I. The Big Ball of Mud
In your career, you often have to deal with a legacy codebase that nobody wants to touch but everyone depends on. I had to deal with a similar real-time observability system that ingested logs, metrics, and traces and routed them to storage, alerting, and analytics systems. It started as a small Node.js project but then grew into a Big Ball of Mud over the years: a system with no discernible structure, where everything depends on everything else, and changes in one area trigger cascading failures across the codebase. The symptoms were textbook:
- God classes: A single
PipelineManagerhad grown to thousand of lines, handling config loading, event parsing, routing, batching, error recovery, and metrics reporting. - Singletons everywhere: dozens of module-level mutable instances accessed via
getInstance(). Testing required elaborate startup sequences and teardown. - Type erasure: thousands of
anyin the TypeScript codebase. Refactoring was impossible because the compiler couldn’t help. - Silent failures: hundres of
catch {}blocks that swallowed errors. Production incidents took hours to diagnose because the system happily continued with corrupted state. - Deep inheritance: A 6-level class hierarchy for “processors” where each level overrode different methods in incompatible ways.
This impacted business in terms of feature velocity, onboarding for new engineers and high change failure rate (see dora metrics). But here is the thing: not everything was broken. Buried under layers of mutation, global state, and type erasure, there were sound architectural ideas. The original designers made some good calls.
This post describes how functional programming patterns, domain-driven design, and hexagonal architecture (see https://shahbhat.medium.com/applying-domain-driven-design-and-clean-onion-hexagonal-architecture-to-microservic-284d54b3a874) with a POC implementation can be used toeliminate entire categories of bugs and restore the ability to move fast.
II. Patterns Worth Preserving
The legacy system had three core architectural patterns that deserved preservation but can be implemented better in Rust.
Pipes and Filters
The legacy system used pipes and filter pattern to flow events through a chain of independent processing stages. Each stage does one thing like parse, filter, enrich, mask, route and passes the result to the next stage. The problems were mutable events shared across stages, untyped filter functions, and no backpressure between stages. The chain was there, but the links were rusty.
The new POC implementation keeps Pipes and Filters as the backbone. Each stage is immutable, strongly typed, and composable. A stage receives an owned event and returns a new event (or drops it, or splits it into many). No stage can observe or interfere with another stage’s work.
// Legacy: mutable, untyped, no backpressure
// function processStage(event: any): any { event.stage = "done"; return event; }
// New: immutable, typed, composable
pub trait PipelineFn: Send + Sync {
fn name(&self) -> &str;
fn process(&self, event: Event) -> FnResult;
}Decorator/Enrich: Adding Context to Events
The legacy system enriched events with metadata like adding timestamps, source identifiers, routing tags, geo-IP data. This is the Decorator pattern applied to streaming data, and it is essential. Raw events from producers are incomplete; the pipeline adds context. The problem was mutation. The legacy enrichment stages modified events in place, so downstream stages could not trust what they received. The new POC system keeps enrichment but uses immutable event copies. Each enrichment stage returns a new event with the added data. The original is untouched.
// Enrichment returns a new event — the original is unchanged
pub fn enrich_with_timestamp(event: Event) -> Event {
event.set_field("_enriched_at", FieldValue::Int(now_millis()))
}Source/Sink: The Endpoints
Every pipeline has endpoints: where data comes in (sources) and where it goes out (sinks). The legacy system had these abstractions, though they were concrete classes rather than interfaces. The new POC system makes sources and sinks trait-based and pluggable. You can swap a Kafka source for an HTTP source without touching the pipeline logic. You can add a new sink type without modifying existing code.
pub trait EventSource: Send + Sync {
async fn start(&mut self) -> Result<(), SourceError>;
fn stream(&mut self) -> Pin<Box<dyn Stream<Item = Event> + Send + '_>>;
}
pub trait EventSink: Send + Sync {
async fn write(&self, events: Vec<Event>) -> Result<(), SinkError>;
async fn flush(&self) -> Result<(), SinkError>;
}These three patterns (Pipes and Filters, Decorator/Enrich, Source/Sink) are natural fits for functional style because they already think in terms of data transformation rather than stateful objects. Pipes and Filters is literally function composition: f ? g ? h. Decorator/Enrich is fmap over an event applying a function to the value inside a context without touching the structure. Source/Sink maps to the producer/consumer model at the heart of stream combinators.
III. The Architecture: DDD + Hexagonal in Rust
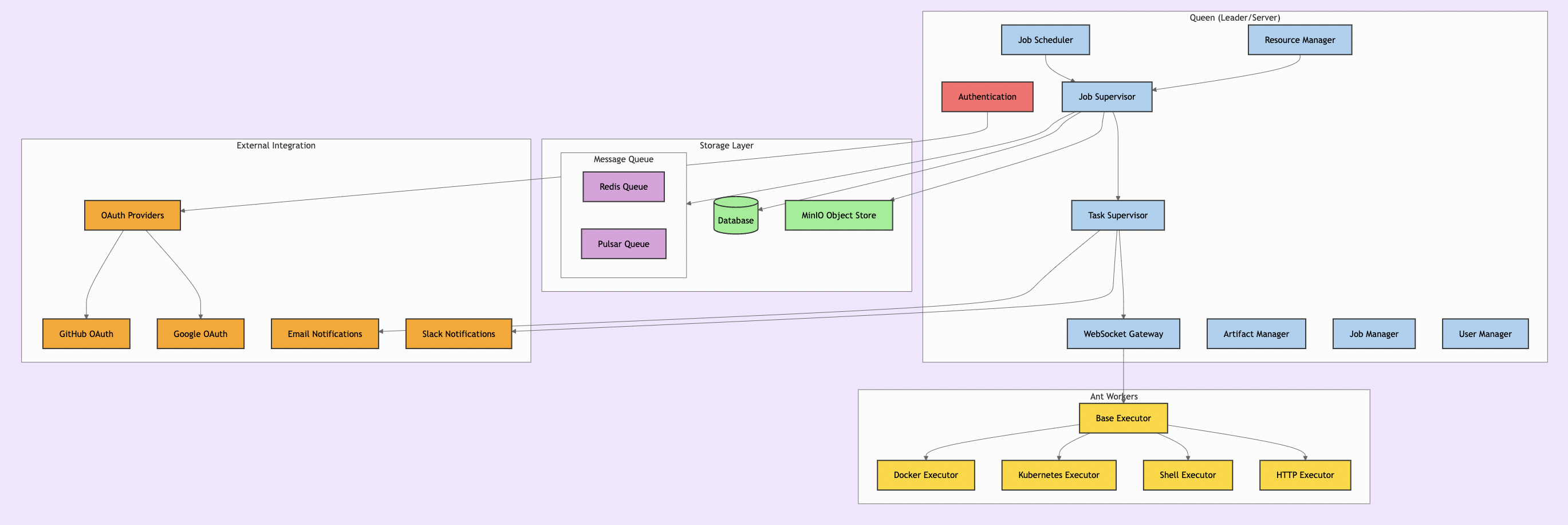
I previously wrote about DDD and Hexagonal architecture in https://shahbhat.medium.com/applying-domain-driven-design-and-clean-onion-hexagonal-architecture-to-microservic-284d54b3a874. I organized the POC as a Rust workspace with four crates, each representing a layer of the hexagonal architecture. Hexagonal architecture (also called ports and adapters) means: business logic sits in the center and knows nothing about the outside world. It defines “ports” as trait interfaces that the outside world must implement. The infrastructure layer provides “adapters” that fulfill those ports. The result is that you can test your domain logic without a database, without a network, without any I/O at all.

