Online services experiencing rapid growth often encounter abrupt surges in traffic and may become targets of Distributed Denial of Service (DDoS) attacks orchestrated by malicious actors or inadvertently due to self-induced bugs. Mitigating these challenges to ensure high availability requires meticulous architectural practices, including implementing caching mechanisms, leveraging Content Delivery Networks (CDNs), Web Application Firewalls (WAFs), deploying queuing systems, employing load balancing strategies, implementing robust monitoring and alerting systems, and incorporating autoscaling capabilities. However, in this context, we will focus specifically on techniques related to load shedding and throttling to manage various traffic shapes effectively.
1. Traffic Patterns and Shapes
Traffic patterns refer to the manner in which user requests or tasks interact with your online service throughout a given period. These requests or tasks can vary in characteristics, including the rate of requests (TPS), concurrency, and the patterns of request flow, such as bursts of traffic. These patterns must be analyzed for scaling your service effectively and providing high availability.
Here’s a breakdown of some common traffic shapes:
- Normal Traffic: defines baseline level of traffic pattern that a service receives most of the time based on regular user activity.
- Peak Traffic: defines recurring period of high traffic based on daily or weekly user activity patterns. Auto-scaling rules can be set up to automatically allocate pre-provisioned additional resources in response to anticipated peaks in traffic.
- Off-Peak Traffic: refers to periods of low or minimal traffic, such as during late-night hours or weekends. Auto-scaling rules can be set to scale down or consolidating resources during periods of low demand help minimize operational costs while maintaining adequate performance levels.
- Burst Traffic: defines sudden, short-lived spikes in traffic that might be caused by viral contents or promotional campaigns. Auto-scaling rules can be configured to allocate extra resources in reaction to burst traffic. However, scaling resources might not happen swiftly enough to match the duration of the burst traffic. Therefore, it’s typically recommended to maintain surplus capacity to effectively handle burst traffic situations.
- Seasonal Traffic: defines traffic patterns based on specific seasons, holidays or events such as Black Friday or back-to-school periods. This requires strategies similar to peak traffic for allocating pre-provisioned additional resources.
- Steady Growth: defines gradual and consistent increase in traffic over time based on organic growth or marketing campaigns. This requires proactive monitoring to ensure resources keep pace with demand.
Classifying Requests
Incoming requests or tasks can be identified and categorized based on various contextual factors, such as the identity of the requester, the specific operation being requested, or other relevant parameters. This classification enables the implementation of appropriate measures, such as throttling or load shedding policies, to manage the flow of requests effectively.
Additional Considerations:
- Traffic Patterns Can Combine: Real-world traffic patterns are often a combination of these shapes, requiring flexible and adaptable scaling strategies.
- Monitoring and Alerting: Continuously monitor traffic patterns to identify trends early and proactively adjust your scaling strategy. Set up alerts and notifications to inform about sudden traffic surges or potential DDoS attacks so you can take timely action.
- Incident Response Plan: Develop a well-defined incident response plan that outlines the steps for communication protocols, mitigation strategies, engaging stakeholders, and recovery procedures.
- Cost-Effectiveness: Balance scaling needs with cost optimization to avoid over-provisioning resources during low traffic periods.
