Over the past years I have written extensively about what makes distributed APIs fail. In How Abstraction Is Killing Software I showed how each layer crossing a network boundary multiplies latency and failure probability. In Transaction Boundaries: The Foundation of Reliable Systems and How Duplicate Detection Became the Dangerous Impostor of True Idempotency, I showed how subtle contract violations produce data corruption. Building Robust Error Handling with gRPC and REST, Zero-Downtime Services with Lifecycle Management, and Robust Retry Strategies for Building Resilient Distributed Systems explained error handling and operational health. My production checklist and fault tolerance deep-dive outlined those lessons actionable before a deployment. I also built an open-source API mock and contract testing framework, available at github.com/bhatti/api-mock-service that addresses how few teams verify their API contracts before clients discover the gaps in production. And in Agentic AI for Automated PII Detection I showed how AI-driven scanning can find the sensitive data leaking through APIs that manual review misses. Here, I am showing 50 anti-patterns across seven categories, each with a real-world example. Two laws sit at the foundation of everything that follows.
Hyrum’s Law: With a sufficient number of users of an API, it does not matter what you promised in the contract, i.e., all observable behaviors of your system will be depended upon by somebody.
Postel’s Law (the Robustness Principle): Be conservative in what you send, be liberal in what you accept.
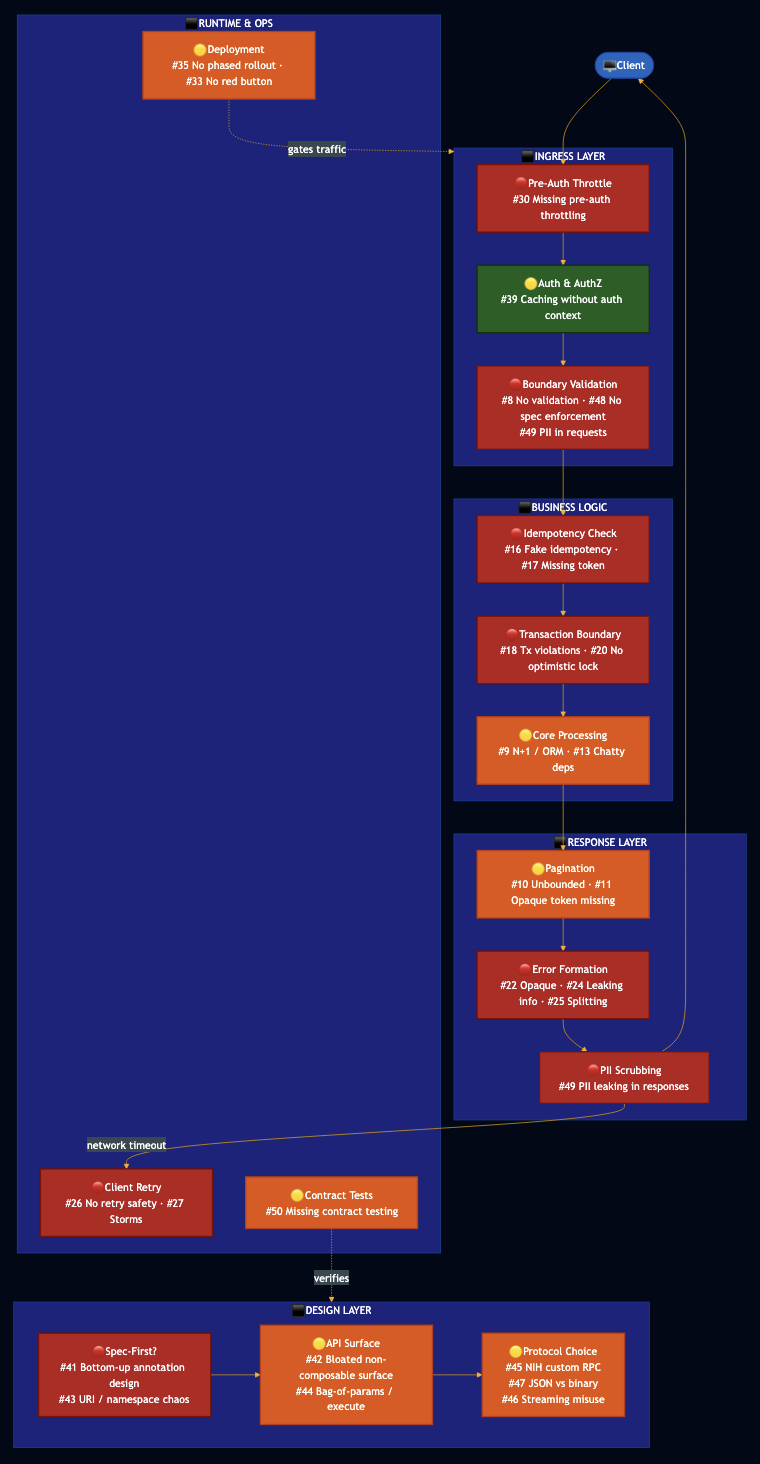
The Anatomy of an API Failure
The diagram below maps where anti-patterns activate in a production request lifecycle. Red nodes are failure hotspots.
Section 1: API Design Philosophy Anti-Patterns
Design philosophy determines everything downstream.
1.1 Bottom-Up API Design: Annotation-Driven and Implementation-First
I have seen this pattern countless times where the team builds the service, then adds Swagger/OpenAPI annotations to the Java or Typescript classes to generate the API spec automatically. The spec is an artifact of the implementation and field names are whatever the ORM column is called. Endpoints are organized around the service layer, not the consumer’s mental model. The spec is generated post-hoc, often incomplete, and rarely reviewed before clients onboard.
In the end, you get an API that perfectly describes your internal implementation and is poorly shaped for external callers. Names leak internal terminology. Refactoring the implementation silently changes the API contract. The APIs are also strongly coupled to the UI that the same team is building and clients who onboard during development find a moving target.
Better approach: Spec-First Design: Write the OpenAPI or Protobuf spec before writing any implementation code. Use the spec as the contract that drives both the server implementation and the client SDK. Review the spec with consumers before implementation begins. Use code generation to produce server stubs from the spec.
# spec-first: openapi.yaml is the source of truth, written before implementation
openapi: "3.1.0"
info:
title: Order Service
version: "1.0.0"
paths:
/v1/orders:
post:
operationId: createOrder
summary: Create a new order
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/CreateOrderRequest'
responses:
'201':
description: Order created
content:
application/json:
schema:
$ref: '#/components/schemas/Order'
'400':
$ref: '#/components/responses/ValidationError'
'409':
$ref: '#/components/responses/ConflictError'
For gRPC: write the .proto file first. The proto is the spec. Code-generate both server stubs and client libraries from it. Also, Google’s API Improvement Proposals (AIP) define a spec-first methodology for gRPC APIs that also maps to HTTP via the google.api.http annotation. A single proto definition can serve both gRPC clients and REST/JSON clients through a transcoding layer (Envoy, gRPC-Gateway), giving you the performance of binary protobuf and the accessibility of JSON from one spec:
service OrderService {
rpc CreateOrder(CreateOrderRequest) returns (Order) {
option (google.api.http) = {
post: "/v1/orders"
body: "*"
};
}
rpc ListOrders(ListOrdersRequest) returns (ListOrdersResponse) {
option (google.api.http) = {
get: "/v1/orders"
};
}
}
1.2 Bloated API Surface: Non-Composable, UI-Coupled APIs
Another common pattern I have seen at a lot of companies is that a service that has hundreds or thousands of endpoints because every new feature needs some new data or behavior. Another artifact of poorly designed APIs is bloated response with all fields, all related resources, deeply nested because the first consumer needed everything and nobody added projection. This often occurs because the API is built by the same team building the UI. When the UI changes, new endpoints are added rather than the existing ones being generalized.
This results in integration without documentation becomes impossible. New clients must read everything to understand what to call. Duplicate endpoints proliferate, e.g., three different endpoints do approximately the same thing because each was built for a different screen without awareness of the others.
Composability principle: A well-designed API surface should be small enough that a competent developer can understand its structure in 30 minutes. Operations should compose small, focused operations that can be combined.
// Anti-pattern: purpose-built for one UI screen rpc GetCheckoutPageData(GetCheckoutPageDataRequest) returns (CheckoutPageData); // CheckoutPageData contains customer, cart, inventory, shipping, payment — all tightly coupled to one view // Better: composable operations that any client can combine rpc GetCustomer(GetCustomerRequest) returns (Customer); rpc GetCart(GetCartRequest) returns (Cart); rpc ListShippingOptions(ListShippingOptionsRequest) returns (ListShippingOptionsResponse); // BFF layer aggregates these for the UI — keeps the core API clean
On API surface size: prefer a small number of well-understood, stable operations over a large surface of purpose-built ones. Use field masks or projections so callers opt-in to the fields they need.
