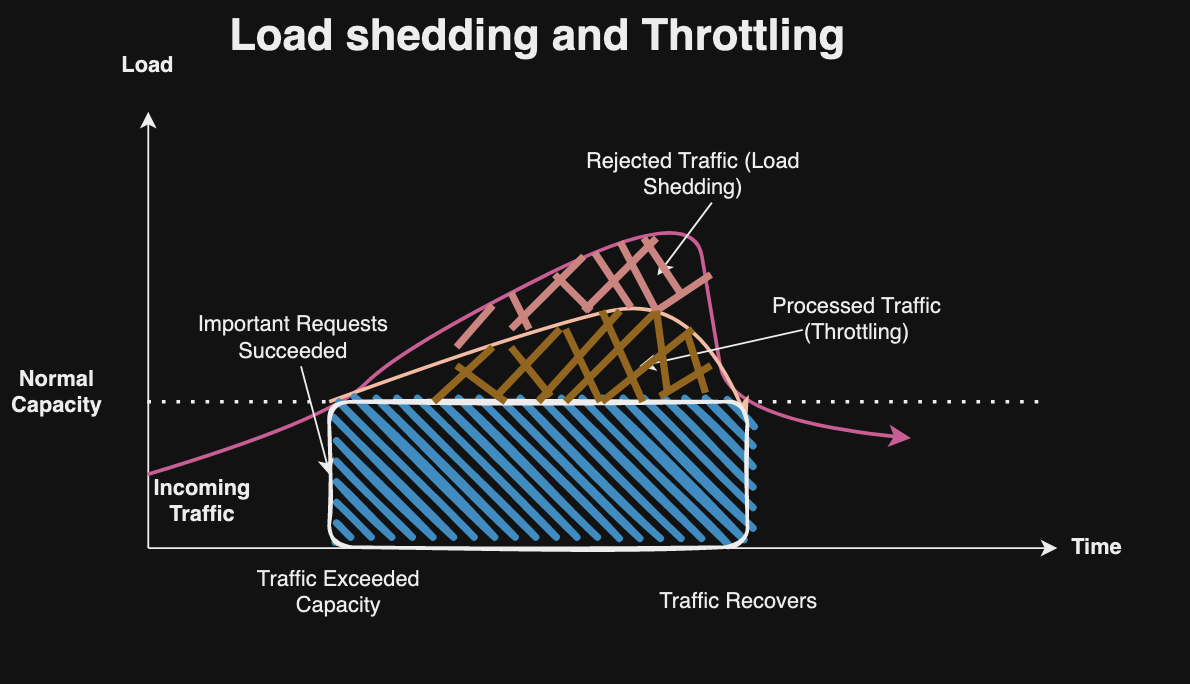
A few years ago, I transferred funds from my bank to one of largest cryptocurrency exchange in US but I noticed my bank account was charged twice. The exchange’s support team was… unhelpful. “Our system shows one transaction,” they insisted. After a week of back-and-forth calls and escalations, they quietly reversed the duplicate charge. This wasn’t an isolated incident, I occasionally see duplicate charges on my credit cards activities. They usually get “fixed automatically in a few days,” but that’s not the point. These aren’t edge cases—they’re symptoms of a fundamental misunderstanding about what idempotency actually means.
Most companies don’t write post-mortems about idempotency failures because they rarely cause outages. Instead, they cause something worse: data corruption, duplicate transactions, and the slow erosion of customer trust. At one trading company, we had duplicate orders execute for millions of dollars during a trading session. We manually caught it and reversed the duplicates with weeks of cleanup, but it was a wake-up call about how dangerous these silent failures can be. The same system also had an aggressive request fingerprinting to prevent duplicates and occasionally it would reject legitimate rapid trades during volatile markets. At another investment firm, a cloud outage forced us to replay thousands of failed order messages. The replay worked as designed for the immediate failure, but it created duplicate entries in downstream systems. What should have been automatic recovery turned into days of manual data cleanup.
The problem isn’t that idempotency is hard to implement. It’s that most engineers fundamentally misunderstand what it means, conflating it with basic duplicate detection and implementing dangerous “check-then-act” patterns that create race conditions.
The Idempotency Illusion
Ask ten engineers to implement idempotency, and you’ll get eleven different implementations. True idempotency means that performing an operation multiple times has the same effect as performing it once, returning the exact same response every time. Not “detecting duplicates.” Not “rejecting retries.” The same effect with the same response—including status codes, headers, and body. Here’s the brutal truth: if your API returns 201 Created on the first call and 409 Conflict on the retry, it’s not idempotent. If it returns different response bodies for the same request, it’s not idempotent. And if two concurrent requests with the same idempotency key can both succeed, you don’t have idempotency—you have a race condition wearing a disguise.
The Twelve Deadly Anti-Patterns
Anti-Pattern 1: Server-Generated Idempotency Keys
This might be the most insidious anti-pattern because it seems logical at first glance:
# THIS IS FUNDAMENTALLY BROKEN - DON'T DO THIS
def create_order(request):
# Generate key from request parameters
idempotency_key = hash(f"{request.user_id}:{request.symbol}:{request.quantity}:{datetime.now().date()}")
if cache.exists(idempotency_key):
return cache.get(idempotency_key)
# Process order...
This prevents legitimate duplicate business operations. A trader trying to buy 100 shares of AAPL twice in the same day gets blocked. At the trading firm I mentioned, they implemented time-windowed keys for “duplicate detection,” using a small time windows. During volatile markets, traders executing rapid legitimate trades were blocked because the system thought they were duplicates.
The fundamental issue: server-generated keys conflate “retry” with “duplicate business operation.” Only the client knows the difference.
The Fix: Idempotency keys MUST be client-generated, period.
