I’ve worked at organizations where engineers would sneak changes into production, bypassing CI/CD pipelines, hoping nobody would notice if something broke. I’ve also worked at places where engineers would openly discuss a failed experiment at standup and get help fixing it. The difference wasn’t the engineers—it was psychological safety. Research on psychological safety, particularly from high-stakes industries like healthcare, tells us something counterintuitive: teams with high psychological safety don’t have fewer incidents. They have better outcomes because people speak up about problems early.
Software engineering isn’t life-or-death medicine, but the principle holds: in blame cultures, I’ve watched talented engineers:
Deploy sketchy changes outside normal hours to avoid oversight
Blame infrastructure, legacy code, or “the previous team” rather than examining their contributions
Build elaborate workarounds instead of fixing root causes
These behaviors don’t just hurt morale—they actively degrade reliability. Post mortems in blame cultures become exercises in creative finger-pointing and CYA documentation.
In learning cultures, post mortems are gold mines of organizational knowledge. The rule of thumb I’ve seen work best: if you’re unsure whether something deserves a post mortem, write one anyway—at least internally. Not every post mortem needs wide distribution, and some (especially those with security implications) shouldn’t be shared externally. But the act of writing crystallizes learning.
The Real Problem: Post Mortem Theater
Here’s what nobody talks about: many organizations claim to value post mortems but treat them like bureaucratic checklists. I’ve seen hundreds of meticulously documented post mortems that somehow don’t prevent the same incidents from recurring. This is what I call “post mortem theater”—going through the motions without actual learning.
Shallow vs. Deep Analysis
Shallow analysis stops at the proximate cause:
“The database connection pool was exhausted”
“An engineer deployed buggy code”
“A dependency had high latency”
Deep analysis asks uncomfortable questions:
“Why don’t we load test with production-scale data? What makes it expensive to maintain realistic test environments?”
“Why did code review and automated tests miss this? What’s our philosophy on preventing bugs vs. recovering quickly?”
“Why do we tolerate single points of failure in our dependency chain? What would it take to build resilience?”
The difference between these approaches determines whether you’re learning or just documenting.
Narrow vs. Systemic Thinking
Narrow analysis fixes the immediate problem:
Add monitoring for connection pool utilization
Add a specific test case for the bug that escaped
Increase timeout values for the slow dependency
Systemic analysis asks meta questions:
“How do we systematically identify what we should be monitoring? Do we have a framework for this?”
“What patterns in our testing gaps led to this escape? Are we missing categories of testing?”
“What’s our philosophy on dependency management and resilience? Should we rethink our architecture?”
I’ve seen teams play post mortem bingo—hitting the same squares over and over. “No monitoring.” “Insufficient tests.” “Deployed during peak traffic.” “Rollback was broken.” When you see repeated patterns, you’re not learning from incidents—you’re collecting them. I have also written about common failures in distributed systems that can show up in recurring incidents if they are not properly addressed.
Understanding Complex System Failures
Modern systems fail in ways that defy simple “root cause” thinking. Consider a typical outage:
Surface story: Database connection pool exhausted Deeper story:
A code change increased query volume 10x
Load testing used 1/10th production data and missed it
Connection pool monitoring didn’t exist
Alerts only monitored error rates, not resource utilization
Manual approval processes delayed rollback by 15 minutes
Staging environment configuration drifted from production
Which of these is the “root cause”? All of them. None of them individually would have caused an outage, but together they created a perfect storm. This is why I cringe when post mortems end with “human error” as the root cause. It’s not wrong—humans are involved in everything—but it’s useless. The question is: why was the error possible? What systemic changes make it impossible, or at least improbable?
You can think of this as the Swiss Cheese Model of failure: your system has multiple layers of defense (code review, testing, monitoring, gradual rollout, alerting, incident response). Each layer has holes. Most of the time, the holes don’t align and problems get caught. But occasionally, everything lines up perfectly and a problem slips through all layers. That’s your incident. This mental model is more useful than hunting for a single root cause because it focuses you on strengthening multiple layers of defense.
When to Write a Post Mortem
Always write one:
Customer-facing service disruptions
SLA/SLO breaches
Security incidents (keep these separate, limited distribution)
Complete service outages
Incidents requiring emergency escalation or multiple teams
Strongly consider:
Near-misses that made you think “we got lucky”
Interesting edge cases with valuable lessons
Internal issues that disrupted other teams
Process breakdowns causing significant project delays
The litmus test: If you’re debating whether it needs a post mortem, write at least an internal one. The discipline of writing forces clarity of thinking.
Post Mortem Ownership
Who should own writing it? The post mortem belongs to the team that owns addressing the root cause, not necessarily the team that triggered the incident or resolved it. If root cause is initially unclear, it belongs with whoever is investigating. If investigation reveals the root cause lies elsewhere, reassign it.
The Anatomy of an Effective Post Mortem
Title and Summary: The Elevator Pitch
Your title should state the customer-facing problem, not the cause.
Good: “Users unable to complete checkout for 23 minutes in US-EAST” Bad: “Connection pool exhaustion caused outage”
Your summary should work as a standalone email to leadership. Include:
Brief service context (one sentence)
Timeline with time zones
Quantified customer impact
How long it lasted (from first customer impact to full recovery)
High-level cause
How it was resolved
Communication sent to customers (if applicable)
Timeline: The Narrative Spine
A good timeline tells the story of what happened, including system events and human decisions. Important: Your timeline should start with the first trigger that led to the problem (e.g., a deployment, a configuration change, a traffic spike), not just when your team got paged. The timeline should focus on the actual event start and end, not just your team’s perception of it.
All times PST
14:32 - Deployment begins in us-west-2
14:38 - Error rates spike to 15%
14:41 - Automated alerts fire
14:43 - On-call engineer begins investigation
14:47 - Customer support escalates: users reporting checkout failures
14:52 - Incident severity raised to SEV-1
15:03 - Root cause identified: connection pool exhaustion
15:07 - Rollback initiated
15:22 - Customer impact resolved, errors back to baseline
Key practices:
Start with the root trigger, not when you were notified
Consistent time zones throughout
Bold major milestones and customer-facing events
Include detection, escalation, and resolution times`
No gaps longer than 10-15 minutes without explanation
Use roles (“on-call engineer”) not names
Include both what the system did and what people did
Metrics: Show, Don’t Just Tell
Visual evidence is crucial. Include graphs showing:
Error rates during the incident
The specific resource that failed (connections, CPU, memory)
Business impact metrics (orders, logins, API calls)
Comparison with normal operation
For complex incidents involving multiple services, include a simple architecture diagram showing the relevant components and their interactions. This helps readers understand the failure chain without needing deep knowledge of your system.
Make graphs comparable:
Same time range across all graphs
Label your axes with units (milliseconds, percentage, requests/second)
Vertical lines marking key events
Include context before and after the incident
Embed actual screenshots, not just links that will break
Don’t do this:
Include 20 graphs because you can
Use different time zones between graphs
Forget to explain what the graph shows and why it matters
Service Context and Glossary
If your service uses specialized terminology or acronyms, add a brief glossary section or spell out all acronyms on first use. Your post mortem should be readable by engineers from other teams. For complex incidents, consider including:
Brief architecture overview (what are the key components?)
Links to related items (monitoring dashboards, deployment records, related tickets)
Key metrics definitions if not standard
Customer Impact: Get Specific
Never write “some customers were affected” or “significant impact.” Quantify everything:
Instead of: “Users experienced errors” Write: “23,000 checkout attempts failed over 23 minutes, representing approximately $89,000 in failed transactions”
Instead of: “API latency increased” Write: “P95 latency increased from 200ms to 3.2 seconds, affecting 15,000 API calls”
If you can’t get exact numbers, explain why and provide estimates with clear caveats.
Root Cause Analysis: Going Deeper
Use numbered lists (not bullets) for your Five Whys so people can easily reference them in discussions (“Why #4 seems incomplete…”). Use the Five Whys technique, but don’t stop at five if you need more. Start with the customer-facing problem and keep asking why:
1. Why did customers see checkout errors?
-> Application servers returned 500 errors
2. Why did application servers return 500 errors?
-> They couldn't connect to the database
3. Why couldn't they connect?
-> Connection pool was exhausted
4. Why was the pool exhausted?
-> New code made 10x more queries per request
5. Why didn't we catch this in testing?
-> Staging uses 1/10th production data
6. Why is staging data volume so different?
-> We haven't prioritized staging environment investment
Branch your analysis for multiple contributing factors. Number your branches (1.1, 1.2, etc.) to maintain traceability:
Primary Chain (1.x):
Why did customers see checkout errors?
did customers see checkou Application servers returned 500 errors
[...]
Branch A - Detection (2.x):
Why did detection take 12 minutes?
-> We only monitor error rates, not resource utilization
Why don't we monitor resource utilization?
-> We haven't established a framework for what to monitor
Branch B - Mitigation (3.x):
Why did rollback take 15 minutes after identifying the cause?
-> Manual approval was required for production rollbacks
Why is manual approval required during emergencies?
-> Our process doesn't distinguish between routine and emergency changes
Never stop at:
“Human error”
“Process failure”
“Legacy system”
Keep asking why until you reach actionable systemic changes.
Incident Response Analysis
This section examines how you handled the crisis during the incident, not how to prevent it. This is distinct from post-incident analysis (root causing) which happens after. Focus on the temporal sequence of events:
Detection: How did you discover the problem? Automated alerts, customer reports, accidental discovery? How could you have detected it sooner?
Diagnosis: How long from “something’s wrong” to “we know what’s wrong”? What information or tools would have accelerated diagnosis?
Mitigation: How long from diagnosis to resolution? What would have made recovery faster?
Blast Radius: What percentage of customers/systems were affected? How could you have reduced the blast radius? Consider:
Would cellular architecture have isolated the failure?
Could gradual rollout have limited impact?
Did failure cascade to dependent systems unnecessarily?
Would circuit breakers have prevented cascade?
For each phase, ask: “How could we have cut this time in half?” And for blast radius: “How could we have cut the affected population in half?”
Post-Incident Analysis vs Real-Time Response
Be clear about the temporal distinction in your post mortem:
Incident Response Analysis = What happened DURING the incident
How we detected, diagnosed, and mitigated
Time-critical decisions under pressure
Effectiveness of runbooks and procedures
Post-Incident Analysis = What happened AFTER to understand root cause
How we diagnosed the underlying cause
What investigation techniques we used
How long root cause analysis took
This distinction matters because improvements differ: incident response improvements help you recover faster from any incident; post-incident improvements help you understand failures more quickly.
Lessons Learned: Universal Insights
Number your lessons learned (not bullets) so they can be easily referenced and linked to action items. Lessons should be broadly applicable beyond your specific incident: 1. Bad lesson learned: “We need connection pool monitoring” Good lesson learned: “Services should monitor resource utilization for all constrained resources, not just error rates” 2. Bad lesson learned: “Load testing failed to catch this” Good lesson learned: “Test environments that don’t reflect production characteristics will systematically miss production-specific issues”
Connect each lesson to specific action items by number reference (e.g., “Lesson #2 ? Action Items #5, #6”).
Action Items: Making Change Happen
This is where post mortems prove their value. Number your action items and explicitly link them to the lessons learned they address. Every action item needs:
Clear description: Not “improve monitoring” but “Add CloudWatch alarms for RDS connection pool utilization with thresholds at 75% (warning) and 90% (critical)”
Specific owner: A person’s name, not a team name
Realistic deadline: Most should complete within 45 days
Priority level:
High for root cause fixes and issues that directly caused customer impact
Medium for improvements to detection/mitigation
Low for nice-to-have improvements
Link to lesson learned: “Addresses Lesson #2”
Avoid action items that start with “investigate.” That’s not an action item—it’s procrastination. Do the investigation during the post mortem process and commit to specific changes.
Note: Your lessons learned should be universal principles that other teams could apply. Your action items should be specific changes your team will make. If your lessons learned just restate your action items, you’re missing the bigger picture.
Common Patterns That Indicate Shallow Learning
When you see the same issues appearing in multiple post mortems, you have a systemic problem:
Repeated monitoring gaps -> You don’t have a framework for determining what to monitor
Repeated test coverage issues -> Your testing philosophy or practices need examination
Repeated “worked in staging, failed in prod” -> Your staging environment strategy is flawed
Repeated manual process errors -> You’re over-relying on human perfection
Repeated deployment-related incidents -> Your deployment pipeline needs investment
These patterns are your organization’s immune system telling you something. Listen to it.
Common Pitfalls
After reading hundreds of post mortems, here are the traps I see teams fall into:
Writing for Insiders Only: Your post mortem should be readable by someone from another team. Explain your system’s architecture briefly, spell out acronyms, and assume your reader is smart but unfamiliar with your specific service.
Action Items That Start with “Investigate”: “Investigate better monitoring” is not an action item – it’s a placeholder for thinking you haven’t done yet. During the post mortem process, do the investigation and commit to specific changes.
Stopping at “Human Error”: If your Five Whys ends with “the engineer made a mistake,” you haven’t gone deep enough. Why was that mistake possible? What system changes would prevent it?
The Boil-the-Ocean Action Plan: Post mortems aren’t the place for your three-year architecture wish list. Focus on targeted improvements that directly address the incident’s causes and can be completed within a few months.
Ownership and Follow-Through
Here’s something that separates good teams from great ones: they actually complete their post mortem action items.
Assign clear ownership: Every action item needs a specific person (not a team) responsible for completion. That person might delegate the work, but they own the outcome.
Set realistic deadlines: Most action items should be completed within 45 days. If something will take longer, either break it down or put it in your regular backlog instead.
Track relentlessly: Use whatever task tracking system your team prefers, but make action item completion visible. Review progress in your regular team meetings.
Close the loop: When action items are complete, update the post mortem with links to the changes made. Future readers (including future you) will thank you.
Making Post Mortems Part of Your Culture
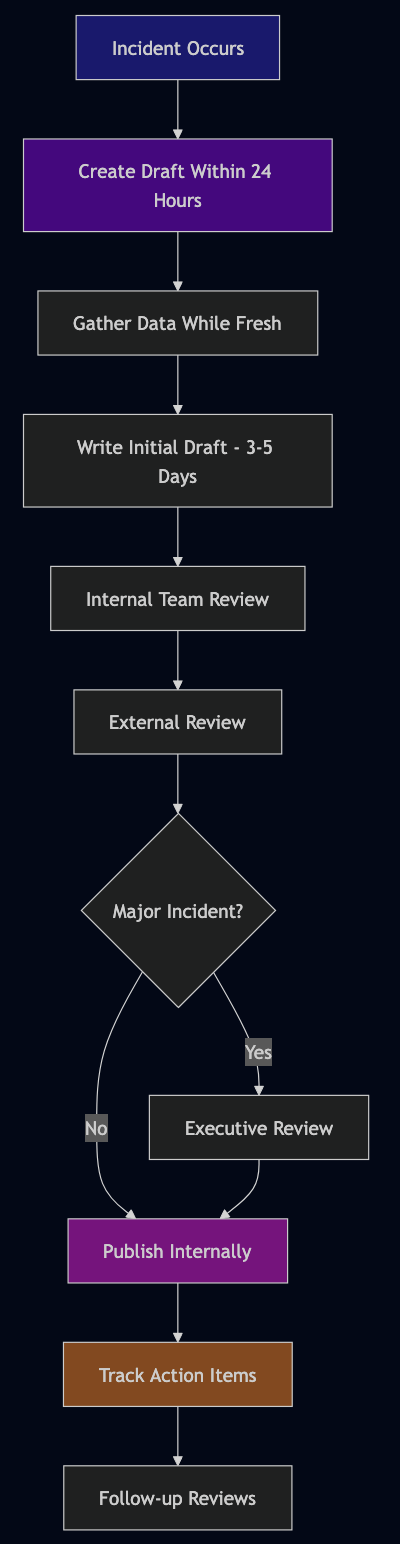
Write them quickly: Create the draft within 24 hours while memory is fresh. Complete the full post mortem within 14 days.
Get outside review (critical step): An experienced engineer from another team—sometimes called a “Bar Raiser”—should review for quality before you publish. The reviewer should check:
Would someone from another team understand and learn from this?
Are the lessons learned actually actionable?
Did you dig deep enough in your root cause analysis?
Are your action items specific and owned?
Does the incident response analysis identify concrete improvements?
Draft status: Keep the post mortem in draft/review status for at least 24 hours to gather feedback from stakeholders. Account for holidays and time zones for distributed teams.
Make them visible: Share widely (except security-sensitive ones) so other teams learn from your mistakes.
Customer communication: For customer-facing incidents, document what communication was sent:
Status page updates
Support team briefings
Proactive customer notifications
Post-incident follow-up
Track action items relentlessly: Use whatever task system you have. Review progress in regular meetings.
Review for patterns: Monthly or quarterly, look across all post mortems for systemic issues.
Celebrate learning: In team meetings, highlight interesting insights from post mortems. Make clear that thorough post mortems are valued, not punishment.
Train your people: Writing good post mortems is a skill. Share examples of excellent ones and give feedback.
Security-Sensitive Post Mortems
Some incidents involve security implications, sensitive customer data, or information that shouldn’t be widely shared. These still need documentation, but with appropriate access controls:
Create a separate, access-controlled version
Document what happened and how to prevent it
Share lessons learned (without sensitive details) more broadly
Work with your security team on appropriate distribution
The learning is still valuable—it just needs careful handling.
The Long Game
Post mortems are how organizations build institutional memory. They’re how you avoid becoming that team that keeps making the same mistakes. They’re how you onboard new engineers to the reality of your systems. Most importantly, they’re how you shift from a culture of blame to a culture of learning.
When your next incident happens—and it will—remember you’re not just fixing a problem. You’re gathering intelligence about how your system really behaves under stress. You’re building your team’s capability to handle whatever comes next. Write the post mortem you wish you’d had during the incident. Be honest about what went wrong. Be specific about what you’ll change. Be generous in sharing what you learned.
Your future self, your teammates, and your customers will all benefit from it. And remember: if you’re not sure whether something deserves a post mortem, write one anyway. The discipline of analysis is never wasted.
Over the years, I have seen countless production issues due to improper transaction management. A typical example: an API requires changes to multiple database tables, and each update is wrapped in different methods without proper transaction boundaries. This works fine when everything goes smoothly, but due to database constraints or other issues, a secondary database update might fail. In too many cases, the code doesn’t handle proper rollback and just throws an error—leaving the database in an inconsistent state.
In other cases, I’ve debugged production bugs due to improper coordination between database updates and event queues, where we desperately needed atomic behavior. I used J2EE in the late 1990s and early 2000s, which provided support for two-phase commit (2PC) to coordinate multiple updates across resources. However, 2PC wasn’t a scalable solution. I then experimented with aspect-oriented programming like AspectJ to handle cross-cutting concerns like transaction management, but it resulted in more complex code that was difficult to debug and maintain.
Later, I moved to Java Spring, which provided annotations for transaction management. This was both efficient and elegant—the @Transactional annotation made transaction boundaries explicit without cluttering business logic. When I worked at a travel booking company where we had to coordinate flight reservations, hotel bookings, car rentals, and insurance through various vendor APIs, I built a transaction framework based on the command pattern and chain of responsibility. This worked well for issuing compensating transactions when a remote API call failed midway through our public API workflow.
However, when I moved to Go and Rust, I found a lack of these basic transaction management primitives. I often see bugs in Go and Rust codebases that could have been caught earlier—many implementations assume the happy path and don’t properly handle partial failures or rollback scenarios.
In this blog, I’ll share learnings from my experience across different languages and platforms. I’ll cover best practices for establishing proper transaction boundaries, from single-database ACID transactions to distributed SAGA patterns, with working examples in Java/Spring, Go, and Rust. The goal isn’t just to prevent data corruption—it’s to build systems you can reason about, debug, and trust.
The Happy Path Fallacy
Most developers write code assuming everything will work perfectly. Here’s a typical “happy path” implementation:
// This looks innocent but is fundamentally broken
public class OrderService {
public void processOrder(Order order) {
orderRepository.save(order); // What if this succeeds...
paymentService.chargeCard(order); // ...but this fails?
inventoryService.allocate(order); // Now we have inconsistent state
emailService.sendConfirmation(order); // And this might never happen
}
}
The problem isn’t just that operations can fail—it’s that partial failures leave your system in an undefined state. Without proper transaction boundaries, you’re essentially playing Russian roulette with your data integrity. In my experience analyzing production systems, I’ve found that most data corruption doesn’t come from dramatic failures or outages. It comes from these subtle, partial failures that happen during normal operation. A network timeout here, a service restart there, and suddenly your carefully designed system is quietly hemorrhaging data consistency.
Transaction Fundamentals
Before we dive into robust transaction management in our applications, we need to understand what databases actually provide and how they achieve consistency guarantees. Most developers treat transactions as a black box—call BEGIN, do some work, call COMMIT, and hope for the best. But understanding the underlying mechanisms is crucial for making informed decisions about isolation levels, recognizing performance implications, and debugging concurrency issues when they inevitably arise in production. Let’s examine the foundational concepts that every developer working with transactions should understand.
The ACID Foundation
Before diving into implementation patterns, let’s establish why ACID properties matter:
Atomicity: Either all operations in a transaction succeed, or none do
Consistency: The database remains in a valid state before and after the transaction
Isolation: Concurrent transactions don’t interfere with each other
Durability: Once committed, changes survive system failures
These aren’t academic concepts—they’re the guardrails that prevent your system from sliding into chaos. Let’s see how different languages and frameworks help us maintain these guarantees.
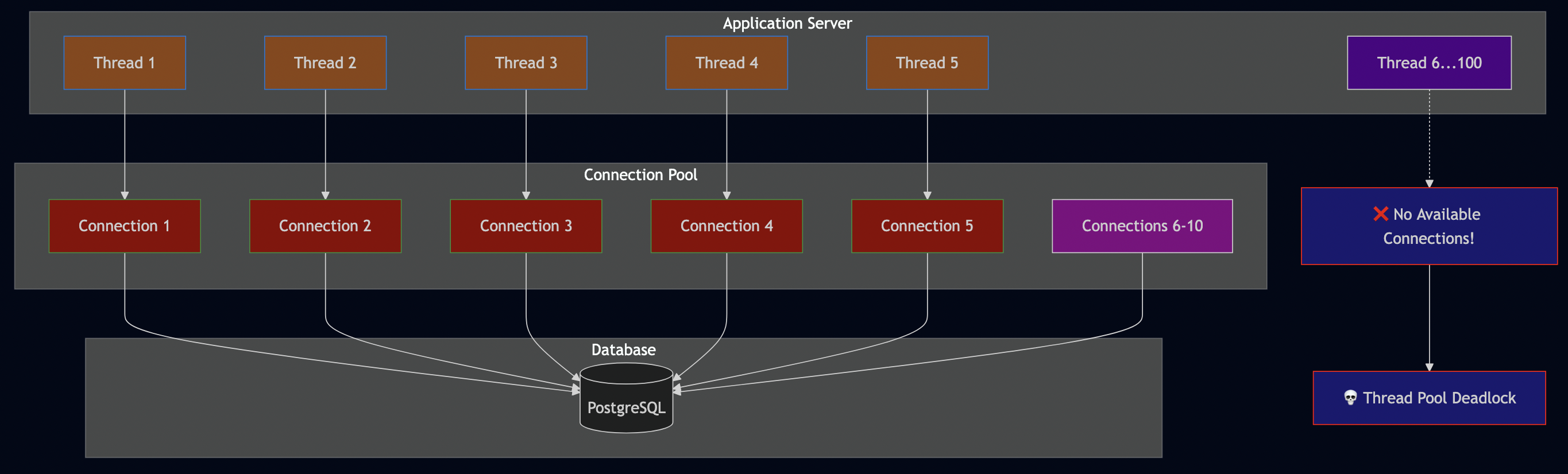
Isolation Levels: The Hidden Performance vs Consistency Tradeoff
Most developers don’t realize that their database isn’t using the strictest isolation level by default. In fact, most production databases (MySQL, PostgreSQL, Oracle, SQL Server) default to READ COMMITTED, not SERIALIZABLE. This creates subtle race conditions that can lead to double spending and other financial disasters.
// The double spending problem with default isolation
@Service
public class VulnerableAccountService {
// This uses READ COMMITTED by default - DANGEROUS for financial operations!
@Transactional
public void withdrawFunds(String accountId, BigDecimal amount) {
Account account = accountRepository.findById(accountId);
// RACE CONDITION: Another transaction can modify balance here!
if (account.getBalance().compareTo(amount) >= 0) {
account.setBalance(account.getBalance().subtract(amount));
accountRepository.save(account);
} else {
throw new InsufficientFundsException();
}
}
}
// What happens with concurrent requests:
// Thread 1: Read balance = $100, check passes
// Thread 2: Read balance = $100, check passes
// Thread 1: Withdraw $100, balance = $0
// Thread 2: Withdraw $100, balance = -$100 (DOUBLE SPENDING!)
Database Default Isolation Levels
Database
Default Isolation
Financial Safety
PostgreSQL
READ COMMITTED
? Vulnerable
MySQL
REPEATABLE READ
?? Better but not perfect
Oracle
READ COMMITTED
? Vulnerable
SQL Server
READ COMMITTED
? Vulnerable
H2/HSQLDB
READ COMMITTED
? Vulnerable
The Right Way: Database Constraints + Proper Isolation
// Method 1: Database constraints (fastest)
@Entity
@Table(name = "accounts")
public class Account {
@Id
private String accountId;
@Column(nullable = false)
@Check(constraints = "balance >= 0") // Database prevents negative balance
private BigDecimal balance;
@Version
private Long version;
}
@Service
public class SafeAccountService {
// Let database constraint handle the race condition
@Transactional
public void withdrawFundsWithConstraint(String accountId, BigDecimal amount) {
try {
Account account = accountRepository.findById(accountId);
account.setBalance(account.getBalance().subtract(amount));
accountRepository.save(account); // Database throws exception if balance < 0
} catch (DataIntegrityViolationException e) {
throw new InsufficientFundsException("Withdrawal would result in negative balance");
}
}
// Method 2: SERIALIZABLE isolation (most secure)
@Transactional(isolation = Isolation.SERIALIZABLE)
public void withdrawFundsSerializable(String accountId, BigDecimal amount) {
Account account = accountRepository.findById(accountId);
if (account.getBalance().compareTo(amount) >= 0) {
account.setBalance(account.getBalance().subtract(amount));
accountRepository.save(account);
} else {
throw new InsufficientFundsException();
}
// SERIALIZABLE guarantees no other transaction can interfere
}
// Method 3: Optimistic locking (good performance)
@Transactional
@Retryable(value = {OptimisticLockingFailureException.class}, maxAttempts = 3)
public void withdrawFundsOptimistic(String accountId, BigDecimal amount) {
Account account = accountRepository.findById(accountId);
if (account.getBalance().compareTo(amount) >= 0) {
account.setBalance(account.getBalance().subtract(amount));
accountRepository.save(account); // Version check prevents race conditions
} else {
throw new InsufficientFundsException();
}
}
}
MVCC
Most developers don’t realize that modern databases achieve isolation levels through Multi-Version Concurrency Control (MVCC), not traditional locking. Understanding MVCC explains why certain isolation behaviors seem counterintuitive. Instead of locking rows for reads, databases maintain multiple versions of each row with timestamps. When you start a transaction, you get a consistent snapshot of the database as it existed at that moment.
// What actually happens under MVCC
@Transactional(isolation = Isolation.REPEATABLE_READ)
public void demonstrateMVCC() {
// T1: Transaction starts, gets snapshot at time=100
Account account = accountRepository.findById("123"); // Reads version at time=100
// T2: Another transaction modifies the account (creates version at time=101)
// T1: Reads same account again
Account sameAccount = accountRepository.findById("123"); // Still reads version at time=100!
assert account.getBalance().equals(sameAccount.getBalance()); // MVCC guarantees this
}
MVCC vs Traditional Locking
-- Traditional locking approach (not MVCC)
BEGIN TRANSACTION;
SELECT * FROM accounts WHERE id = '123' FOR SHARE; -- Acquires shared lock
-- Other transactions blocked from writing until this transaction ends
-- MVCC approach (PostgreSQL, MySQL InnoDB)
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SELECT * FROM accounts WHERE id = '123'; -- No locks, reads from snapshot
-- Other transactions can write freely, creating new versions
MVCC delivers better performance and reduces deadlock contention compared to traditional locking, but it comes with cleanup overhead requirements (PostgreSQL VACUUM, MySQL purge operations). I have encountered numerous production issues where real-time queries or ETL jobs would suddenly degrade in performance due to aggressive background VACUUM operations on older PostgreSQL versions, though recent versions have significantly improved this behavior. MVCC can also lead to stale reads in long-running transactions, as they maintain their snapshot view even as the underlying data changes.
// MVCC write conflict example
@Transactional
@Retryable(value = {OptimisticLockingFailureException.class})
public void updateAccountMVCC(String accountId, BigDecimal newBalance) {
Account account = accountRepository.findById(accountId);
// If another transaction modified this account between our read
// and write, MVCC will detect the conflict and retry
account.setBalance(newBalance);
accountRepository.save(account); // May throw OptimisticLockingFailureException
}
This is why PostgreSQL defaults to READ COMMITTED and why long-running analytical queries should use dedicated read replicas—MVCC snapshots can become expensive to maintain over time.
Java and Spring: The Gold Standard
Spring’s @Transactional annotation is probably the most elegant solution I’ve encountered for transaction management. It uses aspect-oriented programming to wrap methods in transaction boundaries, making the complexity invisible to business logic.
Basic Transaction Management
@Service
@Transactional
public class OrderService {
@Autowired
private OrderRepository orderRepository;
@Autowired
private PaymentService paymentService;
@Autowired
private InventoryService inventoryService;
// All operations within this method are atomic
public Order processOrder(CreateOrderRequest request) {
Order order = new Order(request);
order = orderRepository.save(order);
// If any of these fail, everything rolls back
Payment payment = paymentService.processPayment(
order.getCustomerId(),
order.getTotalAmount()
);
inventoryService.reserveItems(order.getItems());
order.setPaymentId(payment.getId());
order.setStatus(OrderStatus.CONFIRMED);
return orderRepository.save(order);
}
}
Different Transaction Types
Spring provides fine-grained control over transaction behavior:
@Service
public class OrderService {
// Read-only transactions can be optimized by the database
@Transactional(readOnly = true)
public List<Order> getOrderHistory(String customerId) {
return orderRepository.findByCustomerId(customerId);
}
// Long-running operations need higher timeout
@Transactional(timeout = 300) // 5 minutes
public void processBulkOrders(List<CreateOrderRequest> requests) {
for (CreateOrderRequest request : requests) {
processOrder(request);
}
}
// Critical operations need strict isolation
@Transactional(isolation = Isolation.SERIALIZABLE)
public void transferInventory(String fromLocation, String toLocation,
String itemId, int quantity) {
Item fromItem = inventoryRepository.findByLocationAndItem(fromLocation, itemId);
Item toItem = inventoryRepository.findByLocationAndItem(toLocation, itemId);
if (fromItem.getQuantity() < quantity) {
throw new InsufficientInventoryException();
}
fromItem.setQuantity(fromItem.getQuantity() - quantity);
toItem.setQuantity(toItem.getQuantity() + quantity);
inventoryRepository.save(fromItem);
inventoryRepository.save(toItem);
}
// Some operations should create new transactions
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void logAuditEvent(String event, String details) {
AuditLog log = new AuditLog(event, details, Instant.now());
auditRepository.save(log);
// This commits immediately, independent of calling transaction
}
// Handle specific rollback conditions
@Transactional(rollbackFor = {BusinessException.class, ValidationException.class})
public void processComplexOrder(ComplexOrderRequest request) {
// Business logic that might throw business exceptions
validateOrderRules(request);
Order order = createOrder(request);
processPayment(order);
}
}
Nested Transactions and Propagation
Understanding nested transactions is critical for building robust systems. In some cases, you want a child transaction to succeed regardless of whether the parent transaction succeeds or not—these are often called “autonomous transactions” or “independent transactions.” The solution was to use REQUIRES_NEW propagation for audit operations, creating independent transactions that commit immediately regardless of what happens to the parent transaction. Similarly, for notification services, you typically want notifications to be sent even if the business operation partially fails—users should know that something went wrong.
@Service
public class OrderProcessingService {
@Autowired
private OrderService orderService;
@Autowired
private NotificationService notificationService;
@Transactional
public void processOrderWithNotification(CreateOrderRequest request) {
// This participates in the existing transaction
Order order = orderService.processOrder(request);
// This creates a new transaction that commits independently
notificationService.sendOrderConfirmation(order);
// If something fails here, the order transaction can still commit
// but the notification might not be sent
}
}
@Service
public class NotificationService {
// Creates a new transaction - notifications are sent even if
// the main order processing fails later
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void sendOrderConfirmation(Order order) {
NotificationRecord record = new NotificationRecord(
order.getCustomerId(),
"Order confirmed: " + order.getId(),
NotificationType.ORDER_CONFIRMATION
);
notificationRepository.save(record);
// Send actual notification asynchronously
emailService.sendAsync(order.getCustomerEmail(),
"Order Confirmation",
generateOrderEmail(order));
}
}
Go with GORM: Explicit Transaction Management
Go doesn’t have the luxury of annotations, so transaction management becomes more explicit. This actually has benefits—the transaction boundaries are clearly visible in the code.