2. Throttling and Rate Limiting
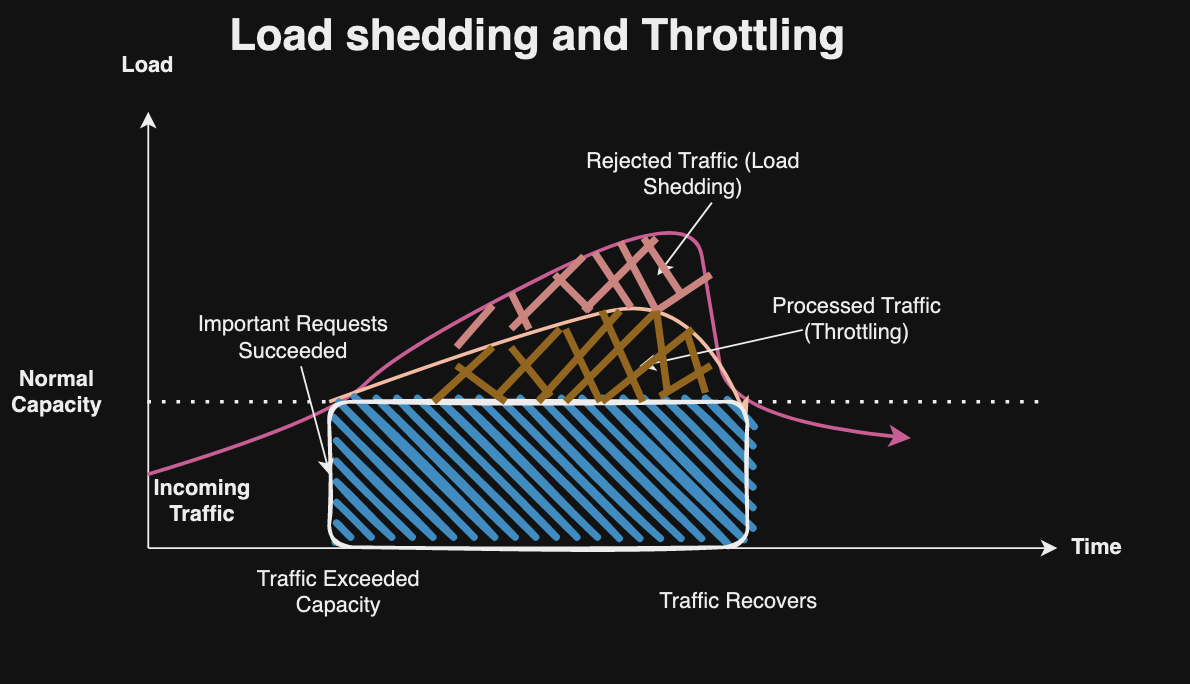
Throttling controls the rate of traffic flow or resource consumption within a system to prevent overload or degradation of service. Throttling enforces quota limits and protects system overload by limiting the amount of resources (CPU, memory, network bandwidth) a single user or client can consume within a specific time frame. Throttling ensures efficient resource utilization, allowing the service to handle more users in a predictable manner. This ensures better fairness and stability while preventing a noisy neighbor problem where unpredictable spikes or slowdowns caused by heavy users. Throttling can be implemented by API Rate Limiting on the number of API requests a client can make with a given time window; by limiting maximum bandwidth allowed for various network traffic; by limiting rate of read/write; or by limiting the number of concurrent connections for a server to prevent overload.
These throttling and rate limiting measures can be applied to both anonymous and authenticated requests as follows:
- Anonymous Requests:
- Rate limiting: Implement rate limiting based on client IP addresses or other identifiers within a specific time window, preventing clients from overwhelming the system.
- Concurrency limits: Set limits on the maximum number of concurrent connections or requests that can be processed simultaneously.
- Server-side throttling: Apply throttling mechanisms at the server level, such as queue-based rate limiting or token bucket algorithms, to control the overall throughput of incoming requests.
- Authenticated Requests:
- User-based rate limiting: Implement rate limiting based on user identities or API keys, ensuring that authenticated users cannot exceed specified request limits.
- Prioritized throttling: Apply different throttling rules or limits based on user roles, subscription tiers, or other criteria, allowing higher priority requests to be processed first during peak loads.
- Circuit breakers: Implement circuit breakers to temporarily disable or throttle load from specific services or components that are experiencing high latency or failures, preventing cascading failures.
2.1 Error Response and Headers
When a request exceeds the rate limit, the server typically returns a 429 HTTP status code indicating that the request has been throttled or rate-limited due to Too Many Requests. The server may also return HTTP headers such as Retry-After, X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Used, X-RateLimit-Reset, and X-RateLimit-Resource.
3. Load Shedding
Load shedding is used to prioritize and manage system resources during periods of high demand or overload. It may discard or defer non-critical tasks or requests to ensure the continued operation of essential functions. Load shedding helps maintain system stability and prevents cascading failures by reallocating resources to handle the most critical tasks first. Common causes of unexpected events that require shedding to prevent overloading system resources include:
- Traffic Spikes: sudden and significant increases in the volume of incoming traffic due to various reasons, such as viral content, marketing campaigns, sudden popularity, or events.