// CORRECT: Client generates unique key per logical operation
const idempotencyKey = uuidv4();
// First attempt
await api.createOrder({ symbol: 'AAPL', qty: 100 }, {
headers: { 'Idempotency-Key': idempotencyKey }
});
// Network timeout - safe retry with SAME key
await api.createOrder({ symbol: 'AAPL', qty: 100 }, {
headers: { 'Idempotency-Key': idempotencyKey }
});
// New order - generates NEW key
const newKey = uuidv4();
await api.createOrder({ symbol: 'AAPL', qty: 100 }, {
headers: { 'Idempotency-Key': newKey }
});
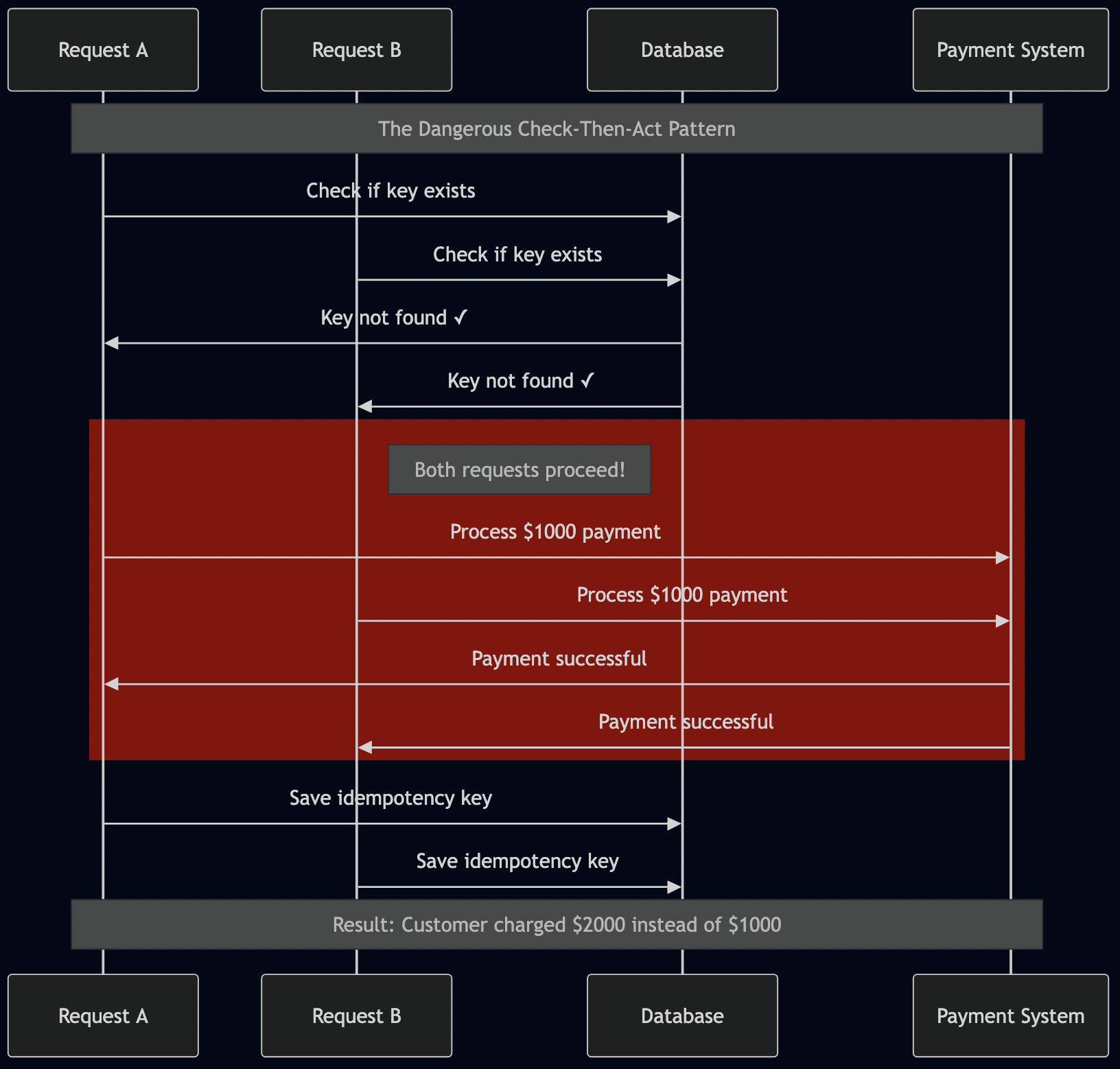
Anti-Pattern 2: The “Check-Then-Act” Race Condition
This is the most common pattern I see in production codebases:
# THIS HAS A CRITICAL RACE CONDITION
def create_payment(request, idempotency_key):
# Check if we've seen this key before
existing = db.query("SELECT * FROM payments WHERE idempotency_key = ?", idempotency_key)
if existing:
return existing
# RACE CONDITION: Another request can execute between check and insert!
payment = process_payment(request)
payment.idempotency_key = idempotency_key
db.save(payment)
return payment
Here’s exactly what happens in the race condition window:
10:00:01.100 - Request A checks: key not found ? 10:00:01.150 - Request B checks: key not found ? 10:00:01.200 - Request A processes payment: $1000 charged 10:00:01.250 - Request B processes payment: $1000 charged AGAIN 10:00:01.300 - Request A saves key 10:00:01.350 - Request B saves key (overwrites A) Customer sees: $2000 charged instead of $1000 System logs: Everything looks normal
The Fix: Use atomic operations or database transactions. The complete implementation is in src/lib.rs and src/sqlite_store.rs in my GitHub project.
Anti-Pattern 3: Not Handling Concurrent In-Progress Requests
// THIS DOESN'T HANDLE CONCURRENT REQUESTS PROPERLY
func HandleRequest(key string, req Request) Response {
if cached := cache.Get(key); cached != nil {
return cached
}
// What if another request with same key arrives NOW?
result := processRequest(req)
cache.Set(key, result)
return result
}
When a request takes 5 seconds to process and a client retries after 2 seconds, both requests execute the business logic. This is exactly what happened in my duplicate payment scenarios.
The Fix: Return a specific status for in-progress requests:
match record.status {
Status::Pending => {
// Return 409 Conflict with Retry-After header
return Err(ApiError::RequestInProgress { retry_after: 2 });
}
Status::Completed => {
// Return the cached response
return Ok(record.cached_response);
}
}
See examples/axum_server.rs for a complete integration example.
Anti-Pattern 4: Optional Idempotency Keys
// THIS IS WRONG - Makes idempotency optional
message CreatePaymentRequest {
optional string idempotency_key = 1; // WRONG!
required string amount = 2;
}
Making idempotency keys optional is like making seatbelts optional—technically possible, but you’ll regret it when things go wrong.
The Fix:
// CORRECT - Required for all mutating operations
message CreatePaymentRequest {
required string idempotency_key = 1; // Client MUST provide
required string amount = 2;
}
For REST APIs, return 400 Bad Request if the Idempotency-Key header is missing on POST/PUT/PATCH requests.