1.3 Improper Namespace and Resource URI Design
Though most companies provide REST based APIs but often endpoints organized around verbs instead of resources: /getOrder, /createOrder, /deleteOrder, /updateOrderStatus. No consistent hierarchy. Related resources scattered across URL spaces: /orders and /order-history and /customer-purchases all refer to variants of the same concept with no clear relationship. Different teams own overlapping namespaces. A service called UserService that has endpoints for users, preferences, addresses, payment methods, and audit logs with no sub-resource structure.
The fundamental concept in REST is that URLs identify resources with nouns and HTTP verbs express actions on those resources. A resource hierarchy expresses relationships. This is not an aesthetic preference; it is the architectural model that makes REST APIs predictable without documentation.
# Anti-pattern: verb-based, flat, unorganized
GET /getUser?id=123
POST /createOrder
POST /updateOrderStatus
GET /getUserOrders?userId=123
DELETE /cancelOrder?orderId=456
GET /getOrderHistory?customerId=123
# Correct: resource-oriented hierarchy
GET /v1/users/{userId} # get user
POST /v1/orders # create order
PATCH /v1/orders/{orderId} # partial update (including status)
GET /v1/users/{userId}/orders # orders for a user
DELETE /v1/orders/{orderId} # cancel order
GET /v1/users/{userId}/orders?status=completed # filtered history
Namespace discipline: Keep related resources under the same base path. OrderService owns /v1/orders/**. UserService owns /v1/users/**. Related sub-resources live under their parent: /v1/orders/{orderId}/items, /v1/orders/{orderId}/events. Do not scatter related concepts across different roots based on internal team ownership.
Avoiding duplicate APIs: Before creating a new endpoint, ask whether an existing one can be parameterized to serve the new use case
1.4 The Execute Anti-Pattern: Bag of Params for Different Actions
Contrary to large surface, this anti pattern reuses same endpoint for different action depending on which parameters are present. The operation is effectively execute(action, params...) with a bag of optional fields, where different combinations of fields trigger different code paths.
// Anti-pattern: one RPC that does many things depending on type
message ProcessOrderRequest {
string order_id = 1;
string action = 2; // "cancel", "ship", "refund", "update", "hold"
string cancel_reason = 3; // only used when action = "cancel"
string tracking_number = 4; // only used when action = "ship"
double refund_amount = 5; // only used when action = "refund"
Address new_address = 6; // only used when action = "update"
string hold_until = 7; // only used when action = "hold"
}
It feels like one operation (“do something with this order”). It minimizes the number of endpoints and it is easy to add a new action without changing the RPC signature.
It results in callers not understanding what the operation does without documentation explaining every action variant. Validation becomes a conditional maze — field cancel_reason is required when action = "cancel" but ignored otherwise. Generated SDK method signatures have no useful type information. Tests multiply exponentially.
Better approach: Separate operations for separate actions. Use oneof in protobuf for requests that have genuinely mutually exclusive parameter sets:
// Better: explicit operations, each with a clear contract
rpc CancelOrder(CancelOrderRequest) returns (Order);
rpc ShipOrder(ShipOrderRequest) returns (Order);
rpc RefundOrder(RefundOrderRequest) returns (Refund);
message CancelOrderRequest {
string order_id = 1;
string reason = 2; // always relevant, always validated
}
// If you truly need a polymorphic command, use oneof to make it explicit:
message UpdateOrderRequest {
string order_id = 1;
oneof update {
ShippingAddressUpdate shipping_address = 2;
StatusUpdate status = 3;
ContactUpdate contact = 4;
}
// oneof makes it structurally impossible to send two update types at once
// Generated SDKs expose typed accessors — no stringly-typed action field
}
gRPC’s required/optional semantics: proto3 makes all fields optional by default. Use proto3’s optional keyword explicitly when a field’s absence carries meaning. You can use Protocol Buffer Validation to add more validation and enforce it in your boundary validation layer.
1.5 NIH Syndrome: Custom RPC Protocols Instead of Standards
At other places, I have seen teams build their own binary protocol over raw TCP because “gRPC has too much overhead.” They have custom framing, error codes, and multiplexing, which runs on a non-standard port, and needs special firewall rules. More often it is NIH (Not Invented Here) syndrome, believing that the standard tools are not good enough, combined with underestimation of the operational cost of maintaining a custom protocol.
In the end, custom protocols do not work through corporate proxies, CDNs, API gateways, or load balancers that only speak HTTP. Many enterprise environments permit only HTTP/HTTPS outbound and a custom port means the integration simply cannot be used. Tools like Wireshark, curl, Postman, and every observability platform will not understand your protocol. Debugging becomes dramatically harder because the entire ecosystem of HTTP tooling is unavailable.
What standard protocols actually give you:
| Protocol | Best For | Transport | Streaming |
|---|---|---|---|
| REST/HTTP | Public APIs, broad compatibility | HTTP/1.1, HTTP/2 | No (use SSE) |
| gRPC | High-performance internal services, strong typing | HTTP/2 | Yes (4 modes) |
| WebSocket | Bidirectional real-time communication | HTTP upgrade | Yes (full-duplex) |
| GraphQL | Flexible queries, client-driven shape | HTTP/1.1, HTTP/2 | Subscriptions |
| Server-Sent Events | Server-push notification | HTTP/1.1 | Server-to-client |
1.6 Badly Designed Streaming APIs
This is similar to previous pattern where a team that needs real-time data pushes builds a polling endpoint (GET /events?since=<timestamp>) and expects clients to poll every second. Or uses raw sockets that send large JSON blobs because “it’s streaming.” Or uses gRPC streaming but sends the entire dataset in one message instead of streaming rows incrementally. Or builds a custom long-polling mechanism with complex session state when SSE would have been simpler.
- gRPC streaming modes:
service DataService {
// Unary: single request, single response — most operations
rpc GetOrder(GetOrderRequest) returns (Order);
// Server streaming: one request triggers a stream of responses
// Use for: sending large datasets, live feeds, log tailing
rpc TailOrderEvents(TailOrderEventsRequest) returns (stream OrderEvent);
// Client streaming: stream of requests, one response
// Use for: bulk ingest, file upload in chunks
rpc BulkCreateOrders(stream CreateOrderRequest) returns (BatchCreateOrdersResponse);
// Bidirectional streaming: both sides stream independently
// Use for: real-time chat, collaborative editing, game state sync
rpc SyncOrderState(stream OrderStateUpdate) returns (stream OrderStateUpdate);
}
- WebSocket is the correct choice for full-duplex browser communication where you need persistent connections with low latency in both directions. It upgrades from HTTP, passes through standard proxies, and is supported universally.
- Server-Sent Events (SSE) is the correct choice for server-push-only scenarios (notifications, live dashboards) where the client only needs to receive, not send. SSE is HTTP.
- Never build: custom TCP streaming, custom HTTP long-polling with complex session management, or custom binary framing when gRPC already provides exactly that.
1.7 Ignoring Encoding: JSON Everywhere Regardless of Cost
This anti-pattern can surfaces when a high-throughput internal service between two microservices you control uses JSON over HTTP/1.1 because “it’s simple.” Internal services process millions of messages per second serializing and deserializing large JSON payloads. The payload includes deeply nested structures with long field names repeated in every message. No compression. No binary encoding.
The performance reality: JSON is human-readable text with significant overhead:
- Field names are repeated in every object (bandwidth and parse cost)
- No schema enforcement at the encoding layer
- No native binary type (base64 for bytes adds ~33% overhead)
- UTF-8 string parsing is CPU-intensive at high throughput
Protobuf binary encoding is typically 3–10× smaller than equivalent JSON and 5–10× faster to serialize/deserialize at high volume. For internal service-to-service communication at scale, this is not a micro-optimization, it is a significant infrastructure cost difference.
Better approach: Choose encoding based on the use case:
| Scenario | Recommended Encoding |
|---|---|
| Public REST API, browser clients | JSON (required for broad compatibility) |
| Internal service-to-service (high throughput) | Protobuf binary over gRPC |
| Internal service-to-service (moderate) | JSON over HTTP/2 with compression is acceptable |
| Mixed: public + internal clients | gRPC with HTTP/JSON transcoding via AIP |
| Event streaming (Kafka, Kinesis) | Avro or Protobuf with schema registry |
gRPC over HTTP/2 gives you multiplexed streams, binary encoding, strongly typed contracts, and bi-directional streaming in one package. For internal services at scale, there is rarely a justification for JSON over HTTP/1.1.
