Abstract
Software is eating the world and today’s businesses demand shipping software features at a higher velocity to enable learning at a greater pace without compromising the quality. However, each new feature increases viscosity of existing code, which can add more complexity and technical debt so the time to market for new features becomes longer. Managing a sustainable pace for software delivery requires continuous improvements to the software development architecture and practices.
Software Architecture
The Software Architecture defines guiding principles and structure of the software systems. It also includes quality attribute such as performance, sustainability, security, scalability, and resiliency. The software architecture is then continuously updated through iterative software development process and feedback cycle from the the actual use in production environment. The software architecture decays if it’s ignored that results in a higher complexity and technical debt. In order to reduce technical debt, you can build a backlog of technical and architecture related changes so that you can prioritize along with the product development. In order to maintain consistent architecture throughout your organization, you can document the architecture principles to define high-level guidelines for best practices, documentation templates, review process and guidance for the architecture decisions.
Quality Attributes
Following are major quality attributes of the software architecture:
- Availability — It defines percentage of time, the system is available, e.g. available-for-use-time / total-time. It is generally referred in percentiles such as P99.99, which indicates a down time of 52 minutes in a year. It can also be calculated in terms of as mean-time between failure (MTBF) and mean-time to recover (MTRR) using
MTBF/(MTBF+MTRR). The availability will depend not only on the service that you are providing but also its dependent services, e.g. P-service * P-dep-service-1 * P-dep-service-2. You can improve availability with redundant services, which can be calculated as Max-availability - (100 - Service-availability) ** Redundancy-factor. In order to further improve availability, you can detect faults and use redundancy and state synchronization for fault recovery. The system should also handle exceptions gracefully so that it doesn’t crash or goes into a bad state. - Capacity — Capacity defines how the system scales by adding hardware resources.
- Extensibility — Extensibility defines how the system meets future business requirements without significantly changing existing design and code.
- Fault Tolerance — Fault tolerance prevents a single point of failure and allows the system to continue operating even when parts of the system fail.
- Maintainability — Higher quality code allows building robust software with higher stability and availability. This improves software delivery due to modular and loosely coupled design.
- Performance — It is defined in terms of latency of an operation under normal or peak load. A performance may degrade with consumptions of resources, which affects throughput and scalability of the system. You can measure user’s response-time, throughput and utilization of computational resources by stress testing the system. A number of tactics can be used to improve performance such as prioritization, reducing overhead, rate-limiting, asynchronicity, caching, etc. Performance testing can be integrated with continuous delivery process that use load and stress testing to measure performance metrics and resource utilization.
- Resilience — Resilience accepts the fact that faults and failure will occur so instead system components resist them by retrying, restarting, limiting error propagation or other measures. A failure is when a system deviates from its expected behavior as a result of accidental fault, misconfigurations, transient network issues or programming error. Two metrics related to resilience are mean-time between failure (MTBF) and mean-time to recover (MTTR), however resilient systems pay more attention to recovery or a shorter MTTR for fast recovery.
- Recovery — Recovery looks at system recover in relation with availability and resilience. Two metrics related to recovery are recovery point objective (RPO) and recovery time objective (RTO), where RPO determines data that can be lost in case of failure and RTO defines wait time for the system recovery.
- Reliability — Reliability looks at the probability of failure or failure rate.
- Reproducibility — Reproducibility uses version control for code, infrastructure, configuration so that you can track and audit changes easily.
- Reusability — It encourages code reuse to improve reliability, productivity and cost savings from the duplicated effort.
- Scalability — It defines ability of the system to handle increase in workload without performance degradation. It can be expressed in terms of vertical or horizontal scalability, where horizontal reduces impact of isolated failure and improves workload availability. Cloud computing offers elastic and auto-scaling features for adding additional hardware when higher request rate is detected by the load balancer.
- Security — Security primarily looks at confidentiality, integrity, availability (CIA) and is critical in building distributed systems. Building secure systems depends on security practices such as a strong identity management, defense in depth, zero trust networks, auditing, ad protecting while data in motion or at rest. You can adopt DevSecOps that shifts security left to earlier in software development lifecycle with processes such as Security by Design (SbD), STRIDE (Spoofing, Tampering, Repudiation, Disclosure, Denial of Service, Elevation of privilege), PASTA (Process for Attack Simulation and Threat Analysis), VAST (Visual, Agile and Simple Threat), CAPEC (Common Attack pattern Enumeration and Classification), and OCTAGE (Operationally Critical Threat, and Vulnerability Evaluation).
