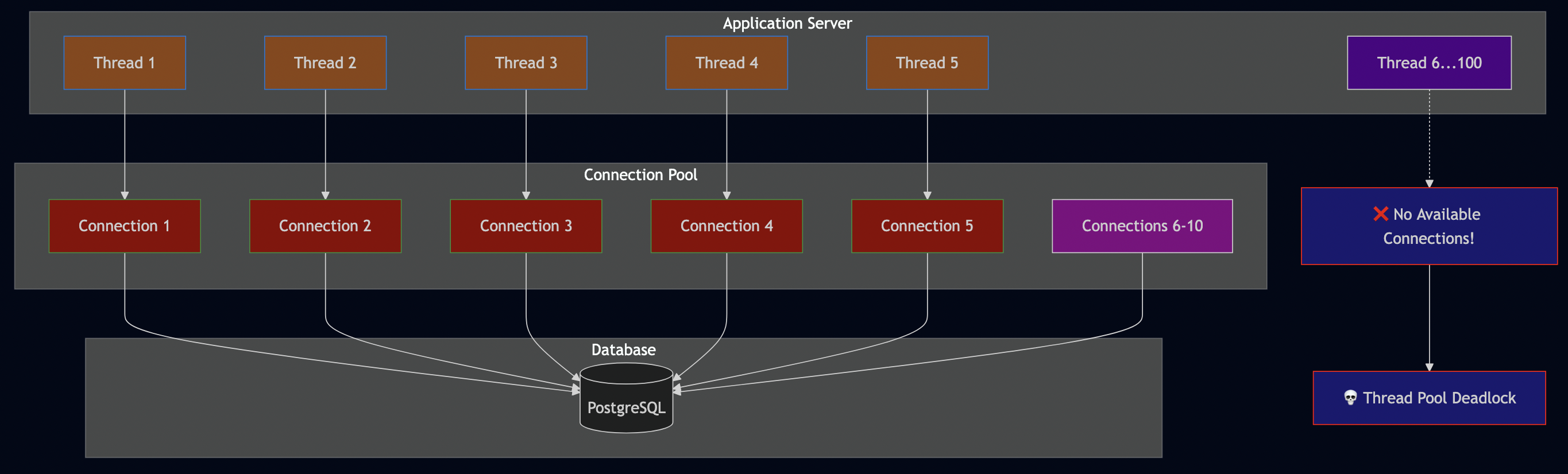
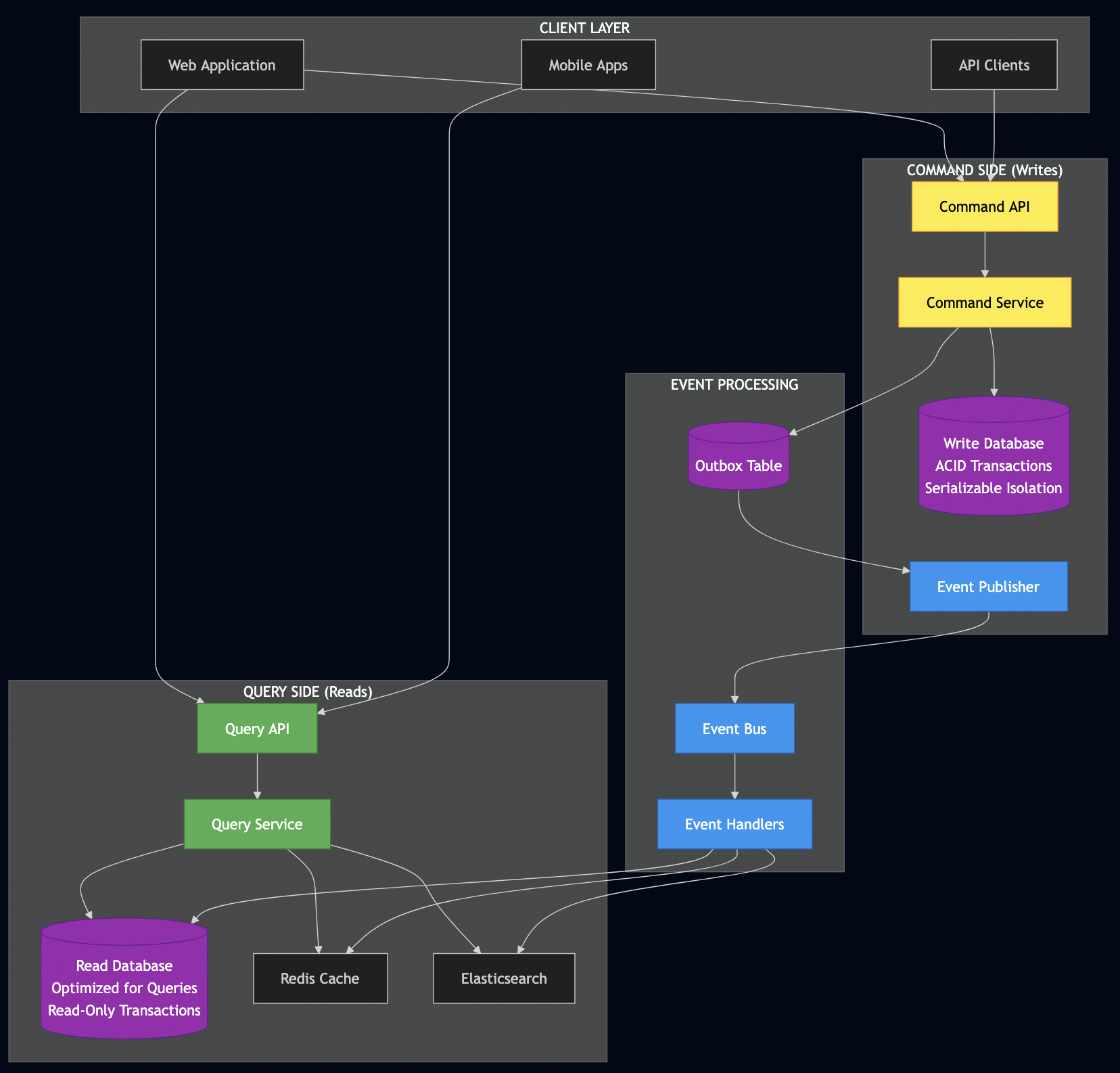
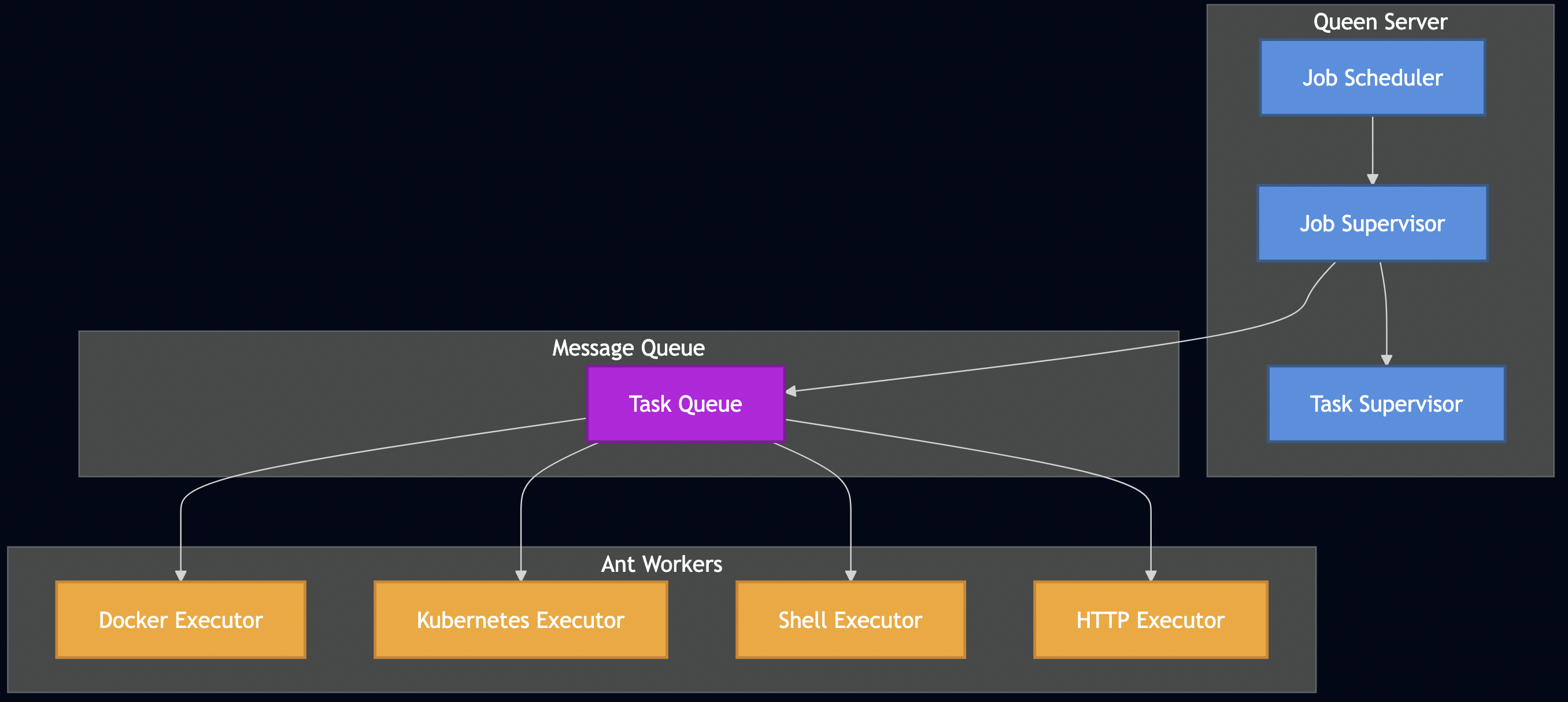
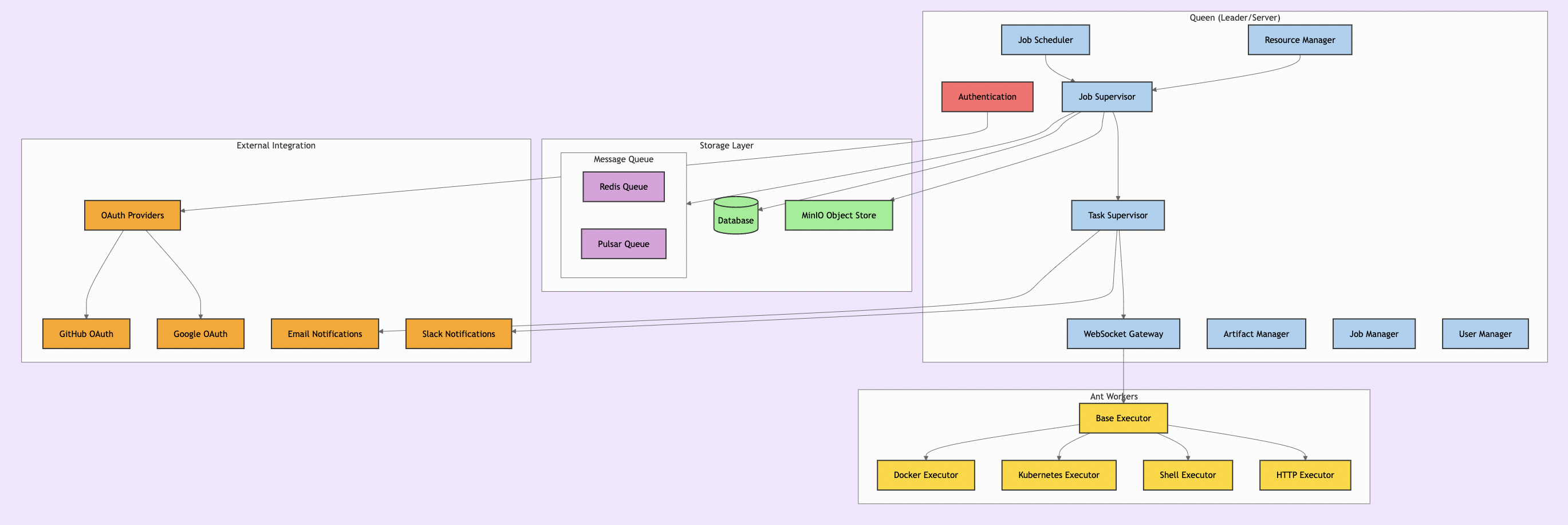
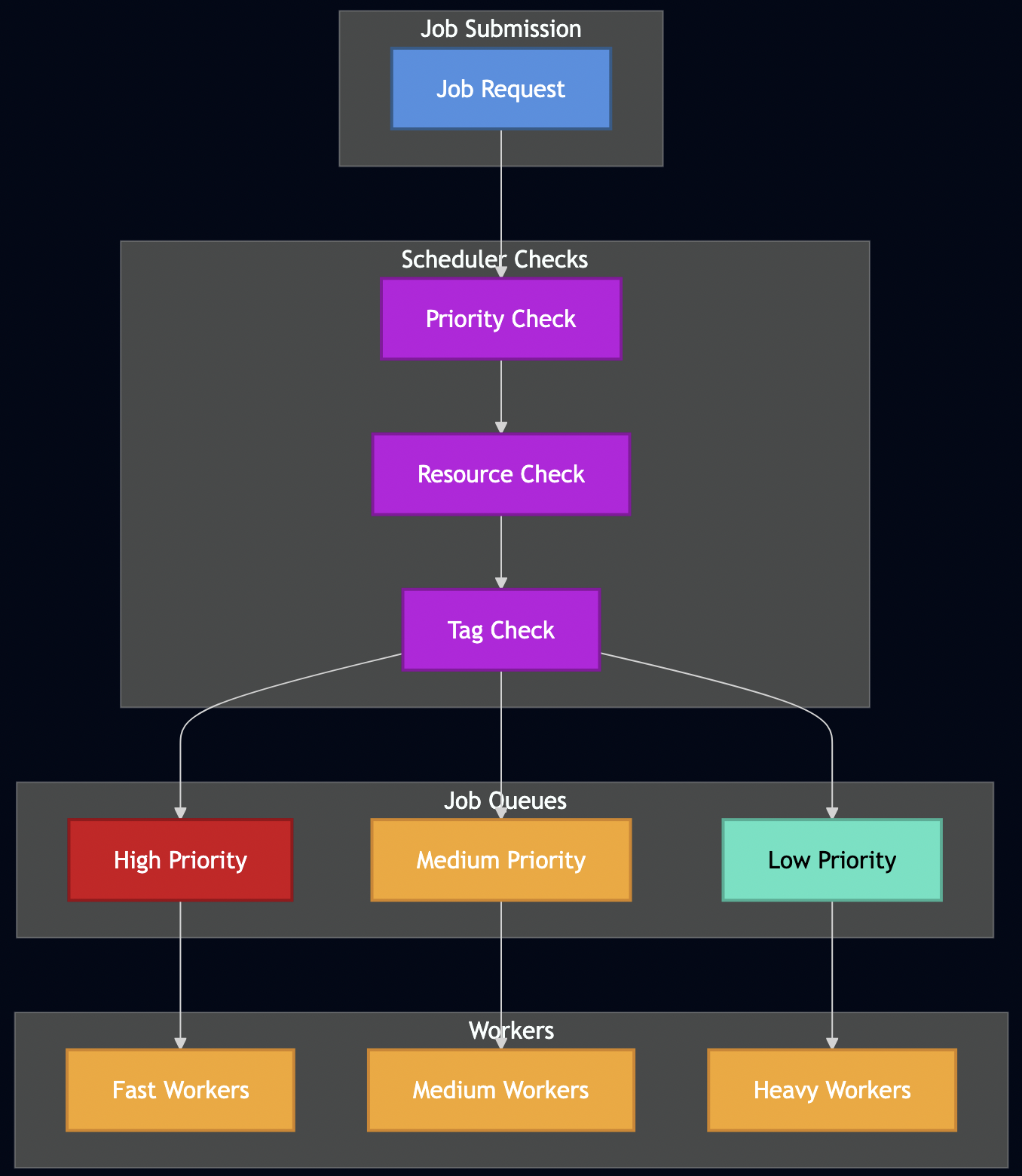
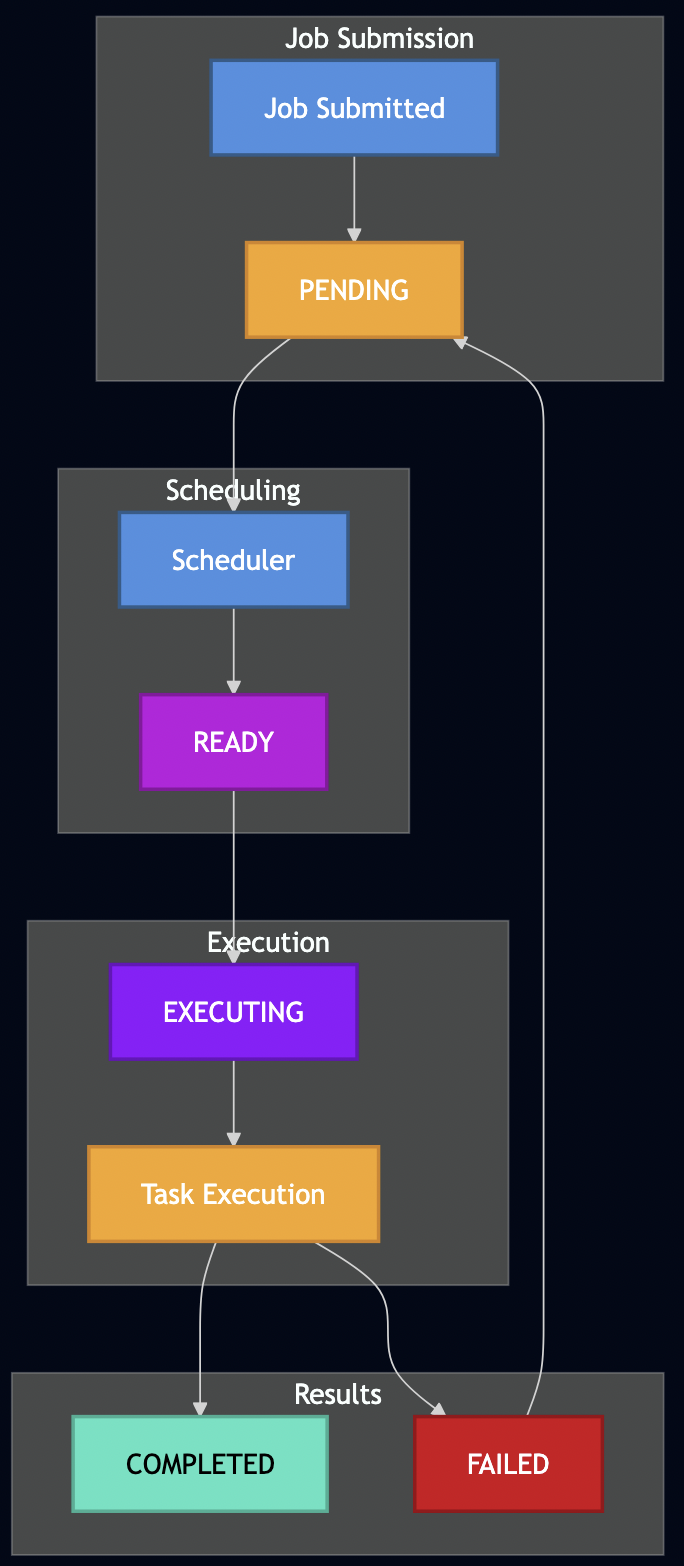
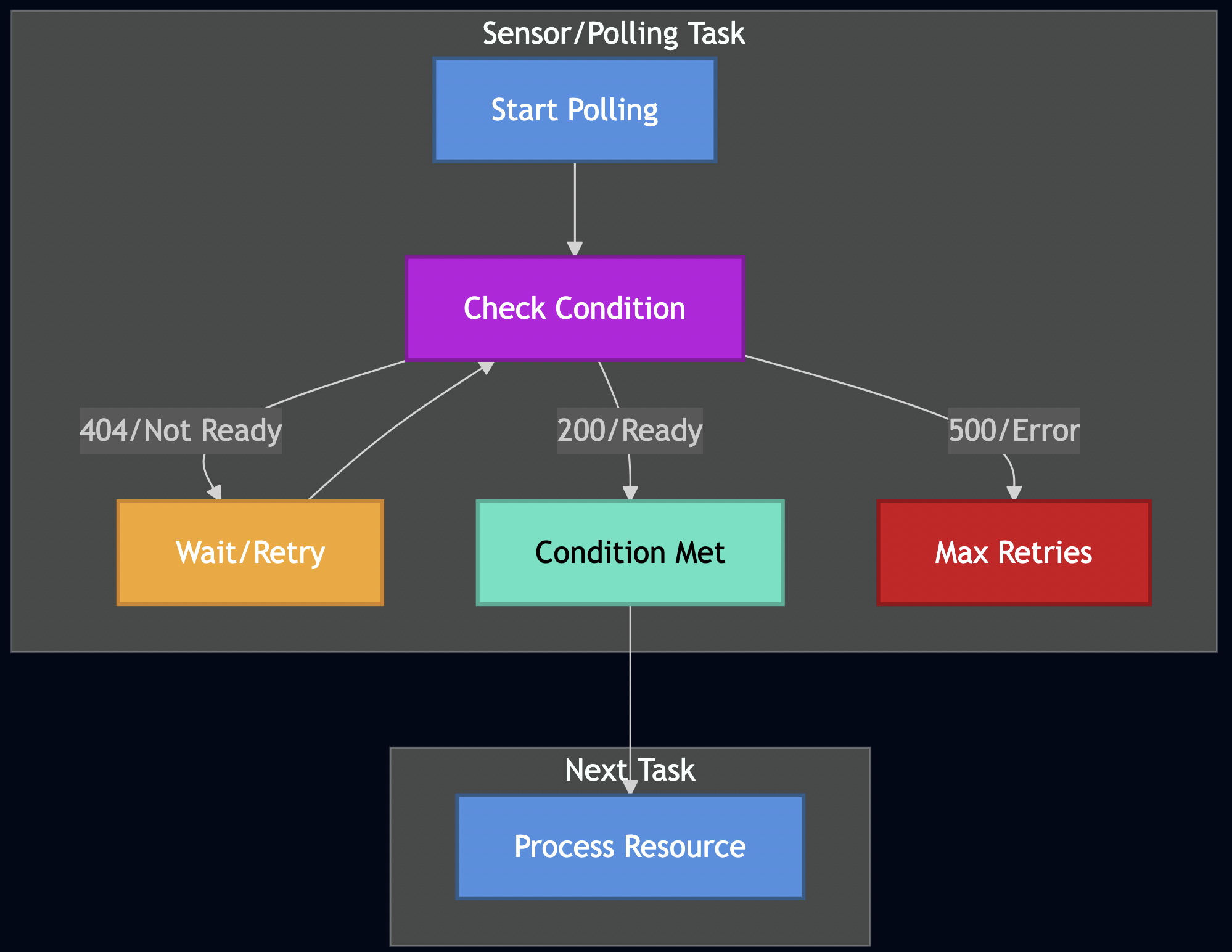
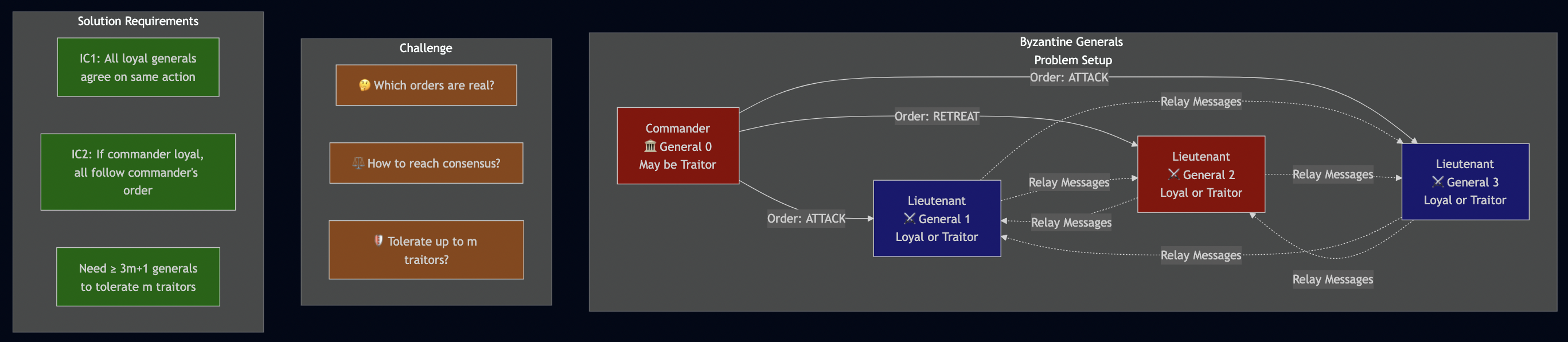
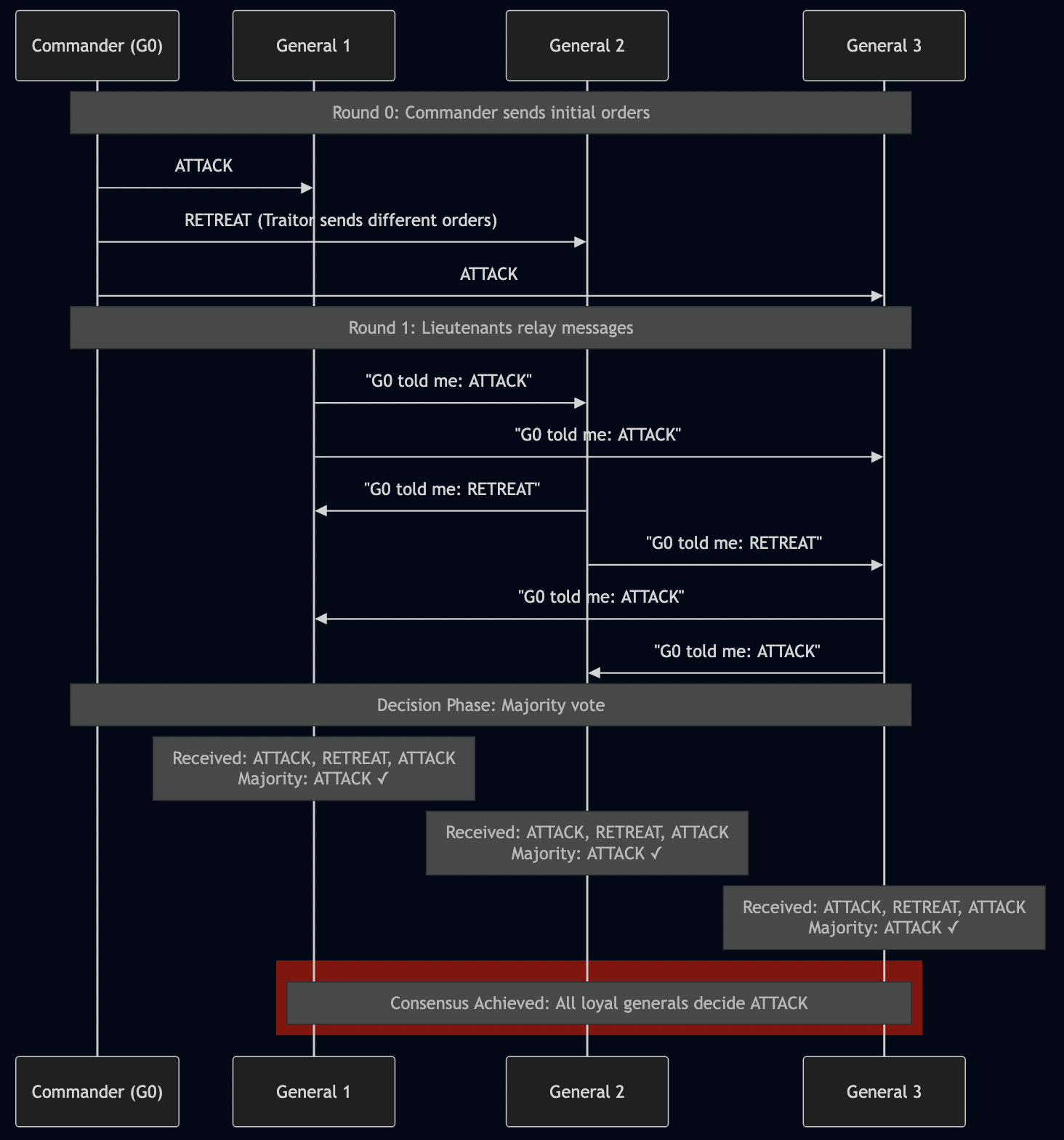
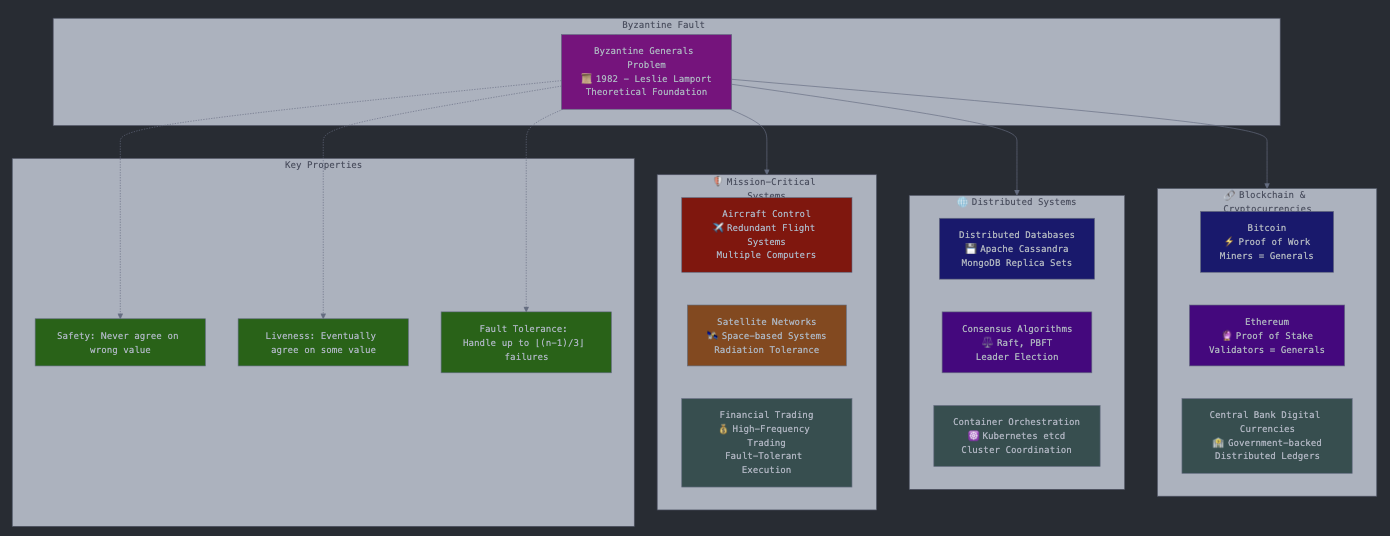
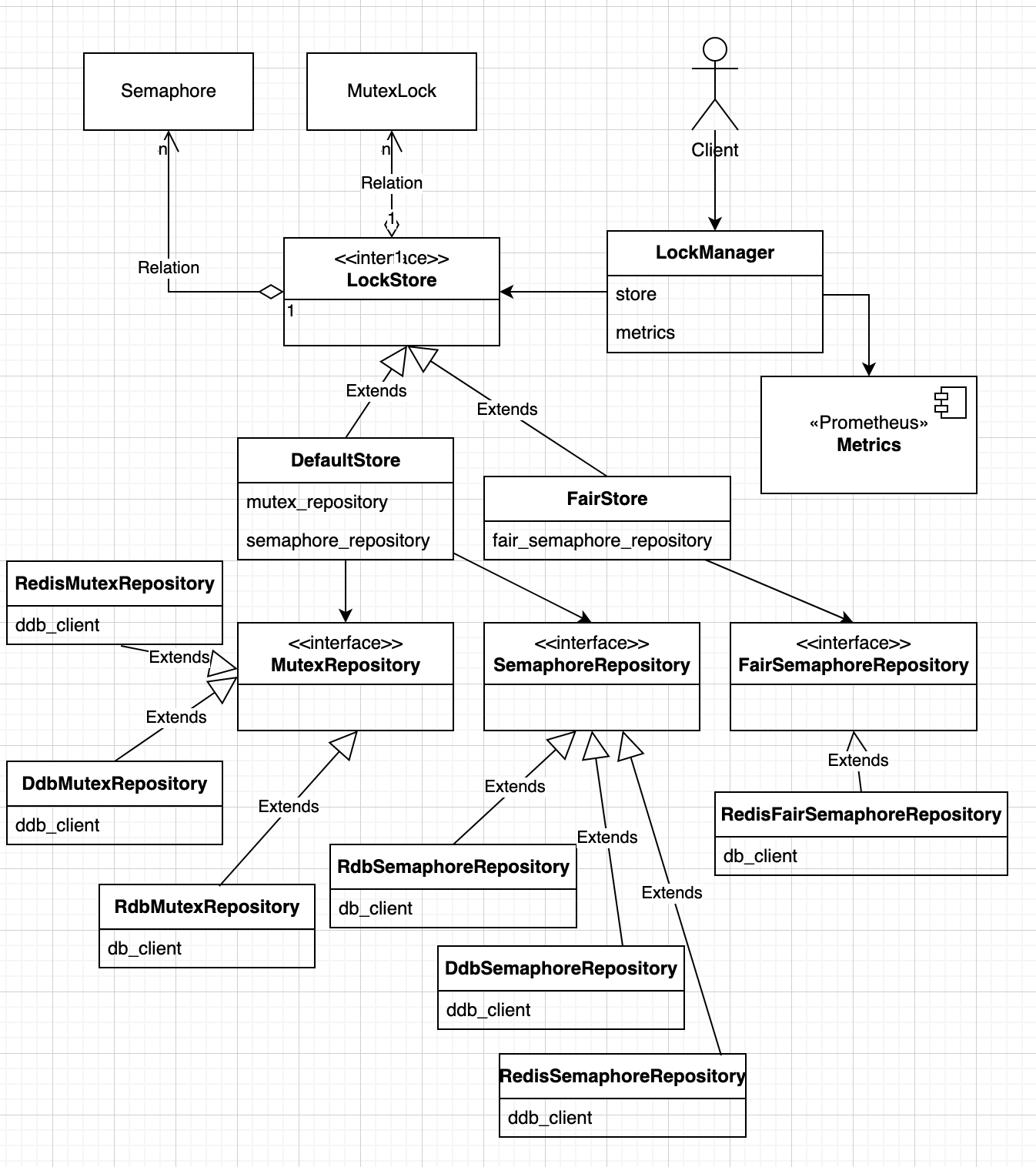
I. Introduction
Debugging a production incidents is much harder when dealing with a system with complex state management. For example, you might see a worker node is simultaneously “draining” and “upgrading” while flagged as “ready to restart.” or the heartbeat buffer filled with 100,000 metrics and silently dropped the overflow. In other cases, you might see a config deployment shows “success” in the database but never actually deployed because the error got swallowed by .catch(NOOP) somewhere. I’ve seen it in most legacy codebase I’ve worked on, e.g., in one system I found:
- 441 instances of
.catch(NOOP): errors silently swallowed - 506 mode checks: scattered everywhere, e.g.,
if (isLeader)... else if (isWorker)... - 64 possible boolean combinations: for worker state, of which only 5 are valid
- Race conditions: in shared state with no synchronization
- 816 files: coupled to global singletons
