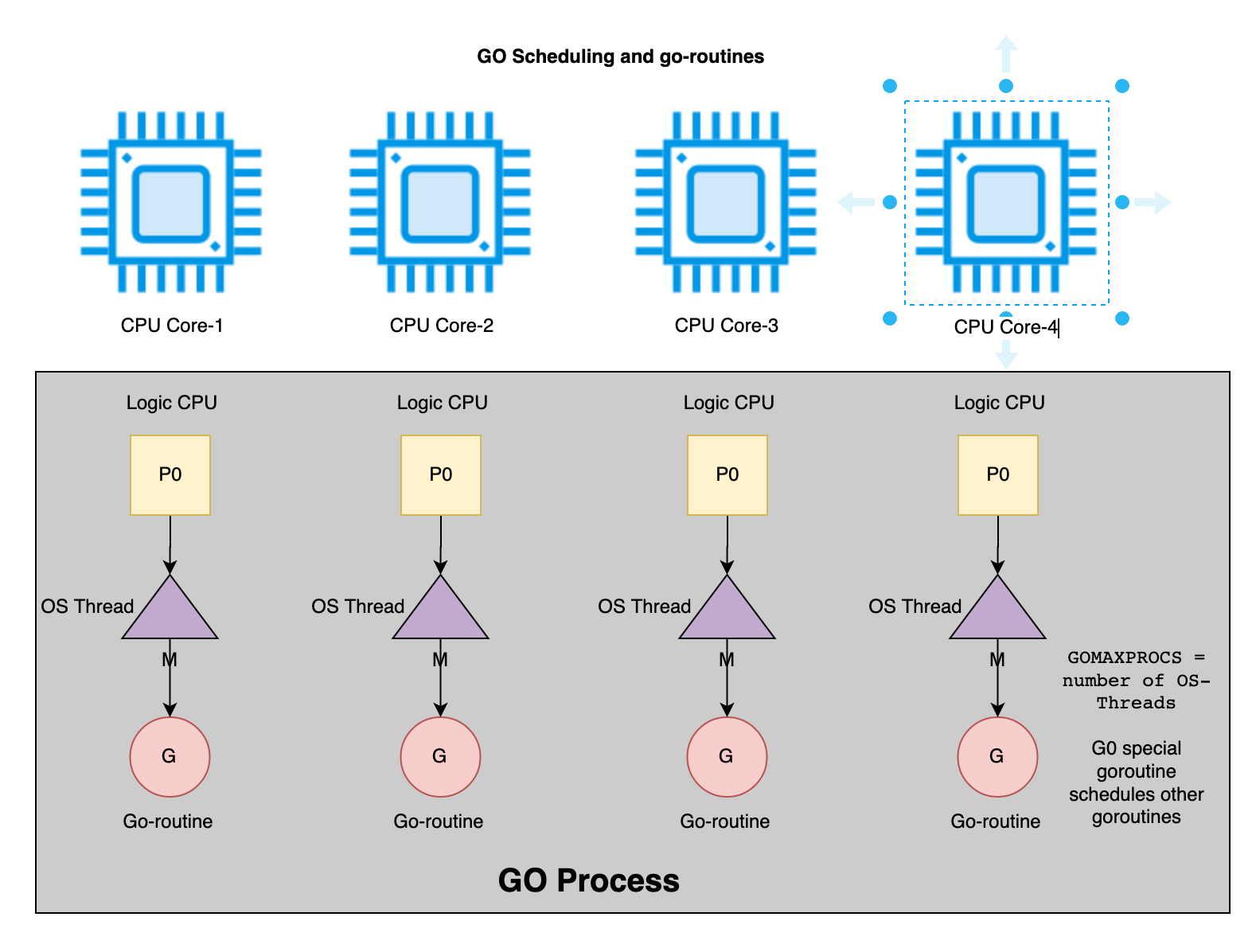
Using go-routines/channels in GO
GO doesn’t support async/await syntax but it can be simulated via go-routine and channels. As the cost of each go-routine is very small, you can use them for each background task.
