Kubernetes has revolutionized how we deploy, scale, and manage applications in the cloud. I’ve been using Kubernetes for many years to build scalable, resilient, and maintainable services. However, Kubernetes was primarily designed for stateless applications – services that can scale horizontally. While such shared-nothing architecture is must-have for most modern microservices but it presents challenges for use-cases such as:
Stateful/Singleton Processes: Applications that must run as a single instance across a cluster to avoid conflicts, race conditions, or data corruption. Examples include:
Legacy applications not designed for distributed operation
Batch processors that need exclusive access to resources
Job schedulers that must ensure jobs run exactly once
Applications with sequential ID generators
Active/Passive Disaster Recovery: High-availability setups where you need a primary instance running with hot standbys ready to take over instantly if the primary fails.
Traditional Kubernetes primitives like StatefulSets provide stable network identities and ordered deployment but don’t solve the “exactly-one-active” problem. DaemonSets ensure one pod per node, but don’t address the need for a single instance across the entire cluster. This gap led me to develop K8 Highlander – a solution that ensures “there can be only one” active instance of your workloads while maintaining high availability through automatic failover.
Architecture
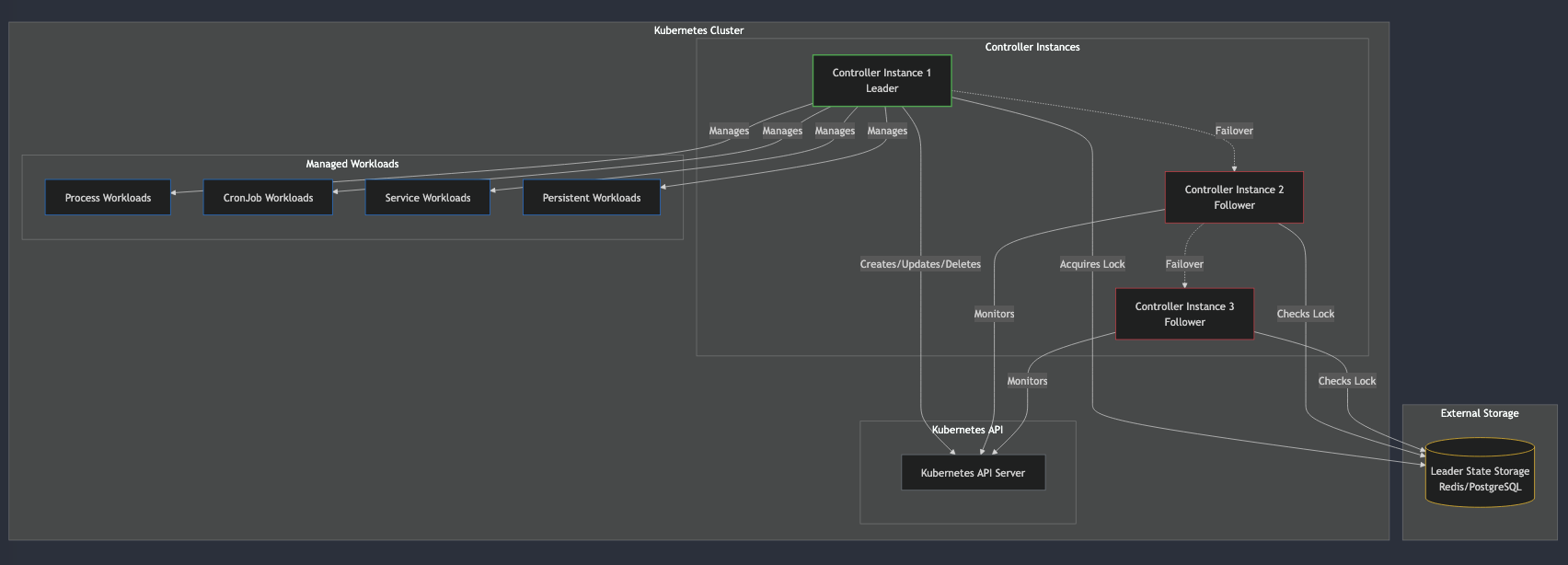
K8 Highlander implements distributed leader election to ensure only one controller instance is active at any time, with others ready to take over if the leader fails. The name “Highlander” refers to the tagline from the 1980s movie & show: “There can be only one.”
Core Components
The system consists of several key components:
Leader Election: Uses distributed locking (via Redis or a database) to ensure only one controller is active at a time. The leader periodically renews its lock, and if it fails, another controller can acquire the lock and take over.
Workload Manager: Manages different types of workloads in Kubernetes, ensuring they’re running and healthy when this controller is the leader.
Monitoring Server: Provides real-time metrics and status information about the controller and its workloads.
HTTP Server: Serves a dashboard and API endpoints for monitoring and management.
How Leader Election Works
The leader election process follows these steps:
Each controller instance attempts to acquire a distributed lock with a TTL (Time-To-Live)
Only one instance succeeds and becomes the leader
The leader periodically renews its lock to maintain leadership
If the leader fails to renew (due to crash, network issues, etc.), the lock expires
Another instance acquires the lock and becomes the new leader
The new leader starts managing workloads
This approach ensures high availability while preventing split-brain scenarios where multiple instances might be active simultaneously.
Workload Types
K8 Highlander supports four types of workloads:
Process Workloads: Single-instance processes running in pods
CronJob Workloads: Scheduled tasks that run at specific intervals
Service Workloads: Continuously running services using Deployments
Persistent Workloads: Stateful applications with persistent storage using StatefulSets
Each workload type is managed to ensure exactly one instance is running across the cluster, with automatic recreation if terminated unexpectedly.