Here is the core thesis: most production incidents aren’t algorithmic bugs. They’re states that shouldn’t exist. The system entered a configuration nobody intended, no test covered, and no monitoring caught. Algebraic Data Types (ADTs) and Algebraic Effects are the tools that make those impossible states unrepresentable in code. Not “less likely.” or “caught by tests.” but impossible to express.
II. What Are Algebraic Data Types?
Forget the word “algebraic” for a moment. It just means “composed of parts using AND and OR.” That’s it.
Product Types: AND
A product type is a structure where ALL fields must be present at the same time. You use these every day:
struct WorkerConnection {
id: String,
address: String,
port: u16,
last_heartbeat: Instant,
}Every WorkerConnection has an id AND an address AND a port AND a last_heartbeat. It’s called “product” because the number of possible values is the product of each field’s possibilities.
Sum Types: OR
A sum type is a value that is ONE of several variants. This is the powerful one most codebases miss:
enum TrafficLight {
Red,
Yellow,
Green,
}A traffic light is Red OR Yellow OR Green. It is never Red AND Green at the same time. It’s called “sum” because the number of possible values is the sum of each variant. The critical feature is exhaustiveness checking. When you pattern-match on a sum type, the compiler forces you to handle every variant. Add a new one and the compiler shows you every place that needs updating:
fn action(light: &TrafficLight) -> &str {
match light {
TrafficLight::Red => "stop",