Basic GORM Transactions
package services
import (
"context"
"fmt"
"gorm.io/gorm"
)
type OrderService struct {
db *gorm.DB
}
type Order struct {
ID uint `gorm:"primarykey"`
CustomerID string
TotalAmount int64
Status string
PaymentID string
Items []OrderItem `gorm:"foreignKey:OrderID"`
}
type OrderItem struct {
ID uint `gorm:"primarykey"`
OrderID uint
SKU string
Quantity int
Price int64
}
// Basic transaction with explicit rollback handling
func (s *OrderService) ProcessOrder(ctx context.Context, request CreateOrderRequest) (*Order, error) {
tx := s.db.Begin()
defer func() {
if r := recover(); r != nil {
tx.Rollback()
panic(r)
}
}()
order := &Order{
CustomerID: request.CustomerID,
TotalAmount: request.TotalAmount,
Status: "PENDING",
}
// Save the order
if err := tx.Create(order).Error; err != nil {
tx.Rollback()
return nil, fmt.Errorf("failed to create order: %w", err)
}
// Process payment
paymentID, err := s.processPayment(ctx, tx, order)
if err != nil {
tx.Rollback()
return nil, fmt.Errorf("payment failed: %w", err)
}
// Reserve inventory
if err := s.reserveInventory(ctx, tx, request.Items); err != nil {
tx.Rollback()
return nil, fmt.Errorf("inventory reservation failed: %w", err)
}
// Update order with payment info
order.PaymentID = paymentID
order.Status = "CONFIRMED"
if err := tx.Save(order).Error; err != nil {
tx.Rollback()
return nil, fmt.Errorf("failed to update order: %w", err)
}
if err := tx.Commit().Error; err != nil {
return nil, fmt.Errorf("failed to commit transaction: %w", err)
}
return order, nil
}
Functional Transaction Wrapper
To reduce boilerplate, we can create a transaction wrapper:
// TransactionFunc represents a function that runs within a transaction
type TransactionFunc func(tx *gorm.DB) error
// WithTransaction wraps a function in a database transaction
func (s *OrderService) WithTransaction(fn TransactionFunc) error {
tx := s.db.Begin()
defer func() {
if r := recover(); r != nil {
tx.Rollback()
panic(r)
}
}()
if err := fn(tx); err != nil {
tx.Rollback()
return err
}
return tx.Commit().Error
}
// Now our business logic becomes cleaner
func (s *OrderService) ProcessOrderClean(ctx context.Context, request CreateOrderRequest) (*Order, error) {
var order *Order
err := s.WithTransaction(func(tx *gorm.DB) error {
order = &Order{
CustomerID: request.CustomerID,
TotalAmount: request.TotalAmount,
Status: "PENDING",
}
if err := tx.Create(order).Error; err != nil {
return fmt.Errorf("failed to create order: %w", err)
}
paymentID, err := s.processPaymentInTx(ctx, tx, order)
if err != nil {
return fmt.Errorf("payment failed: %w", err)
}
if err := s.reserveInventoryInTx(ctx, tx, request.Items); err != nil {
return fmt.Errorf("inventory reservation failed: %w", err)
}
order.PaymentID = paymentID
order.Status = "CONFIRMED"
return tx.Save(order).Error
})
return order, err
}
Context-Based Transaction Management
For more sophisticated transaction management, we can use context to pass transactions:
type contextKey string
const txKey contextKey = "transaction"
// WithTransactionContext creates a new context with a transaction
func WithTransactionContext(ctx context.Context, tx *gorm.DB) context.Context {
return context.WithValue(ctx, txKey, tx)
}
// TxFromContext retrieves a transaction from context
func TxFromContext(ctx context.Context) (*gorm.DB, bool) {
tx, ok := ctx.Value(txKey).(*gorm.DB)
return tx, ok
}
// GetDB returns either the transaction from context or the main DB
func (s *OrderService) GetDB(ctx context.Context) *gorm.DB {
if tx, ok := TxFromContext(ctx); ok {
return tx
}
return s.db
}
// Now services can automatically use transactions when available
func (s *PaymentService) ProcessPayment(ctx context.Context, customerID string, amount int64) (string, error) {
db := s.GetDB(ctx) // Uses transaction if available
payment := &Payment{
CustomerID: customerID,
Amount: amount,
Status: "PROCESSING",
}
if err := db.Create(payment).Error; err != nil {
return "", err
}
// Simulate payment processing
if amount > 100000 { // Reject large amounts for demo
payment.Status = "FAILED"
db.Save(payment)
return "", fmt.Errorf("payment amount too large")
}
payment.Status = "COMPLETED"
payment.TransactionID = generatePaymentID()
if err := db.Save(payment).Error; err != nil {
return "", err
}
return payment.TransactionID, nil
}
// Usage with context-based transactions
func (s *OrderService) ProcessOrderWithContext(ctx context.Context, request CreateOrderRequest) (*Order, error) {
var order *Order
return order, s.WithTransaction(func(tx *gorm.DB) error {
// Create context with transaction
txCtx := WithTransactionContext(ctx, tx)
order = &Order{
CustomerID: request.CustomerID,
TotalAmount: request.TotalAmount,
Status: "PENDING",
}
if err := tx.Create(order).Error; err != nil {
return err
}
// These services will automatically use the transaction
paymentID, err := s.paymentService.ProcessPayment(txCtx, order.CustomerID, order.TotalAmount)
if err != nil {
return err
}
if err := s.inventoryService.ReserveItems(txCtx, request.Items); err != nil {
return err
}
order.PaymentID = paymentID
order.Status = "CONFIRMED"
return tx.Save(order).Error
})
}
Read-Only and Isolation Control
// Read-only operations can be optimized
func (s *OrderService) GetOrderHistory(ctx context.Context, customerID string) ([]Order, error) {
var orders []Order
// Use read-only transaction for consistency
err := s.db.Transaction(func(tx *gorm.DB) error {
return tx.Raw("SELECT * FROM orders WHERE customer_id = ? ORDER BY created_at DESC",
customerID).Scan(&orders).Error
}, &sql.TxOptions{ReadOnly: true})
return orders, err
}
// Operations requiring specific isolation levels
func (s *InventoryService) TransferStock(ctx context.Context, fromSKU, toSKU string, quantity int) error {
return s.db.Transaction(func(tx *gorm.DB) error {
var fromItem, toItem InventoryItem
// Lock rows to prevent concurrent modifications
if err := tx.Set("gorm:query_option", "FOR UPDATE").
Where("sku = ?", fromSKU).First(&fromItem).Error; err != nil {
return err
}
if err := tx.Set("gorm:query_option", "FOR UPDATE").
Where("sku = ?", toSKU).First(&toItem).Error; err != nil {
return err
}
if fromItem.Quantity < quantity {
return fmt.Errorf("insufficient inventory")
}
fromItem.Quantity -= quantity
toItem.Quantity += quantity
if err := tx.Save(&fromItem).Error; err != nil {
return err
}
return tx.Save(&toItem).Error
}, &sql.TxOptions{Isolation: sql.LevelSerializable})
}
Rust: Custom Transaction Annotations with Macros
Rust doesn’t have runtime annotations like Java, but we can create compile-time macros that provide similar functionality. This approach gives us zero-runtime overhead while maintaining clean syntax.
// src/services/order_service.rs
use diesel::prelude::*;
use crate::transaction::*;
use crate::models::*;
use crate::schema::orders::dsl::*;
pub struct OrderService;
impl OrderService {
// Transactional order processing with automatic rollback
transactional! {
fn process_order(request: CreateOrderRequest) -> Order {
// Create the order
let new_order = NewOrder {
customer_id: &request.customer_id,
total_amount: request.total_amount,
status: "PENDING",
};
let order: Order = diesel::insert_into(orders)
.values(&new_order)
.get_result(conn)
.map_err(TransactionError::Database)?;
// Process payment
let payment_id = Self::process_payment_internal(conn, &order)
.map_err(|e| TransactionError::Business(format!("Payment failed: {}", e)))?;
// Reserve inventory
Self::reserve_inventory_internal(conn, &request.items)
.map_err(|e| TransactionError::Business(format!("Inventory reservation failed: {}", e)))?;
// Update order with payment info
let updated_order = diesel::update(orders.filter(id.eq(order.id)))
.set((
payment_id.eq(&payment_id),
status.eq("CONFIRMED"),
))
.get_result(conn)
.map_err(TransactionError::Database)?;
Ok(updated_order)
}
}
// Read-only transaction for queries
read_only! {
fn get_order_history(customer_id: String) -> Vec<Order> {
let order_list = orders
.filter(customer_id.eq(&customer_id))
.order(created_at.desc())
.load::<Order>(conn)
.map_err(TransactionError::Database)?;
Ok(order_list)
}
}
// Helper functions that work within existing transactions
fn process_payment_internal(conn: &mut PgConnection, order: &Order) -> Result<String, String> {
use crate::schema::payments::dsl::*;
let new_payment = NewPayment {
customer_id: &order.customer_id,
order_id: order.id,
amount: order.total_amount,
status: "PROCESSING",
};
let payment: Payment = diesel::insert_into(payments)
.values(&new_payment)
.get_result(conn)
.map_err(|e| format!("Payment creation failed: {}", e))?;
// Simulate payment processing logic
if order.total_amount > 100000 {
diesel::update(payments.filter(id.eq(payment.id)))
.set(status.eq("FAILED"))
.execute(conn)
.map_err(|e| format!("Payment update failed: {}", e))?;
return Err("Payment amount too large".to_string());
}
let transaction_id = format!("txn_{}", uuid::Uuid::new_v4());
diesel::update(payments.filter(id.eq(payment.id)))
.set((
status.eq("COMPLETED"),
transaction_id.eq(&transaction_id),
))
.execute(conn)
.map_err(|e| format!("Payment finalization failed: {}", e))?;
Ok(transaction_id)
}
fn reserve_inventory_internal(conn: &mut PgConnection, items: &[OrderItemRequest]) -> Result<(), String> {
use crate::schema::inventory::dsl::*;
for item in items {
// Lock the inventory row for update
let mut inventory_item: InventoryItem = inventory
.filter(sku.eq(&item.sku))
.for_update()
.first(conn)
.map_err(|e| format!("Inventory lookup failed: {}", e))?;
if inventory_item.quantity < item.quantity {
return Err(format!("Insufficient inventory for SKU: {}", item.sku));
}
inventory_item.quantity -= item.quantity;
diesel::update(inventory.filter(sku.eq(&item.sku)))
.set(quantity.eq(inventory_item.quantity))
.execute(conn)
.map_err(|e| format!("Inventory update failed: {}", e))?;
}
Ok(())
}
}
Advanced Transaction Features in Rust
// More sophisticated transaction management with isolation levels
#[macro_export]
macro_rules! serializable_transaction {
(
fn $name:ident($($param:ident: $param_type:ty),*) -> $return_type:ty {
$($body:tt)*
}
) => {
fn $name(conn: &mut PgConnection, $($param: $param_type),*) -> TransactionResult<$return_type> {
// Set serializable isolation level
conn.batch_execute("SET TRANSACTION ISOLATION LEVEL SERIALIZABLE")
.map_err(TransactionError::Database)?;
conn.transaction::<$return_type, TransactionError, _>(|conn| {
$($body)*
})
}
};
}
// Usage for operations requiring strict consistency
impl InventoryService {
serializable_transaction! {
fn transfer_stock(from_sku: String, to_sku: String, quantity: i32) -> (InventoryItem, InventoryItem) {
use crate::schema::inventory::dsl::*;
// Lock both items in consistent order to prevent deadlocks
let (first_sku, second_sku) = if from_sku < to_sku {
(&from_sku, &to_sku)
} else {
(&to_sku, &from_sku)
};
let mut from_item: InventoryItem = inventory
.filter(sku.eq(first_sku))
.for_update()
.first(conn)
.map_err(TransactionError::Database)?;
let mut to_item: InventoryItem = inventory
.filter(sku.eq(second_sku))
.for_update()
.first(conn)
.map_err(TransactionError::Database)?;
// Ensure we have the right items
if from_item.sku != from_sku {
std::mem::swap(&mut from_item, &mut to_item);
}
if from_item.quantity < quantity {
return Err(TransactionError::Business(
"Insufficient inventory for transfer".to_string()
));
}
from_item.quantity -= quantity;
to_item.quantity += quantity;
let updated_from = diesel::update(inventory.filter(sku.eq(&from_sku)))
.set(quantity.eq(from_item.quantity))
.get_result(conn)
.map_err(TransactionError::Database)?;
let updated_to = diesel::update(inventory.filter(sku.eq(&to_sku)))
.set(quantity.eq(to_item.quantity))
.get_result(conn)
.map_err(TransactionError::Database)?;
Ok((updated_from, updated_to))
}
}
}
Async Transaction Support
For modern Rust applications using async/await:
// src/transaction/async_transaction.rs
use diesel_async::{AsyncPgConnection, AsyncConnection};
use diesel_async::pooled_connection::bb8::Pool;
#[macro_export]
macro_rules! async_transactional {
(
async fn $name:ident($($param:ident: $param_type:ty),*) -> $return_type:ty {
$($body:tt)*
}
) => {
async fn $name(pool: &Pool<AsyncPgConnection>, $($param: $param_type),*) -> TransactionResult<$return_type> {
let mut conn = pool.get().await
.map_err(|e| TransactionError::Database(e.into()))?;
conn.transaction::<$return_type, TransactionError, _>(|conn| {
Box::pin(async move {
$($body)*
})
}).await
}
};
}
// Usage with async operations
impl OrderService {
async_transactional! {
async fn process_order_async(request: CreateOrderRequest) -> Order {
// All the same logic as before, but with async/await support
let new_order = NewOrder {
customer_id: &request.customer_id,
total_amount: request.total_amount,
status: "PENDING",
};
let order: Order = diesel::insert_into(orders)
.values(&new_order)
.get_result(conn)
.await
.map_err(TransactionError::Database)?;
// Process payment asynchronously
let payment_id = Self::process_payment_async(conn, &order).await
.map_err(|e| TransactionError::Business(format!("Payment failed: {}", e)))?;
// Continue with order processing...
Ok(order)
}
}
}
Multi-Database Transactions: Two-Phase Commit
I used J2EE and XA transactions extensively in the late 1990s and early 2000s when these standards were being defined by Sun Microsystems with major contributions from IBM, Oracle, and BEA Systems. While these technologies provided strong consistency guarantees, they added enormous complexity to applications and resulted in significant performance issues. The fundamental problem with 2PC is that it’s a blocking protocol—if the transaction coordinator fails during the commit phase, all participating databases remain locked until the coordinator recovers. I’ve seen production systems grind to a halt for hours because of coordinator failures. There are also edge cases that 2PC simply cannot handle, such as network partitions between the coordinator and participants, which led to the development of three-phase commit (3PC). In most cases, you should avoid distributed transactions entirely and use patterns like SAGA, event sourcing, or careful service boundaries instead.
Java XA Transactions
@Configuration
@EnableTransactionManagement
public class XATransactionConfig {
@Bean
@Primary
public DataSource orderDataSource() {
MysqlXADataSource xaDataSource = new MysqlXADataSource();
xaDataSource.setURL("jdbc:mysql://localhost:3306/orders");
xaDataSource.setUser("orders_user");
xaDataSource.setPassword("orders_pass");
return xaDataSource;
}
@Bean
public DataSource inventoryDataSource() {
MysqlXADataSource xaDataSource = new MysqlXADataSource();
xaDataSource.setURL("jdbc:mysql://localhost:3306/inventory");
xaDataSource.setUser("inventory_user");
xaDataSource.setPassword("inventory_pass");
return xaDataSource;
}
@Bean
public JtaTransactionManager jtaTransactionManager() {
JtaTransactionManager jtaTransactionManager = new JtaTransactionManager();
jtaTransactionManager.setTransactionManager(atomikosTransactionManager());
jtaTransactionManager.setUserTransaction(atomikosUserTransaction());
return jtaTransactionManager;
}
@Bean(initMethod = "init", destroyMethod = "close")
public UserTransactionManager atomikosTransactionManager() {
UserTransactionManager transactionManager = new UserTransactionManager();
transactionManager.setForceShutdown(false);
return transactionManager;
}
@Bean
public UserTransactionImp atomikosUserTransaction() throws SystemException {
UserTransactionImp userTransactionImp = new UserTransactionImp();
userTransactionImp.setTransactionTimeout(300);
return userTransactionImp;
}
}
@Service
public class DistributedOrderService {
@Autowired
@Qualifier("orderDataSource")
private DataSource orderDataSource;
@Autowired
@Qualifier("inventoryDataSource")
private DataSource inventoryDataSource;
// XA transaction spans both databases
@Transactional
public void processDistributedOrder(CreateOrderRequest request) {
// Operations on orders database
try (Connection orderConn = orderDataSource.getConnection()) {
PreparedStatement orderStmt = orderConn.prepareStatement(
"INSERT INTO orders (customer_id, total_amount, status) VALUES (?, ?, ?)"
);
orderStmt.setString(1, request.getCustomerId());
orderStmt.setBigDecimal(2, request.getTotalAmount());
orderStmt.setString(3, "PENDING");
orderStmt.executeUpdate();
}
// Operations on inventory database
try (Connection inventoryConn = inventoryDataSource.getConnection()) {
for (OrderItem item : request.getItems()) {
PreparedStatement inventoryStmt = inventoryConn.prepareStatement(
"UPDATE inventory SET quantity = quantity - ? WHERE sku = ? AND quantity >= ?"
);
inventoryStmt.setInt(1, item.getQuantity());
inventoryStmt.setString(2, item.getSku());
inventoryStmt.setInt(3, item.getQuantity());
int updatedRows = inventoryStmt.executeUpdate();
if (updatedRows == 0) {
throw new InsufficientInventoryException("Not enough inventory for " + item.getSku());
}
}
}
// If we get here, both database operations succeeded
// The XA transaction manager will coordinate the commit across both databases
}
}
Go Distributed Transactions
Go doesn’t have built-in distributed transaction support, so we need to implement 2PC manually:
package distributed
import (
"context"
"database/sql"
"fmt"
"log"
"time"
"github.com/google/uuid"
)
type TransactionManager struct {
resources []XAResource
}
type XAResource interface {
Prepare(ctx context.Context, txID string) error
Commit(ctx context.Context, txID string) error
Rollback(ctx context.Context, txID string) error
}
type DatabaseResource struct {
db *sql.DB
name string
}
func (r *DatabaseResource) Prepare(ctx context.Context, txID string) error {
tx, err := r.db.BeginTx(ctx, nil)
if err != nil {
return err
}
// Store transaction for later commit/rollback
// In production, you'd need a proper transaction store
transactionStore[txID+"-"+r.name] = tx
return nil
}
func (r *DatabaseResource) Commit(ctx context.Context, txID string) error {
tx, exists := transactionStore[txID+"-"+r.name]
if !exists {
return fmt.Errorf("transaction not found: %s", txID)
}
err := tx.Commit()
delete(transactionStore, txID+"-"+r.name)
return err
}
func (r *DatabaseResource) Rollback(ctx context.Context, txID string) error {
tx, exists := transactionStore[txID+"-"+r.name]
if !exists {
return nil // Already rolled back
}
err := tx.Rollback()
delete(transactionStore, txID+"-"+r.name)
return err
}
// Global transaction store (in production, use Redis or similar)
var transactionStore = make(map[string]*sql.Tx)
func (tm *TransactionManager) ExecuteDistributedTransaction(ctx context.Context, fn func() error) error {
txID := uuid.New().String()
// Phase 1: Prepare all resources
for _, resource := range tm.resources {
if err := resource.Prepare(ctx, txID); err != nil {
// Rollback all prepared resources
tm.rollbackAll(ctx, txID)
return fmt.Errorf("prepare failed: %w", err)
}
}
// Execute business logic
if err := fn(); err != nil {
tm.rollbackAll(ctx, txID)
return fmt.Errorf("business logic failed: %w", err)
}
// Phase 2: Commit all resources
for _, resource := range tm.resources {
if err := resource.Commit(ctx, txID); err != nil {
log.Printf("Commit failed for txID %s: %v", txID, err)
// In production, you'd need a recovery mechanism here
return fmt.Errorf("commit failed: %w", err)
}
}
return nil
}
func (tm *TransactionManager) rollbackAll(ctx context.Context, txID string) {
for _, resource := range tm.resources {
if err := resource.Rollback(ctx, txID); err != nil {
log.Printf("Rollback failed for txID %s: %v", txID, err)
}
}
}
// Usage example
func ProcessDistributedOrder(ctx context.Context, request CreateOrderRequest) error {
orderDB, _ := sql.Open("mysql", "orders_connection_string")
inventoryDB, _ := sql.Open("mysql", "inventory_connection_string")
tm := &TransactionManager{
resources: []XAResource{
&DatabaseResource{db: orderDB, name: "orders"},
&DatabaseResource{db: inventoryDB, name: "inventory"},
},
}
return tm.ExecuteDistributedTransaction(ctx, func() error {
// Business logic goes here - use the prepared transactions
orderTx := transactionStore[txID+"-orders"]
inventoryTx := transactionStore[txID+"-inventory"]
// Create order
_, err := orderTx.Exec(
"INSERT INTO orders (customer_id, total_amount, status) VALUES (?, ?, ?)",
request.CustomerID, request.TotalAmount, "PENDING",
)
if err != nil {
return err
}
// Update inventory
for _, item := range request.Items {
result, err := inventoryTx.Exec(
"UPDATE inventory SET quantity = quantity - ? WHERE sku = ? AND quantity >= ?",
item.Quantity, item.SKU, item.Quantity,
)
if err != nil {
return err
}
rowsAffected, _ := result.RowsAffected()
if rowsAffected == 0 {
return fmt.Errorf("insufficient inventory for %s", item.SKU)
}
}
return nil
})
}
Concurrency Control: Optimistic vs Pessimistic
Understanding when to use optimistic versus pessimistic concurrency control can make or break your application’s performance under load.
// Go pessimistic locking with GORM
func (s *AccountService) TransferFunds(ctx context.Context, fromAccountID, toAccountID string, amount int64) error {
return s.WithTransaction(func(tx *gorm.DB) error {
var fromAccount, toAccount Account
// Lock accounts in consistent order
firstID, secondID := fromAccountID, toAccountID
if fromAccountID > toAccountID {
firstID, secondID = toAccountID, fromAccountID
}
// Lock first account
if err := tx.Set("gorm:query_option", "FOR UPDATE").
Where("id = ?", firstID).First(&fromAccount).Error; err != nil {
return err
}
// Lock second account
if err := tx.Set("gorm:query_option", "FOR UPDATE").
Where("id = ?", secondID).First(&toAccount).Error; err != nil {
return err
}
// Ensure we have the correct accounts
if fromAccount.ID != fromAccountID {
fromAccount, toAccount = toAccount, fromAccount
}
if fromAccount.Balance < amount {
return fmt.Errorf("insufficient funds")
}
fromAccount.Balance -= amount
toAccount.Balance += amount
if err := tx.Save(&fromAccount).Error; err != nil {
return err
}
return tx.Save(&toAccount).Error
})
}
Optimistic Locking: “Hope for the Best, Handle the Rest”
// JPA optimistic locking with version fields
@Entity
public class Account {
@Id
private String id;
private BigDecimal balance;
@Version
private Long version; // JPA automatically manages this
// getters and setters...
}
@Service
public class OptimisticAccountService {
@Transactional
@Retryable(value = {OptimisticLockingFailureException.class}, maxAttempts = 3)
public void transferFunds(String fromAccountId, String toAccountId, BigDecimal amount) {
Account fromAccount = accountRepository.findById(fromAccountId);
Account toAccount = accountRepository.findById(toAccountId);
if (fromAccount.getBalance().compareTo(amount) < 0) {
throw new InsufficientFundsException();
}
fromAccount.setBalance(fromAccount.getBalance().subtract(amount));
toAccount.setBalance(toAccount.getBalance().add(amount));
// If either account was modified by another transaction,
// OptimisticLockingFailureException will be thrown
accountRepository.save(fromAccount);
accountRepository.save(toAccount);
}
}
When 2PC becomes too heavyweight or you’re dealing with services that don’t support XA transactions, the SAGA pattern provides an elegant alternative using compensating transactions.
Command Pattern for Compensating Transactions
I initially applied this design pattern at a travel booking company in mid 2000 where we had to integrate with numerous external vendors—airline companies, hotels, car rental agencies, insurance providers, and activity booking services. Each vendor had different APIs, response times, and failure modes, but we needed to present customers with a single, atomic booking experience. The command pattern worked exceptionally well for this scenario. When a customer booked a vacation package, we’d execute a chain of commands: reserve flight, book hotel, rent car, purchase insurance. If any step failed midway through, we could automatically issue compensating transactions to undo the previous successful reservations. This approach delivered both excellent performance (operations could run in parallel where possible) and high reliability.
// Base interfaces for SAGA operations
public interface SagaCommand<T> {
T execute() throws Exception;
void compensate(T result) throws Exception;
}
public class SagaOrchestrator {
public class SagaExecution<T> {
private final SagaCommand<T> command;
private T result;
private boolean executed = false;
public SagaExecution(SagaCommand<T> command) {
this.command = command;
}
public T execute() throws Exception {
result = command.execute();
executed = true;
return result;
}
public void compensate() throws Exception {
if (executed && result != null) {
command.compensate(result);
}
}
}
private final List<SagaExecution<?>> executions = new ArrayList<>();
public <T> T execute(SagaCommand<T> command) throws Exception {
SagaExecution<T> execution = new SagaExecution<>(command);
executions.add(execution);
return execution.execute();
}
public void compensateAll() {
// Compensate in reverse order
for (int i = executions.size() - 1; i >= 0; i--) {
try {
executions.get(i).compensate();
} catch (Exception e) {
log.error("Compensation failed", e);
// In production, you'd need dead letter queue handling
}
}
}
}
// Concrete command implementations
public class CreateOrderCommand implements SagaCommand<Order> {
private final OrderService orderService;
private final CreateOrderRequest request;
public CreateOrderCommand(OrderService orderService, CreateOrderRequest request) {
this.orderService = orderService;
this.request = request;
}
@Override
public Order execute() throws Exception {
return orderService.createOrder(request);
}
@Override
public void compensate(Order order) throws Exception {
orderService.cancelOrder(order.getId());
}
}
public class ProcessPaymentCommand implements SagaCommand<Payment> {
private final PaymentService paymentService;
private final String customerId;
private final BigDecimal amount;
@Override
public Payment execute() throws Exception {
return paymentService.processPayment(customerId, amount);
}
@Override
public void compensate(Payment payment) throws Exception {
paymentService.refundPayment(payment.getId());
}
}
public class ReserveInventoryCommand implements SagaCommand<List<InventoryReservation>> {
private final InventoryService inventoryService;
private final List<OrderItem> items;
@Override
public List<InventoryReservation> execute() throws Exception {
return inventoryService.reserveItems(items);
}
@Override
public void compensate(List<InventoryReservation> reservations) throws Exception {
for (InventoryReservation reservation : reservations) {
inventoryService.releaseReservation(reservation.getId());
}
}
}
// Usage in service
@Service
public class SagaOrderService {
public void processOrderWithSaga(CreateOrderRequest request) throws Exception {
SagaOrchestrator saga = new SagaOrchestrator();
try {
// Execute commands in sequence
Order order = saga.execute(new CreateOrderCommand(orderService, request));
Payment payment = saga.execute(new ProcessPaymentCommand(
paymentService, order.getCustomerId(), order.getTotalAmount()
));
List<InventoryReservation> reservations = saga.execute(
new ReserveInventoryCommand(inventoryService, request.getItems())
);
// If we get here, everything succeeded
orderService.confirmOrder(order.getId());
} catch (Exception e) {
// Compensate all executed commands
saga.compensateAll();
throw e;
}
}
}
Persistent SAGA with State Machine
// SAGA state management
@Entity
public class SagaTransaction {
@Id
private String id;
@Enumerated(EnumType.STRING)
private SagaStatus status;
private String currentStep;
@ElementCollection
private List<String> completedSteps = new ArrayList<>();
@ElementCollection
private List<String> compensatedSteps = new ArrayList<>();
private String contextData; // JSON serialized context
// getters/setters...
}
public enum SagaStatus {
STARTED, IN_PROGRESS, COMPLETED, COMPENSATING, COMPENSATED, FAILED
}
@Component
public class PersistentSagaOrchestrator {
@Autowired
private SagaTransactionRepository sagaRepo;
@Transactional
public void executeSaga(String sagaId, List<SagaStep> steps) {
SagaTransaction saga = sagaRepo.findById(sagaId)
.orElse(new SagaTransaction(sagaId));
try {
for (SagaStep step : steps) {
if (saga.getCompletedSteps().contains(step.getName())) {
continue; // Already completed
}
saga.setCurrentStep(step.getName());
saga.setStatus(SagaStatus.IN_PROGRESS);
sagaRepo.save(saga);
// Execute step
step.execute();
saga.getCompletedSteps().add(step.getName());
sagaRepo.save(saga);
}
saga.setStatus(SagaStatus.COMPLETED);
sagaRepo.save(saga);
} catch (Exception e) {
compensateSaga(sagaId);
throw e;
}
}
@Transactional
public void compensateSaga(String sagaId) {
SagaTransaction saga = sagaRepo.findById(sagaId)
.orElseThrow(() -> new IllegalArgumentException("SAGA not found"));
saga.setStatus(SagaStatus.COMPENSATING);
sagaRepo.save(saga);
// Compensate in reverse order
List<String> stepsToCompensate = new ArrayList<>(saga.getCompletedSteps());
Collections.reverse(stepsToCompensate);
for (String stepName : stepsToCompensate) {
if (saga.getCompensatedSteps().contains(stepName)) {
continue;
}
try {
SagaStep step = findStepByName(stepName);
step.compensate();
saga.getCompensatedSteps().add(stepName);
sagaRepo.save(saga);
} catch (Exception e) {
log.error("Compensation failed for step: " + stepName, e);
saga.setStatus(SagaStatus.FAILED);
sagaRepo.save(saga);
return;
}
}
saga.setStatus(SagaStatus.COMPENSATED);
sagaRepo.save(saga);
}
}
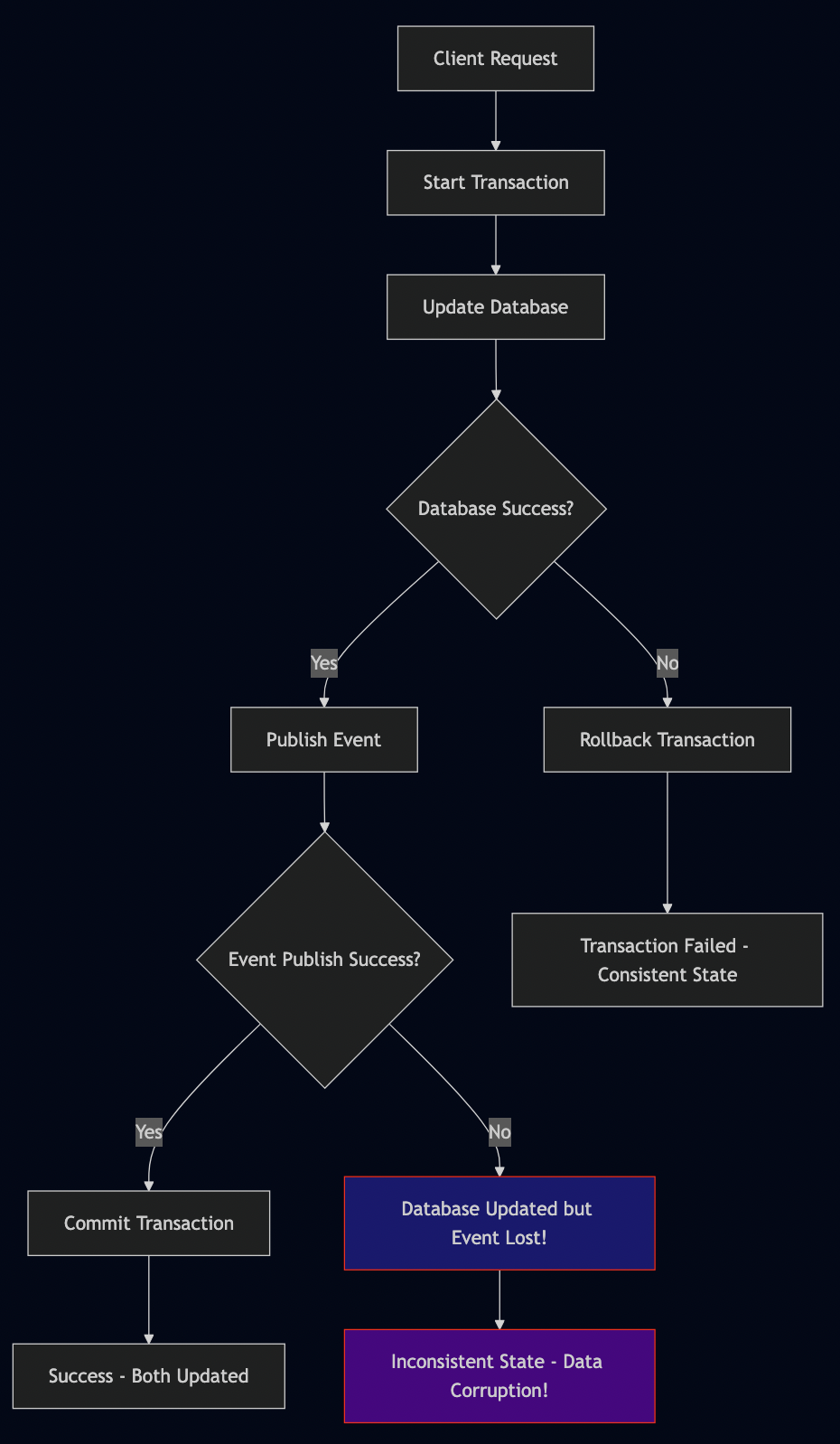
One of the most insidious transaction problems occurs when you need to both update the database and publish an event. I’ve debugged countless production issues where customers received order confirmations but no order existed in the database, or orders were created but notification events never fired.
The Anti-Pattern: Sequential Operations
// THIS IS FUNDAMENTALLY BROKEN - DON'T DO THIS
@Service
public class BrokenOrderService {
@Transactional
public void processOrder(CreateOrderRequest request) {
Order order = orderRepository.save(new Order(request));
// DANGER: Event published outside transaction boundary
eventPublisher.publishEvent(new OrderCreatedEvent(order));
// What if this line throws an exception?
// Event is already published but transaction will rollback!
}
// ALSO BROKEN: Event first, then database
@Transactional
public void processOrderEventFirst(CreateOrderRequest request) {
Order order = new Order(request);
// DANGER: Event published before persistence
eventPublisher.publishEvent(new OrderCreatedEvent(order));
// What if database save fails?
// Event consumers will query for order that doesn't exist!
orderRepository.save(order);
}
}
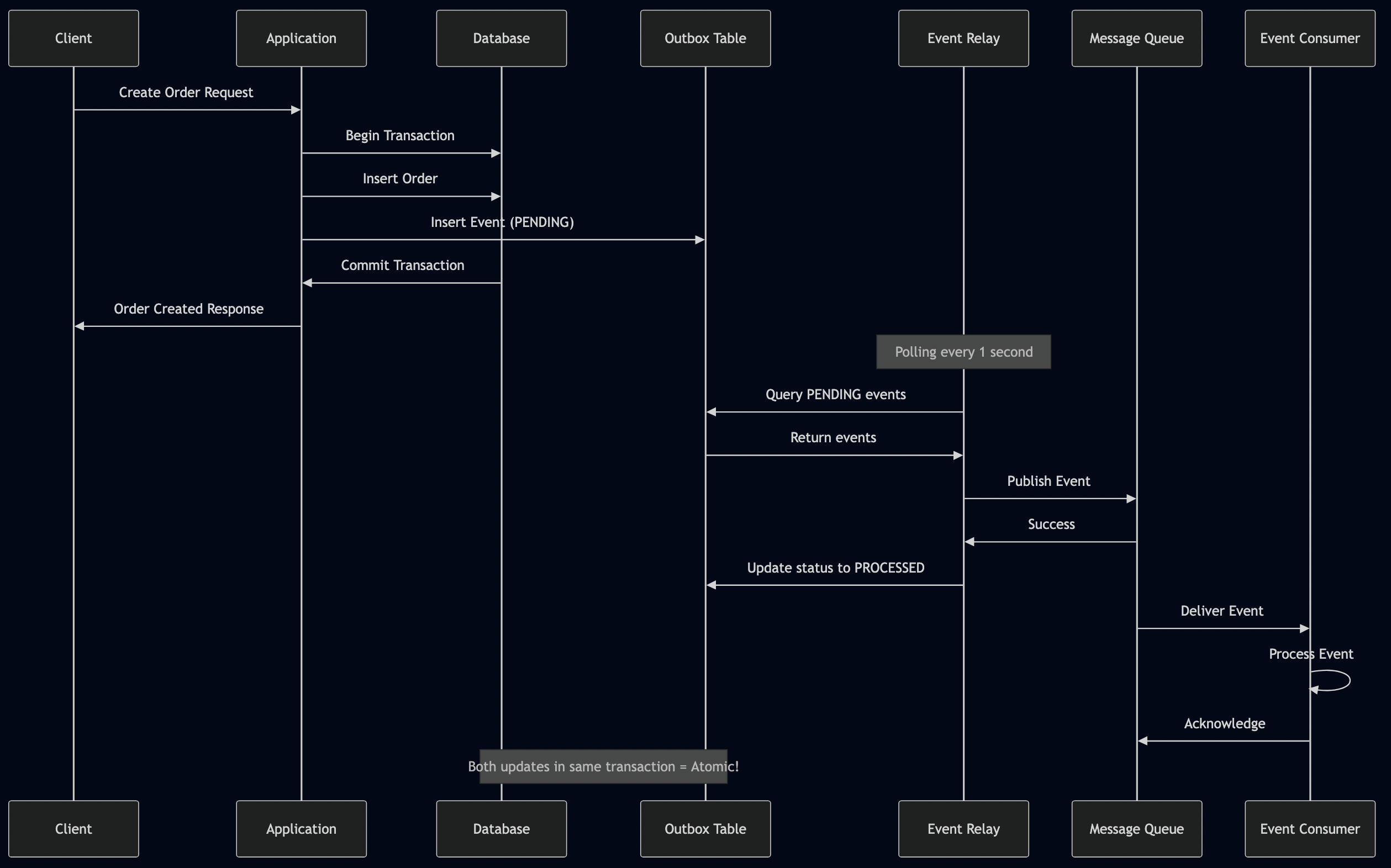
Solution 1: Transactional Outbox Pattern
I have used Outbox pattern in a number of applications especially for sending notifications to users where instead of directly sending an event to a queue, the messages are stored in the database and then relayed to external service like Apple Push Notification Service (APNs) or Google Push Notification Service (FCM).