Dependencies point inward only: Interfaces depend on Application, Application depends on Domain, Infrastructure depends on Domain. The domain never imports anything from the outer layers. Here is how the Pipes and Filters pattern looks as an event flow through the system:

Each box in the filter chain is an independent PipelineFn. Each arrow carries an immutable Event. The chain is configured at runtime via the pipeline definition, but each stage is statically typed and independently testable.
The critical insight: Rust’s crate system makes architectural boundaries a compile-time guarantee. The domain crate literally cannot import infrastructure code. There is no way to “just quickly” add a database call to a domain service. This is the difference between architecture as aspiration and architecture as enforcement. The domain crate’s dependencies tell the whole story:
[dependencies]
ulid = { version = "1", features = ["serde"] }
serde = { version = "1", features = ["derive"] }
thiserror = "2"
async-trait = "0.1"
futures-core = "0.3"No I/O. No database drivers. No HTTP clients. No channels. Just data structures, pure functions, and trait definitions (ports) that the infrastructure layer must implement.
IV. Group 1 Foundations: Types, Errors, and Dependencies
These six patterns form the bedrock.
Antipattern 1: Singletons to Dependency Injection
Before: The legacy system used module-level singletons for everything like database connections, config, registries:
// Module-level mutable state, accessed globally
let pipelineManager: PipelineManager;
export function getInstance(): PipelineManager {
if (!pipelineManager) {
pipelineManager = new PipelineManager(/* hardcoded deps */);
}
return pipelineManager;
}
// Somewhere far away in the codebase:
getInstance().processBatch(events); // untestable, hidden dependencyTesting was a nightmare. You could not create a PipelineManager with a mock database because it internally called DatabaseSingleton.getInstance().
After: Every dependency is passed explicitly through constructors. The composition root (main.rs) is the only place that knows how to wire things together:
// Composition root: wiring happens once, at startup
let pipeline_repo = Arc::new(SqlitePipelineRepository::new(conn));
let route_repo = Arc::new(SqliteRouteRepository::new(conn));
let event_bus = Arc::new(ChannelEventBus::new(256));
// Services receive their dependencies — they don't hunt for them
let handler = CreatePipelineHandler::new(
pipeline_repo.clone(),
event_bus.clone(),
);This is the Reader monad made explicit: each handler is a function Config -> A, where the configuration (its dependencies) is threaded through construction rather than pulled from a global. No DI framework needed and the type system enforces what each component depends on.
Antipattern 2: Module-Level Mutable State to Immutable Values
Before: Events were passed by reference and mutated in place across pipeline stages:
function processEvent(event: any): void {
event.timestamp = Date.now(); // mutate in place
event.fields.processed = true; // caller's copy is changed
event.metadata.stage = "enriched"; // invisible side effect
}This is where the Decorator/Enrich pattern went wrong in the legacy system. The enrichment was correct in intent but destructive in implementation.
After: Events are immutable value objects. Every transformation returns a new event:
// Event is immutable — set_field returns a NEW event
pub fn set_field(&self, name: impl Into<FieldName>, value: FieldValue) -> Self {
let mut new_event = self.clone();
new_event.fields.insert(name.into(), value);
new_event
}
// Pipeline functions take ownership and return new values
pub trait PipelineFn: Send + Sync {
fn process(&self, event: Event) -> FnResult;
}An immutable Event is referentially transparent and enrich_with_timestamp(event) can be replaced by its result value anywhere in the program with no change in behavior. No aliasing bugs. The type system guarantees that if you have a reference to an event, nobody else is changing it.
Antipattern 5: God Class to Bounded Contexts
The thousands of lines in PipelineManager was split across four crates. Each crate has exactly one responsibility:
// domain/ — Event, Pipeline, Route, FnResult (pure data + logic) // app/ — CreatePipelineHandler, IngestEventHandler (orchestration) // infra/ — SqlitePipelineRepository, ChannelEventBus (I/O adapters) // api/ — REST endpoints, CLI commands (user interface)
The compiler enforces the boundaries. You cannot accidentally couple the routing logic to the database layer.
Antipattern 7: Error Swallowing to Result Types
Before: Errors vanished into the void:
try {
const pipeline = await loadPipeline(id);
const result = pipeline.process(event);
await sink.write(result);
} catch (e) {
// "it's fine"
}Hundreds of catch blocks like this in the legacy codebase. When something went wrong in production, the system kept running in a corrupted state.
After: Errors are values in the type signature. You cannot ignore them without the compiler warning you:
#[derive(Debug, thiserror::Error)]
pub enum DomainError {
#[error("validation: {0}")]
Validation(String),
#[error("{0} not found: {1}")]
NotFound(String, String),
#[error("pipeline execution: {0}")]
PipelineExecution(String),
#[error("persistence: {0}")]
Persistence(String),
}
// Every function that can fail declares it in its type
pub async fn handle(&self, cmd: CreatePipelineCommand) -> Result<Pipeline, DomainError> {
pipeline.validate()?; // ? propagates errors — impossible to forget
self.pipeline_repo.save(&pipeline).await?;
Ok(pipeline)
}The ? operator is syntactic sugar for monadic bind over Result. The for-comprehension equivalent in Scala (for { x <- f1; y <- f2 } yield ...) and Rust’s ?-chaining are the same pattern: sequence dependent computations and short-circuit on the first failure, propagating the error with full context.”
Antipattern 11: Primitive Obsession to Newtypes
Before: IDs were raw strings. Mix them up and nothing stops you:
function linkPipeline(pipelineId: string, routeId: string) { ... }
// Oops: arguments swapped, compiles fine, fails at runtime
linkPipeline(routeId, pipelineId);After: Each ID is a distinct type. The compiler catches mix-ups:
macro_rules! define_id {
($name:ident) => {
#[derive(Debug, Clone, PartialEq, Eq, Hash, Serialize, Deserialize)]
pub struct $name(String);
impl $name {
pub fn new() -> Self { Self(ulid::Ulid::new().to_string()) }
pub fn as_str(&self) -> &str { &self.0 }
}
};
}
define_id!(PipelineId);
define_id!(RouteId);
define_id!(EventId);
// fn link(pipeline: &PipelineId, route: &RouteId) — can't swap theseThis is the phantom type pattern: PipelineId and RouteId are both String at runtime, but they are different types at compile time because the wrapper carries no runtime data. Zero cost, full safety.
Antipattern 18: any Types to Generics and Trait Bounds
Before: The pipeline function interface accepted and returned any:
type ProcessorFn = (event: any) => any; // No contract. No guarantees. Runtime explosions.