TrafficLight::Yellow => "caution",
TrafficLight::Green => "go",
// Add FlashingRed and this won't compile until you handle it here
}
}Why This Matters: Making Illegal States Unrepresentable
Here’s the practical payoff. Look at actual legacy code managing worker nodes:
// Legacy pattern
struct WorkerNode {
current_action: Option<ExclusiveAction>,
reconfig_in_progress: Option<ClusterRequest>,
upgrade_in_progress: bool,
draining: bool,
allow_restart: bool,
restart_on_exit: bool,
}Six independent boolean fields. That’s 2^6 = 64 possible combinations. But the system only has about 5 valid states: idle, configuring, upgrading, draining, or restarting. The other 59 combinations are bugs waiting to happen. What does upgrade_in_progress = true AND draining = true AND reconfig_in_progress = Some(request) mean? Nobody knows and no test covers it. Now the same thing as a Rust enum:
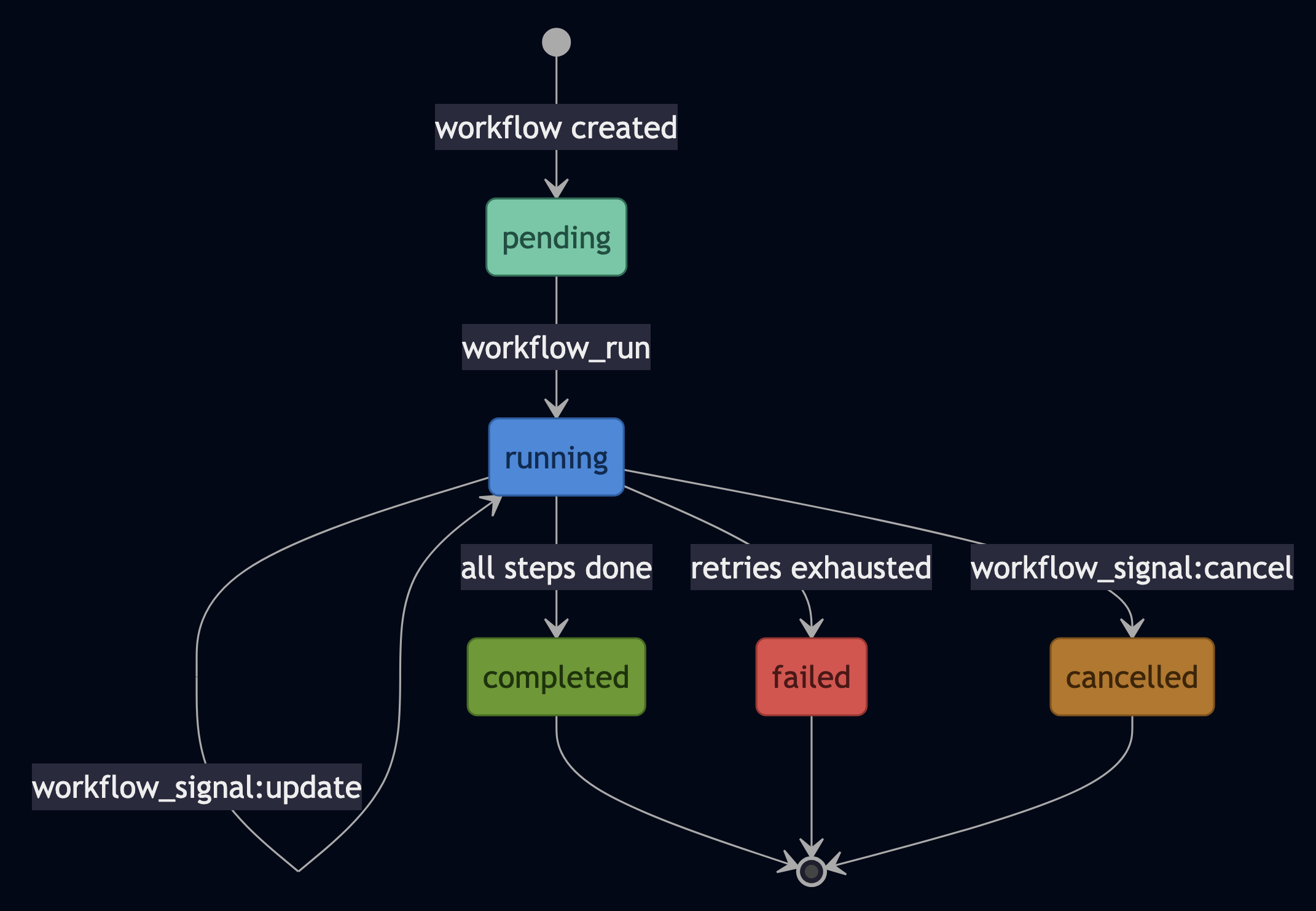
enum WorkerState {
Idle,
Configuring { request: ClusterRequest },
Upgrading { version: String },
Draining { reason: String },
Restarting,
}Five states but the 59 impossible combinations literally cannot be expressed. You cannot write code that puts the worker in an invalid state because the type won’t compile. This isn’t about “good practice.” It’s about making an entire class of bugs impossible at compile time. The compiler becomes your 24/7 code reviewer, rejecting every impossible state before the code ever runs.