- DDoS (Distributed Denial of Service): deliberate attempts to disrupt the normal functioning of a targeted server, service, or network by overwhelming it with a flood of traffic. A DDoS attack can be orchestrated by an attacker who commands a vast botnet comprising thousands of compromised devices, including computers, IoT devices, or servers. Additionally, misconfigurations, software bugs, or unforeseen interactions among system components such as excessive retries without exponential delays that can also lead to accidental DDoS attacks.
Here is how excessive load for anonymous and authenticated requests can be shed:
- Anonymous Requests: Drop requests during extreme load conditions or when server capacity is reached, drop a percentage of incoming requests to protect the system from overload. This can be done randomly or based on specific criteria such as request types, and headers. Alternatively, service can degrade non-critical features or functionalities temporarily to reduce the overall system load and prioritize essential services.
- Authenticated Requests: Apply load shedding rules based on user roles, subscription tiers, or other criteria, prioritizing requests from high-value users or critical services.
3.1 Error Response
When a request exceeds the rate limit, the server typically returns a 503 HTTP status code indicating that the request has been throttled or rate-limited due to Too Many Requests. The server may also return HTTP headers such as Retry-After, other headers specifically employed for throttling are less prevalent in the context of load shedding. Unlike throttling errors, which fall under user-errors with 4XX error codes, load shedding is categorized as a server error with 5XX error codes. Consequently, load shedding requires more aggressive monitoring and alerting compared to throttling errors. Throttling errors, on the other hand, can be considered expected behavior as a means to address noisy neighbor problems and maintain high availability.
4. Additional Techniques for Throttling and Load Shedding
Throttling, rate-limiting and load shedding measures described above can be used to handle high traffic and to prevent resource exhaustion in distributed systems. Here are common techniques that can be used to implement these measures:
- Admission Control: Set up thresholds for maximum concurrent requests or resource utilization.
- Request Classification and Prioritization: Classify requests based on priority, user type, or criticality and then dropping low-priority requests when the thresholds for capacity are exceeded.
- Backpressure and Queue Management: Use a fixed-length queues to buffer incoming requests during high loads and applying back-pressure by rejecting requests when queues reach their limits.
- Fault Isolation and Containment: Partition the system into isolated components or cells to limit the blast radius of failures.
- Redundancy and Failover: Build redundancy into your infrastructure and implement failover mechanisms to ensure that your services remain available even if parts of your infrastructure are overwhelmed.
- Simplicity and Modularity: Design systems with simple, modular components that can be easily understood, maintained, and replaced. Avoid complex dependencies and tight coupling between components.
- Circuit Breaker: Monitor the health and performance of downstream services or components and stop forwarding requests if a service is overloaded or unresponsive. Periodically attempt to re-establish the connection (close the circuit breaker).
- Noisy Neighbors: Throttle and apply rate limits to customer traffic to prevent them from consuming resources excessively, thereby ensuring fair access for all customers.
- Capacity Planning and Scaling: Continuously monitor resource utilization and plan for capacity growth. Implement auto-scaling mechanisms to dynamically adjust resources based on demand.
- Communication Optimization: Employ communication optimization techniques like compression, quantization to minimize network traffic and bandwidth requirements.
- Privacy and Security Considerations: Incorporate privacy-preserving mechanisms like secure aggregation, differential privacy, and secure multi-party computation to ensure data privacy and model confidentiality.
- Graceful Degradation: Identify and disable non-critical features or functionality during high loads.
- Monitoring and Alerting: Monitor system metrics (CPU, memory, request rates, latency, etc.) to detect overload scenarios and sending alerts when thresholds are exceeded.
- Defense in Depth: Implement multi-layered defense strategy to detect, mitigate, and protect customer workloads from malicious attacks, like blacklisting IP addresses or employing Geo-location filters, at the Edge Layer using CDN, Load Balancer, or API Gateway. Constrain network bandwidth and requests per second (RPS) for individual tenants at the Network Layer. Applying resource quota, prioritization and admission control at the Application Layer based on account information, request attributes and system metrics. Isolating tenants’ data in separate partitions at the Storage Layer. Each dependent service may use similar multi-layered defense to throttle based on the usage patterns and resource constraints.
