Building and maintaining distributed systems is challenging due to complex intricacies of production environments, configuration differences, data and traffic scaling, dependencies on third-party services, and unpredictable usage patterns. These factors can lead to outages, security breaches, performance degradation, data inconsistencies, and other operational issues that may negatively impact customers [See Architecture Patterns and Well-Architected Framework]. These risks can be mitigated with phased rollouts with canary releases, leveraging feature flags for controlled feature activation, and ensuring comprehensive observability through monitoring, logging, and tracing are crucial. Additionally, rigorous scalability testing, including load and chaos testing, and proactive security testing are necessary to identify and address potential vulnerabilities. The use of blue/green deployments and the ability to quickly roll back changes further enhance the resilience of your system. Beyond these strategies, fostering a DevOps culture that emphasizes collaboration between development, operations, and security teams is vital. The following checklist serves as a guide to verify critical areas that may go awry when deploying code to production, helping teams navigate the inherent challenges of distributed systems.
Build Pipelines
Separate Pipelines: Create distinct CI/CD pipelines for each microservice, including infrastructure changes managed through IaC (Infrastructure as Code). Also, set up a separate pipeline for config changes such as throttling limits or access policies.
Securing and Managing Dependencies: Identify and address deprecated and vulnerable dependencies during the build process and ensure third party dependencies are vetted and hosted internally.
Build Failures: Verify build pipelines with comprehensive suite of unit and integration tests, and promptly resolve any flaky tests caused by concurrency, networking, or other issues.
Automatic Rollback: Automatically roll back changes if sanity tests or alarm metrics fail during the build process.
Phased Deployments: Deploy new changes in phases gradually across multiple data centers using canary testing with adequate baking period to validate functional and non-functional behavior. Immediately roll back and halt further deployments if error rates exceed acceptable thresholds [See Mitigate Production Risks with Phased Deployment].
Avoid Risky Deployments: Deploy changes during regular office hours to ensure any issues can be promptly addressed. Avoid deploying code during outages, availability issues, when 20%+ hosts are unhealthy, or during special calendar days like holidays or peak traffic periods.
IAM Best Practices: Follow IAM best practices such as using multi-factor authentication (MFA), regularly rotating credentials and encryption keys, and implementing role-based access control (RBAC).
Authentication and Authorization: Verify that authentication and authorization policies adhere to the principle of least privilege.
Defense in Depth: Implement admission controls at every layer including network, application and data.
Vulnerability & Penetration Testing: Conduct security tests targeting vulnerabilities based on the threat model for the service’s functionality.
Encryption: Implement encryption at rest and in-transit policies.
Test Plan: Ensure test plan accurately simulate real use cases, including varying data sizes and read/write operations.
Scalability Assessment: Conduct load tests to assess the scalability of both your primary service and its dependencies.
Testing Strategies: Conduct load tests using both mock dependent services and real services to identify potential bottlenecks.
Resource Monitoring: During load testing, monitor for excessive logs, events, and other resources, and assess their impact on latency and potential bottlenecks.
Autoscaling Validation: Validate on-demand autoscaling policies by testing them under increased load conditions.
Service Unavailability: Test scenarios where the dependent service is unavailable, experiences high latency, or results in a higher number of faults.
Monitoring and Alarms: Ensure that monitoring, alarms and on-call procedures for troubleshooting and recovery are functioning as intended.
Canary Testing and Continuous Validation
This strategy involves deploying a new version of a service to a limited subset of users or servers with real-time monitoring and validation before a full deployment.
Canary Test Validation: Ensure canary tests based on real use cases and validate functional and non-functional behavior of the service. If a canary test fails, it should automatically trigger a rollback and halt further deployments until the underlying issues are resolved.
Continuous Validation: Continuously validate API behavior and monitor performance metrics such as latency, error rates, and resource utilization.
Edge Case Testing: Canary tests should include common and edge cases such as large request size.
Resilience and Reliability
Idle Timeout Configuration: Set your API server’s idle connection timeout slightly longer than the load balancer’s idle timeout.
Load Balancer Configuration: Ensure the load balancer evenly distributes requests among servers using a round-robin method and avoids directing traffic to unhealthy hosts. Prefer this approach over least-connections method.
Backward Compatibility: Ensure API changes are backward compatible that are verified through Contract-based testing, and forward compatible by ignoring unknown properties.
Correlation ID Injection: Inject a Correlation ID into incoming requests, allowing it to be propagated through all dependent services for logging and tracing purposes.
Graceful Degradation: Implement graceful degradation to operate in a limited capacity even when dependent services are down.
Idempotent APIs: Ensure APIs especially those that create resources are implemented with idempotent behavior.
Request Validation: Validate all request parameters and fail fast any requests that are malformed, improperly sized, or contain malicious data.
Single Points of Failure: Eliminate single points of failure, bottlenecks, and dependencies on shared resources to minimize the blast radius.
Cold Start Optimization: Ensure that cold service startup time is limited to just a few seconds.
Performance Optimization
Latency Reduction: Identify and optimize parts of the system with high latency, such as database queries, network calls, or computation-heavy tasks.
Pagination: Implement pagination for list operations, ensuring that pagination tokens are account-specific and invalid after the query expiration time.
Thread and Queue Management: Set up the number of threads, connections, and queuing limits. Generally, the queue size should be proportional to the number of threads and kept small.
Resource Optimization: Optimize resource usage (e.g., CPU, memory, disk) by tuning configuration settings and optimizing code paths to reduce unnecessary overhead.
Caching Strategy: Review and optimize caching strategies to reduce load on databases and services, ensuring that cached data is used effectively without becoming stale.
Database Indexing: Regularly review and update database indexing strategies to ensure queries run efficiently and data retrieval is optimized.
Web Application Firewall: Consider implementing Web application firewall integration with your services’ load balancers to enhance security, traffic management and protect against distributed denial-of-service (DDoS). Confirm WAF settings and assess performance through load and security testing.
Testing Throttling Limits: Test throttling and rate limiting policies in the test environment.
Granular Limits: Implement tenant-level rate limits at the API endpoint level to prevent the noisy neighbor problem, and ensure that tenant context is passed to downstream services to enforce similar limits.
Aggregated Limits: When setting rate limits for both tenant-level and API-levels, ensure that the tenant-level limits exceed the combined total of all API limits.
Graceful degradation: Cache throttling and rate limit data to enable graceful degradation with fail-open if datastore retrieval fails.
Unauthenticated requests: Minimize processing for unauthenticated requests and safeguard against large payloads and invalid parameters.
Dependent Services
Timeout and Retry Configuration: Configure connection and request timeouts, implement retries with backoff and circuit-breaker, and set up fallback mechanisms for API clients with circuit breakers when connecting to dependent services.
Monitoring and Logging: Monitor and log failures and latency of dependent services and infrastructure components such as load balancers, and trigger alarms when they exceed the defined SLOs.
Scalability of Dependent Service: Verify that dependent services can cope with increased traffic loads during scaling traffic.
Compliance and Privacy
Below are some best practices for ensuring compliance:
Compliance: Ensure all data compliance to local regulations such as California Consumer Privacy Act (CCPA), General Data Protection Regulation (GDPR), Health Insurance Portability and Accountability Act (HIPAA), and other privacy regulations [See NIST SP 800-122].
Privacy: Identify and classify Personal Identifiable Information (PII), and ensure all data access is protected through Identity and Access Management (IAM) and compliance based PII policies [See DHS Guidance].
Privacy by design: Incorporate privacy by design principles into every stage of development to reduce the risk of data breaches.
Audit Logs: Maintain logs for all administrative actions, access to sensitive data and changes to critical configurations for compliance audit trails.
Monitoring: Continuously monitor of compliance requirements to ensure ongoing adherence to regulations.
Data Management
Data Consistency: Evaluate requirements for the data consistency such as strong and eventual consistency. Ensure data is consistently stored across multiple data stores, and implement a reconciliation process to detect any inconsistencies or lag times, logging them for monitoring and alerting purposes.
Schema Compatibility: Ensure data schema changes are both backward and forward compatible by implementing a two-phase release process. First, deploy an intermediate version that can read the new schema format but continues to write in the old format. Once this intermediate version is fully deployed and stable, proceed to roll out the new code that writes data in the new format.
Retention Policies: Establish and verify data retention policies across all datasets.
Unique Data IDs: Ensure data IDs are unique and do not overflow especially when using 32-bit or smaller integers.
Auto-scaling Testing: Test auto-scaling policies triggered by traffic spikes, and confirm proper partitioning/sharding across scaled resources.
Data Cleanup: Clean up stale data, logs and other resources that have expired or are no longer needed.
Divergence Monitoring: Implement automated processes to identify divergence from data consistency or high lag time with data synchronization when working with multiple data stores.
Data Migration Testing: Test data migrations in isolated environments to ensure they can be performed without data loss or corruption.
Backup and Recovery: Test backup and recovery processes to confirm they meet defined Recovery Point Objective (RPO) and Recovery Time Objective (RTO) targets.
Data Masking: Implement data masking in non-production environments to protect sensitive information.
Stale Cache Handling: Handle stale cache data by setting appropriate time-to-live (TTL) values and ensuring cache invalidation is correctly implemented.
Cache Preloading: Pre-load cache before significant traffic spikes so that latency can be minimized.
Cache Validation: Validate the effectiveness of your cache invalidation and clearing methods.
Negative Cache: Implement caching behavior for both positive and negative use cases and monitor the cache hits and misses.
Peak Traffic Testing: Assess service performance under peak traffic conditions without caching.
Bimodal Behavior: Minimize reliance on caching to reduce the complexity of bimodal logic paths.
Disaster Recovery
Backup Validation: Regularly test backup and recovery processes to ensure they meet defined Recovery Point Objective (RPO) and Recovery Time Objective (RTO) targets.
Failover Testing: Test failover procedures for critical services to validate that they can seamlessly switch over to backup systems or regions without service disruption.
Chaos Engineering: Incorporate chaos engineering practices to simulate disaster scenarios and validate the resilience of your systems under failure conditions.
Configuration and Feature-Flags
Configuration Storage: Prefer storing configuration changes in a source code repository and releasing them gradually through a deployment pipeline including tests for verification.
Configuration Validation: Validate configuration changes in a test environment before applying them in production to avoid misconfigurations that could cause outages.
Feature Management: Use a centralized feature flag management system to maintain consistency across environments and easily roll back features if necessary.
Testing Feature Flags: Test every combination of feature flags comprehensively in both test and pre-production environments before the release.
Observability
Observability allows instrumenting systems to collect and analyze logs metrics and trace for monitoring system performance and health. Below are some best practices for monitoring, logging, tracing and alarms [See USE and RED methodologies for Systems Performance]:
Monitoring
System Metrics: Monitor key system metrics such as CPU usage, memory usage, disk I/O, network latency, and throughput across all nodes in your distributed system.
Application Metrics: Track application-specific metrics like request latency, error rates, throughput, and the performance of critical application functions.
Server Faults and Client Errors: Monitor metrics for server-side faults (5XX) and client-side errors (4XX) including those from dependent services.
Service Level Objectives (SLOs): Define and monitor SLOs for latency, availability, and error rates. Use these to trigger alerts if the system’s performance deviates from expected levels.
Health Checks: Implement regular health checks to assess the status of services and underlying infrastructure, including database connections and external dependencies.
Dashboards: Use dashboards to display real-time and historical graphs for throughput, P9X latency, faults/errors, data size, and other service metrics, with the ability to filter by tenant ID.
Logging
Structured Logging: Ensure logs are structured and include essential information such as timestamps, correlation IDs, user IDs, and relevant request/response data.
Log API entry and exits: Log the start and completion of API invocations along with correlation IDs for tracing purpose.
Log Retention: Define and enforce log retention policies to avoid storage overuse and ensure compliance with data regulations.
Log Aggregation: Use log aggregation tools to centralize logs from different services and nodes, making it easier to search and analyze them in real-time.
Log Levels: Properly categorize logs (e.g., DEBUG, INFO, WARN, ERROR) and ensure sensitive information (such as PII) is not logged.
Tracing
Distributed Tracing: Implement distributed tracing to capture end-to-end latency and the flow of requests across multiple services. This helps in identifying bottlenecks and understanding dependencies between services.
Trace Sampling: Use trace sampling to manage the volume of tracing data, capturing detailed traces for a subset of requests to balance observability and performance.
Trace Context Propagation: Ensure that trace context (e.g., trace IDs, span IDs) is propagated across all services, allowing complete trace reconstruction.
Alarms
Threshold-Based Alarms: Set up alarms based on predefined thresholds for key metrics such as CPU/memory/disk/network usage, latency, error rates, throughput, starvation of threads and database connections, etc. Ensure that alarms are actionable and not too sensitive to avoid alert fatigue.
Anomaly Detection: Implement anomaly detection to identify unusual patterns in metrics or logs that might indicate potential issues before they lead to outages.
Metrics Isolation: Keep metrics and alarms from continuous canary tests and dependent services separate from those generated by real traffic.
On-Call Rotation: Ensure that alarms trigger appropriate notifications to on-call personnel, and maintain a rotation schedule to distribute the on-call load among team members.
Runbook Integration: Include runbooks with alarms to provide on-call engineers with guidance on how to investigate and resolve issues.
Rollback and Roll Forward
Rolling back involves redeploying a previous version to undo unwanted changes. Rolling forward involves pushing a new commit with the fix and deploying it. Here are some best practices for rollback and roll forward:
Immutable infrastructure: Implement immutable infrastructure practices so that switching back to a previous instance is simple.
Automated Rollbacks: Ensure rollbacks are automated so that they can be executed quickly and reliably without human intervention.
Rollback Testing: Test rollback changes in a test environment to ensure the code and data can be safely reverted.
Critical bugs: To prevent customer impact, avoid rolling back if the changes involve critical bug fixes or compliance and security-related updates.
Schema changes: If the new code introduced schema changes, confirm that the previous version can still read and update the modified data.
Roll Forward: Use rolling forward when rollback isn’t possible.
Avoid rushing Roll Forwards: Avoid roll forward if other changes have been committed that still being tested.
Testing Roll Forwards: Make sure the new changes including configuration updates are thoroughly tested before the roll forward.
Documentation and Knowledge Sharing
Operational Runbooks: Maintain comprehensive runbooks that document operational procedures, troubleshooting steps, and escalation paths for common issues.
Postmortems: Conduct postmortems after incidents to identify root causes, share lessons learned, and implement corrective actions to prevent recurrence.
Knowledge Base: Build and maintain a knowledge base with documentation on system architecture, deployment processes, testing strategies, and best practices for new team members and ongoing reference.
Training and Drills: Regularly train the team on disaster recovery procedures, runbooks, and incident management. Conduct disaster recovery drills to ensure readiness for actual incidents.
Continuous Improvement
Feedback Loops: Establish feedback loops between development, operations, and security teams to continuously improve deployment processes and system reliability.
Metrics Review: Regularly review metrics, logs, and alarms to identify trends, optimize configurations, and enhance system performance.
Automation: Automate repetitive tasks, such as deployments, monitoring setup, and incident response, to reduce human error and increase efficiency.
Conclusion
Releasing software in distributed systems presents unique challenges due to the complexity and scale of production environments, which cannot be fully replicated in testing. By adhering to the practices outlined in this checklist—such as canary releases, feature flags, comprehensive observability, rigorous scalability testing, and well-prepared rollback mechanisms—you can significantly reduce the risks associated with deploying new code. A strong DevOps culture, where development, operations, and security teams work closely together, ensures continuous improvement and adaptability to new challenges. By following this checklist and fostering a culture of collaboration, you can enhance the stability, security, and scalability of each release for your platform.
I recently read “The Engineering Executive’s Primer“, a comprehensive guide for helping engineering leaders navigate challenges like strategic planning, effective communication, hiring, and more. Here are the key highlights from the book, organized by chapter:
1. Getting the Job
This chapter focuses on securing an executive role and successfully navigating the executive interview process.
Why Pursue an Executive Role?
The author suggests reflecting on this question personally and then reviewing your thoughts with a few peers or mentors to gather feedback.
One of One
While there are general guidelines for searching an executive role, each executive position and the process are unique and singular.
Finding Internal Executive Roles
Finding an executive role internally can be challenging, as companies often look for executives with skill sets that differ from those currently in place and peers may feel slighted for not getting the role.
Finding External Executive Roles
The author advises leveraging your established network to find roles before turning to executive recruiters, as many highly respected executive positions often never make it to recruiting firms or public job postings.
Interview Process
The interview process for executive roles is generally a bit chaotic and the author recommends STAR method to keep answers concise and organized. Other advice includes:
Ask an interviewer for feedback on your presentation before the session.
Ask what other candidates have done that was particularly well received.
Make sure to follow the prompt directly.
Prioritize where you want to spend time in the presentation.
Leave time for questions.
Negotiating the Contract
The aspects of negotiation include:
Equity
Equity acceleration
Severance package
Bonus
Parental leave
Start date
Support
Deciding to Take the Job
The author recommends following steps before finalizing your decision:
Spend enough time with the CEO
Speak to at least one member of the board
Speak with members of the executive team
Speak with finance team to walk through the recent P&L statement
Make sure they answered your questions
Reasons of previous executive departure
2. Your First 90 Days
This chapter emphasizes the importance of prioritizing learning, building trust, and gaining a deep understanding of the organization’s health, technology, processes, and overall operations.