It Costs Real Money
- Double settlement in banking: A payment system tracks settlement with
isAuthorized,isSettled,isReversed. A race condition sets bothisSettled = trueandisReversed = trueat the same time. Result: the same transaction is both settled and reversed so money moves twice. With a sum type (Authorized | Settled | Reversed | Disputed), that combination cannot exist. - Ghost billing in telecom: A session tracker uses
isActive,isBilled,isTerminated. A network glitch terminates the session but the billing flag was set a millisecond before termination. Result: terminated sessions generate charges for hours. With a sum type (Active { startTime } | Terminated { endTime } | Billed { amount, endTime }), a terminated session cannot be in a billable state.
These aren’t hypothetical. They’re the kind of bugs that cost millions in reconciliation and regulatory fines. The root cause is always the same: boolean flags that allow impossible combinations.
Immutability Makes This Even Better
When state is immutable, you can’t accidentally corrupt it from another part of the code. But how do you “change” immutable data? You copy it:
fn update_progress(state: &JobState, new_progress: u8) -> JobState {
JobState {
progress: new_progress,
updated_at: Instant::now(),
..state.clone() // copy everything else
}
}
let state1 = JobState { phase: Phase::Running, progress: 50, worker_id: "w-1".into() };
let state2 = update_progress(&state1, 75);
// state1.progress is still 50 — no other code sees a half-updated stateIn Rust, this is enforced by the ownership system: you can have either one mutable reference OR many immutable references. Race conditions on shared state become a compile error, not a runtime bug.
III. ADTs Applied to Real Problems
Problem 1: Mode Detection Hell
Production systems support multiple deployment modes: leader, worker, edge, standalone. The result in the legacy codebase? Mode checks everywhere:
// 500+ instances of this scattered throughout
const configHelperMode = ProcessInfo.isConfigHelperMode();
const workerProcessMode = ProcessInfo.isWorkerMode();
const apiProcessMode = !configHelperMode && !workerProcessMode;
if (configHelperMode) { return runConfigHelper(...); }
if (workerProcessMode) { return ProcessMgr.initWorkerProcess(...); }
if (ServiceInfo.isService(role)) { return Service.initServiceProcess(...); }
if (isProxyNode(distMode)) { /* ... */ }
if (isSearchSupervisor(distMode)) { /* ... */ }
if (isLeader) { /* ... */ }
else if (isManaged(distMode)) { /* ... */ }
else if (isStandalone(distMode)) { /* ... */ }The problems: adding a new mode requires finding and updating all 506 sites, missing one means silent incorrect behavior, and it’s easy to create contradictory states (isLeader && isWorker). The fix: one decision point at startup, exhaustive matching everywhere else:
enum AppMode {
Leader { config: LeaderConfig },
Worker { leader_id: String },
Edge { leader_id: String },
Standalone,
ConfigHelper { group_id: String },
SearchSupervisor { cluster_id: String },
}
// ONE place where mode is determined — at startup
fn determine_mode(env: &Environment) -> AppMode { ... }
// EVERYWHERE else — exhaustive matching
fn bootstrap(mode: AppMode) -> Application {
match mode {
AppMode::Leader { config } => bootstrap_leader(config),
AppMode::Worker { leader_id } => bootstrap_worker(&leader_id),
AppMode::Edge { leader_id } => bootstrap_edge(&leader_id),
AppMode::Standalone => bootstrap_standalone(),
AppMode::ConfigHelper { group_id } => bootstrap_config_helper(&group_id),
AppMode::SearchSupervisor { cluster_id } => bootstrap_search(&cluster_id),
}
}Add a new mode and the compiler immediately shows you every match that needs a new arm. Miss one? Compilation fails. This is what “compiler-guided refactoring” means in practice.
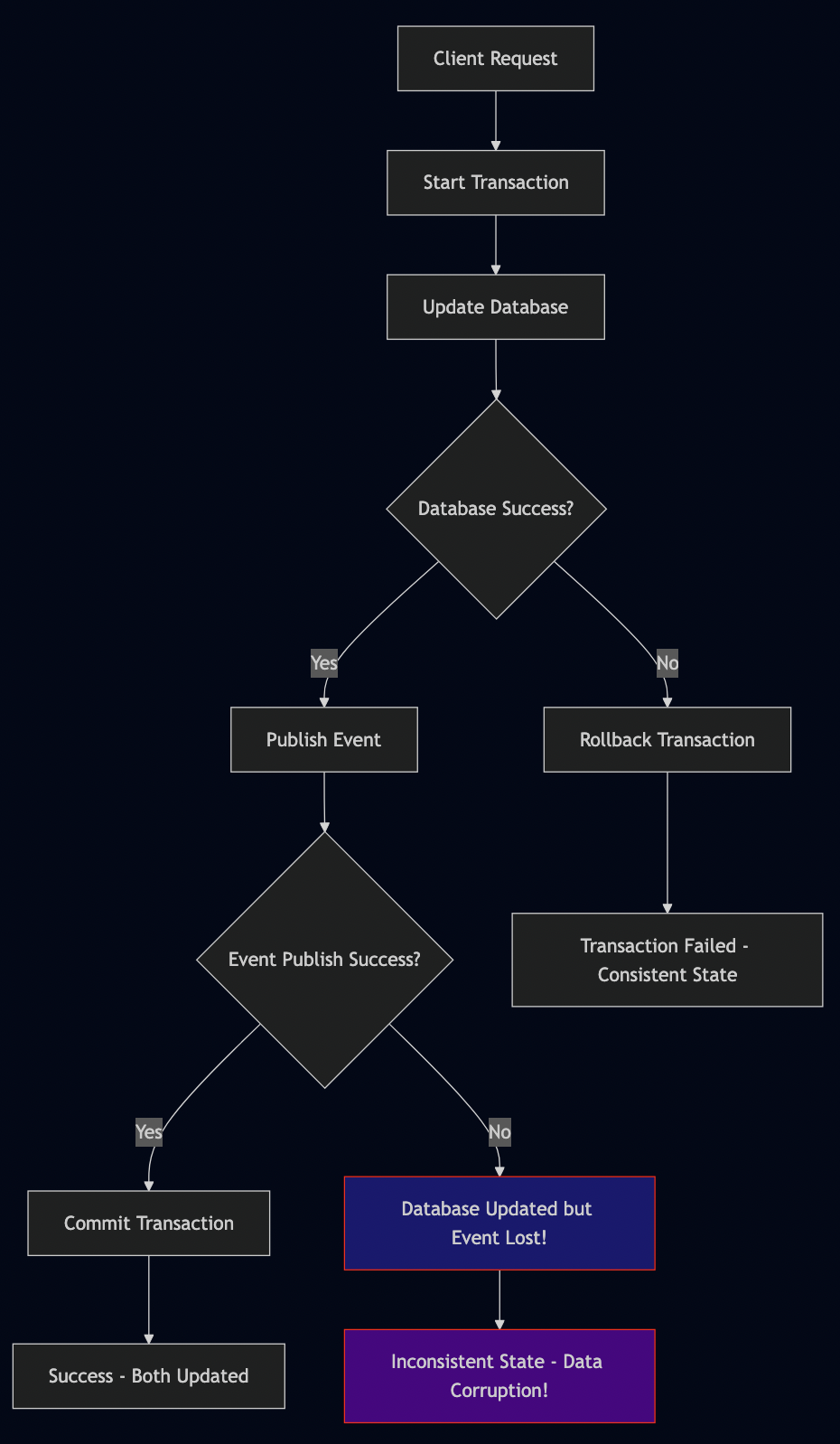
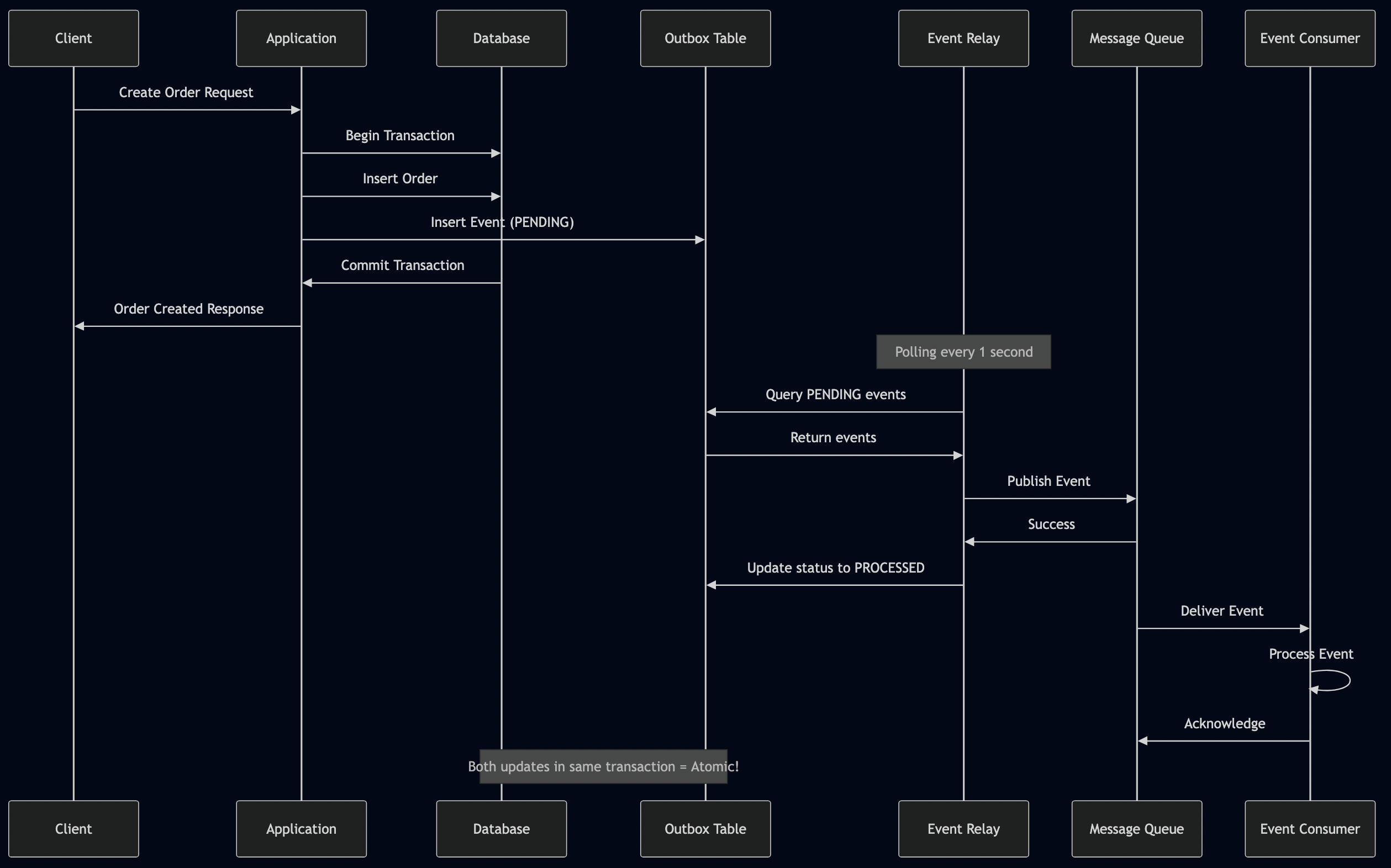
Problem 2: Operations That Partially Succeed
One of the most dangerous patterns I’ve seen: multi-step operations without atomic boundaries. I wrote about it in Transaction Boundaries: The Foundation of Reliable Systems. Here is an example:
// Config updated BEFORE deployment succeeds groupConf.configVersion = hash; // Step 1: mutate config await this.update(groupConf); // Step 2: persist to database await cm.deploy(); // Step 3: actually deploy // If step 3 fails: database says "deployed" but nothing deployed. // State is permanently inconsistent. Nobody notices until 2am.