// Outbox event entity
@Entity
@Table(name = "outbox_events")
public class OutboxEvent {
@Id
private String id;
@Column(name = "event_type")
private String eventType;
@Column(name = "payload", columnDefinition = "TEXT")
private String payload;
@Column(name = "created_at")
private Instant createdAt;
@Column(name = "processed_at")
private Instant processedAt;
@Enumerated(EnumType.STRING)
private OutboxStatus status;
// constructors, getters, setters...
}
public enum OutboxStatus {
PENDING, PROCESSED, FAILED
}
// Outbox repository
@Repository
public interface OutboxEventRepository extends JpaRepository<OutboxEvent, String> {
@Query("SELECT e FROM OutboxEvent e WHERE e.status = :status ORDER BY e.createdAt ASC")
List<OutboxEvent> findByStatusOrderByCreatedAt(@Param("status") OutboxStatus status);
@Modifying
@Query("UPDATE OutboxEvent e SET e.status = :status, e.processedAt = :processedAt WHERE e.id = :id")
void updateStatus(@Param("id") String id, @Param("status") OutboxStatus status, @Param("processedAt") Instant processedAt);
}
// Corrected order service using outbox
@Service
public class TransactionalOrderService {
@Autowired
private OrderRepository orderRepository;
@Autowired
private OutboxEventRepository outboxRepository;
@Transactional
public void processOrder(CreateOrderRequest request) {
// 1. Process business logic
Order order = new Order(request);
order = orderRepository.save(order);
// 2. Store event in same transaction
OutboxEvent event = new OutboxEvent(
UUID.randomUUID().toString(),
"OrderCreated",
serializeEvent(new OrderCreatedEvent(order)),
Instant.now(),
OutboxStatus.PENDING
);
outboxRepository.save(event);
// Both order and event are committed atomically!
}
private String serializeEvent(Object event) {
try {
return objectMapper.writeValueAsString(event);
} catch (JsonProcessingException e) {
throw new RuntimeException("Event serialization failed", e);
}
}
}
// Event relay service
@Component
public class OutboxEventRelay {
@Autowired
private OutboxEventRepository outboxRepository;
@Autowired
private ApplicationEventPublisher eventPublisher;
@Scheduled(fixedDelay = 1000) // Poll every second
@Transactional
public void processOutboxEvents() {
List<OutboxEvent> pendingEvents = outboxRepository
.findByStatusOrderByCreatedAt(OutboxStatus.PENDING);
for (OutboxEvent outboxEvent : pendingEvents) {
try {
// Deserialize and publish the event
Object event = deserializeEvent(outboxEvent.getEventType(), outboxEvent.getPayload());
eventPublisher.publishEvent(event);
// Mark as processed
outboxRepository.updateStatus(
outboxEvent.getId(),
OutboxStatus.PROCESSED,
Instant.now()
);
} catch (Exception e) {
log.error("Failed to process outbox event: " + outboxEvent.getId(), e);
outboxRepository.updateStatus(
outboxEvent.getId(),
OutboxStatus.FAILED,
Instant.now()
);
}
}
}
}
Go Implementation: Outbox Pattern with GORM
// Outbox event model
type OutboxEvent struct {
ID string `gorm:"primarykey"`
EventType string `gorm:"not null"`
Payload string `gorm:"type:text;not null"`
CreatedAt time.Time
ProcessedAt *time.Time
Status OutboxStatus `gorm:"type:varchar(20);default:'PENDING'"`
}
type OutboxStatus string
const (
OutboxStatusPending OutboxStatus = "PENDING"
OutboxStatusProcessed OutboxStatus = "PROCESSED"
OutboxStatusFailed OutboxStatus = "FAILED"
)
// Service with outbox pattern
type OrderService struct {
db *gorm.DB
eventRelay *OutboxEventRelay
}
func (s *OrderService) ProcessOrder(ctx context.Context, request CreateOrderRequest) (*Order, error) {
var order *Order
err := s.db.Transaction(func(tx *gorm.DB) error {
// 1. Create order
order = &Order{
CustomerID: request.CustomerID,
TotalAmount: request.TotalAmount,
Status: "CONFIRMED",
}
if err := tx.Create(order).Error; err != nil {
return fmt.Errorf("failed to create order: %w", err)
}
// 2. Store event in same transaction
eventPayload, err := json.Marshal(OrderCreatedEvent{
OrderID: order.ID,
CustomerID: order.CustomerID,
TotalAmount: order.TotalAmount,
})
if err != nil {
return fmt.Errorf("failed to serialize event: %w", err)
}
outboxEvent := &OutboxEvent{
ID: uuid.New().String(),
EventType: "OrderCreated",
Payload: string(eventPayload),
CreatedAt: time.Now(),
Status: OutboxStatusPending,
}
if err := tx.Create(outboxEvent).Error; err != nil {
return fmt.Errorf("failed to store outbox event: %w", err)
}
return nil
})
return order, err
}
// Event relay service
type OutboxEventRelay struct {
db *gorm.DB
eventPublisher EventPublisher
ticker *time.Ticker
done chan bool
}
func NewOutboxEventRelay(db *gorm.DB, publisher EventPublisher) *OutboxEventRelay {
return &OutboxEventRelay{
db: db,
eventPublisher: publisher,
ticker: time.NewTicker(1 * time.Second),
done: make(chan bool),
}
}
func (r *OutboxEventRelay) Start(ctx context.Context) {
go func() {
for {
select {
case <-r.ticker.C:
r.processOutboxEvents(ctx)
case <-r.done:
return
case <-ctx.Done():
return
}
}
}()
}
func (r *OutboxEventRelay) processOutboxEvents(ctx context.Context) {
var events []OutboxEvent
// Find pending events
if err := r.db.Where("status = ?", OutboxStatusPending).
Order("created_at ASC").
Limit(100).
Find(&events).Error; err != nil {
log.Printf("Failed to fetch outbox events: %v", err)
return
}
for _, event := range events {
if err := r.processEvent(ctx, event); err != nil {
log.Printf("Failed to process event %s: %v", event.ID, err)
// Mark as failed
now := time.Now()
r.db.Model(&event).Updates(OutboxEvent{
Status: OutboxStatusFailed,
ProcessedAt: &now,
})
} else {
// Mark as processed
now := time.Now()
r.db.Model(&event).Updates(OutboxEvent{
Status: OutboxStatusProcessed,
ProcessedAt: &now,
})
}
}
}
func (r *OutboxEventRelay) processEvent(ctx context.Context, event OutboxEvent) error {
// Deserialize and publish the event
switch event.EventType {
case "OrderCreated":
var orderEvent OrderCreatedEvent
if err := json.Unmarshal([]byte(event.Payload), &orderEvent); err != nil {
return err
}
return r.eventPublisher.Publish(ctx, orderEvent)
default:
return fmt.Errorf("unknown event type: %s", event.EventType)
}
}
Rust Implementation: Outbox with Diesel
// Outbox event model
use diesel::prelude::*;
use serde::{Deserialize, Serialize};
use chrono::{DateTime, Utc};
#[derive(Debug, Clone, Queryable, Insertable, Serialize, Deserialize)]
#[diesel(table_name = outbox_events)]
pub struct OutboxEvent {
pub id: String,
pub event_type: String,
pub payload: String,
pub created_at: DateTime<Utc>,
pub processed_at: Option<DateTime<Utc>>,
pub status: OutboxStatus,
}
#[derive(Debug, Clone, Serialize, Deserialize, diesel_derive_enum::DbEnum)]
#[ExistingTypePath = "crate::schema::sql_types::OutboxStatus"]
pub enum OutboxStatus {
Pending,
Processed,
Failed,
}
// Service with outbox
impl OrderService {
transactional! {
fn process_order_with_outbox(request: CreateOrderRequest) -> Order {
use crate::schema::orders::dsl::*;
use crate::schema::outbox_events::dsl::*;
// 1. Create order
let new_order = NewOrder {
customer_id: &request.customer_id,
total_amount: request.total_amount,
status: "CONFIRMED",
};
let order: Order = diesel::insert_into(orders)
.values(&new_order)
.get_result(conn)
.map_err(TransactionError::Database)?;
// 2. Create event in same transaction
let event_payload = serde_json::to_string(&OrderCreatedEvent {
order_id: order.id,
customer_id: order.customer_id.clone(),
total_amount: order.total_amount,
}).map_err(|e| TransactionError::Business(format!("Event serialization failed: {}", e)))?;
let outbox_event = OutboxEvent {
id: uuid::Uuid::new_v4().to_string(),
event_type: "OrderCreated".to_string(),
payload: event_payload,
created_at: Utc::now(),
processed_at: None,
status: OutboxStatus::Pending,
};
diesel::insert_into(outbox_events)
.values(&outbox_event)
.execute(conn)
.map_err(TransactionError::Database)?;
Ok(order)
}
}
}
// Event relay service
pub struct OutboxEventRelay {
pool: Pool<ConnectionManager<PgConnection>>,
event_publisher: Arc<dyn EventPublisher>,
}
impl OutboxEventRelay {
pub async fn start(&self, mut shutdown: tokio::sync::broadcast::Receiver<()>) {
let mut interval = tokio::time::interval(Duration::from_secs(1));
loop {
tokio::select! {
_ = interval.tick() => {
if let Err(e) = self.process_outbox_events().await {
tracing::error!("Failed to process outbox events: {}", e);
}
}
_ = shutdown.recv() => {
tracing::info!("Outbox relay shutting down");
break;
}
}
}
}
async fn process_outbox_events(&self) -> Result<(), Box<dyn std::error::Error>> {
use crate::schema::outbox_events::dsl::*;
let mut conn = self.pool.get()?;
let pending_events: Vec<OutboxEvent> = outbox_events
.filter(status.eq(OutboxStatus::Pending))
.order(created_at.asc())
.limit(100)
.load(&mut conn)?;
for event in pending_events {
match self.process_single_event(&event).await {
Ok(_) => {
// Mark as processed
let now = Utc::now();
diesel::update(outbox_events.filter(id.eq(&event.id)))
.set((
status.eq(OutboxStatus::Processed),
processed_at.eq(Some(now))
))
.execute(&mut conn)?;
}
Err(e) => {
tracing::error!("Failed to process event {}: {}", event.id, e);
let now = Utc::now();
diesel::update(outbox_events.filter(id.eq(&event.id)))
.set((
status.eq(OutboxStatus::Failed),
processed_at.eq(Some(now))
))
.execute(&mut conn)?;
}
}
}
Ok(())
}
}
Solution 2: Change Data Capture (CDC)
I have used this pattern extensively for high-throughput systems where polling-based outbox patterns couldn’t keep up with the data volume. My first implementation was in the early 2000s when building an intelligent traffic management system, where I used CDC to synchronize data between two subsystems—all database changes were captured and published to a JMS queue, with consumers updating their local databases in near real-time. In subsequent projects, I used CDC to publish database changes directly to Kafka topics, enabling downstream services to build analytical systems, populate data lakes, and power real-time reporting dashboards.
As CDC eliminates the polling overhead entirely, this approach can be scaled to millions of transactions per day while maintaining sub-second latency for downstream consumers.
// CDC-based event publisher using Debezium
@Component
public class CDCEventHandler {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@KafkaListener(topics = "dbserver.public.orders")
public void handleOrderChange(ConsumerRecord<String, String> record) {
try {
// Parse CDC event
JsonNode changeEvent = objectMapper.readTree(record.value());
String operation = changeEvent.get("op").asText(); // c=create, u=update, d=delete
if ("c".equals(operation)) {
JsonNode after = changeEvent.get("after");
OrderCreatedEvent event = OrderCreatedEvent.builder()
.orderId(after.get("id").asLong())
.customerId(after.get("customer_id").asText())
.totalAmount(after.get("total_amount").asLong())
.build();
// Publish to business event topic
kafkaTemplate.send("order-events",
event.getOrderId().toString(),
objectMapper.writeValueAsString(event));
}
} catch (Exception e) {
log.error("Failed to process CDC event", e);
}
}
}
Solution 3: Event Sourcing
I have often used this pattern with financial systems in conjunction with CQRS, where all changes are stored as immutable events and can be replayed if needed. This approach is particularly valuable in financial contexts because it provides a complete audit trail—every account balance change, every trade, every adjustment can be traced back to its originating event.
For systems where events are the source of truth:
// Event store as the primary persistence
@Entity
public class EventStore {
@Id
private String eventId;
private String aggregateId;
private String eventType;
private String eventData;
private Long version;
private Instant timestamp;
// getters, setters...
}
@Service
public class EventSourcedOrderService {
@Transactional
public void processOrder(CreateOrderRequest request) {
String orderId = UUID.randomUUID().toString();
// Store event - this IS the transaction
OrderCreatedEvent event = new OrderCreatedEvent(orderId, request);
EventStore eventRecord = new EventStore(
UUID.randomUUID().toString(),
orderId,
"OrderCreated",
objectMapper.writeValueAsString(event),
1L,
Instant.now()
);
eventStoreRepository.save(eventRecord);
// Publish immediately - event is already persisted
eventPublisher.publishEvent(event);
// Read model is updated asynchronously via event handlers
}
}
One of the most overlooked sources of transaction problems is the mismatch between application threads and database connections. I’ve debugged production deadlocks that turned out to be caused by connection pool starvation rather than actual database contention.
The Thread-Pool vs Connection-Pool Mismatch
// DANGEROUS CONFIGURATION - This will cause deadlocks
@Configuration
public class ProblematicDataSourceConfig {
@Bean
public DataSource dataSource() {
HikariConfig config = new HikariConfig();
config.setMaximumPoolSize(10); // Only 10 connections
config.setConnectionTimeout(30000); // 30 second timeout
return new HikariDataSource(config);
}
@Bean
public Executor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(50); // 50 threads!
executor.setMaxPoolSize(100); // Up to 100 threads!
return executor;
}
}
// This service will cause connection pool starvation
@Service
public class ProblematicBulkService {
@Async
@Transactional
public CompletableFuture<Void> processBatch(List<Order> orders) {
// 100 threads trying to get 10 connections = deadlock
for (Order order : orders) {
// Long-running transaction holds connection
processOrder(order);
// Calling another transactional method = needs another connection
auditService.logOrderProcessing(order); // DEADLOCK RISK!
}
return CompletableFuture.completedFuture(null);
}
}
Correct Connection Pool Configuration
@Configuration
public class OptimalDataSourceConfig {
@Value("${app.database.max-connections:20}")
private int maxConnections;
@Bean
public DataSource dataSource() {
HikariConfig config = new HikariConfig();
// Rule of thumb: connections >= active threads + buffer
config.setMaximumPoolSize(maxConnections);
config.setMinimumIdle(5);
// Prevent connection hoarding
config.setConnectionTimeout(5000); // 5 seconds
config.setIdleTimeout(300000); // 5 minutes
config.setMaxLifetime(1200000); // 20 minutes
// Detect leaked connections
config.setLeakDetectionThreshold(60000); // 1 minute
return new HikariDataSource(config);
}
@Bean
public Executor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// Keep thread pool smaller than connection pool
executor.setCorePoolSize(maxConnections - 5);
executor.setMaxPoolSize(maxConnections);
executor.setQueueCapacity(100);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
}
// Connection-aware bulk processing
@Service
public class OptimalBulkService {
@Transactional
public void processBatchOptimized(List<Order> orders) {
int batchSize = 50; // Tune based on connection pool size
for (int i = 0; i < orders.size(); i += batchSize) {
List<Order> batch = orders.subList(i, Math.min(i + batchSize, orders.size()));
// Process batch in single transaction
processBatchInternal(batch);
// Flush and clear to prevent memory issues
entityManager.flush();
entityManager.clear();
}
}
private void processBatchInternal(List<Order> batch) {
// Bulk operations to reduce connection time
orderRepository.saveAll(batch);
// Batch audit logging
List<AuditLog> auditLogs = batch.stream()
.map(order -> new AuditLog("ORDER_PROCESSED", order.getId()))
.collect(Collectors.toList());
auditRepository.saveAll(auditLogs);
}
}
ETL Transaction Boundaries: The Performance Killer
Object-Relational (OR) mapping and automated transactions simplify development, but I have encountered countless performance issues where the same patterns were used for ETL processing or importing data. For example, I’ve seen code where developers used Hibernate to import millions of records, and it took hours to process data that should have completed in minutes. In other cases, I saw transactions committed after inserting each record—an import job that should have taken an hour ended up running for days.
These performance issues stem from misunderstanding the fundamental differences between OLTP (Online Transaction Processing) and OLAP/ETL (Online Analytical Processing) workloads. OLTP patterns optimize for individual record operations with strict ACID guarantees, while ETL patterns optimize for bulk operations with relaxed consistency requirements. Care must be taken to understand these tradeoffs and choose the right approach for each scenario.
// WRONG - Each record in its own transaction (SLOW!)
@Service
public class SlowETLService {
public void importOrders(InputStream csvFile) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(csvFile))) {
String line;
while ((line = reader.readLine()) != null) {
processOrderRecord(line); // Each call = new transaction!
}
}
}
@Transactional // New transaction per record = DISASTER
private void processOrderRecord(String csvLine) {
Order order = parseOrderFromCsv(csvLine);
orderRepository.save(order);
// Commit happens here - thousands of commits!
}
}
// CORRECT - Batch processing with optimal transaction boundaries
@Service
public class FastETLService {
@Value("${etl.batch-size:1000}")
private int batchSize;
public void importOrdersOptimized(InputStream csvFile) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(csvFile))) {
List<Order> batch = new ArrayList<>(batchSize);
String line;
while ((line = reader.readLine()) != null) {
Order order = parseOrderFromCsv(line);
batch.add(order);
if (batch.size() >= batchSize) {
processBatch(batch);
batch.clear();
}
}
// Process remaining records
if (!batch.isEmpty()) {
processBatch(batch);
}
}
}
@Transactional
private void processBatch(List<Order> orders) {
// Single transaction for entire batch
orderRepository.saveAll(orders);
// Bulk validation and error handling
validateBatch(orders);
// Bulk audit logging
createAuditEntries(orders);
}
}
Go Connection Pool Management
// Connection pool configuration with proper sizing
func setupDatabase() *gorm.DB {
dsn := "host=localhost user=postgres password=secret dbname=orders port=5432 sslmode=disable"
db, err := gorm.Open(postgres.Open(dsn), &gorm.Config{})
if err != nil {
log.Fatal("Failed to connect to database:", err)
}
sqlDB, err := db.DB()
if err != nil {
log.Fatal("Failed to get SQL DB:", err)
}
// Critical: Match pool size to application concurrency
sqlDB.SetMaxOpenConns(20) // Maximum connections
sqlDB.SetMaxIdleConns(5) // Idle connections
sqlDB.SetConnMaxLifetime(time.Hour) // Connection lifetime
sqlDB.SetConnMaxIdleTime(time.Minute * 30) // Idle timeout
return db
}
// ETL with proper batching
type ETLService struct {
db *gorm.DB
batchSize int
}
func (s *ETLService) ImportOrders(csvFile io.Reader) error {
scanner := bufio.NewScanner(csvFile)
batch := make([]*Order, 0, s.batchSize)
for scanner.Scan() {
order, err := s.parseOrderFromCSV(scanner.Text())
if err != nil {
log.Printf("Failed to parse order: %v", err)
continue
}
batch = append(batch, order)
if len(batch) >= s.batchSize {
if err := s.processBatch(batch); err != nil {
return fmt.Errorf("batch processing failed: %w", err)
}
batch = batch[:0] // Reset slice but keep capacity
}
}
// Process remaining orders
if len(batch) > 0 {
return s.processBatch(batch)
}
return scanner.Err()
}
func (s *ETLService) processBatch(orders []*Order) error {
return s.db.Transaction(func(tx *gorm.DB) error {
// Batch insert for performance
if err := tx.CreateInBatches(orders, len(orders)).Error; err != nil {
return err
}
// Bulk audit logging in same transaction
auditLogs := make([]*AuditLog, len(orders))
for i, order := range orders {
auditLogs[i] = &AuditLog{
Action: "ORDER_IMPORTED",
OrderID: order.ID,
Timestamp: time.Now(),
}
}
return tx.CreateInBatches(auditLogs, len(auditLogs)).Error
})
}
Deadlock Detection and Resolution
Deadlocks are inevitable in high-concurrency systems. The key is detecting and handling them gracefully:
Database-Level Deadlock Prevention
@Service
public class DeadlockAwareAccountService {
@Retryable(
value = {CannotAcquireLockException.class, DeadlockLoserDataAccessException.class},
maxAttempts = 3,
backoff = @Backoff(delay = 100, multiplier = 2, random = true)
)
@Transactional(isolation = Isolation.READ_COMMITTED)
public void transferFunds(String fromAccountId, String toAccountId, BigDecimal amount) {
// CRITICAL: Always acquire locks in consistent order to prevent deadlocks
String firstId = fromAccountId.compareTo(toAccountId) < 0 ? fromAccountId : toAccountId;
String secondId = fromAccountId.compareTo(toAccountId) < 0 ? toAccountId : fromAccountId;
// Lock accounts in alphabetical order
Account firstAccount = accountRepository.findByIdForUpdate(firstId);
Account secondAccount = accountRepository.findByIdForUpdate(secondId);
// Determine which is from/to after locking
Account fromAccount = fromAccountId.equals(firstId) ? firstAccount : secondAccount;
Account toAccount = fromAccountId.equals(firstId) ? secondAccount : firstAccount;
if (fromAccount.getBalance().compareTo(amount) < 0) {
throw new InsufficientFundsException();
}
fromAccount.setBalance(fromAccount.getBalance().subtract(amount));
toAccount.setBalance(toAccount.getBalance().add(amount));
accountRepository.save(fromAccount);
accountRepository.save(toAccount);
}
}
// Custom repository with explicit locking
@Repository
public interface AccountRepository extends JpaRepository<Account, String> {
@Query("SELECT a FROM Account a WHERE a.id = :id")
@Lock(LockModeType.PESSIMISTIC_WRITE)
Account findByIdForUpdate(@Param("id") String id);
// Timeout-based locking to prevent indefinite waits
@QueryHints({@QueryHint(name = "javax.persistence.lock.timeout", value = "5000")})
@Query("SELECT a FROM Account a WHERE a.id = :id")
@Lock(LockModeType.PESSIMISTIC_WRITE)
Account findByIdForUpdateWithTimeout(@Param("id") String id);
}
Application-Level Deadlock Detection
// Deadlock-aware service with timeout and retry
type AccountService struct {
db *gorm.DB
lockTimeout time.Duration
retryAttempts int
}
func (s *AccountService) TransferFundsWithDeadlockHandling(
ctx context.Context,
fromAccountID, toAccountID string,
amount int64,
) error {
for attempt := 0; attempt < s.retryAttempts; attempt++ {
err := s.attemptTransfer(ctx, fromAccountID, toAccountID, amount)
if err == nil {
return nil // Success
}
// Check if it's a deadlock or timeout error
if s.isRetryableError(err) {
// Exponential backoff with jitter
backoff := time.Duration(attempt+1) * 100 * time.Millisecond
jitter := time.Duration(rand.Intn(100)) * time.Millisecond
select {
case <-time.After(backoff + jitter):
continue // Retry
case <-ctx.Done():
return ctx.Err()
}
}
return err // Non-retryable error
}
return fmt.Errorf("transfer failed after %d attempts", s.retryAttempts)
}
func (s *AccountService) attemptTransfer(
ctx context.Context,
fromAccountID, toAccountID string,
amount int64,
) error {
// Set transaction timeout
timeoutCtx, cancel := context.WithTimeout(ctx, s.lockTimeout)
defer cancel()
return s.db.WithContext(timeoutCtx).Transaction(func(tx *gorm.DB) error {
// Lock in consistent order
firstID, secondID := fromAccountID, toAccountID
if fromAccountID > toAccountID {
firstID, secondID = toAccountID, fromAccountID
}
var fromAccount, toAccount Account
// Lock first account
if err := tx.Set("gorm:query_option", "FOR UPDATE NOWAIT").
Where("id = ?", firstID).First(&fromAccount).Error; err != nil {
return err
}
// Lock second account
if err := tx.Set("gorm:query_option", "FOR UPDATE NOWAIT").
Where("id = ?", secondID).First(&toAccount).Error; err != nil {
return err
}
// Ensure we have the right accounts
if fromAccount.ID != fromAccountID {
fromAccount, toAccount = toAccount, fromAccount
}
if fromAccount.Balance < amount {
return fmt.Errorf("insufficient funds")
}
fromAccount.Balance -= amount
toAccount.Balance += amount
if err := tx.Save(&fromAccount).Error; err != nil {
return err
}
return tx.Save(&toAccount).Error
})
}
func (s *AccountService) isRetryableError(err error) bool {
errStr := strings.ToLower(err.Error())
// Common deadlock/timeout indicators
retryablePatterns := []string{
"deadlock detected",
"lock timeout",
"could not obtain lock",
"serialization failure",
"concurrent update",
}
for _, pattern := range retryablePatterns {
if strings.Contains(errStr, pattern) {
return true
}
}
return false
}
CQRS: Separating Read and Write Transaction Models
I have also used Command Query Responsibility Segregation pattern in some financial applications that allows different transaction strategies for reads vs writes:
Java CQRS Implementation
// Command side - strict ACID transactions
@Service
public class OrderCommandService {
@Autowired
private OrderRepository orderRepository;
@Autowired
private EventPublisher eventPublisher;
@Transactional(isolation = Isolation.SERIALIZABLE)
public void createOrder(CreateOrderCommand command) {
// Validate command
validateOrderCommand(command);
Order order = new Order(command);
order = orderRepository.save(order);
// Publish event for read model update
eventPublisher.publish(new OrderCreatedEvent(order));
}
@Transactional(isolation = Isolation.READ_COMMITTED)
public void updateOrderStatus(UpdateOrderStatusCommand command) {
Order order = orderRepository.findById(command.getOrderId())
.orElseThrow(() -> new OrderNotFoundException());
order.updateStatus(command.getNewStatus());
orderRepository.save(order);
eventPublisher.publish(new OrderStatusChangedEvent(order));
}
}
// Query side - optimized for reads, eventual consistency
@Service
public class OrderQueryService {
@Autowired
private OrderReadModelRepository readModelRepository;
// Read-only transaction for consistency within the query
@Transactional(readOnly = true)
public OrderSummary getOrderSummary(String customerId) {
List<OrderReadModel> orders = readModelRepository
.findByCustomerId(customerId);
return OrderSummary.builder()
.totalOrders(orders.size())
.totalAmount(orders.stream()
.mapToLong(OrderReadModel::getTotalAmount)
.sum())
.recentOrders(orders.stream()
.sorted((o1, o2) -> o2.getCreatedAt().compareTo(o1.getCreatedAt()))
.limit(10)
.collect(Collectors.toList()))
.build();
}
// No transaction needed for simple lookups
public List<OrderReadModel> searchOrders(OrderSearchCriteria criteria) {
return readModelRepository.search(criteria);
}
}
// Event handler updates read model asynchronously
@Component
public class OrderReadModelUpdater {
@EventHandler
@Async
@Transactional
public void handle(OrderCreatedEvent event) {
OrderReadModel readModel = OrderReadModel.builder()
.orderId(event.getOrderId())
.customerId(event.getCustomerId())
.totalAmount(event.getTotalAmount())
.status(event.getStatus())
.createdAt(event.getCreatedAt())
.build();
readModelRepository.save(readModel);
}
@EventHandler
@Async
@Transactional
public void handle(OrderStatusChangedEvent event) {
readModelRepository.updateStatus(
event.getOrderId(),
event.getNewStatus(),
event.getUpdatedAt()
);
}
}
Data Locality and Performance Considerations
Data locality is critical to performance issues and I have seen a number of performance issues where data-source was not colocated with the data processing APIs resulting in higher network latency and poor performance:
Multi-Region Database Strategy
@Configuration
public class MultiRegionDataSourceConfig {
// Primary database in same region
@Bean
@Primary
@ConfigurationProperties("spring.datasource.primary")
public DataSource primaryDataSource() {
return DataSourceBuilder.create().build();
}
// Read replica in same availability zone
@Bean
@ConfigurationProperties("spring.datasource.read-replica")
public DataSource readReplicaDataSource() {
return DataSourceBuilder.create().build();
}
// Cross-region backup for disaster recovery
@Bean
@ConfigurationProperties("spring.datasource.cross-region")
public DataSource crossRegionDataSource() {
return DataSourceBuilder.create().build();
}
}
@Service
public class LocalityAwareOrderService {
@Autowired
@Qualifier("primaryDataSource")
private DataSource writeDataSource;
@Autowired
@Qualifier("readReplicaDataSource")
private DataSource readDataSource;
// Writes go to primary in same region
@Transactional("primaryTransactionManager")
public void createOrder(CreateOrderRequest request) {
// Fast writes - same AZ latency ~1ms
Order order = new Order(request);
orderRepository.save(order);
}
// Reads from local replica
@Transactional(value = "readReplicaTransactionManager", readOnly = true)
public List<Order> getOrderHistory(String customerId) {
// Even faster reads - same rack latency ~0.1ms
return orderRepository.findByCustomerId(customerId);
}
// Critical path optimization
@Transactional(timeout = 5) // Fail fast if network issues
public void processUrgentOrder(UrgentOrderRequest request) {
// Use connection pooling and keep-alive for predictable latency
processOrder(request);
}
}
Go with Regional Database Selection
type RegionalDatabaseConfig struct {
primaryDB *gorm.DB
readReplica *gorm.DB
crossRegion *gorm.DB
}
func NewRegionalDatabaseConfig(region string) *RegionalDatabaseConfig {
// Select database endpoints based on current region
primaryDSN := fmt.Sprintf("host=%s-primary.db user=app", region)
readDSN := fmt.Sprintf("host=%s-read.db user=app", region)
backupDSN := fmt.Sprintf("host=%s-backup.db user=app", getBackupRegion(region))
return &RegionalDatabaseConfig{
primaryDB: connectWithLatencyOptimization(primaryDSN),
readReplica: connectWithLatencyOptimization(readDSN),
crossRegion: connectWithLatencyOptimization(backupDSN),
}
}
func connectWithLatencyOptimization(dsn string) *gorm.DB {
db, err := gorm.Open(postgres.Open(dsn), &gorm.Config{})
if err != nil {
log.Fatal("Database connection failed:", err)
}
sqlDB, _ := db.DB()
// Optimize for low-latency
sqlDB.SetMaxOpenConns(20)
sqlDB.SetMaxIdleConns(20) // Keep connections alive
sqlDB.SetConnMaxIdleTime(0) // Never close idle connections
sqlDB.SetConnMaxLifetime(time.Hour) // Rotate connections hourly
return db
}
type OrderService struct {
config *RegionalDatabaseConfig
}
func (s *OrderService) CreateOrder(ctx context.Context, request CreateOrderRequest) error {
// Use primary database for writes
return s.config.primaryDB.WithContext(ctx).Transaction(func(tx *gorm.DB) error {
order := &Order{
CustomerID: request.CustomerID,
TotalAmount: request.TotalAmount,
Status: "PENDING",
}
return tx.Create(order).Error
})
}
func (s *OrderService) GetOrderHistory(ctx context.Context, customerID string) ([]Order, error) {
var orders []Order
// Use read replica for queries - better performance
err := s.config.readReplica.WithContext(ctx).
Where("customer_id = ?", customerID).
Order("created_at DESC").
Find(&orders).Error
return orders, err
}
Understanding Consistency: ACID vs CAP vs Linearizability
One of the most confusing aspects of distributed systems is that “consistency” means different things in different contexts. The C in ACID has nothing to do with the C in CAP, and this distinction is crucial for designing reliable systems.
The Three Faces of Consistency
// ACID Consistency: Data integrity constraints
@Entity
public class BankAccount {
@Id
private String accountId;
@Column(nullable = false)
@Min(0) // ACID Consistency: Balance cannot be negative
private BigDecimal balance;
@Version
private Long version;
}
// CAP Consistency: Linearizability across distributed nodes
@Service
public class DistributedAccountService {
// This requires coordination across all replicas
@Transactional
public void withdraw(String accountId, BigDecimal amount) {
// All replicas must see this change at the same logical time
// = CAP Consistency (Linearizability)
BankAccount account = accountRepository.findById(accountId);
if (account.getBalance().compareTo(amount) < 0) {
throw new InsufficientFundsException(); // ACID Consistency violated
}
account.setBalance(account.getBalance().subtract(amount));
accountRepository.save(account); // Maintains ACID invariants
}
}
ACID Consistency ensures your data satisfies business rules and constraints – balances can’t be negative, foreign keys must reference valid records, etc. It’s about data integrity within a single database.
CAP Consistency (Linearizability) means all nodes in a distributed system see the same data at the same time – as if there’s only one copy of the data. It’s about coordination across multiple machines.
Consistency Models in Distributed Systems
Here’s how different NoSQL systems handle consistency:
DynamoDB: Tunable Consistency
I have used DynamoDB extensively in a number of systems, especially when I worked for a large cloud provider. DynamoDB provides both strongly consistent and eventually consistent reads, but when using strongly consistent reads, all requests go to the leader node, which limits performance and scalability and is also more costly from a financial perspective. We had to carefully evaluate each use case to configure proper consistency settings to balance performance requirements with financial costs.
Additionally, NoSQL databases like DynamoDB don’t typically enforce ACID transactions across multiple items or support normal foreign key constraints, though they do support global secondary indexes. This means you have to manually handle compensating transactions and maintain referential integrity in your application code.