- Testability — It encourages building systems in a such way it’s easier to test them.
- Usability — It defines user experience of user interface and information architecture.
Architecture Patterns
Following is a list of architecture patterns that help building a high quality software:
Asynchronicity
Synchronous services are difficult to scale and recover from failures because they require low-latency and can easily overwhelm the services. Messaging-based asynchronous communication based on point-to-point or publish/subscribe are more suitable for handling faults or high load. This improves resilience because service components can restart in case of failure while messages remain in the queue.
Admission Control
The admission control adds a authentication, authorization or validation check in front event queue so that service can handle the load and prevent overload when demand exceeds the server capacity.
Back Pressure
When a producer is generating workload faster than the server can process, it can result in long request queues. Back pressure signals clients that servers are overloaded and clients need to slow down. However, rogue clients may ignore these signals so servers often employ other tactics such as admission control, load shedding, rate limiting or throttling requests.
Big fleet in front of small fleet
You should look at all transitive dependencies when scaling a service with a large fleet of hosts so that you don’t drive a large network traffic that needs to invoke dependent services with a smaller fleet. You can use use load testing to find the bottlenecks and update SLAs for the dependent services so that they are aware of network load from your APIs.
Blast Radius
A blast radius defines impact of failure on overall system when an error occurs. In order to limit the blast radius, the system should eliminate a single point of failure, rolling deploy changes using canaries and stop cascading failures using circuit breakers, retry and timeout.
Bulkheads
Bulkheads isolate faults from one component to another, e.g. you may use different thread pool for different workloads or use multiple regions/availability-zones to isolate failures in a specific datacenter.
Caching
Caching can be implemented at a several layers to improve performance such as database-cache, application-cache, proxy/edge cache, pre-compute cache and client-side cache.
Circuit Breakers
The circuit breaker is defined as a state machine with three states: normal, checking and tripped. It can be used to detect persistent failures in a dependent service and trip its state to disable invocation of the service temporarily with some default behavior. It can be later changed to the checking state for detecting success, which changes its state to normal after a successful invocation of the dependent service.
CQRS / Event Sourcing
Command and Query Responsibility Segregation (CQRS) separates read and update operations in the database. It’s often implemented using event-sourcing that records changes in an append-only store for maintaining consistency and audit trails.
Default Values
Default values provide a simple way to provide limited or degraded behavior in case of failure in dependent configuration or control service.
Disaster Recovery
Disaster recovery (DR) enables business continuity in the event of large-scale failure of data centers. Based on cost, availability and RTO/RPO constraints, you can deploy services to multiple regions for hot site; only replicate data from one region to another region while keeping servers as standby for warm site; or use backup/restore for cold site. It is essential to periodically test and verify these DR procedures and processes.
Distributed Saga
Maintaining data consistency in a distributed system where data is stored in multiple databases can be hard and using 2-phase-commit may incur high complexity and performance. You can use distributed Saga for implementing long-running transactions. It maintains state of the transaction and applies compensating transactions in case of a failure.
Failing Fast
You can fail fast if the workload cannot serve the request due to unavailability of resources or dependent services. In some cases, you can queue requests, however it’s best to keep those queues short so that you are not spending resources to serve stale requests.
Function as a Service
Function as a service (FaaS) offers serverless computing to simplify managing physical resources. Cloud vendors offer APIs for AWS Lambda, Google Cloud Functions and Azure Functions to build serverless applications for scalable workloads. These functions can be easily scaled to handle load spikes, however you have to be careful scaling these functions so that any services that they depend on can support the workload. Each function should be designed with a single responsibility, idempotency and shared nothing principles that can be executed concurrently. The serverless applications generally use event-based architecture for triggering functions and as the serverless functions are more granular, they incur more communication overhead. In addition, chaining functions within the code can result in tightly coupled applications, instead use a state machine or a workflow to orchestrate the communication flow. There is also an open source support for FaaS based serverless computing such as OpenFaas and OpenWhisk on top of Kubernetes or OpenShift, which prevents locking into a specific cloud provider.
Graceful Degradation
Instead of failing a request when dependent components are unhealthy, a service may use circuit-breaker pattern to return a predefined or default response.