- Adaptive Scaling: Automatically scale resources up or down based on demand and multi-tenant fairness policies. Employ predictive auto-scaling or load-based scaling.
- Fault Tolerance and Checkpointing: Incorporate fault tolerance mechanisms, redundant computation and checkpointing to ensure reliable and resilient task processing in the face of potential resource failures. The fault tolerance mechanisms can be used to handle potential failures or stragglers (slow or unresponsive devices).
- Web Application Firewall (WAF): Inspects incoming traffic and blocks malicious requests, including DDoS attacks, based on predefined rules and patterns.
- Load Balancing: By distributing incoming traffic across multiple servers or instances, load balancing helps prevent any single server from becoming overwhelmed.
- Content Delivery Network (CDN): Distribute your content across multiple geographic locations, reducing the strain on your origin servers.
- Cost-Aware Scaling: Implements a cost-aware scaling strategy like like cost modeling and performance prediction that considers the cost of different resource types.
- Security Mechanisms: Incorporate various security mechanisms such as secure communication channels, code integrity verification, and runtime security monitoring to protect against potential vulnerabilities and attacks in multi-tenant environments.
- SOPs and Run books: Develop well-defined procedures that outlines the steps for detecting traffic spikes, pinpointing source of malicious attack, analyzing the logs and monitoring metrics, mitigation strategies, engaging stakeholders, and recovery procedures.
5. Pitfalls with Use of Throttling and Load Shedding
Here are some potential challenges to consider when implementing throttling and load shedding:
- Autoscaling Failures: If your throttling policies are too aggressive, they may prevent your application from generating enough load to trigger autoscaling policies. This can lead to under-provisioning of resources and performance degradation. Conversely, if your throttling policies are too lenient, your application may scale up unnecessarily, leading to overspending.
- Load Balancer Health Checks: Some load balancers use synthetic health checks to determine the health of backend instances. If your throttling policies block these health checks, it can cause instances to be marked as unhealthy and removed from the load balancer, even though they are still capable of serving traffic.
- Unhealthy Instance Overload: When instances are marked as unhealthy by a load balancer, the remaining healthy instances may become overloaded if throttling policies are not properly configured. This can lead to a cascading failure scenario where more and more instances are marked as unhealthy due to the increased load.
- Sticky Sessions: If your application uses sticky sessions (session affinity) for user sessions, and your throttling policies are not consistently applied across all instances, it can lead to inconsistent user experiences or session loss.
- Cache Invalidation: Aggressive throttling or load shedding policies can lead to more frequent cache invalidations, which can impact performance and increase the load on your backend systems.
- Upstream Service Overload: If your application relies on upstream services or APIs, and your throttling policies are not properly coordinated with those services, you may end up overloading those systems and causing cascading failures.
- Insufficient capacity of the Failover: The failover servers must possess adequate capacity to manage the entire expected traffic load from the primary servers.
- Monitoring Challenges: Throttling and load shedding policies can make it more difficult to monitor and troubleshoot performance issues, as the metrics you’re observing may be skewed by the throttling mechanisms.
- Delays in Updating Throttling Policies: The policy adjustments for throttling and load shedding should be capable of updating at runtime swiftly to adapt to various traffic patterns..
- Balancing Load based on number of connections: When directing incoming traffic based on the host with the least number of connections, there’s a risk of unhealthy hosts will have fewer connections due to their quick error responses. Consequently, the load balancer may direct more traffic towards these hosts, resulting in a majority of requests failing. To counteract this, it’s essential to employ robust Layer 7 health checks that comprehensively assess the application’s functionality and dependencies. Layer 4 health checks, which are susceptible to false positives, should be avoided. The unhealthy host should be removed from the available pool as quickly as possible. Additionally, ensuring that error responses from the service have similar latency to successful responses can serve as another effective mitigation strategy.
