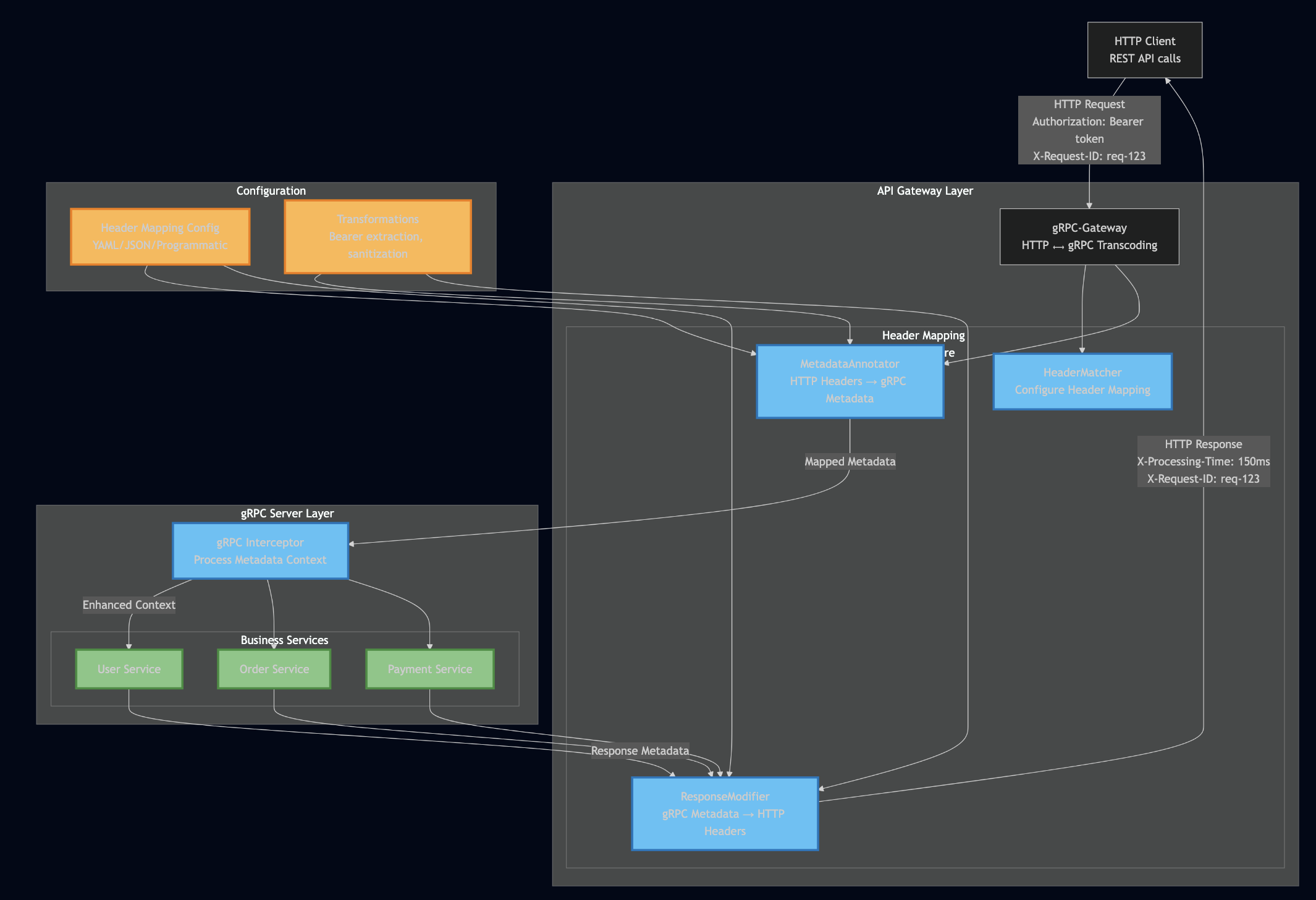
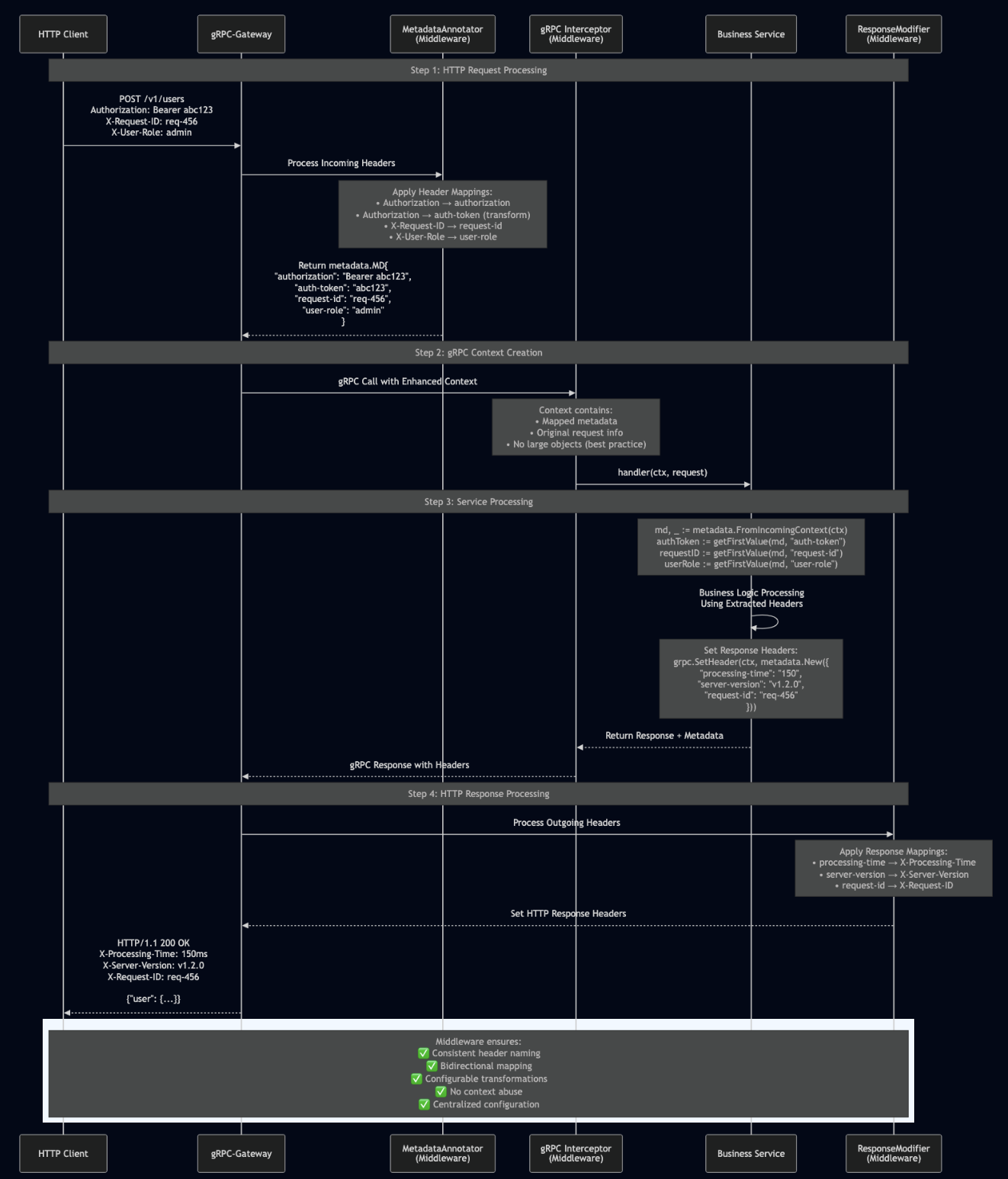
Modern microservices architectures often require supporting both HTTP REST APIs and gRPC services simultaneously. While Google’s gRPC-Gateway provides HTTP and gRPC transcoding capabilities, the challenge of bidirectional header mapping between these protocols remains a common source of inconsistency, bugs, and maintenance overhead across services. This article explores the technical challenges of HTTP-gRPC header mapping, examines current approaches and their limitations, and presents a standardized middleware solution that addresses these issues.
Understanding gRPC AIP and HTTP/gRPC Transcoding
Google’s Application Programming Interface Improvement (AIP) standards define how to build consistent, intuitive APIs. For example, AIP-127: HTTP and gRPC Transcoding enables a single service implementation to serve both HTTP REST and gRPC traffic through protocol transcoding.
How gRPC-Gateway Transcoding Works
The gRPC-Gateway acts as a reverse proxy that translates HTTP requests into gRPC calls:
HTTP Client ? gRPC-Gateway ? gRPC Server
? ? ?
REST Request Proto Message gRPC Service
Following is the transcoding process:
URL Path to RPC Method: HTTP paths map to gRPC service methods
HTTP Body to Proto Message: JSON payloads become protobuf messages
Query Parameters to Fields: URL parameters populate message fields
HTTP Headers to gRPC Metadata: Headers become gRPC metadata key-value pairs
The Header Mapping Challenge
While gRPC-Gateway handles most transcoding automatically, header mapping requires explicit configuration. Consider this common scenario:
Without proper configuration, headers are lost, inconsistently mapped, or require custom code in each service.