// DynamoDB allows you to choose consistency per operation
@Service
public class DynamoConsistencyService {
@Autowired
private DynamoDBClient dynamoClient;
// Eventually consistent read - faster, cheaper, may be stale
public Order getOrder(String orderId) {
GetItemRequest request = GetItemRequest.builder()
.tableName("Orders")
.key(Map.of("orderId", AttributeValue.builder().s(orderId).build()))
.consistentRead(false) // Eventually consistent
.build();
return dynamoClient.getItem(request);
}
// Strongly consistent read - slower, more expensive, always latest
public Order getOrderStrong(String orderId) {
GetItemRequest request = GetItemRequest.builder()
.tableName("Orders")
.key(Map.of("orderId", AttributeValue.builder().s(orderId).build()))
.consistentRead(true) // Strongly consistent = linearizable
.build();
return dynamoClient.getItem(request);
}
// Quorum-based tunable consistency
public void updateOrderWithQuorum(String orderId, String newStatus) {
// W + R > N guarantees consistency
// W=2, R=2, N=3 means writes must succeed on 2 nodes,
// reads must check 2 nodes, guaranteeing overlap
UpdateItemRequest request = UpdateItemRequest.builder()
.tableName("Orders")
.key(Map.of("orderId", AttributeValue.builder().s(orderId).build()))
.updateExpression("SET #status = :status")
.expressionAttributeNames(Map.of("#status", "status"))
.expressionAttributeValues(Map.of(":status", AttributeValue.builder().s(newStatus).build()))
.build();
dynamoClient.updateItem(request);
}
}
// Distributed lock implementation for financial operations
@Service
public class DynamoDistributedLockService {
@Autowired
private DynamoDBClient dynamoClient;
private static final String LOCK_TABLE = "distributed_locks";
private static final int LOCK_TIMEOUT_SECONDS = 30;
public boolean acquireTransferLock(String fromAccount, String toAccount, String requestId) {
// Always lock accounts in consistent order to prevent deadlocks
List<String> sortedAccounts = Arrays.asList(fromAccount, toAccount)
.stream()
.sorted()
.collect(Collectors.toList());
String lockKey = String.join(":", sortedAccounts);
long expiryTime = System.currentTimeMillis() + (LOCK_TIMEOUT_SECONDS * 1000);
try {
PutItemRequest request = PutItemRequest.builder()
.tableName(LOCK_TABLE)
.item(Map.of(
"lock_key", AttributeValue.builder().s(lockKey).build(),
"owner", AttributeValue.builder().s(requestId).build(),
"expires_at", AttributeValue.builder().n(String.valueOf(expiryTime)).build(),
"accounts", AttributeValue.builder().ss(sortedAccounts).build()
))
.conditionExpression("attribute_not_exists(lock_key) OR expires_at < :current_time")
.expressionAttributeValues(Map.of(
":current_time", AttributeValue.builder().n(String.valueOf(System.currentTimeMillis())).build()
))
.build();
dynamoClient.putItem(request);
return true;
} catch (ConditionalCheckFailedException e) {
return false; // Lock already held
}
}
public void releaseLock(String fromAccount, String toAccount, String requestId) {
List<String> sortedAccounts = Arrays.asList(fromAccount, toAccount)
.stream()
.sorted()
.collect(Collectors.toList());
String lockKey = String.join(":", sortedAccounts);
DeleteItemRequest request = DeleteItemRequest.builder()
.tableName(LOCK_TABLE)
.key(Map.of("lock_key", AttributeValue.builder().s(lockKey).build()))
.conditionExpression("owner = :request_id")
.expressionAttributeValues(Map.of(
":request_id", AttributeValue.builder().s(requestId).build()
))
.build();
try {
dynamoClient.deleteItem(request);
} catch (ConditionalCheckFailedException e) {
log.warn("Failed to release lock - may have been taken by another process: {}", lockKey);
}
}
}
// Usage in financial service
@Service
public class DynamoFinancialService {
@Autowired
private DynamoDistributedLockService lockService;
public TransferResult transferFunds(String fromAccount, String toAccount, BigDecimal amount) {
String requestId = UUID.randomUUID().toString();
// Acquire distributed lock to prevent concurrent transfers
if (!lockService.acquireTransferLock(fromAccount, toAccount, requestId)) {
return TransferResult.rejected("Another transfer in progress for these accounts");
}
try {
// Now safe to perform transfer with DynamoDB transactions
Collection<TransactionWriteRequest> actions = new ArrayList<>();
// Conditional update for from account
actions.add(TransactionWriteRequest.builder()
.update(Update.builder()
.tableName("accounts")
.key(Map.of("account_id", AttributeValue.builder().s(fromAccount).build()))
.updateExpression("SET balance = balance - :amount")
.conditionExpression("balance >= :amount") // Prevent negative balance
.expressionAttributeValues(Map.of(
":amount", AttributeValue.builder().n(amount.toString()).build()
))
.build())
.build());
// Conditional update for to account
actions.add(TransactionWriteRequest.builder()
.update(Update.builder()
.tableName("accounts")
.key(Map.of("account_id", AttributeValue.builder().s(toAccount).build()))
.updateExpression("SET balance = balance + :amount")
.expressionAttributeValues(Map.of(
":amount", AttributeValue.builder().n(amount.toString()).build()
))
.build())
.build());
// Execute atomic transaction
TransactWriteItemsRequest txRequest = TransactWriteItemsRequest.builder()
.transactItems(actions)
.build();
dynamoClient.transactWriteItems(txRequest);
return TransferResult.success();
} catch (TransactionCanceledException e) {
return TransferResult.rejected("Transfer failed - likely insufficient funds");
} finally {
lockService.releaseLock(fromAccount, toAccount, requestId);
}
}
}
The CAP Theorem in Practice
// Real-world CAP tradeoffs in microservices
@Service
public class CAPAwareOrderService {
// Partition tolerance is mandatory in distributed systems
// So you choose: Consistency OR Availability
// CP System: Choose Consistency over Availability
@CircuitBreaker(fallbackMethod = "fallbackCreateOrder")
public OrderResponse createOrderCP(CreateOrderRequest request) {
try {
// All replicas must acknowledge - may fail if partition occurs
return orderService.createOrderWithQuorum(request);
} catch (PartitionException e) {
// System becomes unavailable during partition
throw new ServiceUnavailableException("Cannot guarantee consistency during partition");
}
}
// AP System: Choose Availability over Consistency
public OrderResponse createOrderAP(CreateOrderRequest request) {
try {
// Try strong consistency first
return orderService.createOrderWithQuorum(request);
} catch (PartitionException e) {
// Fall back to available replicas - may create conflicts
log.warn("Partition detected, falling back to eventual consistency");
return orderService.createOrderEventual(request);
}
}
// Fallback for CP system
public OrderResponse fallbackCreateOrder(CreateOrderRequest request, Exception ex) {
// Return cached response or friendly error
return OrderResponse.builder()
.status("DEFERRED")
.message("Order will be processed when system recovers")
.build();
}
}
This distinction between ACID consistency and CAP consistency is fundamental to designing distributed systems. ACID gives you data integrity within a single node, while CAP forces you to choose between strong consistency and availability when networks partition. Understanding these tradeoffs lets you make informed architectural decisions based on your business requirements.
CAP Theorem and Financial Consistency
The CAP theorem creates fundamental challenges for financial systems. You cannot have both strong consistency and availability during network partitions, which forces difficult architectural decisions:
// CP System: Prioritize Consistency over Availability
@Service
public class FinancialConsistencyService {
@CircuitBreaker(fallbackMethod = "rejectTransaction")
@Transactional(isolation = Isolation.SERIALIZABLE)
public TransferResult transferFunds(String fromAccount, String toAccount, BigDecimal amount) {
// Requires consensus across all replicas
// May become unavailable during partitions
if (!distributedLockService.acquireLock(fromAccount, toAccount)) {
throw new ServiceUnavailableException("Cannot acquire distributed lock");
}
try {
// This operation requires strong consistency across all nodes
Account from = accountService.getAccountWithQuorum(fromAccount);
Account to = accountService.getAccountWithQuorum(toAccount);
if (from.getBalance().compareTo(amount) < 0) {
throw new InsufficientFundsException();
}
// Both updates must succeed on majority of replicas
accountService.updateWithQuorum(fromAccount, from.getBalance().subtract(amount));
accountService.updateWithQuorum(toAccount, to.getBalance().add(amount));
return TransferResult.success();
} finally {
distributedLockService.releaseLock(fromAccount, toAccount);
}
}
public TransferResult rejectTransaction(String fromAccount, String toAccount,
BigDecimal amount, Exception ex) {
// During partitions, reject rather than risk double spending
return TransferResult.rejected("Cannot guarantee consistency during network partition");
}
}
NoSQL Transaction Limitations: DynamoDB and Compensating Transactions
NoSQL databases often lack ACID guarantees, requiring different strategies:
DynamoDB Optimistic Concurrency
// DynamoDB with optimistic locking using version fields
@DynamoDBTable(tableName = "Orders")
public class DynamoOrder {
@DynamoDBHashKey
private String orderId;
@DynamoDBAttribute
private String customerId;
@DynamoDBAttribute
private Long totalAmount;
@DynamoDBAttribute
private String status;
@DynamoDBVersionAttribute
private Long version; // DynamoDB handles optimistic locking
// getters, setters...
}
@Service
public class DynamoOrderService {
@Autowired
private DynamoDBMapper dynamoMapper;
// Optimistic concurrency with retry
@Retryable(
value = {ConditionalCheckFailedException.class},
maxAttempts = 3,
backoff = @Backoff(delay = 100, multiplier = 2)
)
public void updateOrderStatus(String orderId, String newStatus) {
try {
// Get current version
DynamoOrder order = dynamoMapper.load(DynamoOrder.class, orderId);
if (order == null) {
throw new OrderNotFoundException();
}
// Update with version check
order.setStatus(newStatus);
dynamoMapper.save(order); // Fails if version changed
} catch (ConditionalCheckFailedException e) {
// Another process modified the record - retry
throw e;
}
}
// Multi-item transaction using DynamoDB transactions (limited)
public void transferOrderItems(String fromOrderId, String toOrderId, List<String> itemIds) {
Collection<TransactionWriteRequest> actions = new ArrayList<>();
// Read both orders first
DynamoOrder fromOrder = dynamoMapper.load(DynamoOrder.class, fromOrderId);
DynamoOrder toOrder = dynamoMapper.load(DynamoOrder.class, toOrderId);
// Prepare conditional updates
fromOrder.removeItems(itemIds);
toOrder.addItems(itemIds);
actions.add(new TransactionWriteRequest()
.withConditionCheck(new ConditionCheck()
.withTableName("Orders")
.withKey(Collections.singletonMap("orderId", new AttributeValue(fromOrderId)))
.withConditionExpression("version = :version")
.withExpressionAttributeValues(Collections.singletonMap(":version",
new AttributeValue().withN(fromOrder.getVersion().toString())))))
actions.add(new TransactionWriteRequest()
.withUpdate(new Update()
.withTableName("Orders")
.withKey(Collections.singletonMap("orderId", new AttributeValue(fromOrderId)))
.withUpdateExpression("SET #items = :items, version = version + :inc")
.withConditionExpression("version = :currentVersion")
.withExpressionAttributeNames(Collections.singletonMap("#items", "items"))
.withExpressionAttributeValues(Map.of(
":items", new AttributeValue().withSS(fromOrder.getItems()),
":inc", new AttributeValue().withN("1"),
":currentVersion", new AttributeValue().withN(fromOrder.getVersion().toString())
))));
// Execute transaction
dynamoClient.transactWriteItems(new TransactWriteItemsRequest()
.withTransactItems(actions));
}
}
Compensating Transactions for NoSQL
// SAGA pattern for NoSQL databases without transactions
@Service
public class NoSQLOrderSaga {
@Autowired
private DynamoOrderService orderService;
@Autowired
private MongoInventoryService inventoryService;
@Autowired
private CassandraPaymentService paymentService;
public void processOrderWithCompensation(CreateOrderRequest request) {
CompensatingTransactionManager saga = new CompensatingTransactionManager();
try {
// Step 1: Create order in DynamoDB
String orderId = saga.execute("CREATE_ORDER",
() -> orderService.createOrder(request),
(orderId) -> orderService.deleteOrder(orderId)
);
// Step 2: Reserve inventory in MongoDB
String reservationId = saga.execute("RESERVE_INVENTORY",
() -> inventoryService.reserveItems(request.getItems()),
(reservationId) -> inventoryService.releaseReservation(reservationId)
);
// Step 3: Process payment in Cassandra
String paymentId = saga.execute("PROCESS_PAYMENT",
() -> paymentService.processPayment(request.getPaymentInfo()),
(paymentId) -> paymentService.refundPayment(paymentId)
);
// All steps successful - confirm order
orderService.confirmOrder(orderId, paymentId, reservationId);
} catch (Exception e) {
// Compensate all executed steps
saga.compensateAll();
throw new OrderProcessingException("Order processing failed", e);
}
}
}
// Generic compensating transaction manager
public class CompensatingTransactionManager {
private final List<CompensatingAction> executedActions = new ArrayList<>();
public <T> T execute(String stepName, Supplier<T> action, Consumer<T> compensation) {
try {
T result = action.get();
executedActions.add(new CompensatingAction<>(stepName, result, compensation));
return result;
} catch (Exception e) {
log.error("Step {} failed: {}", stepName, e.getMessage());
throw e;
}
}
public void compensateAll() {
// Compensate in reverse order
for (int i = executedActions.size() - 1; i >= 0; i--) {
CompensatingAction action = executedActions.get(i);
try {
action.compensate();
log.info("Compensated step: {}", action.getStepName());
} catch (Exception e) {
log.error("Compensation failed for step: {}", action.getStepName(), e);
// In production, you'd send to dead letter queue
}
}
}
@AllArgsConstructor
private static class CompensatingAction<T> {
private final String stepName;
private final T result;
private final Consumer<T> compensationAction;
public void compensate() {
compensationAction.accept(result);
}
public String getStepName() {
return stepName;
}
}
}
Real-World Considerations
After implementing transaction management across dozens of production systems, here are the lessons that only come from battle scars:
Performance vs. Consistency Tradeoffs
// Different strategies for different use cases
@Service
public class OrderService {
// High-consistency financial operations
@Transactional(isolation = Isolation.SERIALIZABLE)
public void processPayment(PaymentRequest request) {
// Strict ACID guarantees
}
// Analytics operations can be eventually consistent
@Transactional(readOnly = true, isolation = Isolation.READ_COMMITTED)
public OrderAnalytics generateAnalytics(String customerId) {
// Faster reads, acceptable if slightly stale
}
// Bulk operations need careful batching
@Transactional
public void processBulkOrders(List<CreateOrderRequest> requests) {
int batchSize = 100;
for (int i = 0; i < requests.size(); i += batchSize) {
int end = Math.min(i + batchSize, requests.size());
List<CreateOrderRequest> batch = requests.subList(i, end);
for (CreateOrderRequest request : batch) {
processOrder(request);
}
// Flush changes to avoid memory issues
entityManager.flush();
entityManager.clear();
}
}
}
Monitoring and Observability
Transaction boundaries are invisible until they fail. Proper monitoring is crucial:
@Component
public class TransactionMetrics {
private final MeterRegistry meterRegistry;
@EventListener
public void handleTransactionCommit(TransactionCommitEvent event) {
Timer.Sample sample = Timer.start(meterRegistry);
sample.stop(Timer.builder("transaction.duration")
.tag("status", "commit")
.tag("name", event.getTransactionName())
.register(meterRegistry));
}
@EventListener
public void handleTransactionRollback(TransactionRollbackEvent event) {
Counter.builder("transaction.rollback")
.tag("reason", event.getRollbackReason())
.register(meterRegistry)
.increment();
}
}
Testing Transaction Boundaries
@TestConfiguration
static class TransactionTestConfig {
@Bean
@Primary
public PlatformTransactionManager testTransactionManager() {
// Use test-specific transaction manager that tracks state
return new TestTransactionManager();
}
}
@Test
public void testTransactionRollbackOnFailure() {
// Given
CreateOrderRequest request = createValidOrderRequest();
// Mock payment service to fail
when(paymentService.processPayment(any(), any()))
.thenThrow(new PaymentException("Payment failed"));
// When
assertThatThrownBy(() -> orderService.processOrder(request))
.isInstanceOf(PaymentException.class);
// Then
assertThat(orderRepository.count()).isEqualTo(0); // No order created
assertThat(inventoryRepository.findBySku("TEST_SKU").getQuantity())
.isEqualTo(100); // Inventory not decremented
}
Conclusion
Transaction management isn’t just about preventing data corruption—it’s about building systems that you can reason about, debug, and trust. Whether you’re using Spring’s elegant annotations, Go’s explicit transaction handling, or building custom macros in Rust, the key principles remain the same:
Make transaction boundaries explicit – Either through annotations, function signatures, or naming conventions
Fail fast and fail clearly – Don’t let partial failures create zombie states
Design for compensation – In distributed systems, rollback isn’t always possible
Monitor transaction health – You can’t improve what you don’t measure
The techniques we’ve covered—from basic ACID transactions to sophisticated SAGA patterns—form a spectrum of tools. Choose the right tool for your consistency requirements, performance needs, and operational complexity. Remember, the best transaction strategy is the one that lets you sleep soundly at night, knowing your data is safe and your system is predictable.
A few years ago, I transferred funds from my bank to one of largest cryptocurrency exchange in US but I noticed my bank account was charged twice. The exchange’s support team was… unhelpful. “Our system shows one transaction,” they insisted. After a week of back-and-forth calls and escalations, they quietly reversed the duplicate charge. This wasn’t an isolated incident, I occasionally see duplicate charges on my credit cards activities. They usually get “fixed automatically in a few days,” but that’s not the point. These aren’t edge cases—they’re symptoms of a fundamental misunderstanding about what idempotency actually means.
Most companies don’t write post-mortems about idempotency failures because they rarely cause outages. Instead, they cause something worse: data corruption, duplicate transactions, and the slow erosion of customer trust. At one trading company, we had duplicate orders execute for millions of dollars during a trading session. We manually caught it and reversed the duplicates with weeks of cleanup, but it was a wake-up call about how dangerous these silent failures can be. The same system also had an aggressive request fingerprinting to prevent duplicates and occasionally it would reject legitimate rapid trades during volatile markets. At another investment firm, a cloud outage forced us to replay thousands of failed order messages. The replay worked as designed for the immediate failure, but it created duplicate entries in downstream systems. What should have been automatic recovery turned into days of manual data cleanup.
The problem isn’t that idempotency is hard to implement. It’s that most engineers fundamentally misunderstand what it means, conflating it with basic duplicate detection and implementing dangerous “check-then-act” patterns that create race conditions.
The Idempotency Illusion
Ask ten engineers to implement idempotency, and you’ll get eleven different implementations. True idempotency means that performing an operation multiple times has the same effect as performing it once, returning the exact same response every time. Not “detecting duplicates.” Not “rejecting retries.” The same effect with the same response—including status codes, headers, and body. Here’s the brutal truth: if your API returns 201 Created on the first call and 409 Conflict on the retry, it’s not idempotent. If it returns different response bodies for the same request, it’s not idempotent. And if two concurrent requests with the same idempotency key can both succeed, you don’t have idempotency—you have a race condition wearing a disguise.
The Twelve Deadly Anti-Patterns
Anti-Pattern 1: Server-Generated Idempotency Keys
This might be the most insidious anti-pattern because it seems logical at first glance:
# THIS IS FUNDAMENTALLY BROKEN - DON'T DO THIS
def create_order(request):
# Generate key from request parameters
idempotency_key = hash(f"{request.user_id}:{request.symbol}:{request.quantity}:{datetime.now().date()}")
if cache.exists(idempotency_key):
return cache.get(idempotency_key)
# Process order...
This prevents legitimate duplicate business operations. A trader trying to buy 100 shares of AAPL twice in the same day gets blocked. At the trading firm I mentioned, they implemented time-windowed keys for “duplicate detection,” using a small time windows. During volatile markets, traders executing rapid legitimate trades were blocked because the system thought they were duplicates.
The fundamental issue: server-generated keys conflate “retry” with “duplicate business operation.” Only the client knows the difference.
The Fix: Idempotency keys MUST be client-generated, period.
Anti-Pattern 2: The “Check-Then-Act” Race Condition
This is the most common pattern I see in production codebases:
# THIS HAS A CRITICAL RACE CONDITION
def create_payment(request, idempotency_key):
# Check if we've seen this key before
existing = db.query("SELECT * FROM payments WHERE idempotency_key = ?", idempotency_key)
if existing:
return existing
# RACE CONDITION: Another request can execute between check and insert!
payment = process_payment(request)
payment.idempotency_key = idempotency_key
db.save(payment)
return payment
Here’s exactly what happens in the race condition window:
10:00:01.100 - Request A checks: key not found ?
10:00:01.150 - Request B checks: key not found ?
10:00:01.200 - Request A processes payment: $1000 charged
10:00:01.250 - Request B processes payment: $1000 charged AGAIN
10:00:01.300 - Request A saves key
10:00:01.350 - Request B saves key (overwrites A)
Customer sees: $2000 charged instead of $1000
System logs: Everything looks normal
The Fix: Use atomic operations or database transactions. The complete implementation is in src/lib.rs and src/sqlite_store.rs in my GitHub project.
Anti-Pattern 3: Not Handling Concurrent In-Progress Requests
// THIS DOESN'T HANDLE CONCURRENT REQUESTS PROPERLY
func HandleRequest(key string, req Request) Response {
if cached := cache.Get(key); cached != nil {
return cached
}
// What if another request with same key arrives NOW?
result := processRequest(req)
cache.Set(key, result)
return result
}
When a request takes 5 seconds to process and a client retries after 2 seconds, both requests execute the business logic. This is exactly what happened in my duplicate payment scenarios.
The Fix: Return a specific status for in-progress requests:
// THIS IS WRONG - Makes idempotency optional
message CreatePaymentRequest {
optional string idempotency_key = 1; // WRONG!
required string amount = 2;
}
Making idempotency keys optional is like making seatbelts optional—technically possible, but you’ll regret it when things go wrong.
The Fix:
// CORRECT - Required for all mutating operations
message CreatePaymentRequest {
required string idempotency_key = 1; // Client MUST provide
required string amount = 2;
}
For REST APIs, return 400 Bad Request if the Idempotency-Key header is missing on POST/PUT/PATCH requests.
Anti-Pattern 5: Not Preserving Original Failed Responses
// WRONG - Doesn't cache failures
if (result.isSuccess()) {
cache.put(key, result);
return result;
} else {
// Not caching failures means retries might succeed!
return result;
}
A validation error (400) on the first attempt might pass on retry if validation rules change or external state changes. This creates inconsistent behavior that’s impossible to debug.
The Fix: Cache deterministic failures:
Always cache: 2xx success responses and 4xx client errors
Never cache: 5xx server errors (allow retries)
Consider caching: Business logic failures like insufficient funds
Anti-Pattern 6: Using Non-ACID Storage for Idempotency Keys
Using eventually consistent stores like DynamoDB (without strong consistency) or Cassandra creates race conditions even with “correct” code:
Request 1 arrives ? Check key in DynamoDB ? Key not found (stale read)
Request 2 arrives ? Check key in DynamoDB ? Key not found (stale read)
Both requests process ? DUPLICATE TRANSACTION!
Amazon was one of the first major companies to adopt NoSQL at scale, using it for their shopping cart system. In the early days, I recall seeing items duplicate in my cart or mysteriously disappear and reappear. Amazon eventually solved this by moving to stronger consistency models for critical operations and implementing sophisticated conflict resolution.
Required Properties:
Strong Consistency: Reads must see all previously committed writes
Atomic Compare-and-Set: INSERT IF NOT EXISTS must be atomic
Transaction Support: Key insertion and business logic must be atomic
The Fix: Use ACID-compliant stores like PostgreSQL, MySQL, or Redis with Lua scripts. The src/sqlite_store.rs implementation shows the correct pattern.
Anti-Pattern 7: Orphaned “PENDING” States Without Recovery
When servers crash mid-processing, PENDING records become eternal blockers:
// Server inserts PENDING record
idempotencyStore.insert(key, "PENDING");
// SERVER CRASHES HERE
processPayment(); // Never executed
idempotencyStore.update(key, "COMPLETED"); // Never reached
This blocks all future retries indefinitely—a silent killer that’s hard to detect until customers complain.
The Fix: Implement timeout-based recovery:
if record.status == Status::Pending {
if record.locked_until < now() {
// Expired PENDING - safe to retry
return Ok(LockResult::Acquired);
} else {
// Still processing
return Ok(LockResult::InProgress { retry_after: 30 });
}
}
Anti-Pattern 8: Missing Request Fingerprinting
Without request fingerprinting, a client bug can reuse a key with different payloads:
# Same key, different amounts - should be rejected!
create_payment(key="abc123", amount=100) # First request
create_payment(key="abc123", amount=200) # Bug: reused key with different amount
The server sees the cached key, assumes it’s a retry, and returns the first response ($100 charged) while the client thinks it charged $200.
The Fix: Generate and verify request fingerprints:
When the idempotency store itself fails (network timeout, database down), services lack a consistent strategy:
// WRONG - Ambiguous error handling
if let Err(e) = IsIdempotentCreateTrade(...) {
return err; // Is this a duplicate or a DB failure? Different handling needed!
}
The Fix: Always fail-closed for financial operations:
Return 503 Service Unavailable for infrastructure failures
Return 409 Conflict for duplicates
Include retry-after headers when appropriate
Anti-Pattern 10: Missing Transaction Rollback on Idempotency Save Failure
// BROKEN - Business logic succeeds but idempotency save fails
dbTransaction1.begin();
processPayment(); // SUCCESS
dbTransaction1.commit();
// Separate transaction for idempotency (WRONG!)
dbTransaction2.begin();
saveIdempotencyRecord(key, response); // FAILS!
dbTransaction2.commit();
// Now payment processed but not recorded as idempotent
The Fix: Everything in one transaction. See src/sqlite_store.rs for the atomic pattern.
Anti-Pattern 11: Insufficient Idempotency Windows
Purging idempotency records too quickly breaks realistic retry scenarios:
Mobile apps with poor connectivity might retry after 5 minutes
Batch jobs might retry failed records after 1 hour
Manual intervention might happen the next business day
The Fix: Follow Stripe’s 24-hour retention window. Balance storage costs with real-world retry patterns.
Anti-Pattern 12: No Correlation Between Related Idempotent Operations
Complex workflows require multiple idempotent operations, but there’s no way to track their relationship:
If step 2 fails, how do you retry the entire workflow without duplicating step 1?
The Fix: Implement workflow-level idempotency that tracks related operations and allows resumption from failure points.
The Correct Implementation: Following Stripe’s Pattern
After analyzing production failures across multiple companies, I built a complete implementation following Stripe’s proven patterns. The core insight is that idempotency requires atomic lock acquisition:
Here’s the actual sample code that implements the atomic pattern correctly:
Core Middleware (src/lib.rs)
use async_trait::async_trait;
use chrono::{DateTime, Duration, Utc};
use serde::{Deserialize, Serialize};
use sha2::{Digest, Sha256};
use std::collections::HashMap;
use thiserror::Error;
use uuid::Uuid;
#[derive(Error, Debug)]
pub enum IdempotencyError {
#[error("Request in progress (retry after {retry_after} seconds)")]
RequestInProgress { retry_after: u64 },
#[error("Idempotency key reused with different request")]
KeyReusedWithDifferentRequest,
#[error("Missing idempotency key")]
MissingIdempotencyKey,
#[error("Storage error: {0}")]
StorageError(String),
#[error("Invalid idempotency key format")]
InvalidKeyFormat,
#[error("Transaction failed: {0}")]
TransactionFailed(String),
#[error("Concurrent request conflict")]
ConcurrentRequestConflict,
#[error("Handler execution failed: {0}")]
HandlerFailed(String),
}
#[derive(Debug, Clone, Serialize, Deserialize, PartialEq)]
pub enum IdempotencyStatus {
Pending,
Completed,
Failed { is_retryable: bool },
}
#[derive(Debug, Clone, Serialize, Deserialize)]
pub struct IdempotencyRecord {
pub key: String,
pub user_id: String, // Scope keys to user/tenant
pub request_path: String,
pub request_method: String,
pub request_fingerprint: String,
pub status: IdempotencyStatus,
pub response: Option<CachedResponse>,
pub created_at: DateTime<Utc>,
pub expires_at: DateTime<Utc>,
pub locked_until: Option<DateTime<Utc>>,
}
#[derive(Debug, Clone, Serialize, Deserialize)]
pub struct CachedResponse {
pub status_code: u16,
pub headers: HashMap<String, String>,
pub body: Vec<u8>,
}
/// Result of attempting to acquire an idempotency lock
#[derive(Debug)]
pub enum LockResult {
/// Lock acquired successfully, safe to proceed
Acquired,
/// Request already completed, return cached response
AlreadyCompleted(CachedResponse),
/// Request is currently being processed by another worker
InProgress { retry_after: u64 },
/// Key reused with different request payload
KeyReused,
/// Failed permanently, return cached error response
FailedPermanently(CachedResponse),
}
/// Trait for idempotency storage backends
#[async_trait]
pub trait IdempotencyStore: Send + Sync {
/// Atomically attempt to acquire a lock for processing
/// This must be an atomic operation that either:
/// 1. Creates a new PENDING record and returns Acquired
/// 2. Returns the current state if record exists
async fn try_acquire_lock(
&self,
record: IdempotencyRecord,
) -> Result<LockResult, IdempotencyError>;
/// Atomically update record with final result and release lock
/// This must happen in a single transaction with business logic
async fn complete_with_response(
&self,
key: &str,
user_id: &str,
status: IdempotencyStatus,
response: Option<CachedResponse>,
) -> Result<(), IdempotencyError>;
/// Atomically release lock on failure (for retryable errors)
async fn release_lock_on_failure(
&self,
key: &str,
user_id: &str,
is_retryable: bool,
response: Option<CachedResponse>,
) -> Result<(), IdempotencyError>;
/// Get a record by key and user_id (for debugging/monitoring)
async fn get(
&self,
key: &str,
user_id: &str,
) -> Result<Option<IdempotencyRecord>, IdempotencyError>;
/// Delete expired records (maintenance operation)
async fn cleanup_expired(&self) -> Result<usize, IdempotencyError>;
/// Execute within a transaction (for stores that support it)
async fn execute_in_transaction<F, T>(&self, f: F) -> Result<T, IdempotencyError>
where
F: FnOnce() -> std::pin::Pin<Box<dyn std::future::Future<Output = Result<T, IdempotencyError>> + Send>> + Send,
T: Send;
}
/// Main idempotency middleware
#[derive(Clone)]
pub struct IdempotencyMiddleware<S: IdempotencyStore + Clone> {
store: S,
ttl: Duration,
lock_timeout: Duration,
}
impl<S: IdempotencyStore + Clone> IdempotencyMiddleware<S> {
pub fn new(store: S) -> Self {
Self {
store,
ttl: Duration::hours(24), // Stripe's 24-hour retention
lock_timeout: Duration::seconds(30), // Max time to hold lock
}
}
pub fn with_config(store: S, ttl: Duration, lock_timeout: Duration) -> Self {
Self {
store,
ttl,
lock_timeout,
}
}
/// Get access to the underlying store (for testing)
#[cfg(test)]
pub fn store(&self) -> &S {
&self.store
}
/// Validate idempotency key format (UUID v4)
fn validate_key(key: &str) -> Result<(), IdempotencyError> {
Uuid::parse_str(key)
.map_err(|_| IdempotencyError::InvalidKeyFormat)?;
Ok(())
}
/// Generate request fingerprint using SHA-256
pub fn generate_fingerprint<T: Serialize>(request: &T) -> String {
let json = serde_json::to_string(request).unwrap_or_default();
let mut hasher = Sha256::new();
hasher.update(json.as_bytes());
format!("{:x}", hasher.finalize())
}
/// Process a request with idempotency guarantees
/// This implements the correct atomic pattern to avoid all race conditions
pub async fn process_request<Req, Res, F, Fut>(
&self,
idempotency_key: Option<String>,
user_id: String,
request_path: String,
request_method: String,
request: &Req,
handler: F,
) -> Result<CachedResponse, IdempotencyError>
where
Req: Serialize,
Res: Serialize,
F: FnOnce() -> Fut,
Fut: std::future::Future<Output = Result<(u16, HashMap<String, String>, Res), IdempotencyError>>,
S: Clone,
{
// Require idempotency key for mutating operations
let key = idempotency_key
.ok_or(IdempotencyError::MissingIdempotencyKey)?;
Self::validate_key(&key)?;
let fingerprint = Self::generate_fingerprint(request);
let now = Utc::now();
// Create the record we want to insert
let record = IdempotencyRecord {
key: key.clone(),
user_id: user_id.clone(),
request_path: request_path.clone(),
request_method: request_method.clone(),
request_fingerprint: fingerprint.clone(),
status: IdempotencyStatus::Pending,
response: None,
created_at: now,
expires_at: now + self.ttl,
locked_until: Some(now + self.lock_timeout),
};
// Step 1: Atomically try to acquire lock
let lock_result = self.store.try_acquire_lock(record).await?;
match lock_result {
LockResult::Acquired => {
// We got the lock - safe to proceed with business logic
tracing::debug!("Lock acquired for key: {}", key);
// Execute business logic
match handler().await {
Ok((status_code, headers, response)) => {
// Success - cache the response
let response_body = serde_json::to_vec(&response)
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
let cached_response = CachedResponse {
status_code,
headers,
body: response_body,
};
// Determine final status based on HTTP status code
let final_status = if status_code >= 500 {
IdempotencyStatus::Failed { is_retryable: true }
} else if status_code >= 400 {
IdempotencyStatus::Failed { is_retryable: false }
} else {
IdempotencyStatus::Completed
};
// Atomically complete the request
self.store.complete_with_response(
&key,
&user_id,
final_status,
Some(cached_response.clone()),
).await?;
tracing::debug!("Request completed successfully for key: {}", key);
Ok(cached_response)
}
Err(e) => {
// Handler failed - determine if retryable
let is_retryable = match &e {
IdempotencyError::StorageError(_) => true,
IdempotencyError::TransactionFailed(_) => true,
IdempotencyError::HandlerFailed(_) => true,
_ => false,
};
// Release lock to allow retry
self.store.release_lock_on_failure(
&key,
&user_id,
is_retryable,
None, // No response to cache for errors
).await?;
tracing::warn!("Handler failed for key: {} - error: {}", key, e);
Err(e)
}
}
}
LockResult::AlreadyCompleted(response) => {
// Request was already processed successfully
tracing::debug!("Returning cached response for key: {}", key);
Ok(response)
}
LockResult::InProgress { retry_after } => {
// Another request is currently processing this key
tracing::debug!("Request in progress for key: {}, retry after: {}s", key, retry_after);
Err(IdempotencyError::RequestInProgress { retry_after })
}
LockResult::KeyReused => {
// Key was reused with different request payload
tracing::warn!("Key reused with different request for key: {}", key);
Err(IdempotencyError::KeyReusedWithDifferentRequest)
}
LockResult::FailedPermanently(response) => {
// Request failed permanently, return cached error
tracing::debug!("Returning cached permanent failure for key: {}", key);
Ok(response)
}
}
}
}
// Storage implementations
pub mod sqlite_store;
#[cfg(feature = "axum-integration")]
pub mod axum_integration;
#[cfg(feature = "grpc")]
pub mod grpc_integration;
// Re-export for convenience
pub use sqlite_store::SqliteIdempotencyStore;
#[cfg(test)]
mod tests;
Storage Backend (src/sqlite_store.rs)
use crate::{
IdempotencyError, IdempotencyRecord, IdempotencyStatus, IdempotencyStore,
CachedResponse, LockResult
};
use async_trait::async_trait;
use chrono::{DateTime, Utc};
use sqlx::{Pool, Sqlite, SqlitePool, Row};
use std::sync::Arc;
use tokio::sync::Mutex;
#[derive(Clone)]
pub struct SqliteIdempotencyStore {
pool: Pool<Sqlite>,
// In-memory lock for the entire store to ensure atomicity
transaction_lock: Arc<Mutex<()>>,
}
impl SqliteIdempotencyStore {
pub async fn new(database_url: &str) -> Result<Self, IdempotencyError> {
let pool = SqlitePool::connect(database_url)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
// Create tables with proper indexes
sqlx::query(
r#"
CREATE TABLE IF NOT EXISTS idempotency_records (
key TEXT NOT NULL,
user_id TEXT NOT NULL,
request_path TEXT NOT NULL,
request_method TEXT NOT NULL,
request_fingerprint TEXT NOT NULL,
status TEXT NOT NULL,
response_status_code INTEGER,
response_headers TEXT,
response_body BLOB,
created_at TEXT NOT NULL,
expires_at TEXT NOT NULL,
locked_until TEXT,
PRIMARY KEY (key, user_id)
);
CREATE INDEX IF NOT EXISTS idx_expires_at ON idempotency_records(expires_at);
CREATE INDEX IF NOT EXISTS idx_user_id ON idempotency_records(user_id);
CREATE INDEX IF NOT EXISTS idx_locked_until ON idempotency_records(locked_until);
"#
)
.execute(&pool)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(Self {
pool,
transaction_lock: Arc::new(Mutex::new(())),
})
}
fn serialize_status(status: &IdempotencyStatus) -> String {
match status {
IdempotencyStatus::Pending => "pending".to_string(),
IdempotencyStatus::Completed => "completed".to_string(),
IdempotencyStatus::Failed { is_retryable } => {
format!("failed:{}", if *is_retryable { "retryable" } else { "permanent" })
}
}
}
fn deserialize_status(status: &str) -> IdempotencyStatus {
match status {
"pending" => IdempotencyStatus::Pending,
"completed" => IdempotencyStatus::Completed,
"failed:retryable" => IdempotencyStatus::Failed { is_retryable: true },
"failed:permanent" => IdempotencyStatus::Failed { is_retryable: false },
_ => IdempotencyStatus::Pending,
}
}
async fn record_from_row(row: &sqlx::sqlite::SqliteRow) -> Result<IdempotencyRecord, IdempotencyError> {
let status_str: String = row.try_get("status")
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
let status = Self::deserialize_status(&status_str);
let response = if let Some(status_code) = row.try_get::<Option<i32>, _>("response_status_code")
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?