To mitigate these issues, it’s essential to carefully coordinate your throttling and load shedding policies with the autoscaling, load balancing, caching, and monitoring strategies. This may involve tuning thresholds, implementing consistent policies across all components, and closely monitoring the interaction between these systems. Additionally, it’s crucial to thoroughly test your configurations under various load conditions to identify and address potential issues before they impact your production environment.
6. Monitoring Metrics and Notifications
Here are some common metrics and alarms to consider for throttling and load shedding:
6.1 Network Traffic Metrics:
- Incoming/Outgoing Bandwidth: Monitor the total network bandwidth to detect abnormal traffic patterns.
- Packets per Second (PPS): Track the number of packets processed per second to identify potential DDoS attacks or traffic bursts.
- Connections per Second: Monitor the rate of new connections being established to detect potential connection exhaustion or DDoS attacks.
6.2 Application Metrics:
- Request Rate: Track the number of requests per second to identify traffic spikes or bursts.
- Error Rate: Monitor the rate of errors or failed requests, which can indicate overloading or application issues.
- Response Time: Measure the application’s response time to detect performance degradation or latency issues.
- Queue Saturation: Monitor the lengths of queues or buffers to identify potential bottlenecks or resource exhaustion.
6.3 System Metrics:
- CPU Utilization: Monitor CPU usage to detect resource contention or overloading.
- Memory Utilization: Track memory usage to identify potential memory leaks or resource exhaustion.
- Disk I/O: Monitor disk read/write operations to detect storage bottlenecks or performance issues.
6.4 Load Balancer Metrics:
- Active Connections: Monitor the number of active connections to the load balancer to identify potential connection exhaustion.
- Unhealthy Hosts: Track the number of unhealthy or unresponsive hosts to ensure load balancing efficiency.
- Request/Response Errors: Monitor errors related to requests or responses to identify issues with backend services.
6.5 Alarms and Notifications:
- Set up alarms for critical metrics, such as high CPU utilization, memory exhaustion or excessive error rates. For example, send alarms when error rate > 5% or response code of 5XX for consecutive 5 seconds or data points.
- Set up alarms for high latency, e.g., P90 latency exceeds 50ms for more than 30 seconds.
- Establish fine-grained alarms for detecting breaches in customer service level agreements (SLAs). Configure the alarm thresholds to trigger below the customer SLAs and ensure they can identify the affected customers.
6.6 Autoscaling Policies:
- CPU Utilization-based Scaling: Scale out or in based on CPU usage thresholds to handle traffic bursts or DDoS attacks.
- Memory Utilization-based Scaling: Scale resources based on memory usage to prevent memory exhaustion.
- Network Traffic-based Scaling: Scale resources based on incoming or outgoing network traffic patterns to handle traffic spikes.
- Request Rate-based Scaling: Scale resources based on the rate of incoming requests to maintain optimal performance.
6.7 Throttling / Load Shedding Overhead:
- Monitor the processing time for throttling and load shedding, accounting for any communication overhead if the target host is unhealthy. Keep track of the time to ascertain priority, identify delays in processing, and ensure that high delays only impact denied requests.
- Monitor the system’s utilization and identify when it reaches its capacity.
- Monitor the observed target throughput at the time of the request.
- Monitor the time taken to determine if load shedding is necessary and track when the percentage of denied traffic exceeds X% of incoming traffic.
It’s essential to tailor these metrics and alarms to your specific application, infrastructure, and traffic patterns.
7. Summary
Throttling and Load Shedding offer effective means for managing traffic for online services to maintain high availability. Traffic patterns may vary in characteristics like rate of requests, concurrency, and flow patterns. Understanding these shapes, including normal, peak, off-peak, burst, and seasonal traffic, is crucial for scaling and ensuring high availability. Requests can be classified based on contextual factors, enabling appropriate measures such as throttling or load shedding.
Throttling manages traffic flow or resource usage to avoid overload, whereas load shedding prioritizes tasks during periods of high demand. These methods can complement other strategies such as admission control, request classification, backpressure management, and redundancy. However, their implementation requires careful monitoring, notification, and thorough testing to ensure effectiveness.