Multi-Factor Authentication (MFA) or 2FA allows multiple method of authentication to verify the user’s identity. The authentication factors generally include something the user has such as security token, something the user knows such as password/PIN/OTP, and something the user is such as biometrics. There are many means for MFA including:
- SMS-Based Verification: delivers one-time password (OTP) via text message but it is vulnerable to SIM swapping, interception, and phishing attacks.
- TOTP: uses Authenticator Apps to generate Time-based One-Time Passwords but it requires a smartphone.
- Push Notifications: provides more convenience but it is vulnerable for users to mistakenly approve malicious requests.
- Hardware Security Keys (FIDO/U2F): offers more secure; resistant to phishing and man-in-the-middle attacks but requires carrying an additional device.
- Biometrics: provides more convenient and secure authentication but can result in privacy and data security violations if implemented incorrectly.
In our implementation, we will use the FIDO (Fast Identity Online) standards, along with CTAP (Client to Authenticator Protocol) and WebAuthn (Web Authentication). FIDO includes specifications like UAF (Universal Authentication Framework) for passwordless authentication and U2F (Universal 2nd Factor) for second-factor authentication. FIDO2 is an extension of the original FIDO standards that includes the CTAP (Client to Authenticator Protocol) and WebAuthn (Web Authentication). CTAP allows external devices to act as authenticators and WebAuthn is a web standard developed by the W3C for secure and passwordless authentication on the web. FIDO/CTAP/WebAuthn uses public key cryptography where the private key never leaves the user’s device and only the public key is stored on the server. This greatly reduces the risk of private key compromise or maintaining shared secrets, which is a common vulnerability in traditional password-based systems. This approach further protects against common attack vectors such as phishing, man-in-the-middle attacks, and data breaches where password databases are compromised. The FIDO/CTAP/WebAuthn uses unique assertions for each login session and device attestation that makes it extremely difficult for attackers to use stolen credentials or to replay an intercepted authentication session. In short, FIDO and WebAuthn provides better security based on public key cryptography, more resistant to phishing attacks, and offers better user experience with cross-platform compatibility compared to other forms of multi-factor authentication.

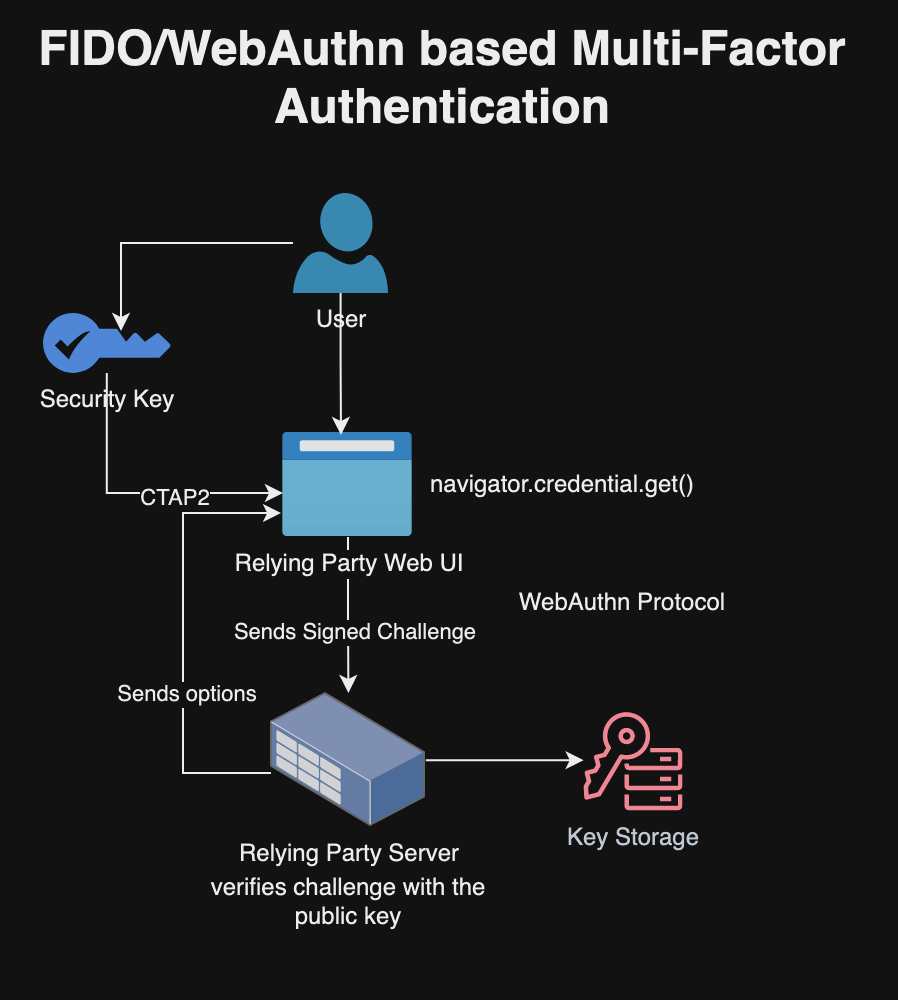
Building Services and Web Client for Multi-Factor Authentication