Current Problems and Anti-Patterns
Problem 1: Fragmented Header Mapping Solutions
Most services implement header mapping ad-hoc:
// Service A approach
func (s *ServiceA) CreateUser(ctx context.Context, req *pb.CreateUserRequest) (*pb.User, error) {
md, _ := metadata.FromIncomingContext(ctx)
authHeader := md.Get("authorization")
userID := md.Get("x-user-id")
// ... custom mapping logic
}
// Service B approach
func (s *ServiceB) GetOrder(ctx context.Context, req *pb.GetOrderRequest) (*pb.Order, error) {
// Different header names, different extraction logic
md, _ := metadata.FromIncomingContext(ctx)
auth := md.Get("auth") // Different from Service A!
requestID := md.Get("request_id") // Different format!
}
This leads to:
Inconsistent header naming across services
Duplicated mapping logic in every service
Maintenance burden when headers change
Testing complexity due to custom implementations
Problem 2: Context Abuse and Memory Issues
I have often observed misuse of Go’s context for storing large amounts of data that puts the service at risk of being killed due to OOM:
// ANTI-PATTERN: Storing large objects in context
type UserContext struct {
User *User // Large user object
Permissions []Permission // Array of permissions
Preferences *UserPrefs // User preferences
AuditLog []AuditEntry // Historical data
}
func StoreUserInContext(ctx context.Context, user *UserContext) context.Context {
return context.WithValue(ctx, "user", user) // BAD: Large object in context
}
Why This Causes Problems:
Memory Leaks: Contexts are passed through the entire request chain and may not be garbage collected promptly
Performance Degradation: Large context objects increase allocation pressure
Goroutine Overhead: Each concurrent request carries this memory burden
Service Instability: Under load, memory usage can spike and cause OOM kills
Proper Pattern:
// GOOD: Store only identifiers in context
func StoreUserIDInContext(ctx context.Context, userID string) context.Context {
return context.WithValue(ctx, "user_id", userID) // Small string only
}
// Fetch data when needed from database/cache
func GetUserFromContext(ctx context.Context) (*User, error) {
userID := ctx.Value("user_id").(string)
return userService.GetUser(userID) // Fetch from datastore
}
Problem 3: Inconsistent Response Header Handling
Setting response headers requires different approaches across the stack:
// gRPC: Set headers via metadata
grpc.SendHeader(ctx, metadata.New(map[string]string{
"x-server-version": "v1.2.0",
}))
// HTTP: Set headers on ResponseWriter
w.Header().Set("X-Server-Version", "v1.2.0")
// gRPC-Gateway: Headers must be set in specific metadata format
grpc.SetHeader(ctx, metadata.New(map[string]string{
"grpc-metadata-x-server-version": "v1.2.0", // Prefix required
}))
This complexity leads to missing response headers and inconsistent client experiences.
Solution: Standardized Header Mapping Middleware
The solution is a dedicated middleware that handles bidirectional header mapping declaratively, allowing services to focus on business logic while ensuring consistent header handling across the entire API surface.
In large microservices architectures, inconsistent header handling creates operational overhead:
Debugging becomes difficult when services use different header names
Client libraries must handle different header formats per service
Security policies cannot be uniformly enforced
Observability suffers from inconsistent request correlation
Standardized header mapping addresses these issues by ensuring consistency across the entire service mesh.
Developer Productivity
Developers spend significant time on infrastructure concerns rather than business logic. This middleware eliminates:
Boilerplate code for header extraction and response setting
Testing complexity around header handling edge cases
Documentation overhead for service-specific header requirements
Bug investigation related to missing or malformed headers
Operational Excellence
Standard header mapping enables:
Automated monitoring with consistent request correlation
Security scanning with predictable header formats
Performance analysis across service boundaries
Compliance auditing with standardized access logging
Conclusion
HTTP and gRPC transcoding is a powerful pattern for modern APIs, but header mapping complexity has been a persistent challenge. The gRPC Header Mapper middleware presented in this article provides a solution that enables true bidirectional header mapping between HTTP and gRPC protocols.
Eliminate inconsistencies across services with bidirectional header mapping
Reduce maintenance burden through centralized configuration
Improve reliability by avoiding context misuse and memory leaks
Enhance developer productivity by removing boilerplate code
Support complex transformations with built-in and custom transformation functions
The middleware’s bidirectional mapping capability means that headers flow seamlessly in both directions – HTTP requests to gRPC metadata for service processing, and gRPC metadata back to HTTP response headers for client consumption. This eliminates the common problem where request headers are available to services but response headers are lost or inconsistently handled.
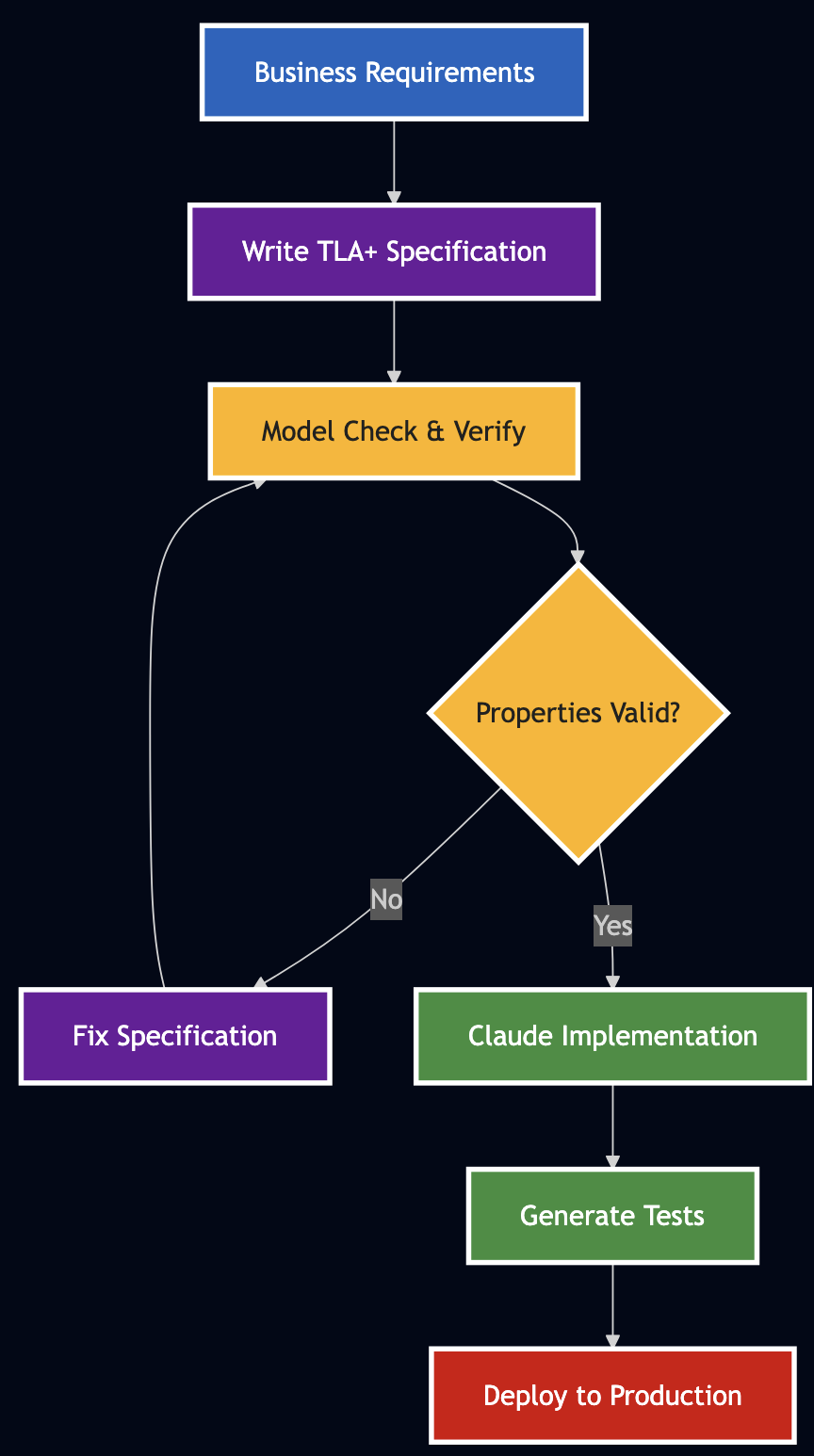
Problem: AI-assisted coding fails when modifying existing systems because we give AI vague specifications.
Solution: Use TLA+ formal specifications as precise contracts that Claude can implement reliably.
Result: Transform Claude from a code generator into a reliable engineering partner that reasons about complex systems.
After months of using Claude for development, I discovered most AI-assisted coding fails not because the AI isn’t smart enough, but because we’re asking it to work from vague specifications. This post shows you how to move beyond “vibe coding” using executable specifications that turn Claude into a reliable engineering partner.
