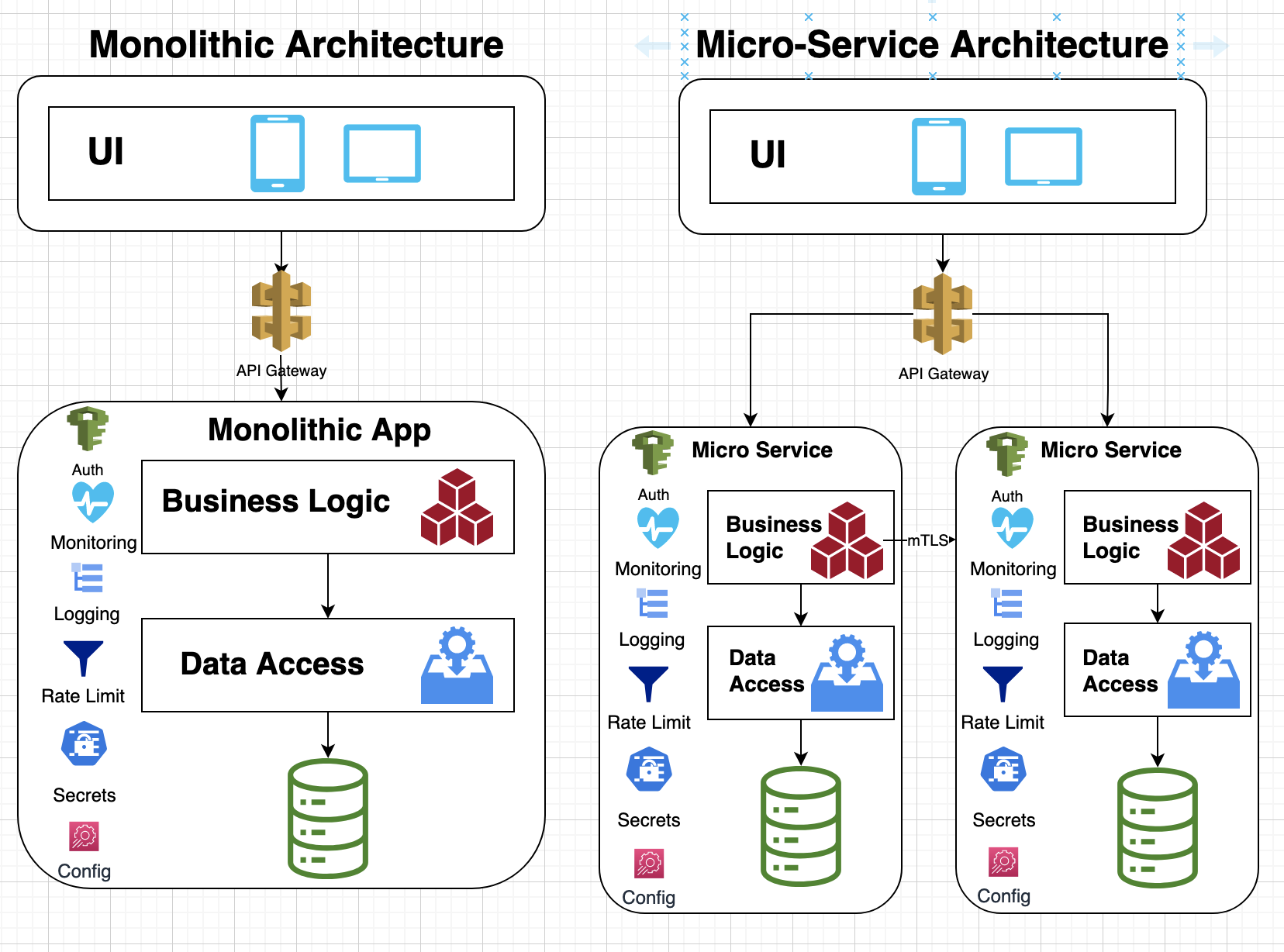
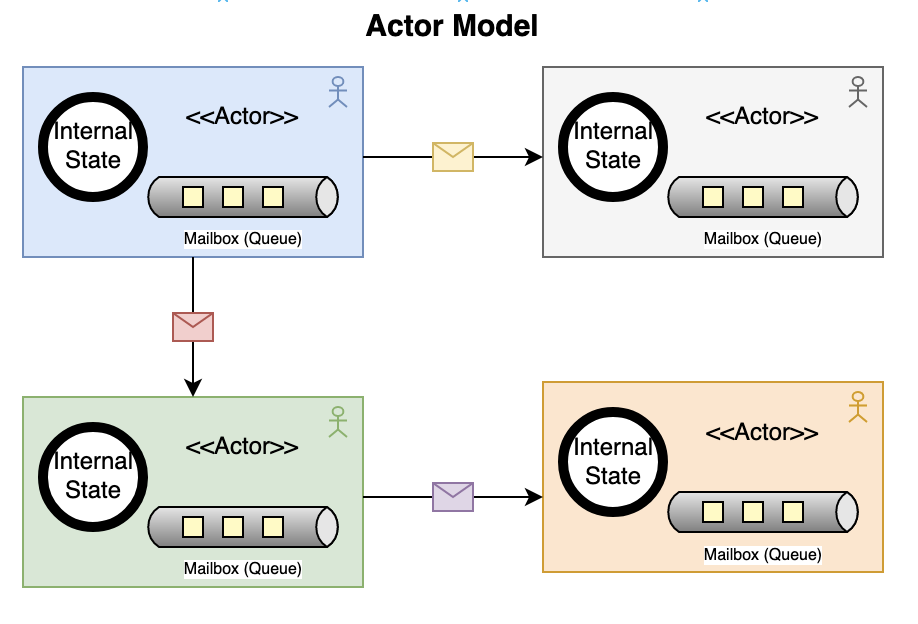
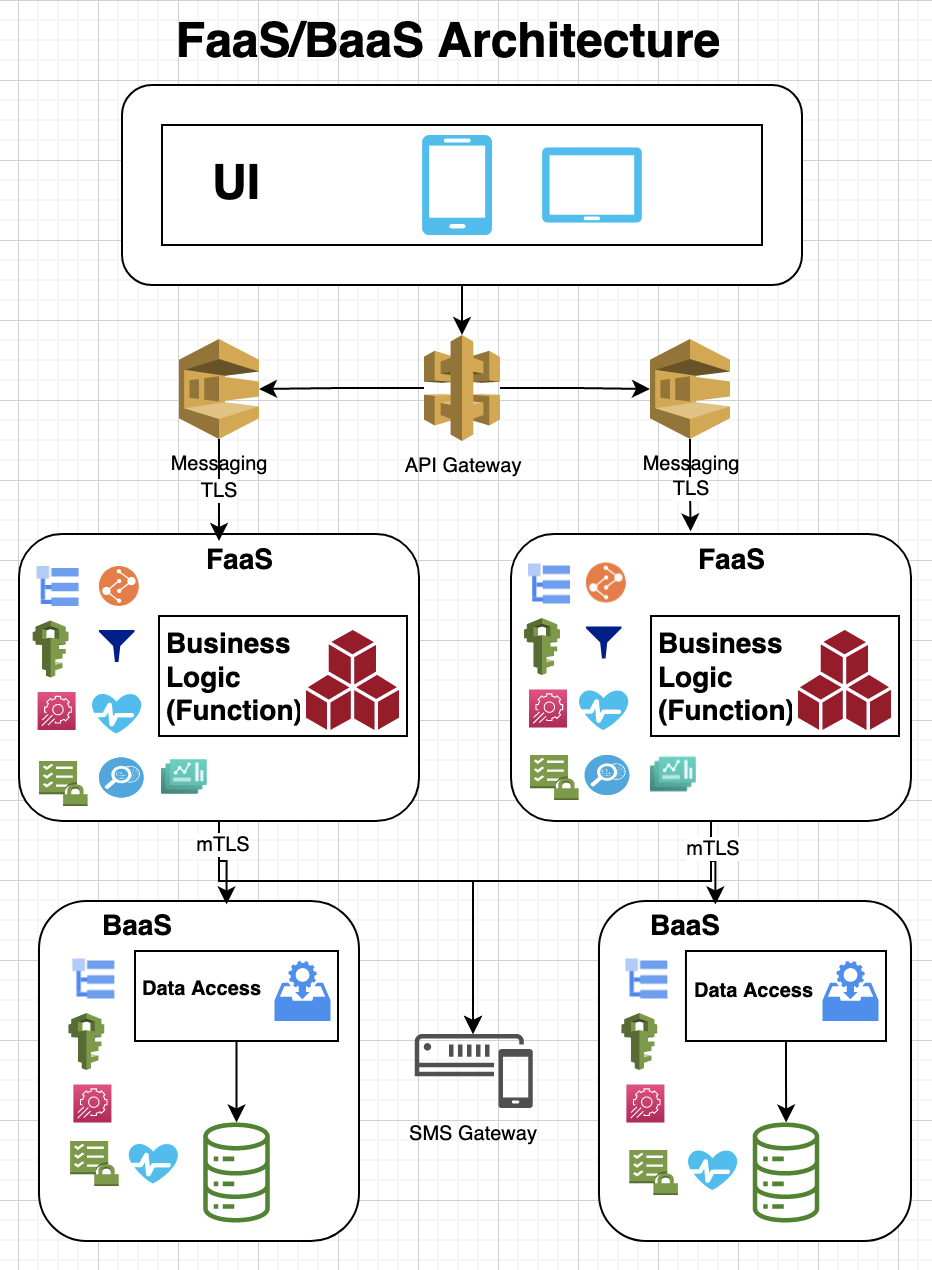
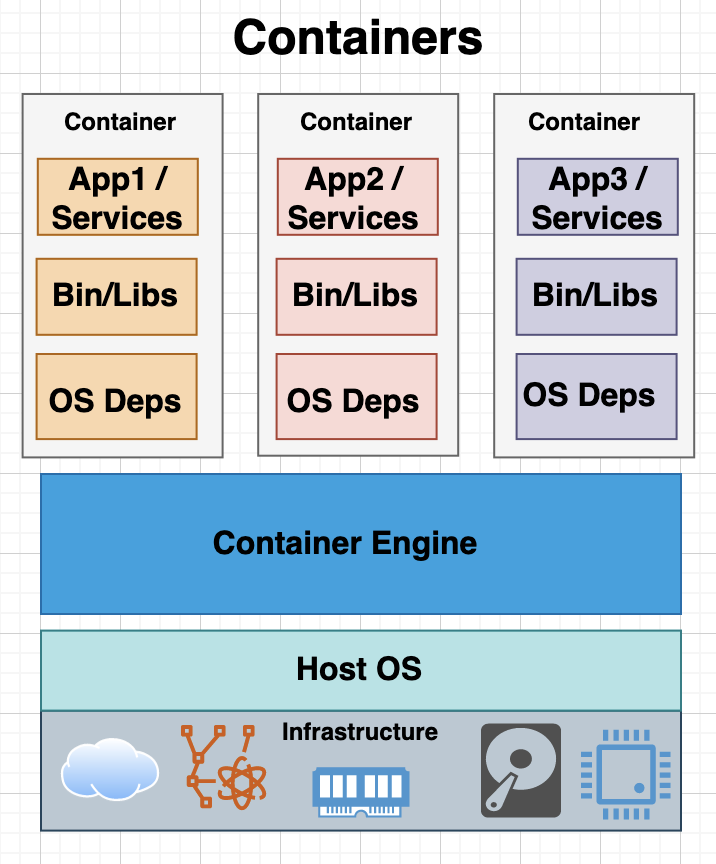
I recently read Leading Effective Engineering Teams by Addy Osmani, which shares the author’s experiences at Google and presents best practices for achieving engineering excellence. Here are the key takeaways from the book, organized by chapter:
1. What Makes a Software Engineering Team Effective?
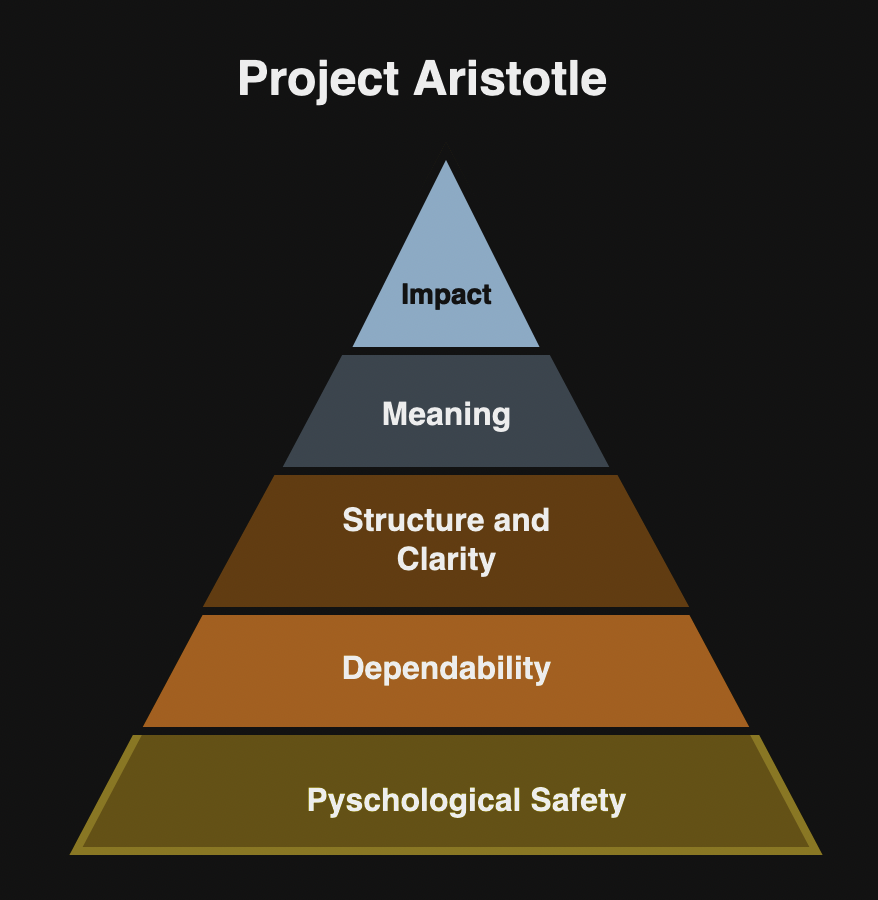
In this chapter, author introduces Project Aristotle that studied nearly 200 Google teams over two years to identify the factors for building effective teams. The researchers studied following factors that might impact team effectiveness such as team dynamics, personal traits, and skill sets. Project Aristotle identified five key dynamics that contribute to the effective teams:
- Psychological safety so that team members can express opinions and ideas freely.
- Dependability so that individuals trust each other to be dependable.
- Structure and clarity about the goals, roles and responsibilities.
- Meaning or purpose of their work.
- Impact on how their work makes an impact to the organization or society.
The author shares numerous other insights from Project Aristotle and various studies, including:
- Smaller teams are more effective, as evidenced by Amazon’s two-pizza team rule.
- Diversity can be beneficial.
- Clear communication based on psychological safety is vital.
- Leadership matters as highlighted by Google’s Project Oxygen.
- Agility fosters adaptability, as demonstrated by a McKinsey & Company study.
- Collaboration drives innovation, as evidenced by studies from Harvard, Stanford, and others.
The author recommends using motivation and intrinsic rewards to enhance performance, citing Daniel H. Pink’s book Drive, which identifies three key elements that motivate people:
- Autonomy
- Mastery
- Purpose
The author outlines the following steps for building an effective team:
- Assemble the right people, focusing on hiring for effectiveness and determining the optimal team size for the project/product. To foster a shared engineering mindset for an effective team, the author recommends looking for the following qualities:
- Cares about the user and comprehends the problem domain, business context, priorities, and relevant technology.
- Is a good problem solver.
- Can keep things simple but cares about quality.
- Can build trust over time, leading to increased autonomy and enhanced social capital.
- Understand team strategy.
- Can prioritize appropriately and execute independently.
- Can think long term.
- Can leave software projects in better shape.
- Is comfortable taking on new challenges.
- Can communicate effectively.
- Promotes diversity and inclusion, fostering an environment where all opinions are valued equally based on psychological safety.
- Enable a sense of team spirit with following foundation:
- Define clarity on roles, and responsibilities.
- Establish a shared purpose and communicate the overall project purpose and goals.
- Foster trust among team members by encouraging open communication and feedback.
- Lead effectively as highlighted by the Project Oxygen and leader should inspire, influence and guide team toward a shared goal. Leaders should prioritize strategic visibility by effectively communicating the team’s accomplishments and their impact on the business.