Health Checks
Health checks runs a dummy or synthetic transaction that performs the action without affecting real data to verify the system component and its dependencies.
Idempotency
Idempotent services completes API request only exactly once so resending same request due to retries has no side effect. Idempotent APIs typically uses a client-generated identifier or token and the idempotent service returns same response if duplicate request is received.
Layered Architecture
The layered architecture separates software into different concerns such as:
- Presentation Layer
- Business Logic Layer
- Service Layer
- Domain Model Layer
- Data Access Layer
Load Balancer
Load balancer allows distributing traffic among groups of resources so that a single resource is not overloaded. These load balancers also monitors health of servers and you can setup a load balancer for each group of resources to ensure that requests are not routed to unhealthy or unavailable resources.
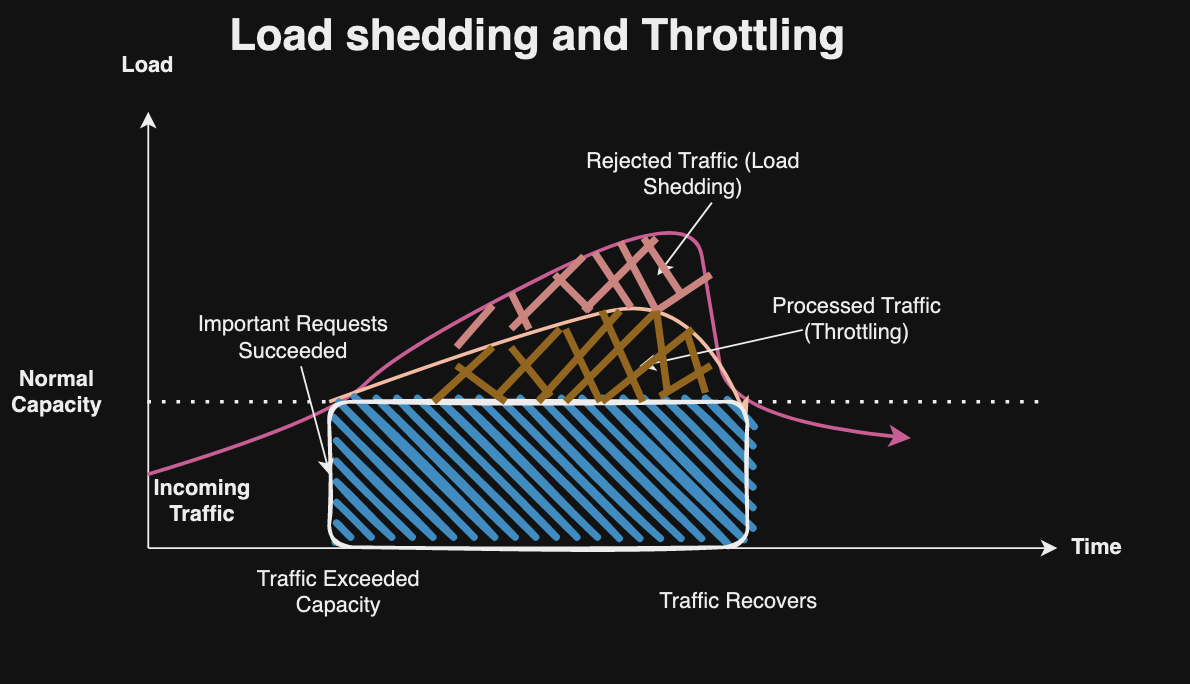
Load Shedding
Load shedding allows rejection the work at the edge when server side exceeds its capacity, e.g. a server may return HTTP 429 error to signal clients that they can retry at a slower rate.
Loosely coupled dependencies
Using queuing systems, streaming systems, and workflows isolate behavior of dependent components and increases resiliency with asynchronous communication.