Following code shows how to use go-routines and channels to build the toy web crawler:
package async
import (
"context"
"fmt"
"time"
)
// type of async function
type Handler func(ctx context.Context, request interface{}) (interface{}, error)
// type of abortHandler function that is called if async operation is cancelled
type AbortHandler func(ctx context.Context, request interface{}) (interface{}, error)
func NoAbort(ctx context.Context, request interface{}) (interface{}, error) {
return nil, nil
}
// Awaiter - defines method to wait for result
type Awaiter interface {
Await(ctx context.Context, timeout time.Duration) (interface{}, error)
IsRunning() bool
}
// task - submits task asynchronously
type task struct {
handler Handler
abortHandler AbortHandler
request interface{}
resultQ chan Response
running bool
}
// Response encapsulates results of async task
type Response struct {
Result interface{}
Err error
}
// Execute executes a long-running function in background and returns a future to wait for the response
func Execute(
ctx context.Context,
handler Handler,
abortHandler AbortHandler,
request interface{}) Awaiter {
task := &task{
request: request,
handler: handler,
abortHandler: abortHandler,
resultQ: make(chan Response, 1),
running: true,
}
go task.run(ctx) // run handler asynchronously
return task
}
// IsRunning checks if task is still running
func (t *task) IsRunning() bool {
return t.running
}
// Await waits for completion of the task
func (t *task) Await(
ctx context.Context,
timeout time.Duration) (result interface{}, err error) {
result = nil
select {
case <-ctx.Done():
err = ctx.Err()
case res := <-t.resultQ:
result = res.Result
err = res.Err
case <-time.After(timeout):
err = fmt.Errorf("async task timedout %v", timeout)
}
if err != nil {
go t.abortHandler(ctx, t.request) // abortHandler operation
}
return
}
// AwaitAll waits for completion of multiple tasks
func AwaitAll(
ctx context.Context,
timeout time.Duration,
all ...Awaiter) []Response {
ctx, cancel := context.WithTimeout(ctx, timeout)
defer cancel()
results := make([]Response, 0)
for _, next := range all {
res, err := next.Await(ctx, timeout)
results = append(results, Response{Result: res, Err: err})
}
return results
}
////////////////////////////////////// PRIVATE METHODS ///////////////////////////////////////
func (t *task) run(ctx context.Context) {
go func() {
result, err := t.handler(ctx, t.request)
t.resultQ <- Response{Result: result, Err: err} // out channel is buffered by 1
t.running = false
close(t.resultQ)
}()
}In above example, Async method takes a function to invoke in background and creates a channel for reply. It then executes the function and sends back reply to the channel. The client uses the future object return by Async method to wait for the response. The Await method provides timeout to specify the max wait time for response. Note: The Await method listens to ctx.Done() in addition to the response channel that notifies it if client canceled the task or if it timed out by high-level settings.
Following code shows how crawler can use these primitives to define background tasks for crawler:
package crawler
import (
"context"
"errors"
"sync/atomic"
"time"
"plexobject.com/crawler/async"
"plexobject.com/crawler/domain"
"plexobject.com/crawler/utils"
)
// MaxDepth max depth of crawling
const MaxDepth = 4
// MaxUrls max number of child urls to crawl
const MaxUrls = 11
// Crawler is used for crawing URLs
type Crawler struct {
crawlHandler async.Handler
downloaderHandler async.Handler
rendererHandler async.Handler
indexerHandler async.Handler
totalMessages uint64
}
// New Instantiates new crawler
func New(ctx context.Context) *Crawler {
crawler := &Crawler{totalMessages: 0}
crawler.crawlHandler = func(ctx context.Context, payload interface{}) (interface{}, error) {
req := payload.(*domain.Request)
return crawler.handleCrawl(ctx, req)
}
crawler.downloaderHandler = func(ctx context.Context, payload interface{}) (interface{}, error) {
// TODO check robots.txt and throttle policies
// TODO add timeout for slow websites and linearize requests to the same domain to prevent denial of service attack
return utils.RandomString(100), nil
}
crawler.rendererHandler = func(ctx context.Context, payload interface{}) (interface{}, error) {
// for SPA apps that use javascript for rendering contents
return utils.RandomString(100), nil
}
crawler.indexerHandler = func(ctx context.Context, payload interface{}) (interface{}, error) {
return 0, nil
}
return crawler
}
// Crawl - crawls list of URLs with specified depth
func (c *Crawler) Crawl(ctx context.Context, urls []string, timeout time.Duration) (int, error) {
// Boundary for concurrency and it will not return until all
// child URLs are crawled up to MaxDepth limit.