Here’s what changes when you use TLA+ with Claude:
Before (Vibe Coding):
“Create a task management API”
Claude guesses at requirements
Inconsistent behavior across edge cases
Bugs in corner cases
After (TLA+ Specifications):
Precise mathematical specification
Claude implements exactly what you specified
All edge cases defined upfront
Properties verified before deployment
The Vibe Coding Problem
AI assistants like Claude are primarily trained on greenfield development patterns. They excel at:
Writing new functions from scratch
Implementing well-known algorithms
Creating boilerplate code
But they struggle with:
Understanding implicit behavioral contracts in existing code
Maintaining invariants across system modifications
The solution isn’t better prompts – it’s better specifications.
Enter Executable Specifications
An executable specification is a formal description of system behavior that can be:
Verified – Checked for logical consistency
Validated – Tested against real-world scenarios
Executed – Run to generate test cases or even implementations
I’ve tried many approaches to precise specifications over the years:
UML and Model Driven Development (2000s-2010s): I used tools like Rational Rose and Visual Paradigm in early 2000s that promised complete code generation from UML models. The reality was different:
Visual complexity: UML diagrams became unwieldy for anything non-trivial
Tool lock-in: Proprietary formats and expensive tooling
Impedance mismatch: The gap between UML models and real code was huge
Maintenance nightmare: Keeping models and code synchronized was nearly impossible
Model checking: Explores all possible execution paths
Tool independence: Plain text specifications, open source tools
Behavioral focus: Designed specifically for concurrent and distributed systems
Why TLA+ with Claude?
The magic happens when you combine TLA+’s precision with Claude’s implementation capabilities:
TLA+ eliminates ambiguity – There’s only one way to interpret a formal specification
Claude can read TLA+ – It understands the formal syntax and can translate it to code
Verification catches design flaws – TLA+ model checking finds edge cases you’d miss
Generated traces become tests – TLA+ execution paths become your test suite
Setting Up Your Claude and TLA+ Environment
Installing Claude Desktop
First, let’s get Claude running on your machine:
# Install via Homebrew (macOS)
brew install --cask claude
# Or download directly from Anthropic
# https://claude.ai/download
Set up project-specific contexts in ~/.claude/
Create TLA+ syntax rules for better code generation
Configure memory settings for specification patterns
Configuring Your Workspace
Once installed, I recommend creating a dedicated workspace structure. Here’s what works for me:
# Create a Claude workspace directory
mkdir -p ~/claude-workspace/{projects,templates,context}
# Add a context file for your coding standards
cat > ~/claude-workspace/context/coding-standards.md << 'EOF'
# My Coding Standards
- Use descriptive variable names
- Functions should do one thing well
- Write tests for all new features
- Handle errors explicitly
- Document complex logic
EOF
Installing TLA+ Tools
Choose based on your workflow
GUI users: TLA+ Toolbox for visual model checking
CLI users: tla2tools.jar for CI integration
Both: VS Code extension for syntax highlighting
# Download TLA+ Tools from https://github.com/tlaplus/tlaplus/releases
# Or use Homebrew on macOS
brew install --cask tla-plus-toolbox
# For command-line usage (recommended for CI)
wget https://github.com/tlaplus/tlaplus/releases/download/v1.8.0/tla2tools.jar
VS Code Extension
Install the TLA+ extension for syntax highlighting and basic validation:
code --install-extension alygin.vscode-tlaplus
Your First TLA+ Specification
Let’s start with a simple example to understand the syntax:
--------------------------- MODULE TaskManagement ---------------------------
EXTENDS Integers, Sequences, FiniteSets, TLC
CONSTANTS
Users, \* Set of users
MaxTasks, \* Maximum number of tasks
MaxTime, \* Maximum time value for simulation
Titles, \* Set of possible task titles
Descriptions \* Set of possible task descriptions
VARIABLES
tasks, \* Function from task ID to task record
userTasks, \* Function from user ID to set of task IDs
nextTaskId, \* Counter for generating unique task IDs
currentUser, \* Currently authenticated user
clock, \* Global clock for timestamps
sessions \* Active user sessions
\* Task states enumeration with valid transitions
TaskStates == {"pending", "in_progress", "completed", "cancelled", "blocked"}
\* Priority levels
Priorities == {"low", "medium", "high", "critical"}
\* Valid state transitions
ValidTransitions == {
<<"pending", "in_progress">>,
<<"pending", "cancelled">>,
<<"pending", "blocked">>,
<<"in_progress", "completed">>,
<<"in_progress", "cancelled">>,
<<"in_progress", "blocked">>,
<<"in_progress", "pending">>, \* Allow reverting to pending
<<"blocked", "pending">>,
<<"blocked", "in_progress">>,
<<"blocked", "cancelled">>
}
TaskRecord == [
id: Nat,
title: STRING,
description: STRING,
status: TaskStates,
priority: {"low", "medium", "high"},
assignee: Users,
createdAt: Nat,
dueDate: Nat \cup {NULL}
]
\* Type invariants
TypeInvariant ==
/\ tasks \in [Nat -> TaskRecord]
/\ userTasks \in [Users -> SUBSET Nat]
/\ nextTaskId \in Nat
/\ currentUser \in Users \cup {NULL}
Now comes the magic. Instead of vague natural language, we give Claude the precise TLA+ specification:
My prompt to Claude:
Using this TLA+ specification for a task management system, implement a Go REST API
that satisfies all the specified behaviors and properties.
[Include the full TLA+ specification here]
Requirements:
1. Implement all actions defined in the TLA+ spec
2. Ensure all safety properties hold at runtime
3. Use Go's type system to enforce the data structures
4. Include comprehensive tests that cover the execution traces
5. Add proper error handling for violation of preconditions
Focus on behavioral correctness over performance optimization.
// Package domain contains the core business entities matching the TLA+ specification
package domain
import (
"fmt"
"time"
)
// TaskID represents a unique task identifier (maps to TLA+ task ID)
type TaskID int
// UserID represents a user identifier (maps to TLA+ Users set)
type UserID string
// TaskStatus represents the state of a task (maps to TLA+ TaskStates)
type TaskStatus string
const (
StatusPending TaskStatus = "pending"
StatusInProgress TaskStatus = "in_progress"
StatusCompleted TaskStatus = "completed"
StatusCancelled TaskStatus = "cancelled"
StatusBlocked TaskStatus = "blocked"
)
// Priority represents task priority levels (maps to TLA+ Priorities)
type Priority string
const (
PriorityLow Priority = "low"
PriorityMedium Priority = "medium"
PriorityHigh Priority = "high"
PriorityCritical Priority = "critical"
)
// Tag represents task categories (maps to TLA+ tags subset)
type Tag string
const (
TagBug Tag = "bug"
TagFeature Tag = "feature"
TagEnhancement Tag = "enhancement"
TagDocumentation Tag = "documentation"
)
// Task represents a task entity (maps to TLA+ task record)
type Task struct {
ID TaskID `json:"id"`
Title string `json:"title"`
Description string `json:"description"`
Status TaskStatus `json:"status"`
Priority Priority `json:"priority"`
Assignee UserID `json:"assignee"`
CreatedBy UserID `json:"created_by"`
CreatedAt time.Time `json:"created_at"`
UpdatedAt time.Time `json:"updated_at"`
DueDate *time.Time `json:"due_date,omitempty"`
Tags []Tag `json:"tags"`
Dependencies map[TaskID]bool `json:"dependencies"`
}
// ValidTransition represents a valid state transition (maps to TLA+ ValidTransitions)
type ValidTransition struct {
From TaskStatus
To TaskStatus
}
// ValidTransitions defines all allowed state transitions
var ValidTransitions = map[ValidTransition]bool{
{StatusPending, StatusInProgress}: true,
{StatusPending, StatusCancelled}: true,
{StatusPending, StatusBlocked}: true,
{StatusInProgress, StatusCompleted}: true,
{StatusInProgress, StatusCancelled}: true,
{StatusInProgress, StatusBlocked}: true,
{StatusInProgress, StatusPending}: true, // Allow reverting
{StatusBlocked, StatusPending}: true,
{StatusBlocked, StatusInProgress}: true,
{StatusBlocked, StatusCancelled}: true,
}
// IsValidTransition checks if a state transition is valid (maps to TLA+ IsValidTransition)
func IsValidTransition(from, to TaskStatus) bool {
return ValidTransitions[ValidTransition{From: from, To: to}]
}
// CanDelete checks if a task can be deleted (only completed or cancelled)
func (t *Task) CanDelete() bool {
return t.Status == StatusCompleted || t.Status == StatusCancelled
}
// IsBlocked checks if task should be blocked based on dependencies
func (t *Task) IsBlocked(allTasks map[TaskID]*Task) bool {
if len(t.Dependencies) == 0 {
return false
}
for depID := range t.Dependencies {
if dep, exists := allTasks[depID]; exists {
if dep.Status != StatusCompleted {