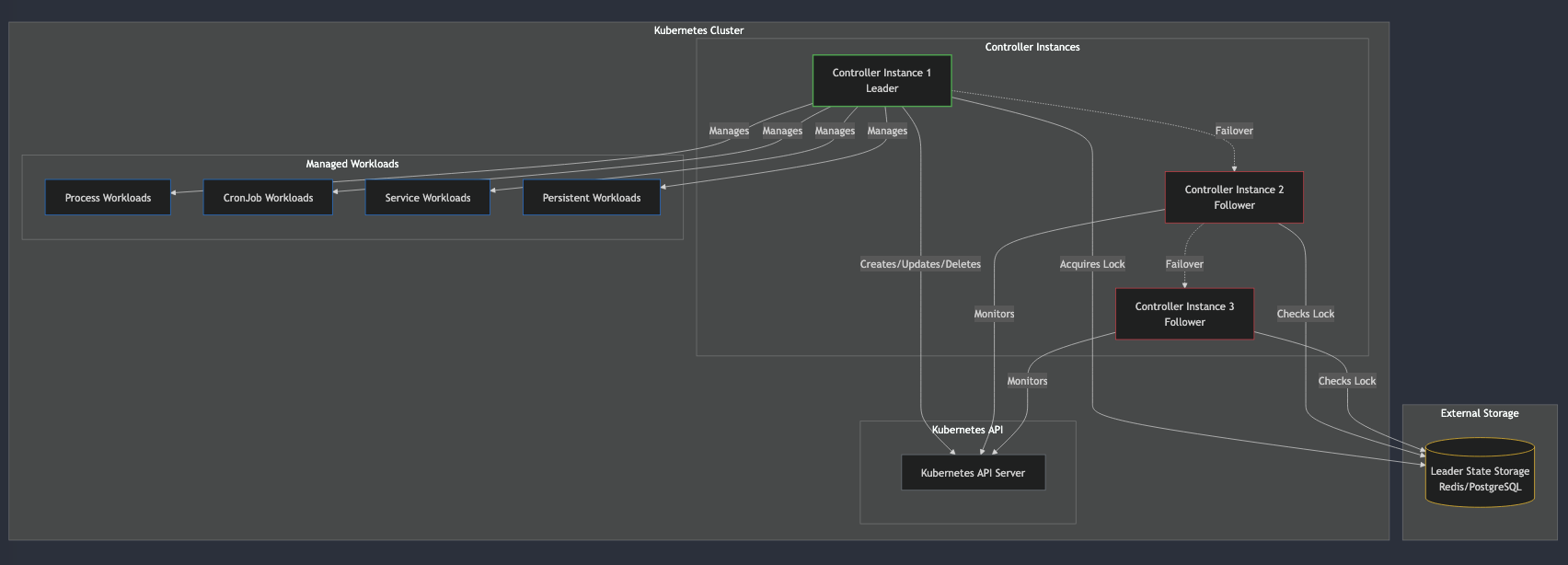
MicroServices
Microservices evolved from service oriented architecture (SOA) and support both point to point protocols such as REST/gRPC and asynchronous protocols based on messaging/event bus. You can apply bounded-context of domain-driven design (DDD) to design loosely coupled services.
Model-View Controller
It decouples user interface from the data model and application functionality so that each component can be independently tested. Other variations of this pattern include model–view–presenter (MVP) and model–view–viewmodel (MVVM).
NoSQL
NoSQL database technology provide support for high availability and variable/write-heavy workloads that can be easily scaled with additional hardware. NoSQL optimizes CAP and PACELC tradeoffs of consistency, availability, partition tolerance and latency, A number of cloud vendors provide managed NoSQL database solutions, however they can create latency issues if services accessing these databases are not colocated.
No Single Point of Failure
In order to eliminate single-points of failures for providing high availability and failover, you can deploy redundant services to multiple regions and availability zones.
Ports and Adapters
Ports and Adapters (Hexagon) separates interface (ports) from implementation (adapters). The business logic is encapsulated in the Hexagon that is invoked by the implementation (adapters) when actors operate on capabilities offered by the interface (port).
Rate Limiting and Throttling
Rate-limiting defines the rate at which clients can access the services based on the license policy. The throttling can be used to restrict access as a result of unexpected increase in demand. For example, the server can return HTTP 429 to notify clients that they can backoff or retry at a slower rate.
Retries with Backoff and Jitter
A remote operation can be retried if it fails due to transient failure or a server overload, however each retry should use a capped exponential backoff so that retries don’t cause additional load on the server. In a layered architecture, retry should be performed at a single point to minimize multifold retries. Retries can use circuit-breakers and rate-limiting to throttle requests. In some cases, requests may timeout for clients but succeed on the server side so the APIs must be designed with idempotency so that they are safe to retry. In order to avoid retries at the same time, a small random jitter can be added with retries.