Anti-Pattern 5: Not Preserving Original Failed Responses
// WRONG - Doesn't cache failures
if (result.isSuccess()) {
cache.put(key, result);
return result;
} else {
// Not caching failures means retries might succeed!
return result;
}
A validation error (400) on the first attempt might pass on retry if validation rules change or external state changes. This creates inconsistent behavior that’s impossible to debug.
The Fix: Cache deterministic failures:
- Always cache: 2xx success responses and 4xx client errors
- Never cache: 5xx server errors (allow retries)
- Consider caching: Business logic failures like insufficient funds
Anti-Pattern 6: Using Non-ACID Storage for Idempotency Keys
Using eventually consistent stores like DynamoDB (without strong consistency) or Cassandra creates race conditions even with “correct” code:
Request 1 arrives ? Check key in DynamoDB ? Key not found (stale read) Request 2 arrives ? Check key in DynamoDB ? Key not found (stale read) Both requests process ? DUPLICATE TRANSACTION!
Amazon was one of the first major companies to adopt NoSQL at scale, using it for their shopping cart system. In the early days, I recall seeing items duplicate in my cart or mysteriously disappear and reappear. Amazon eventually solved this by moving to stronger consistency models for critical operations and implementing sophisticated conflict resolution.
Required Properties:
- Strong Consistency: Reads must see all previously committed writes
- Atomic Compare-and-Set: INSERT IF NOT EXISTS must be atomic
- Transaction Support: Key insertion and business logic must be atomic
The Fix: Use ACID-compliant stores like PostgreSQL, MySQL, or Redis with Lua scripts. The src/sqlite_store.rs implementation shows the correct pattern.
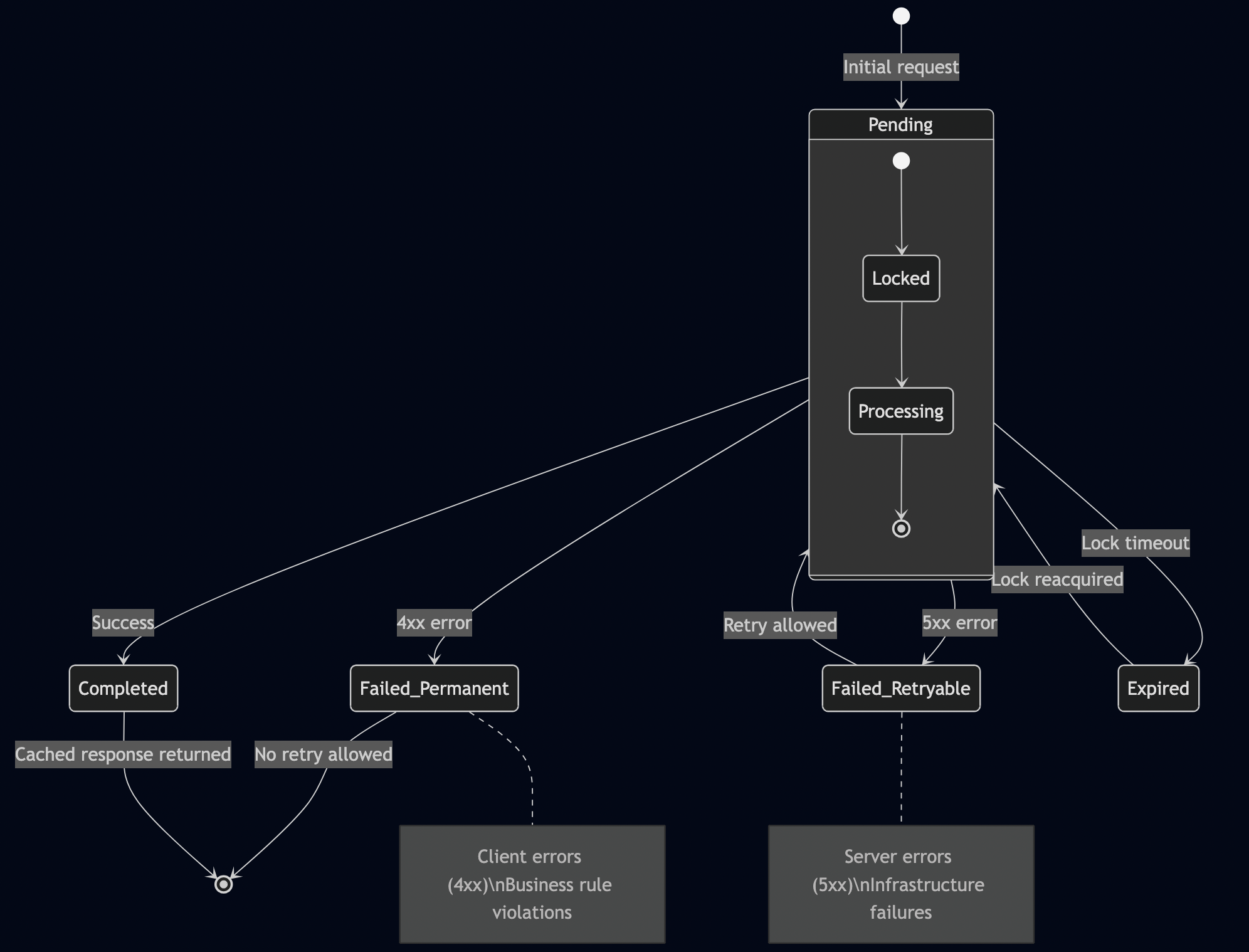
Anti-Pattern 7: Orphaned “PENDING” States Without Recovery
When servers crash mid-processing, PENDING records become eternal blockers:
// Server inserts PENDING record idempotencyStore.insert(key, "PENDING"); // SERVER CRASHES HERE processPayment(); // Never executed idempotencyStore.update(key, "COMPLETED"); // Never reached
This blocks all future retries indefinitely—a silent killer that’s hard to detect until customers complain.
The Fix: Implement timeout-based recovery:
if record.status == Status::Pending {
if record.locked_until < now() {
// Expired PENDING - safe to retry
return Ok(LockResult::Acquired);
} else {
// Still processing
return Ok(LockResult::InProgress { retry_after: 30 });
}
}
Anti-Pattern 8: Missing Request Fingerprinting
Without request fingerprinting, a client bug can reuse a key with different payloads:
# Same key, different amounts - should be rejected! create_payment(key="abc123", amount=100) # First request create_payment(key="abc123", amount=200) # Bug: reused key with different amount
The server sees the cached key, assumes it’s a retry, and returns the first response ($100 charged) while the client thinks it charged $200.