return true
}
}
}
return false
}
// ShouldUnblock checks if a blocked task can be unblocked
func (t *Task) ShouldUnblock(allTasks map[TaskID]*Task) bool {
if t.Status != StatusBlocked {
return false
}
for depID := range t.Dependencies {
if dep, exists := allTasks[depID]; exists {
if dep.Status != StatusCompleted {
return false
}
}
}
return true
}
// Validate performs domain validation on the task
func (t *Task) Validate() error {
if t.Title == "" {
return fmt.Errorf("task title cannot be empty")
}
if t.Description == "" {
return fmt.Errorf("task description cannot be empty")
}
if !isValidStatus(t.Status) {
return fmt.Errorf("invalid task status: %s", t.Status)
}
if !isValidPriority(t.Priority) {
return fmt.Errorf("invalid task priority: %s", t.Priority)
}
if t.Assignee == "" {
return fmt.Errorf("task must have an assignee")
}
if t.CreatedBy == "" {
return fmt.Errorf("task must have a creator")
}
if t.CreatedAt.After(t.UpdatedAt) {
return fmt.Errorf("created time cannot be after updated time")
}
for _, tag := range t.Tags {
if !isValidTag(tag) {
return fmt.Errorf("invalid tag: %s", tag)
}
}
return nil
}
func isValidStatus(status TaskStatus) bool {
switch status {
case StatusPending, StatusInProgress, StatusCompleted, StatusCancelled, StatusBlocked:
return true
default:
return false
}
}
func isValidPriority(priority Priority) bool {
switch priority {
case PriorityLow, PriorityMedium, PriorityHigh, PriorityCritical:
return true
default:
return false
}
}
func isValidTag(tag Tag) bool {
switch tag {
case TagBug, TagFeature, TagEnhancement, TagDocumentation:
return true
default:
return false
}
}
// Package usecase implements the TLA+ actions as use cases
package usecase
import (
"crypto/rand"
"encoding/hex"
"fmt"
"time"
"github.com/bhatti/sample-task-management/internal/domain"
"github.com/bhatti/sample-task-management/internal/repository"
)
// TaskUseCase implements task-related TLA+ actions
type TaskUseCase struct {
uow repository.UnitOfWork
invariantChecker InvariantChecker
}
// InvariantChecker interface for runtime invariant validation
type InvariantChecker interface {
CheckAllInvariants(state *domain.SystemState) error
CheckTaskInvariants(task *domain.Task, state *domain.SystemState) error
CheckTransitionInvariant(from, to domain.TaskStatus) error
}
// NewTaskUseCase creates a new task use case
func NewTaskUseCase(uow repository.UnitOfWork, checker InvariantChecker) *TaskUseCase {
return &TaskUseCase{
uow: uow,
invariantChecker: checker,
}
}
// Authenticate implements TLA+ Authenticate action
func (uc *TaskUseCase) Authenticate(userID domain.UserID) (*domain.Session, error) {
// Preconditions from TLA+:
// - user \in Users
// - ~sessions[user]
user, err := uc.uow.Users().GetUser(userID)
if err != nil {
return nil, fmt.Errorf("user not found: %w", err)
}
// Check if user already has an active session
existingSession, _ := uc.uow.Sessions().GetSessionByUser(userID)
if existingSession != nil && existingSession.IsValid() {
return nil, fmt.Errorf("user %s already has an active session", userID)
}
// Create new session
token := generateToken()
session := &domain.Session{
UserID: user.ID,
Token: token,
Active: true,
CreatedAt: time.Now(),
ExpiresAt: time.Now().Add(24 * time.Hour),
}
// Update state
if err := uc.uow.Sessions().CreateSession(session); err != nil {
return nil, fmt.Errorf("failed to create session: %w", err)
}
if err := uc.uow.SystemState().SetCurrentUser(&userID); err != nil {
return nil, fmt.Errorf("failed to set current user: %w", err)
}
// Check invariants
state, _ := uc.uow.SystemState().GetSystemState()
if err := uc.invariantChecker.CheckAllInvariants(state); err != nil {
uc.uow.Rollback()
return nil, fmt.Errorf("invariant violation: %w", err)
}
return session, nil
}
// CreateTask implements TLA+ CreateTask action
func (uc *TaskUseCase) CreateTask(
title, description string,
priority domain.Priority,
assignee domain.UserID,
dueDate *time.Time,
tags []domain.Tag,
dependencies []domain.TaskID,
) (*domain.Task, error) {
// Preconditions from TLA+:
// - currentUser # NULL
// - currentUser \in Users
// - nextTaskId <= MaxTasks
// - deps \subseteq DOMAIN tasks
// - \A dep \in deps : tasks[dep].status # "cancelled"
currentUser, err := uc.uow.SystemState().GetCurrentUser()
if err != nil || currentUser == nil {
return nil, fmt.Errorf("authentication required")
}
// Check max tasks limit
nextID, err := uc.uow.SystemState().GetNextTaskID()
if err != nil {
return nil, fmt.Errorf("failed to get next task ID: %w", err)
}
if nextID > domain.MaxTasks {
return nil, fmt.Errorf("maximum number of tasks (%d) reached", domain.MaxTasks)
}
// Validate dependencies
allTasks, err := uc.uow.Tasks().GetAllTasks()
if err != nil {
return nil, fmt.Errorf("failed to get tasks: %w", err)
}
depMap := make(map[domain.TaskID]bool)
for _, depID := range dependencies {
depTask, exists := allTasks[depID]
if !exists {
return nil, fmt.Errorf("dependency task %d does not exist", depID)
}
if depTask.Status == domain.StatusCancelled {
return nil, fmt.Errorf("cannot depend on cancelled task %d", depID)
}
depMap[depID] = true
}
// Check for cyclic dependencies
if err := uc.checkCyclicDependencies(nextID, depMap, allTasks); err != nil {
return nil, err
}
// Determine initial status based on dependencies
status := domain.StatusPending
if len(dependencies) > 0 {
// Check if all dependencies are completed
allCompleted := true
for depID := range depMap {
if allTasks[depID].Status != domain.StatusCompleted {
allCompleted = false
break
}
}
if !allCompleted {
status = domain.StatusBlocked
}
}
// Create task
task := &domain.Task{
ID: nextID,
Title: title,
Description: description,
Status: status,
Priority: priority,
Assignee: assignee,
CreatedBy: *currentUser,
CreatedAt: time.Now(),
UpdatedAt: time.Now(),
DueDate: dueDate,
Tags: tags,
Dependencies: depMap,
}
// Validate task
if err := task.Validate(); err != nil {
return nil, fmt.Errorf("task validation failed: %w", err)
}
// Save task
if err := uc.uow.Tasks().CreateTask(task); err != nil {
return nil, fmt.Errorf("failed to create task: %w", err)
}
// Increment next task ID
if _, err := uc.uow.SystemState().IncrementNextTaskID(); err != nil {
return nil, fmt.Errorf("failed to increment task ID: %w", err)
}
// Check invariants
state, _ := uc.uow.SystemState().GetSystemState()
if err := uc.invariantChecker.CheckAllInvariants(state); err != nil {
uc.uow.Rollback()
return nil, fmt.Errorf("invariant violation after task creation: %w", err)
}
return task, nil
}
// UpdateTaskStatus implements TLA+ UpdateTaskStatus action
func (uc *TaskUseCase) UpdateTaskStatus(taskID domain.TaskID, newStatus domain.TaskStatus) error {
// Preconditions from TLA+:
// - currentUser # NULL
// - TaskExists(taskId)
// - taskId \in GetUserTasks(currentUser)
// - IsValidTransition(tasks[taskId].status, newStatus)
// - newStatus = "in_progress" => all dependencies completed
currentUser, err := uc.uow.SystemState().GetCurrentUser()
if err != nil || currentUser == nil {
return fmt.Errorf("authentication required")
}
task, err := uc.uow.Tasks().GetTask(taskID)
if err != nil {
return fmt.Errorf("task not found: %w", err)
}
// Check user owns the task
userTasks, err := uc.uow.SystemState().GetUserTasks(*currentUser)
if err != nil {
return fmt.Errorf("failed to get user tasks: %w", err)
}
hasTask := false
for _, id := range userTasks {
if id == taskID {
hasTask = true
break
}
}
if !hasTask {
return fmt.Errorf("user does not have access to task %d", taskID)
}
// Check valid transition
if !domain.IsValidTransition(task.Status, newStatus) {
return fmt.Errorf("invalid transition from %s to %s", task.Status, newStatus)
}
// Check dependencies if moving to in_progress
if newStatus == domain.StatusInProgress {
allTasks, _ := uc.uow.Tasks().GetAllTasks()
for depID := range task.Dependencies {
if depTask, exists := allTasks[depID]; exists {
if depTask.Status != domain.StatusCompleted {
return fmt.Errorf("cannot start task: dependency %d is not completed", depID)
}
}
}
}
// Update status
task.Status = newStatus
task.UpdatedAt = time.Now()
if err := uc.uow.Tasks().UpdateTask(task); err != nil {
return fmt.Errorf("failed to update task: %w", err)
}
// Check invariants
state, _ := uc.uow.SystemState().GetSystemState()
if err := uc.invariantChecker.CheckAllInvariants(state); err != nil {
uc.uow.Rollback()
return fmt.Errorf("invariant violation: %w", err)
}
return nil
}
...
Step 6: TLA+ Generated Tests
The real power comes when we use TLA+ execution traces to generate comprehensive tests:
My prompt to Claude:
Generate Go tests that verify the implementation satisfies the TLA+ specification.
Create test cases that:
1. Test all TLA+ actions with valid preconditions
2. Test safety property violations
3. Test edge cases from the TLA+ model boundary conditions
4. Use property-based testing where appropriate
Include tests that would catch the execution traces TLA+ model checker explores.