return c.crawl(ctx, urls, 0, timeout)
}
// TotalMessages - total number of messages processed
func (c *Crawler) TotalMessages() uint64 {
return c.totalMessages
}
// handles crawl
func (c *Crawler) handleCrawl(ctx context.Context, req *domain.Request) (*domain.Result, error) {
atomic.AddUint64(&c.totalMessages, 1)
timeout := time.Duration(req.Timeout * time.Second)
res := domain.NewResult(req)
if contents, err := async.Execute(ctx, c.downloaderHandler, async.NoAbort, req.URL).Await(ctx, timeout); err != nil {
res.Failed(err)
} else {
if newContents, err := async.Execute(ctx, c.rendererHandler, async.NoAbort, [...]string{req.URL, contents.(string)}).Await(ctx, timeout); err != nil {
res.Failed(err)
} else {
if hasContentsChanged(ctx, req.URL, newContents.(string)) && !isSpam(ctx, req.URL, newContents.(string)) {
async.Execute(ctx, c.indexerHandler, async.NoAbort, [...]string{req.URL, newContents.(string)}).Await(ctx, timeout)
urls := parseURLs(ctx, req.URL, newContents.(string))
if childURLs, err := c.crawl(ctx, urls, req.Depth+1, req.Timeout); err != nil {
res.Failed(err)
} else {
res.Succeeded(childURLs + 1)
}
} else {
res.Failed(errors.New("contents didn't change"))
}
}
}
return res, nil
}
/////////////////// Internal private methods ///////////////////////////
// Crawls list of URLs with specified depth
func (c *Crawler) crawl(ctx context.Context, urls []string, depth int, timeout time.Duration) (int, error) {
if depth < MaxDepth {
futures := make([]async.Awaiter, 0)
for i := 0; i < len(urls); i++ {
futures = append(futures, async.Execute(ctx, c.crawlHandler, async.NoAbort, domain.NewRequest(urls[i], depth, timeout)))
}
sum := 0
var savedError error
for i := 0; i < len(futures); i++ {
res, err := futures[i].Await(ctx, timeout)
if err != nil {
savedError = err // returning only a single error
}
if res != nil {
sum += res.(*domain.Result).ChildURLs
}
}
return sum, savedError
}
return 0, nil
}
func parseURLs(ctx context.Context, url string, contents string) []string {
// tokenize contents and extract href/image/script urls
urls := make([]string, 0)
for i := 0; i < MaxUrls; i++ {
urls = append(urls, utils.RandomChildUrl(url))
}
return urls
}
func hasContentsChanged(ctx context.Context, url string, contents string) bool {
return true
}
func isSpam(ctx context.Context, url string, contents string) bool {
return false
}In above implementation, crawler defines background tasks for crawling, downloading, rendering and indexing. The Crawl defines concurrency boundary and waits until all child tasks are completed. Go provides first class support for cancellation and timeout via context.Context, but you have to listen special ctx.Done() channel.