After: Trait bounds make the contract explicit and compiler-checked:
pub trait PipelineFn: Send + Sync {
fn name(&self) -> &str;
fn process(&self, event: Event) -> FnResult;
}
pub trait PipelineFnFactory: Send + Sync {
fn create(&self, config: &serde_json::Value) -> Result<Box<dyn PipelineFn>, String>;
}The trait says: “Give me an Event, I’ll give you an FnResult (Pass, Split, or Drop).” No ambiguity. No any. The compiler enforces the contract at every call site.
V. Group 2 Data Modeling: Making Illegal States Unrepresentable
Antipattern 3: Mode/Env Branching to Sum Types
A sum type (also called an algebraic data type or ADT) is an enum where each variant carries different data. Instead of one struct with optional fields where only some combinations are valid, you define each valid combination as its own variant.
Before: Configuration types were discriminated by strings, with every consumer doing defensive checking:
interface FunctionConfig {
type: string; // "eval" | "drop" | "mask" | ... maybe?
field?: string; // required for some types
pattern?: string; // required for mask and regex
expression?: string; // required for eval
targetFields?: string[]; // only regex
}
// Every consumer:
if (config.type === "eval") {
if (!config.field || !config.expression) throw new Error("invalid");
}After: An enum makes illegal states unrepresentable. Each variant carries exactly its required data:
pub enum FunctionConfig {
Eval { field: String, expression: String },
Drop { filter: String },
Mask { field: String, pattern: String, replacement: String },
RegexExtract { field: String, pattern: String, target_fields: Vec<String> },
}
// Pattern matching is exhaustive — add a new variant and the compiler
// shows you every place that needs updating
fn resolve(config: &FunctionConfig) -> Result<Box<dyn PipelineFn>, DomainError> {
match config {
FunctionConfig::Eval { field, expression } => { /* guaranteed present */ }
FunctionConfig::Drop { filter } => { /* ... */ }
FunctionConfig::Mask { field, pattern, replacement } => { /* ... */ }
FunctionConfig::RegexExtract { field, pattern, target_fields } => { /* ... */ }
}
}Similarly, the result of processing an event is a sum type:
pub enum FnResult {
Pass(Event), // event continues downstream
Split(Vec<Event>), // one event becomes many
Drop, // event is discarded
}This is the core ADT insight: product types (structs, where a value has field A and field B) model data that is always fully present; sum types (enums, where a value is variant A or variant B) model data where only some combinations are valid. Illegal states become unrepresentable by construction. FnResult is a sum type that makes the three possible outcomes of a pipeline stage explicit. The legacy equivalent was return null | Event | Event[], but invisible to the type system and easy to miss in a catch {} block.
Antipattern 4: Type-String Dispatch to Registry Pattern
Before: Function types were resolved with an if/else chain that grew with every new type:
function createFunction(config: any): ProcessorFn {
if (config.type === "eval") return new EvalFn(config);
else if (config.type === "drop") return new DropFn(config);
else if (config.type === "mask") return new MaskFn(config);
// ... grows forever, easy to forget one
else throw new Error(`unknown type: ${config.type}`);
}After: A registry maps type names to factories. Adding new types does not touch existing code:
pub struct DefaultFunctionRegistry {
factories: HashMap<String, Box<dyn PipelineFnFactory>>,
}
impl DefaultFunctionRegistry {
pub fn new() -> Self {
let mut registry = Self { factories: HashMap::new() };
registry.factories.insert("eval".into(), Box::new(EvalFnFactory));
registry.factories.insert("drop".into(), Box::new(DropFnFactory));
registry.factories.insert("mask".into(), Box::new(MaskFnFactory));
registry.factories.insert("regex_extract".into(), Box::new(RegexExtractFnFactory));
registry
}
}The registry is an interpreter pattern where you separate the description of what to do (FunctionConfig as a DSL) from how to do it (PipelineFnFactory as the interpreter). This is the same structure as Free Monads: define your algebra as data (each FunctionConfig variant is an AST node), then write interpreters against it (production factories, test stubs, dry-run validators). The registry approach is the pragmatic version without monad transformer overhead, just a HashMap of factories. The key property is the same: you can swap the interpreter without touching the program description.
Antipattern 8: Temporal Coupling to Typestate Builder
Typestate is a pattern that uses the type system to enforce valid state transitions at compile time. You encode the object’s lifecycle phase into its type, so calling methods in the wrong order is a compiler error rather than a runtime error.
Before: Pipelines could be created in invalid states — no functions, empty description — and the error only surfaced at runtime:
const pipeline = new Pipeline(); pipeline.save(); // Oops: no functions, no description. Runtime error.
After: The builder uses phantom types to make the invalid state impossible to compile:
pub struct PipelineBuilder<State> {
id: PipelineId,
description: String,
functions: Vec<PipelineFunction>,
_state: PhantomData<State>,
}
// Can only add functions in the NoFunctions state (transitions to HasFunctions)
impl PipelineBuilder<NoFunctions> {
pub fn add_function(self, func: PipelineFunction) -> PipelineBuilder<HasFunctions> { ... }
}
// build() only exists on HasFunctions — you literally cannot call it without functions
impl PipelineBuilder<HasFunctions> {
pub fn build(self) -> Pipeline { ... }
}Rust’s ownership system is an affine type system: values may be used at most once (moved, not copied, unless Copy). The typestate builder exploits this: add_function(self) takes ownership of the builder and returns a new one in the next state. You literally cannot hold onto the old PipelineBuilder<NoFunctions> after calling add_function and the borrow checker makes it a compile error. This is stronger than a runtime lifecycle check: the invalid state cannot exist in memory, not just in logic.
Antipattern 9: Global Mutable Registry to Persistent Data Structures
Before: The route table was a global mutable singleton. Updates caused race conditions and stale reads:
class RouteRegistry {
private static instance: RouteRegistry;
private rules: RouteRule[] = []; // mutated by multiple threads
addRule(rule: RouteRule) { this.rules.push(rule); } // race!
}After: Route tables are immutable values. “Updating” returns a new version:
impl RouteTable {
pub fn add_rule(&self, rule: RouteRule) -> Self {
let mut new_table = self.clone();
new_table.rules.push(rule);
new_table.version += 1;
new_table
}
}In a real persistent data structure (Clojure’s HAMT, Haskell’s finger trees), ‘copying’ only involves copying the path from the modified node to the root with O(log n) nodes, not O(n). Rust’s clone() here is a simple structural copy, which is fine for small route tables. The principle is the same: multiple versions coexist safely because neither modifies the other.
Antipattern 12: Signal-Based Dispatch to Handler Map
Before: Event handling used a giant switch statement that grew with every new event type:
function handleSignal(signal: string, data: any) {
switch (signal) {
case "pipeline.created": notifyUI(data); break;
case "pipeline.deleted": cleanupCache(data); break;
// ... 40 more cases
}
}After: A handler map registers handlers by event type. New events are handled by registering a new handler, not by modifying existing code:
// Register handlers at composition time
let mut handlers: HashMap<String, Box<dyn EventHandler>> = HashMap::new();
handlers.insert("pipeline.created".into(), Box::new(NotifyUiHandler));
handlers.insert("pipeline.deleted".into(), Box::new(CleanupCacheHandler));
// Dispatch is a single lookup — no switch statement
if let Some(handler) = handlers.get(event.event_type()) {
handler.handle(event).await?;
}Antipattern 13: Anemic Domain Model to Rich Domain Objects
Before: Pipeline was a data bag with all logic living in external “service” classes:
class Pipeline {
id: string;
functions: FunctionConfig[];
// That's it. No behavior. Just a struct with public fields.