- Sustain effectiveness (Growth culture) by supporting the factors of agility, purpose, and impact. Leaders should enhance learning and development opportunities for team members. Author recommends agile strategies, including adopting agile practices, promoting cross-functional collaboration, prioritize communication, building a culture of adaptability and implementing continuous integration and delivery. Additionally, the author emphasizes continuous improvement by fostering continuous learning and monitoring key performance indicators to evaluate team performance.
2. Efficiency Versus Effectiveness Versus Productivity
The author defines following key terms:
- Efficiency is about doing things right to minimize waste and maximize output. It enhances productivity by measuring factors such as time to complete a task, resource utilization, bug fix rate, defect density, and quality.
- Effectiveness is about doing the right thing and delivering the right outcome. Team effectiveness can be measured by customer satisfaction, business value, user adoption rate, ROI, and time to market.
- Productivity is a measure of output over input. The team productivity can be measured by lines of code, function points, story points, and DevOps metrics.
The author repeats factors from the first chapter that are imperative for achieving higher efficiency and effectiveness such as team size, diversity, role clarity, communication, work environment, tools and technology and code health. Further, author differentiates between output and outcome:
- An output is a deliverable resulting from engineering tasks. It can be measured by metrics such as throughput, velocity, quality, capacity, and code health.
- An outcome is the actual result of the work done. It can be measured by metrics including business value, investment, user adoption rate. However, measuring outcome is challenging because accurate measurement is difficult. Other factors such as focusing too much on output, unreasonable deadline and burnout can diminish the outcome.
The author defines effective efficiency as “do the right things right” and suggests following practices:
- Asking questions
- Following standards
- Collaborating
- Using the right tools
- Managing tradeoffs based on project timelines, budgets, long-term maintainability and user needs.
The author suggests following metrics for tracking productivity, which is a subset of efficiency:
- Time to receive valuable user feedback and insights.
- Collaborate through asynchronous communication.
- Focus blocks
- Novel problem solving
- Code and bug fixing
- Security and vulnerability
- Upskilling
- Automated testing
- Context switching
- Subjective well being
- Meeting culture
At the individual level, the author recommends SMART goals and at the team level, the author recommends two techniques for defining productivity metrics:
- Goal-question-metric (GQM) for driving goal-oriented measurement such as code quality, process efficiency, and team performance.
- Objectives and key results (OKRs) for setting specific and measurable objectives and then identifying a set of key results that monitor how to get the objectives.
3. The 3E’s Model of Effective Engineering
In this chapter, the author introduces following stages to install effectiveness:
- Enable effectiveness by defining what it means to your team or organization. General steps to define effectiveness include:
- Identify team’s goals and objectives.
- Determine what metrics are relevant to measuring success.
- Set targets for each metric.
- Define effectiveness in terms of outcomes.
- Involve key stakeholders.
- Keep the definitions simple and review them regularly.
- Empower teams to shape standards.
- Practice servant leadership.
- Empower teams to adopt effectiveness. The author shares following methods for empowering teams:
- Feed opportunities, starve problems with continuous delivery and feedback loops, kanban boards, and delegation.
- Expand to scale effectiveness for larger teams. The shares following methods for expanding effectiveness:
- Empowerment through trust by delegating responsibilities.
- Effective delegation.
- Streamlining communication.
- Fostering a culture of autonomy.
- Setting priorities and boundaries.
- Mentoring and developing leaders.
- Reflective practices.
In order to empower team effectiveness, the author suggests several strategies to improve individual effectiveness including:
- Using delegation as a tool, not a retreat.
- Building a culture of trust and transparency.
- Using process optimization beyond command-and-control.
The author cites following habits from the Peter Drucker’s Effective Executive:
- Know where your time goes.
- Focus on what you uniquely can contribute to your organization.
- Build on your own strengths, the strengths of your colleagues, and the team.
- Concentrate on a few major areas where superior performance will produce outstanding results.