Following unit tests show examples of cancellation, timeout and normal processing:
package crawler
import (
"context"
"log"
"testing"
"time"
)
const EXPECTED_URLS = 19032
func TestCrawl(t *testing.T) {
rootUrls := []string{"https://a.com", "https://b.com", "https://c.com", "https://d.com", "https://e.com", "https://f.com", "https://g.com", "https://h.com", "https://i.com", "https://j.com", "https://k.com", "https://l.com", "https://n.com"}
started := time.Now()
timeout := time.Duration(8 * time.Second)
ctx, cancel := context.WithTimeout(context.Background(), timeout)
defer cancel()
crawler := New(ctx)
received, err := crawler.Crawl(ctx, rootUrls, timeout)
elapsed := time.Since(started)
log.Printf("Crawl took %s to process %v messages -- %v", elapsed, received, crawler.TotalMessages())
if crawler.totalMessages != EXPECTED_URLS {
t.Errorf("Expected %v urls but was %v", EXPECTED_URLS, crawler.totalMessages)
}
if err != nil {
t.Errorf("Unexpected error %v", err)
} else if EXPECTED_URLS != received {
t.Errorf("Expected %v urls but was %v", EXPECTED_URLS, received)
}
}
func TestCrawlWithTimeout(t *testing.T) {
started := time.Now()
timeout := time.Duration(4 * time.Millisecond)
ctx, cancel := context.WithTimeout(context.Background(), timeout)
defer cancel()
crawler := New(ctx)
received, err := crawler.Crawl(ctx, []string{"a.com", "b.com", "c.com", "d.com", "e.com", "f.com", "g.com", "h.com", "i.com", "j.com", "k.com", "l.com", "n.com"}, timeout)
if err == nil {
t.Errorf("Expecting timeout error")
}
elapsed := time.Since(started)
log.Printf("Timedout took %s to process %v messages -- %v - %v", elapsed, received, crawler.TotalMessages(), err)
}
func TestCrawlWithCancel(t *testing.T) {
started := time.Now()
timeout := time.Duration(3 * time.Second)
ctx, cancel := context.WithTimeout(context.Background(), timeout)
crawler := New(ctx)
var err error
var received int
go func() {
// calling asynchronously
received, err = crawler.Crawl(ctx, []string{"a.com", "b.com", "c.com", "d.com", "e.com", "f.com", "g.com", "h.com", "i.com", "j.com", "k.com", "l.com", "n.com"}, timeout)
}()
time.Sleep(5 * time.Millisecond)
cancel()
time.Sleep(50 * time.Millisecond)
if err == nil {
t.Errorf("Expecting cancel error")
}
elapsed := time.Since(started)
log.Printf("Cancel took %s to process %v messages -- %v - %v", elapsed, received, crawler.TotalMessages(), err)
}You can download the full source code from https://github.com/bhatti/concurency-katas/tree/main/go_pool.
Following are major benefits of using this approach to implement crawler and its support of structured concurrency:
- The main Crawl method defines high level scope of concurrency and it waits for the completion of child tasks.
- Go supports cancellation and timeout APIs and the Crawl method passes timeout parameter so that the crawling all URLs must complete with the time period.
- The Crawl method captures error from async response and returns so that client code can perform error handling.
Following are shortcomings using this approach for structured concurrency and general design:
- You can’t monitor life-time of go-routines and you won’t get any errors if background task dies unexpectedly.
- The cancellation API returns without cancelling underlying operation so you will need to implement a cooperative cancellation to persist any state or clean up underlying resources.
- Go doesn’t support specifying execution context for go-routines and all asynchronous code is automatically scheduled by GO (G0 go-routines).
- GO go-routines are not easily composable because they don’t have any parent/child relationship as opposed to async methods that can invoke other async methods in Typescript, Rust or other languages supporting async/await.
- As Go doesn’t enforce immutability so you will need mutex to protect shared state. Also, mutex implementation in GO is not re-entrant aware so you can’t use for any recursive methods where you are acquiring locks.
- Above code creates a new go-routine for crawling each URL and though the overhead of each process is small but it may use other expensive resources such as network resource.
Using worker-pool in GO
As opposed to creating new go-routine, we can use worker-pool of go-routines to perform background tasks so that we can manage external resource dependencies easily.
Following code shows an implementation of worker-pool in GO:
package pool
import (
"context"
"errors"
"fmt"
"time"
"github.com/google/uuid"
)
const BUFFER_CAPACITY = 2 // allow buffering to support asynchronous behavior as by default sender will be blocked
type Handler func(ctx context.Context, payload interface{}) (interface{}, error)
type Awaiter interface {
Await(ctx context.Context, timeout time.Duration) (interface{}, error)
}
// Request encapsulates request to process
type Request struct {
id string
payload interface{}
outQ chan Result
}
// Result encapsulates results
type Result struct {
id string
payload interface{}
err error
}
// Worker structure defines inbound channel to receive request and lambda function to execute
type Worker struct {
id int
handler Handler
workerRequestChannel chan *Request
}
// NewWorker creates new worker
func NewWorker(id int, handler Handler) Worker {
return Worker{
id: id,
handler: handler,
workerRequestChannel: make(chan *Request),
}
}
func (w Worker) start(ctx context.Context, workersReadyPool chan chan *Request, done chan bool) {
go func(w Worker) {
for {
// register the current worker into the worker queue.