Following implementation is based on my experience with building multi-factor authentication for PlexPass, which is an open source password manager. The PlexPass is built in Rust and provides web based UI along with CLI and REST APIs. In this implementation, the WebAuthn protocol is implemented using webauthn-rs library for multi-factor authentication. Here’s a general overview of how webauthn-rs can be added to a Rust application:
Add the Dependency:
First, you need to add webauthn-rs to your project’s Cargo.toml file:
[dependencies]
webauthn-rs = { version = "0.4", features = ["danger-allow-state-serialisation"] }Configure the WebAuthn Environment:
You can then set up the WebAuthn environment with your application’s details, which includes the origin (the URL of your website), relying party name (your site’s name), and other configuration details as follows:
use webauthn_rs::prelude::*;
fn create_webauthn_config() -> WebauthnConfig {
WebauthnConfigBuilder::new()
.rp_name("My App".to_string())
.rp_id("localhost") // Change for production
.origin("https://localhost:8443") // Change for production
.build()
.unwrap()
}
let config = create_webauthn_config();
let webauthn = Webauthn::new(config);You can view an actual example of this configuration in https://github.com/bhatti/PlexPass/blob/main/src/service/authentication_service_impl.rs.
Integrate with User Accounts:
WebAuthn should be integrated with your user account system and WebAuthn credentials should be associated user accounts upon registration and authentication. For example, here is a User object used by the PlexPass password manager:
pub struct User {
// id of the user.
pub user_id: String,
// The username of user.
pub username: String,
...
// hardware keys for MFA via UI.
pub hardware_keys: Option<HashMap<String, HardwareSecurityKey>>,
// otp secret for MFA via REST API/CLI.
pub otp_secret: String,
// The attributes of user.
pub attributes: Option<Vec<NameValue>>,
pub created_at: Option<NaiveDateTime>,
pub updated_at: Option<NaiveDateTime>,
}Implementing Registration
When a user registers their device, first it will be registered and then associated with user account. Here is how PlexPass defines registration start method on the server side:
// Start MFA registration
async fn start_register_key(&self,
ctx: &UserContext,
) -> PassResult<CreationChallengeResponse> {
let user = self.user_repository.get(ctx, &ctx.user_id).await?;
// clear reg-state
self.hsm_store.set_property(&ctx.username, WEBAUTHN_REG_STATE, "")?;
// If the user has any other credentials, we exclude these here so they
// can't be duplicate registered.
// It also hints to the browser that only new credentials should be
// "blinked" for interaction.
let exclude_credentials = user.hardware_key_ids();
let (ccr, reg_state) = self.webauthn.start_passkey_registration(
Uuid::parse_str(&ctx.user_id)?, // user-id as UUID
&ctx.username, // internal username
&ctx.username, // display username
exclude_credentials)?;
// NOTE: We shouldn't sore reg_state in session because we are using cookies store.