}
class PipelineService {
validate(p: Pipeline) { /* 200 lines */ }
addFunction(p: Pipeline, f: FunctionConfig) { /* 50 lines */ }
}After: The pipeline owns its behavior. Invariants are maintained internally:
impl Pipeline {
pub fn add_function(&mut self, func: PipelineFunction) {
self.functions.push(func);
self.version += 1; // version always tracks mutations
}
pub fn validate(&self) -> Result<(), DomainError> {
if self.description.is_empty() {
return Err(DomainError::Validation("description cannot be empty".into()));
}
if self.functions.is_empty() {
return Err(DomainError::Validation("must have at least one function".into()));
}
Ok(())
}
pub fn active_functions(&self) -> impl Iterator<Item = &PipelineFunction> {
self.functions.iter().filter(|f| !f.disabled)
}
}VI. Group 3: Composition and Control Flow
Antipattern 6: forEach + Push to Iterator Combinators
Before: Processing was imperative loops accumulating into mutable vectors:
function processBatch(events: any[], functions: ProcessorFn[]): any[] {
const results: any[] = [];
for (const event of events) {
let current = event;
for (const fn of functions) {
const result = fn(current);
if (result === null) break;
if (Array.isArray(result)) { results.push(...result); break; }
current = result;
}
if (current) results.push(current);
}
return results;
}After: The pipeline engine uses fold (reduce) over the function chain. This is the Pipes and Filters pattern made explicit where each function is a filter stage, the vector is the pipe:
pub struct PipelineEngine;
impl PipelineEngine {
pub fn process_event(event: Event, functions: &[&dyn PipelineFn]) -> Vec<FnResult> {
let mut current_events = vec![event];
let mut final_results = Vec::new();
for func in functions {
let mut next_batch = Vec::new();
for evt in current_events {
match func.process(evt) {
FnResult::Pass(e) => next_batch.push(e),
FnResult::Split(es) => next_batch.extend(es),
FnResult::Drop => final_results.push(FnResult::Drop),
}
}
current_events = next_batch;
}
final_results.extend(current_events.into_iter().map(FnResult::Pass));
final_results
}
}The pipeline engine’s inner loop is a fold (catamorphism) over the function list, with the accumulator being the current set of live events. Every iteration either passes events forward, fans them out (Split), or drops them. This is the structural recursion pattern: the shape of the computation mirrors the shape of the data (a linear chain of functions).
Antipattern 10: Callback Chains to Async Composition
Before: Nested callbacks (or deeply chained .then() promises) with error handling at each level:
loadConfig()
.then(config => loadPipeline(config.pipelineId))
.then(pipeline => pipeline.process(event))
.then(result => sink.write(result))
.catch(e => { /* which step failed? */ });After: Rust’s async/await with ? gives linear, readable control flow:
async fn handle(&self, cmd: IngestEventCommand) -> Result<Vec<Event>, DomainError> {
let route_table = self.route_repo.get_table().await?;
let decisions = RoutingEngine::route_event(&cmd.event, &route_table)?;
for decision in decisions {
let pipeline = self.pipeline_repo.get(&decision.pipeline_id).await?;
// ... each ? short-circuits on error with full context
}
Ok(all_output)
}Antipattern 14: Eager Initialization to Lazy Evaluation
Before: All pipeline functions, parsers, and regex patterns were compiled at startup, even if never used:
// All compiled eagerly at module load time, even for pipelines never triggered const ALL_PATTERNS = compileAllRegexPatterns(); // 500ms startup cost
After: Expensive initializations are deferred until first use with once_cell::Lazy, and streams are demand-driven:
use once_cell::sync::Lazy;
static REGEX_CACHE: Lazy<HashMap<String, Regex>> = Lazy::new(|| {
// Only compiled when first accessed
HashMap::new()
});
// Sources produce events on demand — pull, not push
impl EventSource for FileSource {
fn stream(&mut self) -> Pin<Box<dyn Stream<Item = Event> + Send + '_>> {
// Lines are read only when the consumer calls .next()
Box::pin(self.reader.lines().map(|line| parse_event(line)))
}
}Lazy::new is memoization with a single input (the unit type): the computation runs at most once and its result is cached forever. This is safe only because the initializer is pure with same (empty) input always produces the same output. If the initializer had side effects, re-running it vs. caching would produce different behavior.
Antipattern 15: Mixed I/O + Logic to Effect Separation
Before: Business logic was interleaved with database calls, HTTP requests, and logging:
async function processEvent(event: any) {
const config = await db.getConfig(); // I/O
event.enriched = transform(event, config); // logic
await kafka.publish(event); // I/O
metrics.increment("processed"); // I/O
if (event.severity > 3) {
await alertService.fire(event); // I/O
}
return event;
}After: Domain services are pure functions. I/O lives exclusively in the infrastructure layer:
// Domain service: PURE — no I/O, no side effects
impl PipelineEngine {
pub fn process_batch(events: Vec<Event>, functions: &[&dyn PipelineFn]) -> BatchResult {
// Pure computation: transform events through functions
}
}
// Application layer: orchestrates I/O around pure domain logic
impl IngestEventHandler {
pub async fn handle(&self, cmd: IngestEventCommand) -> Result<Vec<Event>, DomainError> {
let route_table = self.route_repo.get_table().await?; // I/O: read
let decisions = RoutingEngine::route_event(&cmd.event, &route_table)?; // Pure
// ... resolve functions (I/O), process (pure), return results
}
}This is Functional Core, Imperative Shell (FCIS) in practice: PipelineEngine::process_batch is the functional core with a pure function, trivially testable, no mocks needed. IngestEventHandler::handle is the imperative shell that orchestrates I/O around the pure core, calling out to repositories and event buses. The pattern is the same as Haskell’s IO monad: describe what to do (pure), defer execution to the edge (impure).
Antipattern 16: Monolithic Functions to Function Composition
The key insight from the pipeline engine: each transform is a small, independent function that composes with others. Instead of one 500-line processEvent() method that does everything, we have a chain of focused transforms:
// Each function is tiny and testable in isolation
struct MaskFn { field: String, regex: Regex, replacement: String }
impl PipelineFn for MaskFn {
fn name(&self) -> &str { "mask" }
fn process(&self, event: Event) -> FnResult {
match event.get_field(&self.field) {
Some(FieldValue::Str(value)) => {
let masked = self.regex.replace_all(value, self.replacement.as_str());
FnResult::Pass(event.set_field(&self.field, FieldValue::Str(masked.into())))
}
_ => FnResult::Pass(event),
}
}
}This is the Pipes and Filters pattern at the code level. Each PipelineFn is a filter. The engine composes them into a pipeline. You can test each filter in isolation, reorder them, add new ones without touching existing filters.