1.8 No Clear Internal/External API Boundary
In many cases, organizations may use gRPC internally and REST externally but in practice, the internal gRPC APIs were never held to any standard. For example, field names are inconsistent, operations are not paginated or there is no versioning.
- Internal APIs become a inconsistent mess with duplicate functionality. Because internal APIs have no governance, each team designs theirs in isolation. Team A has
GetUserProfile. Team B hasFetchUser. Team C hasLookupUserById. The internal API surface grows without bound. - Internal APIs leak into the external surface. The public REST API was designed conservatively, returning only what external callers need. But an internal team needs the same resource with additional fields. Rather than adding a projection or a scoped access tier, the quickest path is to promote the internal API endpoint. Over time, the line between “public” and “internal” API blurs. External clients discover undocumented internal fields (Hyrum’s Law again) and start depending on them.
Better approach — treat internal and external APIs as two tiers of the same governance model:
External API (public) Internal API (private) ?????????????????????? ????????????????????????? Same naming conventions Same naming conventions Same error shape Same error shape Same pagination model Same pagination model Same versioning policy Same versioning policy — yes, even internally Minimal response fields Additional fields gated by internal scope/role OpenAPI spec enforced Proto spec enforced with protoc-gen-validate Published SLA Published SLA (even if internal) Contract tests in CI Contract tests in CI
The key discipline is that internal APIs must follow the same standards as public APIs in terms of naming, versioning, error shapes, pagination. The only difference is the data they expose and the authentication model.
Handling the “extra fields” problem: use scoped projections rather than separate endpoints:
message GetOrderRequest {
string order_id = 1;
// Callers with INTERNAL_READ scope receive all fields.
// External callers receive only the public projection.
// The same RPC serves both — authorization determines the projection.
FieldMaskScope scope = 2;
}
enum FieldMaskScope {
FIELD_MASK_SCOPE_PUBLIC = 0; // external callers: customer-visible fields
FIELD_MASK_SCOPE_INTERNAL = 1; // internal callers: + audit, cost, state flags
FIELD_MASK_SCOPE_ADMIN = 2; // ops callers: + all internal diagnostics
}
message Order {
// Public fields — always returned
string order_id = 1;
OrderStatus status = 2;
google.protobuf.Timestamp created_at = 3;
// Internal fields — returned only to INTERNAL_SCOPE callers
// Stripped at the API gateway for external requests
string internal_routing_key = 100;
CostAllocation cost_allocation = 101;
// Admin fields — returned only to ADMIN_SCOPE callers
repeated AuditEvent audit_trail = 200;
}This approach keeps one canonical API, one proto spec, one set of tests. The authorization layer determines which fields a caller receives. The API gateway strips internal fields from external responses. The same spec, with scope annotations, documents both tiers.
On internal API governance: internal APIs need the same review gates as public APIs, even if the review is lighter. Some organizations enforce this via a service registry where every internal API must be registered, and the registry enforces naming and schema standards automatically.
1.9 Mixing Control-Plane and Data-Plane APIs
This anti-pattern occurs when a single API service handles both resource management (create a cluster, update a configuration, rotate a secret) and the high-frequency operational traffic that those resources serve (process a transaction, ingest a telemetry event). The same service, the same load balancer, the same deployment unit. A configuration change that causes a brief control-plane outage also takes down the data plane. A traffic spike on the data plane starves the management operations that operators need most during an incident.
Defining the planes: these terms come from networking and are now standard in cloud platform design.
| Plane | Purpose | Typical TPS | Latency requirement | Caller |
|---|---|---|---|---|
| Control plane | Manage and configure resources | Low (10s–100s/s) | Relaxed (100ms–seconds) | Operators, automation, UI |
| Data plane | Serve the workload those resources define | High (1,000s–millions/s) | Strict (single-digit ms) | End-users, services, devices |
Real-world examples of the split done correctly:
- Kubernetes:
kube-apiserveris the control plane that creates Deployments, update ConfigMaps, scale ReplicaSets. The actual pod-to-pod traffic it orchestrates is the data plane. Akube-apiserverbrownout does not stop running pods from serving traffic. - AWS API Gateway: The management API (create/update/delete routes, authorizers, stages) is the control plane. The actual HTTP proxy that forwards requests to Lambda or ECS is the data plane.
The scaling difference between management traffic and operational traffic is invisible until it isn’t. The consequence: Two failure modes, both serious.
- First, data-plane load starves control-plane availability. A traffic spike on the data plane consumes all available threads, connections, and CPU. Operators cannot reach the management API to make the configuration change that would fix the problem.
- Second, control-plane deployments risk data-plane availability. A risky configuration change deployed to the unified service takes down both planes together. A misconfigured authentication change gates all traffic, including the operational traffic that cannot tolerate any interruption.
Better approach:
Separate the planes at the service level, not just at the routing level. A reverse proxy that routes /mgmt/* to one backend and /v1/* to another on the same process does not achieve the isolation you need.
// Control-plane API — management operations, low TPS, relaxed latency
service OrderConfigService {
// Create/update routing rules — takes effect asynchronously
rpc UpsertRoutingRule(UpsertRoutingRuleRequest) returns (RoutingRule);
rpc DeleteRoutingRule(DeleteRoutingRuleRequest) returns (google.protobuf.Empty);
rpc ListRoutingRules(ListRoutingRulesRequest) returns (ListRoutingRulesResponse);
// Capacity and rate limit configuration
rpc SetRateLimit(SetRateLimitRequest) returns (RateLimit);
// Returns async job — config changes propagate eventually to data plane
rpc TriggerConfigSync(TriggerConfigSyncRequest) returns (ConfigSyncJob);
}
// Data-plane API — operational traffic, high TPS, strict latency
service OrderService {
// Reads routing rules from LOCAL CACHE — never calls control plane in-band
rpc CreateOrder(CreateOrderRequest) returns (Order);
rpc GetOrder(GetOrderRequest) returns (Order);
rpc ListOrders(ListOrdersRequest) returns (ListOrdersResponse);
}- Config propagation: the data plane must not call the control plane synchronously on the hot path. Configuration is pushed from the control plane to the data plane via an event stream or periodically polled and cached locally. The data plane starts with the last known good configuration and operates independently if the control plane is temporarily unavailable.
- Deployment and SLA differences: control-plane deployments can be careful, canary-gated, and slow because the cost of a management API degradation is low (operators retry). Data-plane deployments should be fast and automated with aggressive auto-rollback because the cost of data-plane degradation is direct user impact.
Section 2: Contract & Consistency Anti-Patterns
2.1 Inconsistent Naming Across APIs
This anti-pattern is fairly common with evolution of API, e.g., EC2 uses CreateTags, ELB uses AddTags, RDS uses AddTagsToResource, Auto Scaling uses CreateOrUpdateTagswith four different verb shapes for the same semantic across four services.
Better approach: Establish a canonical vocabulary before first public release. For lifecycle operations: Create, Get, List, Update, Delete. Use id (server-assigned) vs name (client-specified) consistently. Use google.protobuf.Timestamp for all time values, never strings, never epoch integers.
message Order {
string order_id = 1; // server-assigned ID
string customer_name = 2; // client-specified name
google.protobuf.Timestamp created_at = 3; // typed timestamp, never string
google.protobuf.Timestamp updated_at = 4;
OrderStatus status = 5; // enum, not string, not int
}
enum OrderStatus {
ORDER_STATUS_UNSPECIFIED = 0; // always include; proto3 default
ORDER_STATUS_PENDING = 1;
ORDER_STATUS_CONFIRMED = 2;
ORDER_STATUS_CANCELLED = 3;
}
2.2 Wrong HTTP Verb for the Operation
Despite adopting REST, I have seen companies misusing verbs like PATCH /orders/{id} that replaces the entire resource. GET /reports/generate that inserts a database record.
Note on GraphQL and gRPC: Both protocols legitimately tunnel all operations through HTTP POST. This is an intentional protocol design choice andnot an anti-pattern but it must be documented explicitly, and REST-layer middleware (caches, proxies, WAFs) must be configured to account for it.
| Verb | Semantics | Idempotent | Safe |
|---|---|---|---|
| GET | Retrieve | Yes | Yes |
| PUT | Full replace | Yes | No |
| PATCH | Partial update | Conditionally | No |
| POST | Create / non-idempotent | No | No |
| DELETE | Remove | Yes | No |
2.3 Breaking API Changes Without Versioning
A breaking change without versioning can easily break clients, e.g., a field renamed from customerId to customer_id, an error code that was 400 becomes 422, a previously optional field becomes required.