- Make effective decisions.
Author then describes team effectiveness models such as:
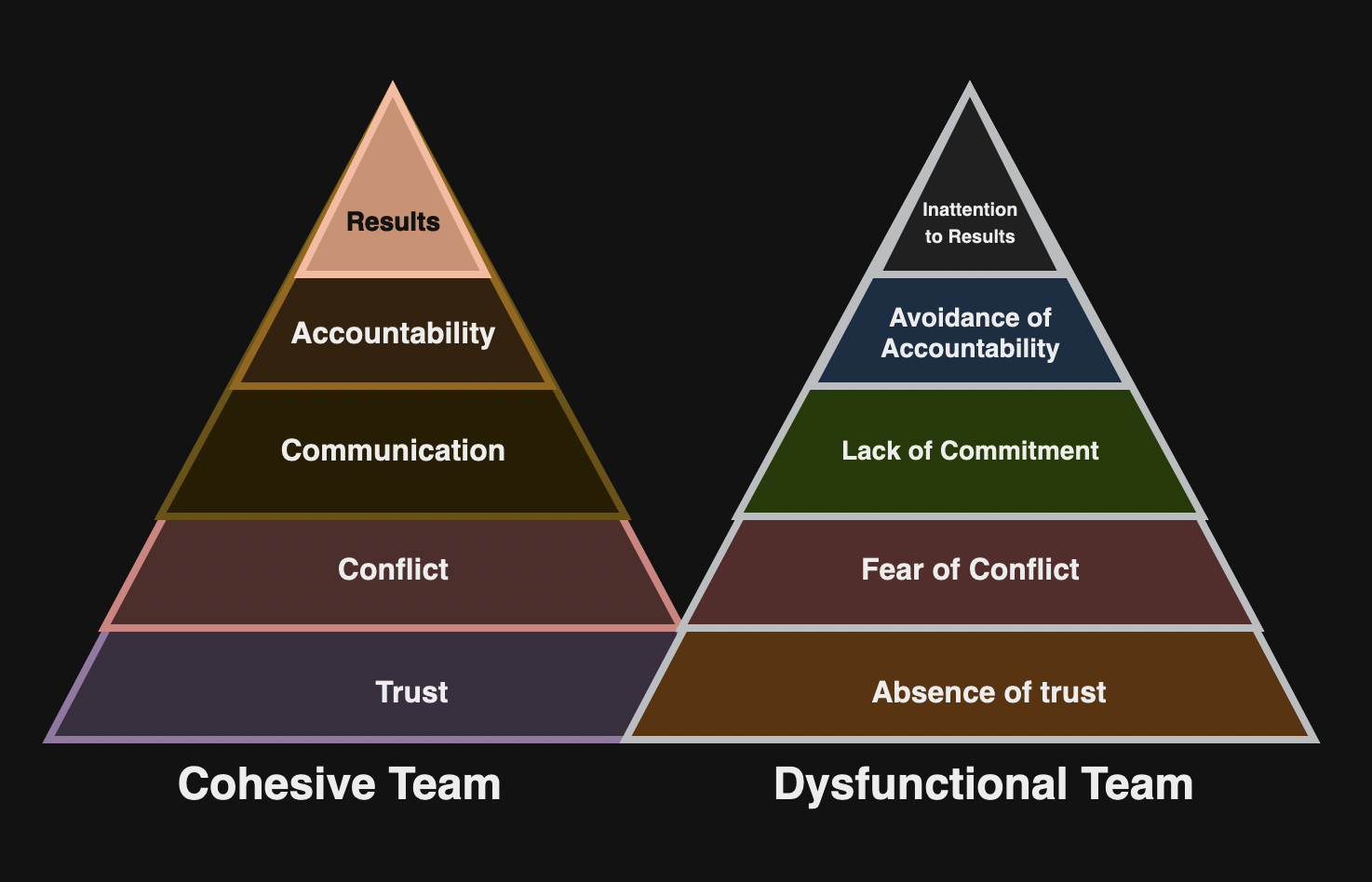
Lencioni’s model
Patrick Lencioni’s model focus on the five dysfunctions that can hinder team effectiveness:
- Absence of trust.
- Fear of conflict
- Lack of commitment
- Avoidance of accountability
- Inattention to results when team members put the needs of individuals above those of the group.
Tuckman’s model
The author cites the Bruce Tuckman’s model to describe the stages teams go through as they mature:
- Forming when the team is coming together.
- Storming when they get to know each other.
- Norming when they find a relative groove.
- Performing where the magic happens.
- Adjourning when the team disbands after completing the objectives.
The author also cites other strategies from a data team from Gitlab, Andy Grove’s book and his experience from Google including:
- Using the right tools and processes
- Reducing meetings and protecting the team
- Securing executive buy-in and resources
- Hiring and employee development
- Planning for growth
- Focusing on core business value
- Being mindful of career path and priorities
- Identifying high-leverage activities as defined by Grove in his book that can enable individuals and organizations to do more with less.
- Standardize and share
- Reuse
- Automate right things
The Three Always of Leadership
In order to expand effectiveness, the author describes several challenges such as people, broader domain, distractions and complications. The author cities Ben Collins-Sussman’s techniques called the three always of leadership:
- Always be deciding to make timely and well-informed decisions. A three-step approach by Ben Collins-Sussman include:
- Identify the blinders or mental blocks.
- Identify the key trade-offs.
- Decide, then iterate.
- Always be leaving by reducing the “bus factor” and ensuring that you don’t become the single point of faiure (SPOF). A leader can divide the problem space and delegate the subproblems to future leaders.
- Always be scaling is about protecting precious resources such as time, attention, and energy. The author suggests being proactive instead of reactive from escalations, embracing the cycle of struggle and success, managing energy by self-care and recharge regularly.
The author cites Jeff Bezos lessons about making high-quality and high-velocity decisions. Though, the author does not mention Jeff Bezos’ advice on one-way vs two-way decisions but I have found it to be very valuable when making decisions.
4. Effective Management: Research from Google
In this chapter, the author describes findings from Project Oxygen and Project Aristotle.
Project Oxygen
Project Oxygen studied the behavior of high-performing managers and identified following key behaviors:
- is a good coach who offers thoughtful feedback and guidance. Other attributes include regular one-on-ones, tailed coaching, asking good questions to help people think, demonstrate empathy, motivate by setting high standards and lead by example.
- Empower team without micromanaging. A good manager offers stretch assignments, intervenes judiciously, allows autonomy, encourages innovation, advocates for the team and provides constructive feedback.
- Creates an inclusive team environment, showing concern for success and well-being. A good manager makes new team member feel welcomed, builds rapport within the team, is an enthusiastic cheerleader to support the team, upholds civility, cres about the well-beings of team members, shows support and creates psychological safety on the team.
- Is productive and results oriented and drives team achieving goals by assembling a diverse team, translating the vision/strategy into measurable goals, structuring the team, defining clear expectations and ownership, removing any roadblocks, and planning for potential risks.
- Is a good communicator who encourages open discussion, aims to be responsive, shares information from leaders honestly, behaves calmly, and listens to other team members.
- Supports career development and discusses performance. A good manager communicates performance expectations, gives employees fair performance evaluations, explains how compensation is tied to performance, advices employees on career prospects, and helps team members to grow. For example, Google uses GROW (Goal, Reality, Option, Will) model to structure career development conversations.
- Has a clear vision/strategy for the team. A good manager creates a vision/strategy to inspire team members, aligns the team’s visions/strategy with the company’s, involves the team in creating the vision where it makes sense, clearly communicates the vision, helps the team understand how the overall strategy translates to its work. Google recommends defining core-values, purpose, mission, strategy and goals for the teams.