The Fix: Generate and verify request fingerprints:
pub fn generate_fingerprint<T: Serialize>(request: &T) -> String {
let json = serde_json::to_string(request).unwrap_or_default();
let mut hasher = Sha256::new();
hasher.update(json.as_bytes());
format!("{:x}", hasher.finalize())
}
The complete implementation is in src/lib.rs.
Anti-Pattern 9: Ambiguous Infrastructure Failure Handling
When the idempotency store itself fails (network timeout, database down), services lack a consistent strategy:
// WRONG - Ambiguous error handling
if let Err(e) = IsIdempotentCreateTrade(...) {
return err; // Is this a duplicate or a DB failure? Different handling needed!
}
The Fix: Always fail-closed for financial operations:
- Return
503 Service Unavailablefor infrastructure failures - Return
409 Conflictfor duplicates - Include retry-after headers when appropriate
Anti-Pattern 10: Missing Transaction Rollback on Idempotency Save Failure
// BROKEN - Business logic succeeds but idempotency save fails dbTransaction1.begin(); processPayment(); // SUCCESS dbTransaction1.commit(); // Separate transaction for idempotency (WRONG!) dbTransaction2.begin(); saveIdempotencyRecord(key, response); // FAILS! dbTransaction2.commit(); // Now payment processed but not recorded as idempotent
The Fix: Everything in one transaction. See src/sqlite_store.rs for the atomic pattern.
Anti-Pattern 11: Insufficient Idempotency Windows
Purging idempotency records too quickly breaks realistic retry scenarios:
- Mobile apps with poor connectivity might retry after 5 minutes
- Batch jobs might retry failed records after 1 hour
- Manual intervention might happen the next business day
The Fix: Follow Stripe’s 24-hour retention window. Balance storage costs with real-world retry patterns.
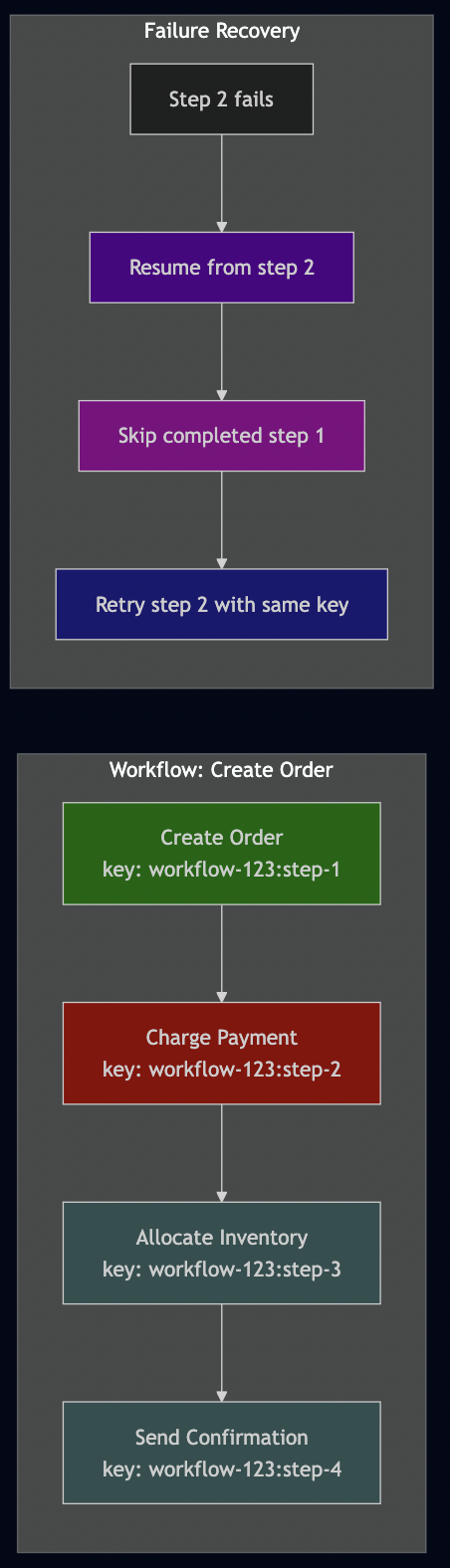
Anti-Pattern 12: No Correlation Between Related Idempotent Operations
Complex workflows require multiple idempotent operations, but there’s no way to track their relationship:
Create Order (key-1) ? Charge Payment (key-2) ? Allocate Inventory (key-3)
If step 2 fails, how do you retry the entire workflow without duplicating step 1?
The Fix: Implement workflow-level idempotency that tracks related operations and allows resumption from failure points.