Safe (no version bump): adding optional request fields, adding response fields, adding new operations, making required fields optional. Never safe without a version bump: removing/renaming fields, changing field types, changing error codes for existing conditions, splitting an exception type, changing default behavior when optional inputs are absent.
2.4 Hyrum’s Law: Changing Semantic Behavior Without Versioning
With this anti-pattern, you fix a bug where ListOrders returned insertion order instead of alphabetical. You update an error message wording. You tighten validation. All of these feel internal. None are.
Better approach: Document everything observable. Use structured error fields (resource IDs, machine-readable codes) so clients never parse message strings. Treat any observable change including ordering, error message wording, validation leniency as potentially breaking.
2.5 Postel’s Law Misapplied: Silently Accepting Bad Input
This anti-pattern occurs when an API that accepts quantity: -5 and treats it as 0. An endpoint that silently drops unknown fields, then later adds a field with the same name with different semantics. An API that accepts both camelCase and snake_case then a new field orderType collides with legacy alias order_type.
Better approach: Be strict at the boundary. Reject invalid input with a structured ValidationException. Accept unknown fields only if explicitly designed for forward compatibility. Never silently coerce.
2.6 Bimodal Behavior
In this scenario, under normal load, ListOrders returns a complete consistent list with 200. Under high load, it silently returns a partial list still with 200.
Better approach: Your degraded paths must return consistent response shapes and correct status codes. A timeout is a 503 with Retry-After. A partial result is not a 200.
2.7 Leaky Abstractions
Examples of leaky abstractions include error messages contain internal ORM table names; pagination tokens are readable base64 JSON containing your database cursor.
Better approach: Map your domain model to your API, not your implementation. Pagination tokens must be opaque, encrypted, and versioned. Internal identifiers and infrastructure topology must never be inferred from responses.
2.8 Missing or Inconsistent Input Validation
This occurs when some fields are validated strictly, others silently truncated. The same field accepts null, "", and "0" on different endpoints.
Better approach: Validate at the boundary, consistently, for every operation.
message ValidationException {
string message = 1; // human-readable — never parse this in code
string request_id = 2;
repeated FieldViolation field_violations = 3;
}
message FieldViolation {
string field = 1; // "order.items[2].quantity"
string description = 2; // "must be greater than 0, got -5"
}
Section 3: Implementation Efficiency Anti-Patterns
3.1 N+1 Queries and ORM Abuse
In this case, you might have a ListOrders endpoint that fetches the list in one query, then issues a separate query per order for customer details, then another per order for line items. With 100 orders: 201 database round trips for what should be 1.
Network cost: Each cloud database round trip costs 1–5ms. 4,700 round trips = 4.7–23.5 seconds of pure network overhead before a byte of business logic executes. As covered in How Abstraction Is Killing Software, every layer crossing a network boundary multiplies the failure surface and latency budget.
Better approach: Return summary structures with commonly needed fields. Audit query plans with production-scale data before launch. Use eager loading for related data.
3.2 Missing Pagination
In this case, you might have a ListOrders endpoint that returns all results in a single response. Works at launch with small datasets. At scale some accounts have millions of records and responses become hundreds of megabytes, timeouts multiply, and clients start crashing on deserialization. Retrofitting pagination is a breaking change. If your endpoint always returned everything and you start returning a page with a next_page_token, clients that assumed completeness silently miss data. For example, EC2’s original DescribeInstances had no pagination. As customer instance counts grew into the thousands, responses became megabyte-scale XML documents that timed out and crashed clients. Retrofitting required making pagination opt-in legacy callers continued hitting the unbounded path for years after the fix shipped.
Guidance: every list operation must be paginated before first release:
- All
List*operations that return a collection MUST be paginated no exceptions. The only exemption is a naturally size-limited result like a top-N leaderboard. - Only one list per operation may be paginated. If you need to paginate two independent collections, expose two operations.
- Paginated results SHOULD NOT return the same item more than once across pages (disjoint pages). If the sort order is not an immutable strict total ordering, provide a temporally static view or snapshot the result set at the time of the first request and page through the snapshot.
- Items deleted during pagination SHOULD NOT appear on later pages.
- Newly created items MAY appear on not-yet-seen pages, but MUST appear in sorted order if they do.
The canonical request/response shape (REST and gRPC should follow the same field naming like page_size in, next_page_token out):
message ListOrdersRequest {
// Optional upper bound — service may return fewer. Default is service-defined.
// Client MUST NOT assume a full page means there are no more results.
int32 page_size = 1 [(validate.rules).int32 = {gte: 0, lte: 1000}];
// Opaque token from previous response. Absent on first call.
string page_token = 2;
// Filter parameters — MUST be identical on every page of the same query.
// Service MUST reject a request where filters change mid-pagination.
OrderFilter filter = 3;
}
message ListOrdersResponse {
repeated OrderSummary orders = 1;
// Absent when there are no more pages. Clients MUST stop when this is absent.
// Never an empty string — absent means done, empty string is ambiguous.
string next_page_token = 2;
// Optional approximate total — document clearly that this is an estimate.
// Do NOT guarantee an exact count; that requires a full scan on every call.
int32 approximate_total = 3;
}page_size is an upper bound, not a target: the service MUST return a next_page_token and stop early when its own threshold is exceeded. Attempting to fill a page to meet page_size for a highly selective filter on a large dataset creates an unbounded operation.
Changing page_size between pages is allowed: it does not change the result set, only how it is partitioned. Changing filter parameters is not allowed and must be rejected.
3.3 Pagination Token Anti-Patterns
Every one of the following mistakes has been made in production by major APIs. Each creates a permanent contract liability.
- Readable token (leaks implementation): When you restructure your database, the token format is a public contract you cannot change. Clients construct tokens manually to jump to arbitrary offsets, bypassing your access controls. Making backwards-compatible changes to a plain-text token format is nearly impossible.
// Decoded token — client immediately knows your DB cursor format
{ "offset": 500, "shard": "us-east-1a", "table": "orders_v2" }- Token derived by client (S3
ListObjectsmistake): S3’s originalListObjectsrequired callers to derive the next token themselves: checkIsTruncated, useNextMarkerif present, otherwise use theKeyof the lastContentsentry. Every S3 client library had to implement this multi-step derivation. When S3 needed to change the pagination algorithm, all that client logic became incorrect.ListObjectsV2was the clean-break solution an explicit opaqueContinuationTokenissued by the server. - Token that never expires: A non-expiring token makes schema migrations impossible. If your pagination token format encodes version 1 of your database schema and you ship version 2, you must maintain a decoder for every token ever issued indefinitely. A 24-hour expiry gives you a bounded window after which all outstanding tokens are on the current format.
- Token usable across users: A token generated for user A contains enough context to enumerate user B’s resources if the user check is missing. This is a data isolation vulnerability, not just a correctness bug.
- Token that influences AuthZ: The service must not evaluate permissions differently based on whether a pagination token is present or what it contains. Authorization must be re-evaluated on every page request using the caller’s current credentials, not credentials cached inside the token.
// What the service stores inside the encrypted token — never visible to callers
message PaginationTokenPayload {
string account_id = 1; // bound to caller's account
int32 version = 2; // token format version for forward compatibility
string cursor = 3; // internal cursor — DB row ID, sort key, etc.
google.protobuf.Timestamp issued_at = 4; // for expiry enforcement
bytes filter_hash = 5; // hash of filter params — reject if changed
}
// This struct is AES-GCM encrypted before being base64-encoded and returned as next_page_token.
// The client sees only an opaque string. The server decrypts and validates on every use.Client usage pattern: SDK helpers should abstract this loop, but every client must implement it correctly when calling raw:
page_token = None
while True:
response = client.list_orders(
filter={"status": "PENDING"},
page_size=100,
page_token=page_token # None on first call
)
process(response.orders)
page_token = response.next_page_token
if not page_token:
break # no token = no more pages; do NOT check len(orders) < page_size
# NOTE: len(orders) < page_size does NOT mean last page.
# The service may return fewer results for internal reasons (execution time limit,
# scan limit, etc.) and still issue a next_page_token. Always check the token.The single most common client-side pagination bug is treating a short page as a signal that pagination is complete.
3.4 Filtering Anti-Patterns
Filtering is where inconsistency compounds fastest as every team makes slightly different choices about semantics, validation, and edge cases, and callers cannot predict the behavior without reading the documentation for every endpoint individually.
The standard AND/OR semantic: all filtering implementations should follow EC2’s model: multiple values for a single attribute are OR’d; multiple attributes are AND’d. The order of attributes must not affect the result (commutative).