workersReadyPool <- w.workerRequestChannel
select {
case <-ctx.Done():
break
case req := <-w.workerRequestChannel:
payload, err := w.handler(ctx, req.payload)
req.outQ <- Result{id: req.id, payload: payload, err: err} // out channel is buffered by 1
close(req.outQ)
case <-done:
return
}
}
}(w)
}
// WorkPool - pool of workers
type WorkPool struct {
size int
workersReadyPool chan chan *Request
pendingRequestQueue chan *Request
done chan bool
handler Handler
}
// New Creates new async structure
func New(handler Handler, size int) *WorkPool {
async := &WorkPool{
size: size,
workersReadyPool: make(chan chan *Request, BUFFER_CAPACITY),
pendingRequestQueue: make(chan *Request, BUFFER_CAPACITY),
done: make(chan bool),
handler: handler}
return async
}
// Start - starts up workers and internal goroutine to receive requests
func (p *WorkPool) Start(ctx context.Context) {
for w := 1; w <= p.size; w++ {
worker := NewWorker(w, p.handler)
worker.start(ctx, p.workersReadyPool, p.done)
}
go p.dispatch(ctx)
}
// Add request to process
func (p *WorkPool) Add(ctx context.Context, payload interface{}) Awaiter {
// Adding request to process
req := &Request{id: uuid.New().String(), payload: payload, outQ: make(chan Result, 1)}
go func() {
p.pendingRequestQueue <- req
}()
return req
}
// Await for reply -- you can only call this once
func (r Request) Await(ctx context.Context, timeout time.Duration) (payload interface{}, err error) {
select {
case <-ctx.Done():
err = errors.New("async_cancelled")
case res := <-r.outQ:
payload = res.payload
err = res.err
case <-time.After(timeout):
payload = nil
err = fmt.Errorf("async_timedout %v", timeout)
}
return
}
// Stop - stops thread pool
func (p *WorkPool) Stop() {
close(p.pendingRequestQueue)
go func() {
p.done <- true
}()
}
// Receiving requests from inbound channel and forward it to the worker's workerRequestChannel
func (p *WorkPool) dispatch(ctx context.Context) {
for {
select {
case <-ctx.Done():
return
case <-p.done:
return
case req := <-p.pendingRequestQueue:
go func(req *Request) {
// Find next ready worker
workerRequestChannel := <-p.workersReadyPool
// dispatch the request to next ready worker
workerRequestChannel <- req
}(req)
}
}
}You can download above examples from https://github.com/bhatti/concurency-katas/tree/main/go_pool.
Rust
Rust was designed by Mozilla Research to provide better performance, type safety, strong memory ownership and safe concurrency. With its strong ownership and lifetime scope, Rust minimizes race conditions because each object can only have one owner that can update the value. Further, strong typing, traits/structured-types, abstinence of null references, immutability by default eliminates most of common bugs in the code.
Rust uses OS-threads for multi-threading but has added support for coroutines and async/await recently. Rust uses futures for asynchronous behavior but unlike other languages, it doesn’t provide runtime environment for async/await. Two popular runtime systems available for Rust are https://tokio.rs/ and https://github.com/async-rs/async-std. Also, unlike other languages, async/await in Rust uses zero-cost abstraction where async just creates a future without scheduling until await is invoked. The runtime systems such as async-std and tokio provides executor that polls future until it returns a value.