The Correct Implementation: Following Stripe’s Pattern
After analyzing production failures across multiple companies, I built a complete implementation following Stripe’s proven patterns. The core insight is that idempotency requires atomic lock acquisition:
// From src/lib.rs - The correct atomic pattern
pub async fn process_request<Req, Res, F, Fut>(
&self,
idempotency_key: Option<String>,
user_id: String,
request_path: String,
request_method: String,
request: &Req,
handler: F,
) -> Result<CachedResponse, IdempotencyError>
{
let key = idempotency_key.ok_or(IdempotencyError::MissingIdempotencyKey)?;
let fingerprint = Self::generate_fingerprint(request);
// Step 1: Atomically try to acquire lock
let lock_result = self.store.try_acquire_lock(record).await?;
match lock_result {
LockResult::Acquired => {
// Execute business logic
match handler().await {
Ok((status_code, headers, response)) => {
// Atomically complete the request
self.store.complete_with_response(
&key, &user_id, final_status, Some(cached_response)
).await?;
Ok(cached_response)
}
Err(e) => {
// Release lock to allow retry
self.store.release_lock_on_failure(&key, &user_id, true, None).await?;
Err(e)
}
}
}
LockResult::AlreadyCompleted(response) => Ok(response),
LockResult::InProgress { retry_after } => {
Err(IdempotencyError::RequestInProgress { retry_after })
}
LockResult::KeyReused => {
Err(IdempotencyError::KeyReusedWithDifferentRequest)
}
}
}
The complete implementation includes:
- src/lib.rs: Core middleware with atomic lock acquisition
- src/sqlite_store.rs: ACID-compliant storage backend
- examples/axum_server.rs: Production-ready web server integration
- src/tests.rs: Comprehensive test suite including race condition scenarios
- src/client_sdk.rs: Client SDK with transparent retry logic
The Core Implementation
Here’s the actual sample code that implements the atomic pattern correctly:
Core Middleware (src/lib.rs)
use async_trait::async_trait;
use chrono::{DateTime, Duration, Utc};
use serde::{Deserialize, Serialize};
use sha2::{Digest, Sha256};
use std::collections::HashMap;
use thiserror::Error;
use uuid::Uuid;
#[derive(Error, Debug)]
pub enum IdempotencyError {
#[error("Request in progress (retry after {retry_after} seconds)")]
RequestInProgress { retry_after: u64 },
#[error("Idempotency key reused with different request")]
KeyReusedWithDifferentRequest,
#[error("Missing idempotency key")]
MissingIdempotencyKey,
#[error("Storage error: {0}")]
StorageError(String),
#[error("Invalid idempotency key format")]
InvalidKeyFormat,
#[error("Transaction failed: {0}")]
TransactionFailed(String),
#[error("Concurrent request conflict")]
ConcurrentRequestConflict,
#[error("Handler execution failed: {0}")]
HandlerFailed(String),
}
#[derive(Debug, Clone, Serialize, Deserialize, PartialEq)]
pub enum IdempotencyStatus {
Pending,
Completed,
Failed { is_retryable: bool },
}
#[derive(Debug, Clone, Serialize, Deserialize)]
pub struct IdempotencyRecord {
pub key: String,
pub user_id: String, // Scope keys to user/tenant
pub request_path: String,
pub request_method: String,
pub request_fingerprint: String,
pub status: IdempotencyStatus,
pub response: Option<CachedResponse>,
pub created_at: DateTime<Utc>,
pub expires_at: DateTime<Utc>,
pub locked_until: Option<DateTime<Utc>>,
}
#[derive(Debug, Clone, Serialize, Deserialize)]
pub struct CachedResponse {
pub status_code: u16,
pub headers: HashMap<String, String>,
pub body: Vec<u8>,
}
/// Result of attempting to acquire an idempotency lock
#[derive(Debug)]
pub enum LockResult {
/// Lock acquired successfully, safe to proceed
Acquired,
/// Request already completed, return cached response
AlreadyCompleted(CachedResponse),
/// Request is currently being processed by another worker
InProgress { retry_after: u64 },
/// Key reused with different request payload
KeyReused,
/// Failed permanently, return cached error response
FailedPermanently(CachedResponse),
}
/// Trait for idempotency storage backends
#[async_trait]
pub trait IdempotencyStore: Send + Sync {
/// Atomically attempt to acquire a lock for processing
/// This must be an atomic operation that either:
/// 1. Creates a new PENDING record and returns Acquired
/// 2. Returns the current state if record exists
async fn try_acquire_lock(
&self,
record: IdempotencyRecord,
) -> Result<LockResult, IdempotencyError>;
/// Atomically update record with final result and release lock
/// This must happen in a single transaction with business logic
async fn complete_with_response(
&self,
key: &str,
user_id: &str,
status: IdempotencyStatus,
response: Option<CachedResponse>,
) -> Result<(), IdempotencyError>;
/// Atomically release lock on failure (for retryable errors)
async fn release_lock_on_failure(
&self,
key: &str,
user_id: &str,
is_retryable: bool,
response: Option<CachedResponse>,
) -> Result<(), IdempotencyError>;
/// Get a record by key and user_id (for debugging/monitoring)
async fn get(
&self,
key: &str,
user_id: &str,
) -> Result<Option<IdempotencyRecord>, IdempotencyError>;
/// Delete expired records (maintenance operation)
async fn cleanup_expired(&self) -> Result<usize, IdempotencyError>;
/// Execute within a transaction (for stores that support it)
async fn execute_in_transaction<F, T>(&self, f: F) -> Result<T, IdempotencyError>
where
F: FnOnce() -> std::pin::Pin<Box<dyn std::future::Future<Output = Result<T, IdempotencyError>> + Send>> + Send,
T: Send;
}
/// Main idempotency middleware
#[derive(Clone)]
pub struct IdempotencyMiddleware<S: IdempotencyStore + Clone> {
store: S,
ttl: Duration,
lock_timeout: Duration,
}
impl<S: IdempotencyStore + Clone> IdempotencyMiddleware<S> {
pub fn new(store: S) -> Self {
Self {
store,
ttl: Duration::hours(24), // Stripe's 24-hour retention
lock_timeout: Duration::seconds(30), // Max time to hold lock
}
}
pub fn with_config(store: S, ttl: Duration, lock_timeout: Duration) -> Self {
Self {
store,
ttl,
lock_timeout,
}
}
/// Get access to the underlying store (for testing)
#[cfg(test)]
pub fn store(&self) -> &S {
&self.store
}
/// Validate idempotency key format (UUID v4)
fn validate_key(key: &str) -> Result<(), IdempotencyError> {
Uuid::parse_str(key)
.map_err(|_| IdempotencyError::InvalidKeyFormat)?;
Ok(())
}
/// Generate request fingerprint using SHA-256
pub fn generate_fingerprint<T: Serialize>(request: &T) -> String {
let json = serde_json::to_string(request).unwrap_or_default();
let mut hasher = Sha256::new();
hasher.update(json.as_bytes());
format!("{:x}", hasher.finalize())
}
/// Process a request with idempotency guarantees
/// This implements the correct atomic pattern to avoid all race conditions
pub async fn process_request<Req, Res, F, Fut>(
&self,
idempotency_key: Option<String>,
user_id: String,
request_path: String,
request_method: String,
request: &Req,
handler: F,
) -> Result<CachedResponse, IdempotencyError>
where
Req: Serialize,
Res: Serialize,
F: FnOnce() -> Fut,
Fut: std::future::Future<Output = Result<(u16, HashMap<String, String>, Res), IdempotencyError>>,