# EC2 canonical example aws ec2 describe-instances \ --filter Name=instance-state-name,Values=running \ --filter Name=image-id,Values=ami-12345 \ --filter Name=tag-value,Values=prod,test # Equivalent SQL semantics: # (instance-state-name = 'running') # AND (image-id = 'ami-12345') # AND (tag-value = 'prod' OR tag-value = 'test')
Swapping the order of the three filter arguments must return an identical result set. Clients must never need to order their filters to get correct behaviour.
Include/exclude filter variants for date, time, and status fields:
# Negation filter: exclude terminated instances from a different AZ aws ec2 describe-instances \ --filter Name=instance-state-name,Values=terminated,operator=exclude \ --filter Name=availability-zone,Values=us-east-1a,operator=include
Timestamp fields MAY support not-before / not-after semantics. When supported, document the semantics exactly and validate that the provided value is a well-formed timestamp.
Filter structure in protobuf: use an enum for attribute names so the set of supported filters is machine-readable, and a validated pattern for values so wildcards and injection vectors are controlled:
message ListOrdersRequest {
repeated Filter filters = 1 [(validate.rules).repeated.max_items = 10];
int32 page_size = 2;
string page_token = 3;
}
message Filter {
FilterAttribute name = 1; // enum — only supported attributes accepted
repeated string values = 2 // OR'd together; max bounded
[(validate.rules).repeated = {min_items: 1, max_items: 20}];
FilterOperator operator = 3; // default INCLUDE; EXCLUDE for negation
}
enum FilterAttribute {
FILTER_ATTRIBUTE_UNSPECIFIED = 0;
FILTER_ATTRIBUTE_STATUS = 1; // maps to Order.status
FILTER_ATTRIBUTE_REGION = 2; // maps to Order.region
FILTER_ATTRIBUTE_CREATED_AFTER = 3; // timestamp lower bound
FILTER_ATTRIBUTE_CREATED_BEFORE = 4; // timestamp upper bound
// Every value here must correspond to a field returned in OrderSummary.
// Never add a filter attribute for an internal field not in the response.
}
enum FilterOperator {
FILTER_OPERATOR_INCLUDE = 0; // default — only matching resources returned
FILTER_OPERATOR_EXCLUDE = 1; // matching resources excluded from results
}Filtering vs. specifying a list of IDs: these are different operations and must not be conflated. A filter is a predicate applied to the result set and it does not guarantee fetching a specific resource. Fetching a known set of resource IDs is a batch read (BatchGetOrders) and belongs in the batch operations standard, not in the filter parameter.
Flat parameters vs. structured filter list: two common shapes exist. Flat parameters (?status=PENDING®ion=us-east) are simpler for simple cases and easier to cache with HTTP GET semantics. A structured filters list (as above) is more extensible and handles negation, wildcards, and complex predicates cleanly. Do not mix shapes across endpoints.
3.5 Chatty APIs and Network Latency Multiplication
Rendering a single page requires six sequential API calls. Each is 20ms. Sequential total: 120ms of pure network time before rendering begins. For example, Netflix’s move to microservices initially produced exactly this. Their solution: the BFF (Backend for Frontend) pattern, which is a purpose-built aggregation layer that parallelizes the six calls and returns one tailored response to the client.
Better approach: Design batch and composite read operations for primary use cases. Where callers need related resources together, provide projections. Parallelize what can be parallelized in your aggregation layer.
3.6 Synchronous APIs for Long-Running Operations
This is another pattern resulting from poor understanding of API behavior, e.g., POST /reports/generate blocks for 45 seconds, or it returns 202 Accepted (or 202 OK) with no body, no job ID, no link to check status, no way to cancel, and no way to know when it is safe to retry. Another related scenario is an API that was designed for a specific UI assumption, e.g., “the UI will only ever submit 100 IDs” but is exposed as a general API. When an automation script submits 10,000 IDs, the synchronous operation times out at the load balancer, the client retries, and two copies of the same job are now running. The API has no idempotency token, no job ID to check for an in-progress operation, and no way to cancel the duplicate. The missing async API primitives:
- No
requestIdin the202response: the caller has no handle to reference the job in subsequent calls, in logs, or in support tickets - No status endpoint: the caller cannot poll for completion; the only signal is silence until a webhook fires
- No cancel operation: a misconfigured job consuming resources cannot be stopped without operator intervention
- No idempotency on submission: submitting the same job twice creates two jobs; there is no way to detect an in-progress duplicate
- No bounded input validation: the operation accepts an unbounded number of IDs because the UI never sends more than 100, but the API contract enforces no limit; automation sends 100,000 and the job runs for hours
Better approach is complete async job lifecycle:
// Submission: returns immediately with a Job handle
rpc StartExport(StartExportRequest) returns (Job) {
option (google.api.http) = { post: "/v1/exports", body: "*" };
// Response: HTTP 202 Accepted
}
// Status + result polling
rpc GetJob(GetJobRequest) returns (Job) {
option (google.api.http) = { get: "/v1/jobs/{job_id}" };
}
// Cancellation — idempotent; safe to call multiple times
rpc CancelJob(CancelJobRequest) returns (Job) {
option (google.api.http) = { post: "/v1/jobs/{job_id}:cancel", body: "*" };
}
message StartExportRequest {
string client_token = 1; // idempotency — same token returns existing job, not a new one
repeated string record_ids = 2 [(validate.rules).repeated = {
min_items: 1,
max_items: 1000 // enforced at boundary — not a UI assumption baked into code
}];
ExportFormat format = 3;
}
message Job {
string job_id = 1; // stable handle for all subsequent calls
string request_id = 2; // trace ID for this submission specifically
JobStatus status = 3;
google.protobuf.Timestamp submitted_at = 4;
google.protobuf.Timestamp completed_at = 5; // absent until terminal state
string result_url = 6; // present only when status = SUCCEEDED
JobError error = 7; // present only when status = FAILED
string self_link = 8; // href to GET this job — no client URL construction needed
string cancel_link = 9; // href to cancel — clients should use these, not construct URLs
int32 estimated_seconds = 10; // hint for polling interval; not a guarantee
}
enum JobStatus {
JOB_STATUS_UNSPECIFIED = 0;
JOB_STATUS_QUEUED = 1;
JOB_STATUS_RUNNING = 2;
JOB_STATUS_SUCCEEDED = 3;
JOB_STATUS_FAILED = 4;
JOB_STATUS_CANCELLED = 5;
JOB_STATUS_CANCELLING = 6; // in-progress cancel — may still complete
}The 202 Accepted response body must include:
job_id— the durable handleself_link— the URL to poll (clients must not construct this)cancel_link— the URL to cancelestimated_seconds— polling hintrequest_id— for logging and support correlation
HTTP 202 Accepted
Location: /v1/jobs/job-a3f9c2
{
"job_id": "job-a3f9c2",
"status": "QUEUED",
"request_id": "req-7d2e1a",
"self_link": "/v1/jobs/job-a3f9c2",
"cancel_link": "/v1/jobs/job-a3f9c2:cancel",
"estimated_seconds": 30
}The Location header is standard HTTP for 202 include it so HTTP clients that follow redirects and standard library polling helpers work without custom code.
Idempotency on submission prevents duplicate jobs: if a client submits with client_token: "export-2024-q1" and receives a timeout, the retry with the same token returns the existing Job.
Bounded input enforced at the boundary: the max_items: 1000 constraint in StartExportRequest is enforced by protoc-gen-validate at the gRPC boundary instead of application code. If the constraint needs to change, it changes in the proto spec and the enforcement changes with it.
3.7 Batch Operations with Mixed Success/Error Lists
This occurs when a batch endpoint returns a single flat list where successes and failures are distinguished only by the presence of an error field. Callers must iterate every entry to determine outcome. For example, Firehose’s PutRecordsBatch uses this anti-pattern with a single mixed list. The correct model (adopted in newer AWS APIs) separates success and failure lists:
message BatchCreateOrdersResponse {
repeated Order created_orders = 1;
repeated OrderError failed_orders = 2;
// HTTP 200 even if all items failed — per-item failure is in failed_orders
// HTTP 400 only if the batch itself is malformed
}
message OrderError {
string client_request_id = 1; // correlates to request entry
string error_code = 2;
string message = 3;
}
Section 4: Idempotency & Transaction Anti-Patterns
4.1 Duplicate Detection Masquerading as True Idempotency
I wrote about this previously at How Duplicate Detection Became the Dangerous Impostor of True Idempotency and this issue arises when you create endpoint checks for an existing resource with the same name and returns it if found, calling this “idempotency.”