What to Lean First?
The author offers following priorities as a starting place:
How does the business work?
What defines the culture and its values? How recent key decisions were made?
How can you establish healthy relationships with peers and stakeholders?
Is the Engineering team executing effectively on the right work?
Is technical quality high?
Is it a high-morale, inclusive engineering team?
Is the place sustainable for the long haul?
Making the Right System Changes
Senior leaders must understand the systems first and then make durable improvements towards organization goals by making right changes. The author cautions against judging without context and reminiscing about past employers.
You Only Learn When You Reflect
The author recommends learning well through reflection and ask for help using 20-40 rule (spend at least 20-minutes but no more than 40-minutes before asking for help).
Tasks for Your First 90 Days
Learning and building trust
Ask your manager to write their explicit expectations for you
Figure out if something is really wrong and needs immediate attention
Go on a listening tour
Set up recurring 1:1s and skip-level meetings
Share what you’re observing
Attend routine forums
Shadow support tickets
Shadow customer/partner meetings
Find business analytics and learn to query the data
Create an External Support System
The author recommends building a network of support of folks in similar roles, getting an executive coach and creating a space for self-care.
Managing Time and Energy
Understanding organization Health and Process
Document existing organizational processes
Implement at most one or two changes
Plan organizational growth for next year
Set up communication pathways
Pay attention beyond the product engineering roles within your organization
Spot check organizational inclusion
Understanding Hiring
Track funnel metrics and hiring pipelines
Shadow existing interviews, onboarding and closing calls
Decide whether an overhaul is ncessary
Identify three or fewer key missing roles
Offer to close priority candidates
Kick off Engineering brand efforts
Understanding Systems of Execution
Figure out whether what’s happening now is working and scales
Establish internal measures of Engineering velocity
Establish external measures of Engineering velocity
Consider small changes to process and controls
Understanding the Technology
Determine whether the existing technology is effective
Learn how high-impact technical decisions are made
Build a trivial change and deploy it
Do an on-call rotations
Attend incident reviews
Record the technology history
Document the existing technology strategy
3. Writing Your Engineering Strategy
The defines an Engineering strategy document as follows:
The what and why of Engineering’s resource allocation against its priorities
The fundamental rules that Engineering’s team must abide by
The author recommends following risk management process for writing an Engineering strategy:
Commit to writing this yourself!
Focus on writing for the Engineering team’s leadership (executive and IC).
Identify the full set of stakeholders you want to align the strategy with.
From within that full set of stakeholders, identify 3-5 who will provide early rapid feedback.
Write your diagnosis section.
Write your guiding policies.
Now share the combined diagnosis and guiding policies with the full set of stakeholders.
Write the coherent actions.
Identify individuals who most likely will disagree with the strategy.
Share the written strategy with the Engineering organization.
Finalize the strategy, send out an announcement and commit to reviewing the strategy’s impact in two months.
When to Write the Strategy
The author recommends asking three questions to ask before getting started:
Are you confident in your diagnosis or do you trust the wider Engineering organization to inform your diagnosis?
Are you willing and able to enforce the strategy?
Are you confident the strategy will create leverage?
Dealing with Missing Company Strategies
Many organizations have Engineering strategies but they are not written. The author recommends focusing on non-Engineering strategies that are most relevant to Engineering and documenting their strategies yourself. Some of the questions that should be in these draft strategies include:
What are the cash-flow targets?
What is the investment thesis across functions?
What is the business unit structure?
Who are products’ users?
How will other functions evaluate success over the next year?
What are most important competitive threats?
What about the current strategy is not working?
Establishing the Diagnosis
The author offers following advice on writing an effective diagnosis:
Don’t skip writing the diagnosis.
When possible, have 2-3 leaders diagnose independently.
Diagnose with each group of stakeholder skeptics.
Be wary when your diagnosis is particular similar to that of your previous roles.
Structuring Your Guiding Policies
The author recommends starting with following key questions:
What is the organization’s resource allocation against its priorities (And why)?
What are the fundamental rules that all teams must abide by?
How are decisions made within Engineering?
Maintaining Your Guiding Policies’ Altitude
To ensure your strategy is operating at the right altitude, the author recommends asking if each of your guiding policies is applicable, enforced and creates leverage with multiplicative impact.
Selecting Coherent Actions
The author recommends three major categories of coherent actions:
Enforcement
Escalations
Transitions to the new state
4. How to Plan
This chapter discusses the default planning process, phases of planning and exploring frequent failure modes.
The Default Planning Process
Most organizations have yearly, quarterly or mid-year documented planning process where teams manage their own execution against the quarter and have a monthly execution review.
Planning’s Three Discrete Phases
Effective planning process requires doing following actions well:
Set your company’s resource allocation, across functions, as documented in an annual financial plan.
Refresh your Engineering strategy’s resource allocation, with a particular focus on Engineering’s functional portfolio allocation between functional priorities and business priorities.
Partner with your closes cross-functional partners to establish a high-level quarter or half roadmap.
Phase 1: Establishing Your Financial Plan
The financial plan includes three specific documents:
A P&L statement showing revenue and cost, broken own by business line and function.
A budget showing expenses by function, vendors, and headcount.
A headcount plan showing the specific roles in the organization.
The Reasoning behind Engineering’s Role in the Financial Plan
The author recommends segmenting Engineering expenses by business line into three specific buckets:
Headcount expenses within Engineering
Production operating costs
Development costs
Why should Financial Planning be an Annual Process?
Adjusting your financial plan too frequently makes it impossible to grade execution.
Making significant adjustments to your financial plan requires intensive activity.
Like all good constraints, if you make the plan durable, then it will focus teams on executing effectively.
Attributing Costs to Business Units
Attributions get messy as you dig in so author recommends a flexible approach with Finance.
Why can Financial Planning be so Contentious?
The author recommends escalation with CEO if financial planning becomes contentious.
Should Engineering Headcount Growth Limit Company Headcount Growth?
The author recommends constraining overall headcount growth based on their growth rate for Engineering.
Incoming Organizational Structure
Divide your total headcount into teams of eight with a manager and a mission.
Group those teams into clusters of four to six with a focus area.
Continue recursively grouping until you get down to 5-7 groups, which will be your direct reports.
Aligning the Hiring Plan and Recruiting Bandwidth
The author recommends comparing historical recruiting capacity against the current hiring plan.
Phase 2: Determining Your Functional Portfolio Allocation
This phase involves allocating the functional portfolio and deciding how much engineering capacity should be dedicated to stakeholder requests versus internal priorities each month over the next year. The author recommends following approach:
Review full set of Engineering investments, their impact and the potential investment.
Update this list on a real-time basis as work completes.
As the list is updated, revise target steady-state allocation to functional priorities.
Spot fixing the large allocations that are not returning much impact.
Why do we need Functional Portfolio Allocation?
The functional planning is best done by the responsible executive and team but you can do it in partnership with your Engineering leadership. The author recommends adding compliance, security, reliability into the functional planning process.
Keep the Allocation Fairly Steady
The author recommends continuity and narrow changes over continually pursuing an ideal allocation. This approach minimizes disruption and avoids creating zero-sum competition with peers.
Be Mindful of Allocation Granularity
Using larger granularity empowers teams to make changes independently, while more specific allocations to specific teams will require greater coordination.
Don’t Over-index on Early Results
Commit to a fixed investment in projects until they reach at least one inflection point in their impact curve.
Phase 3: Agreeing on the Roadmap
The author highlights key issues that lead to roadmapping failures:
Roadmapping with Disconnected Planners
When roadmap is not aligned with all stakeholders such as Sales and Marketing.
Roadmapping Concrete and Unscoped Work
During planning process, executives may ask for new ideas, but these are often unscoped and unproven. The author suggests establishing an agreed-upon allocation between scoped and unscoped initiatives, and maintaining a continuous allocation for validating projects.
Roadmapping in Too Much Detail
The author references Melissa Perri, who recommends against roadmapping that is focused narrowly on project to-do items rather than on desired outcome.
Timeline for Planning Processes
Annual budget should be prepared at the end of the prior year.
Functional planning should occur on a rolling basis throughout the year.
Quarterly planning should occur in the several weeks proceeding each quarter.
Pitfalls to Avoid
Planning as ticking checkboxes
Planning is a ritual rather than part of doing work.
Planning is focused on format rather than quality.
Planning as inefficient resource allocator
Planning creates a budget, then ignores it.
Planning rewards the least efficient organization.
Planning treats headcount as a universal curve – when focused on rationalizing heacount rather than most important work.
Planning as rewarding shiny projects
Planning is anchored on work the executive team finds most interesting.
Planning only accounts for cross-functional requests.
Planning as diminishing ownership
Planning is narrowly focused on project prioritization rather than necessary outcome.
Planning generates new projects.
5. Creating Useful Organizational Values
This chapter delves into organizational values, exploring how to establish them and assess their effectiveness.
What Problems Do Values Solve?
Values increase cohesion across the new and existing team as the organization grows.
Formalize cultural changes so it persists over time.
Prevent conflict when engineers disagree on existing practices and patterns.
Should Engineering Organization Have Values?
Some values aren’t as relevant outside of Engineering and other values might work well for an entire company.
What Makes a Value Useful?
Reversible: It can be rewritten to have a different or opposite perspective without being nonsensical.
Applicable: It can be used to navigate complex, real scenarios, particularly when making trade-offs.
Honest: It accurately describe real behavior.
How are Engineering Values Distinct from a Technology Strategy?
Some guiding principles from an engineering strategy might resemble engineering values, but guiding principles typically address specific circumstances.
When and How to Roll Out Values
The author advises focusing on honest values and rolling them out gradually by collaborating with stakeholders, testing, and iterating as needed. The author also recommends integrating values into the hiring process, onboarding, promotions and meetings.
Some Values I’ve Found Useful
The author shares some of the values:
Create capacity (rather than capture it).
Default to vendors unless it’s our core competency.
Follow existing patterns unless there’s a need for order of magnitude improvements.
Optimize for the [whole, business unit, team].
Approach conflict with curiosity.
6. Measuring Engineering Organizations
This chapter focuses on measuring Engineering organizations to build software more effectively.
Measuring for Yourself
The author recommends following buckets:
Measure to Plan – track the number of shipped projects by team and their impact.
Measure to Operate – track the number of incidents, downtime, latency, cost of APIs.
Some things are difficult to measure, so only measure those if you will incorporate that data into your decision making.
Some things are easy to measure, so measure those to build trust with your stakeholders.
Whenever possible, only take on one new measurement task at a time.
Antipatterns
Focusing on measurement when the bigger issue is a lack of trust.
Letting perfect be the enemy of good.
Using optimization metrics to judge performance.
Measuring individuals rather than teams.
Worrying too much about measurements being misused.
Deciding alone rather than in community.
Building Confidence in Data
Review the data on a weekly cadence.
Maintain a hypothesis for why the data changes.
Avoid spending too much time alone with the data.
Segmenting data to capture distinct experiences.
Discuss how the objective measurement corresponds with the subjective experience.
7. Participating in Mergers and Acquisitions
This chapter explores the incentives for acquiring another company, developing a shared vision, and the processes involved in engineering evaluation and integration.
Complex Incentives
Mergers and acquisitions often involve miscommunication about the technology being acquired and its integration or replacement within the existing stack. This can lead to misaligned incentives, such as the drive to increase revenue if the integration process is overly complex.
Developing a Shared Perspective
The author recommends following tools to evaluate an acquisition:
Business strategy
Acquisition thesis
Engineering evaluation
Business Strategy
The author recommends asking following questions:
What are your business lines?
What are your revenue and cash-flow expectations for each business line?
How do you expect M&A to fit into these expectations?
Are you pursuing acquihires, product acquisitions or business acquisitions?
What kinds and sizes of M&A would you consider?
Common M&Q strategies include:
Acquring revenue or users for your core business.
Entering new business lines via acquisition.
Driving innovation by acquiring startups in similar spaces.
Reducing competition.
Acquisition Thesis
Acquisition thesis is how a particular fits into your company’s business strategy including product capabilities, intellectual property, revenue, cash flow and other aspects.
Engineering Evaluation
The author recommends following approach:
Create a default template of topics and questions to cover in every acquisition.
For each acquisition, for that template and add specific questions for validation.
For each question or topic, ask the Engineering contact for supporting material.
After reviewing those materials, schedule discussion with the Engineering contact for all yet-to-be-validated assumptions.
Run the follow-up actions.
Sync with the deal team on whether it makes sense to move forward.
Potentially interview a few select members of the company to be acquired.
Recommended Topics for an Engineering Evaluation Template
Product implementation
Intellectual property
Security
Compliance
Integration mismatches
Costs and scalability
Engineering culture
Making an Integration Plan
The author recommends following approach:
Commit to running the acquired stack “as is” for first six months and consolidate technologies wherever possible.
Bring the acquired Engineering team over and combine vertical teams.
Be direct and transparent with any senior leaders about roles where they could step in.
Three important questions to work through are:
How will you integrate the technology?
How will you integrate the teams?
How will you integrate the leadership?
Dissent Now or Forever Hold Your Peace
The author recommends anchoring feedback to the company’s goals rather than Engineering’s.
8. Developing Leadership Styles
This chapter covers leadership styles and how to balance across those styles.
Why Executives Need Several Leadership Styles
The author recommends working with the policy as it empowers the organization to move quickly but you still need to guide operations to handle exceptions.
Leading with Policy
It involves establishing a documented and consistent process for decision-making such as determining promotions. The core mechanics are:
Identify a decision that needs to be made frequently.
Examine how decisions are currently being made and structure your process around the most effective decision-makers.
Document that methodology into a written policy with feedback from the best decision makers.
Roll out the policy.
Commit to revisiting the policy with data after a reasonable period.
Leading from Consensus
It involves gathering the relevant stakeholders to collaboratively identify a unified approach to addressing the problem. The core mechanics include:
It is specially applicable when there are many stakeholders and none of them has the full and relevant context.
Evaluate whether it’s important to make a good decision (one-way vs two-way).
Identify the full set of stakeholders to include the decision.
Write a framing document capturing the perspectives that are needed from other stakeholders.
Identify a leader to decide how group will work together on the decision and deadline for the decision.
Follow that leader’s direction on building consensus.
Leading with Conviction
It involves absorbing all relevant context, carefully considering the trade-offs, and making a clear, decisive choice. The core mechanics include:
Identify an important decision to make a high-quality decision.
Figure out the individuals with the most context and deep dive them to build a mental model of the problem space.
Pull that context into a decision that you write down.
Test the decision widely with folks who have relevant context.
Tentatively make the decision that will go into effect a days in the future.
Finalize the decision after your timeout and move forward to execution.
In order to show how you reach the decision, write down your decision making process.
Development
The author recommends following steps to get comfortable with leadership styles:
Set aside an hour to collect the upcoming problems once a month.
Identify a problem that might require using a style that you don’t use frequently.
Do a thought exercise of solving that scenario using that leadership style.
Review your thoughts exercise with someone.
Think about how scenario can be solved using a style you’re more comfortable with.
If the alternative isn’t much worse and stakes aren’t exceptionally high, then use the style you’re less comfortable with.
9. Managing Your Priorities and Energy
This chapter discusses prioritization, energy management and being flexible.
“Company, Team, Self” Framework
The author suggests using this framework to ensure engineers don’t create overly complex software solely for career progression but also acknowledges that engineers can become demotivated if they’re not properly recognized for addressing urgent issues.
Energy Management is Positive-Sum
Managers may get energy from different activities such as writing software, mentoring, optimizing existing systems, etc. However, energizing work needs to avoid creating problems for other teams.
Eventual Quid Pro Quo
The author cautions against becoming de-energized or disengaged in any particular job and offers “eventual quid pro quo” framework:
Generally, prioritize company and team priorities over my own.
If getting de-energized, prioritize some energizing work.
If the long-term balance between energy and priorities can’t be achieved, work on solving it.
10. Meetings for an Effective Engineering Organization
This chapter digs into the need of meetings and how to run meetings effectively.
Why Have Meetings?
Meetings help distribute context down the reporting hierarchy, communicate culture and surface concerns from the organizations.