{
let headers_json: Option<String> = row.try_get("response_headers")
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
let headers = headers_json
.and_then(|h| serde_json::from_str(&h).ok())
.unwrap_or_default();
let body: Option<Vec<u8>> = row.try_get("response_body")
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Some(CachedResponse {
status_code: status_code as u16,
headers,
body: body.unwrap_or_default(),
})
} else {
None
};
Ok(IdempotencyRecord {
key: row.try_get("key").map_err(|e| IdempotencyError::StorageError(e.to_string()))?,
user_id: row.try_get("user_id").map_err(|e| IdempotencyError::StorageError(e.to_string()))?,
request_path: row.try_get("request_path").map_err(|e| IdempotencyError::StorageError(e.to_string()))?,
request_method: row.try_get("request_method").map_err(|e| IdempotencyError::StorageError(e.to_string()))?,
request_fingerprint: row.try_get("request_fingerprint").map_err(|e| IdempotencyError::StorageError(e.to_string()))?,
status,
response,
created_at: {
let dt_str: String = row.try_get("created_at").map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
DateTime::parse_from_rfc3339(&dt_str)
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?
.with_timezone(&Utc)
},
expires_at: {
let dt_str: String = row.try_get("expires_at").map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
DateTime::parse_from_rfc3339(&dt_str)
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?
.with_timezone(&Utc)
},
locked_until: {
let dt_str: Option<String> = row.try_get("locked_until").map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
dt_str
.and_then(|s| DateTime::parse_from_rfc3339(&s).ok())
.map(|dt| dt.with_timezone(&Utc))
},
})
}
}
#[async_trait]
impl IdempotencyStore for SqliteIdempotencyStore {
/// Atomically attempt to acquire a lock for processing
async fn try_acquire_lock(
&self,
record: IdempotencyRecord,
) -> Result<LockResult, IdempotencyError> {
// Use a global lock to ensure atomicity (in production, rely on DB transactions)
let _lock = self.transaction_lock.lock().await;
let mut tx = self.pool.begin()
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
let now = Utc::now();
// First, check if record exists
let existing_row = sqlx::query(
r#"
SELECT key, user_id, request_path, request_method,
request_fingerprint, status, response_status_code,
response_headers, response_body, created_at,
expires_at, locked_until
FROM idempotency_records
WHERE key = ? AND user_id = ?
"#
)
.bind(&record.key)
.bind(&record.user_id)
.fetch_optional(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
let result = if let Some(row) = existing_row {
let existing = Self::record_from_row(&row).await?;
// Check fingerprint match
if existing.request_fingerprint != record.request_fingerprint {
Ok(LockResult::KeyReused)
} else {
// Check current status and lock
match existing.status {
IdempotencyStatus::Completed => {
if let Some(response) = existing.response {
Ok(LockResult::AlreadyCompleted(response))
} else {
// If completed but no response, need to reprocess
// Update existing record to pending with new lock
sqlx::query(
r#"
UPDATE idempotency_records
SET status = ?, locked_until = ?, created_at = ?
WHERE key = ? AND user_id = ?
"#
)
.bind(Self::serialize_status(&IdempotencyStatus::Pending))
.bind(record.locked_until.map(|dt| dt.to_rfc3339()))
.bind(record.created_at.to_rfc3339())
.bind(&record.key)
.bind(&record.user_id)
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(LockResult::Acquired)
}
}
IdempotencyStatus::Failed { is_retryable: false } => {
if let Some(response) = existing.response {
Ok(LockResult::FailedPermanently(response))
} else {
// If failed but no response, need to reprocess
// Update existing record to pending with new lock
sqlx::query(
r#"
UPDATE idempotency_records
SET status = ?, locked_until = ?, created_at = ?
WHERE key = ? AND user_id = ?
"#
)
.bind(Self::serialize_status(&IdempotencyStatus::Pending))
.bind(record.locked_until.map(|dt| dt.to_rfc3339()))
.bind(record.created_at.to_rfc3339())
.bind(&record.key)
.bind(&record.user_id)
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(LockResult::Acquired)
}
}
IdempotencyStatus::Failed { is_retryable: true } => {
// Allow retry for retryable failures
// Update existing record to pending with new lock
sqlx::query(
r#"
UPDATE idempotency_records
SET status = ?, locked_until = ?, created_at = ?
WHERE key = ? AND user_id = ?
"#
)
.bind(Self::serialize_status(&IdempotencyStatus::Pending))
.bind(record.locked_until.map(|dt| dt.to_rfc3339()))
.bind(record.created_at.to_rfc3339())
.bind(&record.key)
.bind(&record.user_id)
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(LockResult::Acquired)
}
IdempotencyStatus::Pending => {
// Check if lock is still active
if let Some(locked_until) = existing.locked_until {
if locked_until > now {
let retry_after = (locked_until - now).num_seconds() as u64;
Ok(LockResult::InProgress { retry_after })
} else {
// Lock expired, allow reprocessing
// Update existing record to pending with new lock
sqlx::query(
r#"
UPDATE idempotency_records
SET status = ?, locked_until = ?, created_at = ?
WHERE key = ? AND user_id = ?
"#
)
.bind(Self::serialize_status(&IdempotencyStatus::Pending))
.bind(record.locked_until.map(|dt| dt.to_rfc3339()))
.bind(record.created_at.to_rfc3339())
.bind(&record.key)
.bind(&record.user_id)
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(LockResult::Acquired)
}
} else {
// No lock timeout, allow reprocessing
// Update existing record to pending with new lock
sqlx::query(
r#"
UPDATE idempotency_records
SET status = ?, locked_until = ?, created_at = ?
WHERE key = ? AND user_id = ?
"#
)
.bind(Self::serialize_status(&IdempotencyStatus::Pending))
.bind(record.locked_until.map(|dt| dt.to_rfc3339()))
.bind(record.created_at.to_rfc3339())
.bind(&record.key)
.bind(&record.user_id)
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(LockResult::Acquired)
}
}
}
}
} else {
// Insert new record
let status = Self::serialize_status(&record.status);
let headers_json = record.response.as_ref()
.map(|r| serde_json::to_string(&r.headers).unwrap_or_default());
sqlx::query(
r#"
INSERT INTO idempotency_records (
key, user_id, request_path, request_method,
request_fingerprint, status, response_status_code,
response_headers, response_body, created_at,
expires_at, locked_until
) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
"#
)
.bind(&record.key)
.bind(&record.user_id)
.bind(&record.request_path)
.bind(&record.request_method)
.bind(&record.request_fingerprint)
.bind(status)
.bind(record.response.as_ref().map(|r| r.status_code as i32))
.bind(headers_json)
.bind(record.response.as_ref().map(|r| r.body.clone()))
.bind(record.created_at.to_rfc3339())
.bind(record.expires_at.to_rfc3339())
.bind(record.locked_until.map(|dt| dt.to_rfc3339()))
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(LockResult::Acquired)
};
// Handle transaction based on result
match &result {
Ok(LockResult::KeyReused) | Ok(LockResult::InProgress { .. }) => {
// These cases don't modify the database, rollback to be safe
tx.rollback().await.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
}
Ok(LockResult::AlreadyCompleted(_)) | Ok(LockResult::FailedPermanently(_)) => {
// These cases just read data, rollback to be safe
tx.rollback().await.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
}
Ok(LockResult::Acquired) => {
// Successfully acquired lock, commit the changes
tx.commit().await.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
}
Err(_) => {
// Error occurred, rollback
tx.rollback().await.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
}
}
result
}
/// Atomically update record with final result and release lock
async fn complete_with_response(
&self,
key: &str,
user_id: &str,
status: IdempotencyStatus,
response: Option<CachedResponse>,
) -> Result<(), IdempotencyError> {
let _lock = self.transaction_lock.lock().await;
let mut tx = self.pool.begin()
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
let status_str = Self::serialize_status(&status);
let headers_json = response.as_ref()
.map(|r| serde_json::to_string(&r.headers).unwrap_or_default());
sqlx::query(
r#"
UPDATE idempotency_records
SET status = ?,
response_status_code = ?,
response_headers = ?,
response_body = ?,
locked_until = NULL
WHERE key = ? AND user_id = ?
"#
)
.bind(status_str)
.bind(response.as_ref().map(|r| r.status_code as i32))
.bind(headers_json)
.bind(response.as_ref().map(|r| r.body.clone()))
.bind(key)
.bind(user_id)
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
tx.commit().await.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(())
}
/// Atomically release lock on failure
async fn release_lock_on_failure(
&self,
key: &str,
user_id: &str,
is_retryable: bool,
response: Option<CachedResponse>,
) -> Result<(), IdempotencyError> {
let _lock = self.transaction_lock.lock().await;
let mut tx = self.pool.begin()
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
let status = IdempotencyStatus::Failed { is_retryable };
let status_str = Self::serialize_status(&status);
let headers_json = response.as_ref()
.map(|r| serde_json::to_string(&r.headers).unwrap_or_default());
sqlx::query(
r#"
UPDATE idempotency_records
SET status = ?,
response_status_code = ?,
response_headers = ?,
response_body = ?,
locked_until = NULL
WHERE key = ? AND user_id = ?
"#
)
.bind(status_str)
.bind(response.as_ref().map(|r| r.status_code as i32))
.bind(headers_json)
.bind(response.as_ref().map(|r| r.body.clone()))
.bind(key)
.bind(user_id)
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
tx.commit().await.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(())
}
async fn get(
&self,
key: &str,
user_id: &str,
) -> Result<Option<IdempotencyRecord>, IdempotencyError> {
let row = sqlx::query(
r#"
SELECT key, user_id, request_path, request_method,
request_fingerprint, status, response_status_code,
response_headers, response_body, created_at,
expires_at, locked_until
FROM idempotency_records
WHERE key = ? AND user_id = ?
"#
)
.bind(key)
.bind(user_id)
.fetch_optional(&self.pool)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
match row {
Some(row) => Ok(Some(Self::record_from_row(&row).await?)),
None => Ok(None),
}
}
async fn cleanup_expired(&self) -> Result<usize, IdempotencyError> {
let now = Utc::now().to_rfc3339();
let result = sqlx::query(
"DELETE FROM idempotency_records WHERE expires_at < ?"
)
.bind(now)
.execute(&self.pool)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(result.rows_affected() as usize)
}
async fn execute_in_transaction<F, T>(&self, f: F) -> Result<T, IdempotencyError>
where
F: FnOnce() -> std::pin::Pin<Box<dyn std::future::Future<Output = Result<T, IdempotencyError>> + Send>> + Send,
T: Send,
{
let _lock = self.transaction_lock.lock().await;
let tx = self.pool.begin()
.await
.map_err(|e| IdempotencyError::TransactionFailed(e.to_string()))?;
let result = f().await;
match result {
Ok(value) => {
tx.commit().await.map_err(|e| IdempotencyError::TransactionFailed(e.to_string()))?;
Ok(value)
}
Err(e) => {
tx.rollback().await.map_err(|e| IdempotencyError::TransactionFailed(e.to_string()))?;
Err(e)
}
}
}
}
The SDK Solution: Making Idempotency Invisible
While requiring clients to generate and manage idempotency keys is correct, it places a burden on developers. Modern cloud providers solve this by embedding idempotency into their SDKs, making it transparent to developers. AWS automatically generates client tokens:
# AWS SDK automatically handles idempotency
ec2_client = boto3.client('ec2')
# The SDK generates a ClientToken internally
response = ec2_client.run_instances(
ImageId='ami-12345',
MinCount=1,
MaxCount=1,
# No idempotency key needed - SDK handles it
)
# On network failure, the SDK safely retries with the same ClientToken
You can build the same experience. The src/client_sdk.rs file shows how to implement transparent idempotency in a client SDK:
// Users don't need to think about idempotency
let client = IdempotentClient::new("https://api.example.com");
// The SDK handles everything:
// - Generates idempotency key
// - Retries with exponential backoff + jitter
// - Reuses same key for retries
// - Respects rate limits
let order = client.call(
"POST",
"/orders",
&CreateOrderRequest {
symbol: "AAPL",
quantity: 100,
}
).await?;
Industry Lessons
The Hidden Cost
Idempotency failures rarely cause outages, which is why they often go unnoticed until they accumulate into bigger problems. But the cost is real:
Support overhead: Each duplicate transaction generates support tickets
Regulatory risk: Financial duplicate transactions can trigger compliance issues
Data corruption: Inconsistent state that’s expensive to clean up
The False Sense of Security
Most teams implement basic duplicate detection and call it “idempotency.” They check a box on their architecture review and move on. Meanwhile, the race conditions and edge cases silently create problems that surface weeks or months later.
The Operational Reality
Even when implemented correctly, idempotency requires operational discipline:
Regular cleanup of expired records (storage management)
The Bottom Line
True idempotency isn’t about preventing duplicates—it’s about providing a consistent, predictable API that clients can safely retry. The difference between “duplicate detection” and real idempotency is the difference between a system that mostly works and one that always works. After seeing too many production incidents caused by misunderstood idempotency, I hope this guide prevents others from making the same expensive mistakes. The patterns I’ve shown here are battle-tested across multiple companies and handle the edge cases that trip up most implementations.
The complete implementation with a storage backend, framework integrations, and deployment examples is available at github.com/bhatti/idempotency-rs.
Modern distributed systems face a fundamental challenge: how to efficiently schedule and execute thousands of tasks across heterogeneous resources while maximizing throughput, minimizing latency, and ensuring fair resource allocation. This challenge becomes even more complex when dealing with workflows, dependencies, and varying resource requirements. I have written about building Formicary, an open-source distributed orchestration engine before and in this post, I’ll explore task scheduling algorithms for executing background tasks, jobs, and workflows through the lens of Formicary. We’ll examine how theoretical scheduling concepts translate into practical implementations in a production-ready system.
Formicary Architecture Overview
Before diving into scheduling algorithms, let’s understand Formicary’s architecture. The system follows a Leader-Follower pattern with two main components:
The Queen (Leader/Server)
API & UI Controllers: RESTful APIs and web dashboard
Job Scheduler: Leader-elected service that polls for pending jobs
Resource Manager: Tracks available ant workers and their capabilities
Job Supervisor: Orchestrates job execution as a DAG
Executors: Support for Docker, Kubernetes, Shell, HTTP, WebSocket, and custom protocols
Registration System: Workers advertise capabilities via tags and methods
Artifact Management: Handle dependencies and outputs
Key Features Supporting Advanced Scheduling
Formicary includes several features that enable sophisticated scheduling strategies:
Tags & Labels: Route tasks to specific workers based on capabilities
Priority Levels: Jobs can have different priority levels for execution order
Resource Constraints: Define CPU, memory, and storage requirements
Tenant Isolation: Multi-tenant support with quota management
Cron Scheduling: Time-based job scheduling
Concurrent Limits: Control maximum parallel job execution
Dynamic Scaling: Kubernetes-based auto-scaling support
Scheduling Algorithm Decision Flow
Before diving into specific algorithms, let’s visualize how different scheduling strategies route jobs through the system:
Job Execution Lifecycle
Understanding how jobs flow through the system helps illustrate where different scheduling algorithms take effect:
Wait Time Estimation Algorithm
Formicary implements a sophisticated wait time estimation system that helps users understand queue delays and plan accordingly. The algorithm considers multiple factors:
// Simplified wait time calculation
func CalculateWaitTime(jobRequest, queuePosition, historicalStats, availableWorkers) time.Duration {
// 1. Find position in priority-ordered queue
queuePosition := findQueuePosition(jobRequest.Priority, jobRequest.SubmissionTime)
// 2. Calculate jobs ahead in queue (70% of executing jobs assumed near completion)
jobsAhead := queuePosition + int(float64(executingJobs) * 0.7)
// 3. Estimate based on historical average execution time
if historicalAverage > 0 && availableWorkers > 0 {
estimatedWait := time.Duration(float64(jobsAhead) / float64(availableWorkers)) *
time.Duration(historicalAverage) * time.Millisecond
}
// 4. Account for scheduled future execution
if jobRequest.ScheduledAt.After(time.Now()) {
scheduleDiff := time.Until(jobRequest.ScheduledAt)
if scheduleDiff > estimatedWait {
estimatedWait = scheduleDiff
}
}
return estimatedWait
}
Formicary uses JobStatsRegistry to track execution patterns:
type JobStats struct {
SucceededJobsAverage int64 // Average execution time
ExecutingJobs int32 // Currently running
AntsCapacity int // Available worker capacity
AntsAvailable bool // Worker availability status
}
It considers worker availability and capacity constraints:
Calculates minimum available workers across all required task types
Accounts for tag-based routing restrictions
Factors in Kubernetes resource quotas
Formicary orders pending jobs by priority and submission time:
sort.Slice(pendingJobs, func(i, j int) bool {
if job1.Priority == job2.Priority {
return job1.CreatedAt.Before(job2.CreatedAt) // FCFS within priority
}
return job1.Priority > job2.Priority // Higher priority first
})
This estimation helps with:
SLA Management: Predict if jobs will meet deadlines
Capacity Planning: Identify when to scale worker pools
User Experience: Provide realistic wait time expectations
Load Balancing: Route jobs to less congested worker pools
Task Scheduling Algorithms in Practice
Now let’s examine how various scheduling algorithms are implemented or can be achieved in Formicary:
1. First-Come First-Serve (FCFS)
FCFS processes tasks in arrival order using a simple FIFO queue. The algorithm maintains fairness by ensuring no task is starved, but suffers from the “convoy effect” where short jobs wait behind long-running ones. Its characteristics include:
Average waiting time: (sum of waiting times) / number of jobs
Turnaround time: completion_time - arrival_time
No preemption – jobs run to completion
Formicary Implementation: This is Formicary’s default behavior. When jobs are submitted, they’re placed in a PENDING state and processed by the Job Scheduler in submission order.
# Job requests are processed in submission order
job_type: data-processing
description: FCFS example - processed in submission order
tasks:
- task_type: process-data
method: DOCKER
container:
image: python:3.9
script:
- python process_data.py
Pros: Simple, predictable, no starvation Cons: Long-running jobs can block shorter ones, poor average wait times
2. Priority Scheduling
Each job has an assigned priority, with higher priority jobs scheduled first. Priority assignment can be static or dynamic based on various factors. A drawback of of this algorithm is starvation of low-priority jobs but it can be addressed with following techniques:
Aging: Gradually increase priority of waiting jobs
Priority Inversion Protection: Temporary priority boost for resource holders
Fair Share: Ensure each user/tenant gets minimum resource allocation
Formicary Implementation: Jobs support priority levels, and the scheduler considers priority when selecting the next job to execute.
Implementation Details: The Job Scheduler queries pending jobs ordered by priority, ensuring high-priority jobs are scheduled first when resources become available.
3. Multilevel Queues – Tag-Based Routing
This algorithm partitions jobs into separate queues based on characteristics (interactive, batch, system). Each queue can use different scheduling algorithms, with inter-queue scheduling typically using fixed priorities or time slicing. Common queue classification strategies include:
Formicary Implementation: Using tags and labels, we can effectively create multilevel queues by routing different job types to specialized worker pools.
At a mobile security company, I implemented this pattern with three distinct worker pools:
Fast Workers: Preflight analysis (seconds to minutes)
Medium Workers: Static analysis (a few minutes)
Heavy Workers: Dynamic analysis on device farms (multiple minutes to hours)
4. Resource-Aware Scheduling
This algorithm makes scheduling decisions based on current and predicted resource availability (CPU, memory, storage, network). It considers both resource requirements and system capacity to prevent oversubscription:
The Resource Manager tracks worker capabilities and current load, ensuring tasks are only scheduled when adequate resources are available.
5. Matchmaking Scheduler – Affinity-Based Routing
It matches jobs to workers based on capabilities, data locality, and preferences. Uses constraint satisfaction to find optimal job-worker pairings. Matching algorithms include:
Hungarian Algorithm: Optimal assignment for bipartite matching
Market-based: Economic models with bids and auctions
Constraint Satisfaction (Kubernetes/Apache Spark): Match job requirements to worker capabilities
Common locality considerations include:
Data Locality: Schedule jobs where data resides
Network Topology: Minimize network hops and bandwidth usage
Hardware Affinity: GPU jobs to GPU nodes, FPGA workloads to FPGA nodes
Formicary Implementation: Using tags, labels, and Kubernetes affinity rules to achieve data locality and capability matching.
job_type: geo-distributed-processing
description: Process data close to its source
tasks:
- task_type: process-eu-data
method: KUBERNETES
tags: ["eu-region", "gdpr-compliant"]
container:
image: data-processor:latest
affinity:
node_affinity:
required_during_scheduling_ignored_during_execution:
node_selector_terms:
- match_expressions:
- key: "region"
operator: In
values: ["eu-west-1", "eu-central-1"]
- key: "compliance"
operator: In
values: ["gdpr"]
variables:
DATA_REGION: "eu"
COMPLIANCE_MODE: "strict"
In mobile security analysis company, I used matchmaking scheduling to manage physical device farms where each device has unique characteristics. The system implemented two-phase matchmaking: first reserving devices based on requirements like platform (iOS/Android), OS version ranges, device type (phone/tablet), and capabilities (SMS, camera, GPS), then using affinity rules to route jobs to the specific reserved device.
Pros: Optimal resource matching, data locality, flexibility Cons: Complex matching logic, potential for suboptimal assignments under constraints
6. Delay Scheduler – Temporal Control
Delay scheduling deliberately postpones task execution until optimal conditions are met, such as data locality, resource availability, or specific timing requirements. The algorithm balances waiting for better conditions against potential starvation, often using configurable timeout thresholds.
Optimal_Delay = min(Max_Wait_Time, Expected_Benefit_Time)
Where:
- Max_Wait_Time = configured upper bound to prevent starvation
- Expected_Benefit_Time = estimated time until optimal conditions
- Locality_Benefit = (Remote_Cost - Local_Cost) / Transfer_Rate
Common delay strategies include:
Data Locality Delay: Wait for data to become available on local nodes
Resource Availability Delay: Wait for preferred resource types to become free
Temporal Delay: Execute at specific times (off-peak hours, scheduled windows)
Condition-Based Delay: Wait for external system states or events
job_type: gpu-intensive-training
tasks:
- task_type: training
method: KUBERNETES
tags: ["gpu-v100", "high-memory"]
timeout: 6h
# Will delay until specific GPU resources become available
Pros:
Improved data locality and reduced network I/O
Better resource utilization through temporal load balancing
Flexible execution timing for cost optimization
Support for external dependency coordination
Cons:
Increased job latency and scheduling complexity
Risk of starvation without proper timeout mechanisms
Difficulty in predicting optimal delay periods
Potential for cascading delays in dependent workflows
7. Capacity Scheduler – Resource Quotas
Capacity scheduling partitions cluster resources into hierarchical queues with guaranteed minimum capacities and configurable maximum limits. Each queue can elastically use unused capacity from other queues while respecting absolute limits and priority policies.
It ensures proportional resource sharing among users, groups, or tenants over time. Uses techniques like weighted fair queueing and deficit round-robin to achieve long-term fairness while maintaining efficiency. Common metrics include:
Proportional Share (Hadoop Fair Scheduler): Resources allocated based on weights/quotas
Max-Min Fairness (Kubernetes): Maximize minimum allocation across users
Deadline Fairness: Ensure SLA compliance across tenants
Advanced fair sharing includes:
Hierarchical Fair Sharing: Nested user groups and organizations
Dominant Resource Fairness: Fair allocation across multiple resource types
Lottery Scheduling: Probabilistic fairness using tickets
Formicary Implementation: It implements tenant isolation with quota enforcement.
// Formicary's Fair Scheduling based on actual implementation
type FairScheduler struct {
jobStatsRegistry *JobStatsRegistry
serverConfig *ServerConfig
}
func (fs *FairScheduler) CheckFairSchedulingConstraints(request *JobRequest) error {
// Multi-level concurrency checking: Organization ? User ? Job-level
// Level 1: Organization concurrency limits
userExecuting, orgExecuting := fs.jobStatsRegistry.UserOrgExecuting(request)
if orgExecuting >= fs.getMaxConcurrentOrgJobs(request.OrganizationID) {
return fs.delayJobForConcurrencyExceeded(request, "organization", orgExecuting)
}
// Level 2: User concurrency limits
if userExecuting >= fs.getMaxConcurrentUserJobs(request.UserID) {
return fs.delayJobForConcurrencyExceeded(request, "user", userExecuting)
}
// Level 3: Job-type concurrency limits
executionCount := fs.jobStatsRegistry.GetExecutionCount(request.GetUserJobTypeKey())
if executionCount >= request.GetMaxConcurrency() {
return fs.delayJobForConcurrencyExceeded(request, "job-type", int(executionCount))
}
return nil
}
func (fs *FairScheduler) delayJobForConcurrencyExceeded(request *JobRequest, limitType string, currentCount int) error {
// Intelligent delay calculation based on historical data
avgCompletionTime := fs.jobStatsRegistry.GetAverageCompletionTime(request.JobType)
// Dynamic wait factor: 25% of average completion time, bounded between 15-60 seconds
waitFactor := min(max(avgCompletionTime/4, 15*time.Second), 60*time.Second)
// Randomized delay to prevent thundering herd
randomDelay := time.Duration(rand.Intn(int(waitFactor))) + waitFactor
// Reschedule with delay
request.ScheduledAt = time.Now().Add(randomDelay)
// Logarithmic priority degradation (inspired by mobile security company approach)
if request.Priority > 0 {
// Priority degradation: log_e(original_priority), minimum of 1
newPriority := max(1, int(math.Log(float64(request.Priority))))
request.Priority = newPriority
// Allow zero-priority jobs to bypass concurrency limits (emergency valve)
if newPriority <= 0 {
return nil // Allow execution despite limits
}
}
// Update schedule attempts counter with exponential backoff
request.ScheduleAttempts++
return fmt.Errorf("%s concurrency limit exceeded: %d jobs running, rescheduling with %v delay",
limitType, currentCount, randomDelay)
}
// Enhanced concurrency tracking from mobile security company experience
func (fs *FairScheduler) trackConcurrencyMetrics(request *JobRequest) {
// Real-time metrics for monitoring fairness
fs.metricsRegistry.Gauge("org_concurrent_jobs", map[string]string{
"org_id": request.OrganizationID,
"job_type": request.JobType,
})
fs.metricsRegistry.Gauge("user_concurrent_jobs", map[string]string{
"user_id": request.UserID,
"job_type": request.JobType,
})
}
Pros: Prevents monopolization, guarantees minimum service levels Cons: May sacrifice efficiency for fairness, complex weight management
9. Earliest Deadline First (EDF)
Dynamic priority algorithm that assigns highest priority to tasks with earliest deadlines. Optimal for single-processor real-time scheduling if total utilization ? 100%. It uses deadline as the primary scheduling criterion. SJF selects the job with the smallest estimated execution time, minimizing average waiting time.
Schedulability Test: ?(Ci/Ti) ? 1
Where Ci = execution time, Ti = period for periodic tasks
EDF is a dynamic priority scheduling algorithm that assigns highest priority to tasks with the earliest absolute deadlines. It’s provably optimal for single-processor real-time scheduling when total CPU utilization ? 100%, providing maximum schedulability under deadline constraints.
While Formicary does not natively supported, SJF can be approximated using separate queues for different job duration categories:
# Short jobs queue
job_type: quick-validation
tags: ["short-queue"]
estimated_runtime: "5m"
# Long jobs queue
job_type: full-analysis
tags: ["long-queue"]
estimated_runtime: "2h"
Deadline assignment strategies include:
Relative_Deadline = Period (for periodic tasks)
Absolute_Deadline = Arrival_Time + Relative_Deadline
Critical_Instant = Simultaneous release of all tasks
It can also be simulated using priority scheduling combined with deadline-aware job submission:
# Simulated EDF using priority and scheduled execution
job_type: time-critical-analysis
priority: {{.UrgencyScore}} # Calculated based on deadline proximity
scheduled_at: "2024-12-31T23:59:59Z"
timeout: 2h
tasks:
- task_type: urgent-processing
method: KUBERNETES
tags: ["priority-worker"]
Implementation Approach: Calculate priority dynamically based on (current_time - deadline) / estimated_runtime to ensure jobs closer to their deadlines receive higher priority.
Pros: Optimal schedulability, maximum resource utilization, simple algorithm, responsive to urgent tasks Cons: Domino effect failures, requires accurate execution time estimates, poor overload behavior, high context switching overhead
10. Speculative Scheduler
It launches multiple instances of slow-running tasks to reduce tail latency. Uses statistical analysis of execution times to detect stragglers and make speculative execution decisions. Balances resource cost against latency improvement. Algorithms include:
Time-based: Tasks running longer than percentile threshold
Resource-based: Launch backup only if resources available
Pros: Reduces tail latency, improves user experience, fault tolerance Cons: Resource waste, coordination overhead, may not help heterogeneous workloads
Formicary Status: Not implemented, but the system provides foundation through:
Task execution monitoring
Historical performance data collection
Resource availability tracking
Conceptual Implementation:
job_type: speculative-execution
tasks:
- task_type: main-task
method: KUBERNETES
timeout: 30m
speculative_backup:
enabled: true
delay_threshold: "150%" # Start backup if 50% slower than average
resource_threshold: 0.3 # Only if 30%+ resources available
11: Polling and Sensors
Beyond time-based delays, Formicary supports condition-based scheduling through polling sensors that wait for external conditions to be met:
job_type: sensor-job
description: Wait for external conditions before proceeding
tasks:
- task_type: wait-for-resource
method: HTTP_GET
url: https://api.example.com/resource/123
delay_between_retries: 15s
retry: 20 # Poll up to 20 times (5 minutes total)
timeout: 15s
on_exit_code:
"200": process-resource # Success - proceed
"404": EXECUTING # Resource not ready - poll again
"FAILED": FATAL # Server error - abort job
- task_type: process-resource
method: DOCKER
container:
image: data-processor:latest
script:
- echo "Resource is now available, processing..."
The key insight is using EXECUTING as an exit code value, which keeps the task in a polling loop rather than completing or failing.
12. Gang Scheduling
Gang scheduling coordinates simultaneous execution of related tasks that need to communicate or synchronize. Instead of scheduling tasks independently, the system reserves resources for all tasks in a “gang” and schedules them together to avoid partial execution and resource deadlocks. Key principles include:
All-or-Nothing (MPI Applications): Either all tasks in the gang get scheduled or none do
Synchronized Start: Tasks begin execution simultaneously
Resource Reservation (Kubernetes Jobs): Pre-allocate resources for the entire task group
Communication Optimization: Minimize synchronization delays between related tasks
Gang_Size = max(task_count, critical_path_parallelism)
Resource_Requirement = ?(individual_task_resources) for all gang members
Schedulability = available_resources >= Resource_Requirement
Formicary’s Gang Scheduling Implementation: Formicary implements gang scheduling at the job level through its Resource Manager. When a job is scheduled, resources are pre-allocated for ALL tasks before execution begins:
// Core gang scheduling logic from ResourceManager
func (rm *ManagerImpl) doReserveJobResources(
requestID string,
def *types.JobDefinition,
dryRun bool) (reservations map[string]*common.AntReservation, err error) {
reservations = make(map[string]*common.AntReservation)
var alloc *common.AntReservation
// Try to reserve resources for each task
for _, task := range def.Tasks {
alloc, err = rm.doReserve(requestID, task.TaskType, task.Method, task.Tags, dryRun)
if err == nil {
reservations[task.TaskType] = alloc
} else {
if !dryRun {
// ALL-OR-NOTHING: Release all allocations and fail entire job
_ = rm.ReleaseJobResources(requestID)
}
return nil, err
}
}
return reservations, nil
}
Two-Phase Gang Scheduling Process:
Resource Check Phase (Dry Run):
// Check if all job resources are available without allocating
func (rm *ManagerImpl) CheckJobResources(job *types.JobDefinition) ([]*common.AntReservation, error) {
if reservationsByTask, err := rm.doReserveJobResources("", job, true); err != nil {
return nil, err // Gang scheduling not possible
}
// All tasks can be scheduled - proceed to actual reservation
}
Earliest Deadline First: For time-sensitive workflows
Speculative Execution: For fault tolerance and performance
Gang Scheduling: For tightly-coupled parallel jobs
Conclusion
Formicary demonstrates how theoretical scheduling algorithms translate into practical distributed systems. It combines multiple strategies—priority scheduling, resource awareness, fair sharing, and intelligent routing for handling diverse workloads while maintaining predictable performance. The key insight is that real-world schedulers rarely use a single algorithm. Instead, they combine multiple approaches, leveraging the strengths of each for different aspects of the scheduling problem. Tags and labels provide the flexibility to implement sophisticated routing logic, while Kubernetes integration enables resource-aware scheduling at scale.
Whether you’re building CI/CD pipelines, data processing workflows, or ML training systems, understanding these scheduling patterns and their trade-offs is crucial for designing systems that scale efficiently and reliably.
Formicary is open source and available at github.com/bhatti/formicary. Try it out for your next workflow automation project!