Another version of the same problem:
// Package manager — loop continues after failure
for (const op of ops) {
try {
switch (op.type) {
case 'install': await this.install(op.pack); break;
case 'uninstall': await this.uninstall(op.pack); break;
}
} catch(e) {
errors.push(e); // collect error but CONTINUE the loop
}
}
await this.save(); // save regardless — partially applied state!The typestate pattern uses types to enforce operation ordering. Each step produces a different type, and the next step only accepts the correct input type:
// Each phase is a distinct type — not an enum, separate structs
struct Planned { operations: Vec<Operation> }
struct Validated { operations: Vec<ValidOperation>, checks: Vec<CheckResult> }
struct Applied { results: Vec<OperationResult> }
struct Committed { hash: String, timestamp: Instant }
// Functions consume one type, return the next
fn validate(tx: Planned) -> Result<Validated, Vec<ValidationError>> { ... }
fn apply(tx: Validated) -> Result<Applied, ApplyError> { ... }
fn commit(tx: Applied) -> Result<Committed, CommitError> { ... }
// You cannot call commit() on a Planned transaction.
// The types won't allow it.
// And because validate() CONSUMES Planned, you can't reuse the old value.If apply fails, you have a Validated, not an Applied. You can retry or abort cleanly. There’s no half-committed state because the type system won’t let you call commit without a successful apply.
Problem 3: Silently Swallowed Errors
441 instances of .catch(NOOP) in production. Each one is a failure that nobody notices until the system is in an inconsistent state:
this.reconcileLbIfStandalone(req.body).catch(NOOP); // load balancer fails silently unlink(bundlePath).catch(NOOP); // file deletion fails silently dest.connect().catch(NOOP); // connection fails silently
The problem isn’t laziness. Promise/exception-based error handling makes it easy to ignore errors and hard to handle them consistently. Rust’s Result type inverts this: handling errors is the default path, and ignoring them requires explicit effort:
// Every operation returns Result — no hidden exceptions
async fn reconcile_lb(body: &Request) -> Result<LbState, ReconcileError> {
let state = do_reconcile(body).await
.map_err(|e| classify_error(e))?; // ? propagates errors up — visible in the code
Ok(state)
}
// Caller MUST handle the Result
let lb_state = reconcile_lb(&req.body).await?;
// If we reach this line, it succeeded. Guaranteed.
// Want to explicitly ignore? You have to WRITE that intention:
let _ = reconcile_lb(&req.body).await; // "I know this can fail and I don't care"The key insight: with Result, ignoring an error requires writing code to ignore it. With exceptions, ignoring an error requires writing nothing. Defaults matter enormously. The ? operator makes propagating errors as easy as typing one character, no try/catch boilerplate, no .catch(NOOP) temptation.
Problem 4: Swapped Arguments and Primitive Obsession
The legacy codebase uses raw strings and numbers for everything like IDs, tokens, keys. Nothing stops you from passing arguments in the wrong order:
// 4,000+ uses of untyped parameters
fn send_request_to_worker(wid: u64, req: &str, body: &[u8]) { ... }
// What stops you from passing (request_id, worker_id, wrong_body)? Nothing.Rust newtypes create distinct types with zero runtime cost:
struct WorkerId(String);
struct RequestId(String);
struct AuthToken(String);
fn send_request(worker_id: &WorkerId, request_id: &RequestId, body: &RequestBody) { ... }
// Now the compiler catches this:
send_request(&request_id, &worker_id, &body); // COMPILE ERROR
// expected `&WorkerId`, found `&RequestId`And smart constructors validate at the boundary, so the type carries the guarantee everywhere:
impl WorkerId {
pub fn new(raw: &str) -> Result<Self, ValidationError> {
if !WORKER_ID_PATTERN.is_match(raw) {
return Err(ValidationError::InvalidFormat("worker ID"));
}
Ok(WorkerId(raw.to_string()))
}
}
// Once you have a WorkerId, you KNOW it's valid. No re-validation needed anywhere.Problem 5: Every Process Carries Everything
The legacy system scaled by spawning full OS processes because there was no type-safe way to separate workloads:
// Every worker loads the FULL binary — all 150 connectors, all modes
// Even edge nodes carry leader code they'll never use
// Default: 2GB heap per worker
this.env.NODE_OPTIONS = `--max-old-space-size=${heapSizeMB || 2048}`;
// 4 workers × 2GB = 8GB minimum. Plus API process, services...
// Competitors: Fluent Bit (10-30MB), Vector (30-50MB)With typed resource boundaries, each workload declares exactly what it needs:
enum WorkloadProfile {
IoBound { connections: usize, buffer_size: Bytes },
CpuBound { parallelism: usize, memory_budget: Bytes },
Mixed { io_weight: f32, cpu_weight: f32 },
}
enum ResourceClaim {
Lightweight { max_memory_mb: u32, max_cpu_cores: f32 },
Standard { max_memory_mb: u32, max_cpu_cores: f32 },
Heavy { max_memory_mb: u32, max_cpu_cores: f32 },
}
fn resources_for(pipeline: &PipelineConfig) -> ResourceClaim {
match analyze_workload(pipeline) {
WorkloadProfile::IoBound { .. } =>
ResourceClaim::Lightweight { max_memory_mb: 64, max_cpu_cores: 0.5 },
WorkloadProfile::CpuBound { .. } =>
ResourceClaim::Heavy { max_memory_mb: 2048, max_cpu_cores: 4.0 },
WorkloadProfile::Mixed { .. } =>
ResourceClaim::Standard { max_memory_mb: 512, max_cpu_cores: 2.0 },
}
}Instead of “every process gets everything,” each workload gets exactly what it declares. Resource requirements are now visible, auditable, and enforced by the type system.
Problem 6: Inheritance Hierarchies Nobody Understands
The legacy codebase had class hierarchies 7 levels deep:
BaseServiceable // 100+ subclasses, forces EventEmitter
--> BaseInput
--> TcpInput
--> FramedProtocol // Framing, auth, metrics, load balancing — all mixed
--> ControlListener
--> ProxyListener // 760 lines of proxy logic inheriting ~4,500 lines it doesn't useReading ProxyListener meant understanding 6 parent classes first. And there were 12 cloud storage subclasses that were entirely empty and they inherited ~5K lines and added exactly zero:
export class ProviderAOut extends CloudStorageOutput {} // empty
export class ProviderBOut extends CloudStorageOutput {} // empty
export class ProviderCOut extends CloudStorageOutput {} // emptyThe fix: composition with enums instead of inheritance:
enum S3Provider {
Aws { region: String },
Storj { gateway: String },
Backblaze { account_id: String },
Wasabi { region: String },
Minio { endpoint: String },
}
fn create_s3_client(provider: &S3Provider) -> S3Client {
match provider {
S3Provider::Aws { region } => S3Client::new().region(region),
S3Provider::Storj { gateway } => S3Client::new().endpoint(gateway),
S3Provider::Backblaze { account_id } =>
S3Client::new().endpoint(&format!("s3.{account_id}.backblazeb2.com")),
S3Provider::Wasabi { region } => S3Client::new().endpoint(&format!("s3.{region}.wasabisys.com")),
S3Provider::Minio { endpoint } => S3Client::new().endpoint(endpoint),
}
}No inheritance and no empty subclasses. Adding a new provider means adding a variant to the enum and the compiler shows you every match that needs a new arm. See my earlier blog The Reusability Trap: When DRY Becomes a Liability for more details on this anti-pattern.
IV. ADTs Applied to Concurrency
Race Conditions in Shared Mutable State
Here’s actual production code where multiple async operations read and write the same map:
private conns: { [key: string]: Connection } = {};
// Called by the service loop (runs periodically)
private async _service() {
const values = Object.values(this.conns);
for (const conn of values) {
if (conn.isStale()) {
delete this.conns[conn.key]; // Mutate while potentially being read elsewhere
}
}
}
// Called when a new node connects (can happen any time)
private addConnection(connKey: string, data: INodeEntry): boolean {
this.conns[connKey] = conn; // Race with _service()!
this.assignToGroup(conn)
.catch(LOG_ERR(logger, 'failed to assign'));
return true;
}And the classic read-modify-write race:
prevState = await this.getState(key); // Process A reads state // ... Process B also reads state here ... // ... Process A modifies and writes ... await this.store.set(key, newState); // Process B writes — A's changes LOST
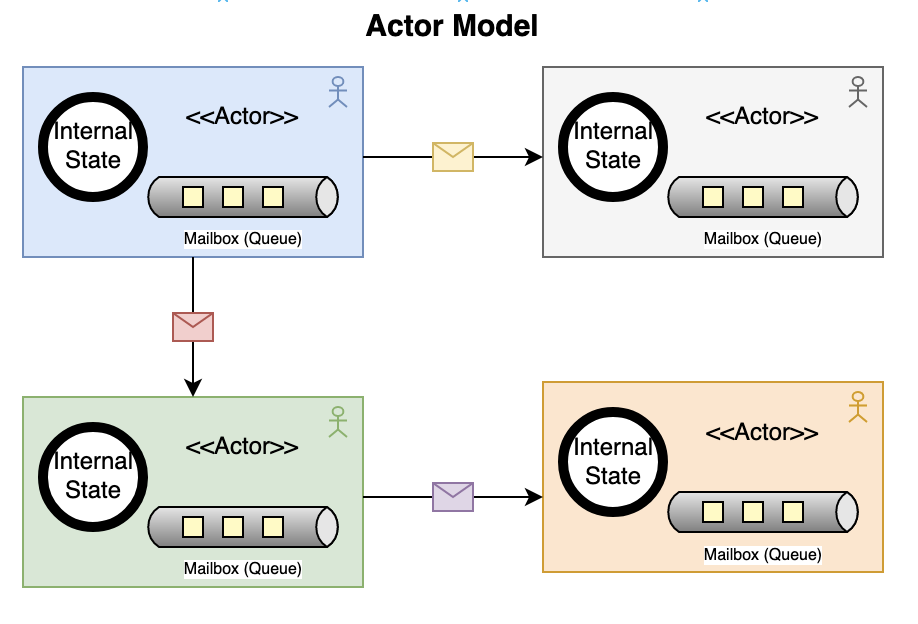
The fix: a single owner of state, communicating through typed messages like actor model:
enum ConnectionCommand {
Add { key: String, conn: Connection },
Remove { key: String },
RemoveStale,
GetAll { reply: oneshot::Sender<Vec<Connection>> },
}
// Single owner — only this task can access `conns`
async fn connection_manager(mut inbox: mpsc::Receiver<ConnectionCommand>) {
let mut conns: HashMap<String, Connection> = HashMap::new();
while let Some(cmd) = inbox.recv().await {
match cmd {
ConnectionCommand::Add { key, conn } => { conns.insert(key, conn); }
ConnectionCommand::Remove { key } => { conns.remove(&key); }
ConnectionCommand::RemoveStale => { conns.retain(|_, conn| !conn.is_stale()); }
ConnectionCommand::GetAll { reply } => {
let _ = reply.send(conns.values().cloned().collect());
}
}
}
}No mutexes, locks or data races. Rust’s ownership system guarantees conns is owned by exactly one task. Other tasks communicate through the channel, they physically cannot access the HashMap directly because they don’t own it.
Backpressure: Making Buffer Overflow Impossible to Ignore
The legacy heartbeat system silently dropped metrics when its buffer filled:
add(metric: MetricPacket, doNotDrop: boolean): void {
if (this.hbMetrics.length > this.maxHbMetrics) {
this.packetCounter.onDroppedMetric(); // Increment a counter nobody watches
return; // Data gone forever. No error. No signal to sender.
}
this.hbMetrics.push(metric);
}The sender had no idea data was being lost. It kept sending happily while the system silently degraded. With Rust’s bounded channels, backpressure is built in. When the buffer is full, you must decide what to do:
match tx.try_send(metric) {
Ok(()) => { /* sent */ }
Err(TrySendError::Full(metric)) => {
// Channel is full — you MUST decide:
// Option 1: wait (applies backpressure to sender)
tx.send(metric).await?;
// Option 2: spill to disk
// disk_buffer.write(metric)?;
// Option 3: drop with explicit acknowledgment
// warn!("Metric dropped due to backpressure");
}
Err(TrySendError::Closed(_)) => {
error!("Metrics channel closed unexpectedly");
return Err(ChannelError::Closed);
}
}The type system forces the conversation: “What should happen when the buffer is full?” You can’t accidentally drop data and you must write explicit code to ignore it.