Six Essential Meetings
Weekly Engineering Leadership Meeting
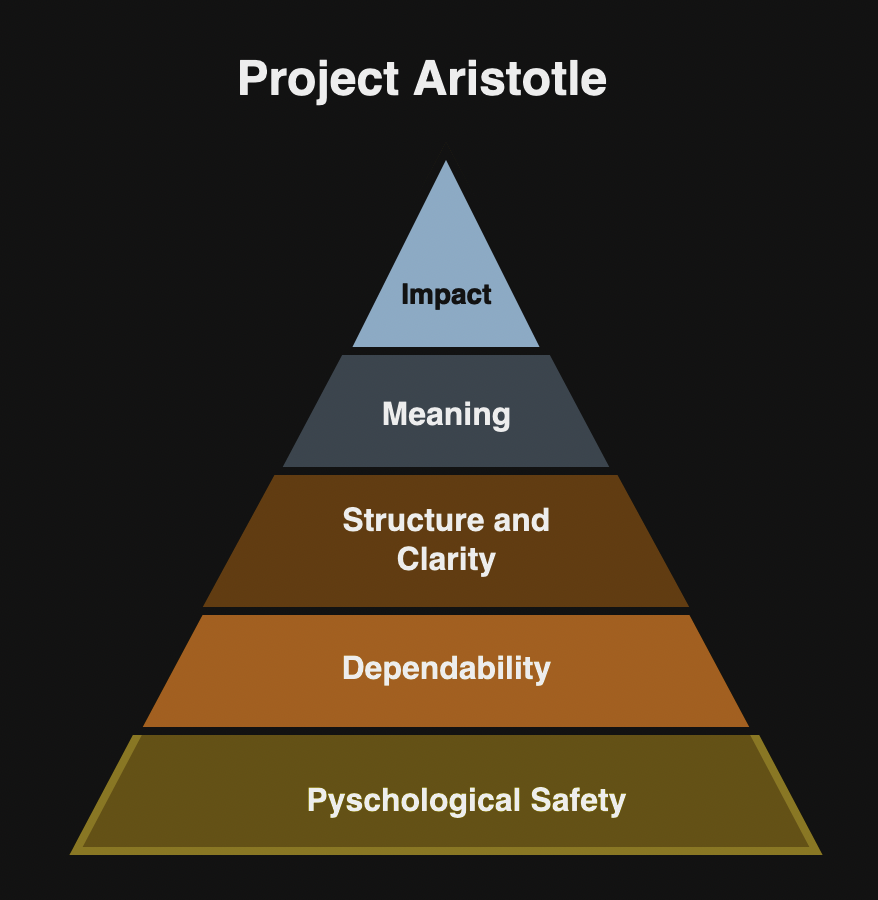
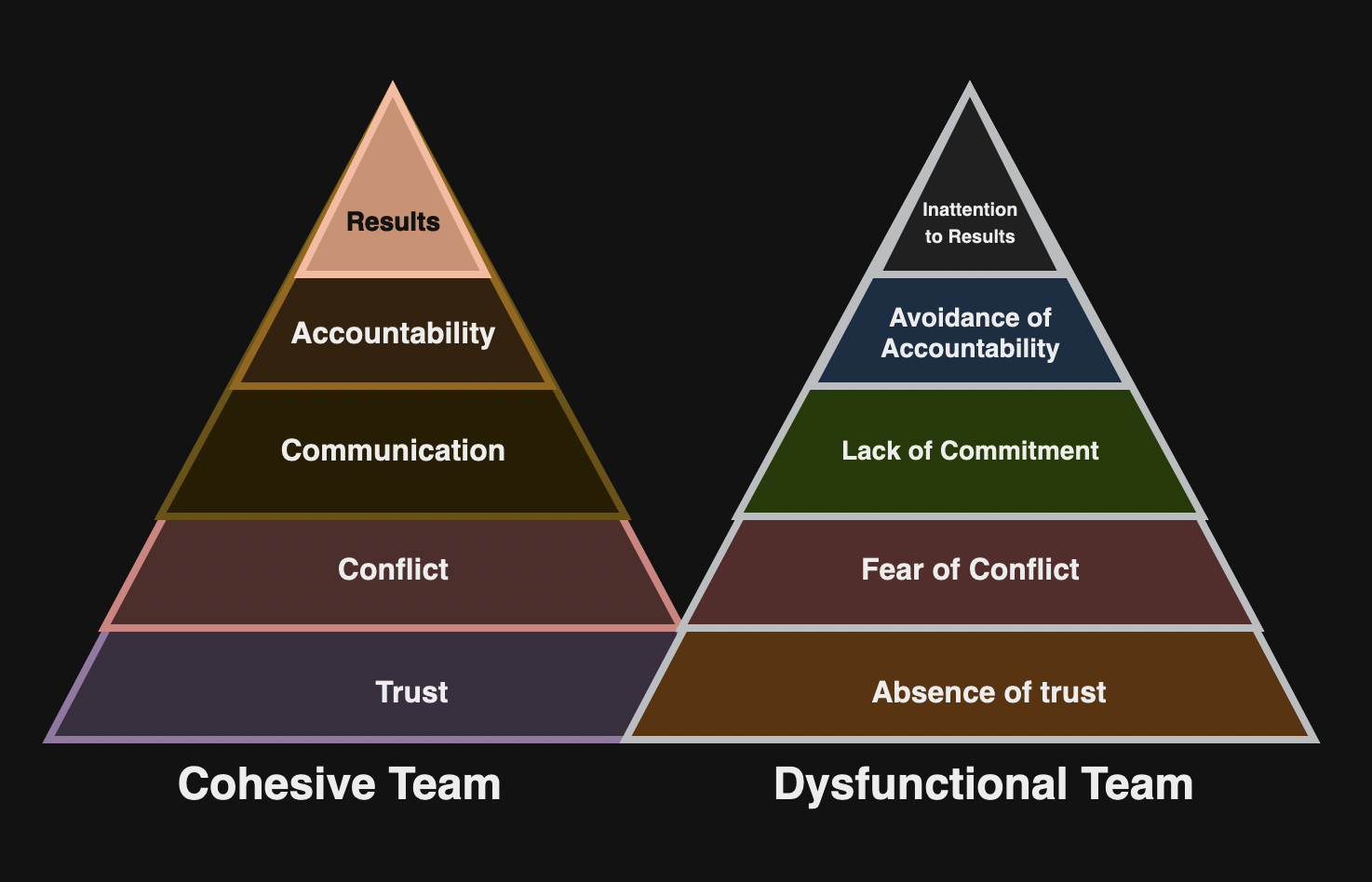
This meeting is a working session for your leadership team to accomplish things together. It allows teams to share context with others and support each other with a “first team” (See The Five Dysfunctions of a Team). Authors offers following suggestions:
Include direct reports and key partners.
Maintain a running agenda in a group-editable document.
Meet weekly.
Weekly Tech Spec Review and Incident Review
This meeting is a weekly session for discussing any new technical specs or incidents. The author offers following suggestions:
All reviews should be anchored to a concise, clearly written document.
Reading the written document should be a prerequisite to providing feedback on it (start with 0 minutes to read the document).
Good reviews are anchored to feedback from the audience and discussion between the author and the audience.
Document a simple process for getting your incident writeup or tech spec scheduled.
Measure the impact of these review meetings by monitoring participation.
Find dedicated owner for each meeting.
Monthlies with Engineering Managers and Staff Engineers
The format of this meeting includes:
Ask each member to share something they’re working on or worried about.
Present a development topic like P&L statement.
Q&A
Monthly Engineering Q&A
Have a good tool for taking questions.
Remind folks the day before the meeting.
Highlight individuals doing important work.
What About Other Meetings?
1:1 meetings
Skip-level meetings
Execution meetings
Show-and-tells
Tech talks or Lunch-and-Learns
Engineering all-hands
Scaling Meetings
Scale operational meetings to optimize for right participants.
Scale development meetings to optimize for participant engagements.
Keep the Engineering Q&A as a whole organization affair.
11. Internal Communication
This chapter covers practices to improve quality of internal communication.
Maintain the Drip
The author recommends sending a weekly update to let the team know what you are focused on. You can maintain a document that accumulate weekly documents and then compile them into an email. The weekly update is generally structured as follows:
1-2 sentences that energized me this week.
One sentence summarizing any key reminders for upcoming deadlines.
One paragraph for each important topic that has come up over the course of the week, e.g., product launch, escalation, planning updates.
A bulleted list of brief updates like incident reviews, a tech spec or product design.
Invitation to reach out with questions and concerns.
Test Before Broadcasting
The author recommends proofreading and asking for feedback from individuals before sharing the updates widely.
Build the Packet
The author recommends following structure for important communication:
Summary
Canonical source of information
Where to ask questions
Keep it short
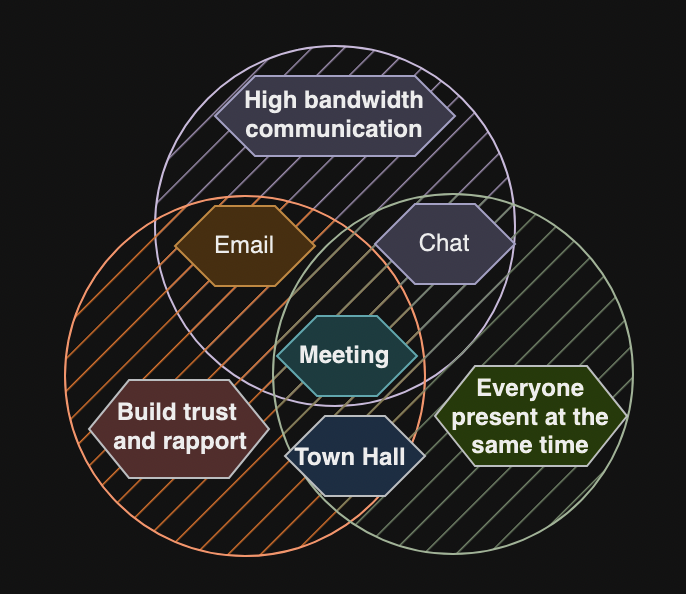
Use Every Channel
Email and chat
Meetings
Meeting minutes
Weekly notes
Decision log
12. Building Personal and Organizational Prestige
This chapter covers building prestige, brand and an audience.
Brand Versus Prestige
A brand is a carefully constructed, ongoing narrative that defines how you’re widely known. Prestige, on the other hand, is the passive recognition that complements your brand. The author suggests the following methods to build prestige:
As an individual – attend a well-respected university, join well-known company.
As a company – problem that is attractive to software engineer.
Manufacturing Prestige with Infrequent, High-Quality Content
The author recommends following approach:
Identify a topic where you have a meaningful perspective.
Pick a format that feels the most comfortable for you.
Create the content!
Develop an explicit distribution plan for sharing your content.
Make it easy for interested parties to discover your writing.
Repeat this process two to three times over the next several years.
Measuring Prestige is a Minefield
Pageviews
Social media followers
Sales
Volume
13. Working with Your CEO, Peers, and Engineering
This chapter discusses topics related to building effective relationships.
Are You Supported, Tolerated, or Resented?
You can check the status of your relationship with other parts of your company:
Supported – when others proactively support your efforts.
Tolerated – when others are indifferent to your work.
Resented – when other view your requests as a distraction.
Navigating the Implicit Power Dynamics
The author recommends listening closely to the CEO, the board and peers but be open to other perspectives who are doing the actual work.
Bridging Narratives
The author suggests taking time to consider a variety of perspectives and adopting a company-first approach before rushing to solve a problem.
Don’t Anchor to Previous Experience
The author advises against simply applying lessons from previous companies. Instead, they recommend first understanding how others solve problems and then asking why they chose that approach.
Fostering an Alignment Habit
The author suggests asking for feedback on what you could have done better or what you might have avoided altogether.
Focusing on Small Number of Changes
In order to retain the support of your team and peers, the author recommends focusing on delivering a small number of changes with meaningful impact.
Having Conflict is Fine, Unresolved Conflict is Not
Conflict isn’t inherently negative but you should avoid unresolved, recurring conflict. The author recommends structured escalation such as:
Agree to resolve the conflict with the counterparty.
Prioritize time with the counterparty to understand each other’s perspective.
Perform clean escalation with a shared document.
Commit to following the direction from whomever both parties escalated to.
14. Gelling Your Engineering Leadership Team
The Five Dysfunctions of a Team introduces the concept of your peers being your “first team” rather than your direct reports. This alignment is difficult and this chapter discusses gelling your leadership into an effective team.
Debugging and Establishing the Team
When starting a new executive role, the author recommends asking following questions:
Are there members of the team who need to move on immediately?
Are there broken relationship pairs within your leadership team.
Does your current organizational structure bring the right leaders into your leadership team?
Operating Your Leadership Team
Operating team effectively requires following:
Define team values
Establish team structure
Find space to interact as individuals
Referee defection from values
Expectations of Team Members
The author recommends set explicit expectations on following for the team members.
Leading their team.
Communicating with peers.
Staying aligned with peers.
Creating their own leadership team.
Learning to navigate you, their executive, effectively.
Competition Amongst Peers
The author lists following three common causes of competition:
A perceived lack of opportunity
The application of poor habits from bureaucratic companies
The failure of a leader to referee their team
15. Building Your Network
This chapter covers building and leveraging your network effectively.
Leveraging Your Network
The author recommends reaching out your network when you can’t solve a problem with your team and peers.
What’s the Cheat Code?
Building your network has no shortcuts; it takes time, and you’ll need to be valuable to others within it.
Building the Network
The author advises being deliberate in expanding your network, with a focus on connecting with those who have the specific expertise you’re seeking.
Working together in a large company in a central tech hub.
Cold outreach with a specific question.
Community building
Writing and speaking
Large communities
What doesn’t work – ambiguous or confusing requests or lack of mutual value.
Other Kinds of Networks
Founders
Venture Capitalists
Executive Recruiters
16. Onboarding Peer Executive
This chapter breaks down onboarding peer executives.
Why This Matters
A high-performing executive ensures their peers excel by providing support, including assistance with onboarding.
Onboarding Executives Versus Onboarding Engineers
When onboarding engineers, you share a common field of software engineering. However, when onboarding executives, they may come from different fields. Your goal should be to help them understand the current processes and the company’s landscape by involving them in a project or addressing critical issues.
Sharing Your Mental Framework
Where can the new executive find real data to inform themselves?
What are the top to three problems they should immediately spend time fixing?
What is your advice to them regarding additional budget and headcount requests?
What are areas in which many companies struggle but are currently going well here?
What is your honest but optimistic read on their new team?
What do they need to spend time with to understand the current state of the company?
What is going to surprise them?
What are the key company processes?
Partnering with an Executive Assistant
When to hire
Leveraging support
Managing time
Drafting communications
Coordinating recurring meetings
Planning off-site sessions
Coordinating all-hands meetings
Define Your Roles
What are your respective roles?
How do you handle public conflict?
What is the escalation process for those times when you disagree?
Trust Comes with Time
Spend some time knowing them as a person
Hold a weekly hour-long 1:1, structured around a shared 1:1 document
Identify the meetings where your organization partner together to resolve prioritization
17. Inspected Trust
This chapter covers how relying on trust heavily can undermine leadership and and using tools instead of relying exclusively on trust.
Limitations of Managing Through Trust
A new hire begins with a reserve of trust, but if they start burning it, their manager might not provide the necessary feedback. A good manager should prioritize accountability over relying too heavily on trust.
Trust Alone isn’t a Management Technique
Trust cannot distinguish between the good and bad variants of work:
Good errors – Good process and decisions, bad outcome
Bad errors – Bad process and decision, bad outcome
Good success – Good process and decision, good outcome
Bad successes – Bad process and decisions, good outcome
Why Inspected Trust is Better
The author recommends inspected trust instead of blind trust.
Inspection Tools
Inspection forums – weekly/monthly metric review forum
Learning spikes
Engaging directly with data
Handling a fundamental intolerance for misalignment
Incorporating Inspection in Your Organization
Don’t expand everywhere all at once; instead focus on 1-2 critical problems.
Figure out your peer executives’ tolerance for inspection forums.
Explain to your Engineering leadership what you are doing?
18. Calibrating Your Standards
This chapter covers standards can cause friction and matching your standards with your organization standards.
The Peril of Misaligned Standards
You may want to hire folks with very high standards but organizations only tolerate a certain degree of those expectations.
Matching Your Organization’s Standards
The author argues that a manager is usually aware of an underperformer’s issues but often fails to address them, which is a mistake. In some companies, certain areas may operate with lower standards due to capacity constraints or tight deadlines.
Escalate Cautiously
When your peers are not meeting your standards, the author recommends leading escalation with constructive energy directed toward a positive outcome.
Role Modeling for Your Peers
The author suggests following playbook to improve an area that you care about:
Model – Identify the area and demonstrate a high-standards approach through role modeling.
Document – Document the approach once it is working.
Share – Send the documented approach to the teams you want to influence.
Adapting Your Standards
The author suggests taking time to determine what matters most to you when your standards exceed those of the organization.
19. How to Run Engineering Processes
This chapter explores patterns for managing processes and how companies evolve through them.
Typical Pattern Progression
The author defines following patterns for running Engineering:
Business Unit Local – Engineering reports into each business unit’s leadership
Patterns Pros and Cons
Early Startup
Pros: Low cost and low overhead
Cons: Quality is low and valuable stuff doesn’t happen
Baseline
Pros: Modest specialization to focus on engineering; Unified systems to inspect across functions
Cons: Outcomes depend on the quality of centralized functions
Specialized Engineering Roles
Pros: Specialized roles introduce efficiency and improvements
Cons: More expensive and freeze a company in a given way of working and specialists incentivized to improve processes instead of eliminating them
Company Embedded Roles
Pros: Engineering can customize its process and approach
Cons: Expensive to operate and quality depends on embedded individuals
Business Unit Local
Pros: Aligns Engineering with business priorities
Cons: Engineering processes and strategies require consensus across many leaders
Early Startup
Pros: Low cost and low overhead
Cons: Quality is low and valuable stuff doesn’t happen
20. Hiring
This chapter covers hiring process, managing headcounts, training and other related topics.