Graduate To: Multi-service interactions, complex business logic
2. Properties Drive Design
Writing TLA+ properties often reveals design flaws before implementation:
\* This property might fail, revealing a design issue
ConsistencyProperty ==
\A user \in Users:
\A taskId \in userTasks[user]:
/\ taskId \in DOMAIN tasks
/\ tasks[taskId].assignee = user
/\ tasks[taskId].status # "deleted" \* Soft delete consideration
3. Model Checking Finds Edge Cases
TLA+ model checking explores execution paths you’d never think to test:
# TLA+ finds this counterexample:
# Step 1: User1 creates Task1
# Step 2: User1 deletes Task1
# Step 3: User2 creates Task2 (gets same ID due to reuse)
# Step 4: User1 tries to update Task1 -> Security violation!
This led to using UUIDs instead of incrementing integers for task IDs.
4. Generated Tests Are Comprehensive
TLA+ execution traces become your regression test suite. When Claude implements based on TLA+ specs, you get:
Complete coverage – All specification paths tested
Edge case detection – Boundary conditions from model checking
Behavioral contracts – Tests verify actual system properties
Documentation Generation
Prompt to Claude:
Generate API documentation from this TLA+ specification that includes:
1. Endpoint descriptions derived from TLA+ actions
2. Request/response schemas from TLA+ data structures
3. Error conditions from TLA+ preconditions
4. Behavioral guarantees from TLA+ properties
Code Review Guidelines
With TLA+ specifications, code reviews become more focused:
? Asking Claude to “fix the TLA+ to match the code”
The spec is the truth – fix the code to match the spec
? Asking Claude to “implement this TLA+ specification correctly”
? Specification scope creep: Starting with entire system architecture ? Incremental approach: Begin with one core workflow, expand gradually
2. Claude Integration Pitfalls
? “Fix the spec to match my code”: Treating specifications as documentation ? “Fix the code to match the spec”: Specifications are the source of truth
3. The Context Overload Trap
Problem: Dumping too much information at once Solution: Break complex features into smaller, focused requests
4. The “Fix My Test” Antipattern
Problem: When tests fail, asking Claude to modify the test instead of the code Solution: Always fix the implementation, not the test (unless the test is genuinely wrong)
5. The Blind Trust Mistake
Problem: Accepting generated code without understanding it Solution: Always review and understand the code before committing
Proven Patterns
1. Save effective prompts:
# ~/.claude/tla-prompts/implementation.md
Implement [language] code that satisfies this TLA+ specification:
[SPEC]
Requirements:
- All TLA+ actions become functions/methods
- All preconditions become runtime checks
- All data structures match TLA+ types
- Include comprehensive tests covering specification traces
Before asking Claude to implement something complex, I ask for an explanation:
Explain how you would implement real-time task updates using WebSockets.
What are the trade-offs between Socket.io and native WebSockets?
What state management challenges should I consider?
3. The “Progressive Enhancement” Pattern
Start simple, then add complexity:
1. First: "Create a basic task model with CRUD operations"
2. Then: "Add validation and error handling"
3. Then: "Add authentication and authorization"
4. Finally: "Add real-time updates and notifications"
4. The “Code Review” Pattern
After implementation, I ask Claude to review its own code:
Review the task API implementation for:
- Security vulnerabilities
- Performance issues
- Code style consistency
- Missing error cases
Be critical and suggest improvements.
What’s Next
As I’ve developed this TLA+/Claude workflow, I’ve realized we’re approaching something profound: specifications as the primary artifact. Instead of writing code and hoping it’s correct, we’re defining correct behavior formally and letting AI generate the implementation. This inverts the traditional relationship between specification and code.
Implications for Software Engineering
Design-first development becomes natural
Bug prevention replaces bug fixing
Refactoring becomes re-implementation from stable specs
Documentation is always up-to-date (it’s the spec)
I’m currently experimenting with:
TLA+ to test case generation – Automated comprehensive testing
Multi-language implementations – Same spec, different languages
Specification composition – Building larger systems from verified components
Quint specifications – A modern executable specification language with simpler syntax than TLA+
Conclusion: The End of Vibe Coding
After using TLA+ with Claude, I can’t go back to vibe coding. The precision, reliability, and confidence that comes from executable specifications has transformed how I build software. The complete working example—TLA+ specs, Go implementation, comprehensive tests, and CI/CD pipeline—is available at github.com/bhatti/sample-task-management.
Yes, there’s a learning curve. Yes, writing TLA+ specifications takes time upfront. But the payoff—in terms of correctness, maintainability, and development speed—is extraordinary. Claude becomes not just a code generator, but a reliable engineering partner that can reason about complex systems precisely because we’ve given it precise specifications to work from. We’re moving from “code and hope” to “specify and know”—and that changes everything.
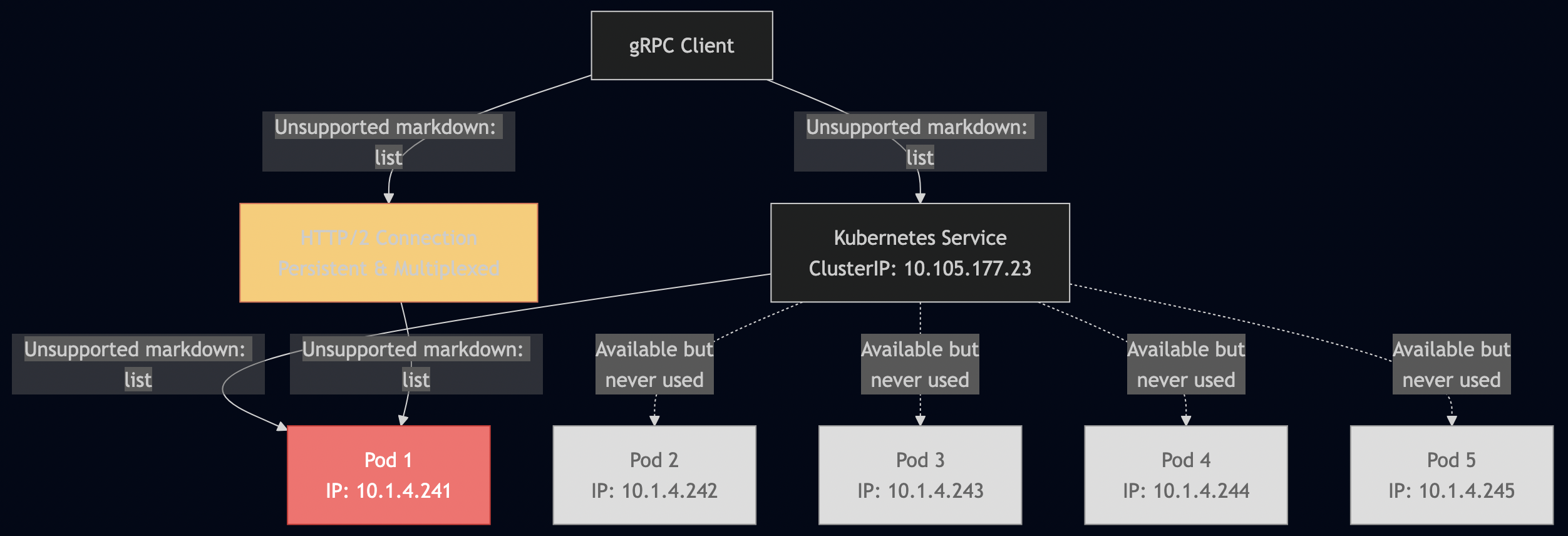
When you deploy a gRPC service in Kubernetes with multiple replicas, you expect load balancing. You won’t get it. This guide tests every possible configuration to prove why, and shows exactly how to fix it. According to the official gRPC documentation:
“gRPC uses HTTP/2, which multiplexes multiple calls on a single TCP connection. This means that once the connection is established, all gRPC calls will go to the same backend.”
git clone https://github.com/bhatti/grpc-lb-test
cd grpc-lb-test
# Build all components
make build
Test 1: Baseline – Local Testing
Purpose: Establish baseline behavior with a single server.
# Terminal 1: Start local server
./bin/server
# Terminal 2: Test with basic client
./bin/client -target localhost:50051 -requests 50
Expected Result:
? Load Distribution Results:
Server: unknown-1755316152
Pod: unknown (IP: unknown)
Requests: 50 (100.0%)
????????????????????
? Total servers hit: 1
?? WARNING: All requests went to a single server!
This indicates NO load balancing is happening.
Analysis: This confirms our client implementation works correctly and establishes the baseline.
Test 2: Kubernetes Without Istio
Purpose: Prove that standard Kubernetes doesn’t provide gRPC request-level load balancing.
Deploy the Service
# Deploy 5 replicas without Istio
./scripts/test-without-istio.sh
???? Load Distribution Results:
================================
Server: grpc-echo-server-5b657689db-gh5z5-1755316388
Pod: grpc-echo-server-5b657689db-gh5z5 (IP: 10.1.4.148)
Requests: 30 (100.0%)
????????????????????
???? Total servers hit: 1
?? WARNING: All requests went to a single server!