The correct idempotency token flow:
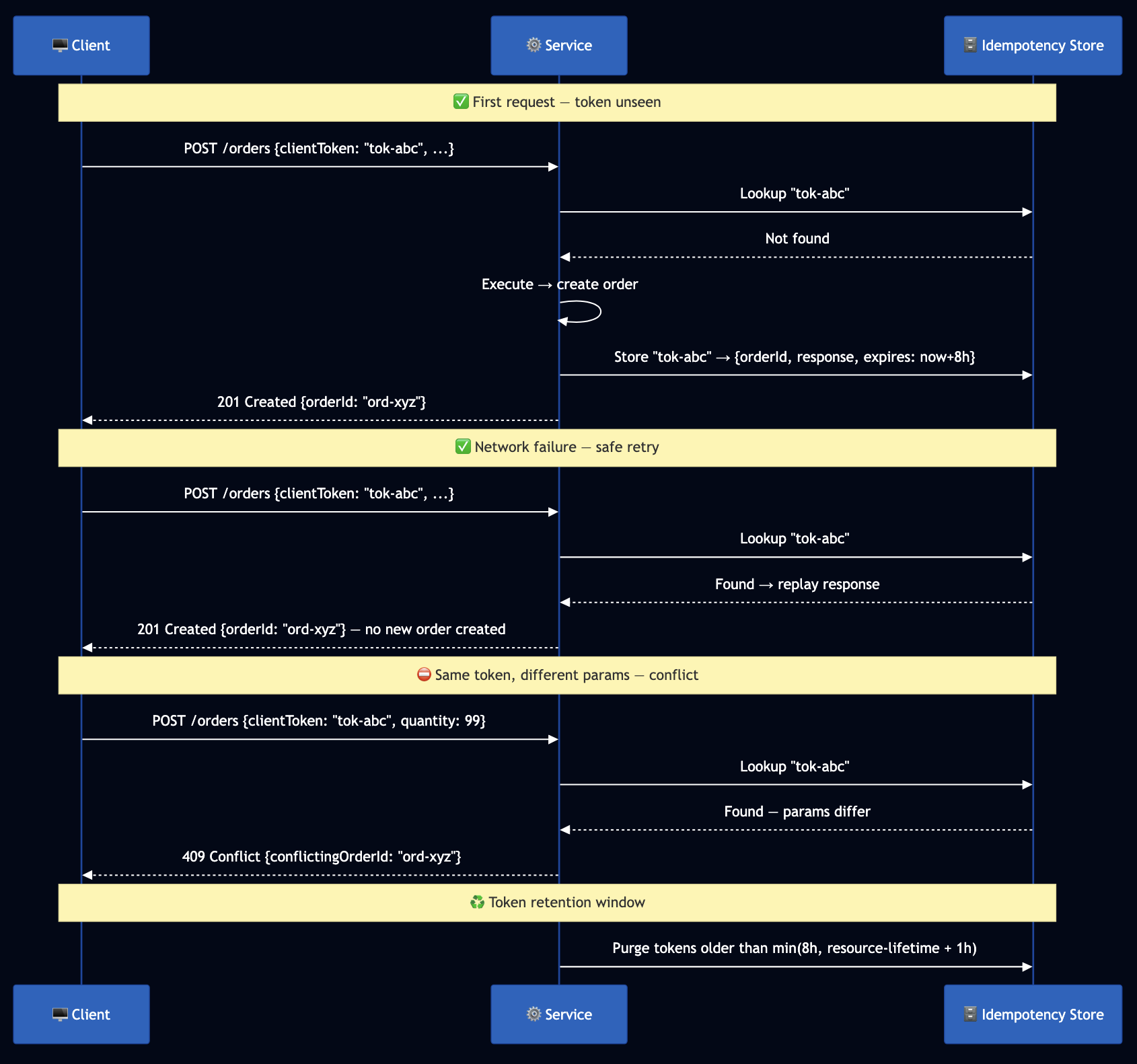
Stripe’s idempotency key is the canonical implementation. Every POST accepts an Idempotency-Key header. Stripe stores the key and the exact response. Same key within 24 hours replays the original response without re-executing. Same key with a different body returns 422.
Failure mode of duplicate detection: A response is lost in transit. The client retries. Meanwhile, another actor deleted the resource and a third created a new one with the same name. Your “idempotent” endpoint returns the new resource which the original client neither created nor controls.
4.2 Missing Idempotency Tokens on Create Operations
This scenario may occur when POST /orders returns an order ID without clientToken. The client gets a timeout. Retry = potential duplicate. No retry = potential data loss. For example, early payments APIs had this problem. A double-charge scenario: customer clicks Pay, network times out, app retries, customer charged twice. Stripe, Adyen, and Braintree all mandate idempotency keys for payment operations.
message CreateOrderRequest {
// SDK auto-generates when absent; callers may provide their own.
// Must be at least 64 ASCII printable characters for uniqueness.
optional string client_token = 1;
string customer_id = 2;
repeated OrderItem items = 3;
}
4.3 Transaction Boundary Violations
I wrote about this anti-pattern previously at Transaction Boundaries: The Foundation of Reliable Systems. This occurs when a single API call updates two separate resources with no atomicity guarantee. The first update succeeds; the service crashes before the second. Caller retries; first update applies twice.
Better approach: Document atomicity guarantees explicitly. For cross-service consistency, use the Saga pattern with compensating transactions.
4.4 Full Update via PATCH (Implicit Field Deletion)
This occurs when PATCH /orders/{id} replaces the entire resource. Fields not included are deleted. A mobile client updating the shipping address silently deletes the contact email. For example, GitHub’s current v3 API is explicit: PATCH applies partial updates, PUT applies full replacement — documented unambiguously for every endpoint.
message UpdateOrderRequest {
string order_id = 1;
Order order = 2;
// Only fields in update_mask are modified.
// paths = ["shipping_address"] ? only shipping_address is touched
google.protobuf.FieldMask update_mask = 3;
}
4.5 Missing Optimistic Concurrency Control
This occurs when two clients GET the same order, both modify it, both PUT back. The last write silently overwrites the first. For example, Kubernetes uses server-side apply with field ownership tracking and returns 409 Conflict with the specific fields in conflict. The ETag / If-Match pattern is the REST equivalent.
GET /orders/123 ? { ..., "version": "v7" }
PATCH /orders/123 + If-Match: v7
# If order is now v8: HTTP 409 Conflict { "current_version": "v8" }
4.6 Ignoring Concurrent Operation Safety
In this scenario, an API that allows parallel create-and-delete on the same resource without concurrency safety. A long-running create that can be invoked a second time while the first is in flight.
Better approach: Document concurrency semantics per operation. For long-running creates: check for an in-progress operation before starting a new one. Use idempotency tokens to prevent parallel retries from compounding.
Section 5: Error Handling Anti-Patterns
5.1 Opaque, Non-Actionable Errors
This anti-pattern occurs with poorly defined errors like: {"error": "Something went wrong"}. An HTML error page from a load balancer served as an API response. The same ValidationException returned for “field missing,” “field too long,” and “field contains invalid characters.”
Better approach: I wrote about better error handling previously at Building Robust Error Handling with gRPC and REST APIs. Seven standard exception types cover nearly all scenarios:
| Exception | HTTP | Retryable |
|---|---|---|
ValidationException | 400 | No |
ServiceQuotaExceededException | 402 | No (contact support) |
AccessDeniedException | 403 | No |
ResourceNotFoundException | 404 | No |
ConflictException | 409 | No (needs resolution) |
ThrottlingException | 429 | Yes (honor Retry-After) |
InternalServerException | 500 | Yes (with backoff) |
Include request_id in every error response for support correlation. Include retry_after_seconds in 429 and 500 responses.
5.2 Error Messages That Clients Must Parse
This occurs where an API error looks like "ValidationException: The field 'order.items[2].quantity' must be greater than 0." A client parses the string to extract the field path. Major cloud providers have been forced to freeze exact error message phrasing for years because clients parse them. Changing a comma placement breaks production integrations.
Better approach: As described in Building Robust Error Handling with gRPC and REST APIs, error message text is for humans reading logs. Any information a program acts on must be in structured fields, never embedded in the message string.
5.3 Leaking Internal Information in Errors
Error messages contain database hostnames, stack traces, SQL fragments, or internal ARNs. 500 that says NullPointerException at com.internal.service.OrderProcessor:237.
Security principle: Return only information applicable to that request and requester. An unauthorized caller asking for a resource that does not exist receives 403 AccessDeniedException, not 404 ResourceNotFoundException that reveals non-existence is as informative as confirming existence.
Better approach: Catch and re-throw all dependency exceptions as service-defined error types. Include only a requestId for support lookup.