In 2007, I wrote about implementing Leslie Lamport’s Byzantine Generals Problem algorithm across several programming languages. At the time, this seemed like an interesting theoretical exercise in distributed computing. I didn’t realize that a year later, Satoshi Nakamoto would publish the Bitcoin whitepaper, introducing a decentralized, Sybil resistant digital currency that solved Byzantine fault tolerance at unprecedented scale.
Nearly two decades later, I’m returning to the Byzantine Generals Problem with the perspective that only hindsight provides. This updated post implements the algorithm in modern languages—Rust, Elixir, and contemporary Erlang.
The Byzantine Generals Problem: A Refresher
The Byzantine Generals Problem, first formalized by Leslie Lamport, addresses a fundamental challenge in distributed computing: how can distributed parties reach consensus when some parties may be unreliable or malicious? For example, imagine several divisions of the Byzantine army camped outside an enemy city, each commanded by a general. The generals must coordinate to either attack or retreat, but they can only communicate by messenger. The challenge: some generals might be traitors who will try to confuse the others by sending conflicting messages. For a solution to work, two conditions must be met:
IC1: All loyal lieutenants obey the same order
IC2: If the commanding general is loyal, then every loyal lieutenant obeys the order he sends
One of the most striking results is that no solution exists with fewer than 3m + 1 generals to handle m traitors. With only three generals, no algorithm can handle even a single traitor.
Why This Matters
When I originally wrote about this problem in 2007, Bitcoin didn’t exist. Satoshi Nakamoto’s whitepaper was published in 2008, and the first Bitcoin block wasn’t mined in 2009. Bitcoin’s proof-of-work consensus mechanism essentially solves the Byzantine Generals Problem in a novel way:
Generals = Miners: Each miner is like a general trying to reach consensus
Orders = Transactions: The “order” is which transactions to include in the next block
Traitors = Malicious Miners: Some miners might try to double-spend or create invalid blocks
Solution = Longest Chain: The network accepts the longest valid chain as truth
Bitcoin’s brilliant insight was using computational work (proof-of-work) as a way to make it economically expensive to be a “traitor.” As long as honest miners control more than 50% of the computing power, the system remains secure.
Modern Applications Beyond Blockchain
The Byzantine Generals Problem isn’t just about cryptocurrency. It’s fundamental to many critical systems:
Aircraft Control Systems: Multiple redundant computers must agree on flight controls
Satellite Networks: Space-based systems need fault tolerance against radiation-induced failures
Missile Defense: Critical decisions must be made reliably even with component failures
Distributed Databases: Systems like Apache Cassandra and MongoDB use Byzantine fault-tolerant algorithms
Container Orchestration: Kubernetes uses etcd, which implements Byzantine fault-tolerant consensus
Central Bank Digital Currencies (CBDCs): Many countries are exploring blockchain-based national currencies
Cross-Border Payments: Systems like Ripple use Byzantine fault-tolerant consensus
Implementation: Modern Languages for a Classic Problem
Let’s implement the Byzantine Generals Problem in three modern languages: Rust, Elixir, and updated Erlang. Each brings different strengths to distributed computing.
Why These Languages?
Rust: Memory safety without garbage collection, excellent for systems programming
Elixir: Built on the Actor model, designed for fault-tolerant distributed systems
Erlang: The original Actor model language, battle-tested in telecom systems
Core Algorithm
We’ll implement the OM(m) algorithm (Oral Messages with m traitors) that works for 3m + 1 or more generals.
Rust Implementation
use std::collections::HashMap;
use std::sync::{Arc, Mutex};
use std::thread;
use std::time::{Duration, Instant};
use tracing::{debug, info};
#[derive(Clone, Debug, PartialEq, Eq, Hash)]
pub enum Value {
Zero,
One,
Retreat, // Default value
}
impl std::fmt::Display for Value {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
match self {
Value::Zero => write!(f, "ZERO"),
Value::One => write!(f, "ONE"),
Value::Retreat => write!(f, "RETREAT"),
}
}
}
#[derive(Clone, Debug)]
pub struct Configuration {
pub source: usize,
pub num_rounds: usize,
pub num_processes: usize,
}
pub struct ByzantineEngine {
config: Configuration,
processes: Vec<Arc<Mutex<Process>>>,
message_count: Arc<Mutex<usize>>,
}
pub struct Process {
id: usize,
config: Configuration,
values: HashMap<String, Value>,
is_faulty: bool,
}
impl Process {
pub fn new(id: usize, config: Configuration) -> Self {
let is_faulty = id == config.source || id == 2; // Configure faulty processes
Process {
id,
config,
values: HashMap::new(),
is_faulty,
}
}
pub fn receive_message(&mut self, path: String, value: Value) {
debug!("Process {} received message: path={}, value={:?}", self.id, path, value);
self.values.insert(path, value);
}
pub fn send_messages(&self, round: usize, processes: &[Arc<Mutex<Process>>],
message_count: Arc<Mutex<usize>>) {
if round == 0 && self.id == self.config.source {
self.send_initial_messages(processes, message_count);
} else if round > 0 {
self.relay_messages(round, processes, message_count);
}
}
fn send_initial_messages(&self, processes: &[Arc<Mutex<Process>>],
message_count: Arc<Mutex<usize>>) {
let base_value = Value::Zero;
for (i, process) in processes.iter().enumerate() {
if i != self.id {
let value = if self.is_faulty {
// Faulty commander sends different values to different processes
if i % 2 == 0 { Value::Zero } else { Value::One }
} else {
base_value.clone()
};
let value_for_log = value.clone(); // Clone for logging
let mut proc = process.lock().unwrap();
proc.receive_message(self.id.to_string(), value);
*message_count.lock().unwrap() += 1;
debug!("Commander {} sent {:?} to process {}", self.id, value_for_log, i);
}
}
}
fn relay_messages(&self, round: usize, processes: &[Arc<Mutex<Process>>],
message_count: Arc<Mutex<usize>>) {
let paths = self.get_paths_for_round(round - 1);
for path in paths {
if let Some(value) = self.values.get(&path) {
let new_value = self.transform_value(value.clone());
let new_path = format!("{}{}", path, self.id);
for (i, process) in processes.iter().enumerate() {
if i != self.id && !self.path_contains_process(&new_path, i) {
let mut proc = process.lock().unwrap();
proc.receive_message(new_path.clone(), new_value.clone());
*message_count.lock().unwrap() += 1;
debug!("Process {} relayed {:?} to process {} with path {}",
self.id, new_value, i, new_path);
}
}
}
}
}
fn transform_value(&self, value: Value) -> Value {
if self.is_faulty && self.id == 2 {
Value::One // Process 2 always sends One when faulty
} else {
value
}
}
fn get_paths_for_round(&self, round: usize) -> Vec<String> {
if round == 0 {
vec![self.config.source.to_string()]
} else {
self.values.keys()
.filter(|path| path.len() == round + 1)
.cloned()
.collect()
}
}
fn path_contains_process(&self, path: &str, process_id: usize) -> bool {
path.contains(&process_id.to_string())
}
pub fn decide(&self) -> Value {
if self.id == self.config.source {
// Source process uses its own value
return if self.is_faulty { Value::One } else { Value::Zero };
}
self.majority_vote()
}
fn majority_vote(&self) -> Value {
let mut counts = HashMap::new();
counts.insert(Value::Zero, 0);
counts.insert(Value::One, 0);
counts.insert(Value::Retreat, 0);
// Count values from the final round paths
let final_paths: Vec<_> = self.values.keys()
.filter(|path| path.len() == self.config.num_rounds + 1)
.collect();
if final_paths.is_empty() {
// Count all available values if no final round paths
for value in self.values.values() {
*counts.entry(value.clone()).or_insert(0) += 1;
}
} else {
for path in final_paths {
if let Some(value) = self.values.get(path) {
*counts.entry(value.clone()).or_insert(0) += 1;
}
}
}
debug!("Process {} vote counts: {:?}", self.id, counts);
// Find majority
let total_votes: usize = counts.values().sum();
if total_votes == 0 {
return Value::Retreat;
}
let majority_threshold = total_votes / 2;
for (value, count) in counts {
if count > majority_threshold {
return value;
}
}
Value::Retreat // Default if no majority
}
pub fn is_faulty(&self) -> bool {
self.is_faulty
}
pub fn is_source(&self) -> bool {
self.id == self.config.source
}
}
impl ByzantineEngine {
pub fn new(source: usize, num_rounds: usize, num_processes: usize) -> Self {
let config = Configuration { source, num_rounds, num_processes };
let processes: Vec<Arc<Mutex<Process>>> = (0..num_processes)
.map(|id| Arc::new(Mutex::new(Process::new(id, config.clone()))))
.collect();
ByzantineEngine {
config,
processes,
message_count: Arc::new(Mutex::new(0)),
}
}
pub fn run(&self) -> (Duration, usize) {
info!("Starting Byzantine Generals algorithm with {} processes, {} rounds",
self.config.num_processes, self.config.num_rounds);
let start = Instant::now();
for round in 0..self.config.num_rounds {
debug!("Starting round {}", round);
let handles: Vec<_> = self.processes.iter().enumerate().map(|(_id, process)| {
let process = Arc::clone(process);
let processes = self.processes.clone();
let message_count = Arc::clone(&self.message_count);
thread::spawn(move || {
let proc = process.lock().unwrap();
proc.send_messages(round, &processes, message_count);
})
}).collect();
for handle in handles {
// Add timeout to prevent hanging
if handle.join().is_err() {
eprintln!("Warning: Thread failed in round {}", round);
}
}
debug!("Completed round {}", round);
// Small delay to ensure message ordering
thread::sleep(Duration::from_millis(10));
}
let duration = start.elapsed();
let messages = *self.message_count.lock().unwrap();
info!("Algorithm completed in {:.2}ms with {} messages",
duration.as_millis(), messages);
self.print_results();
(duration, messages)
}
fn print_results(&self) {
println!("\nByzantine Generals Results:");
println!("===========================");
for (id, process) in self.processes.iter().enumerate() {
let proc = process.lock().unwrap();
if proc.is_source() {
print!("Source ");
}
print!("Process {}", id);
if proc.is_faulty() {
println!(" is faulty");
} else {
println!(" decides on value {}", proc.decide());
}
}
println!();
}
}
pub fn benchmark_comprehensive(max_processes: usize) {
let test_cases = generate_test_cases(max_processes);
for (processes, rounds) in test_cases {
if processes < 4 {
continue; // Skip invalid cases
}
let source = processes / 3;
let engine = ByzantineEngine::new(source, rounds, processes);
let start_memory = get_memory_usage();
let start = Instant::now();
let (duration, messages) = engine.run();
let _total_duration = start.elapsed();
let end_memory = get_memory_usage();
let memory_used = end_memory.saturating_sub(start_memory);
println!("Rust,{},{},{},{:.2},{:.2}",
processes, rounds, messages,
duration.as_millis(), memory_used as f64 / 1024.0 / 1024.0);
}
}
fn generate_test_cases(max_processes: usize) -> Vec<(usize, usize)> {
let mut cases = Vec::new();
for n in (4..=max_processes).step_by(3) {
for m in 1..=3 {
if 3 * m + 1 <= n {
cases.push((n, m));
}
}
}
cases
}
fn get_memory_usage() -> usize {
// Simplified memory usage - would need platform-specific code for accurate measurement
std::process::id() as usize * 1024 // Placeholder
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_value_display() {
assert_eq!(format!("{}", Value::Zero), "ZERO");
assert_eq!(format!("{}", Value::One), "ONE");
assert_eq!(format!("{}", Value::Retreat), "RETREAT");
}
#[test]
fn test_process_creation() {
let config = Configuration {
source: 0,
num_rounds: 2,
num_processes: 4,
};
let process = Process::new(0, config.clone());
assert!(process.is_source());
assert!(process.is_faulty()); // Source is faulty in our test setup
let process2 = Process::new(1, config);
assert!(!process2.is_source());
assert!(!process2.is_faulty());
}
#[test]
fn test_engine_creation() {
let engine = ByzantineEngine::new(0, 2, 4);
assert_eq!(engine.config.source, 0);
assert_eq!(engine.config.num_rounds, 2);
assert_eq!(engine.config.num_processes, 4);
assert_eq!(engine.processes.len(), 4);
}
#[test]
fn test_minimum_byzantine_case() {
let engine = ByzantineEngine::new(0, 1, 4);
let (duration, messages) = engine.run();
assert!(duration.as_nanos() > 0);
assert!(messages > 0);
}
}
Elixir Implementation
defmodule ByzantineGenerals do
@moduledoc """
Byzantine Generals Problem implementation in Elixir
Leverages the Actor model for natural distributed computing
"""
require Logger
defmodule Configuration do
@moduledoc "Configuration for Byzantine Generals algorithm"
defstruct [:source, :num_rounds, :num_processes]
@type t :: %__MODULE__{
source: non_neg_integer(),
num_rounds: non_neg_integer(),
num_processes: non_neg_integer()
}
end
defmodule Process do
@moduledoc "Individual process (general) in the Byzantine Generals algorithm"
use GenServer
require Logger
defstruct [:id, :config, :values, :is_faulty, :message_count, :processes]
@type value :: :zero | :one | :retreat
@type path :: String.t()
# Client API
def start_link(%{id: id, config: config}) do
GenServer.start_link(__MODULE__, %{id: id, config: config}, name: :"process_#{id}")
end
def receive_message(pid, path, value) do
GenServer.call(pid, {:receive_message, path, value}, 10_000)
end
def send_messages(pid, round, processes) do
GenServer.call(pid, {:send_messages, round, processes}, 10_000)
end
def decide(pid) do
GenServer.call(pid, :decide, 5_000)
end
def is_faulty?(pid) do
GenServer.call(pid, :is_faulty, 1_000)
end
def is_source?(pid) do
GenServer.call(pid, :is_source, 1_000)
end
def get_message_count(pid) do
GenServer.call(pid, :get_message_count, 1_000)
end
def get_values(pid) do
GenServer.call(pid, :get_values, 1_000)
end
# Server callbacks
@impl true
def init(%{id: id, config: config}) do
is_faulty = id == config.source || id == 2
state = %__MODULE__{
id: id,
config: config,
values: %{},
is_faulty: is_faulty,
message_count: 0,
processes: []
}
Logger.debug("Process #{id} initialized, faulty: #{is_faulty}")
{:ok, state}
end
@impl true
def handle_call({:receive_message, path, value}, _from, state) do
Logger.debug("Process #{state.id} received message: path=#{path}, value=#{value}")
new_values = Map.put(state.values, path, value)
new_count = state.message_count + 1
{:reply, :ok, %{state | values: new_values, message_count: new_count}}
end
@impl true
def handle_call({:send_messages, round, processes}, _from, state) do
new_state = %{state | processes: processes}
cond do
round == 0 && state.id == state.config.source ->
send_initial_messages(new_state)
round > 0 ->
relay_messages(new_state, round)
true ->
{:reply, :ok, new_state}
end
end
@impl true
def handle_call(:decide, _from, state) do
decision = if state.id == state.config.source do
# Source process uses its own value
if state.is_faulty, do: :one, else: :zero
else
majority_vote(state)
end
{:reply, decision, state}
end
@impl true
def handle_call(:is_faulty, _from, state) do
{:reply, state.is_faulty, state}
end
@impl true
def handle_call(:is_source, _from, state) do
{:reply, state.id == state.config.source, state}
end
@impl true
def handle_call(:get_message_count, _from, state) do
{:reply, state.message_count, state}
end
@impl true
def handle_call(:get_values, _from, state) do
{:reply, state.values, state}
end
# Private functions
defp send_initial_messages(state) do
base_value = :zero
Enum.each(state.processes, fn {id, pid} ->
if id != state.id do
value = if state.is_faulty do
# Faulty commander sends different values
if rem(id, 2) == 0, do: :zero, else: :one
else
base_value
end
receive_message(pid, Integer.to_string(state.id), value)
Logger.debug("Commander #{state.id} sent #{value} to process #{id}")
end
end)
{:reply, :ok, state}
end
defp relay_messages(state, round) do
paths = get_paths_for_round(state, round - 1)
Enum.each(paths, fn path ->
case Map.get(state.values, path) do
nil ->
:ok
value ->
new_value = transform_value(state, value)
new_path = path <> Integer.to_string(state.id)
Enum.each(state.processes, fn {id, pid} ->
if id != state.id && !String.contains?(new_path, Integer.to_string(id)) do
receive_message(pid, new_path, new_value)
Logger.debug("Process #{state.id} relayed #{new_value} to #{id}, path: #{new_path}")
end
end)
end
end)
{:reply, :ok, state}
end
defp transform_value(state, value) do
if state.is_faulty && state.id == 2 do
:one
else
value
end
end
defp get_paths_for_round(state, round) do
if round == 0 do
[Integer.to_string(state.config.source)]
else
state.values
|> Map.keys()
|> Enum.filter(&(String.length(&1) == round + 1))
end
end
defp majority_vote(state) do
counts = Enum.reduce(state.values, %{zero: 0, one: 0, retreat: 0}, fn {_path, value}, acc ->
Map.update!(acc, value, &(&1 + 1))
end)
Logger.debug("Process #{state.id} vote counts: #{inspect(counts)}")
total_votes = Map.values(counts) |> Enum.sum()
if total_votes == 0 do
:retreat
else
majority_threshold = div(total_votes, 2)
case Enum.find(counts, fn {_value, count} -> count > majority_threshold end) do
{value, _count} -> value
nil -> :retreat
end
end
end
end
defmodule Engine do
@moduledoc "Engine that orchestrates the Byzantine Generals algorithm"
require Logger
def run(source, num_rounds, num_processes, opts \\ []) do
config = %Configuration{
source: source,
num_rounds: num_rounds,
num_processes: num_processes
}
verbose = Keyword.get(opts, :verbose, true)
if verbose do
Logger.info("Starting Byzantine Generals: #{num_processes} processes, #{num_rounds} rounds, source: #{source}")
end
# Start processes
processes = start_processes(config)
start_time = :os.system_time(:millisecond)
# Run algorithm rounds
run_rounds(processes, num_rounds)
end_time = :os.system_time(:millisecond)
duration = end_time - start_time
# Collect results
{results, total_messages} = collect_results(processes, config, verbose)
# Clean up
cleanup_processes(processes)
{duration, total_messages, results}
end
defp start_processes(config) do
for id <- 0..(config.num_processes - 1) do
{:ok, pid} = Process.start_link(%{id: id, config: config})
{id, pid}
end
end
defp run_rounds(processes, num_rounds, timeout \\ 30_000) do
for round <- 0..(num_rounds - 1) do
Logger.debug("Starting round #{round}")
tasks = Enum.map(processes, fn {_id, pid} ->
Task.async(fn ->
Process.send_messages(pid, round, processes)
end)
end)
try do
Task.await_many(tasks, timeout)
# Small delay to ensure message ordering
:timer.sleep(10)
catch
:exit, {:timeout, _} ->
Logger.error("Round #{round} timed out")
throw(:timeout)
end
end
:ok
end
defp collect_results(processes, _config, verbose) do
total_messages = Enum.sum(Enum.map(processes, fn {_id, pid} ->
Process.get_message_count(pid)
end))
results = Enum.map(processes, fn {id, pid} ->
is_source = Process.is_source?(pid)
is_faulty = Process.is_faulty?(pid)
decision = if is_faulty, do: nil, else: Process.decide(pid)
result = %{
id: id,
is_source: is_source,
is_faulty: is_faulty,
decision: decision
}
if verbose do
print_process_result(result)
end
result
end)
{results, total_messages}
end
defp print_process_result(%{id: id, is_source: is_source, is_faulty: is_faulty, decision: decision}) do
prefix = if is_source, do: "Source ", else: ""
if is_faulty do
IO.puts("#{prefix}Process #{id} is faulty")
else
IO.puts("#{prefix}Process #{id} decides on value #{decision}")
end
end
defp cleanup_processes(processes) do
Enum.each(processes, fn {_id, pid} ->
GenServer.stop(pid, :normal, 1000)
end)
end
def benchmark(max_processes, opts \\ []) do
verbose = Keyword.get(opts, :verbose, true)
if verbose do
IO.puts("Elixir Byzantine Generals Benchmark")
IO.puts("===================================")
IO.puts("Language,Processes,Rounds,Messages,Time(ms)")
end
test_cases = generate_test_cases(max_processes)
results = Enum.map(test_cases, fn {processes, rounds} ->
source = div(processes, 3)
{time, messages, _results} = run(source, rounds, processes, verbose: false)
result = %{
language: "Elixir",
processes: processes,
rounds: rounds,
messages: messages,
time_ms: time
}
if verbose do
IO.puts("Elixir,#{processes},#{rounds},#{messages},#{time}")
end
result
end)
results
end
defp generate_test_cases(max_processes) do
for n <- 4..max_processes, rem(n - 1, 3) == 0 do
for m <- 1..3, 3 * m + 1 <= n do
{n, m}
end
end
|> List.flatten()
end
end
# Main module functions
def run(source, num_rounds, num_processes, opts \\ []) do
Engine.run(source, num_rounds, num_processes, opts)
end
def benchmark(max_processes \\ 20, opts \\ []) do
Engine.benchmark(max_processes, opts)
end
def quick_test do
IO.puts("Running quick test with 4 processes, 1 round...")
{time, messages, results} = run(0, 1, 4)
IO.puts("\nTest Results:")
IO.puts("Time: #{time}ms")
IO.puts("Messages: #{messages}")
IO.puts("Processes reached consensus: #{length(results)}")
IO.puts("? Test completed successfully")
:ok
end
end
defmodule ByzantineGenerals.Application do
@moduledoc false
use Application
@impl true
def start(_type, _args) do
children = [
# Add supervised processes here if needed
]
opts = [strategy: :one_for_one, name: ByzantineGenerals.Supervisor]
Supervisor.start_link(children, opts)
end
end
Testing Erlang Implementation
-module(byzantine_generals).
-export([run/3, benchmark/1, quick_test/0, start/0, stop/0]).
-include_lib("kernel/include/logger.hrl").
-record(config, {source, num_rounds, num_processes}).
-record(process_state, {id, config, values, is_faulty, message_count, processes}).
%% Public API
%% Start the application
start() ->
application:start(byzantine_generals).
%% Stop the application
stop() ->
application:stop(byzantine_generals).
%% Run the Byzantine Generals algorithm
run(Source, NumRounds, NumProcesses) ->
?LOG_INFO("Starting Byzantine Generals: ~p processes, ~p rounds, source: ~p",
[NumProcesses, NumRounds, Source]),
Config = #config{source = Source, num_rounds = NumRounds, num_processes = NumProcesses},
% Validate configuration
case validate_config(Config) of
ok ->
run_algorithm(Config);
{error, Reason} ->
?LOG_ERROR("Invalid configuration: ~p", [Reason]),
{error, Reason}
end.
%% Run benchmark with different configurations
benchmark(MaxProcesses) ->
?LOG_INFO("Running Erlang Byzantine Generals Benchmark up to ~p processes", [MaxProcesses]),
io:format("Erlang Byzantine Generals Benchmark~n"),
io:format("===================================~n"),
io:format("Language,Processes,Rounds,Messages,Time(ms)~n"),
TestCases = generate_test_cases(MaxProcesses),
Results = lists:map(fun({Processes, Rounds}) ->
Source = Processes div 3,
case run(Source, Rounds, Processes) of
{ok, Time, Messages, _ProcessResults} ->
io:format("Erlang,~p,~p,~p,~p~n", [Processes, Rounds, Messages, Time]),
#{language => erlang, processes => Processes, rounds => Rounds,
messages => Messages, time_ms => Time};
{error, _Reason} ->
#{error => true, processes => Processes, rounds => Rounds}
end
end, TestCases),
Results.
%% Quick test function
quick_test() ->
io:format("Running quick test with 4 processes, 1 round...~n"),
case run(0, 1, 4) of
{ok, Time, Messages, _Results} ->
io:format("~nTest Results:~n"),
io:format("Time: ~pms~n", [Time]),
io:format("Messages: ~p~n", [Messages]),
io:format("? Test completed successfully~n"),
ok;
{error, Reason} ->
io:format("? Test failed: ~p~n", [Reason]),
error
end.
%% Internal functions
validate_config(#config{source = Source, num_rounds = NumRounds, num_processes = NumProcesses}) ->
if
NumProcesses < 4 ->
{error, "Need at least 4 processes for Byzantine Generals Problem"};
Source >= NumProcesses ->
{error, "Source must be less than number of processes"};
NumRounds < 1 ->
{error, "Need at least 1 round"};
true ->
ok
end.
run_algorithm(Config) ->
% Start message counter
CounterPid = spawn_link(fun() -> counter_loop(0) end),
register(message_counter, CounterPid),
StartTime = erlang:system_time(millisecond),
try
% Start processes
ProcessPids = start_processes(Config),
% Initialize processes with neighbor information
initialize_processes(ProcessPids, Config),
% Run algorithm rounds
run_rounds(ProcessPids, Config),
% Wait for completion
timer:sleep(100),
EndTime = erlang:system_time(millisecond),
Duration = EndTime - StartTime,
% Collect results
{TotalMessages, ProcessResults} = collect_results(ProcessPids, Config),
% Cleanup
cleanup_processes(ProcessPids),
unregister(message_counter),
exit(CounterPid, normal),
{ok, Duration, TotalMessages, ProcessResults}
catch
Class:Reason:Stacktrace ->
?LOG_ERROR("Algorithm failed: ~p:~p~n~p", [Class, Reason, Stacktrace]),
% Cleanup on error
catch unregister(message_counter),
catch exit(CounterPid, kill),
{error, {Class, Reason}}
end.
start_processes(Config) ->
NumProcesses = Config#config.num_processes,
lists:map(fun(Id) ->
Pid = spawn_link(fun() -> process_loop(Id, Config) end),
{Id, Pid}
end, lists:seq(0, NumProcesses - 1)).
initialize_processes(ProcessPids, Config) ->
lists:foreach(fun({_Id, Pid}) ->
Pid ! {init, ProcessPids, Config}
end, ProcessPids).
run_rounds(ProcessPids, Config) ->
NumRounds = Config#config.num_rounds,
lists:foreach(fun(Round) ->
?LOG_DEBUG("Starting round ~p", [Round]),
% Send messages for this round
lists:foreach(fun({_Id, Pid}) ->
Pid ! {send_messages, Round, self()}
end, ProcessPids),
% Wait for all processes to complete the round
lists:foreach(fun({_Id, _Pid}) ->
receive
{round_complete, Round} -> ok
after 5000 ->
?LOG_WARNING("Timeout waiting for round ~p completion", [Round])
end
end, ProcessPids),
% Small delay between rounds
timer:sleep(10)
end, lists:seq(0, NumRounds - 1)).
collect_results(ProcessPids, Config) ->
% Get total message count
TotalMessages = get_message_count(),
% Get process results
ProcessResults = lists:map(fun({Id, Pid}) ->
Pid ! {get_result, self()},
receive
{result, Id, Result} ->
print_process_result(Id, Result, Config#config.source),
Result
after 2000 ->
?LOG_WARNING("Timeout getting result from process ~p", [Id]),
#{id => Id, error => timeout}
end
end, ProcessPids),
{TotalMessages, ProcessResults}.
print_process_result(Id, Result, Source) ->
Prefix = case Id of
Source -> "Source ";
_ -> ""
end,
case maps:get(is_faulty, Result, false) of
true ->
io:format("~sProcess ~p is faulty~n", [Prefix, Id]);
false ->
Decision = maps:get(decision, Result, retreat),
io:format("~sProcess ~p decides on value ~p~n", [Prefix, Id, Decision])
end.
cleanup_processes(ProcessPids) ->
lists:foreach(fun({_Id, Pid}) ->
Pid ! stop,
% Don't wait for exit - let them clean up
ok
end, ProcessPids).
generate_test_cases(MaxProcesses) ->
lists:flatten([
[{N, M} || M <- lists:seq(1, 3), 3 * M + 1 =< N]
|| N <- lists:seq(4, MaxProcesses, 3)
]).
%% Process implementation
process_loop(Id, Config) ->
IsFaulty = (Id =:= Config#config.source) orelse (Id =:= 2),
State = #process_state{
id = Id,
config = Config,
values = #{},
is_faulty = IsFaulty,
message_count = 0,
processes = []
},
?LOG_DEBUG("Process ~p initialized, faulty: ~p", [Id, IsFaulty]),
process_loop(State).
process_loop(State) ->
receive
{init, ProcessPids, Config} ->
NewState = State#process_state{processes = ProcessPids, config = Config},
process_loop(NewState);
{receive_message, Path, Value} ->
NewValues = maps:put(Path, Value, State#process_state.values),
NewState = State#process_state{
values = NewValues,
message_count = State#process_state.message_count + 1
},
increment_message_count(),
?LOG_DEBUG("Process ~p received message: path=~s, value=~p",
[State#process_state.id, Path, Value]),
process_loop(NewState);
{send_messages, Round, From} ->
NewState = handle_send_messages(State, Round),
From ! {round_complete, Round},
process_loop(NewState);
{get_result, From} ->
Result = create_result(State),
From ! {result, State#process_state.id, Result},
process_loop(State);
stop ->
?LOG_DEBUG("Process ~p stopping", [State#process_state.id]),
ok;
Other ->
?LOG_WARNING("Process ~p received unexpected message: ~p",
[State#process_state.id, Other]),
process_loop(State)
end.
handle_send_messages(State, Round) ->
Id = State#process_state.id,
Config = State#process_state.config,
if
Round =:= 0 andalso Id =:= Config#config.source ->
send_initial_messages(State);
Round > 0 ->
relay_messages(State, Round);
true ->
State
end.
send_initial_messages(State) ->
BaseValue = zero,
ProcessPids = State#process_state.processes,
lists:foreach(fun({Id, Pid}) ->
if Id =/= State#process_state.id ->
Value = case State#process_state.is_faulty of
true ->
% Faulty commander sends different values
case Id rem 2 of
0 -> zero;
1 -> one
end;
false ->
BaseValue
end,
Pid ! {receive_message, integer_to_list(State#process_state.id), Value},
?LOG_DEBUG("Commander ~p sent ~p to process ~p",
[State#process_state.id, Value, Id]);
true ->
ok
end
end, ProcessPids),
State.
relay_messages(State, Round) ->
Paths = get_paths_for_round(State, Round - 1),
ProcessPids = State#process_state.processes,
lists:foreach(fun(Path) ->
case maps:get(Path, State#process_state.values, undefined) of
undefined ->
ok;
Value ->
NewValue = transform_value(State, Value),
NewPath = Path ++ integer_to_list(State#process_state.id),
lists:foreach(fun({Id, Pid}) ->
IdStr = integer_to_list(Id),
case Id =/= State#process_state.id of
true ->
case string:str(NewPath, IdStr) of
0 -> % IdStr not found in NewPath
Pid ! {receive_message, NewPath, NewValue},
?LOG_DEBUG("Process ~p relayed ~p to ~p, path: ~s",
[State#process_state.id, NewValue, Id, NewPath]);
_ -> % IdStr found in NewPath, skip
ok
end;
false -> % Same process, skip
ok
end
end, ProcessPids)
end
end, Paths),
State.
transform_value(State, Value) ->
if State#process_state.is_faulty andalso State#process_state.id =:= 2 ->
one;
true ->
Value
end.
get_paths_for_round(State, Round) ->
if Round =:= 0 ->
[integer_to_list((State#process_state.config)#config.source)];
true ->
maps:fold(fun(Path, _Value, Acc) ->
case length(Path) of
Len when Len =:= Round + 1 -> [Path | Acc];
_ -> Acc
end
end, [], State#process_state.values)
end.
create_result(State) ->
Decision = if State#process_state.id =:= (State#process_state.config)#config.source ->
% Source process uses its own value
case State#process_state.is_faulty of
true -> one;
false -> zero
end;
true ->
majority_vote(State)
end,
#{
id => State#process_state.id,
is_source => State#process_state.id =:= (State#process_state.config)#config.source,
is_faulty => State#process_state.is_faulty,
decision => Decision,
message_count => State#process_state.message_count
}.
majority_vote(State) ->
Values = maps:values(State#process_state.values),
Counts = lists:foldl(fun(Value, Acc) ->
maps:update_with(Value, fun(Count) -> Count + 1 end, 1, Acc)
end, #{zero => 0, one => 0, retreat => 0}, Values),
?LOG_DEBUG("Process ~p vote counts: ~p", [State#process_state.id, Counts]),
TotalVotes = maps:fold(fun(_Value, Count, Sum) -> Sum + Count end, 0, Counts),
if TotalVotes =:= 0 ->
retreat;
true ->
MajorityThreshold = TotalVotes div 2,
case maps:fold(fun(Value, Count, Acc) ->
if Count > MajorityThreshold -> Value;
true -> Acc
end
end, retreat, Counts) of
retreat -> retreat;
Value -> Value
end
end.
%% Message counter implementation
counter_loop(Count) ->
receive
increment ->
counter_loop(Count + 1);
{get_count, From} ->
From ! {count, Count},
counter_loop(Count);
reset ->
counter_loop(0);
stop ->
ok;
_ ->
counter_loop(Count)
end.
increment_message_count() ->
case whereis(message_counter) of
undefined -> ok;
Pid -> Pid ! increment
end.
get_message_count() ->
case whereis(message_counter) of
undefined -> 0;
Pid ->
Pid ! {get_count, self()},
receive
{count, Count} -> Count
after 1000 -> 0
end
end.
Performance Analysis and Benchmarking
To properly benchmark these implementations, we need to consider several factors:
Metrics to Measure
Execution Time: How long does the algorithm take?
Message Count: How many messages are exchanged?
Memory Usage: Peak memory consumption
Scalability: How performance degrades with increasing generals
CPU Utilization: How efficiently the languages use system resources
Modern Benchmarking Approach
// Example comprehensive benchmark
pub struct BenchmarkResults {
pub language: String,
pub num_processes: usize,
pub num_rounds: usize,
pub execution_time_ms: f64,
pub messages_sent: usize,
pub memory_peak_mb: f64,
pub cpu_utilization: f64,
}
pub fn comprehensive_benchmark() {
let test_cases = vec![
(4, 1), // Minimum viable case
(7, 2), // Small scale
(10, 3), // Medium scale
(16, 5), // Larger scale
];
for (processes, rounds) in test_cases {
// Rust benchmark
let rust_result = benchmark_rust_detailed(processes, rounds);
// Elixir benchmark (would call via Port)
let elixir_result = benchmark_elixir_detailed(processes, rounds);
// Erlang benchmark (would call via Port)
let erlang_result = benchmark_erlang_detailed(processes, rounds);
compare_results(vec![rust_result, elixir_result, erlang_result]);
}
}
Real-World Implications
The performance characteristics matter significantly in different contexts:
Blockchain Applications
Latency-Critical: Rust’s performance advantage matters for high-frequency trading
Node Count: Elixir/Erlang’s superior scaling helps with large blockchain networks
Fault Tolerance: Actor model languages excel at handling network partitions
IoT and Edge Computing
Resource Constraints: Rust’s low memory footprint is crucial
Device Coordination: Byzantine fault tolerance becomes critical for autonomous systems
Financial Systems
Regulatory Requirements: Provable consensus algorithms are increasingly required
High Availability: Erlang’s fault tolerance model aligns with financial system needs
Future Directions
Looking ahead, several trends will likely shape how we think about Byzantine fault tolerance:
Quantum Computing: Post-quantum cryptography will change how we implement Byzantine fault-tolerant signatures and may require new consensus mechanisms.
Climate Considerations: Energy-efficient consensus mechanisms (like Proof of Stake) are becoming increasingly important as environmental concerns grow.