// Instead, we will store HSM for safe storage.
let json_reg_state = serde_json::to_string(®_state)?;
self.hsm_store.set_property(&ctx.username, WEBAUTHN_REG_STATE, &json_reg_state)?;
Ok(ccr)
}The above implementation first loads user object from the database and clears any previous state of device registration. The PlexPass uses secure storage such as Keychain on Mac for storing registration state and though you may store registration state in the session but you shouldn’t use it if the session is actually stored in a cookie as that will be exposed to remote clients. In addition, the registration method finds device-ids of all existing devices so that we don’t register same device more than once. It then returns CreationChallengeResponse, which is used by the Web UI to prompt user to insert the security key. Here is example response from the above registration challenge:
{
"publicKey": {
"rp": {
"name": "PlexPass-Webauthn",
"id": "localhost"
},
"user": {
"id": {
"0": 130, "1": 244,...
},
"name": "myuser",
"displayName": "my user"
},
"challenge": {
"30": 197,"31": 221..
},
"pubKeyCredParams": [
{
"type": "public-key",
"alg": -7
},
{
"type": "public-key",
"alg": -257
}
],
"timeout": 60000,
"attestation": "none",
"excludeCredentials": [],
"authenticatorSelection": {
"requireResidentKey": false,
"userVerification": "preferred"
},
"extensions": {
"uvm": true,
"credProps": true
}
}
}Client-Side Registration
On the client side (in the user’s browser), you can use the challenge to register the user’s authenticator, e.g.,
const newCredential = await navigator.credentials.create(options);
For example, here is how PlexPass registers MFA key on the client side:
async function registerMFAKey() {
try {
let response = await fetch('/ui/webauthn/register_start');
let options = await response.json();
// Convert challenge from Base64URL to Base64, then to Uint8Array
const challengeBase64 = base64UrlToBase64(options.publicKey.challenge);
options.publicKey.challenge = Uint8Array.from(atob(challengeBase64), c => c.charCodeAt(0));
// Convert user ID from Base64URL to Base64, then to Uint8Array
const userIdBase64 = base64UrlToBase64(options.publicKey.user.id);
options.publicKey.user.id = Uint8Array.from(atob(userIdBase64), c => c.charCodeAt(0));
// Convert each excludeCredentials id from Base64URL to ArrayBuffer
if (options.publicKey.excludeCredentials) {
for (let cred of options.publicKey.excludeCredentials) {
cred.id = base64UrlToArrayBuffer(cred.id);
}
}
// Create a new credential
const newCredential = await navigator.credentials.create(options);
// Prepare data to be sent to the server
const credentialForServer = {
id: newCredential.id,
rawId: arrayBufferToBase64(newCredential.rawId),
response: {
attestationObject: arrayBufferToBase64(newCredential.response.attestationObject),
clientDataJSON: arrayBufferToBase64(newCredential.response.clientDataJSON)
},
type: newCredential.type
};
// Send the new credential to the server for verification and storage
response = await fetch('/ui/webauthn/register_finish', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify(credentialForServer)
});
let savedKey = await response.json();
...