5.4 Exception Type Splitting and Proliferation
Splitting ConflictException into ResourceAlreadyExistsException, ConcurrentModificationException, and OptimisticLockException after release. Clients catching ConflictException silently miss the new subtypes.
The rule: Splitting an existing exception type is a breaking change. Adding fields to an existing exception type is always safe. Add new exception types only for genuinely new scenarios triggered by new optional parameters.
Section 6: Resilience & Operations Anti-Patterns
6.1 Missing Retry Safety in the SDK
This occurs when an SDK retrying any 5xx response including non-idempotent POST. No jitter causing synchronized retry storms.
Correct retry policy:
- Retry only: idempotent operations (GET, PUT, DELETE) OR POST with
clientToken - Retry on:
429(honorRetry-After),500(ifretryable: true),503 - Never retry:
400,401,403,404,409 - Backoff: base 100ms, 2x multiplier, ±25% jitter, max 10s, max 3 attempts
6.2 Retry Storms and Missing Bulkheads
This occurs where all clients receive 429 simultaneously. All back off for exactly 2^n * 100ms. All retry at the same moment. The retry wave is as large as the original spike. I wrote previously Robust Retry Strategies for Building Resilient Distributed Systems that shows effective strategies for robust retries. For example, Netflix built Hystrix specifically to isolate downstream dependency thread pools. Slow responses in one pool cannot bleed into others. Circuit breakers open when error rates exceed thresholds, failing fast rather than queueing.
6.3 Hard Startup Dependencies
This occurs when a service cannot start unless all dependencies are reachable. During a dependency outage, no new instances can start so the deployment stalls and you cannot deploy fixes when you most need to.
Better approach: I wrote about this previously at Zero-Downtime Services with Lifecycle Management on Kubernetes and Istio, which shows safe startup and shutdown. Start despite all dependencies unavailable. Initialize connectivity lazily. Distinguish not yet ready (503 + Retry-After) from unhealthy (500). Degrade gracefully rather than refuse to start.
6.4 Missing Graceful Shutdown
This is another common anti-pattern, e.g., a pod receives SIGTERM and exits immediately, dropping in-flight requests. I have seen it caused a data loss because a locally saved data failed to synchronize with the remote server before the pod was shutdown.
Correct sequence: Stop accepting new connections -> complete in-flight requests (bounded timeout) -> flush async work -> exit. As covered in Zero-Downtime Services with Lifecycle Management, getting any stage wrong produces dropped requests during every deployment.
6.5 No Pre-Authentication Throttling
This occurs when throttling applied only after auth. An attacker sends millions of requests that exhaust authentication infrastructure before per-account quota applies.
Better approach: Lightweight rate limiting before authentication (source IP / API key prefix) as first-line defense. Per-account throttling after auth. Both layers required. Configuration updatable without deployment.
6.6 Shallow Health Checks
I have seen companies touting 99.99% availability where their /health returns 200 as long as the HTTP server is running, regardless of whether the database connection pool is exhausted or the cache is unreachable.
| Endpoint | Purpose | Checked by |
|---|---|---|
/health/live | Process alive | Kubernetes liveness probe |
/health/ready | Can handle requests | Readiness probe, load balancer |
/health/deep | Full end-to-end validation | Deployment pipeline gate |
6.7 Insufficient Metrics, SLAs, and Alerting
I wrote about From Code to Production: A Checklist for Reliable, Scalable, and Secure Deployments that shows metrics/alerting must be configured for API deployment. If you have insufficient metrics like only request count and binary error rate tracked without latency percentiles or defined SLA then diagnosing failure will be hard . For example, alerts fire at 100% error rate and the entire service is down before anyone is notified.
Better approach: Instrument every operation with request rate, error rate (4xx vs 5xx), latency at P50/P95/P99/P999, and downstream dependency health. Set alert thresholds below your SLA, e.g. if P99 SLA is 500ms, alert at 400ms.
6.8 No “Big Red Button” and Missing Emergency Rollback
This occurs when there is no fast path to revert a bad deployment. Configuration changes require a full deployment to roll back. No tested runbook.
Better approach: Feature flags togglable without deployment (tested weekly). Sub-5-minute rollback pipeline. Pre-tested load shedding with documented decision thresholds. Runbooks practiced in drills, not just read.
6.9 Backup Communication Channels Not Tested
Incident response plans rely on Slack to coordinate a Slack outage. Runbooks stored in Confluence, down when cloud IAM is broken. For example, Google’s 2017 OAuth outage logged 350M users out of devices and services. Teams expected to coordinate via Google Hangouts, which was also down. Incident coordination was hampered by the incident. Recovery took 12 hours.
6.10 Phased Deployment Anti-Patterns and Missing Automation
This occurs when you deploy globally in a single wave. Rollback criteria is “wait and see.” Canary populations too small. Rollback requires human decision-making at 3 AM. I wrote about Mitigate Production Risks with Phased Deployment that shows how phased deployment can mitigate production releases. Automated phased deployment:
- Deploy 1-5% canary
- Run automated integration tests against canary
- Monitor SLA metrics for bake period (10 minutes)
- Auto-rollback if any threshold breaches without human intervention
- Promote to next fault boundary only on clean bake
Section 7: Security, Data Privacy & Lifecycle Anti-Patterns
7.1 Missing Boundary Validation: Specs That Don’t Enforce
In this case, an OpenAPI spec exists but is not enforced at runtime and is documentation only. A proto definition marks fields as optional but the service processes requests where required fields are absent and produces undefined behavior. Input validation is implemented inconsistently in business logic rather than at the API boundary.
Better approach: Enforce the spec at the boundary. For OpenAPI/REST: Use middleware that validates every request against the OpenAPI schema before it reaches business logic. Libraries like express-openapi-validator (Node.js), connexion (Python), or API Gateway request validation do this. Every field type, pattern, range, and required constraint in the spec is automatically enforced.
# openapi.yaml — enforced at runtime, not just documentation
components:
schemas:
CreateOrderRequest:
type: object
required: [customer_id, items]
properties:
client_token:
type: string
minLength: 16
maxLength: 128
customer_id:
type: string
pattern: '^cust-[a-z0-9]{8,}$'
items:
type: array
minItems: 1
maxItems: 100
items:
$ref: '#/components/schemas/OrderItem'
For gRPC/Protobuf: Use protoc-gen-validate (PGV), a protobuf plugin that generates validation code from annotations in your .proto files:
import "validate/validate.proto";
message CreateOrderRequest {
// clientToken: optional but if present must be 16-128 printable ASCII chars
optional string client_token = 1 [(validate.rules).string = {
min_len: 16, max_len: 128
}];
// customer_id: required, must match pattern
string customer_id = 2 [(validate.rules).string = {
pattern: "^cust-[a-z0-9]{8,}$",
min_len: 1
}];
// items: required, 1-100 items
repeated OrderItem items = 3 [(validate.rules).repeated = {
min_items: 1, max_items: 100
}];
}
message OrderItem {
string product_id = 1 [(validate.rules).string.min_len = 1];
// quantity: must be positive
int32 quantity = 2 [(validate.rules).int32.gt = 0];
// price: must be non-negative
double unit_price = 3 [(validate.rules).double.gte = 0.0];
}
This enforces validation at the boundary, before your business logic runs, using the same .proto file that is your source of truth. No duplicate validation code. No inconsistency between the spec and the enforcement.
7.2 PII Data Exposure in APIs
This anti-pattern exposes PII data like full credit card numbers, SSNs, or passport numbers returned in GET responses. Email addresses and phone numbers included in audit logs and error messages. User location data exposed in list endpoints without access controls. Responses cached at the CDN layer with no consideration of the PII they contain.
Better approach: Apply data minimization at the API layer and return only the fields a caller needs and is authorized to receive. I wrote Agentic AI for Automated PII Detection: Building Privacy Guardians with LangChain and Vertex AI to show how annotations to mark sensitive fields in your schema and AI agents can be used to detect violations:
import "google/api/field_behavior.proto";
message Customer {
string customer_id = 1;
string display_name = 2;
// Sensitive: only returned to callers with PII_READ permission
// Masked in logs: shown as "****@example.com"
string email_address = 3 [
(google.api.field_behavior) = OPTIONAL,
// Custom option — your PII classification
(pii.sensitivity) = HIGH
];
// Never returned in list operations; only in GetCustomer with explicit consent
string phone_number = 4 [(pii.sensitivity) = HIGH];
// Tokenized before storage; never returned as plaintext
string payment_method_token = 5;
}
Operational controls:
- Never log full request/response bodies; use structured logging with explicit field allowlists
- Apply response field filtering at the API gateway based on caller permissions
- Scan API responses in CI/CD pipelines for PII patterns before deployment
- Ensure pagination tokens do not contain PII
- Cache keys must never contain PII; cached responses must never contain PII for a different caller
7.3 Missing Contract Testing
In this case, a service team ships an API. Client teams write integration tests against their own mock servers. The mock servers are written from the documentation, not from the actual service behavior. When the service changes, the mocks stay static. Clients discover the breaking change in production.