Each PipelineFn implementation is a pure function transformer: it takes an Event and returns an FnResult. The engine is function composition at runtime — the pipeline definition is a list of function names that the registry resolves into a chain of Box<dyn PipelineFn>. Adding a new stage means writing one new impl PipelineFn block, not touching the engine.
Antipattern 17: No Rollback to Saga Pattern
Before: Multi-step operations had no compensation logic. If step 3 of 5 failed, steps 1-2 left orphaned state:
await db.savePipeline(pipeline);
await registry.register(pipeline); // if this fails, DB has orphan
await bus.publish("created"); // if this fails, registry is staleAfter: Command handlers treat publish failures as non-fatal (eventual consistency), and the pattern supports full compensation:
pub async fn handle(&self, cmd: CreatePipelineCommand) -> Result<Pipeline, DomainError> {
self.pipeline_repo.save(&pipeline).await?;
// Non-critical: event publication. If it fails, the pipeline still exists.
// A background reconciler can re-publish later.
if let Err(e) = self.event_publisher.publish(event).await {
tracing::warn!("Failed to publish PipelineCreated event: {}", e);
}
Ok(pipeline)
}This is the simplified saga pattern, treating non-critical steps (event publication) as best-effort with background reconciliation, rather than requiring two-phase commit. Full saga compensation (explicit rollback actions for each step) would be appropriate if, say, publishing failure meant the pipeline should be marked inactive. The pattern scales from ‘log and retry’ to full compensating transactions depending on consistency requirements.
VII. Group 4: Concurrency and Architecture
Antipattern 20: Monolithic Startup to Plugin Architecture
Before: Adding a new source or sink type required modifying core initialization code in multiple files:
// startup.ts — grows with every new component
import { KafkaSource } from './sources/kafka';
import { S3Sink } from './sinks/s3';
import { HttpSource } from './sources/http';
// ... 30 more imports
function init() {
registerSource('kafka', KafkaSource);
registerSource('http', HttpSource);
// ... grows linearly
}After: Cargo features allow components to be compiled in or out. The function registry pattern means new types are added without modifying existing code:
[features] default = ["http-source", "file-source", "stdout-sink"] http-source = [] file-source = [] stdout-sink = [] memory-sink = []
// New source? Implement the trait and register in the feature-gated module.
// No existing code changes.
#[cfg(feature = "http-source")]
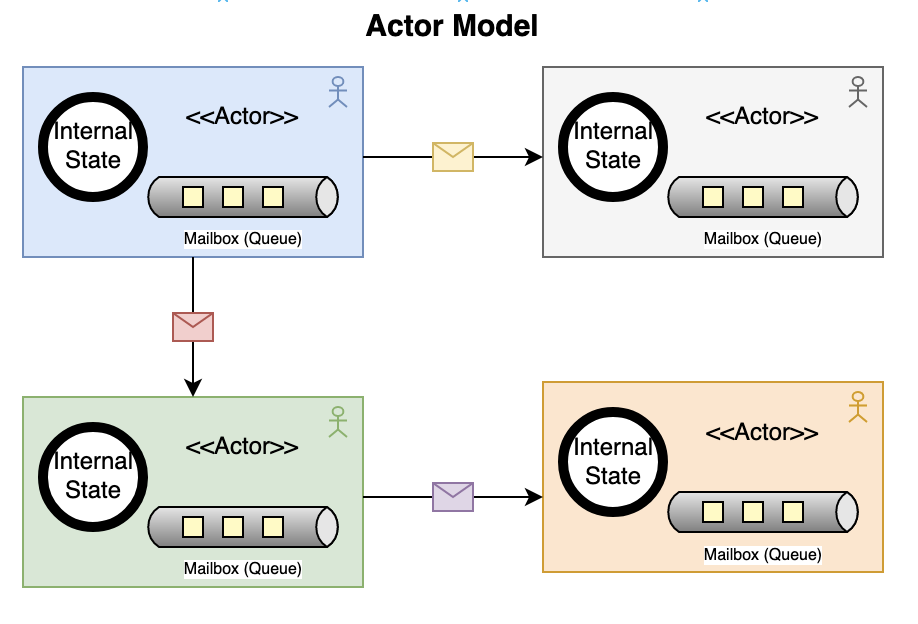
registry.register_source("http", Box::new(HttpSourceFactory));Antipattern 21: OS Process Forking to Actor Model
Before: The legacy system scaled by forking OS processes, each with its own copy of global state:
import cluster from 'cluster';
if (cluster.isPrimary) {
for (let i = 0; i < numCPUs; i++) cluster.fork();
} else {
startWorker(); // entire app copied, 200MB per worker
}After: Lightweight async actors communicate through bounded channels:
pub struct PipelineActor {
rx: mpsc::Receiver<PipelineActorMsg>,
output_tx: mpsc::Sender<Vec<Event>>,
functions: Vec<Box<dyn PipelineFn>>,
state: PipelineActorState,
}
impl PipelineActor {
pub async fn run(mut self) {
while let Some(msg) = self.rx.recv().await {
match msg {
PipelineActorMsg::ProcessBatch(events) => {
let result = PipelineEngine::process_batch(events, &fn_refs);
self.state.processed += result.passed.len() as u64;
if !result.passed.is_empty() {
let _ = self.output_tx.send(result.passed).await;
}
}
PipelineActorMsg::Shutdown => break,
}
}
}
}This is Erlang’s actor model translated to Tokio tasks. The key insight from both models: if there is no shared mutable state, there is nothing to race over. Tokio’s mpsc bounded channel is the CSP channel where both sender and receiver synchronize on the buffer, and backpressure propagates automatically when the buffer is full.
Antipattern 22: Leader Bottleneck to Version Vectors
Rather than a single leader node holding all configuration state, each entity carries its own version number. Concurrent updates to different pipelines do not conflict.
pub struct Pipeline {
pub version: u64, // incremented on every mutation
// ...
}
impl Pipeline {
pub fn add_function(&mut self, func: PipelineFunction) {
self.functions.push(func);
self.version += 1;
}
}
// Optimistic concurrency: "update only if still at version 7"
pub async fn save(&self, pipeline: &Pipeline) -> Result<(), DomainError> {
let rows = sqlx::query("UPDATE pipelines SET ... WHERE id = ? AND version = ?")
.bind(pipeline.id.as_str())
.bind(pipeline.version - 1) // expected previous version
.execute(&self.pool).await?;
if rows.rows_affected() == 0 {
return Err(DomainError::ConcurrencyConflict);
}
Ok(())
}The principled FP alternative to optimistic locking is Software Transactional Memory (STM): compose atomic operations on shared memory without locks, with automatic retry on conflict. Haskell’s atomically $ do { modifyTVar from subtract; modifyTVar to (+) } makes multi-step updates composable where either all happen or none do. Rust doesn’t have STM in the standard library, and for database-backed state, optimistic locking (version vectors + UPDATE WHERE version = N) achieves the same semantic: detect conflicts at commit time, retry at the application layer. STM is preferable when conflicts are rare and the critical section is in-memory; version vectors scale to distributed state across process boundaries.