- Has key technical skills to help advice the team. A good manager helps the team navigate technical complexity, understands the challenges of the work, uses technical skills to help solve problems, learns new skills to meet business needs, bridges the gap between technical and non-technical stakeholders.
- Collaborates across company by doing: Prioritize collective goals and outcomes, seek opportunities to partner with other teams, role-model collaboration across teams, hold team accountable for following company practices/policies, and take art in the company’s culture and community.
Project Oxygen helped increased employee performance, satisfaction, better decision making and collaboration, and reduced employee turnover.
Project Aristotle
As mentioned in chapter 1, the Project Aristotle found the five critical dynamics in building successful teams:
- Psychological Safety for feeling safe to speak up, which was first proposed by Amy Edmondson, which is distinct from “group cohesiveness” that is about getting along with each other as a group. In order to promote psychological safety in the teams, a manager should approach conflict as a collaborator, not an adversary, speak human to human, anticipate reactions and plan countermoves, replace blam with curiosity, ask for feedback on delivery, and measure psychological safety.
- Dependability for fostering trust. Dependable team members demonstrate genuine intentions, accountability by taking ownership of their tasks and responsibility for their actions, sound thinking, and consistent contribution. As a leader, you can lead by example, promote collaboration and interdependence, clearly define roles and expectations, encourage open communication, and provide supportive feedback.
- Structure and clarity so that team members understand what is expected of them. At Google, teams are encouraged to align their OKRs with the company’s overarching goals. The teams identify key results that would have the greatest impact on advancing the organizational OKRs. The author also suggests RACI matrix to bring structure an clarity to assigning responsibilities to various roles. It stands for Responsible (who do the work), Accountable (who owns the work to be done), Consulted (who reviews the work), and Informed (stakeholders). In past, I have used the single-threaded-leader (STL) or Directly-Responsible-Individual (DRI) roles for defining similar structure for ownership of the overall project.
- Meaning refers to a sense of purpose, fulfillment, and progress at work.
- Impact of the work that can highlighted by connection to organization objectives, working toward a team vision, understanding the impact on clents and users, and linking performance to outcomes.
Project Aristotle taught empathy and showed team wants to feel that their work matters.
5. Common Effectiveness Antipatterns
In this chapter, the author reviews antipatterns to effectiveness categorized by individual, practice-related, structural and leadership.
Individual Antipatterns
Following are the most common individual antipatterns:
- The specialist when a person is strongly identified with a particular module or feature. It is a high-risk antipattern that leads to higher bus-factor and limits professional growth. A leader should encourage team members to develop expertise in different areas, document exceptional cases and set learning goals.
- The generalist arises when team members spreads themselves too thin and dilute expertise. A leader must task the generalist with a specific area of the project, focus on honing their expertise in areas that aligns with their strengths, foster a collaborative environment and promote continuous learning and pursuit of master within specialized domain.
- The hoarder antipattern occurs when a team member does not trust their team and does not share the work consistently. It disrupts team’s collaborative rhythm, hampers feedback loop and hoarder becomes a bottleneck during the code review stages. A leader should encourage frequent commits that show ongoing progress, promote daily stand-up meetings, advocate for early and frequent code reviews.
- The relentless guide when an engineer offers assistance beyond its intended scope and other team members may ask engineer’s guidance, even for minor tasks. A leader should encourage team members to attempt problem-solving independently, foster peer learning by pairing individuals, organize regular knowledge-sharing sessions, and assign the guide to challenging tasks.
- The trivial tweaker when an individual consistently indulges in minor code changes and refactoring. A leader should assign challenging task to the trivial tweaker, encourage the engineer to evaluate the potential impact of code changes, and align code changes with the project’s objectives.
Practice-Related Antipatterns
Practice-related antipatterns include:
- Last-minute heroics when issues and challenges are often addressed hastily and heroically just before a release. It can lead to lack of feedback, hidden technical debt, decreased quality, and dependency on heroes. A leader should encourage effective planning, transparent communication, prioritized backlog, and sustainable pace.
- PR Process Irregularities such as rubber-stamping, self-merging, long-running PRs, and last-minute PRs can introduce inefficiencies, decrease code quality and hinder collaboration. A leader should promote thorough review and accountability, diverse approvals, timely feedback and closure, and intermediate checkpoints.
- Protracted Refactoring when the refactor stretches beyond its expected timeline due to escalating scope and causes progress delays, resource drain and diluted focus. A leader should identify the cause, set time constraints, implement peer review and closure, and foster open communication.
- Retrospective Negligence when teams skip retrospectives due to time constraints, shorten sessions, lacks structure, avoid discussing conflicting viewpoints, lack follow-ups, and surface-level analysis. A leader should prioritize retrospectives regularly, allocate adequate time, embrace structure (start, stop, continue or mad, sad, glad), encourage diverse participation, implement action items, and focus on root causes.
Structural Antipatterns
Structural antipatterns include:
- Isolated clusters where subteams or groups form within a larger team, leading to insular pockets of collaboration. It can lead to knowledge fragmentation, missed insights, stagnant growth, and reduced cohesion. A leader must encourage interdisciplinary sessions, rotating roles, cross-domain initiatives, and open communication channels.
- Knowledge Bottlenecks where vital knowledge and expertise is concentrated to a limited individuals leading to higher bus factor, single point of failure, dependency, knowledge silos, and communication gaps. A leader should promote cross-training, knowledge sharing, pair programming, rotation of responsibilities, and mentorship.
Leadership Antipatterns
There are cases when the leader’s actions become antipatterns such as:
- Micromanagement where managers exert unnecessary control that leads to perfectionist bottleneck, prescriptive direction, guardians of information, stiffled innovation, low morale, slow progress, limited growth, and uninformed decisions. In order to remedy these issues, leaders should increase ownership, enhance creativity, improve morale, foster innovation and act as a glass barriers to shield their teams.