} catch (err) {
console.error('Error during registration:', err);
}
}Note: The webauthn-rs library sends data in the Base64-URL format instead of Base64 so the javascript code provides conversion. Here is an example of the transformation logic:
function arrayBufferToBase64(buffer) {
let binary = '';
let bytes = new Uint8Array(buffer);
let len = bytes.byteLength;
for (let i = 0; i < len; i++) {
binary += String.fromCharCode(bytes[i]);
}
return window.btoa(binary);
}
function base64UrlToBase64(base64Url) {
// Replace "-" with "+" and "_" with "/"
let base64 = base64Url.replace(/-/g, '+').replace(/_/g, '/');
// Pad with "=" to make the length a multiple of 4 if necessary
while (base64.length % 4) {
base64 += '=';
}
return base64;
}
function base64UrlToArrayBuffer(base64url) {
var padding = '='.repeat((4 - base64url.length % 4) % 4);
var base64 = (base64url + padding)
.replace(/\-/g, '+')
.replace(/_/g, '/');
var rawData = window.atob(base64);
var outputArray = new Uint8Array(rawData.length);
for (var i = 0; i < rawData.length; ++i) {
outputArray[i] = rawData.charCodeAt(i);
}
return outputArray.buffer;
}The Web client in above example asks user to insert the security key and then sends attestation to the server. For example, here is screenshot in PlexPass application for prompting user to add security key:
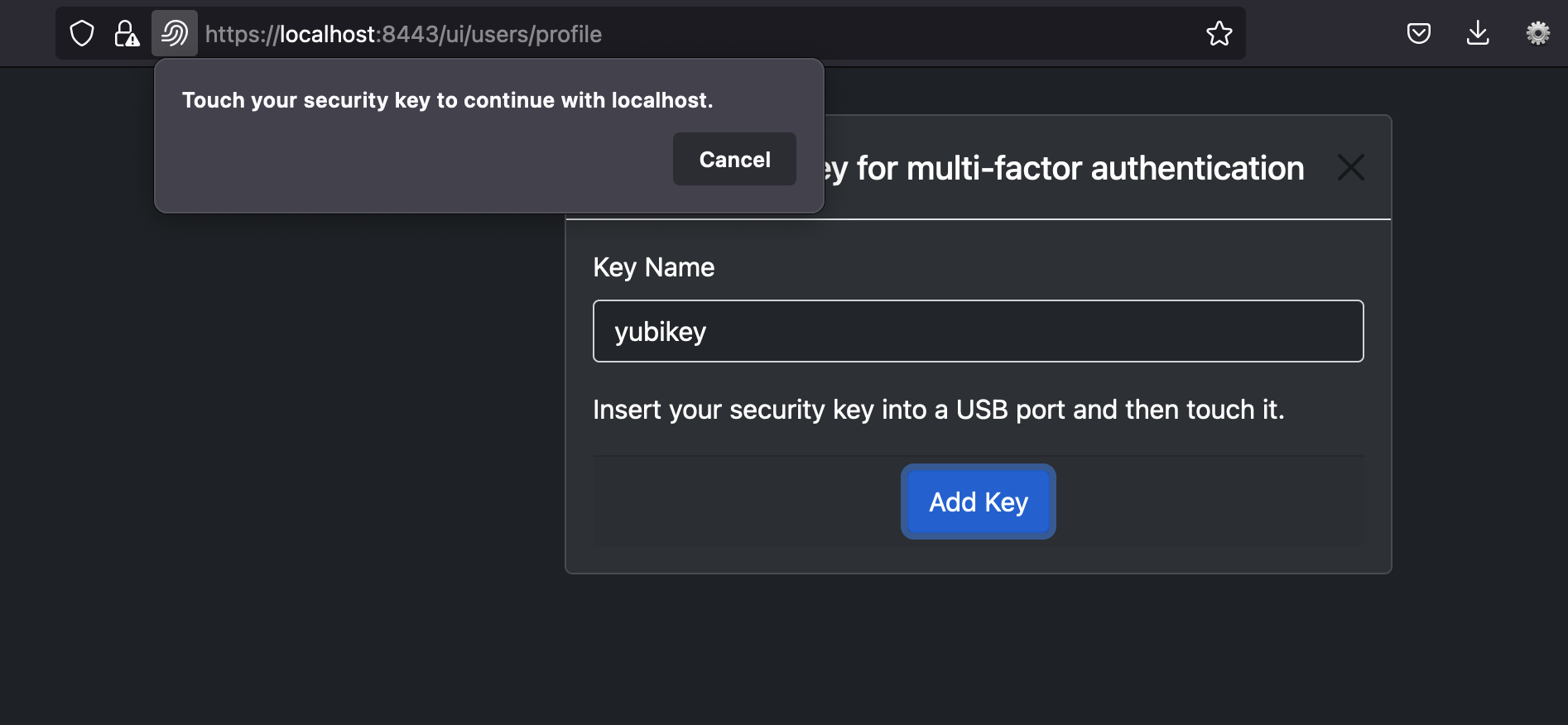
Here is an example of response from Web client:
{
"id": "tMV..",
"rawId": "tMVM..PJA==",
"response": {
"attestationObject": "o2Nm...JFw==",
"clientDataJSON": "eyJja...ifQ=="
},
"type": "public-key"
}Verify Registration Response
The server side then verifies attestation and then adds security key so that user can be prompted to insert security key upon authentication. Here is how PlexPass defines registration finish method on the server side:
// Finish MFA registration ad returns user
async fn finish_register_key(&self,
ctx: &UserContext,
key_name: &str,
req: &RegisterPublicKeyCredential,
) -> PassResult<HardwareSecurityKey> {
let reg_state_str = self.hsm_store.get_property(&ctx.username, WEBAUTHN_REG_STATE)?;
if reg_state_str.is_empty() {
return Err(PassError::authentication("could not find webauthn registration key"));
}
let reg_state: PasskeyRegistration = serde_json::from_str(®_state_str)?;
self.hsm_store.set_property(&ctx.username, WEBAUTHN_REG_STATE, "")?;
let sk = self.webauthn.finish_passkey_registration(req, ®_state)?;