Establish a Hiring Process
The author recommends a hiring process with following components:
Application Tracking System (ATS)
Interview definition and rubric – set of questions for each interview
Interview loop documentation – for every role
Leveling framework – based on interview performance
Hiring role definitions
Job description template
Job description library
Hiring manager and interviewer training
Pursue Effective Rather than Perfect
The author warns against implementing overly burdensome processes that consume significant energy without yielding much impact, such as adding extra interviews in hopes of a clearer signal. Instead, the author recommends setting a high standard for any additions to your hiring process.
Monitoring Hiring Process and Problems
The author offers following mechanisms for monitoring and debugging hiring:
Include Recruiting in your weekly team meeting
Conduct a hiring review meeting
Maintain visibility into hiring approval
Approve out-of-band compensation
Review monthly hiring statistics
Helping Close Key Candidates
An executive can help secure senior candidates by sharing the Engineering team’s story and highlighting why it offers compelling and meaningful work.
Leveling Candidates
The author recommend executives to level candidate before they start the interview process. The approach for leveling decision includes:
A final decision is made by the hiring manager.
Approval is done by the hiring manager’s manager for senior roles.
Determining Compensation Details
The recruiter calculates the offer and shares it into a private channel with the hiring manager.
Offer approvers are added to the channel to okay the decision.
Offers following standard guidelines.
Any escalation occur within the same private chat.
Managing Hiring Prioritization
The author suggests a centralized decision-making process for evaluating prioritization by assigning headcount and recruiters to each sub-organization, allowing them to optimize their priorities.
Training Hiring Managers
The author recommends training hiring managers to avoid problems such unrealistic demands, non-standard compensation, being indecisive, etc.
Hiring Internally and Within Your Network
The author advises distancing yourself from the decision-making process when hiring within your network. Additionally, the author recommends exercising moderation when hiring, whether internally, externally, or within your own network.
Increasing Diversity with Hiring
The author warns against placing the responsibility for diversity solely on Recruiting, emphasizing that Engineering should also be held accountable for diversity efforts.
Should You Introduce a Hiring Committee?
Hiring committees can be valuable, but the author cautions against relying on them as the default solution, as they can create ambiguity about accountability and distance from the team the candidate will join. An alternative approach is to implement a Bar Raiser, similar to Amazon’s hiring process.
21. Engineering Onboarding
The chapter examines key components of effective onboarding, focusing on the roles of the executive sponsor, manager, and buddy in a typical process. It explores how these positions contribute to successfully integrating new employees into an organization.
Onboarding Fundamentals
A structured onboarding process defines specific curriculum based on roles:
Roles
Executive sponsor – select the program orchestrator to operate the program.
Program orchestrator – Develop and maintain the program’s curriculum.
Why Onboarding Programs Fail
The onboarding programs often due to lack of sustained internal engagement or the program becomes stale and bureaucratic.
22. Performance and Compensation
This chapter covers designing, operating and participating in performance and compensation processes.
Conflicting Goals
A typical process at a company tries to balance following stakeholders:
Individuals – they want to get useful feedback so they can grow.
Managers – provide fair and useful feedback to their team.
People team (or HR) – ensure individuals receive valuable feedback.
Executives – decide who to promote based on evaluations.
Performance and Promotions
Feedback Sources
The feedback generally comes from peers and the manager. However, peer feedback can take up a significant amount of time and often is inconsistent.
Titles, Levels, and Leveling Rubrics
The author outlines a typical career progression in software engineering: Entry-level, Software Engineer, Senior Software Engineer, and Staff Software Engineer. They recommend creating concise leveling rubrics that describe expectations for each level, favoring broad job families over narrow ones. These guidelines aim to provide clear career paths while maintaining flexibility across different company structures.
Promotions and Calibration
A common calibration process looks like:
Managers submit their tentative ratings and promotion decisions.
Managers in a sub-organization meet together to discuss tentative decisions.
Managers re-review tentative decisions for the entire organization.
The Engineering executive reviews the final decisions and aligns with other executives.
Compensation
Build compensation bands by looking at aggregated data from compensation benchmarking companies.
Compensation benchmarking is always done against a self-defined peer group.
This chapter covers reading survey results and taking actions on survey data.
Reading Results
The author outlines following approach for reviewing survey data:
Verify your access level: company-wide or Engineering report only. If limited to Engineering, raise the issue at the next executive team meeting to request broader access.
Create a private document to collect your notes on the survey.
Get a sense of the size of your population in the report.
Skim through the entire report and group insights into: things to celebrate, things to address and things to acknowledge.
Focus on highest and lowest absolute ratings.
Focus on ratings that are changing the fastest.
Identify what stands out when you compare across cohorts.
Read every single comment and add relevant comments to your document.
Review findings with a peer.
Taking Action on the Results
The author outlines following standard pattern around taking action:
Identify serious issues, take action immediately.
Use analysis notes to select 2-3 areas you want to invest in.
Edit your notes and new investment areas into a document that can be shared.
Review this document with direct reports.
For the areas to invest, ensure you have verifiable actions to take.
Share the document with your organization.
Follow up on a monthly cadence on progress against your action items
Mention these improvements in the next cultural surveying.
24. Leaving the Job
This chapter covers the decision to leave, negotiating the exit package and transitioning out.
Succession Planning Before a Transition
The planing may look like:
In performance reviews, provide feedback to your direct reports to focus on.
Talk to the CEO about the growth you are seeing in your team.
Every quarter, run an audit of the meetings you attend and delegate each meeting to someone on your team.
Go on a long vacation each year and avoid chiming in on email and chat.
Deciding to Leave
The author recommends asking following questions when executives grapple with intersection of identify and frustration:
Has your rate of learning significantly decreased?
Are you consistently de-energized by your work?
Can you authentically close candidates to join your team?
Would it be more damaging to leave in six months than today?
Am I Changing Jobs Too Often?
If it’s less than three months, just delete it from your resume.
If it’s more than two years, you will be able to find another role as some of your previous roles have been 3+ years.
As long as there’s strong narrative, any duration is long enough.
If a company reaches out to you, there is no tenure penalty.
Telling the CEO
The discussion with CEO should include:
Departure timeline
What you intend to do next
Why you are departing?
Recommended transition plan
Negotiating the Exit Package
You may get better exit package if your exit matches the company’s preference and you have a good relationship with the CEO.
Establish the Communication Plan
A shared description of why you are leaving.
When each party will be informed of your departure.
Drafts of emails and announcements to be made to larger groups.
Transition Out and Actually Leave
A common mistake is to try too hard to help, instead author recommends getting out of the way and supporting your CEO and your team.
I recently read “Become a Great Engineering Leader” (currently in beta version B5.0), which introduces tools, techniques, and secrets for engineering leadership roles. The book is divided into three parts: “The Roles Defined,” “Tools, Techniques, and Time,” and “Strategy, Planning, and Execution.” Here are the key insights from the book, organized by chapter:
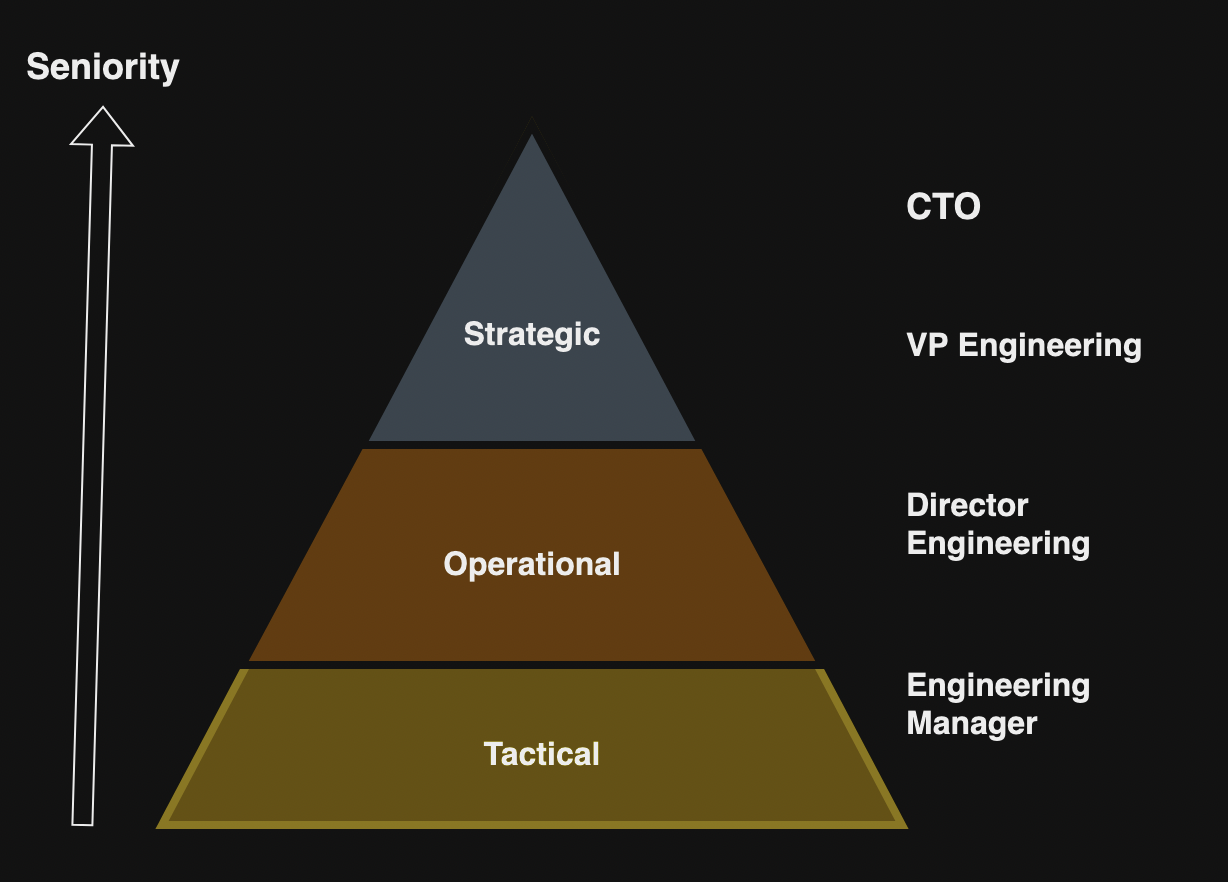
1. VP, Director, What?
This chapter introduces first part about the roles defined. It lays out the career tracks where a career track for an individual contributor might looks like:
Software Engineer
Senior Software Engineer
Staff Engineer
Principal Engineer
A similar career track for manager may look like:
Engineering Manager
Senior Engineering Manager
Director of Engineering
VP of Engineering
CTO
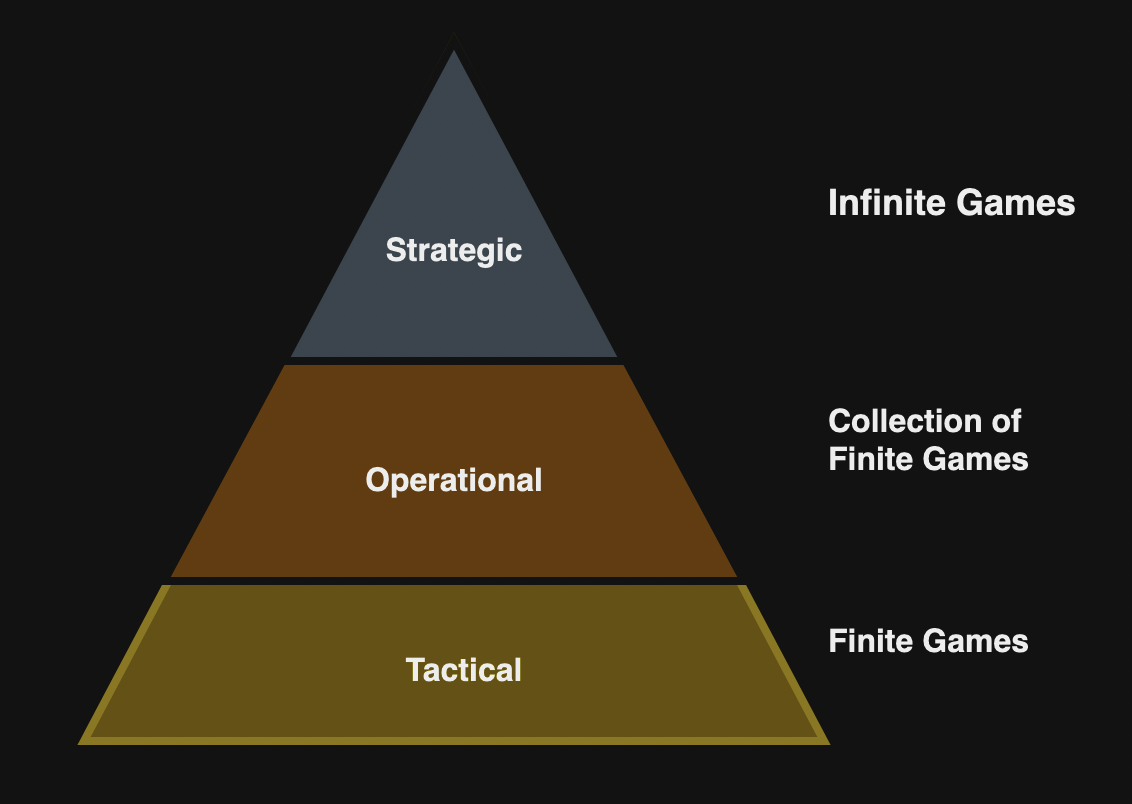
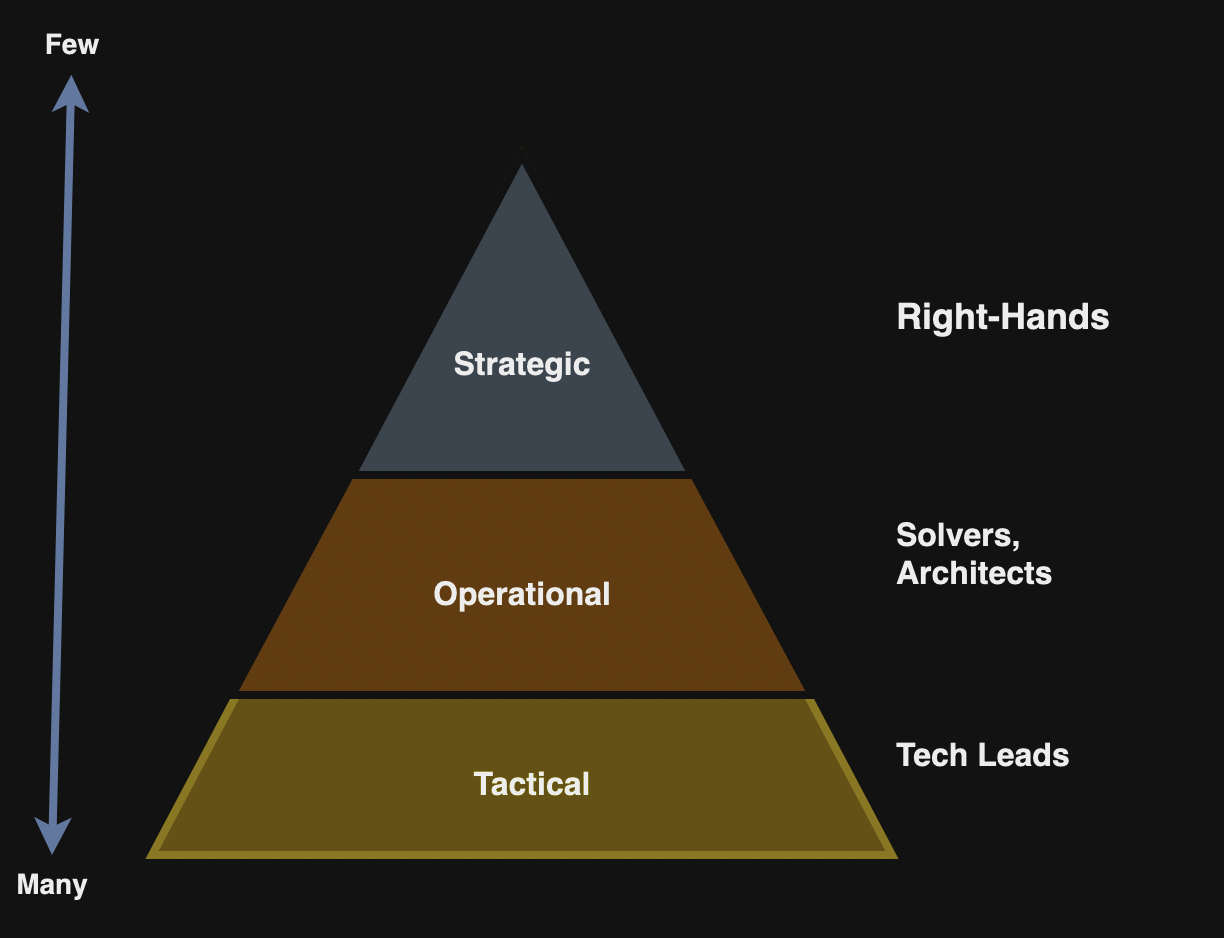
Many skills are common to both tracks and both tracks are viable options for individuals. The author cites three levels of warfare for defining responsibilities for above roles:
Strategic
Operational
Tactical
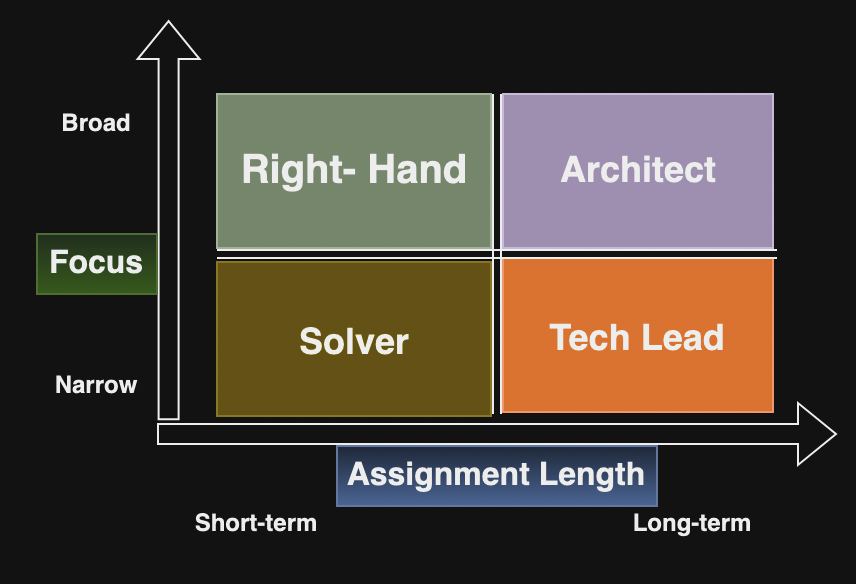
The author defines scope and impact for leadership roles where the scope describes the boundaries of responsibilities and impact describes the effect the person holding the role is having. As an individual progresses through the senior roles, the impact increases that will increase the opportunities for increase of scope.