S: Clone,
{
// Require idempotency key for mutating operations
let key = idempotency_key
.ok_or(IdempotencyError::MissingIdempotencyKey)?;
Self::validate_key(&key)?;
let fingerprint = Self::generate_fingerprint(request);
let now = Utc::now();
// Create the record we want to insert
let record = IdempotencyRecord {
key: key.clone(),
user_id: user_id.clone(),
request_path: request_path.clone(),
request_method: request_method.clone(),
request_fingerprint: fingerprint.clone(),
status: IdempotencyStatus::Pending,
response: None,
created_at: now,
expires_at: now + self.ttl,
locked_until: Some(now + self.lock_timeout),
};
// Step 1: Atomically try to acquire lock
let lock_result = self.store.try_acquire_lock(record).await?;
match lock_result {
LockResult::Acquired => {
// We got the lock - safe to proceed with business logic
tracing::debug!("Lock acquired for key: {}", key);
// Execute business logic
match handler().await {
Ok((status_code, headers, response)) => {
// Success - cache the response
let response_body = serde_json::to_vec(&response)
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
let cached_response = CachedResponse {
status_code,
headers,
body: response_body,
};
// Determine final status based on HTTP status code
let final_status = if status_code >= 500 {
IdempotencyStatus::Failed { is_retryable: true }
} else if status_code >= 400 {
IdempotencyStatus::Failed { is_retryable: false }
} else {
IdempotencyStatus::Completed
};
// Atomically complete the request
self.store.complete_with_response(
&key,
&user_id,
final_status,
Some(cached_response.clone()),
).await?;
tracing::debug!("Request completed successfully for key: {}", key);
Ok(cached_response)
}
Err(e) => {
// Handler failed - determine if retryable
let is_retryable = match &e {
IdempotencyError::StorageError(_) => true,
IdempotencyError::TransactionFailed(_) => true,
IdempotencyError::HandlerFailed(_) => true,
_ => false,
};
// Release lock to allow retry
self.store.release_lock_on_failure(
&key,
&user_id,
is_retryable,
None, // No response to cache for errors
).await?;
tracing::warn!("Handler failed for key: {} - error: {}", key, e);
Err(e)
}
}
}
LockResult::AlreadyCompleted(response) => {
// Request was already processed successfully
tracing::debug!("Returning cached response for key: {}", key);
Ok(response)
}
LockResult::InProgress { retry_after } => {
// Another request is currently processing this key
tracing::debug!("Request in progress for key: {}, retry after: {}s", key, retry_after);
Err(IdempotencyError::RequestInProgress { retry_after })
}
LockResult::KeyReused => {
// Key was reused with different request payload
tracing::warn!("Key reused with different request for key: {}", key);
Err(IdempotencyError::KeyReusedWithDifferentRequest)
}
LockResult::FailedPermanently(response) => {
// Request failed permanently, return cached error
tracing::debug!("Returning cached permanent failure for key: {}", key);
Ok(response)
}
}
}
}
// Storage implementations
pub mod sqlite_store;
#[cfg(feature = "axum-integration")]
pub mod axum_integration;
#[cfg(feature = "grpc")]
pub mod grpc_integration;
// Re-export for convenience
pub use sqlite_store::SqliteIdempotencyStore;
#[cfg(test)]
mod tests;
Storage Backend (src/sqlite_store.rs)
use crate::{
IdempotencyError, IdempotencyRecord, IdempotencyStatus, IdempotencyStore,
CachedResponse, LockResult
};
use async_trait::async_trait;
use chrono::{DateTime, Utc};
use sqlx::{Pool, Sqlite, SqlitePool, Row};
use std::sync::Arc;
use tokio::sync::Mutex;
#[derive(Clone)]
pub struct SqliteIdempotencyStore {
pool: Pool<Sqlite>,
// In-memory lock for the entire store to ensure atomicity
transaction_lock: Arc<Mutex<()>>,
}
impl SqliteIdempotencyStore {
pub async fn new(database_url: &str) -> Result<Self, IdempotencyError> {
let pool = SqlitePool::connect(database_url)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
// Create tables with proper indexes
sqlx::query(
r#"
CREATE TABLE IF NOT EXISTS idempotency_records (
key TEXT NOT NULL,
user_id TEXT NOT NULL,
request_path TEXT NOT NULL,
request_method TEXT NOT NULL,
request_fingerprint TEXT NOT NULL,
status TEXT NOT NULL,
response_status_code INTEGER,
response_headers TEXT,
response_body BLOB,
created_at TEXT NOT NULL,
expires_at TEXT NOT NULL,
locked_until TEXT,
PRIMARY KEY (key, user_id)
);
CREATE INDEX IF NOT EXISTS idx_expires_at ON idempotency_records(expires_at);
CREATE INDEX IF NOT EXISTS idx_user_id ON idempotency_records(user_id);
CREATE INDEX IF NOT EXISTS idx_locked_until ON idempotency_records(locked_until);
"#
)
.execute(&pool)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(Self {
pool,
transaction_lock: Arc::new(Mutex::new(())),
})
}
fn serialize_status(status: &IdempotencyStatus) -> String {
match status {
IdempotencyStatus::Pending => "pending".to_string(),
IdempotencyStatus::Completed => "completed".to_string(),
IdempotencyStatus::Failed { is_retryable } => {
format!("failed:{}", if *is_retryable { "retryable" } else { "permanent" })
}
}
}
fn deserialize_status(status: &str) -> IdempotencyStatus {
match status {
"pending" => IdempotencyStatus::Pending,
"completed" => IdempotencyStatus::Completed,
"failed:retryable" => IdempotencyStatus::Failed { is_retryable: true },
"failed:permanent" => IdempotencyStatus::Failed { is_retryable: false },
_ => IdempotencyStatus::Pending,
}
}
async fn record_from_row(row: &sqlx::sqlite::SqliteRow) -> Result<IdempotencyRecord, IdempotencyError> {
let status_str: String = row.try_get("status")
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
let status = Self::deserialize_status(&status_str);
let response = if let Some(status_code) = row.try_get::<Option<i32>, _>("response_status_code")
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?
{
let headers_json: Option<String> = row.try_get("response_headers")
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
let headers = headers_json
.and_then(|h| serde_json::from_str(&h).ok())
.unwrap_or_default();
let body: Option<Vec<u8>> = row.try_get("response_body")
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Some(CachedResponse {
status_code: status_code as u16,
headers,
body: body.unwrap_or_default(),
})
} else {
None
};
Ok(IdempotencyRecord {
key: row.try_get("key").map_err(|e| IdempotencyError::StorageError(e.to_string()))?,
user_id: row.try_get("user_id").map_err(|e| IdempotencyError::StorageError(e.to_string()))?,
request_path: row.try_get("request_path").map_err(|e| IdempotencyError::StorageError(e.to_string()))?,
request_method: row.try_get("request_method").map_err(|e| IdempotencyError::StorageError(e.to_string()))?,
request_fingerprint: row.try_get("request_fingerprint").map_err(|e| IdempotencyError::StorageError(e.to_string()))?,
status,
response,
created_at: {
let dt_str: String = row.try_get("created_at").map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
DateTime::parse_from_rfc3339(&dt_str)
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?