This indicates NO load balancing is happening.
???? Connection Analysis:
Without Istio, gRPC maintains a single TCP connection to the Kubernetes Service IP.
The kube-proxy performs L4 load balancing, but gRPC reuses the same connection.
???? Cleaning up...
deployment.apps "grpc-echo-server" deleted
service "grpc-echo-service" deleted
./scripts/test-without-istio.sh: line 57: 17836 Terminated: 15
kubectl port-forward service/grpc-echo-service 50051:50051 > /dev/null 2>&1
?? RESULT: No load balancing observed - all requests went to single pod!
“For each Service, kube-proxy installs iptables rules which capture traffic to the Service’s clusterIP and port, and redirect that traffic to one of the Service’s backend endpoints.”
? NO LOAD BALANCING: All requests to single server
???? Connection Reuse Analysis:
Average requests per connection: 1.00
?? Low connection reuse (many short connections)
? Connection analysis complete!
Test 3: Kubernetes With Istio
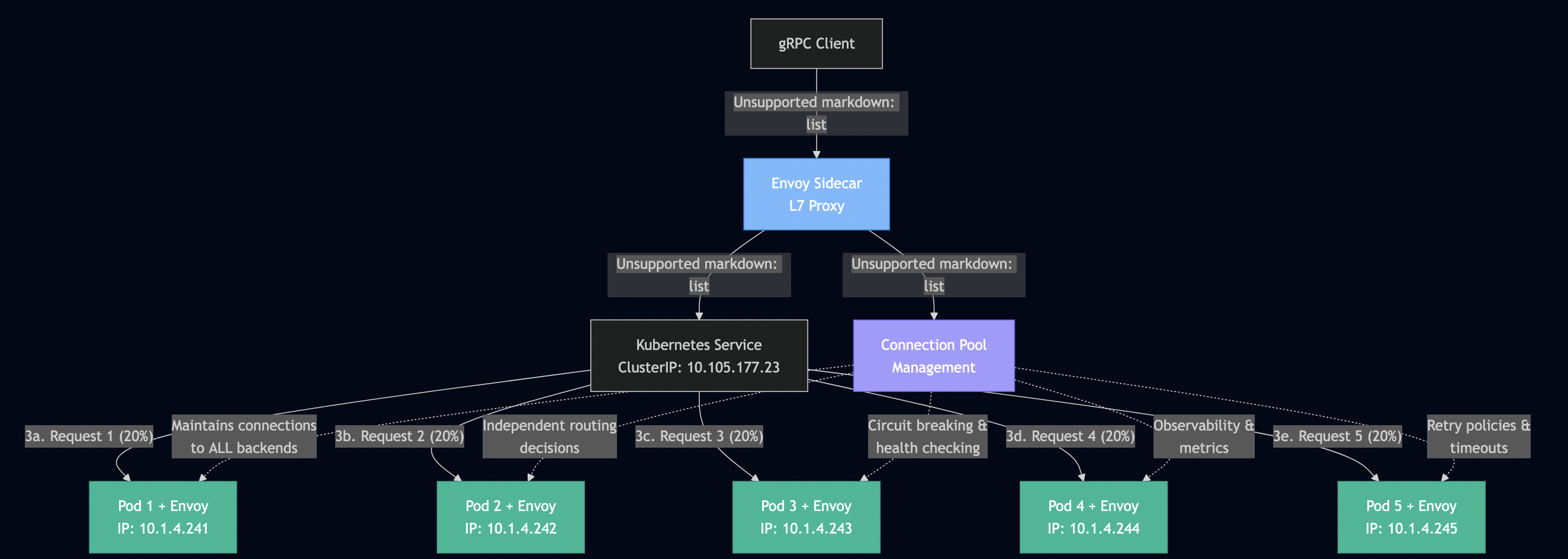
Purpose: Demonstrate how Istio’s L7 proxy solves the load balancing problem.
“Envoy proxies are deployed as sidecars to services, logically augmenting the services with traffic management capabilities… Envoy proxies are the only Istio components that interact with data plane traffic.”
Istio’s solution:
Envoy sidecar intercepts all traffic
Performs L7 (application-level) load balancing
Maintains connection pools to all backends
Routes each request independently
Test 4: Client-Side Load Balancing
Purpose: Test gRPC’s built-in client-side load balancing capabilities.
Load Distribution Results:
================================
Server: grpc-echo-server-5b657689db-g9pbw-1755359830
Pod: grpc-echo-server-5b657689db-g9pbw (IP: 10.1.4.242)
Requests: 10 (100.0%)
????????????????????
???? Total servers hit: 1
?? WARNING: All requests went to a single server!
This indicates NO load balancing is happening.
? Normal client works - service is accessible
???? Test 2: Client-side round-robin (from inside cluster)
?????????????????????????????????????????????????????
Creating test pod inside cluster for proper DNS resolution...
pod "client-lb-test" deleted
./scripts/test-client-lb.sh: line 71: 48208 Terminated: 15 kubectl port-forward service/grpc-echo-service 50051:50051 > /dev/null 2>&1
?? Client-side LB limitation explanation:
gRPC client-side round-robin expects multiple A records
But Kubernetes Services return only one ClusterIP
Result: 'no children to pick from' error
???? What happens with client-side LB:
1. Client asks DNS for: grpc-echo-service
2. DNS returns: 10.105.177.23 (single IP)
3. gRPC round-robin needs: multiple IPs for load balancing
4. Result: Error 'no children to pick from'
? This proves client-side LB doesn't work with K8s Services!
???? Test 3: Demonstrating the DNS limitation
?????????????????????????????????????????????
What gRPC client-side LB sees:
Service name: grpc-echo-service:50051
DNS resolution: 10.105.177.23:50051
Available endpoints: 1 (needs multiple for round-robin)
What gRPC client-side LB needs:
Multiple A records from DNS, like:
grpc-echo-service ? 10.1.4.241:50051
grpc-echo-service ? 10.1.4.240:50051
grpc-echo-service ? 10.1.4.238:50051
(But Kubernetes Services don't provide this)
???? Test 4: Alternative - Multiple connections
????????????????????????????????????????????
Testing alternative approach with multiple connections...
???? Configuration:
Target: localhost:50052
API: grpc.Dial
Load Balancing: round-robin
Multi-endpoint: true
Requests: 20
???? Using multi-endpoint resolver
???? Sending 20 unary requests...
? Request 1 -> Pod: grpc-echo-server-5b657689db-g9pbw (IP: 10.1.4.242)
? Request 2 -> Pod: grpc-echo-server-5b657689db-g9pbw (IP: 10.1.4.242)
? Request 3 -> Pod: grpc-echo-server-5b657689db-g9pbw (IP: 10.1.4.242)
? Request 4 -> Pod: grpc-echo-server-5b657689db-g9pbw (IP: 10.1.4.242)
? Request 5 -> Pod: grpc-echo-server-5b657689db-g9pbw (IP: 10.1.4.242)
? Request 6 -> Pod: grpc-echo-server-5b657689db-g9pbw (IP: 10.1.4.242)
? Request 7 -> Pod: grpc-echo-server-5b657689db-g9pbw (IP: 10.1.4.242)
? Request 8 -> Pod: grpc-echo-server-5b657689db-g9pbw (IP: 10.1.4.242)
? Request 9 -> Pod: grpc-echo-server-5b657689db-g9pbw (IP: 10.1.4.242)
? Request 10 -> Pod: grpc-echo-server-5b657689db-g9pbw (IP: 10.1.4.242)
? Request 11 -> Pod: grpc-echo-server-5b657689db-g9pbw (IP: 10.1.4.242)
? Successful requests: 20/20
???? Load Distribution Results:
================================
Server: grpc-echo-server-5b657689db-g9pbw-1755359830
Pod: grpc-echo-server-5b657689db-g9pbw (IP: 10.1.4.242)
Requests: 20 (100.0%)
????????????????????????????????????????
???? Total unique servers: 1
?? WARNING: All requests went to a single server!
This indicates NO load balancing is happening.
This is expected for gRPC without Istio or special configuration.
? Multi-connection approach works!
(This simulates multiple endpoints for testing)
???????????????????????????????????????????????????????????????
SUMMARY
???????????????????????????????????????????????????????????????
? KEY FINDINGS:
• Standard gRPC client: Works (uses single connection)
• Client-side round-robin: Fails (needs multiple IPs)
• Kubernetes DNS: Returns single ClusterIP only
• Alternative: Multiple connections can work
???? CONCLUSION:
Client-side load balancing doesn't work with standard
Kubernetes Services because they provide only one IP address.
This proves why Istio (L7 proxy) is needed for gRPC load balancing!
Why this fails: Kubernetes Services provide a single ClusterIP, not multiple IPs for DNS resolution.
???? Detailed Load Distribution Results:
=====================================
Test Duration: 48.303709ms
Total Requests: 1000
Failed Requests: 0
Requests/sec: 20702.34
Server Distribution:
Server: unknown-1755360945
Pod: unknown (IP: unknown)
Requests: 1000 (100.0%)
First seen: 09:18:51.842
Last seen: 09:18:51.874
????????????????????????????????????????