The author lists several competencies that are required to be successful in a particular role. These include:
Professional experience
Technical knowledge
Mentorship
Conflict resolution
Communication
Influence
2. Your Place in the Org Chart
In this chapter, the author describes how humans have become the dominant species by applying division of labor and collaboration to achieve a shared goals. The author describes org charts to show different teams, divisions and people. The org chart can help clarify who is accountable and responsible for what, relative levels of investment, encourage collaboration and avoid duplication. The author describes best practices to look shape of org chart at the tactical, operational and strategic levels.
Span of control is the number of people that report to a manager. Some of the considerations for determining the span of control includes practical limits, the seniority of manager, the seniority of the reports, and the type of work that the team does.
Tactical: The Engineering Manager – typically has five to ten individual contributors as direct reports.
Senior Engineering Manager – typically has five to ten Engineering Managers as direct reports who are responsible for a larger product or service. In some cases, senior individual contributors also report to them.
Operational: The Director of Engineering – typically has five to ten direct reports and focus around an operational area.
Strategic: The VP of Engineering and CTO – typically has five to ten directors as direct reports who form the implementation of the strategy that the VP defines.
Structural Antipatterns
The author defines a number of structural antipatterns including:
Spans and Modes of Operation: A manager with one or two direct reports is effectively redundant in their role. A manager with a large large becomes effectively a coordinator but a manager with fifteen or more becomes ineffective.
Making Yourself Redundant: Managers with very few reports or low-span managers are redundant. Instead of deep hierarchy, hire an Engineering Manager to run one of the sub-teams and then run the other team by Senior Manager or Director.
Rigidity and Self-Selection: When org charts are not periodically updated in order to match the current investment. Instead, periodically review your org chart to ensure that it is still fit for the priorities.
Flows of Communication and Collaboration
Conway’s Law
It states that “any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.” It can be used to facilitate the right collaboration and communication between teams.
Dunbar’s Number
It is a cognitive limit to the number of people that an individual can maintain stable social relationships with, which is estimated to be around 150. It can be applied to structure teams and types of collaboration and communication between them.
Team Topologies
Matthew Skelton and Manuel Pais in 2019 published team topology model with following four types:
Stream-aligned teams: typically called “product teams”, which are autonomous and cross-functional teams.
Enabling teams: support the stream-aligned teams by owning and developing shared platforms, frameworks, and tools.
Platform teams: enable the stream-aligned teams to work autonomously by reducing the cognitive load.
Complicated subsystem teams: own and develop the most complex parts of the system that require specialist knowledge.
The team topology model defines three modes of interaction: Collaboration, X-as-a-service, Facilitating. The team topologies model can also be fractal. Using the org chart, you can refactor it to define the interactions between teams so that ownership of user experience, critical infrastructure and other areas is clear.
3. Time: Observed, Spent, and Allocated
This is the first chapter for the second part of the book that focus on “Tools, Techniques and Time” and discusses how time and capacity is managed and other tools can be leveraged for better time management.
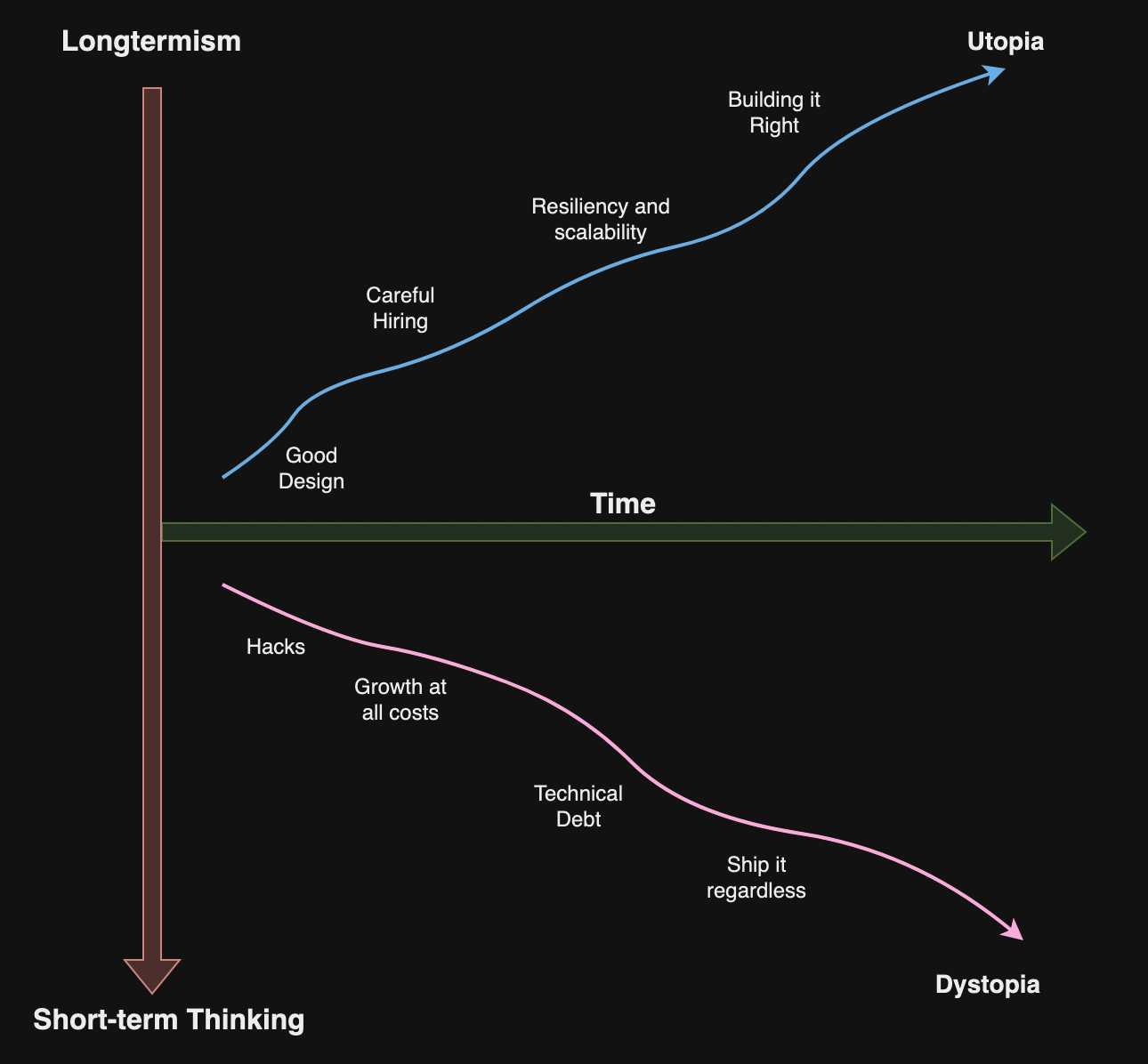
A Lens of Longtermism
The author asserts that humans can be extremely short-sighted that leads to poor decisions. The Longtermism allows making decisions that reduce major risks in the long-term future.
The author suggests following practices for longtermism:
Ensuring that you organization’s vision and strategy is aligned with the long-term future.
Hiring and developing the right people.
Developing future leaders.
Working on scalability, resilience, and reliability.
Reducing technical debt.
Your Time Is Not Your Own
Senior leaders should spend time wisely based on the organization needs such as reviewing metrics and projects for tracking their progress, connecting and collaborating with peers and reports, strategic work, etc. The author suggests spending about 10% of time on yourself and not overcommit.
Your Capacity: Your Most Important Resource
Before managing time, you need to evaluate your capacity and the author cautions against allocating workload to your full capacity as you will need to handle escalations, meetings and other interruptions.
Managing Your Energy
The capacity is not a constant but it is a function of your energy levels. The capacity depletes when you are spending time on tasks that drain your energy and it replenishes when you work on tasks that energize you.
Input Versus Output: The Tug of War
The inputs may come from emails, meetings and interruptions and outputs are things where you add value. The author recommends keeping balance between those so that you are not in a constant state of reactivity.
Time Management: Models, Tools, and Techniques
In this section, the author goes over a number of different models, tools, and techniques for managing your time effectively.
The Eisenhower Matrix
The Eisenhower Matrix consists of following 4×4 matrix:
Saying No
As your capacity is finite, and you need to ensure that you are spending it on the right things. You will have to explain the reasons for saying now and decide if it can be delegated.
Getting Executive Assistance
The executive assistance may use the Eisenhower Matrix to organize your tasks and help manage your energy.
Deadlines and Cadences: The Greatest Trick You Can Play on Yourself
Due to self-directed and future-facing work, you may fall into the trap of never getting things done. The author recommends artificial boundaries and deadline that exploits Parkinson’s Law. You can use these recurring synthetic deadlines as cadences to set goals that can be shared with the team in a sustainable way.
Using Accountability Partners
An accountability partner is someone that you trust that you can share your goals with. Your accountability partner who can also be a group (mastermind group) becomes part of your cadence.
Your Calendar: Wielding a Double-Edged Sword
This section refers to your calendar as a double-edged sword because it become a tool that others use to control you.
Blocking Time
The author recommends blocking time to ensure that you have the space to work on the things that matter. For example, you can create recurring focus time in your calendar so that others know that you are busy.
Getting the Most out of Focus Blocks
Creating the Right Environment
You can set your status to busy on any applications that support it and disable all unnecessary notifications. You can set a goal in the focus block.
The Pomodoro Technique
The Pomodoro Technique is a time management technique that was developed by Francesco Cirillo. It breaks work into intervals, typically 25 minutes in length.
Things To Focus On
You can plan on things to focus such as making progress on your goals, review the work of others or other longtermist activities. Though, the author recommends against using this time for working with your inbox but you can setup a dedicated time a few times a day to organize your inbox based on the Eisenhower Matrix.
The Power of Nothing
You can also use the focus time to brainstorm ideas, spending time using the product, read design docs or latest research.
Meetings: Crisp, Clear, and with a Purpose
Meetings are essential for certain types of communication and collaboration but they can drain your time and capacity. Some of the tips for controlling meetings include:
To Meet or Not to Meet: That Is the Question
The author offers following venn diagram for meetings:
The author recommends meeting if all three properties are present: high-bandwidth communication, the need to build trust and rapport, and the need for everyone to be present at the same time. The speed of a decision should not be limited by the availability of the person with the busiest calendar.
Clear Agendas, Clear Outcomes, Clear Actions
A meeting agenda should be written before the event and shared with all attendees. The agenda should include purpose and talking points including ideal outcome.
Calendar Stagnation: Blowing It All Up
The author suggests resetting calendar at various points of the year and delete recurring meetings to make sure everyone is using their time wisely.
Syncs, Status Updates, and Other Ways to Die
The author offers alternatives to various types of meetings such as:
Chat updates instead of standups.
Weekly updates that is shared asynchronously instead of weekly group syncs.
Enforce strict agenda for staff meetings that focus on critical issues the team is facing.
Instead of unfacilitated brainstoring, consider getting participants to sketch ideas beforehand and share them asynchronously.
Auditing Your Time
In High Output Management, Andy Grove categorizes the activities of a senior manager into four buckets:
Information gathering
Decision-making
Nudging
Being a role model
4. The Games We Play and How to Win Them
This chapter focuses on fundamentals of managing senior people and other techniques for achieving goals.
Management 101: The Fundamentals
Coaching Versus Directing
Instead of directing managers and senior individual contributors, you will be coaching them. The author recommends GROW model that stands for:
What is Goal?
What is current Reality or situation?
What are Obstacles?
What are Options available?
Way-forward for next steps, decisions and actions.
This model is similar coaching and can be used for directive coaching or following interests where you listen to them on what they should do.
Delegation
The essential principle of delegation is to assign the responsibility of a task to others while still retaining accountability for its completion and ensuring it meets the expected high standards. The key to effective delegation is to clearly define where you stand on the accountability scale, and to specify who is accountable and who is responsible for the task.
1:1s 101
1:1s is the backbone of your relationship with your direct reports and you should treat 1:1s with the utmost priority.
Contracting
The author suggests an exercise called contracting for effective 1:1s that asks questions such as:
What are the areas that you would like support with?
How would you like to receive feedback and support from me?
What could be a challenge of us working together?
How might we know if the support I’m offering isn’t going well?
How confidential is the content of our meetings?
Focus and Format
The author recommends a clear focus and format for 1:1s by having a shared agenda, being mindful of time, using time to coach, summarizing and agreeing to next steps.
Brag Docs: The Greatest Gift You’ll Ever Receive
The brag docs track of what your direct reports are doing by maintaining a shared document that regularly updates their achievements, challenges, and goals. The author suggests structure for a bag doc such as choosing a period of time, broad goals, link achievements to wider goals, and review it regularly.
It’s All Just Leadership After All
The author recommends using same strategy for managing senior managers and senior individual contributors.
Control at the Intersection
The author recommends delegation model to manage senior staff that report to you, regardless of their role. Senior individual contributors demonstrate leadership by leading technical initiatives such as leading a project or a technical area.
From the Swamp to Infinity: Achieving Together
The author recommends building relationship with your staff that leads working together towards the same goal.
The Swamp
Senior managers often face a constant influx of tasks, resulting in a reactionary and disorganized situation that the author refers to as “the swamp.” The author suggests a mental model to make sense of the issues as managers wade through the muddy water.
Finite games: These are games with a clear beginning and end. They follow a set of agreed-upon rules, and the objective is to win. Each game has an entry criteria or the problem to solve, rules or constraints, and exit criteria or the success. As a manager, you need to minimize number of active finite games to prevent context-switching and reducing entropy in the organization.
Infinite games: These games have no defined start or finish. Players come and go, the rules constantly change, and the goal is to continue playing. Finite games can be played within infinite games, e.g., product roadmap may require finite games from engineering, sales, marketing and other organizations. Infinite games require maintaining stability to keep players happy, motivated, growing, learning, and, most importantly, preventing burnout.
5. Become a Great Engineering Leader
This chapter classifies the type of work for individual contributors so that senior managers benefit from a close relationship with individual contributors.
Individual Contributors: The Higher Rungs
As Senior Engineers advance in their careers, they can choose between the managerial track to become a manager or the technical track to become a Staff or Principal Engineer.
The Tech Lead who closely works with a single team.
The Architect who is responsible for ongoing design, scalability and quality of the system.
The Solver who solves complex issues.
The Right-Hand who partners with a senior manager to increase their bandwidth.
Deploying Senior Individual Contributors
The scope of Engineering Manager typically a single team and Tech Lead archetype fits for this role.
The scope of Senior Engineering Manager is broader with multiple teams and it can deploy multiple archetypes such as the Tech Lead, the Solver and the Architect.
At the Director and VP level, the Right-Hand archetype becomes a viable option typically Staff/Principal Engineer when reporting to the Directory and Distinguished Engineer when reporting to the VP.
The Technical Shadow Organization
The group of senior individual contributors forms a kind of technical shadow organization that influences and guides the work being done.
Your Technical Council
The Technical Council is a group of senior individual contributors who meet regularly to discuss and guide the organization’s technical direction. The Technical Council can be utilized to discuss and make decisions on various topics, including the technical roadmap, technical standards, technical debt, deep dives, and reviews.
Building Connections Across the Organization
The author encourages the Technical Council to establish connections across the organization to prevent knowledge silos and better serve the broader organization.
6. The Tragedy of the Common Leader
In this chapter, the author demonstrates how middle managers can combat entropy when they are continually reacting and receiving without reciprocation from others.