Rollbacks
The software should be designed with rollbacks in mind so that all code, database schema and configurations can be easily rolled back. A production environment might be running multiple versions of same service so care must be taken to design the APIs that are both backward and forward compatibles.
Stateless and Shared nothing
Shared nothing architecture helps building stateless and loosely decoupled services that can be easily horizontally scaled for providing high availability. This architecture allows recovering from isolated failures and support auto-scaling by shrinking or expanding resources based on the traffic patterns.
Startup dependencies
Upon start of services, they may need to connect to certain configuration or bootstrap services so care must be taken to avoid thundering herd problems that can overwhelm those dependent services in the event of a wide region outage.
Timeouts
Timeouts help building resilient systems by throttling invocation of external services and preventing the thundering herd problem. Timeouts can also be used when retrying a failed operation after a transient failure or a server overload. A timeout can also add a small jitter to randomly spread the load on the server. Jitter can also be applied to timers of scheduled jobs or delayed work.
Watchdogs and Alerts
A watchdogs monitors a system component for a specific action such as latency, traffic, errors, saturation and SLOs. It then send an alert based on the monitoring configuration that triggers an email, on-call paging or an escalation.
Virtualization and Containers
Virtualization allows abstracting computing resources using virtual machines or containers so that you don’t depend on physical implementation. A virtual machine is a complete operating system on top of hypervisors whereas container is an isolated, lightweight environment for running applications. Virtualization allows building immutable infrastructure that are specially design to meet application requirements and can be easily deployed on a variety of hardware resources.
Architecture Practices
Following are best practices for sustainable software delivery:
Automation
Automation builds pipelines for continuous integration, continuous testing and continuous delivery to improve speed and agility of the software delivery. Any kind of operation procedures for deployment and monitoring can be stored in version control and then automatically applied with CI/CD procedures. In addition, automated procedures can be defined to track failures based on key performance indicators and trigger recovery or repair for the erroneous components.
Automated Testing
Automated testing allows building software with a suite of unit, integration, functional, load and security tests that verify the behavior and ensures that it can meet production demand. These automated tests will run as part of CI/CD pipelines and will stop deployment if any of the tests fail. In order to run end-to-end and load tests, the deployment scripts will create a new environment and setup a tests data. These tests may replicate synthetic transactions based on production traffic and benchmark the performance metrics.
Capacity Planning
Using load testing, monitoring production traffic patterns and demand with workload utilization help forecast the resources needed for future growth. This can be further strengthened with a capacity model that calculates unit-price of resources and growth forecast so that you can automate addition or removal of resources based on demand.
Cloud Computing
Adopting cloud computing simplifies resource provisioning and its elasticity allows organizations to grow or shrink those resources based on the demand. You can also add automation to optimize utilization of the resources and reduce costs when allocating more resources.
Continuous Delivery
Continuous delivery automates production deployment of small and frequent changes by developers. Continuous delivery relies on continuous integration that runs automated tests and automated deployment without any manual interventions. During a software development process, a developer picks a feature, works on changes and then commits changes to the source control after peer code-review. The automated build system will run a pipeline to create a container image based on the commit and then deploy it to a test or QA environment. The test environment will run automated unit, integration and regression tests using a test data in the database. The code is then promoted to the main branch and the automated build system tags and build the image on the head commit of main-branch, which that is pushed to the container registry. The pre-prod environment pulls the image, restarts the pre-prod container and runs more comprehensive tests with a larger set of test data in the database including performance tests. You may need multiple stages of pre-prod deployment such as alpha, beta and gamma environments, where each environment may require deployment to a unique datacenter. After successful testing, the production systems are updated with the new image using rolling updates, blue/green deployments or canary deployments to minimize disruption to end users. The monitoring system watches for error rates at each stage of the deployment and automatically rollbacks changes if a problem occurs.
Deploy over Multiple Zones and Regions
In order to provide high availability, compliance and reduced latency, you can deploy to multiple availability zones and regions. Global load balancers can be used to route traffic based on geographic proximity to the closest region. This also helps implementing business continuity as applications can easily failover to another region with minimal data.
Service Mesh
In order to easily build distributed systems, a number of platforms based on service-mesh pattern have emerged to abstract a common set of problems such as network communication, security, observability, etc:
Dapr – Distributed Application Runtime
The Distributed Application Runtime (Dapr) provides a variety of communication protocols, encryption, observability and secret management for building secured and resilient distributed services.