Following example shows how async/await can be used to implement
extern crate rand;
use std::{error::Error, fmt};
use std::time::{Duration, SystemTime, UNIX_EPOCH};
use rand::Rng;
use rand::distributions::Alphanumeric;
use rand::seq::SliceRandom;
use futures::future::{Future, join_all, BoxFuture};
use futures::stream::{FuturesUnordered};
use futures::executor;
use async_std::{task, future};
use async_std::future::timeout;
const MAX_DEPTH: u8 = 4;
const MAX_URLS: u8 = 11;
// Request encapsulates details of url to crawl
#[derive(Debug, Clone, PartialEq)]
pub struct Request {
pub url: String,
pub depth: u8,
pub timeout: Duration,
pub created_at: u128,
}
impl Request {
pub fn new(url: String, depth: u8, timeout: Duration) -> Request {
let epoch = SystemTime::now().duration_since(UNIX_EPOCH).expect("epoch failed").as_millis();
Request{url: url.to_string(), depth: depth, timeout: timeout, created_at: epoch}
}
}
#[derive(Debug, Copy, Clone)]
pub enum CrawlError {
Unknown,
MaxDepthReached,
DownloadError,
ParseError,
IndexError,
ContentsNotChanged,
Timedout,
}
impl Error for CrawlError {}
impl fmt::Display for CrawlError {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
match *self {
CrawlError::MaxDepthReached => write!(f, "MaxDepthReached"),
CrawlError::DownloadError => write!(f, "DownloadError"),
CrawlError::ParseError => write!(f, "ParseError"),
CrawlError::IndexError => write!(f, "IndexError"),
CrawlError::ContentsNotChanged => write!(f, "ContentsNotChanged"),
CrawlError::Timedout=> write!(f, "Timedout"),
CrawlError::Unknown => write!(f, "Unknown"),
}
}
}
//////// PUBLIC METHODS
// crawling a collection of urls
pub fn crawl(urls: Vec<String>, timeout_dur: Duration) -> Result<usize, CrawlError> {
// Boundary for concurrency and it will not return until all
// child URLs are crawled up to MAX_DEPTH limit.
//
match task::block_on(
timeout(timeout_dur, async {
do_crawl(urls, timeout_dur, 0)
})
) {
Ok(res) => res,
Err(_err) => Err(CrawlError::Timedout),
}
}
//////// PRIVATE METHODS
fn do_crawl(urls: Vec<String>, timeout_dur: Duration, depth: u8) -> Result<usize, CrawlError> {
if depth >= MAX_DEPTH {
return Ok(0)
}
let mut futures = Vec::new();
let mut size = 0;
for u in urls {
size += 1;
futures.push(async move {
let child_urls = match handle_crawl(Request::new(u, depth, timeout_dur)) {
Ok(urls) => urls,
Err(_err) => [].to_vec(),
};
if child_urls.len() > 0 {
do_crawl(child_urls, timeout_dur, depth+1)
} else {
Ok(0)
}
});
}
task::block_on(
async {
let res: Vec<Result<usize, CrawlError>> = join_all(futures).await;
let sizes: Vec<usize> = res.iter().map(|r| r.map_or(0, |n|n)).collect::<Vec<usize>>();
size += sizes.iter().fold(0usize, |sum, n| n+sum);
}
);
Ok(size)
}
// method to crawl a single url
fn handle_crawl(req: Request) -> Result<Vec<String>, CrawlError> {
let res: Result<Vec<String>, CrawlError> = task::block_on(
async {
let contents = match download(&req.url).await {
Ok(data) => data,
Err(_err) => return Err(CrawlError::DownloadError),
};
if has_contents_changed(&req.url, &contents) && !is_spam(&req.url, &contents) {
let urls = match index(&req.url, &contents).await {
Ok(_) =>
match parse_urls(&req.url, &contents) {
Ok(urls) => urls,
Err(_err) => return Err(CrawlError::ParseError),
},
Err(_err) => return Err(CrawlError::IndexError),
};
return Ok(urls)
} else {
return Err(CrawlError::ContentsNotChanged)
}
}
);
match res {
Ok(list) => return Ok(list),
Err(err) => return Err(err),
}
}
async fn download(url: &str) -> Result<String, CrawlError> {
// TODO check robots.txt and throttle policies
// TODO add timeout for slow websites and linearize requests to the same domain to prevent denial of service attack
// invoke jsrender to generate dynamic content
jsrender(url, &random_string(100)).await
}
async fn jsrender(_url: &str, contents: &str) -> Result<String, CrawlError> {
// for SPA apps that use javascript for rendering contents
Ok(contents.to_string())
}
async fn index(_url: &str, _contents: &str) -> Result<bool, CrawlError> {
// apply standardize, stem, ngram, etc for indexing
Ok(true)
}
fn parse_urls(_url: &str, _contents: &str) -> Result<Vec<String>, CrawlError> {
// tokenize contents and extract href/image/script urls
Ok((0..MAX_URLS).into_iter().map(|i| random_url(i)).collect())
}
fn has_contents_changed(_url: &str, _contents: &str) -> bool {