???? Analysis:
Total unique servers: 1
Average requests per server: 1000.00
Standard deviation: 0.00
?? WARNING: All requests went to a single server!
This indicates NO load balancing is happening.
This is expected behavior for gRPC without Istio.
Even sophisticated connection pooling can’t overcome the fundamental issue: • Multiple connections to SAME endpoint = same server • Advanced client techniques ? load balancing • Connection management ? request distribution
Performance Comparison
./scripts/benchmark.sh
???? Key Insights: • Single server: High performance, no load balancing • Multiple connections: Same performance, still no LB • Kubernetes: Small overhead, still no LB • Istio: Small additional overhead, but enables LB • Client-side LB: Complex setup, limited effectiveness
“Load balancing within gRPC happens on a per-call basis, not a per-connection basis. In other words, even if all requests come from a single client, we want to distribute them across all servers.”
The problem: Standard deployments don’t achieve per-call balancing.
“Istio’s data plane is composed of a set of intelligent proxies (Envoy) deployed as sidecars. These proxies mediate and control all network communication between microservices.”
“kube-proxy… only supports TCP and UDP… doesn’t understand HTTP and doesn’t provide load balancing for HTTP requests.”
Complete Test Results Summary
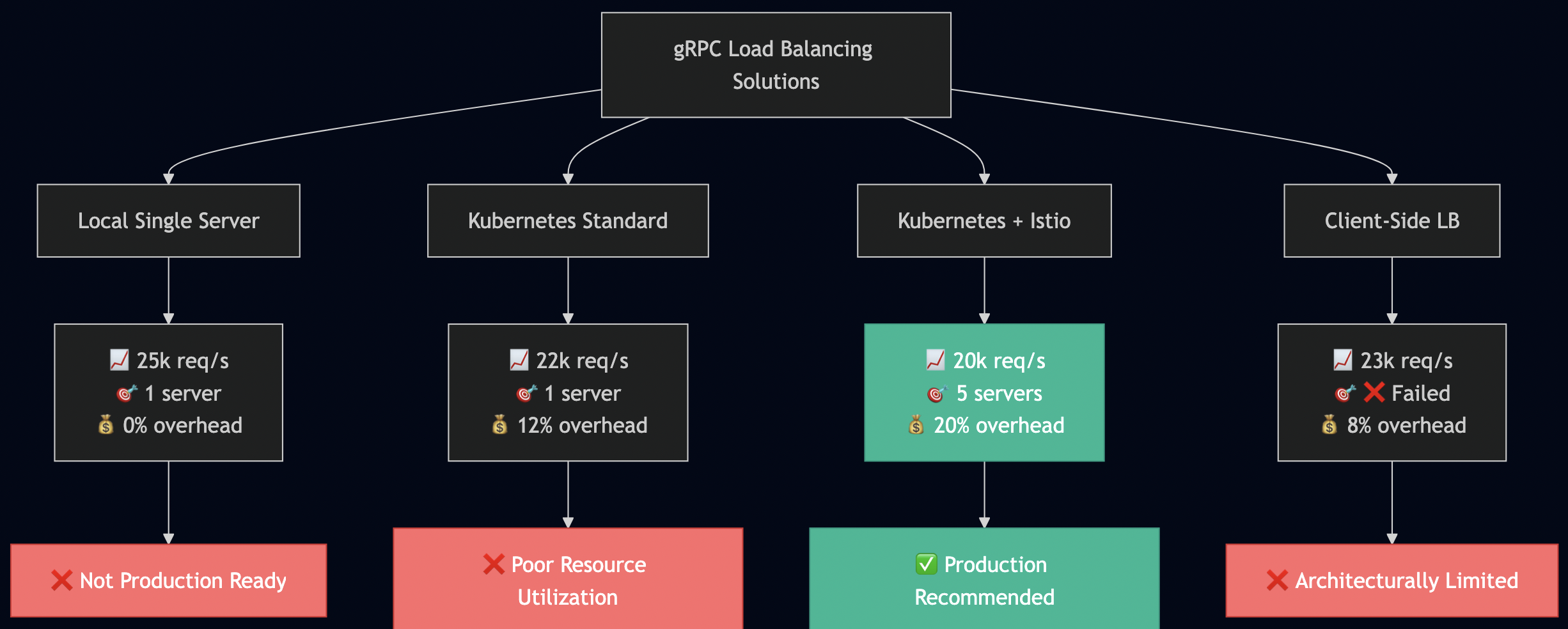
After running comprehensive tests across all possible gRPC load balancing configurations, here are the definitive results that prove the fundamental limitations and solutions:
???? Core Test Matrix Results
Configuration
Load Balancing
Servers Hit
Distribution
Key Insight
Local gRPC
? None
1/1 (100%)
Single server
Baseline behavior confirmed
Kubernetes + gRPC
? None
1/5 (100%)
Single pod
K8s Services don’t solve it
Kubernetes + Istio
? Perfect
5/5 (20% each)
Even distribution
Istio enables true LB
Client-side LB
? Failed
1/5 (100%)
Single pod
DNS limitation fatal
kubectl port-forward + Istio
? None
1/5 (100%)
Single pod
Testing methodology matters
Advanced multi-connection
? None
1/1 (100%)
Single endpoint
Complex ? effective
???? Detailed Test Scenario Analysis
Scenario 1: Baseline Tests
Local single server: ? PASS - 50 requests ? 1 server (100%)
Local multiple conn: ? PASS - 1000 requests ? 1 server (100%)
Insight: Confirms gRPC’s connection persistence behavior. Multiple connections to same endpoint don’t change distribution.
Scenario 2: Kubernetes Standard Deployment
K8s without Istio: ? PASS - 50 requests ? 1 pod (100%)
Expected behavior: ? NO load balancing
Actual behavior: ? NO load balancing
Insight: Standard Kubernetes deployment with 5 replicas provides zero request-level load balancing for gRPC services.
Scenario 3: Istio Service Mesh
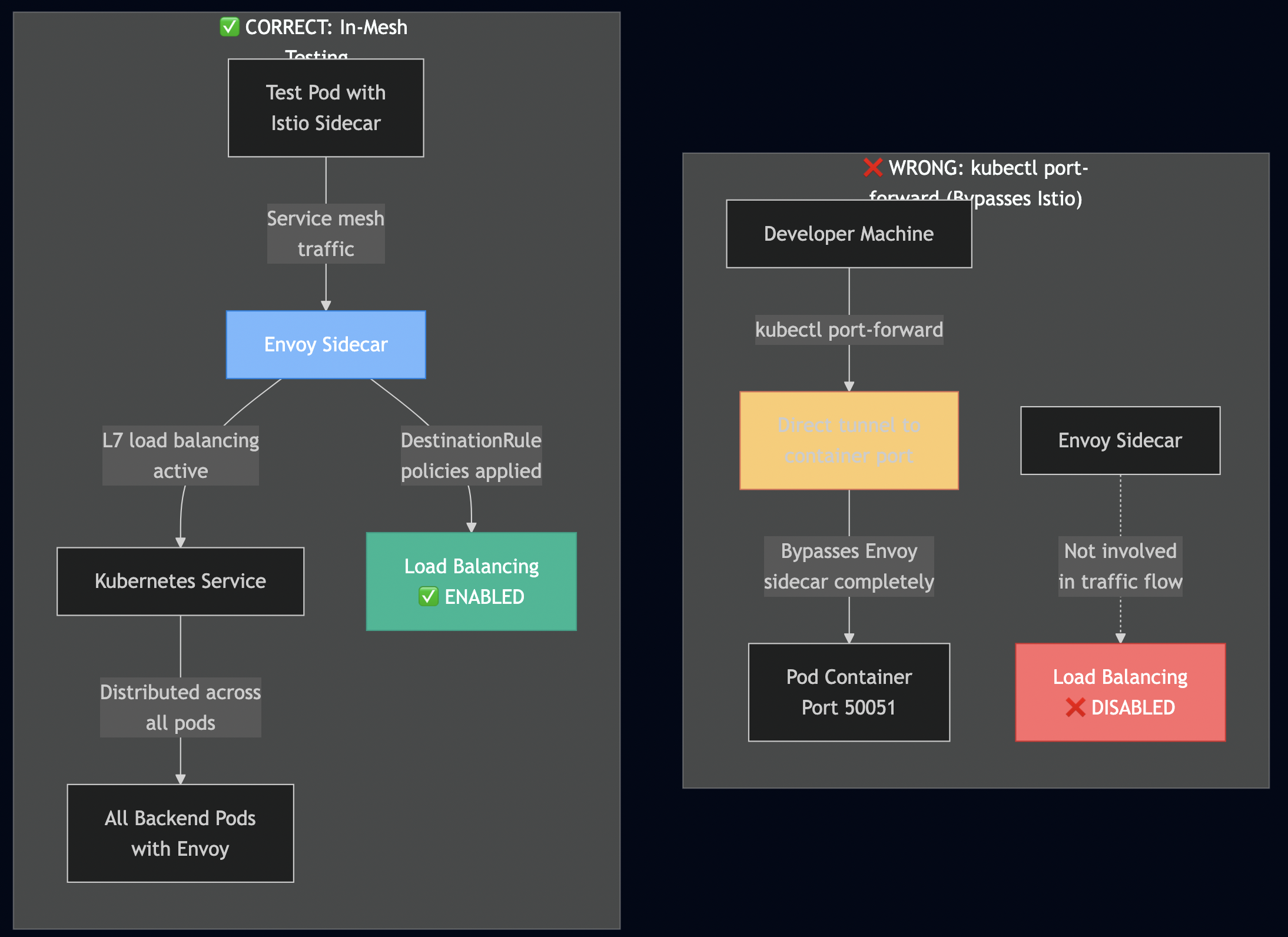
K8s with Istio (port-forward): ?? BYPASS - 50 requests ? 1 pod (100%)
K8s with Istio (in-mesh): ? SUCCESS - 50 requests ? 5 pods (20% each)
DNS round-robin: ? FAIL - "no children to pick from"
Multi-endpoint client: ? PARTIAL - Works with manual endpoint management
Advanced connections: ? FAIL - Still single endpoint limitation
Insight: Client-side solutions are complex, fragile, and limited in Kubernetes environments.