.with_timezone(&Utc)
},
expires_at: {
let dt_str: String = row.try_get("expires_at").map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
DateTime::parse_from_rfc3339(&dt_str)
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?
.with_timezone(&Utc)
},
locked_until: {
let dt_str: Option<String> = row.try_get("locked_until").map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
dt_str
.and_then(|s| DateTime::parse_from_rfc3339(&s).ok())
.map(|dt| dt.with_timezone(&Utc))
},
})
}
}
#[async_trait]
impl IdempotencyStore for SqliteIdempotencyStore {
/// Atomically attempt to acquire a lock for processing
async fn try_acquire_lock(
&self,
record: IdempotencyRecord,
) -> Result<LockResult, IdempotencyError> {
// Use a global lock to ensure atomicity (in production, rely on DB transactions)
let _lock = self.transaction_lock.lock().await;
let mut tx = self.pool.begin()
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
let now = Utc::now();
// First, check if record exists
let existing_row = sqlx::query(
r#"
SELECT key, user_id, request_path, request_method,
request_fingerprint, status, response_status_code,
response_headers, response_body, created_at,
expires_at, locked_until
FROM idempotency_records
WHERE key = ? AND user_id = ?
"#
)
.bind(&record.key)
.bind(&record.user_id)
.fetch_optional(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
let result = if let Some(row) = existing_row {
let existing = Self::record_from_row(&row).await?;
// Check fingerprint match
if existing.request_fingerprint != record.request_fingerprint {
Ok(LockResult::KeyReused)
} else {
// Check current status and lock
match existing.status {
IdempotencyStatus::Completed => {
if let Some(response) = existing.response {
Ok(LockResult::AlreadyCompleted(response))
} else {
// If completed but no response, need to reprocess
// Update existing record to pending with new lock
sqlx::query(
r#"
UPDATE idempotency_records
SET status = ?, locked_until = ?, created_at = ?
WHERE key = ? AND user_id = ?
"#
)
.bind(Self::serialize_status(&IdempotencyStatus::Pending))
.bind(record.locked_until.map(|dt| dt.to_rfc3339()))
.bind(record.created_at.to_rfc3339())
.bind(&record.key)
.bind(&record.user_id)
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(LockResult::Acquired)
}
}
IdempotencyStatus::Failed { is_retryable: false } => {
if let Some(response) = existing.response {
Ok(LockResult::FailedPermanently(response))
} else {
// If failed but no response, need to reprocess
// Update existing record to pending with new lock
sqlx::query(
r#"
UPDATE idempotency_records
SET status = ?, locked_until = ?, created_at = ?
WHERE key = ? AND user_id = ?
"#
)
.bind(Self::serialize_status(&IdempotencyStatus::Pending))
.bind(record.locked_until.map(|dt| dt.to_rfc3339()))
.bind(record.created_at.to_rfc3339())
.bind(&record.key)
.bind(&record.user_id)
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(LockResult::Acquired)
}
}
IdempotencyStatus::Failed { is_retryable: true } => {
// Allow retry for retryable failures
// Update existing record to pending with new lock
sqlx::query(
r#"
UPDATE idempotency_records
SET status = ?, locked_until = ?, created_at = ?
WHERE key = ? AND user_id = ?
"#
)
.bind(Self::serialize_status(&IdempotencyStatus::Pending))
.bind(record.locked_until.map(|dt| dt.to_rfc3339()))
.bind(record.created_at.to_rfc3339())
.bind(&record.key)
.bind(&record.user_id)
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(LockResult::Acquired)
}
IdempotencyStatus::Pending => {
// Check if lock is still active
if let Some(locked_until) = existing.locked_until {
if locked_until > now {
let retry_after = (locked_until - now).num_seconds() as u64;
Ok(LockResult::InProgress { retry_after })
} else {
// Lock expired, allow reprocessing
// Update existing record to pending with new lock
sqlx::query(
r#"
UPDATE idempotency_records
SET status = ?, locked_until = ?, created_at = ?
WHERE key = ? AND user_id = ?
"#
)
.bind(Self::serialize_status(&IdempotencyStatus::Pending))
.bind(record.locked_until.map(|dt| dt.to_rfc3339()))
.bind(record.created_at.to_rfc3339())
.bind(&record.key)
.bind(&record.user_id)
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(LockResult::Acquired)
}
} else {
// No lock timeout, allow reprocessing
// Update existing record to pending with new lock
sqlx::query(
r#"
UPDATE idempotency_records
SET status = ?, locked_until = ?, created_at = ?
WHERE key = ? AND user_id = ?
"#
)
.bind(Self::serialize_status(&IdempotencyStatus::Pending))
.bind(record.locked_until.map(|dt| dt.to_rfc3339()))
.bind(record.created_at.to_rfc3339())
.bind(&record.key)
.bind(&record.user_id)
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(LockResult::Acquired)
}
}
}
}
} else {
// Insert new record
let status = Self::serialize_status(&record.status);
let headers_json = record.response.as_ref()
.map(|r| serde_json::to_string(&r.headers).unwrap_or_default());
sqlx::query(
r#"
INSERT INTO idempotency_records (
key, user_id, request_path, request_method,
request_fingerprint, status, response_status_code,
response_headers, response_body, created_at,
expires_at, locked_until
) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
"#
)
.bind(&record.key)
.bind(&record.user_id)
.bind(&record.request_path)
.bind(&record.request_method)
.bind(&record.request_fingerprint)
.bind(status)
.bind(record.response.as_ref().map(|r| r.status_code as i32))
.bind(headers_json)
.bind(record.response.as_ref().map(|r| r.body.clone()))
.bind(record.created_at.to_rfc3339())
.bind(record.expires_at.to_rfc3339())
.bind(record.locked_until.map(|dt| dt.to_rfc3339()))
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(LockResult::Acquired)
};
// Handle transaction based on result
match &result {
Ok(LockResult::KeyReused) | Ok(LockResult::InProgress { .. }) => {
// These cases don't modify the database, rollback to be safe
tx.rollback().await.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
}
Ok(LockResult::AlreadyCompleted(_)) | Ok(LockResult::FailedPermanently(_)) => {
// These cases just read data, rollback to be safe
tx.rollback().await.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
}
Ok(LockResult::Acquired) => {
// Successfully acquired lock, commit the changes
tx.commit().await.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
}
Err(_) => {
// Error occurred, rollback
tx.rollback().await.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
}
}
result
}
/// Atomically update record with final result and release lock
async fn complete_with_response(
&self,
key: &str,
user_id: &str,
status: IdempotencyStatus,
response: Option<CachedResponse>,
) -> Result<(), IdempotencyError> {
let _lock = self.transaction_lock.lock().await;
let mut tx = self.pool.begin()
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
let status_str = Self::serialize_status(&status);
let headers_json = response.as_ref()
.map(|r| serde_json::to_string(&r.headers).unwrap_or_default());
sqlx::query(
r#"
UPDATE idempotency_records
SET status = ?,
response_status_code = ?,
response_headers = ?,
response_body = ?,
locked_until = NULL
WHERE key = ? AND user_id = ?