Event Sourcing: Eliminating Lost Updates
Instead of mutable state that can be overwritten by concurrent operations, event sourcing treats state as a derived value from an append-only log:
enum JobEvent {
Created { job_id: String, config: JobConfig, at: Instant },
Started { worker_id: String, at: Instant },
Progressed { percentage: u8, at: Instant },
Completed { result: JobResult, at: Instant },
Failed { error: ErrorInfo, retryable: bool, at: Instant },
}
// State is derived — never directly mutated
fn derive_state(events: &[JobEvent]) -> JobState {
events.iter().fold(initial_state(events), apply_event)
}
fn apply_event(state: JobState, event: &JobEvent) -> JobState {
match (state, event) {
(JobState::Pending { .. }, JobEvent::Started { worker_id, .. }) =>
JobState::Running { worker_id: worker_id.clone(), progress: 0 },
(JobState::Running { worker_id, .. }, JobEvent::Progressed { percentage, .. }) =>
JobState::Running { worker_id, progress: *percentage },
(state, _) => state, // Invalid transition — state unchanged
}
}No lost updates because events are appended, never overwritten. Invalid transitions are no-ops and the reduce function simply ignores events that don’t make sense for the current state.
Message Ordering: Protocol State Machines
The legacy system sent commands from leader to worker with no ordering guarantees:
// Leader sends: 1. configure, 2. upgrade
// Worker may RECEIVE: 1. upgrade, 2. configure (reversed!)
// Result: config applied AFTER upgrade — potential data corruption
// Current "fix": reject conflicting operations
private failOnConflictingOperation() {
if (this.currentAction) {
throw new ConflictingActionError(); // Command REJECTED, not queued!
}
}
// No command queue. No ordering. No acknowledgment.
// Leader has NO WAY to know if the worker processed the command.A typed protocol state machine makes invalid command sequences unrepresentable:
enum NodePhase { Idle, Configured, Upgrading, Draining }
fn apply_command(state: ProtocolState, cmd: &Command) -> Result<ProtocolState, ProtocolError> {
let seq = cmd.seq();
if seq != state.last_applied_seq + 1 {
return Err(ProtocolError::OutOfOrder { expected: state.last_applied_seq + 1, got: seq });
}
match (&state.phase, cmd) {
(NodePhase::Idle | NodePhase::Configured, Command::Configure { .. }) =>
Ok(ProtocolState { phase: NodePhase::Configured, ..state }),
(NodePhase::Configured, Command::Upgrade { .. }) =>
Ok(ProtocolState { phase: NodePhase::Upgrading, ..state }),
(NodePhase::Idle | NodePhase::Configured, Command::Drain { .. }) =>
Ok(ProtocolState { phase: NodePhase::Draining, ..state }),
(phase, cmd) =>
Err(ProtocolError::InvalidTransition { from: phase.clone(), command: cmd.name() }),
}
}The system cannot apply an upgrade before configuration because the match on (current_phase, command) rejects it. The exhaustive match means there’s no way to accidentally leave a case unhandled.
RAII: Locks That Can’t Leak
The legacy system used file-based locks with no timeouts or heartbeats:
// If the process crashes while holding this lock, it's stuck forever
static async acquireConfigUpdateLock(dir: string): Promise<void> {
if (!(await acquireLock(dir, CONFIG_UPDATE_LOCK_NAME))) {
throw new AppError('Failed to acquire config update lock.');
}
// No timeout. No heartbeat. Crash = lock held forever.
}In Rust, RAII (Resource Acquisition Is Initialization) makes forgotten locks a compile-time impossibility:
struct ConfigLock {
path: PathBuf,
acquired_at: Instant,
ttl: Duration,
}
impl Drop for ConfigLock {
fn drop(&mut self) {
// Automatically called when ConfigLock goes out of scope — even on panic!
let _ = std::fs::remove_file(&self.path);
}
}
async fn with_config_lock<T, F>(resource: &str, ttl: Duration, f: F) -> Result<T, LockError>
where F: FnOnce(&ConfigLock) -> Result<T, LockError>
{
let lock = acquire_lock(resource, ttl).await?;
f(&lock)
// lock dropped here automatically — file released no matter what
}
let result = with_config_lock("config-update", Duration::from_secs(30), |_lock| {
extract_bundle(&dir)?;
save_system(&dir)?;
Ok("deployed")
}).await?;
// Lock released here — even if any step panickedThe lock cannot leak because Drop::drop() runs when the guard goes out of scope and it’s a compiler guarantee.
Serialization: Schema Evolution as an ADT
The legacy heartbeat system used JSON serialization for 100,000+ metrics per heartbeat:
// JSON.parse for 100K metrics: ~500ms–1s // With a 10s heartbeat interval, serialization alone eats 5–10% of your cycle time // And there's no versioning — if the schema changes, old and new nodes break silently
With Rust enums, the protocol schema is defined once and versioning is a first-class concern:
enum HeartbeatMessage {
V1 { metrics: Vec<MetricV1> },
V2 { metrics: Vec<MetricV2>, deltas: Vec<DeltaMetric> }, // added delta support
}
// Schema evolution is an enum — every version must be explicitly handled
fn parse_heartbeat(data: &[u8]) -> Result<HeartbeatMessage, ParseError> {
let version = data[0];
match version {
1 => parse_v1(&data[1..]),
2 => parse_v2(&data[1..]),
_ => Err(ParseError::UnknownVersion(version)),
// Add v3? The compiler shows you every match that needs updating.
}
}With protobuf or flatbuffers: zero-copy deserialization runs 10–100x faster than JSON. And schema evolution is no longer an afterthought and the enum ensures every protocol version is explicitly handled.
V. What Are Algebraic Effects?
ADTs solve the problem of representing valid states. Algebraic Effects solve a different but related problem: how to separate what code needs from how those needs are fulfilled without forcing that separation to infect every caller in the chain.
The Intuition: Exceptions That Can Resume
You already understand exceptions, e.g., when you throw, execution stops and the stack unwinds:
function getName() {
throw new Error("need a name"); // Execution stops. Stack unwinds. Gone.
}
try {
getName();
} catch (e) {
// We're here, but getName() is DEAD. We can't go back.
}Now imagine if, instead of killing getName(), the handler could answer the question and let it continue:
function getName() {
const name = perform AskUser("What's your name?"); // Pause, don't die
return `Hello, ${name}`; // Continues after handler responds!
}
handle(getName(), {
AskUser: (question, resume) => {
const answer = prompt(question);
resume(answer); // Jump BACK into getName() with the answer
}
});That’s algebraic effects in one sentence: exceptions that can resume. The code that performs an effect doesn’t die instead it pauses, gets an answer, and continues where it left off. You can think of it this way: regular exceptions are like quitting your job when you have a question. Effects are like asking your manager, you pause, they answer, you continue.
The Function Coloring Problem
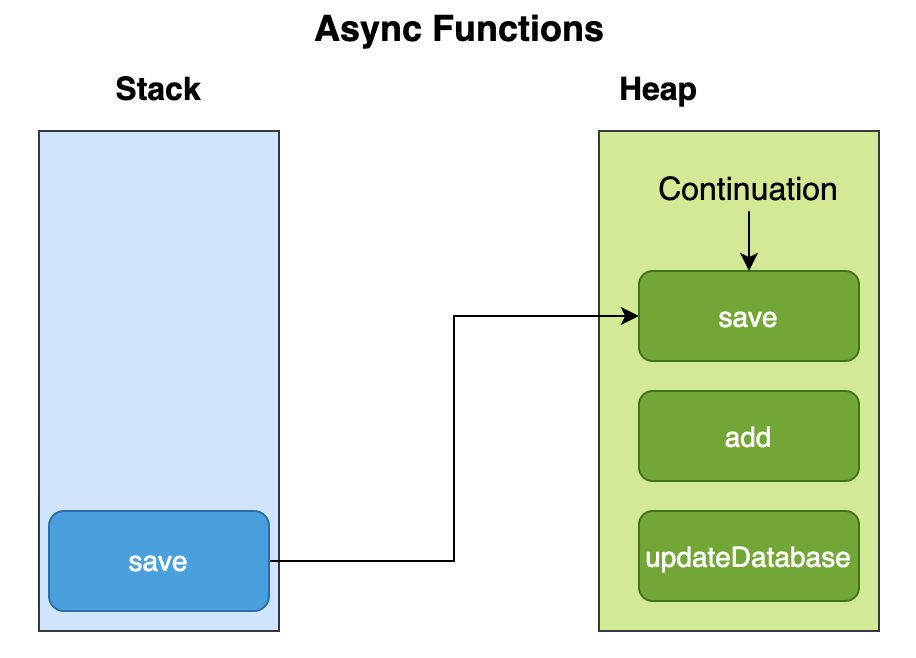
Here’s why effects matter for real systems. Once a function is async, everything that calls it must also be async:
async function getConfig(): Promise<Config> { ... }
async function processEvent(e: Event): Promise<void> { // must be async because getConfig is
const config = await getConfig();
// ...
}
async function handleRequest(req: Request): Promise<Response> { // must be async because processEvent is
await processEvent(req.body);
// ...
}One async function forces asyncness through the entire call stack. This is generally called “function coloring“, async and sync functions are different “colors” and they can’t mix freely. The same problem applies to error handling (once you use Result, every caller must handle it), to dependencies (once you need config, every caller must thread it through), and to logging (once you need a logger, every intermediate function must pass it along). Effects solve this by separating what a function needs from who provides it. Intermediate functions stay uncolored:
// With effects (conceptual syntax):
function getConfig(): Effect<ConfigService, Config> {
return perform GetConfig;
}
function processEvent(e: Event): Effect<ConfigService, void> {
const config = getConfig(); // NOT async! Just performs an effect.
transform(e, config);
}
// Only the TOP-LEVEL handler knows how config is provided:
handle(processEvent(event), {
GetConfig: (resume) => {
const config = loadFromDisk(); // or from env, or hardcoded for tests
resume(config);
}
});processEvent doesn’t know or care whether config comes from disk, network, or a test fixture. The handler at the boundary decides. Intermediate functions don’t need to thread the dependency through.
You Already Use Effects
If you use React, you’re already working with algebraic effects in disguise. React Hooks are effects:
function Counter() {
const [count, setCount] = useState(0); // "perform GetState" — component doesn't manage storage
useEffect(() => { ... }); // "perform ScheduleSideEffect"
const data = use(fetchData()); // "perform Suspend"
return <div>{count}</div>;
}useState doesn’t tell the component where state lives. It performs an effect (“I need state”), and the React runtime acts as a handler and then provides it. The component doesn’t know if state is in memory, in a reducer, or synced to a server. React Suspense is literally “throw, then resume”:
// Simplified React Suspense:
function fetchData() {
if (!cache.has(key)) {
throw promise; // "perform Suspend" — throws a Promise UP the tree
// React catches it, shows fallback, waits for promise to resolve,
// then RE-RENDERS the component — effectively "resuming" it with data
}
return cache.get(key);
}This is exactly the algebraic effects pattern: code performs an effect (throws a Promise), a handler catches it (the Suspense boundary), and the code is resumed (re-rendered) with the result. React couldn’t add real algebraic effects to JavaScript, so they simulated them with throw/re-render.
Everything Is the Same Control Flow Mechanism
Look at these seemingly different language features:
| Feature | “Perform” | “Handle” | “Resume” |
|---|---|---|---|
| Exceptions | throw error | try/catch | ? (can’t resume) |
| Async/Await | await promise | Runtime scheduler | Resolves with value |
| Generators | yield value | for..of consumer | .next(value) |
| React Hooks | useState() | React runtime | Re-render with state |
| DI Container | @Inject | Container config | Constructor call |
| Algebraic Effects | perform effect | handle block | resume(value) |
They’re all the same pattern: (1) code declares “I need something,” (2) something up the call stack provides it, (3) execution continues with the provided value. Algebraic effects are just the general version that unifies all the others. The historical arc of control flow in programming languages tells the same story:
goto --> structured control (if/while) --> exceptions --> continuations --> algebraic effects
Each step gives more structured, more composable control over program flow.
The Monad Infection Problem
If you’ve used functional languages, you know what happens once you use Result, Option, Future, or IO as every function in the chain must return that type:
fn get_config() -> Result<Config, Error> { ... }
fn parse_event(config: &Config) -> Result<Event, Error> { ... }
fn validate(event: &Event) -> Result<ValidEvent, Error> { ... }
fn process() -> Result<Output, Error> {
let config = get_config()?;
let event = parse_event(&config)?;
let valid = validate(&event)?;
Ok(transform(valid))
}Once one function returns Result<T, E>, everything up the chain must acknowledge it. This is the same coloring problem as async just with error types. Effects solve this: the function just performs the effect, and a single handler at the top decides what to do. Intermediate functions stay clean.