let mut user = self.user_repository.get(ctx, &ctx.user_id).await?;
let hardware_key = user.add_security_key(key_name, &sk);
self.user_repository.update(ctx, &user).await?;
Ok(hardware_key)
}In above example, the server side extracts registration state from Keychain and then invokes finish_passkey_registration of webauthn-rs library using registration state and client side attestation. The hardware keys are then added to the user object and saved in the database. PlexPass encrypts user object in the database based on user’s password so all security keys are safeguarded against unauthorized access.
Fallback Mechanisms
When registering security keys for multi-factor authentication, it’s recommended to implement fallback authentication methods for scenarios where the user’s security key is unavailable. For example, PlexPass generates a recovery code that can be used to reset multi-factor authentication in case the security key is lost as displayed below:

Implementing Authentication
When a user attempts to log in, the server side recognizes that user has configured multi-facor authentication, generate an authentication challenge and then directed to a web page to prompt user to insert the security key. Here is how PlexPass defines authentication start authentication method on the server side:
// Start authentication with MFA
async fn start_key_authentication(&self,
ctx: &UserContext,
) -> PassResult<RequestChallengeResponse> {
// clear reg-state
self.hsm_store.set_property(&ctx.username, WEBAUTHN_AUTH_STATE, "")?;
let user = self.user_repository.get(ctx, &ctx.user_id).await?;
let allow_credentials = user.get_security_keys();
if allow_credentials.is_empty() {
return Err(PassError::authentication("could not find webauthn keys"));
}
let (rcr, auth_state) = self.webauthn
.start_passkey_authentication(&allow_credentials)?;
// Note: We will store auth-state in HSM as we use cookie-store for session.
let json_auth_state = serde_json::to_string(&auth_state)?;
self.hsm_store.set_property(&ctx.username, WEBAUTHN_AUTH_STATE, &json_auth_state)?;
Ok(rcr)
}
In above example, the server side loads user object from the database, extracts security keys, and uses start_passkey_authentication method of webauthn-rs library to create authentication challenge.
Note: The server side saves authentication state in secure storage similar to the registration state so that it’s safeguarded against unauthorized access.