true
}
fn is_spam(_url: &str, _contents: &str) -> bool {
false
}
fn random_string(max: usize) -> String {
rand::thread_rng().sample_iter(&Alphanumeric).take(max).collect::<String>()
}
fn random_url(i: u8) -> String {
let domains = vec!["ab.com", "bc.com", "cd.com", "de.com", "ef.com", "fg.com", "gh.com", "hi.com", "ij.com", "jk.com", "kl.com", "lm.com", "mn.com",
"no.com", "op.com", "pq.com", "qr.com", "rs.com", "st.com", "tu.com", "uv.com", "vw.com", "wx.com", "xy.com", "yz.com"];
let domain = domains.choose(&mut rand::thread_rng()).unwrap();
format!("https://{}/{}_{}", domain, random_string(20), i)
}The crawl method defines scope of concurrency and asynchronously crawls each URL recursively but the parent URL waits until child URLs are crawled. The async-std provides support for timeout so that asynchronous task can fail early if it’s not completed within the bounded time-frame. However, it doesn’t provide cancellation support so you have to rely on cooperative cancellation.
Following unit-test and main routine shows example of crawling a list of URLs:
use std::time::Duration;
use futures::prelude::*;
use std::time::{Instant};
use crate::crawler::crawler::*;
mod crawler;
fn main() {
let _ = do_crawl(8000);
}
fn do_crawl(timeout: u64) -> Result<usize, CrawlError> {
let start = Instant::now();
let urls = vec!["a.com", "b.com", "c.com", "d.com", "e.com", "f.com", "g.com", "h.com", "i.com", "j.com", "k.com", "l.com", "n.com"].into_iter().map(|s| s.to_string()).collect();
let res = crawl(urls, Duration::from_millis(timeout));
let duration = start.elapsed();
println!("Crawled {:?} urls in () is: {:?}", res, duration);
res
}
#[cfg(test)]
mod tests {
use super::do_crawl;
#[test]
fn crawl_urls() {
match do_crawl(8000) {
Ok(size) => assert_eq!(size, 19032),
Err(err) => assert!(false, format!("Unexpected error {:?}", err)),
}
}
}You can download the full source code from https://github.com/bhatti/concurency-katas/tree/main/rust_async.
Following are major benefits of using this approach to implement crawler and its support of structured concurrency:
- The main crawl method defines high level scope of concurrency and it waits for the completion of child tasks.
- The async-std runtime environment supports timeout APIs and the crawl method takes the timeout parameter so that the crawling all URLs must complete with the time period.
- The crawl method captures error from async response and returns the error so that client code can perform error handling.
- The async declared methods in above implementation shows asynchronous code can be easily composed.
Following are shortcomings using this approach for structured concurrency and general design:
- Rust async/await APIs doesn’t support native support for cancellation so you will need to implement a cooperative cancellation to persist any state or clean up underlying resources.
- Rust async/await APIs doesn’t allow you to specify execution context for asynchronous code.
- The async/await support in Rust is relatively new and has not matured yet. Also, it requires separate runtime environment and there are a few differences in these implementations.
- Above design for crawler is not very practical because it creates a asynchronous task for each URL that is crawled and it may strain network or IO resources.
Overall, GO provides decent support for low-level concurrency but its complexity can create subtle bugs and incorrect use of go-routines can result in deadlocks. Also, it’s prone to data races due to mutable shared state. Just like structured programming considered GOTO statements harmful and recommended if-then, loops, and function calls for control flow, structured concurrency considers GO statements harmful and recommends parent waits for children completion and supports propagating errors from children to parent. Rust offers async/await syntax for concurrency scope and supports composition and error propagation with strong ownership that reduces chance of data races. Also, Rust uses continuations by suspending async block and async keyword just creates a future and does not start execution so it results in better performance when async code is chained together. However, async/await is still in its inception phase in Rust and lacks proper support for cancellation and customized execution context.