"#
)
.bind(status_str)
.bind(response.as_ref().map(|r| r.status_code as i32))
.bind(headers_json)
.bind(response.as_ref().map(|r| r.body.clone()))
.bind(key)
.bind(user_id)
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
tx.commit().await.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(())
}
/// Atomically release lock on failure
async fn release_lock_on_failure(
&self,
key: &str,
user_id: &str,
is_retryable: bool,
response: Option<CachedResponse>,
) -> Result<(), IdempotencyError> {
let _lock = self.transaction_lock.lock().await;
let mut tx = self.pool.begin()
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
let status = IdempotencyStatus::Failed { is_retryable };
let status_str = Self::serialize_status(&status);
let headers_json = response.as_ref()
.map(|r| serde_json::to_string(&r.headers).unwrap_or_default());
sqlx::query(
r#"
UPDATE idempotency_records
SET status = ?,
response_status_code = ?,
response_headers = ?,
response_body = ?,
locked_until = NULL
WHERE key = ? AND user_id = ?
"#
)
.bind(status_str)
.bind(response.as_ref().map(|r| r.status_code as i32))
.bind(headers_json)
.bind(response.as_ref().map(|r| r.body.clone()))
.bind(key)
.bind(user_id)
.execute(&mut *tx)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
tx.commit().await.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(())
}
async fn get(
&self,
key: &str,
user_id: &str,
) -> Result<Option<IdempotencyRecord>, IdempotencyError> {
let row = sqlx::query(
r#"
SELECT key, user_id, request_path, request_method,
request_fingerprint, status, response_status_code,
response_headers, response_body, created_at,
expires_at, locked_until
FROM idempotency_records
WHERE key = ? AND user_id = ?
"#
)
.bind(key)
.bind(user_id)
.fetch_optional(&self.pool)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
match row {
Some(row) => Ok(Some(Self::record_from_row(&row).await?)),
None => Ok(None),
}
}
async fn cleanup_expired(&self) -> Result<usize, IdempotencyError> {
let now = Utc::now().to_rfc3339();
let result = sqlx::query(
"DELETE FROM idempotency_records WHERE expires_at < ?"
)
.bind(now)
.execute(&self.pool)
.await
.map_err(|e| IdempotencyError::StorageError(e.to_string()))?;
Ok(result.rows_affected() as usize)
}
async fn execute_in_transaction<F, T>(&self, f: F) -> Result<T, IdempotencyError>
where
F: FnOnce() -> std::pin::Pin<Box<dyn std::future::Future<Output = Result<T, IdempotencyError>> + Send>> + Send,
T: Send,
{
let _lock = self.transaction_lock.lock().await;
let tx = self.pool.begin()
.await
.map_err(|e| IdempotencyError::TransactionFailed(e.to_string()))?;
let result = f().await;
match result {
Ok(value) => {
tx.commit().await.map_err(|e| IdempotencyError::TransactionFailed(e.to_string()))?;
Ok(value)
}
Err(e) => {
tx.rollback().await.map_err(|e| IdempotencyError::TransactionFailed(e.to_string()))?;
Err(e)
}
}
}
}
The SDK Solution: Making Idempotency Invisible
While requiring clients to generate and manage idempotency keys is correct, it places a burden on developers. Modern cloud providers solve this by embedding idempotency into their SDKs, making it transparent to developers. AWS automatically generates client tokens:
# AWS SDK automatically handles idempotency
ec2_client = boto3.client('ec2')
# The SDK generates a ClientToken internally
response = ec2_client.run_instances(
ImageId='ami-12345',
MinCount=1,
MaxCount=1,
# No idempotency key needed - SDK handles it
)
# On network failure, the SDK safely retries with the same ClientToken
You can build the same experience. The src/client_sdk.rs file shows how to implement transparent idempotency in a client SDK:
// Users don't need to think about idempotency
let client = IdempotentClient::new("https://api.example.com");
// The SDK handles everything:
// - Generates idempotency key
// - Retries with exponential backoff + jitter
// - Reuses same key for retries
// - Respects rate limits
let order = client.call(
"POST",
"/orders",
&CreateOrderRequest {
symbol: "AAPL",
quantity: 100,
}
).await?;
Industry Lessons
The Hidden Cost
Idempotency failures rarely cause outages, which is why they often go unnoticed until they accumulate into bigger problems. But the cost is real:
- Customer trust erosion: Duplicate charges damage credibility
- Support overhead: Each duplicate transaction generates support tickets
- Regulatory risk: Financial duplicate transactions can trigger compliance issues
- Data corruption: Inconsistent state that’s expensive to clean up
The False Sense of Security
Most teams implement basic duplicate detection and call it “idempotency.” They check a box on their architecture review and move on. Meanwhile, the race conditions and edge cases silently create problems that surface weeks or months later.
The Operational Reality
Even when implemented correctly, idempotency requires operational discipline:
- Monitoring key collision rates (possible client bugs)
- Alerting on lock timeout occurrences (performance issues)
- Tracking retry patterns (client behavior insights)
- Regular cleanup of expired records (storage management)
The Bottom Line
True idempotency isn’t about preventing duplicates—it’s about providing a consistent, predictable API that clients can safely retry. The difference between “duplicate detection” and real idempotency is the difference between a system that mostly works and one that always works. After seeing too many production incidents caused by misunderstood idempotency, I hope this guide prevents others from making the same expensive mistakes. The patterns I’ve shown here are battle-tested across multiple companies and handle the edge cases that trip up most implementations.
The complete implementation with a storage backend, framework integrations, and deployment examples is available at github.com/bhatti/idempotency-rs.