For example, Jane Street’s hardware simulation team switched from monads to OCaml 5’s algebraic effects for exactly this reason. Their testbench code had to synchronize threads stepping through clock cycles. With monads, every function needed special let%bind syntax and couldn’t use normal OCaml features. With effects:
(* Business logic is PLAIN OCaml — no special syntax *)
let run_testbench () =
let clk = read_signal clock in
step (); (* "perform Step" — suspend until next clock cycle *)
let data = read_signal data_bus in
assert (data = expected);
step (); (* Step again — handler resumes us at next cycle *)
write_signal reset 1
(* Handler provides the simulation scheduler *)
let simulate circuit testbench =
match_with testbench () {
effc = (fun (type a) (eff : a Effect.t) ->
match eff with
| Step -> Some (fun (k : (a, _) continuation) ->
advance_circuit circuit; (* Tick the simulated hardware *)
continue k () (* Resume testbench at next line *)
)
)
}The testbench reads like sequential code without monadic boilerplate. The step() call suspends execution, the handler advances the simulated hardware clock, and execution resumes.
Effects in Languages You Use Today
You don’t need OCaml 5 or Koka. Effects can be approximated in any language. In TypeScript using generator functions:
function* processEvent(event: RawEvent) {
const config = yield { effect: 'getConfig' }; // "perform GetConfig"
const enabled = yield { effect: 'checkFlag', flag: 'v2' }; // "perform CheckFlag"
yield { effect: 'log', msg: 'processing' }; // "perform Log"
return transform(event, config);
}
// Handler interprets the effects
function runWithHandler(gen, handlers) {
let result = gen.next();
while (!result.done) {
const effect = result.value;
const value = handlers[effect.effect](effect); // "resume with value"
result = gen.next(value);
}
return result.value;
}
// Production vs test — trivially swapped
const prodResult = runWithHandler(processEvent(event), productionHandlers);
const testResult = runWithHandler(processEvent(event), testHandlers);In Python using context variables:
from contextvars import ContextVar
config_effect: ContextVar[Config] = ContextVar('config')
metrics_effect: ContextVar[MetricsCollector] = ContextVar('metrics')
def process_event(event):
config = config_effect.get() # "perform GetConfig"
metrics = metrics_effect.get() # "perform GetMetrics"
return transform(event, config)
# Handler provides implementations at the boundary
config_effect.set(production_config)
metrics_effect.set(prometheus_collector)
result = process_event(event)VI. Algebraic Effects Applied to Real Problems
Problem 1: Dependency Injection Without a Framework
The legacy codebase had 816 files coupled to global singletons:
// Configuration.instance() called in 858 files
// ProcessInfo singleton accessed in 320 files
// GlobalMetrics singleton in 200+ files
// FeatureFlags singleton in 186 files
class WorkerConnection {
async configure() {
const config = Configuration.instance(); // Hidden dependency
const metrics = GlobalMetrics.instance(); // Hidden dependency
const flags = FeatureFlags.instance(); // Hidden dependency
const env = process.env.DEPLOYMENT_MODE; // Hidden dependency (488 files!)
}
}You can’t test this without the real singleton. You can’t run different configurations in the same process. And the dependencies are invisible because you discover them at runtime via crashes. Effects-style DI (approximated with the Reader pattern in TypeScript):
type AppDeps = {
config: IConfigProvider;
metrics: IMetricsCollector;
flags: IFeatureFlags;
clock: IClock;
};
// Business logic is a pure function of its dependencies
function configurePipeline(deps: AppDeps) {
return (pipeline: PipelineConfig): Result<ConfiguredPipeline, ConfigError> => {
const features = deps.flags.getEnabled(pipeline.namespace);
const stages = pipeline.stages
.filter(s => features.includes(s.requiredFeature))
.map(s => buildStage(s, deps.config));
return { ok: true, value: { stages, configuredAt: deps.clock.now() } };
};
}
// Production wiring — one place, at startup
const production = configurePipeline({
config: new FileConfigProvider('/etc/app/config.yaml'),
metrics: new PrometheusCollector(),
flags: new LaunchDarklyFlags(apiKey),
clock: SystemClock,
});
// Tests — zero mocking frameworks needed
const test = configurePipeline({
config: { get: (key) => testDefaults[key] },
metrics: new NoOpCollector(),
flags: { getEnabled: () => ['all-features'] },
clock: { now: () => new Date('2024-01-01') },
});In languages with native effect support (OCaml 5, Koka, Eff), this becomes even cleaner as intermediate functions don’t need to accept or pass deps at all. They just perform GetConfig and the handler provides the value.
Problem 2: Multiple Metrics Implementations
The legacy system had multiple parallel metrics implementations built by different teams, each with stringly-typed dimensions:
// different ways to record metrics, scattered across 17+ files IMetricsStore GlobalMetrics IoMetricsMgr DataInsightsMetricsMgr LocalSearchMetricsReporter // Plus per-class ad-hoc metrics: PeriodicStats, ConnectionMetrics, PacketReducer... // Stringly-typed dimensions — typos produce SILENT missing metrics: metrics.record(['id', prefixId, 'route', routeId]); // Swap any string? Silent wrong data.
With a single metrics effect:
type MetricEffect =
| { kind: 'counter', name: MetricName, value: number, tags: MetricTags }
| { kind: 'gauge', name: MetricName, value: number, tags: MetricTags }
| { kind: 'histogram', name: MetricName, value: number, tags: MetricTags };
// Branded types prevent typos
type MetricName = string & { __brand: 'MetricName' };
type MetricTags = Record<TagKey, TagValue>; // Also branded
// Business logic performs the effect — doesn't know WHERE metrics go
function processRoute(event: Event, route: Route): ProcessedEvent {
perform { kind: 'counter', name: MetricName('events.processed'), value: 1, tags: { route: route.id } };
const result = transform(event, route);
perform { kind: 'histogram', name: MetricName('events.latency_ms'), value: elapsed(), tags: { route: route.id } };
return result;
}
// Handler decides: Prometheus? StatsD? Both? Test collector? All swappable.Five implementations and seventeen files collapse into one typed effect that the compiler validates.
Problem 3: Auth Tokens Anyone Can Forge
The legacy system used a single shared HS256 symmetric token for ALL workers:
// All workers share the same symmetric auth secret // HS256 symmetric means: every worker can FORGE admin tokens! // No per-node identity. No revocation without rotating for ALL. const isValid = authToken === this.masterAuthToken; // Raw secret comparison
With branded types, per-worker tokens become type-enforced:
type WorkerToken = string & { __brand: 'WorkerToken', workerId: WorkerId, scope: TokenScope };
type LeaderToken = string & { __brand: 'LeaderToken' };
type TokenScope =
| { kind: 'control_plane', permissions: ControlPermission[] }
| { kind: 'data_plane', routes: RouteId[] }
| { kind: 'metrics_only' };
// Functions declare what token scope they require
function deployConfig(token: WorkerToken & { scope: { kind: 'control_plane' } }): Result<...> {
// Can ONLY be called with a control-plane scoped token
// Data-plane tokens won't typecheck here
}Now a compromised worker can’t forge admin tokens. The type system enforces token scope at compile time.
Problem 4: Control Flow Disguised as Errors
The legacy codebase used exceptions for control flow:
try {
for (const event of events) {
processEvent(event);
}
} catch (e) {
if (e instanceof SkipEventError) continue; // Control flow disguised as error!
if (e instanceof AppError) logger.warn(e);
if (e instanceof PipelineError) { ... }
// Unknown errors fall through and are silently swallowed
}There were multiple error hierarchies (AppError, RESTError, RpcError, PipelineError) with no unified classification. With effects, control flow signals and failures are distinct and handled separately:
type ControlEffect =
| { kind: 'skip', reason: string }
| { kind: 'retry', after: Duration }
| { kind: 'terminate', gracefully: boolean };
type FailureEffect =
| { kind: 'transient', error: Error, retryable: true }
| { kind: 'permanent', error: Error, retryable: false }
| { kind: 'validation', field: string, message: string };
// Business logic declares intent — doesn't decide policy
function processEvent(event: RawEvent): Effect<ControlEffect | FailureEffect, ProcessedEvent> {
if (!isRelevant(event)) {
return perform { kind: 'skip', reason: 'irrelevant event type' };
}
const validated = validate(event);
if (!validated.ok) {
return perform { kind: 'validation', field: validated.field, message: validated.message };
}
return transform(validated.value);
}
// Handler decides policy — completely separate from business logic
const withPolicy = handle(processEvent(event), {
skip: (effect, resume) => { metrics.increment('skipped'); resume(null); },
transient: (effect, resume) => { queue.requeue(event); resume(null); },
permanent: (effect, resume) => { deadLetter.send(event, effect.error); resume(null); },
validation: (effect, resume) => { logger.warn('Validation failed', effect); resume(null); },
});The business logic says “this event should be skipped” or “this operation failed transiently.” It doesn’t decide whether to retry, log, or dead-letter. That’s the handler’s job and handlers can be swapped independently.
Problem 5: No Circuit Breakers
The legacy system had no circuit breakers. When a downstream service failed, requests piled up until the process crashed:
dest.connect().catch(NOOP); // If it fails, try again next time. Or don't. Who knows.
// Retry with infinite loop and no idempotency:
while (true) {
try {
await writeToFile(...);
callback();
break;
} catch {
await delay(1000); // Retry forever. No backoff. No limit. No idempotency check.
}
}With effects, retry and circuit-breaking become composable middleware:
type RetryPolicy =
| { kind: 'none' }
| { kind: 'fixed', attempts: number, delay: Duration }
| { kind: 'exponential', maxAttempts: number, baseDelay: Duration, maxDelay: Duration }
| { kind: 'circuitBreaker', failureThreshold: number, resetAfter: Duration };
// Circuit breaker itself is a state machine — an ADT!
type CircuitState =
| { kind: 'closed', failureCount: number }
| { kind: 'open', openedAt: Date, failureCount: number }
| { kind: 'halfOpen', testRequest: Promise<unknown> };
function circuitTransition(state: CircuitState, event: CircuitEvent): CircuitState {
switch (state.kind) {
case 'closed':
if (event.kind === 'failure') {
const newCount = state.failureCount + 1;
if (newCount >= threshold) return { kind: 'open', openedAt: new Date(), failureCount: newCount };
return { ...state, failureCount: newCount };
}
return { kind: 'closed', failureCount: 0 };
case 'open':
if (elapsed(state.openedAt) > resetTimeout) return { kind: 'halfOpen', testRequest: null };
return state;
case 'halfOpen':
if (event.kind === 'success') return { kind: 'closed', failureCount: 0 };
return { kind: 'open', openedAt: new Date(), failureCount: state.failureCount };
}
}Notice: the circuit breaker itself is modeled as an ADT with exhaustive state transitions. ADTs model the state. Effects separate the retry policy from the code that needs retrying. Together they create systems that are both correct and composable.
VII. Design Thinking: Transformations Over Entities
Here’s an insight that ties everything together: design the transformations first, then the things being transformed. A system’s architecture is defined by how data flows, not by what objects exist.
The God Class Problem: Architecture You Can’t See
// A pipeline manager — 1,300+ lines, 80+ methods
class PipelineManager {
process(event: any) {
if (this.shouldFilter(event)) return; // filtering concern
this.metrics.increment('processed'); // observability concern
const result = this.transform(event); // transformation concern
this.route(result); // routing concern
this.metrics.recordLatency(start); // observability again
}
}The architecture is invisible. Everything is tangled. You can’t test transformation without routing. You can’t add observability without modifying the pipeline. When you model the same thing as typed functions, the architecture becomes visible:
// Each stage is a typed function with a clear input/output contract
fn parse(raw: RawEvent) -> Result<ParsedEvent, ParseError> { ... }
fn validate(parsed: ParsedEvent) -> Result<ValidEvent, ValidationError> { ... }
fn enrich(valid: ValidEvent) -> Result<EnrichedEvent, EnrichError> { ... }
fn route(enriched: &EnrichedEvent) -> RoutingDecision { ... }
// Composition IS the architecture — visible, testable, reorderable
fn process_event(raw: RawEvent) -> Result<EnrichedEvent, PipelineError> {
let parsed = parse(raw)?;
let valid = validate(parsed)?;
let enriched = enrich(valid)?;
Ok(enriched)
}
// Cross-cutting concerns are separate composable wrappers
let pipeline = WithMetrics::new("pipeline", process_event);
let pipeline = WithFilter::new(filter_config, pipeline);
let pipeline = WithRouting::new(route_table, pipeline);Each stage is independently testable. Adding observability doesn’t touch business logic. Reordering is just reordering function composition. The types document the flow: RawEvent --> ParsedEvent . This is what “the arrows are the architecture” means the transformations between types are the system’s behavior. --> ValidEvent --> EnrichedEvent
Rust’s ? Is Railway-Oriented Programming Built In
Think of data processing as a railway with two tracks: success and failure. Data flows along the success track until something goes wrong then it switches to the failure track and skips all remaining stages:
// Each ? is a branch point onto the failure track
fn process_event(raw: RawEvent) -> Result<ClassifiedEvent, PipelineError> {
let parsed = parse(raw)?; // fails? switch to error track
let valid = validate(parsed)?; // fails? switch to error track
let enriched = enrich(valid)?; // fails? switch to error track
let classified = classify(enriched)?;
Ok(classified)
}
// Each piece tested in isolation:
#[test]
fn parse_handles_malformed_json() {
let result = parse(RawEvent::new("not json"));
assert!(matches!(result, Err(PipelineError::MalformedInput { .. })));
}Rust’s ? operator is this pattern built into the language syntax. No special library, no monadic boilerplate and the language itself is railway-oriented.