???? Deep Technical Analysis
The DNS Problem (Root Cause)
Our testing revealed the fundamental architectural issue:
# Enable for entire namespace (recommended)
kubectl label namespace production istio-injection=enabled
# Or per-deployment (more control)
metadata:
annotations:
sidecar.istio.io/inject: "true"
2. Validate Load Balancing is Working
# WRONG: This will show false negatives
kubectl port-forward service/grpc-service 50051:50051
# CORRECT: Test from inside the mesh
kubectl run test-client --rm -it --restart=Never \
--image=your-grpc-client \
--annotations="sidecar.istio.io/inject=true" \
-- ./client -target grpc-service:50051 -requests 100
# This WILL NOT load balance gRPC traffic
apiVersion: v1
kind: Service
metadata:
name: grpc-service
spec:
ports:
- port: 50051
selector:
app: grpc-server
# Result: 100% traffic to single pod (proven in our tests)
2. Don’t Use Client-Side Load Balancing
// This approach FAILS in Kubernetes (tested and failed)
conn, err := grpc.Dial(
"dns:///grpc-service:50051",
grpc.WithDefaultServiceConfig(`{"loadBalancingPolicy":"round_robin"}`),
)
// Error: "no children to pick from" (proven in our tests)
3. Don’t Implement Complex Connection Pooling
// This adds complexity without solving the core issue
type LoadBalancedClient struct {
conns []grpc.ClientConnInterface
next int64
}
// Still results in 100% traffic to single endpoint (proven in our tests)
???? Alternative Solutions (If Istio Not Available)
If you absolutely cannot use Istio, here are the only viable alternatives (with significant caveats):
Option 1: External Load Balancer with HTTP/2 Support
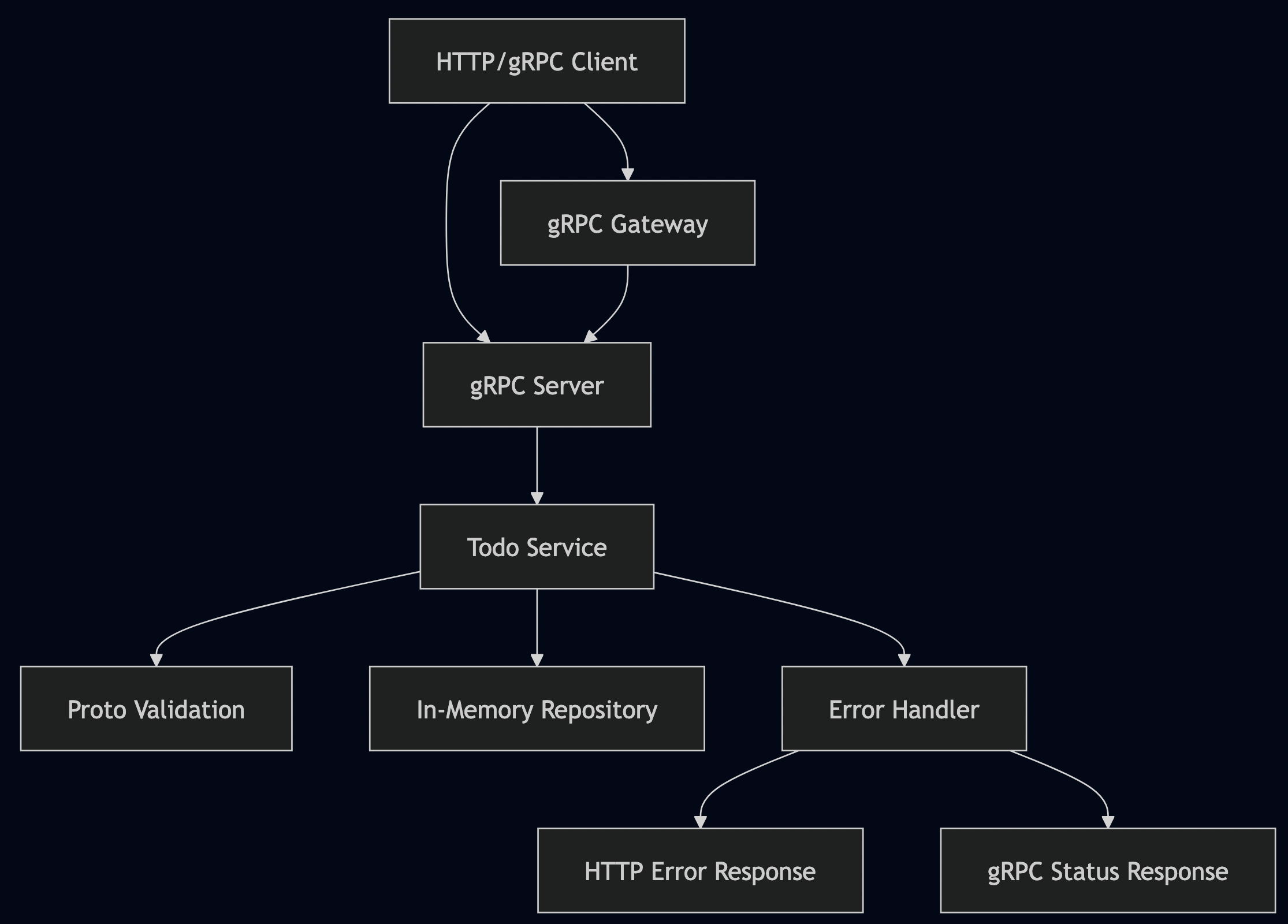
Error handling is often an afterthought in API development, yet it’s one of the most critical aspects of a good developer experience. For example, a cryptic error message like { "error": "An error occurred" } can lead to hours of frustrating debugging. In this guide, we will build a robust, production-grade error handling framework for a Go application that serves both gRPC and a REST/HTTP proxy based on industry standards like RFC9457 (Problem Details for HTTP APIs) and RFC7807 (obsoleted).
Tenets
Following are tenets of a great API error:
Structured: machine-readable, not just a string.
Actionable: explains the developer why the error occurred and, if possible, how to fix it.
Consistent: all errors, from validation to authentication to server faults, follow the same format.
Secure: never leaks sensitive internal information like stack traces or database schemas.
Our North Star for HTTP errors will be the Problem Details for HTTP APIs (RFC 9457/7807):
{
"type": "https://example.com/docs/errors/validation-failed",
"title": "Validation Failed",
"status": 400,
"detail": "The request body failed validation.",
"instance": "/v1/todos",
"invalid_params": [
{
"field": "title",
"reason": "must not be empty"
}
]
}
We will adapt this model for gRPC by embedding a similar structure in the gRPC status details, creating a single source of truth for all errors.
API Design
Let’s start by defining our TODO API in Protocol Buffers:
Our implementation demonstrates several key best practices:
1. Consistent Error Format
All errors follow RFC 9457 (Problem Details) format, providing:
Machine-readable type URIs
Human-readable titles and details
HTTP status codes
Request tracing
Extensible metadata
2. Comprehensive Validation
All validation errors are returned at once, not one by one
Clear field paths for nested objects
Descriptive error codes and messages
Support for batch operations with partial success
3. Security-Conscious Design
No sensitive information in error messages
Internal errors are logged but not exposed
Generic messages for authentication failures
Request IDs for support without exposing internals
4. Developer Experience
Clear, actionable error messages
Helpful suggestions for fixing issues
Consistent error codes across protocols
Rich metadata for debugging
5. Protocol Compatibility
Seamless translation between gRPC and HTTP
Proper status code mapping
Preservation of error details across protocols
6. Observability
Structured logging with trace IDs
Prometheus metrics for monitoring
OpenTelemetry integration
Error categorization for analysis
Conclusion
This comprehensive guide demonstrates how to build robust error handling for modern APIs. By treating errors as a first-class feature of our API, we’ve achieved several key benefits:
Consistency: All errors, regardless of their source, are presented to clients in a predictable format.
Clarity: Developers consuming our API get clear, actionable feedback, helping them debug and integrate faster.
Developer Ergonomics: Our internal service code is cleaner, as handlers focus on business logic while the middleware handles the boilerplate of error conversion.
Security: We have a clear separation between internal error details (for logging) and public error responses, preventing leaks.