Envoy
Envoy is a service proxy for building cloud native application with builtin support for networking protocols and observability.
Istio service mesh
Istio is built on top of Kubernetes and Envoy to build service mesh with builtin support for networking, traffic management, observability and security. A service mesh also addresses features such as A/B testing, canary deployments, rate limiting, access control, encryption, and end-to-end authentication.
Linkerd
Linkerd is a service mesh for Kubernetes and consists of control-plane and data-plane with builtin support for networking, observability and security. The control-plane allows controlling services and data-plane acts as a sidecar container that handles network traffic and communicate with the control-plane for configuration.
WebAssembly
The WebAssembly is a stack-based virtual machine that can run at the edge or in cloud. A number of WebAssembly platforms have adopted Actor model to build a platform for writing distributed applications such as wasmCloud and Lunatic.
Documentation
The architecture document defines goals and constraints of the software system and provides various perspectives such as use-cases, logical, data, processes, and physical deployment. It also includes non-functional or quality attributes such as performance, growth, scalability, etc. You can document these aspects using standards such as 4+1, C4, and ERD as well as document the broader enterprise architecture using methodologies like TOGAF, Zachman, and EA.
Incident management
Incident management defines process of root-cause analysis and actions that organization can take when an incident occurs affecting production environment. It defines best practices such as clear ownership, reducing time to detect/mitigate, blameless postmortems and prevention measures. The organization can then implement preventing measures and share lessons learned from all operational events and failures across teams. You can also use pre-mortem to identify potential areas that can be improved or mitigated. Another way to simulate potential problems is using chaos engineering or setting up game days to test the workloads for various scenarios and outage.
Infrastructure as Code
Infrastructure as code uses declarative language to define development, test and production environment, which is managed by the source code management software. These provisioning and configuration logic can be used by CI/CD pipelines to automatically deploy and test environments. Following is a list of frameworks for building infrastructure from code:
Azure Resource Manager
Azure cloud offer Azure Resource Manager (ARM) templates based on JSON format to declaratively define the infrastructure that you intend to deploy.
AWS Cloud Development Kit
The Cloud Development Kit (CDK) supports high-level programming languages to construct cloud resources on Amazon Web Services so that you can easily build cloud applications.
Terraform uses HCL based configurations to describe computing resources that can be deployed to multiple cloud providers.
Monitoring
Monitoring measures key performance indicators (KPI) and service-level objectives (SLO) that are defined at the infrastructure, applications, services and end-to-end levels. These include both business and technical metrics such as number of errors, hot spots, call graphs, which are visible to the entire team for monitoring trends and reacting quickly to failures.
Multi-tenancy
If your system is consumed by a different groups or tenants of users, you will need to design your system and services so that it isolates data and computing resources for secure and reliable fashion. Each layer of the system can be designed to treat tenant context as a first-class construct, which is tied to the user identity. You can capture usage metrics per tenant to identify bottlenecks, estimate cost and analyze the resource utilization for capacity planning and growth projections. The operational dashboards can also use these metrics to construct tenant-based operational views and proactively respond to unexpected load.
Security Review
In order to minimize the security risk, the development teams can adopt shift-left on security and DevSecOps practices to closely collaborate with the InfoSec team and integrate security review into every phase of the software development lifecycle.
Version Control Systems
Version control systems such as Git or Mercurial help track code changes, configurations and scripts over time. You can adopt workflows such as gitflow or trunk-based development for check-in process. Other common practices include smaller commits, testing code and running static analysis or linters/profiling tools before checkin.
Summary
The software complexity is a major reason for missed deadlines and slow/buggy software. This complexity can be essential complexity within the business domain but it’s often result of accidental complexity as a result of technical debt, poor architecture and development practices. Another source of incidental complexity comes from distributed computing where you need handle security, rate-limiting, observability, etc. that needs to be applied consistently across the distributed systems. For example, virtualization helps building immutable infrastructures and adopting infrastructure as a code; functions as a service simplifies building micro-services; and distributed platforms such as Istio, Linkerd remove a lot of cruft such as security, observability, traffic management and communication protocols when building distributed systems. The goal of a good architecture is to simplify building, testing, deploying and operating a software. You need to continually improve the systems architecture and its practices to build sustainable software delivery pipelines that can meet both current and future demands of users.