Regulatory Frameworks: Government regulations around cryptocurrencies and distributed systems may influence which Byzantine fault-tolerant algorithms are acceptable in different contexts.
Edge and IoT: As computing moves to the edge, Byzantine fault tolerance becomes crucial for coordinating potentially millions of small, unreliable devices.
Performance Analysis
To compare the implementations, I measured complete wall-clock execution time including language runtime startup and algorithm execution across different process counts (10 to 2000 processes) with 1 round each. Each configuration was tested 3 times to ensure consistency. These benchmarks focus on demonstrating algorithmic correctness and relative performance characteristics rather than highly optimized production implementations.
Erlang showed significantly higher execution times but maintained reliability across all test configurations
Message counts remained consistent across languages for equivalent configurations, confirming algorithmic correctness
The results show that as process count increases from 10 to 2000:
Elixir scales relatively well, with execution time increasing by ~45%
Rust shows similar scaling characteristics, with ~24% increase
Erlang maintains consistent performance overhead regardless of scale
Note: These benchmarks measure wall-clock time including runtime startup overhead. The performance differences may be influenced by implementation patterns (GenServer vs raw message passing) and language-specific optimizations rather than fundamental runtime capabilities.
# Clone and run benchmarks
git clone https://github.com/bhatti/byz-sample
cd byz-sample
make benchmark
Disclaimer: Above implementation of the Byzantine Generals Problem serves as a case study for evaluating distributed computing approaches across different programming paradigms rather than benchmarking specific implementations in these languages.
Conclusion
The Byzantine Generals Problem exemplifies how fundamental computer science research can unexpectedly become the foundation for revolutionary technology. What began as an abstract theoretical exercise in 1982 became the backbone of Bitcoin in 2008 and continues to be crucial for modern distributed systems. My 2007 exploration of this problem was motivated by curiosity about distributed computing and language performance. Today, understanding Byzantine fault tolerance is essential for anyone working with blockchain technology, distributed databases, or fault-tolerant systems.
In my previous blog of the Adaptive Object Model (AOM) pattern, I focused on dynamic schema evolution and metadata-driven architectures. However, there’s a complementary pattern that addresses a different but equally important challenge: how to compose behavior dynamically at runtime without modifying existing objects. I first saw this pattern in Voyager ORB’s “Dynamic Aggregation” and San Francisco Design Patterns: Blueprints for Business Software (Part-IV Dynamic Behavioral Patterns) in early 2000s, which has profound implications for building extensible systems. The facets pattern, also known as dynamic aggregation or extension objects, allows secondary objects (facets) to be attached to primary objects at runtime, effectively extending their capabilities without inheritance or modification. Unlike AOM, which focuses on schema flexibility, facets address behavioral composition – the ability to mix and match capabilities based on runtime requirements.
Facets Pattern
The facets pattern emerged from several key observations about real-world software systems:
Interface Segregation: Not every object needs every capability all the time. A User object might need audit trail capabilities in some contexts, caching in others, and validation in yet others.
Runtime Composition: The specific mix of capabilities often depends on runtime context – user permissions, configuration settings, or environmental factors that cannot be determined at compile time.
Separation of Concerns: Cross-cutting concerns like logging, security, and persistence should be composable without polluting domain objects.
Voyager ORB’s implementation demonstrated these principles elegantly:
// Voyager ORB example - attaching an account facet to an employee
IEmployee employee = new Employee("joe", "234-44-2678");
IFacets facets = Facets.of(employee);
IAccount account = (IAccount) facets.of(IAccount.class);
account.deposit(2000);
The beauty of this approach is that the Employee class knows nothing about accounting capabilities, yet the object can seamlessly provide financial operations when needed.
Modern Implementations
Let’s explore how this pattern can be implemented in modern languages, taking advantage of their unique strengths while maintaining the core principles.
Rust Implementation: Type-Safe Facet Composition
Rust’s type system and trait system provide excellent foundations for type-safe facet composition:
use std::collections::HashMap;
use std::any::{Any, TypeId};
use std::sync::RwLock;
// Core facet trait that all facets must implement
pub trait Facet: Any + Send + Sync {
fn as_any(&self) -> &dyn Any;
fn as_any_mut(&mut self) -> &mut dyn Any;
}
// Faceted object that can have facets attached
pub struct FacetedObject {
facets: RwLock<HashMap<TypeId, Box<dyn Facet>>>,
core_object: Box<dyn Any + Send + Sync>,
}
impl FacetedObject {
pub fn new<T: Any + Send + Sync>(core: T) -> Self {
Self {
facets: RwLock::new(HashMap::new()),
core_object: Box::new(core),
}
}
// Attach a facet to this object
pub fn attach_facet<F: Facet + 'static>(&self, facet: F) -> Result<(), String> {
let type_id = TypeId::of::<F>();
let mut facets = self.facets.write()
.map_err(|_| "Failed to acquire write lock")?;
if facets.contains_key(&type_id) {
return Err(format!("Facet of type {:?} already attached", type_id));
}
facets.insert(type_id, Box::new(facet));
Ok(())
}
// Execute an operation that requires a specific facet (safe callback pattern)
pub fn with_facet<F: Facet + 'static, R>(
&self,
operation: impl FnOnce(&F) -> R
) -> Result<R, String> {
let facets = self.facets.read()
.map_err(|_| "Failed to acquire read lock")?;
let type_id = TypeId::of::<F>();
if let Some(facet) = facets.get(&type_id) {
if let Some(typed_facet) = facet.as_any().downcast_ref::<F>() {
Ok(operation(typed_facet))
} else {
Err("Failed to downcast facet".to_string())
}
} else {
Err(format!("Required facet not found: {:?}", type_id))
}
}
// Execute a mutable operation on a facet
pub fn with_facet_mut<F: Facet + 'static, R>(
&self,
operation: impl FnOnce(&mut F) -> R
) -> Result<R, String> {
let mut facets = self.facets.write()
.map_err(|_| "Failed to acquire write lock")?;
let type_id = TypeId::of::<F>();
if let Some(facet) = facets.get_mut(&type_id) {
if let Some(typed_facet) = facet.as_any_mut().downcast_mut::<F>() {
Ok(operation(typed_facet))
} else {
Err("Failed to downcast facet".to_string())
}
} else {
Err(format!("Required facet not found: {:?}", type_id))
}
}
// Check if a facet is attached
pub fn has_facet<F: Facet + 'static>(&self) -> bool {
let facets = self.facets.read().unwrap();
let type_id = TypeId::of::<F>();
facets.contains_key(&type_id)
}
// Get the core object
pub fn get_core<T: 'static>(&self) -> Option<&T> {
self.core_object.downcast_ref::<T>()
}
}
// Example domain object
#[derive(Debug)]
pub struct Employee {
pub name: String,
pub id: String,
pub department: String,
}
impl Employee {
pub fn new(name: &str, id: &str, department: &str) -> Self {
Self {
name: name.to_string(),
id: id.to_string(),
department: department.to_string(),
}
}
}
// Account facet for financial operations
#[derive(Debug)]
pub struct AccountFacet {
balance: f64,
account_number: String,
}
impl AccountFacet {
pub fn new(account_number: &str) -> Self {
Self {
balance: 0.0,
account_number: account_number.to_string(),
}
}
pub fn deposit(&mut self, amount: f64) -> Result<f64, String> {
if amount <= 0.0 {
return Err("Deposit amount must be positive".to_string());
}
self.balance += amount;
Ok(self.balance)
}
pub fn withdraw(&mut self, amount: f64) -> Result<f64, String> {
if amount <= 0.0 {
return Err("Withdrawal amount must be positive".to_string());
}
if amount > self.balance {
return Err("Insufficient funds".to_string());
}
self.balance -= amount;
Ok(self.balance)
}
pub fn get_balance(&self) -> f64 {
self.balance
}
pub fn get_account_number(&self) -> &str {
&self.account_number
}
}
impl Facet for AccountFacet {
fn as_any(&self) -> &dyn Any {
self
}
fn as_any_mut(&mut self) -> &mut dyn Any {
self
}
}
// Audit trail facet for tracking operations
#[derive(Debug)]
pub struct AuditFacet {
entries: Vec<AuditEntry>,
}
#[derive(Debug, Clone)]
pub struct AuditEntry {
timestamp: std::time::SystemTime,
operation: String,
details: String,
}
impl AuditFacet {
pub fn new() -> Self {
Self {
entries: Vec::new(),
}
}
pub fn log_operation(&mut self, operation: &str, details: &str) {
self.entries.push(AuditEntry {
timestamp: std::time::SystemTime::now(),
operation: operation.to_string(),
details: details.to_string(),
});
}
pub fn get_audit_trail(&self) -> &[AuditEntry] {
&self.entries
}
pub fn get_recent_entries(&self, count: usize) -> &[AuditEntry] {
let start = if self.entries.len() > count {
self.entries.len() - count
} else {
0
};
&self.entries[start..]
}
}
impl Facet for AuditFacet {
fn as_any(&self) -> &dyn Any {
self
}
fn as_any_mut(&mut self) -> &mut dyn Any {
self
}
}
// Permission facet for access control
#[derive(Debug)]
pub struct PermissionFacet {
permissions: HashMap<String, bool>,
role: String,
}
impl PermissionFacet {
pub fn new(role: &str) -> Self {
let mut permissions = HashMap::new();
// Define role-based permissions
match role {
"admin" => {
permissions.insert("read".to_string(), true);
permissions.insert("write".to_string(), true);
permissions.insert("delete".to_string(), true);
permissions.insert("financial_operations".to_string(), true);
},
"manager" => {
permissions.insert("read".to_string(), true);
permissions.insert("write".to_string(), true);
permissions.insert("financial_operations".to_string(), true);
},
"employee" => {
permissions.insert("read".to_string(), true);
},
_ => {}
}
Self {
permissions,
role: role.to_string(),
}
}
pub fn has_permission(&self, permission: &str) -> bool {
self.permissions.get(permission).copied().unwrap_or(false)
}
pub fn grant_permission(&mut self, permission: &str) {
self.permissions.insert(permission.to_string(), true);
}
pub fn revoke_permission(&mut self, permission: &str) {
self.permissions.insert(permission.to_string(), false);
}
pub fn get_role(&self) -> &str {
&self.role
}
}
impl Facet for PermissionFacet {
fn as_any(&self) -> &dyn Any {
self
}
fn as_any_mut(&mut self) -> &mut dyn Any {
self
}
}
// Composite operations that work across facets
pub struct EmployeeOperations;
impl EmployeeOperations {
pub fn perform_financial_operation<F>(
employee_obj: &FacetedObject,
mut operation: F,
) -> Result<String, String>
where
F: FnMut(&mut AccountFacet) -> Result<f64, String>,
{
// Check permissions first
let has_permission = employee_obj.with_facet::<PermissionFacet, bool>(|permissions| {
permissions.has_permission("financial_operations")
}).unwrap_or(false);
if !has_permission {
return Err("Access denied: insufficient permissions for financial operations".to_string());
}
// Get employee info for logging
let employee_name = employee_obj.get_core::<Employee>()
.map(|emp| emp.name.clone())
.unwrap_or_else(|| "Unknown".to_string());
// Perform the operation
let result = employee_obj.with_facet_mut::<AccountFacet, Result<f64, String>>(|account| {
operation(account)
})?;
let balance = result?;
// Log the operation if audit facet is present
let _ = employee_obj.with_facet_mut::<AuditFacet, ()>(|audit| {
audit.log_operation("financial_operation", &format!("New balance: {}", balance));
});
Ok(format!("Financial operation completed for {}. New balance: {}", employee_name, balance))
}
pub fn get_employee_summary(employee_obj: &FacetedObject) -> String {
let mut summary = String::new();
// Core employee information
if let Some(employee) = employee_obj.get_core::<Employee>() {
summary.push_str(&format!("Employee: {} (ID: {})\n", employee.name, employee.id));
summary.push_str(&format!("Department: {}\n", employee.department));
}
// Account information if available
let account_info = employee_obj.with_facet::<AccountFacet, String>(|account| {
format!("Account: {} (Balance: ${:.2})\n",
account.get_account_number(), account.get_balance())
}).unwrap_or_else(|_| "No account information\n".to_string());
summary.push_str(&account_info);
// Permission information if available
let permission_info = employee_obj.with_facet::<PermissionFacet, String>(|permissions| {
format!("Role: {}\n", permissions.get_role())
}).unwrap_or_else(|_| "No permission information\n".to_string());
summary.push_str(&permission_info);
// Audit information if available
let audit_info = employee_obj.with_facet::<AuditFacet, String>(|audit| {
let recent_entries = audit.get_recent_entries(3);
if !recent_entries.is_empty() {
let mut info = "Recent Activity:\n".to_string();
for entry in recent_entries {
info.push_str(&format!(" - {:?}: {} ({})\n",
entry.timestamp,
entry.operation,
entry.details));
}
info
} else {
"No recent activity\n".to_string()
}
}).unwrap_or_else(|_| "No audit information\n".to_string());
summary.push_str(&audit_info);
summary
}
}
// Usage example
fn example_usage() -> Result<(), String> {
println!("=== Dynamic Facets Example ===");
// Create an employee
let employee = Employee::new("Alice Johnson", "EMP001", "Engineering");
let employee_obj = FacetedObject::new(employee);
// Attach different facets based on requirements
employee_obj.attach_facet(AccountFacet::new("ACC001"))?;
employee_obj.attach_facet(PermissionFacet::new("manager"))?;
employee_obj.attach_facet(AuditFacet::new())?;
println!("Facets attached successfully!");
// Use facets through the composite object
let summary = EmployeeOperations::get_employee_summary(&employee_obj);
println!("\nEmployee Summary:\n{}", summary);
// Attempt financial operation (deposit)
let result = EmployeeOperations::perform_financial_operation(
&employee_obj,
|account| account.deposit(1000.0)
)?;
println!("Deposit result: {}", result);
// Attempt another financial operation (withdrawal)
let result = EmployeeOperations::perform_financial_operation(
&employee_obj,
|account| account.withdraw(250.0)
)?;
println!("Withdrawal result: {}", result);
// Display final summary
let final_summary = EmployeeOperations::get_employee_summary(&employee_obj);
println!("\nFinal Employee Summary:\n{}", final_summary);
Ok(())
}
fn main() {
match example_usage() {
Ok(_) => println!("\nFacet composition example completed successfully."),
Err(e) => eprintln!("Error: {}", e),
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_facet_attachment() {
let employee = Employee::new("Test User", "TEST001", "Engineering");
let employee_obj = FacetedObject::new(employee);
// Test attaching facets
assert!(employee_obj.attach_facet(AccountFacet::new("ACC001")).is_ok());
assert!(employee_obj.has_facet::<AccountFacet>());
// Test duplicate attachment fails
assert!(employee_obj.attach_facet(AccountFacet::new("ACC002")).is_err());
}
#[test]
fn test_financial_operations() {
let employee = Employee::new("Test User", "TEST001", "Engineering");
let employee_obj = FacetedObject::new(employee);
employee_obj.attach_facet(AccountFacet::new("ACC001")).unwrap();
employee_obj.attach_facet(PermissionFacet::new("manager")).unwrap();
// Test deposit
let result = employee_obj.with_facet_mut::<AccountFacet, Result<f64, String>>(|account| {
account.deposit(1000.0)
}).unwrap();
assert_eq!(result.unwrap(), 1000.0);
// Test balance check
let balance = employee_obj.with_facet::<AccountFacet, f64>(|account| {
account.get_balance()
}).unwrap();
assert_eq!(balance, 1000.0);
}
#[test]
fn test_permission_checking() {
let employee = Employee::new("Test User", "TEST001", "Engineering");
let employee_obj = FacetedObject::new(employee);
employee_obj.attach_facet(PermissionFacet::new("employee")).unwrap();
let has_financial = employee_obj.with_facet::<PermissionFacet, bool>(|permissions| {
permissions.has_permission("financial_operations")
}).unwrap();
assert_eq!(has_financial, false);
let has_read = employee_obj.with_facet::<PermissionFacet, bool>(|permissions| {
permissions.has_permission("read")
}).unwrap();
assert_eq!(has_read, true);
}
}
The Rust implementation provides several key advantages:
Type Safety: The type system ensures that facets can only be cast to their correct types
Memory Safety: Rust’s ownership model prevents common issues with shared mutable state
Performance: Zero-cost abstractions mean the facet system has minimal runtime overhead
Concurrency: Built-in thread safety through Send and Sync traits
TypeScript Implementation: Dynamic Composition with Type Safety
TypeScript’s type system allows for sophisticated compile-time checking while maintaining JavaScript’s dynamic nature:
// Base interfaces for the facet system
// Base interfaces for the facet system
interface Facet {
readonly facetType: string;
}
interface FacetConstructor<T extends Facet> {
new(...args: any[]): T;
readonly facetType: string;
}
// Core faceted object implementation
class FacetedObject<TCore = any> {
private facets: Map<string, Facet> = new Map();
private core: TCore;
constructor(core: TCore) {
this.core = core;
}
// Attach a facet to this object
attachFacet<T extends Facet>(FacetClass: FacetConstructor<T>, ...args: any[]): T {
const facet = new FacetClass(...args);
if (this.facets.has(FacetClass.facetType)) {
throw new Error(`Facet ${FacetClass.facetType} already attached`);
}
this.facets.set(FacetClass.facetType, facet);
return facet;
}
// Get a facet by its constructor
getFacet<T extends Facet>(FacetClass: FacetConstructor<T>): T | undefined {
const facet = this.facets.get(FacetClass.facetType);
return facet as T | undefined;
}
// Check if a facet is attached
hasFacet<T extends Facet>(FacetClass: FacetConstructor<T>): boolean {
return this.facets.has(FacetClass.facetType);
}
// Remove a facet
removeFacet<T extends Facet>(FacetClass: FacetConstructor<T>): boolean {
return this.facets.delete(FacetClass.facetType);
}
// Get the core object
getCore(): TCore {
return this.core;
}
// Execute operation with facet requirement checking
withFacet<T extends Facet, R>(
FacetClass: FacetConstructor<T>,
operation: (facet: T) => R
): R {
const facet = this.getFacet(FacetClass);
if (!facet) {
throw new Error(`Required facet ${FacetClass.facetType} not found`);
}
return operation(facet);
}
// Get all attached facet types
getAttachedFacetTypes(): string[] {
return Array.from(this.facets.keys());
}
}
// Example domain objects
interface Employee {
name: string;
id: string;
department: string;
email: string;
}
class EmployeeImpl implements Employee {
constructor(
public name: string,
public id: string,
public department: string,
public email: string
) {}
}
// Account facet for financial operations
class AccountFacet implements Facet {
static readonly facetType = 'account';
readonly facetType = AccountFacet.facetType;
private balance: number = 0;
private accountNumber: string;
private transactions: Transaction[] = [];
constructor(accountNumber: string, initialBalance: number = 0) {
this.accountNumber = accountNumber;
this.balance = initialBalance;
}
deposit(amount: number): number {
if (amount <= 0) {
throw new Error('Deposit amount must be positive');
}
this.balance += amount;
this.transactions.push({
type: 'deposit',
amount,
timestamp: new Date(),
balanceAfter: this.balance
});
return this.balance;
}
withdraw(amount: number): number {
if (amount <= 0) {
throw new Error('Withdrawal amount must be positive');
}
if (amount > this.balance) {
throw new Error('Insufficient funds');
}
this.balance -= amount;
this.transactions.push({
type: 'withdrawal',
amount,
timestamp: new Date(),
balanceAfter: this.balance
});
return this.balance;
}
getBalance(): number {
return this.balance;
}
getAccountNumber(): string {
return this.accountNumber;
}
getTransactionHistory(): Transaction[] {
return [...this.transactions];
}
getRecentTransactions(count: number): Transaction[] {
return this.transactions.slice(-count);
}
}
interface Transaction {
type: 'deposit' | 'withdrawal';
amount: number;
timestamp: Date;
balanceAfter: number;
}
// Notification facet for alerting
class NotificationFacet implements Facet {
static readonly facetType = 'notification';
readonly facetType = NotificationFacet.facetType;
private subscribers: Map<string, NotificationHandler[]> = new Map();
subscribe(eventType: string, handler: NotificationHandler): void {
if (!this.subscribers.has(eventType)) {
this.subscribers.set(eventType, []);
}
this.subscribers.get(eventType)!.push(handler);
}
unsubscribe(eventType: string, handler: NotificationHandler): boolean {
const handlers = this.subscribers.get(eventType);
if (!handlers) return false;
const index = handlers.indexOf(handler);
if (index !== -1) {
handlers.splice(index, 1);
return true;
}
return false;
}
notify(eventType: string, data: any): void {
const handlers = this.subscribers.get(eventType) || [];
handlers.forEach(handler => {
try {
handler(eventType, data);
} catch (error) {
const errorMessage = error instanceof Error ? error.message : 'Unknown error';
console.error(`Notification handler error for ${eventType}:`, errorMessage);
}
});
}
getSubscriberCount(eventType: string): number {
return this.subscribers.get(eventType)?.length || 0;
}
}
type NotificationHandler = (eventType: string, data: any) => void;
// Cache facet for performance optimization
class CacheFacet implements Facet {
static readonly facetType = 'cache';
readonly facetType = CacheFacet.facetType;
private cache: Map<string, CacheEntry> = new Map();
private maxSize: number;
private defaultTTL: number;
constructor(maxSize: number = 100, defaultTTL: number = 300000) { // 5 minutes default
this.maxSize = maxSize;
this.defaultTTL = defaultTTL;
}
set<T>(key: string, value: T, ttl?: number): void {
// Remove oldest entries if cache is full
if (this.cache.size >= this.maxSize) {
const oldestKey = this.cache.keys().next().value;
if (oldestKey !== undefined) {
this.cache.delete(oldestKey);
}
}
this.cache.set(key, {
value,
timestamp: Date.now(),
ttl: ttl || this.defaultTTL
});
}
get<T>(key: string): T | undefined {
const entry = this.cache.get(key);
if (!entry) return undefined;
// Check if entry has expired
if (Date.now() - entry.timestamp > entry.ttl) {
this.cache.delete(key);
return undefined;
}
return entry.value as T;
}
has(key: string): boolean {
const entry = this.cache.get(key);
if (!entry) return false;
// Check if entry has expired
if (Date.now() - entry.timestamp > entry.ttl) {
this.cache.delete(key);
return false;
}
return true;
}
invalidate(key: string): boolean {
return this.cache.delete(key);
}
clear(): void {
this.cache.clear();
}
getStats(): CacheStats {
return {
size: this.cache.size,
maxSize: this.maxSize,
hitRate: 0 // Would need to track hits/misses for real implementation
};
}
}
interface CacheEntry {
value: any;
timestamp: number;
ttl: number;
}
interface CacheStats {
size: number;
maxSize: number;
hitRate: number;
}
// Permission facet with role-based access control
class PermissionFacet implements Facet {
static readonly facetType = 'permission';
readonly facetType = PermissionFacet.facetType;
private permissions: Set<string> = new Set();
private role: string;
constructor(role: string) {
this.role = role;
this.initializeRolePermissions(role);
}
private initializeRolePermissions(role: string): void {
const rolePermissions: Record<string, string[]> = {
'admin': ['read', 'write', 'delete', 'financial', 'admin'],
'manager': ['read', 'write', 'financial', 'manage_team'],
'employee': ['read', 'view_profile'],
'guest': ['read']
};
const perms = rolePermissions[role] || [];
perms.forEach(perm => this.permissions.add(perm));
}
hasPermission(permission: string): boolean {
return this.permissions.has(permission);
}
grantPermission(permission: string): void {
this.permissions.add(permission);
}
revokePermission(permission: string): void {
this.permissions.delete(permission);
}
getPermissions(): string[] {
return Array.from(this.permissions);
}
getRole(): string {
return this.role;
}
requirePermission(permission: string): void {
if (!this.hasPermission(permission)) {
throw new Error(`Access denied: missing permission '${permission}'`);
}
}
}
// Composite operations using multiple facets
class EmployeeService {
static performSecureFinancialOperation(
employeeObj: FacetedObject<Employee>,
operation: (account: AccountFacet) => number,
operationType: string
): number {
// Check permissions
const permissions = employeeObj.getFacet(PermissionFacet);
if (permissions) {
permissions.requirePermission('financial');
}
// Perform operation
const result = employeeObj.withFacet(AccountFacet, operation);
// Send notification if facet is available
const notifications = employeeObj.getFacet(NotificationFacet);
if (notifications) {
notifications.notify('financial_operation', {
employee: employeeObj.getCore().name,
operation: operationType,
timestamp: new Date()
});
}
// Invalidate related cache entries
const cache = employeeObj.getFacet(CacheFacet);
if (cache) {
cache.invalidate(`balance_${employeeObj.getCore().id}`);
cache.invalidate(`transactions_${employeeObj.getCore().id}`);
}
return result;
}
static getEmployeeSummary(employeeObj: FacetedObject<Employee>): string {
const employee = employeeObj.getCore();
const facetTypes = employeeObj.getAttachedFacetTypes();
let summary = `Employee: ${employee.name} (${employee.id})\n`;
summary += `Department: ${employee.department}\n`;
summary += `Email: ${employee.email}\n`;
summary += `Active Facets: ${facetTypes.join(', ')}\n`;
// Add account information if available
const account = employeeObj.getFacet(AccountFacet);
if (account) {
summary += `Account: ${account.getAccountNumber()} (Balance: $${account.getBalance().toFixed(2)})\n`;
const recentTransactions = account.getRecentTransactions(3);
if (recentTransactions.length > 0) {
summary += 'Recent Transactions:\n';
recentTransactions.forEach(tx => {
summary += ` ${tx.type}: $${tx.amount.toFixed(2)} on ${tx.timestamp.toLocaleString()}\n`;
});
}
}
// Add permission information if available
const permissions = employeeObj.getFacet(PermissionFacet);
if (permissions) {
summary += `Role: ${permissions.getRole()}\n`;
summary += `Permissions: ${permissions.getPermissions().join(', ')}\n`;
}
// Add cache stats if available
const cache = employeeObj.getFacet(CacheFacet);
if (cache) {
const stats = cache.getStats();
summary += `Cache: ${stats.size}/${stats.maxSize} entries\n`;
}
return summary;
}
static configureEmployeeCapabilities(
employeeObj: FacetedObject<Employee>,
config: EmployeeConfig
): void {
// Attach facets based on configuration
if (config.hasAccount) {
employeeObj.attachFacet(AccountFacet, config.accountNumber, config.initialBalance);
}
if (config.role) {
employeeObj.attachFacet(PermissionFacet, config.role);
}
if (config.enableNotifications) {
const notifications = employeeObj.attachFacet(NotificationFacet);
// Set up default notification handlers
notifications.subscribe('financial_operation', (eventType, data) => {
console.log(`Financial operation performed: ${JSON.stringify(data)}`);
});
}
if (config.enableCaching) {
employeeObj.attachFacet(CacheFacet, config.cacheSize, config.cacheTTL);
}
}
}
interface EmployeeConfig {
hasAccount?: boolean;
accountNumber?: string;
initialBalance?: number;
role?: string;
enableNotifications?: boolean;
enableCaching?: boolean;
cacheSize?: number;
cacheTTL?: number;
}
// Usage example
function demonstrateFacetComposition(): void {
console.log('=== Dynamic Facet Composition Demo ===');
// Create an employee
const employee = new EmployeeImpl('Bob Smith', 'EMP002', 'Finance', 'bob.smith@company.com');
const employeeObj = new FacetedObject(employee);
// Configure capabilities based on requirements
EmployeeService.configureEmployeeCapabilities(employeeObj, {
hasAccount: true,
accountNumber: 'ACC002',
initialBalance: 500,
role: 'manager',
enableNotifications: true,
enableCaching: true,
cacheSize: 50,
cacheTTL: 600000 // 10 minutes
});
// Display initial summary
console.log('\nInitial Employee Summary:');
console.log(EmployeeService.getEmployeeSummary(employeeObj));
// Perform financial operations
try {
const newBalance = EmployeeService.performSecureFinancialOperation(
employeeObj,
(account) => account.deposit(1000),
'deposit'
);
console.log(`Deposit successful. New balance: $${newBalance.toFixed(2)}`);
const finalBalance = EmployeeService.performSecureFinancialOperation(
employeeObj,
(account) => account.withdraw(200),
'withdrawal'
);
console.log(`Withdrawal successful. Final balance: $${finalBalance.toFixed(2)}`);
} catch (error) {
const errorMessage = error instanceof Error ? error.message : 'Unknown error occurred';
console.error('Operation failed:', errorMessage);
}
// Display final summary
console.log('\nFinal Employee Summary:');
console.log(EmployeeService.getEmployeeSummary(employeeObj));
}
// Run the demonstration
demonstrateFacetComposition();
The TypeScript implementation provides:
Type Safety: Compile-time type checking for facet operations
IntelliSense Support: Rich IDE support with autocompletion and error detection
Interface Segregation: Clean separation between different capabilities
Dynamic Composition: Runtime attachment and detachment of behaviors
Ruby’s metaprogramming capabilities make facet implementation particularly elegant:
require 'date'
require 'set'
require 'json'
# Core facet module that all facets include
module Facet
def self.included(base)
base.extend(ClassMethods)
end
module ClassMethods
def facet_type
@facet_type ||= name.downcase.gsub(/facet$/, '')
end
def facet_type=(type)
@facet_type = type
end
end
def facet_type
self.class.facet_type
end
end
# Main faceted object implementation
class FacetedObject
def initialize(core_object)
@core_object = core_object
@facets = {}
@method_cache = {}
# Enable method delegation
extend_with_facet_methods
end
def attach_facet(facet_instance)
facet_type = facet_instance.facet_type
if @facets.key?(facet_type)
raise ArgumentError, "Facet '#{facet_type}' already attached"
end
@facets[facet_type] = facet_instance
# Add facet methods to this instance
add_facet_methods(facet_instance)
# Call initialization hook if facet defines it
facet_instance.on_attached(self) if facet_instance.respond_to?(:on_attached)
facet_instance
end
def detach_facet(facet_type_or_class)
facet_type = case facet_type_or_class
when String
facet_type_or_class
when Class
facet_type_or_class.facet_type
else
facet_type_or_class.facet_type
end
facet = @facets.delete(facet_type)
if facet
# Remove facet methods
remove_facet_methods(facet)
# Call cleanup hook if facet defines it
facet.on_detached(self) if facet.respond_to?(:on_detached)
end
facet
end
def get_facet(facet_type_or_class)
facet_type = case facet_type_or_class
when String
facet_type_or_class
when Class
facet_type_or_class.facet_type
else
facet_type_or_class.facet_type
end
@facets[facet_type]
end
def has_facet?(facet_type_or_class)
!get_facet(facet_type_or_class).nil?
end
def facet_types
@facets.keys
end
def core_object
@core_object
end
def with_facet(facet_type_or_class)
facet = get_facet(facet_type_or_class)
raise ArgumentError, "Facet not found: #{facet_type_or_class}" unless facet
yield(facet)
end
# Require specific facets for an operation
def requires_facets(*facet_types, &block)
missing_facets = facet_types.select { |type| !has_facet?(type) }
unless missing_facets.empty?
raise ArgumentError, "Missing required facets: #{missing_facets.join(', ')}"
end
block.call(self) if block_given?
end
private
def extend_with_facet_methods
# Add method_missing to handle facet method calls
singleton_class.class_eval do
define_method :method_missing do |method_name, *args, &block|
# Try to find the method in attached facets
@facets.values.each do |facet|
if facet.respond_to?(method_name)
return facet.send(method_name, *args, &block)
end
end
# Try the core object
if @core_object.respond_to?(method_name)
return @core_object.send(method_name, *args, &block)
end
super(method_name, *args, &block)
end
define_method :respond_to_missing? do |method_name, include_private = false|
@facets.values.any? { |facet| facet.respond_to?(method_name, include_private) } ||
@core_object.respond_to?(method_name, include_private) ||
super(method_name, include_private)
end
end
end
def add_facet_methods(facet)
facet.public_methods(false).each do |method_name|
next if method_name == :facet_type
# Create a delegating method for each public method of the facet
singleton_class.class_eval do
define_method("#{facet.facet_type}_#{method_name}") do |*args, &block|
facet.send(method_name, *args, &block)
end
end
end
end
def remove_facet_methods(facet)
facet.public_methods(false).each do |method_name|
method_to_remove = "#{facet.facet_type}_#{method_name}"
if respond_to?(method_to_remove)
singleton_class.class_eval do
remove_method(method_to_remove) if method_defined?(method_to_remove)
end
end
end
end
end
# Example domain class
class Employee
attr_accessor :name, :id, :department, :email, :hire_date
def initialize(name, id, department, email, hire_date = Date.today)
@name = name
@id = id
@department = department
@email = email
@hire_date = hire_date
end
def years_of_service
((Date.today - @hire_date) / 365.25).to_i
end
def to_h
{
name: @name,
id: @id,
department: @department,
email: @email,
hire_date: @hire_date,
years_of_service: years_of_service
}
end
end
# Account facet for financial operations
class AccountFacet
include Facet
attr_reader :account_number, :balance
def initialize(account_number, initial_balance = 0)
@account_number = account_number
@balance = initial_balance.to_f
@transactions = []
end
def deposit(amount)
raise ArgumentError, "Amount must be positive" unless amount > 0
@balance += amount
log_transaction('deposit', amount)
@balance
end
def withdraw(amount)
raise ArgumentError, "Amount must be positive" unless amount > 0
raise ArgumentError, "Insufficient funds" if amount > @balance
@balance -= amount
log_transaction('withdrawal', amount)
@balance
end
def transfer_to(target_account_number, amount)
raise ArgumentError, "Cannot transfer to same account" if target_account_number == @account_number
withdraw(amount)
log_transaction('transfer_out', amount, target_account_number)
amount
end
def receive_transfer(from_account_number, amount)
deposit(amount)
log_transaction('transfer_in', amount, from_account_number)
@balance
end
def transaction_history(limit = nil)
limit ? @transactions.last(limit) : @transactions.dup
end
def monthly_summary(year, month)
start_date = Date.new(year, month, 1)
end_date = start_date.next_month - 1
monthly_transactions = @transactions.select do |tx|
tx[:timestamp].to_date.between?(start_date, end_date)
end
{
period: "#{year}-#{month.to_s.rjust(2, '0')}",
transactions: monthly_transactions,
total_deposits: monthly_transactions.select { |tx| tx[:type] == 'deposit' }.sum { |tx| tx[:amount] },
total_withdrawals: monthly_transactions.select { |tx| tx[:type] == 'withdrawal' }.sum { |tx| tx[:amount] }
}
end
private
def log_transaction(type, amount, reference = nil)
@transactions << {
type: type,
amount: amount,
balance_after: @balance,
timestamp: Time.now,
reference: reference
}
end
end
# Performance tracking facet
class PerformanceFacet
include Facet
def initialize
@metrics = {}
@goals = {}
@reviews = []
end
def set_metric(name, value, period = Date.today)
@metrics[name] ||= []
@metrics[name] << { value: value, period: period, timestamp: Time.now }
end
def get_metric(name, period = nil)
return nil unless @metrics[name]
if period
@metrics[name].find { |m| m[:period] == period }&.fetch(:value)
else
@metrics[name].last&.fetch(:value)
end
end
def set_goal(name, target_value, deadline)
@goals[name] = { target: target_value, deadline: deadline, set_on: Date.today }
end
def goal_progress(name)
goal = @goals[name]
return nil unless goal
current_value = get_metric(name)
return nil unless current_value
progress = (current_value.to_f / goal[:target]) * 100
{
goal: goal,
current_value: current_value,
progress_percentage: progress.round(2),
days_remaining: (goal[:deadline] - Date.today).to_i
}
end
def add_review(rating, comments, reviewer, review_date = Date.today)
@reviews << {
rating: rating,
comments: comments,
reviewer: reviewer,
review_date: review_date,
timestamp: Time.now
}
end
def average_rating(last_n_reviews = nil)
reviews_to_consider = last_n_reviews ? @reviews.last(last_n_reviews) : @reviews
return 0 if reviews_to_consider.empty?