But We Didn’t Want This to Become a Dumpster Fire
The author introduces the tragedy of the commons, where individuals acting in their own self-interest deplete a shared resource, leading to complex shared codebases or infrastructure that no one wants to take ownership of. The tragedy of the commons opposes longtermism, the principle of selflessly investing in a shared future, even if it requires sacrificing in the present.
Up and Down but Not Sideways
The middle managers reporting to the common leader often look up and down the org chart but not sideways. Protecting your team while competing for the manager’s time, focus, and favor can create a hostile and competitive environment.
Magnetism and Polarity: Pulling Peers Together
The author suggests strengthening relationships with peers to achieve collective goals. By connecting with peers, both you and your peers can gain valuable benefits from the relationship.
Attraction, Repulsion, and the Middle Ground
The author introduces a concept of polarity similar to magnets, where positive polarity creates value for other teams by attracting, negative polarity creates conflict by repelling, and neutral polarity creates neither value nor conflict for other teams.
Polarity-Led Relationships
The author defines following relationship traits based on polarity:
Positive: Your team enables or collaborates with the other team. You can share knowledge and focus on ways to improve collaboration.
Negative: You team has difficulty collaborating with the other team or your team’s direction collides with the other team strategically. You can build trust and empathy with the other team to improve the collaboration.
Neutral: You team rarely interact with the other team. You can build trust and rapport with the other team.
Actually, It’s All on You: Do It Yourself
The author recommends proactively establishing connections with your peer group and continually nurturing them to demonstrate that you are a trusted partner and collaborator, helping to fight entropy of competing with manager’s time. To combat the tragedy of the commons, the author reiterates lessons from longtermism and infinite games, advocating for a positive-sum game instead of a zero-sum game.
Your Manager Is Not Your Single Point of Contact
In some organizations a set of peers only communicate with each other through their manager who becomes a bottleneck. This is an antipattern that encourages a lack of transparency, politics and snide behavior. Instead, the author recommends fostering open communication among peer groups through a chat channel, regular meetings, and seeking discussions proactively.
The Best Way to Build Trust: Deliver Something Awesome
Some peer groups may be quick to spot and escalate problems but rarely take action to fix them. The author recommends dedicating 10 percent of your capacity to initiatives that improve the organization such as codifying best practices, and unifying reporting on health of the code and production environment.
7. Of Clownfish and Anemone
This chapter focuses on developing a productive, symbiotic relationship with your manager.
Teenage Rebellion: Raging Against the Machine
In a senior leadership role, you are expected to be self-sufficient and an expert in your domain, with a unique leadership style or perspective on the organization. This can sometimes lead to friction with your manager and disappointment when they don’t meet your standards.
The Reporting to Peter Principle
The Peter Principle states that “in a hierarchy every employee tends to rise to their level of incompetence.” The author introduces the Reporting to Peter principle, which suggests that in every organization, you will eventually reach a point where you experience significant internal conflict with how your manager performs their job. The author recommends embracing these differences, viewing them as strengths, and using them as opportunities to learn from each other and develop a symbiotic relationship.
Prescriptions Don’t Work: Tools Do
The author advises against relying on prescriptive advice. Instead, they suggest observing and understanding both your own strengths and weaknesses, as well as those of your manager, and using this insight to build a mutually beneficial relationship.
Symbiosis: Defined, Observed, and Applied
The author recommends recognizing additive and subtractive actions and cultivating symbiotic relationships with your manager that benefit both parties.
Skip to the End: Defining the Relationship
The author distinguishes between additive and subtractive actions in relationships:
Additive actions: These explicitly benefit your relationships and can be undertaken by both parties.
Subtractive actions: These can cause friction in your relationship and should be transformed into additive actions.
To build a mutually beneficial virtuous cycle, the author recommends transforming subtractive actions into additive ones. For example, if regular one-on-one meetings are frequently cancelled at the last minute (a subtractive action), this can be transformed into an additive action by implementing weekly written status updates.
How Do You Actually Want to Be Managed?
As a high-growth individual, you may desire more autonomy than your manager is comfortable giving, or, particularly at senior levels, you might want more frequent check-ins than your manager provides. The key to resolving this misalignment is self-awareness: understand your preferred working style, clearly communicate your expectations to your manager, and work together to find a mutually satisfactory arrangement.
When the Stuff Hits the Fan
This section addresses how to handle adverse situations, including escalations, intense scrutiny (the “eye of Sauron”), and unexpected negative events.
Escalations
Well-managed escalations can be highly productive, fostering trust among you, your manager, and other involved parties, while leading to improved outcomes for the entire organization. The author provides following recipe for dealing with escalations:
Identify the problem.
Have all parties involved in the escalation agree to it being escalated.
Collaborate with all involved parties to identify the problem, explore potential solutions, and evaluate the trade-offs of each option.
Make a recommendation.
Escalate!
Don’t take it personally.
The Eye of Sauron
The Eye of Sauron refers to situations involving external events or intense internal scrutiny, often triggered by a major incident, a sudden increase in oversight, or a change in direction from an executive. The author offers following recipe for handling the Eye of Sauron:
Remain calm.
Listen to all inputs.
Come up with a communication plan.
Coach others to see these situations as a learning opportunity.
Retrospect after the situation is over.
Unpleasant Surprises
Unpleasant surprises are situations that catch both you and your manager off guard. The author offers following recipe for handling unpleasant surprises:
Assess and confirm the situation.
Come up with a clear plan.
Execute on the plan.
Retrospect after the situation is over.
8. Trifectas, Multifectas, and Allies
This chapter explores trifectas (three people from different disciplines collaborating), multifectas (teams with more than three disciplines), and allies (supportive individuals from other disciplines).
Omne Trium Perfectum
The author asserts that the number three frequently appears, as in the iron triangle where decisions has three options: scope, resources, and time, allowing for only two out of the three. Having three variables creates the ideal amount of tension for decision-making.
Trifectas: Your Own Perfect Triplet
A trifecta is a team of three individuals from different disciplines collaborating to achieve a goal, typically involving engineering, product, and UX. Different parts of the department may have varied trifecta members. For instance, a platform team might include engineering, product, and developer relations instead. The author outlines the following responsibilities for a team’s trifecta:
Ensure strategic alignment.
Define the team’s roadmap.
Make decisions.
Drive up the execution of their individual crafts.
Resolve escalations and blockers.
Communicate with stakeholders.
Trifectas Should Go All the Way Up
Many organizations structure their reporting lines by discipline, causing trifectas to disappear and resulting in dysfunctional behaviors like lack of visibility, accountability, and clear escalation paths. The author recommends maintaining a trifecta organizational structure independent of reporting lines to ensure clear accountability, quick resolution of escalations, and alignment with the roadmap and project approvals.
Setting the Stage for Your Trifecta
The author offers following tips for a healthy trifecta relationship:
Start a private chat channel.
Consider a regular meeting.
Consider office hours or regular syncs with front-line trifectas.
Develop a process for project approvals.
Develop a process for reporting on progress.
Extending to Multifectas
Bringing a new feature to market requires more than just a trifecta; it involves additional stakeholders such as marketing, sales, support, developer relations, legal, and security. These groups form a multifecta that can be organized for sustained collaboration.
Snow Melts at the Periphery
In High Output Management, Andy Grove wrote that “the snow melts at the periphery first.” The author recommends a concerted effort to be connected to outside world where you allies come in. When identifying your allies, author recommends forming a symbiotic relationship by sharing useful information, engaging with customers, resolving issues, and providing coaching.
9. Communication at Scale
This chapter focuses on large-scale communication, communication patterns, and building a communication architecture.
Standing on the Shoulders of Scribbles
In this section, the author emphasizes the role of communication in enabling organizational progress and learning.
Patterns of Communication
The author defines following patterns of communication:
Synchronous versus asynchronous
Stateless versus stateful
One-to-one, one-to-many, many-to-many
The Spectrum of Synchronousness
As you advance in seniority and your organization grows, efficient synchronous communication becomes more challenging so you have rely on asynchronous communication.
Artifacts: One-to-One, One-to-Many, Many-to-Many
When designing data pipelines, you must consider the relationships between data sources, sinks, and the transformations in between. The author recommends similar scrutiny for senior leaders for the design of communication so that communication artifacts (documents, emails, meeting notes) support organizational learning and progress. Moving these ideas from transient, informal thoughts to formal, documented communication ensures they contribute to lasting organizational success.
Optimizing for Decision Speed
Creating shareable and permanent artifacts is a great start, but the ultimate goal is to facilitate decision-making. As a leader, you should focus on optimizing decision speed without compromising decision quality and distinguish between:
One-way doors: Irreversible decisions, like making breaking changes to an API or firing an employee require careful consideration and often higher-level approval.
Two-way doors: Reversible decisions, like choosing a temporary UI component that can be made quickly and adjusted later if needed.
The author describes following protocol when making decisions:
Identify the type of decision (one-way or two-way).
Make two-way door decisions as close to the front line as possible and empowering teams to decide autonomously.
Escalate one-way door decisions to the appropriate level to ensure critical decisions have top-level buy-in.
Following this protocol allows 90% of decisions to be made quickly and safely, while the remaining 10% receive the necessary scrutiny, balancing speed and careful consideration.
Parkinson’s Law: It’s Real, So Use It
Parkinson’s Law states that “work expands so as to fill the time available for its completion.” Without deadlines, projects often take longer and suffer from feature creep and scope bloat. The author recommends setting challenging deadlines to achieve better results by managing the Iron Triangle of scope, resources, and time. Additionally, implementing a weekly reporting cadence helps maintain discipline and energy.
Leadership Is Writing
Much of leadership involves writing and as you advance in seniority, you will spend an increasing amount of time reading and writing.
The Paper Triangle
Writing is the most efficient way to communicate complex ideas to other people.
Writing is the most efficient way to communicate complex ideas, as reading is faster than listening. Writing is also the process of thinking itself and aids in organizing and structuring thoughts. The author recommends following steps to communicate effectively:
Write to think: Jot down thoughts without worrying about clarity.
Interrogate your thoughts: Review and question your initial writing to identify gaps.
Edit to read: Refine the text for clarity and conciseness for others.
This process, akin to the Iron Triangle of scope, resources, and time, ensures clear communication and aids in organizational progress.
What Is Your Recommendation?
The author recommends guiding conversations with clear recommendations rather than strong opinion, loosely held when making decisions. When reviewing documents or discussing problems, always start with a recommendation so that it fosters a culture where every communication aims to move the organization forward.
Building Your Second Brain
As writing helps organizing thoughts, the author recommends creating personal artifacts besides creating artifacts for others. At higher organizational levels, dealing with vast information is routine and the concept of a “second brain” can be beneficial in managing information. A second brain is an interconnected system to capture, process, and recall information. Popular tools include Roam Research, Notion, Obsidian, and Logseq for creating and linking notes, forming a knowledge graph. The author offers following recipe for starting with a second brain:
Create a Daily Note.
Link Important Concepts.
Use Proactively as a Reference.
Regularly Review Your Knowledge Graph.
The Grand Commit Log of History
The organization’s state can be viewed as a function of past ideas, decisions, and actions, forming a “commit log of history.” This section looks at the communication architecture framework based on tactical, operational and strategic level.
The Tactical Level
At the tactical level (frontline teams), key elements include:
Codebase artifacts include:
Good commit messages
Architecture Decision Records (ADRs)
Documentation
Projects: Each team should have:
A project container such as Github or JIRA project.
Statuses for their projects.
Design documents
Regular updates
Communication: Each team should have:
A private team chat
A public team chat
An announcement mechanism
Metrics: Each team should have:
Key Performance Indicators (KPIs)
Operational health metrics
Logs of incidents and post-mortems
Meetings: a variety of meetings that they attend
At the operational level
At the operational level (director level), key elements include:
Communication: Each operational grouping should have:
An optional private department chat
A public department chat
Discipline-specific private chats such as engineering managers or product mangers
An internal announcement mechanism
An external announcement mechanism
Projects: Each operational grouping should have:
Rollup dashboards
Clearly visible statuses
Approval information
Metrics: Each operational grouping should have:
Department KPIs
Operational health metrics
Rollup of incidents and post-mortems
Meetings: Each operational grouping should have:
A regular all-hands
Office hours
Project syncs
At the strategic level:
At the strategic level (executive level), key elements include:
Communication:
Ownership of the system of truth, deciding what tools are used.
The vision
The mission
Discipline leadership chats
Projects:
High-level dashboards
Flags for projects that are at risk
Metrics:
Company or Department-wide KPIs
Budgets and forecasts
Rollup of high-critical issues
Meetings:
Town halls
Regular business reviews
Project syncs
Board or investor interactions
10. Performance Management: Raising the Bar
This chapter examines the overarching concepts of performance management and explores the calibration process to ensure fairness and consistency in evaluations.
The Rising Tide: Why We’re Doing This
The goal of performance management is to improve everyone in the organization and keep raising the bar. Key elements of a good performance management system includes:
A well-defined set of competencies that outlines expectations for all employees.
A regular performance review process.
A calibration process.
A PIP process.
A compensation process
Performance Management of Senior Staff
In High Output Management, Andy Grove describes the output of a manager as being the output of their organization plus the output of the neighboring organizations under their influence. This output can be measured by:
Self-assessment: Subjective, Qualitative (self-awareness about their impact), Quantitative.
360 feedback: Negative, Neutral, Positive.
Metrics or KPIs: Defined, Progressed for the period, Achieved or Exceeded.
Your own observations: Negative, Neutral, Positive.
The author recommends starting a brag doc, mentoring, and writing a monthly detailed update for their area.
Calibrations: Converging on Fairness
Calibration is typically run by HR and ensures that performance management is fair and consistent across the entire organization. It can be broken into three phases:
Preparation: Generates all of the supporting evidence for each person.
Calibration: Reviews the aggregate performance of staff in the organization.
Actions: Such as follow-ups with managers.
Debugging Common Performance Management Issues
Your Lowest Performer Is the Performance Bar You Accept
Current Performance Is Not Historical Performance
Brilliant Jerks Are Not Worth It
Keeping job title inflation under control is extremely important
Being Held Hostage
Gather Data When You Disagree With One of Your Managers
11. Strategy 101
This is first chapter for third part of the book that focuses on strategy, planning and execution. It defines a strategy and focus on engineering strategies.
What on Earth Is a Strategy, Anyway?
A strategy encompasses the initiatives an organization undertakes to create value for itself and its stakeholders while gaining a competitive market advantage. It defines the specific approaches the organization will employ to position itself so that it can achieve both short-term and long-term objectives.
A Strategy Is Not a Plan
Professor Roger Martin defines strategy as “an integrative set of choices that positions you on a preferred playing field in a way that enables you to win.” Martin notes that leaders often default to planning instead of strategizing because it’s easier. This tendency stems from two factors:
Strategy focuses on outcome such as acquiring and satisfying customers, who are external to the organization.
Planning deals with internal resources and costs, which are controllable, and where the organization itself is the customer.
Engineering Strategy: Your Piece of the Puzzle
The engineering strategy is a vital subset of the overall company strategy but companies often lack a well-documented and communicated engineering strategy. As an engineering leader, you navigate two distinct worlds: the nontechnical senior executives who struggle to understand engineering complexities and the engineers who seek clarity on how their work aligns with the company’s goals. Balancing these needs is challenging, but a well-crafted strategy will address both groups effectively.
Let’s Build an Engineering Strategy Together
The author breaks down strategy into four parts:
Initiatives – What are we hoping to achieve and why?
Success metrics
Investments in teams and technology
Processes and ways of working
12. Company Cycles
This chapter looks at the calendar and how the year is broken up into cycles that serve as the rhythm of the business.
The Calendar Is Dead, Long Live the Calendar
Regardless of the estimation framework used by engineering, it must ultimately translate into concrete commitments that the entire organization can use for accountability.
Different Departments, Different Cycles
Typically, departments divide the year into four quarters (Q1..Q4). As a senior leader, you need to align your efforts effectively with the broader business cycles. You need to balance continuous delivery with the ability to support major launches or unveilings. Effective communication with the rest of the business is key to translate your team’s work into terms that make sense to other departments. The author recommends increasing the awareness of financial cycles so that you can understand and justify your spending.
Sales: Can’t Live With Them, Can’t Live Without Them
In order to support the sales team, a senior leader must generate certainty about future developments, provide support to the sales team and handle urgent customer demands.
Removing Uncertainty: The Tip of the Iceberg
The engineering leadership as being about managing and reducing uncertainty as building large scale software often involves complex tasks that others may not be visible like building an infrastructure. In order to shift your team’s focus from deadlines to reducing uncertainty, you must prototype, design, code and ship incrementally. You must prioritize tackling the most uncertain aspects first to either validate their feasibility or explore alternative solutions. The author recommends incorporating following:
Defining success metrics and key performance indicators upfront.
Prototyping to validate ideas quickly and efficiently.
Creating technical design documents to refine approaches before coding begins.