- Scope Mismanagement where leaders struggle to manage the scope of a project due to incessant change requests, lack of prioritization, inflated workload, delayed deliverables, and reduced quality. A leader should change evaluation process, promote effective communication, introduce scope freeze periods, regular reviews, empower decision making, and escalation.
- Planning Overkill where excessive time and effort are invested in planning due to overanalysis, endless design iterations, extensive documentation, delayed development, and inflexibility. A leader should instead promote realistic scope, iterative refinement, flexibility in execution, progressive elaboration, and risk management.
- Skeptical Leadership where leaders develop unwarranted insecurities about the team’s competence. A skeptical leader can build insecurities with unfounded fears, insecure technology decisions, passing the pain, constant reassurances, diminished confidence, and slowed progress. A leader must restore productive collaboration with evidence-based decisions, effective communication, transparency, time management, and confidence building.
- Passive Leadership is characterized by maintaining the status quo, avoiding disruptions, stagnation, lack of direction, missed opportunities, limited accountability, and resistance to change. Leaders should instead set clear expectations and promote open communication, empowerment, innovative culture, and accountability
- Underappreciation when leaders fail to acknowledge and celebrate commendable actions. Leaders should implement a practice of regular recognition, timely feedback, and appreciate publicly.
6. Effective Managers
This chapter focuses on the operational role of a manager and provides tips for time management, people management and project management.
From Engineering to Management
Transitioning from an engineering to a management position can be challenging and new managers may fail to empower team members, micromanage or find difficulty with prioritizing people management over technical expertise.
Getting Started
Following tasks are recommended for a new manager:
- Meeting with team members
- Project assessment
- Understand the tech stack
- Address immediate concerns
- Identify quick wins
- Start networking
- Start prioritizing
- Setup essential communication channels
- Reflect and engage in self-care
- Manage imposter syndrome
Defining a Strategy
A new manager can focus on:
- Long-term strategic vision based on OKRs or other frameworks.
- Transparent tracking of objectives.
- Data-driven decision making.
- Calculated risk management. You may use SWOT (Strengths, Weaknesses, Opportunities, and Threats) to assess a decision.
Managing Your Time
The author recommends following techniques:
- Planning by time blocking, chunking similar tasks (Pomodoro), planning communication by using labels and filters to prioritize and categorize messages.
- Execution by mentoring your team members to handle specific tasks, delegation, learn to say “no”.
- Assessment by calendar audits, reflect and adjust.
Understanding and Setting Expectations
Leaders can elaborate key components of the expectations from the team members.
- What results are expected from me? Critical factors include regular and open communication, setting goals (OKR or SMART), prioritization, and self-assessment by evaluating performance against the expectations.
- What results do I expect from team members? The author suggests clear communication, individual meetings, goal alignment, and documenting expectations.
Communication Essentials
To ensure consistent communication, the author suggests a clear management strategy with various methods of communication.
- Team meetings where frequency depends on the overall duration planned for the project. Each meeting should have clear objectives, is focused and time-bound and promote active participation and inclusivity.
- One-on-Ones should focus on the team members and their needs. You should provide specific, useful and actionable feedback (both positive and negative).
- Messaging may use various channels such as email, instant messaging, and task management software.
- Nonverbal Communication based on body language, facial expressions, and physical proximity.
People Management
People management poses several challenges such as tech talent competition, skill diversification, remote work dynamics and expectations. The author suggests following areas for people management:
- Hiring by clearly defining job roles and essential skills.
- Performance evaluation that includes career goals, professional development, additional responsibilities, challenges and achievements, feedback and improvement, and work-life balance.
- Attrition Management by understanding the reasons, using feedback from exit interviews, and smooth transition of knowledge and responsibilities.
- Mentorship and Coaching that can avoid attrition by better cultural fit and alignment, cost and time savings, and employee development and morale.
Managing Challenging Projects
The author suggests following key considerations for navigating through challenging projects:
- Agile approach
- Scope management
- Prototype
- Decisive but flexible
- Quality control
- Work-life balance
- Communication
- Removing blockers
- Celebrating successes
Managing Team Dynamics
These challenges include:
- Individual idiosyncrasies and diverse teams
- Remote teams
- Conflict Resolution
Enabling Mastery and Growth
A manager can facilitate growth by following:
- Harnessing downtime for growth
- Empowering growth amid high-workload periods
Networking Essentials
The author suggests following techniques for building relationships:
- Knowledge-exchange
- Problem-solving
- Professional growth
- Collaboration opportunities
Other things to network effectively include:
- Be genuine
- Listen actively
- Follow up
- Maintain regular contact
- Diversify your network
7. Becoming an Effective Leader
Leadership involves mentorship, coaching and setting a visionary course. The author cites John Kotter who distinguishes leadership from management where leadership produces change and movement, while management produces order and consistency. The author defines following focus areas for effective leaders and managers.
- Effective leaders focuses on establishing direction, align people, motivate and inspire.
- Effective managers plan and budget, bring organization structural, and control and problem-solving.
The author suggests following approaches to combine managerial responsibilities with leadership qualities are as follows:
- Strategic vision by ensuring decisions are directed towards the correct long-term goals.
- Motivational leadership by understanding what motivates each team member.
- Empowerment and trust.
- Adaptability and change management.
Leadership Roles
The author defines following different types of leadership roles:
- Technical Lead who provides technical guidance and direction to the engineering team. The key responsibilities include guide technical design and architecture, set coding standards and best practices, lead troubleshooting of complex bugs and issues, make key technical decisions with engineering trade-offs, do hands-on coding alongside the team, serve as a mentor for development skills, and ensure deliverables meet the quality bar.