Antipattern 23: Shared Code Bloat to Feature-Gated Modules
The Cargo features system means you only compile what you need. A deployment that only uses HTTP sources does not include the file-tailing code. Binary size stays small, and the dependency graph is explicit.
// Only compiled when the feature is enabled #[cfg(feature = "file-source")] pub mod file_source; #[cfg(feature = "http-source")] pub mod http_source;
Antipattern 24: Push Without Backpressure to Bounded Channels
Before: Producers pushed events into unbounded queues. Under load, memory grew until the process OOM’d:
const queue: Event[] = []; // grows forever
source.on('data', event => queue.push(event)); // no limit!After: Bounded channels create natural backpressure. When the buffer is full, producers wait:
pub struct HttpEventSource {
sender: mpsc::Sender<Event>,
receiver: Option<mpsc::Receiver<Event>>,
}
impl HttpEventSource {
pub fn new(buffer_size: usize) -> Self {
let (sender, receiver) = mpsc::channel(buffer_size); // bounded!
Self { sender, receiver: Some(receiver) }
}
}Bounded channels are the Rust equivalent of reactive streams backpressure: when the downstream consumer can’t keep up, the sender.send().await call suspends the producer task rather than buffering unboundedly. The pipeline becomes a dataflow graph where each stage’s throughput is constrained by its slowest downstream neighbor.
Antipattern 25: Polling to Lazy Pull Streams
Before: Workers polled for new data on a timer, wasting CPU when idle and introducing latency when busy:
setInterval(async () => {
const batch = await queue.poll(); // wasteful when idle
if (batch.length > 0) process(batch);
}, 100); // 100ms latency floorAfter: Event sources implement the Stream trait. Consumers pull one item at a time via .next().await, which parks the task until data is available:
use futures::StreamExt;
// Consumer pulls events on demand — no polling, no wasted cycles
while let Some(event) = source.stream().next().await {
let results = PipelineEngine::process_event(event, &fn_refs);
for result in results {
sink.write(result).await?;
}
}A Stream is corecursive: where recursion consumes a finite structure by breaking it down (a catamorphism, like AP 28), corecursion produces a potentially infinite structure by building it up one step at a time (an anamorphism). FileSource::stream() is an anamorphism over the file: the seed is the file handle, each step produces one event and a new handle position, and the stream terminates when the handle is exhausted. The Stream trait is Rust’s lazy sequence and the functional equivalent of Haskell’s LazyList or Scala’s LazyList. Nothing is computed until the consumer calls .next().await. This is demand-driven (pull) evaluation: the producer runs exactly as fast as the consumer needs, with no intermediate buffering and no polling overhead.
VIII. Group 5: Advanced Functional Patterns
Antipattern 19: Opaque Service Interfaces to Capability Traits
Before: Services exposed god-interfaces with dozens of methods, most irrelevant to any given caller:
interface PipelineService {
create(p: Pipeline): void;
delete(id: string): void;
process(event: any): any;
getMetrics(): Metrics;
reload(): void;
// ... 20 more methods
}After: Each capability is a separate trait. Callers depend only on what they need:
// Fine-grained capability traits
pub trait FunctionResolver: Send + Sync {
fn resolve(&self, config: &FunctionConfig) -> Result<Box<dyn PipelineFn>, DomainError>;
}
pub trait PipelineRepository: Send + Sync {
async fn get(&self, id: &PipelineId) -> Result<Pipeline, DomainError>;
async fn save(&self, pipeline: &Pipeline) -> Result<(), DomainError>;
}
// Callers declare exactly what they need — nothing more
struct IngestHandler {
resolver: Arc<dyn FunctionResolver>,
repo: Arc<dyn PipelineRepository>,
}Fine-grained capability traits are Tagless Final in practice. Instead of a concrete PipelineService god-object, you declare your algebra as a set of type class constraints: fn ingest<R, P>(resolver: &R, repo: &P, event: Event) where R: FunctionResolver and P: PipelineRepository. The function is polymorphic over its effects and you substitute production implementations at the composition root and test stubs in unit tests, with zero runtime overhead compared to dynamic dispatch.
Antipattern 26: Deep Inheritance to Trait Composition
Before: A 6-level inheritance hierarchy where each level overrode different methods:
class BaseProcessor { ... }
class FilteringProcessor extends BaseProcessor { ... }
class EnrichingProcessor extends FilteringProcessor { ... }
class BatchingEnrichingProcessor extends EnrichingProcessor { ... }
// "Which version of transform() am I actually running?" — nobody knowsAfter: Behavior is defined through trait composition. No inheritance. Each implementation is independent and flat:
pub trait PipelineFn: Send + Sync {
fn name(&self) -> &str;
fn process(&self, event: Event) -> FnResult;
}
// Each implementation is flat — no hierarchy, no overriding
impl PipelineFn for EvalFn { ... }
impl PipelineFn for DropFn { ... }
impl PipelineFn for MaskFn { ... }
impl PipelineFn for RegexExtractFn { ... }You never ask “which version of process() am I actually running?” There is exactly one implementation per type. No surprises.
Antipattern 27: Unbounded Recursion to Iterative Fold
Before: Batch processing used recursion that could blow the stack on large inputs:
function processAll(events: any[], fns: Function[], idx: number): any[] {
if (idx >= fns.length) return events;
return processAll(events.map(fns[idx]), fns, idx + 1); // stack overflow risk
}After: The pipeline engine uses iterative fold. Stack overflow is impossible regardless of pipeline length:
// Iterative: each function is applied in a loop, not via recursion
for func in functions {
let mut next_batch = Vec::new();
for evt in current_events {
match func.process(evt) {
FnResult::Pass(e) => next_batch.push(e),
FnResult::Split(es) => next_batch.extend(es),
FnResult::Drop => {}
}
}
current_events = next_batch;
}Antipattern 28: Ad-Hoc Recursion to Catamorphism
A catamorphism is a recursive fold over a tree structure and you define how to handle each node type, and the recursion follows the shape of the data automatically. The routing engine evaluates filter expressions using this pattern:
pub fn evaluate_filter(filter: &FilterExpr, event: &Event) -> Result<bool, DomainError> {
match filter {
FilterExpr::Eq(field, expected) => {
Ok(event.get_field(field) == Some(expected))
}
FilterExpr::And(left, right) => {
Ok(Self::evaluate_filter(left, event)? && Self::evaluate_filter(right, event)?)
}
FilterExpr::Or(left, right) => {
Ok(Self::evaluate_filter(left, event)? || Self::evaluate_filter(right, event)?)
}
FilterExpr::Not(inner) => Self::evaluate_filter(inner, event).map(|b| !b),
FilterExpr::True => Ok(true),
}
}The catamorphism’s real value is that it separates what to compute at each node from how to recurse. You never write the recursive traversal by hand and the match on the enum is the recursion. Add a new FilterExpr variant and every unhandled match becomes a compile error.