Client-Side Authentication
The client side prompts user to insert the key with following Javascript code:
async function signinMFA(options) {
try {
// Convert challenge from Base64URL to ArrayBuffer
options.publicKey.challenge = base64UrlToArrayBuffer(options.publicKey.challenge);
// Convert id from Base64URL to ArrayBuffer for each allowed credential
if (options.publicKey.allowCredentials) {
for (let cred of options.publicKey.allowCredentials) {
cred.id = base64UrlToArrayBuffer(cred.id);
}
}
// Request an assertion
const assertion = await navigator.credentials.get(options);
console.log(JSON.stringify(assertion))
// Send the assertion to the server for verification
let response = await doFetch('/ui/webauthn/login_finish', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify(assertion)
});
...
} catch (err) {
console.error('Error during authentication:', err);
}
}The authentication options from the server looks like:
{
"publicKey": {
"challenge": {},
"timeout": 60000,
"rpId": "localhost",
"allowCredentials": [
{
"type": "public-key",
"id": {}
}
],
"userVerification": "preferred"
}
}The client UI prompts user to insert the key and then sends a response with signed challenge such as:
{
"authenticatorAttachment": "cross-platform",
"clientExtensionResults": {},
"id": "hR..",
"rawId": "hR..",
"response": {
"authenticatorData": "SZ..",
"clientDataJSON": "ey...",
"signature": "ME..0"
},
"type": "public-key"
}Verify Authentication Response
The server then verifies signed challenge to authenticate the user. Here is an example of authentication business logic based on PlexPass application:
// Finish MFA authentication
async fn finish_key_authentication(&self,
ctx: &UserContext,
session_id: &str,
auth: &PublicKeyCredential) -> PassResult<()> {
let auth_state_str = self.hsm_store.get_property(&ctx.username, WEBAUTHN_AUTH_STATE)?;
if auth_state_str.is_empty() {
return Err(PassError::authentication("could not find webauthn auth key"));
}
self.hsm_store.set_property(&ctx.username, WEBAUTHN_AUTH_STATE, "")?;
let auth_state: PasskeyAuthentication = serde_json::from_str(&auth_state_str)?;
let auth_result = self.webauthn.finish_passkey_authentication(auth, &auth_state)?;
let mut user = self.user_repository.get(ctx, &ctx.user_id).await?;
user.update_security_keys(&auth_result);
self.user_repository.update(ctx, &user).await?;
let _session = self.login_session_repository.mfa_succeeded(&ctx.user_id, session_id)?;
Ok(())
}
The server side loads authentication state from secure storage and user object from the database. It then uses finish_passkey_authentication method of webauthn-rs library to validate signed challenge and updates user object and user-session so that user can proceed with full access to the application.
Multi-Factor Authentication with Command-Line and REST APIs
The PlexPass password manager uses Time-based One-Time Passwords (TOTP) for adding multi-factor authentication to the command-line access and REST APIs. This also means that users can reset security keys using CLI and APIs with the recovery code. A base32 based TOTP code is automatically generated when a user registers, which is accessible via WebUI, CLI or REST APIs. Here is an example of using multi-factor authentication with CLI:
otp=`plexpass -j true generate-otp --otp-secret DA**|jq '.otp_code'` plexpass -j true --master-username charlie --master-password *** \ --otp-code $otp reset-multi-factor-authentication --recovery-code D**
Summary
In summary, FIDO, CTAP, and WebAuthn represent a major leap forward in Multi-Factor Authentication (MFA), effectively addressing several vulnerabilities of traditional authentication methods. These protocols bolster security using cryptographic techniques and minimize the reliance on shared secrets, enhancing both security and user experience. However, a notable gap exists in readily available resources and comprehensive examples, particularly in integrating these standards. This gap was evident when I incorporated MFA into the PlexPass password manager using the webauthn-rs Rust library. While it offered server-side sample code, the absence of corresponding client-side JavaScript examples posed a lot of challenges for me. By sharing my experiences and learnings, I hope to facilitate wider adoption of FIDO/CTAP/WebAuthn standards, given their superior security capabilities.