Structuring a Roadmap Based on Uncertainty
As uncertainty in a project decreases over time, you can structure your roadmap to reflect this progression. In business cycles, you can:
Be certain about the next month
Be fairly certain about the next quarter
Be less certain about the next half-year
Be even less certain about the next yea
Your roadmap should include:
Feature
Stage such as Rollout, Build, Prototype, Design
Expected delivery date or quarter
Initiative with links to relevant strategy documents
Owner
Latest update
Latest demo
Dependencies
Marketing: Big Bangs Without the Bang
The author recommends following to ensure alignment between marketing and engineering:
Clear Roadmap
Feature Flags
Feature flags offer several benefits:
Continuous Delivery
Early Testing
Simplified Testing
Easy Rollbacks
Internal Visibility
A/B Testing
Beta Programs
Early Access
Two Worlds Collide: Troubleshooting and Solutions
Misselling: The Tail Wagging the Dog
One of the most common frustrations arises when salespeople sell products or features that don’t yet exist. To address this, the author offers the following advice:
Understand how this happens in the first place.
Build better connections at the periphery and at the top of sales.
Set aside resource allocation for these surprises.
Make it clear what suffers as a result of reprioritization.
No Feature, No Deal
The ideal roadmap focuses on features that enhance the product for a broad audience, saying “no” more often than “yes.” The author cautions against building niche features for a few customers, as this can dilute your product’s vision, clutter your roadmap, and create long-term maintenance challenges. Adding too many specialized features can lead to a “death by a thousand papercuts,” where minor adjustments accumulate into significant complications over time.
Full-On Feature Factory Grind
The engineering department may feel like a “feature factory,” constantly producing new features without addressing technical debt, resiliency, scalability, or developer efficiency. The author recommends allocating engineering resources wisely for long-term stability and performance. Here are some strategies:
Educate the Business that speed and stability are features
Allocate Time for Engineering-Led Work
Highlight the Cost of Neglect
Celebrate Engineering Wins
Remember, They’re Smart Too
The author offers the following advice if there’s a pervasive culture where engineers believe they are smarter than the rest of the business:
Be clear that this is unacceptable.
Help your teams understand that transparency buys them more time to do engineering work.
Be clear that the rest of the business is incredibly smart too.
13. Money Makes the World Go Round
This chapter covers the basics of company finance and managing a large budget.
Finance 101: The Basics of Company Finance
A company operates like a flywheel, where money (input) is converted into products and services (output) that generate more money than the cost to produce them. This process creates a self-sustaining cycle that drives growth. Each department functions as a subsystem, with the executive and finance teams allocating resources to maximize output. Expenditures fall into two categories: capital expenditure (capex) and operating expenditure (opex). In order to accelerate the company’s growth, the gap between revenue (top line) and profit (bottom line) should be maximized.
Modes of Operation: Bootstrapping, Venture Capital, and More
Startups have different ways to fund their growth such as:
Bootstrapping
Venture Capital
Angel Investment
Debt Financing
The funding method influences how a company operates and allocates resources.
Cost Centers and Profit Centers
A cost center is a department that incurs expenses but doesn’t directly generate revenue, like HR. A profit center generates revenue, such as the sales department. Engineering can be either a cost or profit center, depending on the company and even specific teams within it.
SaaS Jargon Busting: Acronym Soup
Author introduces key metrics for SaaS startups such as:
MRR (Monthly Recurring Revenue)
ARR (Annual Recurring Revenue)
LTV (Lifetime Value)
CAC (Customer Acquisition Cost)
LTV:CAC Ratio – profitability from customer acquisition (ratio of 3:1 or higher is considered strong)
Churn Rate
Do You Need to Make a Profit?
Many fast-growing, venture capital-backed technology companies operate at a loss, prioritizing rapid market capture over immediate profitability. This rapid growth strategy can lead to substantial returns for investors when the company eventually goes public or is acquired.
Managing a Large Budget: Levers and Dials
The author defines following kinds of costs for engineering departments:
People – largest cost where you have to solve a multivariate optimization problem around allocation with following criteria:
Alignment with strategy
Alignment with increasing the power curve of capabilities
Alignment with the mode of operation
Infrastructure – next largest cost
Opex infrastructure
Capex infrastructure
Software and Hardware
Essential
Productivity gains
Temporary services (contractors) – Opex
Rule of Thumb
A useful rule of thumb for people is to track the revenue per employee.
Software and Hardware Spend as a Percentage of Revenue.
Temporary services – Estimate the cost of not using them.
Common Dilemmas: Patterns to Follow
Build Versus Buy
The trade-offs include:
You can build it to your exact specifications but it will take time and effort to build.
Up and running quickly but it costs money.
Dealing with Vendors: Never Trust the Book Price
Always negotiate
Consider contract length – the longer the contract, the better the deal
Consider volume – the more you buy, the better the deal
Consider competition
Top Line Versus Bottom Line: The Eternal Struggle
Budget management involves balancing top-line growth with bottom-line costs. Key metrics to track:
Revenue per employee (should increase over time)
Infrastructure spend as % of revenue (should decrease over time)
Software and hardware spend as % of revenue (should decrease over time)
Cost of distraction from top-line focus (minimize based on company phase)
14. Boom and Bust
This chapter covers the phenomenon of boom and bust cycles and categorizes the operations of a company along a scale.
Spend! Invest! Grow! Crash! Burn! Rebuild!
Technology companies thrive on innovation, which is inherently risky. Rapid growth is crucial for long-term success, fueled by investment capital and driven by network effects. This leads to two outcomes: success (continued growth, acquisition, or going public) or failure (downsizing or closure). These outcomes contribute to the industry’s boom-bust cycles, characterized by periods of rapid expansion and hiring alternating with widespread layoffs and company closures.
ZIRP, QE, and the Tech Industry
The author discusses key macroeconomic factors influencing tech industry boom and bust cycles:
Quantitative easing (QE)
Low interest rates (ZIRP – Zero Interest Rate Policy)
Low inflation
Peacetime and Wartime: A Spectrum
In The Hard Thing About Hard Things, Ben Horowitz introduces the concepts of peacetime (boom periods) and wartime CEOs (survival). Understanding where a company stands on this spectrum helps leaders adopt the appropriate strategy to guide their organization effectively.
Concentric Circles of Trust
The author introduces a model of concentric circles of trust:
Confidential – most sensitive information (NDA)
Sensitive
Open
Leading Through Peacetime: Invest, Spend, Grow
In peacetime, growth is the agenda, which is governed by following activities:
Hiring, Onboarding, and Ramping Up – onboarding and contribution curve.
Incubating New Products – ensure that there are clear tripwires for success and failure.
Mergers and Acquisitions (M&A) – technical due diligence, talent assessment, organizational fit
Leading Through Wartime: Cut, Save, Rebuild
In wartime, your company is focused primarily on survival.
Reforecasting, Restrategizing, and Reorganizing
Understand drivers such as revenue targets, funding, costs, product-market fit
Enumerate options – hiring, auditing software and services, negotiating with vendors, layoffs
Layoffs: The Worst Part Comes First
Become a Great Engineering Leader
Maximizes the chances of the department and company surviving
Retains the best talent
Complies with labor laws
A Line in the Sand – all your efforts within the inner circles of trust are brought out into the open
15. Tarzan Swings from Vine to Vine
This chapter offers guidelines for steering your career using Tarzan method.
The Fallacy of the Straight Line
Focus on what you can control, and let go of what you can’t.
The Tarzan Method
The direct path to a lofty career goal, like becoming the CTO might not exist or be clear. Instead, think of your career like Tarzan swinging through the jungle—moving from one opportunity to the next, guided by instincts and a general sense of direction.
The Trajectory of Your Swing
The author reiterates the concept of scope and impact:
Scope refers to the breadth of responsibility, such as team size, budget, and influence.
Impact refers to the depth of responsibility, such as the results of your work and the effectiveness of decisions.
Career growth can be visualized in a quadrant where:
Stagnating (low scope, low impact) means being in an unchallenging role with little satisfaction
Stepping Up (high scope, low impact) involves taking on more responsibility
Skyrocketing (high scope, high impact) is the ideal state, often in a fast-growing startup
Skilling Up (low scope, high impact) follows a period of stepping up, focusing on improving skills
Earn, Learn, or Quit
Y Combinator CEO Garry Tan suggests that “at every job, you should either learn or earn.” To progress in your career, it’s essential to consider how much you want to earn, what you want to learn, and how you can expand your scope and impact.
Putting It All Together
Writing Your Strategy
The author recommends answering the following questions:
What kind of role might you see yourself in if you could achieve everything you wanted?
What kind of environment do you want to work in?
What sort of products or services is the company creating?
What kind of people do you want to work with?
What kind of impact do you want to have?
What does all of the above mean for other aspects of your life?
The Next Vine Swing
The author recommends considering the following:
Where are you right now in the quadrant?
How long have you been in this quadrant?
Is there a route to the top-right quadrant from where you are right now?
At this moment, are you learning, earning, or both?
What sort of opportunity would tempt you if it arrived tomorrow?
I recently read Leading Effective Engineering Teams by Addy Osmani, which shares the author’s experiences at Google and presents best practices for achieving engineering excellence. Here are the key takeaways from the book, organized by chapter:
1. What Makes a Software Engineering Team Effective?
In this chapter, author introduces Project Aristotle that studied nearly 200 Google teams over two years to identify the factors for building effective teams. The researchers studied following factors that might impact team effectiveness such as team dynamics, personal traits, and skill sets. Project Aristotle identified five key dynamics that contribute to the effective teams:
Psychological safety so that team members can express opinions and ideas freely.
Dependability so that individuals trust each other to be dependable.
Structure and clarity about the goals, roles and responsibilities.
Meaning or purpose of their work.
Impact on how their work makes an impact to the organization or society.
The author shares numerous other insights from Project Aristotle and various studies, including:
Smaller teams are more effective, as evidenced by Amazon’s two-pizza team rule.
Diversity can be beneficial.
Clear communication based on psychological safety is vital.
Collaboration drives innovation, as evidenced by studies from Harvard, Stanford, and others.
The author recommends using motivation and intrinsic rewards to enhance performance, citing Daniel H. Pink’s book Drive, which identifies three key elements that motivate people:
Autonomy
Mastery
Purpose
The author outlines the following steps for building an effective team:
Assemble the right people, focusing on hiring for effectiveness and determining the optimal team size for the project/product. To foster a shared engineering mindset for an effective team, the author recommends looking for the following qualities:
Cares about the user and comprehends the problem domain, business context, priorities, and relevant technology.
Is a good problem solver.
Can keep things simple but cares about quality.
Can build trust over time, leading to increased autonomy and enhanced social capital.
Understand team strategy.
Can prioritize appropriately and execute independently.
Can think long term.
Can leave software projects in better shape.
Is comfortable taking on new challenges.
Can communicate effectively.
Promotes diversity and inclusion, fostering an environment where all opinions are valued equally based on psychological safety.
Enable a sense of team spirit with following foundation:
Define clarity on roles, and responsibilities.
Establish a shared purpose and communicate the overall project purpose and goals.
Foster trust among team members by encouraging open communication and feedback.
Lead effectively as highlighted by the Project Oxygen and leader should inspire, influence and guide team toward a shared goal. Leaders should prioritize strategic visibility by effectively communicating the team’s accomplishments and their impact on the business.
Sustain effectiveness (Growth culture) by supporting the factors of agility, purpose, and impact. Leaders should enhance learning and development opportunities for team members. Author recommends agile strategies, including adopting agile practices, promoting cross-functional collaboration, prioritize communication, building a culture of adaptability and implementing continuous integration and delivery. Additionally, the author emphasizes continuous improvement by fostering continuous learning and monitoring key performance indicators to evaluate team performance.
2. Efficiency Versus Effectiveness Versus Productivity
The author defines following key terms:
Efficiency is about doing things right to minimize waste and maximize output. It enhances productivity by measuring factors such as time to complete a task, resource utilization, bug fix rate, defect density, and quality.
Effectiveness is about doing the right thing and delivering the right outcome. Team effectiveness can be measured by customer satisfaction, business value, user adoption rate, ROI, and time to market.
Productivity is a measure of output over input. The team productivity can be measured by lines of code, function points, story points, and DevOps metrics.
The author repeats factors from the first chapter that are imperative for achieving higher efficiency and effectiveness such as team size, diversity, role clarity, communication, work environment, tools and technology and code health. Further, author differentiates between output and outcome:
An output is a deliverable resulting from engineering tasks. It can be measured by metrics such as throughput, velocity, quality, capacity, and code health.
An outcome is the actual result of the work done. It can be measured by metrics including business value, investment, user adoption rate. However, measuring outcome is challenging because accurate measurement is difficult. Other factors such as focusing too much on output, unreasonable deadline and burnout can diminish the outcome.
The author defines effective efficiency as “do the right things right” and suggests following practices:
Asking questions
Following standards
Collaborating
Using the right tools
Managing tradeoffs based on project timelines, budgets, long-term maintainability and user needs.
The author suggests following metrics for tracking productivity, which is a subset of efficiency:
Time to receive valuable user feedback and insights.
Collaborate through asynchronous communication.
Focus blocks
Novel problem solving
Code and bug fixing
Security and vulnerability
Upskilling
Automated testing
Context switching
Subjective well being
Meeting culture
At the individual level, the author recommends SMART goals and at the team level, the author recommends two techniques for defining productivity metrics:
Goal-question-metric (GQM) for driving goal-oriented measurement such as code quality, process efficiency, and team performance.
Objectives and key results (OKRs) for setting specific and measurable objectives and then identifying a set of key results that monitor how to get the objectives.
3. The 3E’s Model of Effective Engineering
In this chapter, the author introduces following stages to install effectiveness:
Enable effectiveness by defining what it means to your team or organization. General steps to define effectiveness include:
Identify team’s goals and objectives.
Determine what metrics are relevant to measuring success.
Set targets for each metric.
Define effectiveness in terms of outcomes.
Involve key stakeholders.
Keep the definitions simple and review them regularly.
Empower teams to shape standards.
Practice servant leadership.
Empower teams to adopt effectiveness. The author shares following methods for empowering teams:
Feed opportunities, starve problems with continuous delivery and feedback loops, kanban boards, and delegation.
Expand to scale effectiveness for larger teams. The shares following methods for expanding effectiveness:
Empowerment through trust by delegating responsibilities.
Effective delegation.
Streamlining communication.
Fostering a culture of autonomy.
Setting priorities and boundaries.
Mentoring and developing leaders.
Reflective practices.
In order to empower team effectiveness, the author suggests several strategies to improve individual effectiveness including:
Using delegation as a tool, not a retreat.
Building a culture of trust and transparency.
Using process optimization beyond command-and-control.
The author cites following habits from the Peter Drucker’s Effective Executive:
Know where your time goes.
Focus on what you uniquely can contribute to your organization.
Build on your own strengths, the strengths of your colleagues, and the team.
Concentrate on a few major areas where superior performance will produce outstanding results.
Make effective decisions.
Author then describes team effectiveness models such as:
Lencioni’s model
Patrick Lencioni’s model focus on the five dysfunctions that can hinder team effectiveness:
Absence of trust.
Fear of conflict
Lack of commitment
Avoidance of accountability
Inattention to results when team members put the needs of individuals above those of the group.
Tuckman’s model
The author cites the Bruce Tuckman’s model to describe the stages teams go through as they mature:
Forming when the team is coming together.
Storming when they get to know each other.
Norming when they find a relative groove.
Performing where the magic happens.
Adjourning when the team disbands after completing the objectives.
The author also cites other strategies from a data team from Gitlab, Andy Grove’s book and his experience from Google including:
Using the right tools and processes
Reducing meetings and protecting the team
Securing executive buy-in and resources
Hiring and employee development
Planning for growth
Focusing on core business value
Being mindful of career path and priorities
Identifying high-leverage activities as defined by Grove in his book that can enable individuals and organizations to do more with less.
Standardize and share
Reuse
Automate right things
The Three Always of Leadership
In order to expand effectiveness, the author describes several challenges such as people, broader domain, distractions and complications. The author cities Ben Collins-Sussman’s techniques called the three always of leadership:
Always be deciding to make timely and well-informed decisions. A three-step approach by Ben Collins-Sussman include:
Identify the blinders or mental blocks.
Identify the key trade-offs.
Decide, then iterate.
Always be leaving by reducing the “bus factor” and ensuring that you don’t become the single point of faiure (SPOF). A leader can divide the problem space and delegate the subproblems to future leaders.
Always be scaling is about protecting precious resources such as time, attention, and energy. The author suggests being proactive instead of reactive from escalations, embracing the cycle of struggle and success, managing energy by self-care and recharge regularly.
The author cites Jeff Bezos lessons about making high-quality and high-velocity decisions. Though, the author does not mention Jeff Bezos’ advice on one-way vs two-way decisions but I have found it to be very valuable when making decisions.
4. Effective Management: Research from Google
In this chapter, the author describes findings from Project Oxygen and Project Aristotle.
Project Oxygen
Project Oxygen studied the behavior of high-performing managers and identified following key behaviors:
is a good coach who offers thoughtful feedback and guidance. Other attributes include regular one-on-ones, tailed coaching, asking good questions to help people think, demonstrate empathy, motivate by setting high standards and lead by example.
Empower team without micromanaging. A good manager offers stretch assignments, intervenes judiciously, allows autonomy, encourages innovation, advocates for the team and provides constructive feedback.
Creates an inclusive team environment, showing concern for success and well-being. A good manager makes new team member feel welcomed, builds rapport within the team, is an enthusiastic cheerleader to support the team, upholds civility, cres about the well-beings of team members, shows support and creates psychological safety on the team.