Antipattern 29: Hardcoded Parsers to Parser Combinators
Before: Filter expressions were parsed with regex and string splitting, growing more fragile with each new operator:
function parseFilter(expr: string): Filter {
if (expr.includes(' AND ')) {
const parts = expr.split(' AND ');
return { type: 'and', left: parseFilter(parts[0]), right: parseFilter(parts[1]) };
}
// fails silently on malformed input
}After: Parser combinators (using nom) build complex parsers from small, tested pieces:
fn parse_comparison(input: &str) -> IResult<&str, FilterExpr> {
let (input, field) = parse_identifier(input)?;
let (input, _) = multispace0(input)?;
let (input, op) = alt((tag("=="), tag("!="), tag(">"), tag("<"), tag("contains")))(input)?;
let (input, _) = multispace0(input)?;
let (input, value) = parse_value(input)?;
let expr = match op {
"==" => FilterExpr::Eq(field, value),
"!=" => FilterExpr::Neq(field, value),
">" => FilterExpr::Gt(field, value),
"<" => FilterExpr::Lt(field, value),
"contains" => FilterExpr::Contains(field, value),
_ => unreachable!(),
};
Ok((input, expr))
}
fn parse_and(input: &str) -> IResult<&str, FilterExpr> {
let (input, left) = parse_atom(input)?;
let (input, _) = delimited(multispace0, tag_no_case("AND"), multispace0)(input)?;
let (input, right) = parse_expr(input)?;
Ok((input, FilterExpr::And(Box::new(left), Box::new(right))))
}Parser combinators are applicative by nature: parse_comparison and parse_and are independent parsers composed with alt (choice) and sequence (both must succeed). This is the Applicative pattern and unlike a monad, where each step depends on the previous result, applicative composition runs independent effects and combines their outputs. alt((tag("=="), tag("!="))) is f <*> g where both parsers are defined statically, with no dependency between them.
Antipattern 30: Stringly-Typed Field Access to Typed Lenses
Before: Accessing nested event data was a chain of string lookups with no type safety:
const value = event.fields["user"]["email"]; // undefined? string? number? who knows
if (value) { /* hope it's a string */ }After: Typed accessor methods (lens-style) provide safe, focused access to nested data:
// get_field returns Option<&FieldValue> — forces the caller to handle absence
let email = event.get_field("user.email");
// set_field returns a new event — the lens "focuses" on one field
// and produces a new whole from the modified part
let masked = event.set_field("user.email", FieldValue::Str("[REDACTED]".into()));
// Type-safe: you know exactly what you're getting
match event.get_field("severity") {
Some(FieldValue::Int(level)) => route_by_severity(*level),
Some(FieldValue::Str(s)) => route_by_severity(s.parse()?),
None => route_to_default(),
_ => Err(DomainError::Validation("unexpected severity type".into())),
}Antipattern 31: Implicit Mutable State to Reducer Pattern
The actor’s message loop is a reducer: it receives a message and transitions to a new state. The state is always consistent because there is only one owner (the actor itself):
// State transitions are explicit and atomic
PipelineActorMsg::ProcessBatch(events) => {
let result = PipelineEngine::process_batch(events, &fn_refs);
self.state.processed += result.passed.len() as u64;
self.state.dropped += result.dropped;
}No concurrent access. No locks. No race conditions. The actor pattern plus Rust’s ownership model guarantees single-writer semantics.
Antipattern 32: Monkey-Patching to Extension via Traits
Before: Extending behavior meant modifying existing classes or patching prototypes at runtime:
// Monkey-patching: modifying someone else's class at runtime
Pipeline.prototype.customProcess = function() { /* surprise! */ };After: You implement a trait for your type. The registry accepts any Box<dyn PipelineFn> — your custom function is a first-class citizen without modifying any framework code:
// Your custom function — no framework modification needed
struct MyCustomFn { config: MyConfig }
impl PipelineFn for MyCustomFn {
fn name(&self) -> &str { "my_custom" }
fn process(&self, event: Event) -> FnResult { /* your logic */ }
}
// Register it alongside built-in functions
registry.register("my_custom", Box::new(MyCustomFnFactory));Antipattern 33: Implicit Ordering to Typestate Lifecycle
The actor has a clear lifecycle: Created, Running, Stopped. The run() method consumes self, making it impossible to use the actor after it has been started (unless you keep the handle):
impl PipelineActor {
pub async fn run(mut self) { // takes ownership — actor is "consumed"
while let Some(msg) = self.rx.recv().await { ... }
// When this returns, the actor is done. No zombie state.
}
}
// After spawning, you only have the handle — not the actor itself
let handle = tokio::spawn(actor.run()); // actor moved into the task
// actor.do_something(); // COMPILE ERROR: actor has been movedAntipattern 34: Window via Mutation to Comonad-Style
A comonad is a structure that provides context around a focused element. Think of it as the dual of a monad: where a monad wraps a value you can map over, a comonad gives you a value plus its neighborhood.
Before: Sliding windows were implemented as mutable arrays with index arithmetic:
class SlidingWindow {
private buffer: any[] = [];
private index = 0;
push(item: any) { this.buffer[this.index++ % this.size] = item; }
getContext() { /* complex index math, off-by-one bugs */ }
}After: A comonad-style window provides extract() (get the focused value) and extend() (apply a context-aware function at every position):
pub struct SlidingWindow<T> {
items: VecDeque<T>,
focus_idx: usize,
window_size: usize,
}
impl<T: Clone> SlidingWindow<T> {
/// Get the focused element (comonad extract)
pub fn extract(&self) -> Option<&T> {
self.items.get(self.focus_idx)
}
/// Apply a function at every position, producing a new window (comonad extend)
pub fn extend<B, F>(&self, f: F) -> SlidingWindow<B>
where
F: Fn(&SlidingWindow<T>) -> B,
B: Clone,
{
let mut results = VecDeque::with_capacity(self.items.len());
for i in 0..self.items.len() {
let shifted = SlidingWindow {
items: self.items.clone(),
focus_idx: i,
window_size: self.window_size,
};
results.push_back(f(&shifted));
}
SlidingWindow { items: results, focus_idx: self.focus_idx, window_size: self.window_size }
}
}A monad lets you chain ‘what to do next’ (flatMap), a comonad lets you ask ‘what does the context around this value say’ (extend). The classic examples are spreadsheets (each cell is a value with a grid of neighbors) and Conway’s Game of Life (extend step grid applies the evolution rule at every cell simultaneously). In the pipeline, extend lets you compute a moving average or rate-of-change at every position in one pass, without index arithmetic.
Antipattern 35: Static Worker Assignment to Work-Stealing
Before: Work was distributed round-robin to a fixed number of workers, causing hot spots:
const workers = Array.from({ length: 4 }, () => new Worker());
let nextWorker = 0;
function dispatch(batch) {
workers[nextWorker++ % workers.length].send(batch); // unbalanced
}After: For CPU-bound batch processing, rayon‘s parallel iterators provide work-stealing scheduling:
use rayon::prelude::*;
// rayon automatically distributes work across cores
let results: Vec<BatchResult> = batches
.par_iter()
.map(|batch| PipelineEngine::process_batch(batch.clone(), &fn_refs))
.collect();Use rayon for CPU-bound batch processing where tasks are independent and similar in size. Use the actor-per-pipeline model (Antipattern 21) for I/O-bound work and heterogeneous task sizes and actors handle backpressure and message ordering; rayon just parallelizes.”