Thinking in Transformations
Not all transformations are the same. Knowing which kind you’re building helps you choose the right pattern:
- One-to-one (parsing, validation): every input produces exactly one output. These compose directly:
parse >> validate >> enrich. - One-to-many (fan-out, splitting): one input produces multiple outputs. Use
flatMapor stream splitting, one log line becomes multiple metrics events. - Many-to-one (aggregation): multiple inputs combine into one. Use windowed
reduce, 1000 metric samples become a single P99 value. - Reversible (encoding, encryption): can be undone without loss. Good for serialization boundaries where you need to cross system edges.
- Self-directed (state transitions): transforms a value into another of the same type. State machines are exactly this, e.g.,
State --> State. An ADT enum is the natural representation.
The legacy PipelineManager muddled all five together in one class. Separating them makes each stage’s contract explicit and independently testable.
Measuring Coupling Through Connections
Here’s a concrete way to see how much a legacy architecture costs. Count the connections:
Point-to-point (legacy): N services = N × (N-1) / 2 connections 10 services = 45 connections 20 services = 190 connections 50 services = 1,225 connections ? quadratic growth Data-oriented: N services = N connections (each talks to a shared typed data layer) 10 services = 10 connections 20 services = 20 connections 50 services = 50 connections ? linear growth
The legacy system’s 125+ endpoints each know about each other implicitly through shared singletons, events, and direct calls. Adding endpoint #126 means understanding what it might break in endpoints #1–125.
With a data-oriented approach, each component only needs to understand the shared data schema instead of every other component. The tradeoff: schema design becomes your hardest decision. Data outlives code. You can rewrite a service in a weekend, but migrating a billion records takes months. Get the ADTs right before committing.
Stratified Design: Layers by Rate of Change
Within the functional core, code should be layered by how often it changes:
Layer 4 (changes weekly): Business rules, feature flags, pricing logic Layer 3 (changes monthly): Domain logic, validation, workflow orchestration Layer 2 (changes quarterly): Framework utilities, pipeline combinators, retry policies Layer 1 (changes yearly): Language extensions, data structures, core types
Each layer only calls downward. A change in Layer 4 (a new pricing rule) cannot break Layer 1 (your Result type). This eliminates cascading failures.
// Layer 1: Stable foundation (built into the language)
// Result<T, E>, Option<T>, Traits: From, Into, TryFrom
// Layer 2: Domain-specific combinators
async fn with_retry<T>(policy: &RetryPolicy, f: impl Fn() -> Fut<T>) -> Result<T, Error>;
async fn with_circuit_breaker<T>(state: &CircuitState, f: impl Fn() -> Fut<T>) -> Result<T, Error>;
// Layer 3: Business domain
fn validate_pipeline(config: &PipelineConfig) -> Result<ValidPipeline, Vec<ValidationError>>;
fn route_event(event: &ValidEvent, table: &RouteTable) -> RoutingDecision;
// Layer 4: Configuration and policies (changes frequently)
let route_table: RouteTable = load_config("routes.yaml")?;
let retry_policy = RetryPolicy::Exponential { max_attempts: 3, base_delay_ms: 100 };Replace Imperative Loops with Pipelines
The legacy codebase had hundreds of imperative accumulation loops:
// Legacy: imperative accumulation (hundreds of instances)
const results = [];
for (const worker of workers) {
if (worker.isActive()) {
const metrics = await worker.getMetrics();
if (metrics.cpuUsage > threshold) {
results.push({ workerId: worker.id, cpu: metrics.cpuUsage });
}
}
}Iterator combinators express the same thing as a pipeline with each step is independently readable and testable:
// Declare WHAT, not HOW
let results: Vec<_> = workers.iter()
.filter(|w| w.is_active())
.filter_map(|w| {
let metrics = w.get_metrics();
(metrics.cpu_usage > threshold).then(|| OverloadedWorker {
worker_id: w.id.clone(),
cpu: metrics.cpu_usage,
})
})
.collect();You can add or remove a stage without restructuring any loop. Each step in the chain has a clear type. And for a 1,200-line initialization sequence, the same idea applies:
// Instead of 1,200 lines of sequential initialization with implicit ordering:
let server = ServerBuilder::new(env)
.with_logging()?
.with_metrics()?
.with_storage()?
.load_pipelines()?
.with_health_check()?
.bind_endpoints()?
.build();
// Each method returns the next builder phase.
// Ordering is explicit in the chain — not hidden at line 847.
// ? propagates errors cleanly — no nested try/catch.Reactive Patterns: Derived State That Can’t Go Stale
The legacy codebase had derived values that went stale because updates were manually tracked:
class Dashboard {
private totalEvents = 0; // must remember to update
private avgLatency = 0; // must remember to update
private activeWorkers = 0; // must remember to update
onMetric(metric) {
this.totalEvents++;
// avgLatency updated... somewhere else. Maybe. If someone remembers.
}
}The reactive pattern (the same idea behind React, Redux, and spreadsheets) makes derived values automatic:
// Source cells (the inputs you can change)
const events = createCell<EventLog>([]);
const workers = createCell<Worker[]>([]);
// Derived formulas (automatically recompute when inputs change)
const totalEvents = formula(() => events.get().length);
const activeWorkers = formula(() => workers.get().filter(w => w.isActive()).length);
const avgLatency = formula(() => {
const recent = events.get().slice(-1000);
return recent.reduce((sum, e) => sum + e.latency, 0) / recent.length;
});
// Can NEVER be stale — recomputes automatically when inputs change
// "Forgot to update" bugs are impossibleThis is ValueCell (a mutable input) and FormulaCell (a derived computation) are the two primitives behind every reactive system from spreadsheets to React.
VIII. The Bigger Framework: Actions, Calculations, Data
Everything covered so far fits into a simple three-way classification from Eric Normand’s book Grokking Simplicity:
Data: Inert facts. Immutable. Serializable. Safe to copy, share, store, send.
type WorkerState = { kind: 'idle' } | { kind: 'configuring', request: ClusterRequest };
type JobEvent = { kind: 'started', workerId: string, at: Date };Calculations: Pure functions. Same input always produces the same output. No side effects. Safe to call anywhere, anytime, as many times as you want.
function deriveState(events: JobEvent[]): JobState { ... }
function validate(event: RawEvent): Result<ValidEvent, ValidationError> { ... }Actions: Depend on when or how often they run. I/O. Time. Network. The dangerous stuff.
async function saveToDatabase(state: JobState): Promise<void> { ... }
async function sendMetrics(metrics: Metric[]): Promise<void> { ... }The legacy system had roughly 80% Actions, 15% Mixed (calculations that accidentally touched singletons or Date.now()), and 5% pure Calculations. The target is the Functional Core, Imperative Shell pattern:

The core is pure: no I/O, no time, no randomness. It takes Data in and produces Data out. It’s trivially testable, trivially parallelizable (no shared state), and trivially composable. The shell is thin, it translates between the real world and the pure core. Every antipattern in the legacy codebase came from violating this boundary: singletons injecting Actions into Calculations, mutable state making “pure” functions depend on timing, mixed I/O making business logic untestable without the full system running.
Consistent API Responses as Typed Envelopes
The legacy system had 125+ endpoints with inconsistent response formats:
GET /system/inputs ? { items: IInput[] }
GET /system/outputs ? IOutput[] // No wrapper!
GET /jobs ? PaginatedListResults<IJob> // Different wrapper!
// Error formats inconsistent too:
throw new RESTError(JSON.stringify(data), code); // JSON string as message!
throw new RESTError('Not found', 404);
throw new RESTError('Not found', 400); // Wrong status code!A typed response envelope makes inconsistency a compile error:
type ApiResponse<T> =
| { ok: true, data: T, meta?: PaginationMeta }
| { ok: false, error: ApiError };
type ApiError = {
code: ErrorCode; // Typed enum, not arbitrary string
message: string;
details?: FieldError[];
traceId: TraceId; // Branded — always present for debugging
};
// Both return the same shape. Always. Compiler enforces it.
function listInputs(req: Request): ApiResponse<Input[]> { ... }
function listOutputs(req: Request): ApiResponse<Output[]> { ... }IX. Let Compiler Work for You
The compiler catches bugs in seconds. Tests catch them in minutes. Staging catches them in hours. Production catches them over days of incident response, root cause analysis, and post-mortems. The math is simple. Investing time in better types eliminates entire categories of bugs that would each cost 10-100x more downstream.
X. When NOT to Use This
These patterns aren’t universally optimal.
- Don’t use ADTs when you’re still exploring. When you don’t know yet what the valid states ARE, encoding them as sum types locks you in prematurely. Start with loose types, discover the states through testing, then lock them down.
- Don’t use ADTs for simple CRUD with few states. A blog post with
{title, body, published}doesn’t needDraft | Published | Archived. If the state space is small and obvious, a boolean is fine. - Don’t use full effects systems in hot paths. Effect handlers add indirection. In inner loops processing millions of events per second, direct function calls beat effect dispatch. Use effects at the boundary, direct calls in the hot path.
- Don’t adopt effects before your team understands them. If your team has never seen algebraic effects, introducing them when
new Service(deps)works fine creates confusion without proportional benefit. The approximations (Reader pattern, context variables) are a gentler on-ramp.
The adoption gradient, from easiest to hardest:
Easy (adopt today): Boolean pairs ? sum types (just types, zero learning curve) .catch(NOOP) ? explicit handling (mindset shift only) Medium (team discussion needed): Singletons ? parameter injection (changes constructor signatures) Imperative loops ? map/filter/reduce (functional style shift) Hard (architectural decision): Shared state ? actors/channels (concurrency model change) Mixed I/O ? functional core/shell (structural refactor) Full effect systems (new paradigm)
Start at the top. Each level delivers value independently. You don’t need to reach the bottom to benefit.
XI. The Migration Path (Incremental, Not Big Bang)
You don’t need to rewrite your system. Here’s the step-by-step path.
- Step 1: Boolean pairs –> sum types (minutes per instance)
// Before
let isConnected: boolean;
let isAuthenticated: boolean;
// After
enum ConnectionState {
Disconnected,
Connected { socket: TcpStream },
Authenticated { socket: TcpStream, token: AuthToken },
}- Step 2: Find every
.catch(NOOP)and make a decision: Each one is a decision point: should it retry, log, propagate, or recover? At minimum, log it. Better: make it aResultso callers know. - Step 3: Singletons ? constructor parameters (one file at a time): Pick one singleton-using class. Pass the dependency as a constructor parameter instead of hunting for it globally. Test it with a stub.
- Step 4: Centralize mode checks before eliminating them: Before you can replace 506 scattered mode checks, you need mode determination in ONE place:
// Step 1: Create the union type
type AppMode = { kind: 'leader', ... } | { kind: 'worker', ... } | ...;
// Step 2: Determine mode ONCE at startup
const mode: AppMode = determineMode(process.env);
// Step 3: Pass mode to subsystems — then replace checks one at a time- Step 5: Shared mutable state ? channels (one boundary at a time): Identify shared mutable state accessed by multiple async operations. Introduce a channel wrapper and don’t rewrite everything at once.
- Step 6: New features go in first (pure core, then I/O): For every new feature, write the business logic as pure functions. Push all I/O to the boundaries.
What’s Available in Your Language Today
| Language | Sum Types | Exhaustiveness | Result Type | Pattern Matching |
|---|---|---|---|---|
| Rust | enum (first-class) | Built-in, enforced | Result<T, E> + ? | match (exhaustive) |
| TypeScript | Discriminated unions | never check | Custom or fp-ts | switch + narrowing |
| Swift | enum with associated values | Built-in | Result<T, E> | switch |
| Kotlin | Sealed classes | when exhaustive | Result / Either | when |
| Java 17+ | Sealed interfaces + records | Switch expressions | Custom or vavr | Pattern matching (21+) |
| Python 3.10+ | @dataclass unions | match (partial) | Custom or returns | match statement |
| Go | Interface + type switch | No built-in | (T, error) tuple | Type assertions |
Rust stands out because it was designed around these patterns: first-class ADTs, mandatory exhaustive matching, built-in Result/Option with the ? operator, ownership-based concurrency safety, and zero-cost newtypes. But you can apply these ideas in any language as the patterns are about thinking, not syntax.
XII. The Three Laws
All of this comes down to three principles:
- If it can’t be represented, it can’t happen. Illegal states that don’t exist in the type system are bugs that don’t exist in production.
- If it must be handled, it will be handled. When the compiler forces you to address every variant, every error, every edge case then nothing slips through.
- If it’s composed from tested parts, the composition is tested. Pure functions that individually work correctly compose into pipelines that work correctly. No emergent failure modes from unexpected interactions.
Conclusion: Architecture as Enforcement
The legacy system I analyzed had documentation describing its intended architecture. It had design reviews. It had coding guidelines. None of it prevented 441 silent error swallows, 64-state boolean explosions, race conditions in shared mutable state, 5 redundant metrics implementations, or a shared auth token that let any worker forge admin credentials. Documentation describes intent. Tests verify behavior at a point in time. But types enforce invariants continuously on every line of code, in every file, for every developer, for the entire lifetime of the codebase.
ADTs make impossible states unrepresentable. Algebraic effects separate mechanism from policy. Together, they transform architecture from aspiration into enforcement. The compiler doesn’t take vacations. It doesn’t forget edge cases. In a world of distributed systems, concurrent operations, and ever-growing complexity, that’s not just good engineering practice, it’s the only approach that scales.