- Engineering Manager oversees a team of engineers, ensuring delivery of projects. The key responsibilities include people management, manage processes, align team with organizational priorities, unblock resources, technical oversight, stakeholder interaction, and strategic work prioritization.
- Tech Lead Manager (TLM) oversee a group of engineers at Google. The key responsibilities include blending people management with hands-on technical leadership, coach and develop engineers on coding skills, establish technical standards and architecture, help unblock developers when they are stuck, focus on higher-priority technical work, advocate for the team while coordinating cross-functionality, make technical decisions weighing various constraints, and provide mentorship and guidance.
Assessing Your Leadership Skills
The author defines a list of critical and desirable traits that distinguish exceptional leaders.
Critical Traits
- Technical expertise is a critical skill for both engineer and team leaders.
- Agility refers to ability to learn, unlearn and adapt to changing conditions.
- Clear Communication is essential to share vision. You can practice active listening and seek feedback from the team.
- Empathy by putting yourself in your team members’ shoes to understand their perspectives.
- Develop a clear and compelling vision
- Delegation
- Integrity
Desirable Leadership Traits
- Self-Motivation
- Drive to maintain focus on the end goals and avoid distractions
- Integrity by being honest, truthful, and ethical
- Fairness to ensure that all individuals in the group are treated fairly and impartially.
- Humility
- Courage (virtue between cowardice and rashness)
- Accountability by taking ownership of the decisions and outcomes
- Influence to motivate and inspire team members
- Caring for others
- Self-awareness
Leading Effectively
The author describes practices and principles for effective leadership:
Leadership Style
- Transformative leadership to inspire and motivate team to achieve extraordinary results.
- Democratic leadership emphasizes involving team members in the decision-making process.
- Servant Leadership prioritizes the needs and well-beings of team members based on empathy, humility, and stewardship.
Combining different styles
Also known as situational leadership based on the specific situation.
Environment-based leadership
Leadership based on size, scope, and complexity of the organization, product, or project.
Strategizing
Strategizing provides a clear roadmap that aligns team’s efforts with organizational goals.
Visualizing the future
It allows you to anticipate challenges and make informed decisions. The author recommends pointers to 360-degree visualization such as environmental scanning, scenario scanning, risk assessment and diverse perspectives.
Defining a strategic roadmap
It involves outlining a clear and cohesive plan including initiatives to be launched and milestones. The author recommends:
- Do maintain clarity and simplicity.
- Do set measurable milestones.
- Do build flexibility and adaptability into the roadmap.
- Don’t treat the roadmap as static document.
- Don’t lack stakeholder involvement.
Immersive strategic thinking
Immersive strategic thinking is a dynamic and deliberate cognitive process that involves dedicated and uninterrupted periods for deep reflection and data analysis. You can use strategic retreats, digital detox or quiet spaces to facilitate this process.
Ruthless prioritization
It encourages to say “no” so that you maintain a clear and unwavering focus on what truly matters.
Playing the Part
Here are a few things to continuously apply:
Relentless communication
The author recommends regular communicating following aspects:
- Long-term goals
- Focus areas
- Context for tasks
- Milestones and achievements
- Challenges and roadblocks
- Changes in strategy or direction
- Opportunities for learning and development
- Organizational updates
Structuring for innovation
This involves the following:
- Flatten unnecessary hierarchy
- Informed decisions
- Emphasized speed
- Adopt minimal viable processes
- Create innovation time
- Facilitate ideation sessions
Psychological safety
It involves proactive measures to allow unconventional ideas and celebrate failures as learning opportunities.
Leading diverse teams
A few strategies for this include the following:
- Address unconscious bias
- Promote diverse hiring practices
- Cultivate an inclusive work culture
Identifying potential and developing capability
- Recognize that talent development is not a one-size-fits-all approach.
- Understand that there is value in small gains.
- Cultivate a diverse and vibrant collective of individuals.
- Provide effective feedback, which is specific and actionable. Balance positive and constructive feedback. Tailor feedback to the individual. Follow up and support.
Balancing technical expertise with leadership skills
- Develop technical expertise by setting aside dedicated time.
- Enhance leadership skills with workshops/courses, mentorship and regular reflection. Develop strategic thinking, decision making and problem solving. Cultivate strong communication, collaboration and interpersonal skills.
Mastering the Attitude
The author recommends embracing the values and demonstrating commitment to the success of the projects. The key components include:
Trust and autonomy
You can grant autonomy via ownership, flexible work structures and decision making authority. You can establish following guardrails:
- Clear communication channels and protocols
- Well-defined roles and responsibilities
- Regular check-ins and progress reviews
- Established coding standards and best practices
- Documented decision-making processes
Modeling behaviors
It involves leading by example and embodying the desired mindsets and values.
- Demonstrate a growth mindset
- Demonstrate inclusiveness
- Demonstrate integrity
Making decisions with conviction
Avoid planning overkill antipattern and make difficult choices with conviction.
Data-driven leadership
Data-driven leadership consists of leading team based on real-time and accurate data and analytics. Some examples of metrics and KPIs include:
- Velocity
- Cycle time
- Defect density (number of defects per unit of code or release).
- Code coverage
- Customer satisfaction
You must establish clear metrics and KPIs, foster data-driven culture and communicate data effectively.
Adapting to change
The author recommends 4A’s framework to lead in complex and uncertain environments:
- Anticipation
- Articulation
- Adaption
- Accountability
Evolving effectiveness into efficiency
Leaders can view leadership practices with following angles:
- Team efficiency.
- Process streamlining.
- Strategic efforts to enhance effectiveness and balancing operational efficiency with the capacity for creative problem-solving.