IX. The Human Cost
The patterns described here are not primarily about performance, they are about cognitive load. When errors are values, when states are explicit in types, when illegal states are unrepresentable, and when each function does one thing, a new engineer can understand any individual piece in isolation. That is the real dividend of functional discipline: onboarding time and debugging time drop together.
Each pattern from above addresses a real cost that the team paid every day. For example, new engineers on the legacy system could not ship features for months. Not because observability pipelines are conceptually hard. It was because the system had enormous artificial complexity. There was no way to understand one piece in isolation because everything depended on everything else.
When errors are swallowed, states are implicit, and types are erased, debugging a production incident means reading every log line and reconstructing what happened. In the new system, errors propagate with context. The route table is immutable, so corruption is structurally impossible. All of these costs reinforce each other. Slow onboarding means fewer experienced engineers. Fewer experienced engineers means less refactoring capacity. Less refactoring means more debt.
X. Conclusion
This is not a story about Rust vs. TypeScript and it comes with a working POC at github.com/bhatti/pipeflow that implements all the patterns described. TypeScript with strict: true, branded types, and careful architecture can achieve many of the same guarantees. The lesson is about principles:
- Keep what works. Pipes and Filters, Decorator/Enrich, Source/Sink worked. The problem was their implementation, not their design.
- Make illegal states unrepresentable. Use sum types (enums where each variant carries different data) and typestate (using the type system to enforce valid state transitions) to shift runtime errors to compile-time.
- Separate effects from logic. Pure domain functions are trivially testable and infinitely composable.
- Enforce boundaries with the build system. Architecture diagrams lie. Compiler errors do not.
- Prefer immutable data. Clone when you need to diverge. The clarity is worth the allocation.
- Make errors explicit.
Result<T, E>in the type signature. No swallowing. No surprises. - Compose small functions. A pipeline of 5 focused transforms beats one 500-line method.
- Name the patterns. Immutable values, sum types, typestate, catamorphism, comonad are not buzzwords. They are compressed names for solutions that took decades to discover. Knowing the name means knowing the laws, the composability guarantees, and the tradeoffs.
The mud did not accumulate overnight, and it will not disappear overnight. But every boundary you draw, every type you make explicit, every error you refuse to swallow makes the next change slightly easier. That is how you reverse the flywheel.
Source code: The full POC implementing all patterns described here is available as an open-source Rust project at github.com/bhatti/pipeflow.
XI. Pattern Index
| # | Antipattern -> Solution | Core FP Concept(s) | Section |
|---|---|---|---|
| 1 | Singletons -> Dependency Injection | Reader Monad, Functional Core/Imperative Shell | IV |
| 2 | Mutable State -> Immutable Values | Referential Transparency, Value Semantics | IV |
| 3 | Mode Branching -> Sum Types | ADT (Sum Types), Exhaustive Pattern Matching | V |
| 4 | String Dispatch -> Registry | Tagless Final (lite), Open/Closed, First-Class Functions | V |
| 5 | God Class -> Bounded Contexts | Module Systems, FCIS, Separation of Concerns | IV |
| 6 | forEach + Push -> Iterator Combinators | Functor (map), Fold / Catamorphism, Lazy Pipelines | VI |
| 7 | Error Swallowing -> Result Types | Monad (bind / ?), Either / Option, Monadic Chaining | IV |
| 8 | Temporal Coupling -> Typestate Builder | Phantom Types, Affine / Linear Types, Typestate | V |
| 9 | Global Registry -> Persistent Data Structures | Persistent DS, Structural Sharing, Immutable Updates | V |
| 10 | Callback Chains -> Async Composition | Monad (sequential composition), CPS (async/await desugaring) | VI |
| 11 | Primitive Obsession -> Newtypes | Newtype Pattern, Phantom Types, Zero-Cost Abstraction | IV |
| 12 | Signal Dispatch -> Handler Map | First-Class Functions, Open Dispatch, Strategy Pattern | V |
| 13 | Anemic Model -> Rich Domain Objects | ADTs, Encapsulation of Invariants, Expression-Oriented | V |
| 14 | Eager Init -> Lazy Evaluation | Thunks, Memoization (evaluate-once semantics) | VI |
| 15 | Mixed I/O + Logic -> Effect Separation | IO Monad, Algebraic Effects, Functional Core / Imperative Shell | VI |
| 16 | Monolithic Functions -> Function Composition | Function Composition, Point-Free Style, Pipes and Filters | VI |
| 17 | No Rollback -> Saga Pattern | Eventual Consistency, Compensating Transactions | VI |
| 18 | any Types -> Generics + Trait Bounds | Type Classes, Parametric Polymorphism, Ad-Hoc Polymorphism | IV |
| 19 | God Interface -> Capability Traits | Interface Segregation, Type Classes, Dependency Inversion | VIII |
| 20 | Monolithic Startup -> Plugin Architecture | Open/Closed Principle, Feature-Gated Modules | VII |
| 21 | OS Process Forking -> Actor Model | Actor Model, CSP (message-passing), Isolated Mutable State | VII |
| 22 | Leader Bottleneck -> Version Vectors | Optimistic Concurrency, STM (contrast), Immutable Versioning | VII |
| 23 | Shared Code Bloat -> Feature-Gated Modules | Conditional Compilation, Module System Boundaries | VII |
| 24 | Unbounded Push -> Bounded Channels | CSP Channels, Reactive Streams, Backpressure | VII |
| 25 | Polling -> Lazy Pull Streams | Lazy Evaluation, Corecursion, Demand-Driven Streams | VII |
| 26 | Deep Inheritance -> Trait Composition | Composition over Inheritance, Type Classes, Flat Dispatch | VIII |
| 27 | Unbounded Recursion -> Iterative Fold | Trampolining, Tail Recursion, Accumulator-Passing Style | VIII |
| 28 | Ad-Hoc Recursion -> Catamorphism | Recursion Schemes (Catamorphism), Structural Recursion | VIII |
| 29 | Hardcoded Parsers -> Parser Combinators | Parser Combinators, Applicative Functor, Monad | VIII |
| 30 | Stringly-Typed Access -> Typed Lenses | Lenses / Optics, Profunctors, Focused Immutable Update | VIII |
| 31 | Implicit Mutation -> Reducer Pattern | Fold, State Monad, Single-Writer Semantics | VIII |
| 32 | Monkey-Patching -> Extension via Traits | Type Classes, Retroactive Extension, Coherence | VIII |
| 33 | Implicit Ordering -> Typestate Lifecycle | Linear / Affine Types, Typestate, Ownership as Protocol | VIII |
| 34 | Mutable Window -> Comonad-Style | Comonad (extract / extend), Context-Aware Computation | VIII |
| 35 | Round-Robin Workers -> Work-Stealing | Parallel Collections, Work-Stealing, parMap | VIII |