Consumer-driven contract testing reverses this: clients publish their expectations (the “contract” of what they call and what they expect back), and the service validates those contracts in its CI/CD pipeline. If the service changes in a way that breaks a client contract, the service’s build fails before the change is deployed.
I built an open-source framework specifically for this: api-mock-service and described in Contract Testing for REST APIs. The framework supports:
- Recording real API traffic and generating mock contracts from it (no manual mock writing)
- Replaying recorded responses in test environments
- Validating that recorded behavior matches the current service
- Contract assertions that run in CI/CD pipelines to catch regressions before deployment
- Support for REST, gRPC, and asynchronous APIs
# Contract generated from real traffic — not hand-written
contract:
name: create_order_success
method: POST
path: /v1/orders
request:
headers:
Content-Type: application/json
body:
customer_id: "{{non_empty_string}}"
items:
- product_id: "{{non_empty_string}}"
quantity: "{{positive_integer}}"
response:
status: 201
body:
order_id: "{{non_empty_string}}"
status: PENDING
created_at: "{{iso_timestamp}}"
# This contract runs against the service in CI — if CreateOrder
# changes its response shape, this test fails before deployment
Spec enforcement + contract testing = full boundary defense:
- The OpenAPI or proto spec enforces what the service accepts
- Contract tests verify what the service returns
- Together they eliminate the “it works in mocks but breaks in production” class of failures
7.4 No API Versioning Strategy
There is no version identifier, or a single v1 with no plan for v2. Or major version bumps so frequent clients cannot keep up. For example, Twitter’s v1.0 deprecation gave clients weeks, not months, and broke thousands of integrations.
Better approach: Version from day one in the URL path (/v1/, /v2/). Run old versions in parallel until usage is zero. Communicate sunset timelines with 12+ months’ notice.
7.5 Poor or Missing Documentation
Documentation covers only the happy path. No failure modes, retry semantics, or idempotency semantics documented. Field descriptions say “the order ID” rather than valid values and behavior when absent.
Documentation is a contract: every field, every failure mode, every error code must be documented. Consumer-driven contract tests are a forcing function.
7.6 Insufficient Rate Limiting and Quota Management
In this scenario, no per-account rate limits exist. Rate limits fixed in code, not configurable without deployment. One client’s traffic starves all others. Throttling responses use 500 instead of 429 Too Many Requests with Retry-After.
GitHub’s rate limiting is a reference implementation. X-RateLimit-Limit, X-RateLimit-Remaining, and X-RateLimit-Reset headers in every response allow clients to implement proactive backoff. 429 with Retry-After when the limit is hit.
7.7 Caching Without Security Consideration
Examples of this anti-pattern surfaces include a CDN cached responses by keyed only on URL, serving account A’s private data to account B. Cache stores authorization decisions without accounting for permission revocation.
Better approach: I described best practices of caches in When Caching is not a Silver Bullet. Cache keys must include all authorization context. Authorization decisions must have TTLs reflecting how quickly permission changes take effect. Cache poisoning must be in your threat model.
7.8 No API Lifecycle Management and Missing Deprecation Path
This occurs when there is no process for retiring old API versions. Deprecated endpoints have no documented migration path. Or endpoints removed with insufficient notice. For example, Twilio’s classic API deprecation was managed over 18 months with migration guides, compatibility layers, and direct client outreach.
Better approach: Collect per-endpoint, per-client usage metrics before announcing deprecation. Block new clients. Provide migration docs and tooling. 12+ months’ lead time. Monitor until zero usage confirmed.
Quick Reference: Pre-Launch Checklist
API Design Philosophy
- [ ] Spec written first (OpenAPI or proto) before any implementation code
- [ ] OpenAPI/proto schema enforced at runtime boundary (PGV, openapi-validator)
- [ ] API surface is small and composable; no UI-specific endpoints in the core API
- [ ] Resources organized in a consistent URI hierarchy under namespaces
- [ ] No bag-of-params / execute pattern; separate operations for separate actions
- [ ] Standard protocol chosen (REST, gRPC, WebSocket, SSE), no custom RPC
- [ ] Encoding chosen based on use case (protobuf binary for internal high-throughput)
- [ ] Streaming APIs use gRPC streaming or WebSocket, not polling or custom framing
Contract & Consistency
- [ ] Consistent naming vocabulary (nouns, verbs, field names, timestamps)
- [ ] Correct HTTP verbs with documented semantics
- [ ] No breaking changes without version bump
- [ ] Hyrum’s Law review: what observable behaviors exist not in the contract?
- [ ] Strict input validation on every field, every operation
Pagination & Filtering
- [ ] Pagination on all list operations before first client, not after
- [ ] Opaque, versioned, expiring, account-scoped pagination tokens
- [ ] Filter semantics documented (AND across attributes, OR within values)
Idempotency & Transactions
- [ ]
clientTokenon all create operations - [ ] Token mismatch returns 409 with conflicting resource ID
- [ ] Transaction boundaries documented
- [ ] PATCH implements partial update (field mask)
- [ ] ETag / version token for optimistic concurrency
Error Handling
- [ ] Structured error format with machine-readable codes
- [ ] No internal implementation detail in error messages
- [ ] Correct HTTP status codes; seven standard exception types
- [ ] 404 vs 403: resource existence hidden from unauthorized callers
Security & Privacy
- [ ] PII tagged in schema; data minimization applied per-endpoint
- [ ] No PII in logs, error messages, or pagination tokens
- [ ] PII scanning in CI/CD pipeline before deployment
- [ ] Cache keys include authorization context
Resilience & Operations
- [ ] Retry logic limited to idempotent or token-protected operations
- [ ] Exponential backoff with jitter; Retry-After honored
- [ ] Service starts despite all dependencies unavailable
- [ ] Graceful shutdown tested (SIGTERM -> drain -> exit)
- [ ] Pre-auth throttling + per-account quota + 429 with Retry-After
- [ ] Three-layer health checks: live / ready / deep
- [ ] Latency SLAs defined; alerts below SLA threshold
- [ ] Phased deployment with automatic metric-gated rollback
- [ ] Big Red Button identified, documented, and drill-tested
- [ ] Backup incident communication channel tested independently
Contract Testing & Lifecycle
- [ ] Contract tests generated from real traffic, run in CI/CD
- [ ] API version in URL path (v1, v2) from day one
- [ ] Documentation covers failure modes, idempotency, retry semantics
- [ ] Usage metrics collected per endpoint for lifecycle decisions
- [ ] Deprecation policy documented; sunset timelines published
Closing Thoughts
Above anti-patterns are based on my decades of experience in building and operating high traffic APIs. They share a common thread: they were invisible at design time, or the team assumed fixing them later would be cheaper. An idempotency contract is cheapest to design correctly before the first client. A spec-first approach catches URI design problems before any client builds against the wrong shape. A contract test catches breaking changes before deployment. The checklist above addresses these as a system because they compound. An unbounded response is worse with no pagination. A missing idempotency token is catastrophic with an aggressive retry policy. A leaky PII field is worse without boundary validation. Two practices matter more than any individual anti-pattern on this list:
- Spec-first design: write the contract before writing the implementation. Review it with consumers before coding starts. Use it as the source of truth for both server stubs and client SDKs.
- Contract testing: verify the contract continuously against the live service. Use recorded real traffic, not hand-written mocks. Run it in every CI/CD pipeline.
Further reading from this series:
- How Abstraction Is Killing Software: A 30-Year Journey Through Complexity
- Transaction Boundaries: The Foundation of Reliable Systems
- How Duplicate Detection Became the Dangerous Impostor of True Idempotency
- Building Robust Error Handling with gRPC and REST APIs
- Bridging HTTP and gRPC: A Standardized Approach to Header Mapping in Microservices
- The Complete Guide to gRPC Load Balancing in Kubernetes and Istio
- Zero-Downtime Services with Lifecycle Management on Kubernetes and Istio
- Robust Retry Strategies for Building Resilient Distributed Systems
- Fault Tolerance in Microservices
- From Code to Production: A Checklist for Reliable, Scalable, and Secure Deployments
- Contract Testing for REST APIs · github.com/bhatti/api-mock-service
- Agentic AI for Automated PII Detection