Is productive and results oriented and drives team achieving goals by assembling a diverse team, translating the vision/strategy into measurable goals, structuring the team, defining clear expectations and ownership, removing any roadblocks, and planning for potential risks.
Is a good communicator who encourages open discussion, aims to be responsive, shares information from leaders honestly, behaves calmly, and listens to other team members.
Supports career development and discusses performance. A good manager communicates performance expectations, gives employees fair performance evaluations, explains how compensation is tied to performance, advices employees on career prospects, and helps team members to grow. For example, Google uses GROW (Goal, Reality, Option, Will) model to structure career development conversations.
Has a clear vision/strategy for the team. A good manager creates a vision/strategy to inspire team members, aligns the team’s visions/strategy with the company’s, involves the team in creating the vision where it makes sense, clearly communicates the vision, helps the team understand how the overall strategy translates to its work. Google recommends defining core-values, purpose, mission, strategy and goals for the teams.
Has key technical skills to help advice the team. A good manager helps the team navigate technical complexity, understands the challenges of the work, uses technical skills to help solve problems, learns new skills to meet business needs, bridges the gap between technical and non-technical stakeholders.
Collaborates across company by doing: Prioritize collective goals and outcomes, seek opportunities to partner with other teams, role-model collaboration across teams, hold team accountable for following company practices/policies, and take art in the company’s culture and community.
Project Oxygen helped increased employee performance, satisfaction, better decision making and collaboration, and reduced employee turnover.
Project Aristotle
As mentioned in chapter 1, the Project Aristotle found the five critical dynamics in building successful teams:
Psychological Safety for feeling safe to speak up, which was first proposed by Amy Edmondson, which is distinct from “group cohesiveness” that is about getting along with each other as a group. In order to promote psychological safety in the teams, a manager should approach conflict as a collaborator, not an adversary, speak human to human, anticipate reactions and plan countermoves, replace blam with curiosity, ask for feedback on delivery, and measure psychological safety.
Dependability for fostering trust. Dependable team members demonstrate genuine intentions, accountability by taking ownership of their tasks and responsibility for their actions, sound thinking, and consistent contribution. As a leader, you can lead by example, promote collaboration and interdependence, clearly define roles and expectations, encourage open communication, and provide supportive feedback.
Structure and clarity so that team members understand what is expected of them. At Google, teams are encouraged to align their OKRs with the company’s overarching goals. The teams identify key results that would have the greatest impact on advancing the organizational OKRs. The author also suggests RACI matrix to bring structure an clarity to assigning responsibilities to various roles. It stands for Responsible (who do the work), Accountable (who owns the work to be done), Consulted (who reviews the work), and Informed (stakeholders). In past, I have used the single-threaded-leader (STL) or Directly-Responsible-Individual (DRI) roles for defining similar structure for ownership of the overall project.
Meaning refers to a sense of purpose, fulfillment, and progress at work.
Impact of the work that can highlighted by connection to organization objectives, working toward a team vision, understanding the impact on clents and users, and linking performance to outcomes.
Project Aristotle taught empathy and showed team wants to feel that their work matters.
5. Common Effectiveness Antipatterns
In this chapter, the author reviews antipatterns to effectiveness categorized by individual, practice-related, structural and leadership.
Individual Antipatterns
Following are the most common individual antipatterns:
The specialist when a person is strongly identified with a particular module or feature. It is a high-risk antipattern that leads to higher bus-factor and limits professional growth. A leader should encourage team members to develop expertise in different areas, document exceptional cases and set learning goals.
The generalist arises when team members spreads themselves too thin and dilute expertise. A leader must task the generalist with a specific area of the project, focus on honing their expertise in areas that aligns with their strengths, foster a collaborative environment and promote continuous learning and pursuit of master within specialized domain.
The hoarder antipattern occurs when a team member does not trust their team and does not share the work consistently. It disrupts team’s collaborative rhythm, hampers feedback loop and hoarder becomes a bottleneck during the code review stages. A leader should encourage frequent commits that show ongoing progress, promote daily stand-up meetings, advocate for early and frequent code reviews.
The relentless guide when an engineer offers assistance beyond its intended scope and other team members may ask engineer’s guidance, even for minor tasks. A leader should encourage team members to attempt problem-solving independently, foster peer learning by pairing individuals, organize regular knowledge-sharing sessions, and assign the guide to challenging tasks.
The trivial tweaker when an individual consistently indulges in minor code changes and refactoring. A leader should assign challenging task to the trivial tweaker, encourage the engineer to evaluate the potential impact of code changes, and align code changes with the project’s objectives.
Practice-Related Antipatterns
Practice-related antipatterns include:
Last-minute heroics when issues and challenges are often addressed hastily and heroically just before a release. It can lead to lack of feedback, hidden technical debt, decreased quality, and dependency on heroes. A leader should encourage effective planning, transparent communication, prioritized backlog, and sustainable pace.
PR Process Irregularities such as rubber-stamping, self-merging, long-running PRs, and last-minute PRs can introduce inefficiencies, decrease code quality and hinder collaboration. A leader should promote thorough review and accountability, diverse approvals, timely feedback and closure, and intermediate checkpoints.
Protracted Refactoring when the refactor stretches beyond its expected timeline due to escalating scope and causes progress delays, resource drain and diluted focus. A leader should identify the cause, set time constraints, implement peer review and closure, and foster open communication.
Retrospective Negligence when teams skip retrospectives due to time constraints, shorten sessions, lacks structure, avoid discussing conflicting viewpoints, lack follow-ups, and surface-level analysis. A leader should prioritize retrospectives regularly, allocate adequate time, embrace structure (start, stop, continue or mad, sad, glad), encourage diverse participation, implement action items, and focus on root causes.
Structural Antipatterns
Structural antipatterns include:
Isolated clusters where subteams or groups form within a larger team, leading to insular pockets of collaboration. It can lead to knowledge fragmentation, missed insights, stagnant growth, and reduced cohesion. A leader must encourage interdisciplinary sessions, rotating roles, cross-domain initiatives, and open communication channels.
Knowledge Bottlenecks where vital knowledge and expertise is concentrated to a limited individuals leading to higher bus factor, single point of failure, dependency, knowledge silos, and communication gaps. A leader should promote cross-training, knowledge sharing, pair programming, rotation of responsibilities, and mentorship.
Leadership Antipatterns
There are cases when the leader’s actions become antipatterns such as:
Micromanagement where managers exert unnecessary control that leads to perfectionist bottleneck, prescriptive direction, guardians of information, stiffled innovation, low morale, slow progress, limited growth, and uninformed decisions. In order to remedy these issues, leaders should increase ownership, enhance creativity, improve morale, foster innovation and act as a glass barriers to shield their teams.
Scope Mismanagement where leaders struggle to manage the scope of a project due to incessant change requests, lack of prioritization, inflated workload, delayed deliverables, and reduced quality. A leader should change evaluation process, promote effective communication, introduce scope freeze periods, regular reviews, empower decision making, and escalation.
Planning Overkill where excessive time and effort are invested in planning due to overanalysis, endless design iterations, extensive documentation, delayed development, and inflexibility. A leader should instead promote realistic scope, iterative refinement, flexibility in execution, progressive elaboration, and risk management.
Skeptical Leadership where leaders develop unwarranted insecurities about the team’s competence. A skeptical leader can build insecurities with unfounded fears, insecure technology decisions, passing the pain, constant reassurances, diminished confidence, and slowed progress. A leader must restore productive collaboration with evidence-based decisions, effective communication, transparency, time management, and confidence building.
Passive Leadership is characterized by maintaining the status quo, avoiding disruptions, stagnation, lack of direction, missed opportunities, limited accountability, and resistance to change. Leaders should instead set clear expectations and promote open communication, empowerment, innovative culture, and accountability
Underappreciation when leaders fail to acknowledge and celebrate commendable actions. Leaders should implement a practice of regular recognition, timely feedback, and appreciate publicly.
6. Effective Managers
This chapter focuses on the operational role of a manager and provides tips for time management, people management and project management.
From Engineering to Management
Transitioning from an engineering to a management position can be challenging and new managers may fail to empower team members, micromanage or find difficulty with prioritizing people management over technical expertise.
Getting Started
Following tasks are recommended for a new manager:
Meeting with team members
Project assessment
Understand the tech stack
Address immediate concerns
Identify quick wins
Start networking
Start prioritizing
Setup essential communication channels
Reflect and engage in self-care
Manage imposter syndrome
Defining a Strategy
A new manager can focus on:
Long-term strategic vision based on OKRs or other frameworks.
Transparent tracking of objectives.
Data-driven decision making.
Calculated risk management. You may use SWOT (Strengths, Weaknesses, Opportunities, and Threats) to assess a decision.
Managing Your Time
The author recommends following techniques:
Planning by time blocking, chunking similar tasks (Pomodoro), planning communication by using labels and filters to prioritize and categorize messages.
Execution by mentoring your team members to handle specific tasks, delegation, learn to say “no”.
Assessment by calendar audits, reflect and adjust.
Understanding and Setting Expectations
Leaders can elaborate key components of the expectations from the team members.
What results are expected from me? Critical factors include regular and open communication, setting goals (OKR or SMART), prioritization, and self-assessment by evaluating performance against the expectations.
What results do I expect from team members? The author suggests clear communication, individual meetings, goal alignment, and documenting expectations.
Communication Essentials
To ensure consistent communication, the author suggests a clear management strategy with various methods of communication.
Team meetings where frequency depends on the overall duration planned for the project. Each meeting should have clear objectives, is focused and time-bound and promote active participation and inclusivity.
One-on-Ones should focus on the team members and their needs. You should provide specific, useful and actionable feedback (both positive and negative).
Messaging may use various channels such as email, instant messaging, and task management software.
Nonverbal Communication based on body language, facial expressions, and physical proximity.
People Management
People management poses several challenges such as tech talent competition, skill diversification, remote work dynamics and expectations. The author suggests following areas for people management:
Hiring by clearly defining job roles and essential skills.
Performance evaluation that includes career goals, professional development, additional responsibilities, challenges and achievements, feedback and improvement, and work-life balance.
Attrition Management by understanding the reasons, using feedback from exit interviews, and smooth transition of knowledge and responsibilities.
Mentorship and Coaching that can avoid attrition by better cultural fit and alignment, cost and time savings, and employee development and morale.
Managing Challenging Projects
The author suggests following key considerations for navigating through challenging projects:
Agile approach
Scope management
Prototype
Decisive but flexible
Quality control
Work-life balance
Communication
Removing blockers
Celebrating successes
Managing Team Dynamics
These challenges include:
Individual idiosyncrasies and diverse teams
Remote teams
Conflict Resolution
Enabling Mastery and Growth
A manager can facilitate growth by following:
Harnessing downtime for growth
Empowering growth amid high-workload periods
Networking Essentials
The author suggests following techniques for building relationships:
Knowledge-exchange
Problem-solving
Professional growth
Collaboration opportunities
Other things to network effectively include:
Be genuine
Listen actively
Follow up
Maintain regular contact
Diversify your network
7. Becoming an Effective Leader
Leadership involves mentorship, coaching and setting a visionary course. The author cites John Kotter who distinguishes leadership from management where leadership produces change and movement, while management produces order and consistency. The author defines following focus areas for effective leaders and managers.
Effective leaders focuses on establishing direction, align people, motivate and inspire.
Effective managers plan and budget, bring organization structural, and control and problem-solving.
The author suggests following approaches to combine managerial responsibilities with leadership qualities are as follows:
Strategic vision by ensuring decisions are directed towards the correct long-term goals.
Motivational leadership by understanding what motivates each team member.
Empowerment and trust.
Adaptability and change management.
Leadership Roles
The author defines following different types of leadership roles:
Technical Lead who provides technical guidance and direction to the engineering team. The key responsibilities include guide technical design and architecture, set coding standards and best practices, lead troubleshooting of complex bugs and issues, make key technical decisions with engineering trade-offs, do hands-on coding alongside the team, serve as a mentor for development skills, and ensure deliverables meet the quality bar.
Engineering Manager oversees a team of engineers, ensuring delivery of projects. The key responsibilities include people management, manage processes, align team with organizational priorities, unblock resources, technical oversight, stakeholder interaction, and strategic work prioritization.
Tech Lead Manager (TLM) oversee a group of engineers at Google. The key responsibilities include blending people management with hands-on technical leadership, coach and develop engineers on coding skills, establish technical standards and architecture, help unblock developers when they are stuck, focus on higher-priority technical work, advocate for the team while coordinating cross-functionality, make technical decisions weighing various constraints, and provide mentorship and guidance.
Assessing Your Leadership Skills
The author defines a list of critical and desirable traits that distinguish exceptional leaders.
Critical Traits
Technical expertise is a critical skill for both engineer and team leaders.
Agility refers to ability to learn, unlearn and adapt to changing conditions.
Clear Communication is essential to share vision. You can practice active listening and seek feedback from the team.
Empathy by putting yourself in your team members’ shoes to understand their perspectives.
Develop a clear and compelling vision
Delegation
Integrity
Desirable Leadership Traits
Self-Motivation
Drive to maintain focus on the end goals and avoid distractions
Integrity by being honest, truthful, and ethical
Fairness to ensure that all individuals in the group are treated fairly and impartially.
Humility
Courage (virtue between cowardice and rashness)
Accountability by taking ownership of the decisions and outcomes
Influence to motivate and inspire team members
Caring for others
Self-awareness
Leading Effectively
The author describes practices and principles for effective leadership:
Leadership Style
Transformative leadership to inspire and motivate team to achieve extraordinary results.
Democratic leadership emphasizes involving team members in the decision-making process.
Servant Leadership prioritizes the needs and well-beings of team members based on empathy, humility, and stewardship.
Combining different styles
Also known as situational leadership based on the specific situation.
Environment-based leadership
Leadership based on size, scope, and complexity of the organization, product, or project.
Strategizing
Strategizing provides a clear roadmap that aligns team’s efforts with organizational goals.
Visualizing the future
It allows you to anticipate challenges and make informed decisions. The author recommends pointers to 360-degree visualization such as environmental scanning, scenario scanning, risk assessment and diverse perspectives.
Defining a strategic roadmap
It involves outlining a clear and cohesive plan including initiatives to be launched and milestones. The author recommends:
Do maintain clarity and simplicity.
Do set measurable milestones.
Do build flexibility and adaptability into the roadmap.
Don’t treat the roadmap as static document.
Don’t lack stakeholder involvement.
Immersive strategic thinking
Immersive strategic thinking is a dynamic and deliberate cognitive process that involves dedicated and uninterrupted periods for deep reflection and data analysis. You can use strategic retreats, digital detox or quiet spaces to facilitate this process.
Ruthless prioritization
It encourages to say “no” so that you maintain a clear and unwavering focus on what truly matters.
Playing the Part
Here are a few things to continuously apply:
Relentless communication
The author recommends regular communicating following aspects:
Long-term goals
Focus areas
Context for tasks
Milestones and achievements
Challenges and roadblocks
Changes in strategy or direction
Opportunities for learning and development
Organizational updates
Structuring for innovation
This involves the following:
Flatten unnecessary hierarchy
Informed decisions
Emphasized speed
Adopt minimal viable processes
Create innovation time
Facilitate ideation sessions
Psychological safety
It involves proactive measures to allow unconventional ideas and celebrate failures as learning opportunities.
Leading diverse teams
A few strategies for this include the following:
Address unconscious bias
Promote diverse hiring practices
Cultivate an inclusive work culture
Identifying potential and developing capability
Recognize that talent development is not a one-size-fits-all approach.
Understand that there is value in small gains.
Cultivate a diverse and vibrant collective of individuals.
Provide effective feedback, which is specific and actionable. Balance positive and constructive feedback. Tailor feedback to the individual. Follow up and support.
Balancing technical expertise with leadership skills
Develop technical expertise by setting aside dedicated time.
Enhance leadership skills with workshops/courses, mentorship and regular reflection. Develop strategic thinking, decision making and problem solving. Cultivate strong communication, collaboration and interpersonal skills.
Mastering the Attitude
The author recommends embracing the values and demonstrating commitment to the success of the projects. The key components include:
Trust and autonomy
You can grant autonomy via ownership, flexible work structures and decision making authority. You can establish following guardrails:
Clear communication channels and protocols
Well-defined roles and responsibilities
Regular check-ins and progress reviews
Established coding standards and best practices
Documented decision-making processes
Modeling behaviors
It involves leading by example and embodying the desired mindsets and values.
Demonstrate a growth mindset
Demonstrate inclusiveness
Demonstrate integrity
Making decisions with conviction
Avoid planning overkill antipattern and make difficult choices with conviction.
Data-driven leadership
Data-driven leadership consists of leading team based on real-time and accurate data and analytics. Some examples of metrics and KPIs include:
Velocity
Cycle time
Defect density (number of defects per unit of code or release).
Code coverage
Customer satisfaction
You must establish clear metrics and KPIs, foster data-driven culture and communicate data effectively.
Adapting to change
The author recommends 4A’s framework to lead in complex and uncertain environments:
Anticipation
Articulation
Adaption
Accountability
Evolving effectiveness into efficiency
Leaders can view leadership practices with following angles:
Team efficiency.
Process streamlining.
Strategic efforts to enhance effectiveness and balancing operational efficiency with the capacity for creative problem-solving.