total = reviews_to_consider.sum { |review| review[:rating] }
(total.to_f / reviews_to_consider.size).round(2)
end
def performance_summary
{
metrics: @metrics.transform_values { |values| values.last },
goals: @goals.transform_values { |goal| goal_progress(@goals.key(goal)) },
recent_reviews: @reviews.last(3),
average_rating: average_rating,
total_reviews: @reviews.size
}
end
end
# Security facet for access control and audit
class SecurityFacet
include Facet
def initialize(security_level = 'basic')
@security_level = security_level
@access_log = []
@failed_attempts = []
@permissions = Set.new
@active_sessions = {}
setup_default_permissions
end
def authenticate(credentials)
# Simulate authentication
success = credentials[:password] == 'secret123'
log_access_attempt(credentials[:user_id], success)
if success
session_id = generate_session_id
@active_sessions[session_id] = {
user_id: credentials[:user_id],
start_time: Time.now,
last_activity: Time.now
}
session_id
else
nil
end
end
def validate_session(session_id)
session = @active_sessions[session_id]
return false unless session
# Check session timeout (30 minutes)
if Time.now - session[:last_activity] > 1800
@active_sessions.delete(session_id)
return false
end
session[:last_activity] = Time.now
true
end
def logout(session_id)
@active_sessions.delete(session_id)
end
def grant_permission(permission)
@permissions.add(permission)
end
def revoke_permission(permission)
@permissions.delete(permission)
end
def has_permission?(permission)
@permissions.include?(permission) || @permissions.include?('admin')
end
def require_permission(permission)
unless has_permission?(permission)
raise SecurityError, "Access denied: missing permission '#{permission}'"
end
end
def security_report
{
security_level: @security_level,
permissions: @permissions.to_a,
active_sessions: @active_sessions.size,
recent_access_attempts: @access_log.last(10),
failed_attempts_today: failed_attempts_today.size,
total_access_attempts: @access_log.size
}
end
private
def setup_default_permissions
case @security_level
when 'admin'
@permissions.merge(['read', 'write', 'delete', 'admin', 'financial'])
when 'manager'
@permissions.merge(['read', 'write', 'financial'])
when 'employee'
@permissions.merge(['read'])
end
end
def log_access_attempt(user_id, success)
attempt = {
user_id: user_id,
success: success,
timestamp: Time.now,
ip_address: '127.0.0.1' # Would be actual IP in real implementation
}
@access_log << attempt
@failed_attempts << attempt unless success
end
def failed_attempts_today
today = Date.today
@failed_attempts.select { |attempt| attempt[:timestamp].to_date == today }
end
def generate_session_id
"session_#{Time.now.to_i}_#{rand(10000)}"
end
end
# Notification facet for messaging and alerts
class NotificationFacet
include Facet
def initialize
@subscribers = Hash.new { |hash, key| hash[key] = [] }
@message_history = []
@preferences = {
email: true,
sms: false,
push: true,
frequency: 'immediate'
}
end
def subscribe(event_type, &handler)
@subscribers[event_type] << handler
end
def unsubscribe(event_type, handler)
@subscribers[event_type].delete(handler)
end
def notify(event_type, data = {})
timestamp = Time.now
message = {
event_type: event_type,
data: data,
timestamp: timestamp
}
@message_history << message
# Deliver to subscribers
@subscribers[event_type].each do |handler|
begin
handler.call(message)
rescue => e
puts "Notification handler error: #{e.message}"
end
end
# Simulate different delivery channels based on preferences
deliver_message(message) if should_deliver?(event_type)
end
def set_preference(channel, enabled)
@preferences[channel] = enabled
end
def set_frequency(frequency)
raise ArgumentError, "Invalid frequency" unless %w[immediate hourly daily].include?(frequency)
@preferences[:frequency] = frequency
end
def message_history(limit = nil)
limit ? @message_history.last(limit) : @message_history.dup
end
def unread_count
# In a real implementation, this would track read status
@message_history.count { |msg| msg[:timestamp] > Time.now - 3600 } # Last hour
end
private
def should_deliver?(event_type)
# Simple delivery logic based on preferences
case @preferences[:frequency]
when 'immediate'
true
when 'hourly'
@message_history.select { |msg| msg[:timestamp] > Time.now - 3600 }.size <= 1
when 'daily'
@message_history.select { |msg| msg[:timestamp] > Time.now - 86400 }.size <= 1
else
true
end
end
def deliver_message(message)
puts "? Email: #{message[:event_type]} - #{message[:data]}" if @preferences[:email]
puts "? Push: #{message[:event_type]} - #{message[:data]}" if @preferences[:push]
puts "? SMS: #{message[:event_type]} - #{message[:data]}" if @preferences[:sms]
end
end
# Service class for coordinated operations
class EmployeeService
def self.create_employee(name, id, department, email, capabilities = {})
employee = Employee.new(name, id, department, email)
faceted_employee = FacetedObject.new(employee)
# Attach facets based on capabilities
if capabilities[:account]
account_facet = AccountFacet.new(capabilities[:account][:number], capabilities[:account][:balance])
faceted_employee.attach_facet(account_facet)
end
if capabilities[:security]
security_facet = SecurityFacet.new(capabilities[:security][:level])
capabilities[:security][:permissions]&.each { |perm| security_facet.grant_permission(perm) }
faceted_employee.attach_facet(security_facet)
end
if capabilities[:performance_tracking]
faceted_employee.attach_facet(PerformanceFacet.new)
end
if capabilities[:notifications]
notification_facet = NotificationFacet.new
# Set up default notification handlers
notification_facet.subscribe('financial_transaction') do |message|
puts "? Financial Alert: #{message[:data][:type]} of $#{message[:data][:amount]}"
end
notification_facet.subscribe('performance_update') do |message|
puts "? Performance Update: #{message[:data][:metric]} = #{message[:data][:value]}"
end
faceted_employee.attach_facet(notification_facet)
end
faceted_employee
end
def self.perform_secure_transaction(employee_obj, transaction_type, amount)
employee_obj.requires_facets('security', 'account') do |obj|
# Authenticate and check permissions
security = obj.get_facet('security')
security.require_permission('financial')
# Perform transaction
account = obj.get_facet('account')
result = case transaction_type
when 'deposit'
account.deposit(amount)
when 'withdraw'
account.withdraw(amount)
else
raise ArgumentError, "Unknown transaction type: #{transaction_type}"
end
# Send notification if available
if obj.has_facet?('notification')
notification = obj.get_facet('notification')
notification.notify('financial_transaction', {
type: transaction_type,
amount: amount,
new_balance: result,
employee: obj.core_object.name
})
end
result
end
end
def self.update_performance(employee_obj, metric_name, value)
employee_obj.with_facet('performance') do |performance|
performance.set_metric(metric_name, value)
# Notify if notification facet is available
if employee_obj.has_facet?('notification')
notification = employee_obj.get_facet('notification')
notification.notify('performance_update', {
metric: metric_name,
value: value,
employee: employee_obj.core_object.name
})
end
end
end
def self.comprehensive_report(employee_obj)
employee = employee_obj.core_object
report = {
employee_info: employee.to_h,
attached_facets: employee_obj.facet_types,
timestamp: Time.now
}
# Add facet-specific information
if employee_obj.has_facet?('account')
account = employee_obj.get_facet('account')
report[:financial] = {
account_number: account.account_number,
balance: account.balance,
recent_transactions: account.transaction_history(5)
}
end
if employee_obj.has_facet?('performance')
performance = employee_obj.get_facet('performance')
report[:performance] = performance.performance_summary
end
if employee_obj.has_facet?('security')
security = employee_obj.get_facet('security')
report[:security] = security.security_report
end
if employee_obj.has_facet?('notification')
notification = employee_obj.get_facet('notification')
report[:notifications] = {
unread_count: notification.unread_count,
recent_messages: notification.message_history(3)
}
end
report
end
end
# Usage demonstration
def demonstrate_facet_system
puts "=== Dynamic Facet Composition Demo ==="
# Create employee with various capabilities
employee_obj = EmployeeService.create_employee(
'Sarah Connor', 'EMP003', 'Engineering', 'sarah.connor@company.com',
{
account: { number: 'ACC003', balance: 1000 },
security: { level: 'manager', permissions: ['read', 'write', 'financial'] },
performance_tracking: true,
notifications: true
}
)
puts "\n--- Initial Employee State ---"
puts "Attached facets: #{employee_obj.facet_types.join(', ')}"
# Demonstrate financial operations
puts "\n--- Financial Operations ---"
begin
# First authenticate (in a real system)
security = employee_obj.get_facet('security')
session_id = security.authenticate(user_id: 'sarah', password: 'secret123')
puts "Authentication successful: #{session_id}"
# Perform transactions
new_balance = EmployeeService.perform_secure_transaction(employee_obj, 'deposit', 500)
puts "Deposit completed. New balance: $#{new_balance}"
new_balance = EmployeeService.perform_secure_transaction(employee_obj, 'withdraw', 200)
puts "Withdrawal completed. New balance: $#{new_balance}"
rescue => e
puts "Transaction failed: #{e.message}"
end
# Demonstrate performance tracking
puts "\n--- Performance Tracking ---"
EmployeeService.update_performance(employee_obj, 'projects_completed', 5)
EmployeeService.update_performance(employee_obj, 'customer_satisfaction', 4.5)
performance = employee_obj.get_facet('performance')
performance.set_goal('projects_completed', 10, Date.today + 90)
puts "Goal progress: #{performance.goal_progress('projects_completed')}"
# Generate comprehensive report
puts "\n--- Comprehensive Employee Report ---"
report = EmployeeService.comprehensive_report(employee_obj)
puts JSON.pretty_generate(report)
# Demonstrate dynamic facet management
puts "\n--- Dynamic Facet Management ---"
puts "Before detachment: #{employee_obj.facet_types.join(', ')}"
# Detach performance facet
employee_obj.detach_facet('performance')
puts "After detaching performance: #{employee_obj.facet_types.join(', ')}"
# Try to use detached facet (should fail gracefully)
begin
EmployeeService.update_performance(employee_obj, 'test_metric', 1)
rescue => e
puts "Expected error when using detached facet: #{e.message}"
end
end
# Run the demonstration
demonstrate_facet_system
The Ruby implementation showcases:
Metaprogramming Power: Dynamic method addition and removal using Ruby’s metaprogramming capabilities
Elegant Syntax: Clean, readable code that expresses intent clearly
Flexible Composition: Easy attachment and detachment of facets at runtime
Duck Typing: Natural method delegation without complex type hierarchies
Real-World Applications
The facets pattern proves particularly valuable in several domains:
Enterprise Software Integration
Modern enterprise systems often need to integrate with multiple external services. Facets allow core business objects to gain integration capabilities dynamically:
// Core customer object
const customer = new Customer('ABC Corp', 'enterprise');
const customerObj = new FacetedObject(customer);
// Attach integration facets based on configuration
if (config.salesforce.enabled) {
customerObj.attachFacet(SalesforceFacet, config.salesforce.credentials);
}
if (config.stripe.enabled) {
customerObj.attachFacet(PaymentFacet, config.stripe.apiKey);
}
if (config.analytics.enabled) {
customerObj.attachFacet(AnalyticsFacet, config.analytics.trackingId);
}
Multi-Tenant SaaS Applications
Different tenants often require different feature sets. Facets enable feature composition based on subscription levels:
// Configure tenant capabilities based on plan
match subscription_plan {
Plan::Basic => {
tenant_obj.attach_facet(BasicAnalyticsFacet::new())?;
},
Plan::Professional => {
tenant_obj.attach_facet(AdvancedAnalyticsFacet::new())?;
tenant_obj.attach_facet(IntegrationFacet::new())?;
},
Plan::Enterprise => {
tenant_obj.attach_facet(AdvancedAnalyticsFacet::new())?;
tenant_obj.attach_facet(IntegrationFacet::new())?;
tenant_obj.attach_facet(WhiteLabelFacet::new())?;
tenant_obj.attach_facet(ApiAccessFacet::new())?;
}
}
IoT Device Management
IoT devices often have optional capabilities that depend on hardware configuration or runtime conditions:
# Device base configuration
device_obj = FacetedObject.new(IoTDevice.new(device_id, device_type))
# Attach facets based on detected capabilities
if device.has_sensor?('temperature')
device_obj.attach_facet(TemperatureFacet.new)
end
if device.has_connectivity?('wifi')
device_obj.attach_facet(WiFiFacet.new)
end
if device.battery_powered?
device_obj.attach_facet(PowerManagementFacet.new)
end
Performance Considerations
While facets provide tremendous flexibility, they come with performance trade-offs that must be carefully managed:
Method Resolution Overhead
Dynamic method resolution can introduce latency. Caching strategies help mitigate this:
class OptimizedFacetedObject<TCore> extends FacetedObject<TCore> {
private methodCache: Map<string, Facet> = new Map();
getFacetForMethod(methodName: string): Facet | undefined {
// Check cache first
if (this.methodCache.has(methodName)) {
return this.methodCache.get(methodName);
}
// Search facets for method
for (const facet of this.facets.values()) {
if (typeof (facet as any)[methodName] === 'function') {
this.methodCache.set(methodName, facet);
return facet;
}
}
return undefined;
}
}
Memory Management
Facets can create reference cycles. Proper cleanup is essential:
impl Drop for FacetedObject {
fn drop(&mut self) {
// Clean up facet references
for (_, facet) in self.facets.drain() {
// Perform any necessary cleanup
// Call facet-specific cleanup if implemented
}
}
}
Serialization Challenges
Faceted objects require special handling for persistence:
class FacetedObject
def to_serializable
{
core_object: @core_object,
facets: @facets.transform_values { |facet| serialize_facet(facet) },
facet_types: @facets.keys
}
end
def self.from_serializable(data)
obj = new(data[:core_object])
data[:facets].each do |type, facet_data|
facet_class = Object.const_get("#{type.camelize}Facet")
facet = facet_class.deserialize(facet_data)
obj.attach_facet(facet)
end
obj
end
private
def serialize_facet(facet)
if facet.respond_to?(:serialize)
facet.serialize
else
# Default serialization
facet.instance_variables.each_with_object({}) do |var, hash|
hash[var] = facet.instance_variable_get(var)
end
end
end
end
Architecture Patterns and Best Practices
Facet Discovery and Registration
Large systems benefit from automatic facet discovery:
RSpec.describe FacetedObject do
let(:employee) { Employee.new('Test User', 'TEST001', 'Engineering', 'test@example.com') }
let(:employee_obj) { FacetedObject.new(employee) }
describe 'facet composition' do
it 'allows dynamic attachment of facets' do
account_facet = AccountFacet.new('ACC001', 1000)
employee_obj.attach_facet(account_facet)
expect(employee_obj.has_facet?('account')).to be true
expect(employee_obj.balance).to eq 1000
end
it 'prevents duplicate facet attachment' do
employee_obj.attach_facet(AccountFacet.new('ACC001'))
expect {
employee_obj.attach_facet(AccountFacet.new('ACC002'))
}.to raise_error(ArgumentError, /already attached/)
end
end
describe 'cross-facet operations' do
before do
employee_obj.attach_facet(AccountFacet.new('ACC001', 1000))
employee_obj.attach_facet(SecurityFacet.new('manager'))
employee_obj.attach_facet(NotificationFacet.new)
end
it 'coordinates operations across multiple facets' do
expect {
EmployeeService.perform_secure_transaction(employee_obj, 'withdraw', 100)
}.to change { employee_obj.balance }.by(-100)
.and output(/Financial Alert/).to_stdout
end
end
end
Comparison with Related Patterns
Facets vs Decorators
While both patterns add behavior dynamically, they serve different purposes:
Decorators: Wrap objects to modify or extend their interface Facets: Compose objects from multiple behavioral aspects
// Decorator pattern - wrapping behavior
class LoggingDecorator implements Employee {
constructor(private wrapped: Employee) {}
performAction(action: string): void {
console.log(`Performing: ${action}`);
this.wrapped.performAction(action);
console.log(`Completed: ${action}`);
}
}
// Facets pattern - compositional behavior
const employee = new FacetedObject(new EmployeeImpl());
employee.attachFacet(LoggingFacet);
employee.attachFacet(SecurityFacet);
// Employee now has both logging AND security capabilities
Facets vs Mixins
Mixins operate at the class level, facets at the instance level:
# Mixin - class-level composition
module Auditable
def log_action(action)
puts "Action: #{action}"
end
end
class Employee
include Auditable # All instances get audit capability
end
# Facets - instance-level composition
employee1 = FacetedObject.new(Employee.new)
employee1.attach_facet(AuditFacet.new) # Only this instance gets audit capability
employee2 = FacetedObject.new(Employee.new) # This instance doesn't have audit
Emerging Patterns
AI-Driven Facet Composition
Machine learning could optimize facet composition based on usage patterns:
The facets pattern represents a powerful approach to runtime behavior composition that complements the Adaptive Object Model pattern I discussed previously. While AOM focuses on schema flexibility, facets address the equally important challenge of behavioral composition. The implementations in Rust, TypeScript, and Ruby demonstrate how this pattern can be adapted to different language paradigms while maintaining its core principles. Each language brings unique strengths: Rust’s type safety and performance, TypeScript’s gradual typing and tooling support, and Ruby’s metaprogramming elegance.
Unfortunately, ObjectSpace company that created Voyager went out of business and San Francisco Design Patterns book didn’t gain traction, in part because of its ties to the now-obsolete EJB technology and the performance overhead from using runtime reflection in the extension pattern. Nevertheless, the facets/extension pattern excels in domains requiring high configurability and runtime adaptability. However, it requires careful attention to performance implications and testing strategies. The pattern works best when you have clear separation of concerns and well-defined interfaces between facets. The combination of AOM for schema evolution and facets for behavior composition provides a comprehensive approach to building truly adaptive systems. Together, these patterns enable software that can evolve gracefully with changing requirements while maintaining performance and reliability.
The sample implementations are available at the Dynamic Facets Sample Project, providing working examples in all three languages discussed. These implementations serve as a foundation for building more sophisticated facet-based systems tailored to specific domain requirements.
I have long been interested in the Adaptive Object Model (AOM) pattern and used it in a couple of projects in early 2000s. I have also written about this pattern earlier, which emerged from the work of Ralph Johnson and his colleagues in the late 1990s. It addresses a fundamental challenge in software architecture: how to build systems that can evolve structurally without code changes or downtime. The pattern draws heavily from several foundational concepts in computer science and software engineering. The roots of AOM can be traced back to several influential ideas:
Reflection and Metaprogramming: Early Lisp systems showed the power of treating code as data, enabling programs to modify themselves at runtime. This concept heavily influenced the AOM pattern’s approach to treating metadata as first-class objects.
Type Theory: The work of pioneers like Alonzo Church and Haskell Curry on type systems provided the theoretical foundation for the “type square” pattern that forms AOM’s core structure, where types themselves become objects that can be manipulated.
Database Systems: The entity-attribute-value (EAV) model used in database design influenced AOM’s approach to storing flexible data structures.
Related Patterns
Following are other patterns that are related to AOM:
Facade Pattern: AOM often employs facades to provide simplified interfaces over complex meta-object structures, hiding the underlying complexity from client code.
Strategy Pattern: The dynamic binding of operations in AOM naturally implements the Strategy pattern, allowing algorithms to be selected and modified at runtime.
Composition over Inheritance: AOM uses the principle of favoring composition over inheritance by building complex objects from simpler, configurable components rather than rigid class hierarchies.
Domain-Specific Languages (DSLs): Many AOM implementations provide DSLs for defining entity types and relationships, making the system accessible to domain experts rather than just programmers.
Voyager ORB’s Dynamic Aggregation
In late 1990s/early 2000s, I used Voyager ORB for some personal projects that pioneered a concept of “Dynamic Aggregation” – the ability to attach secondary objects, called facets, to primary objects at runtime. This system demonstrated several key principles that later influenced AOM development:
Runtime Object Extension: Objects could be extended with new capabilities without modifying their original class definitions:
// Voyager ORB example - attaching an account facet to an employee
IEmployee employee = new Employee("joe", "234-44-2678");
IFacets facets = Facets.of(employee);
IAccount account = (IAccount) facets.of(IAccount.class);
account.deposit(2000);
Interface-based Composition: Facets were accessed through interfaces, providing a clean separation between capability and implementation – a principle central to modern AOM.
Distributed Object Mobility: Voyager‘s facet system worked seamlessly across network boundaries, allowing objects and their attached capabilities to move between different machines while maintaining their extended functionality.
Automatic Proxy Generation: Like modern AOM systems, Voyager automatically generated the necessary plumbing code at runtime, using Java’s reflection and bytecode manipulation capabilities.
The Voyager approach influenced distributed computing patterns and demonstrated that dynamic composition could work reliably in production systems. The idea of attaching behavior at runtime through well-defined interfaces is directly applicable to modern AOM implementations. The key insight from Voyager was that objects don’t need to know about all their potential capabilities at compile time. Instead, capabilities can be discovered, attached, and composed dynamically based on runtime requirements – a principle that AOM extends to entire domain models.
Introduction to Adaptive Object Model
Adaptive Object Model is an architectural pattern used in domains requiring dynamic manipulation of metadata and business rules. Unlike traditional object-oriented design where class structures are fixed at compile time, AOM treats class definitions, attributes, relationships, and even business rules as data that can be modified at runtime.
Consider our vehicle example again. In traditional OO design, you might have:
Vehicle
??? Car
? ??? Sedan
? ??? SUV
? ??? Coupe
??? Motorcycle
??? Truck
??? PickupTruck
??? SemiTruck
With AOM, instead of predefined inheritance hierarchies, we use the “type square” pattern:
EntityType: Represents what would traditionally be a class
Entity: Represents what would traditionally be an object instance
PropertyType: Defines the schema for attributes
Property: Holds actual attribute values
This meta-model allows for unlimited extensibility without code changes, making it ideal for domains with rapidly evolving requirements or where different customers need different data models.
The Database Challenge: From Relational to Document
Traditional relational databases present significant challenges for AOM implementations:
Excessive Joins: In a relational AOM implementation, reconstructing a single business object requires joining multiple tables:
Entity table (object instances)
Property table (attribute values)
PropertyType table (attribute metadata)
EntityType table (type definitions)
Schema Rigidity: Relational schemas require predefined table structures, which conflicts with AOM’s goal of runtime flexibility.
Performance Issues: The EAV (Entity-Attribute-Value) pattern commonly used in relational AOM implementations suffers from poor query performance due to the lack of indexing on the “value” column’s varied data types.
Complex Queries: Simple business queries become complex multi-table joins with numerous conditions, making the system difficult to optimize and maintain.
The Document Database Solution
Document databases like MongoDB naturally align with AOM principles:
Schema Flexibility: Documents can contain arbitrary fields without predefined schemas, allowing entity types to evolve dynamically.
Nested Structures: Complex relationships and metadata can be stored within documents, reducing the need for joins.
Rich Querying: Modern document databases provide sophisticated query capabilities while maintaining flexibility.
Indexing: Flexible indexing strategies can be applied to document fields as needed.
Rust Implementation
Let’s implement AOM in Rust, taking advantage of its type safety while maintaining flexibility through traits and enums. Rust’s ownership model and pattern matching make it particularly well-suited for safe metaprogramming.
Schema Evolution: MongoDB’s flexible schema allows entity types to evolve without database migrations.
Rich Querying: MongoDB’s query language supports complex operations on nested documents.
Indexing Strategy: Flexible indexing on any field, including nested properties.
Aggregation Pipeline: Powerful analytics capabilities for business intelligence.
Horizontal Scaling: Built-in sharding support for handling large datasets.
Modern Applications and Future Directions
Contemporary Usage Patterns
Configuration Management: Modern applications use AOM-like patterns for feature flags, A/B testing configurations, and user preference systems.
API Gateway Configuration: Services like Kong and AWS API Gateway use dynamic configuration patterns similar to AOM.
Workflow Engines: Business process management systems employ AOM patterns to define configurable workflows.
Multi-tenant SaaS: AOM enables SaaS applications to provide customizable data models per tenant.
Emerging Technologies
GraphQL Schema Stitching: Dynamic schema composition shares conceptual similarities with AOM’s type composition.
Serverless Functions: Event-driven architectures benefit from AOM’s dynamic behavior binding.
Container Orchestration: Kubernetes uses similar patterns for dynamic resource management and configuration.
Low-Code Platforms: Modern low-code solutions extensively use AOM principles for visual application building.
Performance Considerations and Optimizations
Caching Strategies
class CachedEntityStore {
private cache: Map<string, Entity> = new Map();
private typeCache: Map<string, EntityType> = new Map();
async getEntity(id: string): Promise<Entity | null> {
// Check cache first
if (this.cache.has(id)) {
return this.cache.get(id)!;
}
// Load from database
const entity = await this.store.findEntity(id);
if (entity) {
this.cache.set(id, entity);
}
return entity;
}
invalidateEntity(id: string): void {
this.cache.delete(id);
}
}
Lazy Loading and Materialized Views
For complex entity relationships, implement lazy loading and consider materialized views for frequently accessed computed properties.
Schema Evolution and Versioning
One of the most critical aspects of production AOM systems is managing schema evolution over time. Unlike traditional systems where database migrations handle schema changes, AOM systems must support dynamic evolution while maintaining data integrity and backward compatibility.
AOM systems face unique performance challenges due to their dynamic nature. However, careful optimization can achieve performance comparable to traditional systems while maintaining flexibility.
Caching Strategies
Entity Type Definition Caching: Cache compiled entity types to avoid repeated parsing:
use std::sync::{Arc, RwLock};
use std::collections::HashMap;
pub struct EntityTypeCache {
types: RwLock<HashMap<String, Arc<EntityType>>>,
compiled_operations: RwLock<HashMap<String, CompiledOperation>>,
}
impl EntityTypeCache {
pub fn get_or_compile(&self, type_name: &str) -> Arc<EntityType> {
// Try read lock first
{
let cache = self.types.read().unwrap();
if let Some(entity_type) = cache.get(type_name) {
return entity_type.clone();
}
}
// Compile with write lock
let mut cache = self.types.write().unwrap();
// Double-check pattern to avoid race conditions
if let Some(entity_type) = cache.get(type_name) {
return entity_type.clone();
}
let compiled_type = self.compile_entity_type(type_name);
let arc_type = Arc::new(compiled_type);
cache.insert(type_name.to_string(), arc_type.clone());
arc_type
}
}
Property Access Optimization: Use property maps with optimized access patterns:
class OptimizedEntity {
private propertyCache: Map<string, any> = new Map();
private accessCounts: Map<string, number> = new Map();
getProperty<T>(name: string): T | undefined {
// Track access patterns for optimization
this.accessCounts.set(name, (this.accessCounts.get(name) || 0) + 1);
// Check cache first
if (this.propertyCache.has(name)) {
return this.propertyCache.get(name);
}
// Load from storage and cache frequently accessed properties
const value = this.loadPropertyFromStorage(name);
if (this.accessCounts.get(name)! > 3) {
this.propertyCache.set(name, value);
}
return value;
}
}
Database Optimization
Strategic Indexing: Create indexes based on query patterns rather than all properties:
class LazyEntity
def initialize(entity_type, id)
@entity_type = entity_type
@id = id
@loaded_properties = {}
@all_loaded = false
end
def method_missing(method_name, *args)
property_name = method_name.to_s
if @entity_type.has_property?(property_name)
load_property(property_name) unless @loaded_properties.key?(property_name)
@loaded_properties[property_name]
else
super
end
end
private def load_property(property_name)
# Load single property from database
value = Database.load_property(@id, property_name)
@loaded_properties[property_name] = value
end
end
Weak References for Caches: Prevent memory leaks in entity caches:
use std::sync::Weak;
use std::collections::HashMap;
pub struct WeakEntityCache {
entities: HashMap<String, Weak<Entity>>,
}
impl WeakEntityCache {
pub fn get(&mut self, id: &str) -> Option<Arc<Entity>> {
// Clean up dead references periodically
if let Some(weak_ref) = self.entities.get(id) {
if let Some(entity) = weak_ref.upgrade() {
return Some(entity);
} else {
self.entities.remove(id);
}
}
None
}
pub fn insert(&mut self, id: String, entity: Arc<Entity>) {
self.entities.insert(id, Arc::downgrade(&entity));
}
}
Security and Validation Framework
Security in AOM systems is critical due to the dynamic nature of schema and operations. Traditional security models must be extended to handle runtime modifications safely.
Authorization Framework
Schema Modification Permissions: Control who can modify entity types:
Business Rule Enforcement: Implement complex validation rules across entities:
class BusinessRuleEngine
def initialize
@rules = {}
end
def add_rule(entity_type, rule_name, &block)
@rules[entity_type] ||= {}
@rules[entity_type][rule_name] = block
end
def validate_entity(entity)
errors = []
if rules = @rules[entity.entity_type.name]
rules.each do |rule_name, rule_block|
begin
result = rule_block.call(entity)
unless result.valid?
errors.concat(result.errors.map { |e| "#{rule_name}: #{e}" })
end
rescue => e
errors << "Rule #{rule_name} failed: #{e.message}"
end
end
end
ValidationResult.new(errors.empty?, errors)
end
end
# Usage example
rule_engine = BusinessRuleEngine.new
rule_engine.add_rule('Vehicle', 'valid_year') do |entity|
year = entity.get_property('year')
if year && (year < 1900 || year > Date.current.year + 1)
ValidationResult.new(false, ['Year must be between 1900 and next year'])
else
ValidationResult.new(true, [])
end
end
class SecureOperationBinder {
private allowedOperations: Set<string> = new Set();
private operationSandbox: OperationSandbox;
constructor() {
// Whitelist of safe operations
this.allowedOperations.add('calculate');
this.allowedOperations.add('format');
this.allowedOperations.add('validate');
this.operationSandbox = new OperationSandbox({
allowedGlobals: ['Math', 'Date'],
timeoutMs: 5000,
memoryLimitMB: 10
});
}
bindOperation(name: string, code: string): Operation {
if (!this.allowedOperations.has(name)) {
throw new Error(`Operation ${name} not in whitelist`);
}
// Static analysis for dangerous patterns
if (this.containsDangerousPatterns(code)) {
throw new Error('Operation contains dangerous patterns');
}
return this.operationSandbox.compile(code);
}
private containsDangerousPatterns(code: string): boolean {
const dangerousPatterns = [
/eval\s*\(/,
/Function\s*\(/,
/require\s*\(/,
/import\s+/,
/process\./,
/global\./,
/window\./
];
return dangerousPatterns.some(pattern => pattern.test(code));
}
}
Anti-patterns and Common Pitfalls
Learning from failures is crucial for successful AOM implementations. Here are the most common anti-patterns and how to avoid them.
1. Over-Engineering Stable Domains
Anti-pattern: Applying AOM to domains that rarely change
// DON'T: Using AOM for basic user authentication
const userType = new EntityType('User');
userType.addProperty('username', 'string');
userType.addProperty('passwordHash', 'string');
userType.addProperty('email', 'string');
// Better: Use traditional class for stable domain
class User {
constructor(
public username: string,
public passwordHash: string,
public email: string
) {}
}
When to avoid AOM:
Core business entities that haven’t changed in years
Performance-critical code paths
Simple CRUD operations
Well-established domain models
2. Performance Neglect
Anti-pattern: Ignoring performance implications of dynamic queries
// DON'T: Loading all entity properties for simple operations
async function getEntityName(id) {
const entity = await entityStore.loadFullEntity(id); // Loads everything
return entity.getProperty('name');
}
// Better: Load only needed properties
async function getEntityName(id) {
return await entityStore.loadProperty(id, 'name');
}
Performance Guidelines:
Monitor query performance continuously
Use database profiling tools
Implement property-level lazy loading
Cache frequently accessed entity types
3. Type Explosion
Anti-pattern: Creating too many similar entity types instead of using properties
// DON'T: Creating separate types for minor variations
const sedanType = new EntityType('Sedan');
const suvType = new EntityType('SUV');
const truckType = new EntityType('Truck');
// Better: Use discriminator properties
const vehicleType = new EntityType('Vehicle');
vehicleType.addProperty('bodyType', 'enum', {
values: ['sedan', 'suv', 'truck']
});
Type Design Guidelines:
Prefer composition over type proliferation
Use enums and discriminator fields
Consider type hierarchies carefully
Regular type audits to identify similar types
4. Missing Business Constraints
Anti-pattern: Focusing on technical flexibility while ignoring business rules
# DON'T: Allowing any combination of properties
vehicle = registry.create_entity('Vehicle',
maker: 'Tesla',
fuel_type: 'gasoline', # This makes no sense!
electric: true
)
# Better: Implement cross-property validation
class VehicleValidator
def validate(entity)
if entity.electric? && entity.fuel_type != 'electric'
raise ValidationError, "Electric vehicles cannot have gasoline fuel type"
end
end
end
Regular Architecture Reviews: Schedule periodic reviews of entity type proliferation and usage patterns.
Performance Monitoring: Implement continuous monitoring of query performance and cache hit rates.
Security Audits: Regular audits of property access patterns and operation bindings.
Automated Testing: Comprehensive test suites covering edge cases and error conditions.
Documentation Standards: Maintain clear documentation of business rules and constraints.
Practical Implementation
To demonstrate these concepts in practice, I’ve created a sample project with working implementations in all three languages discussed: AOM Sample Project.
The repository includes:
Rust implementation (cargo run) – Type-safe AOM with memory safety
TypeScript implementation (npx ts-node app.ts) – Gradual typing with modern JavaScript features
The Adaptive Object Model pattern continues to evolve with modern programming languages and database technologies. While the core concepts remain the same, implementation approaches have been refined to take advantage of:
Type safety in languages like Rust and TypeScript
Better performance through caching and optimized data structures
Improved developer experience with modern tooling and language features
Scalable persistence using document databases and modern storage patterns
The combination of dynamic languages with flexible type systems and schema-less databases provides a powerful foundation for building adaptable systems. From my consulting experience implementing AOM on large projects, I’ve seen mixed results that highlight important considerations. The pattern’s flexibility is both its greatest strength and potential weakness. Without proper architectural discipline, teams can easily create overly complex systems with inconsistent entity types and validation rules. The dynamic nature that makes AOM powerful also requires more sophisticated debugging skills and comprehensive testing strategies than traditional static systems. In my early implementations using relational databases, we suffered from performance issues due to the excessive joins required to reconstruct entities from the normalized AOM tables. This was before NoSQL and document-oriented databases became mainstream. Modern document databases have fundamentally changed the viability equation by storing AOM entities naturally without the join penalties that plagued earlier implementations.
The practical implementations available at https://github.com/bhatti/aom-sample demonstrate that AOM is not just theoretical but a viable architectural approach for real-world systems. By studying these examples and adapting them to your specific domain requirements, you can build systems that gracefully evolve with changing business needs.