Deploying and Using K8 Highlander
Let me walk through how to deploy and use K8 Highlander for your singleton workloads.
Prerequisites
Kubernetes cluster (v1.16+)
Redis server or PostgreSQL database for leader state storage
kubectl configured to access your cluster
Installation Using Docker
The simplest way to install K8 Highlander is using the pre-built Docker image:
This deploys K8 Highlander with your configuration, ensuring high availability with multiple replicas while maintaining the singleton behavior for your workloads.
Using K8 Highlander Locally for Testing
You can also run K8 Highlander locally for testing:
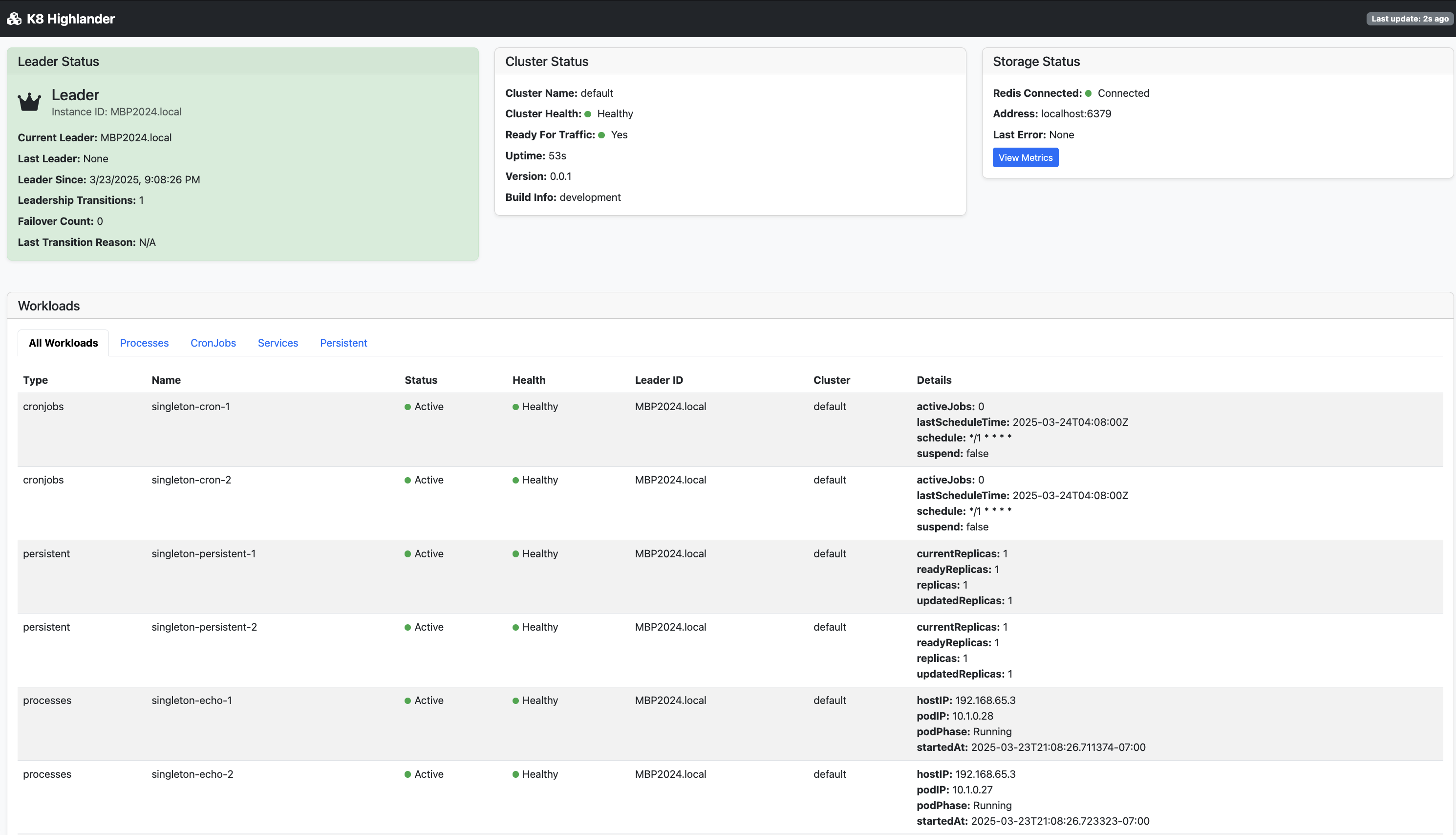
K8 Highlander exposes Prometheus metrics at /metrics for monitoring and alerting:
# HELP k8_highlander_is_leader Indicates if this instance is currently the leader (1) or not (0)
# TYPE k8_highlander_is_leader gauge
k8_highlander_is_leader 1
# HELP k8_highlander_leadership_transitions_total Total number of leadership transitions
# TYPE k8_highlander_leadership_transitions_total counter
k8_highlander_leadership_transitions_total 1
# HELP k8_highlander_workload_status Status of managed workloads (1=active, 0=inactive)
# TYPE k8_highlander_workload_status gauge
k8_highlander_workload_status{name="data-processor",namespace="default",type="process"} 1
Key metrics include:
Leadership status and transitions
Workload health and status
Redis/database operations
Failover events and duration
System resource usage
Grafana Dashboard
A Grafana dashboard is available for visualizing K8 Highlander metrics. Import the dashboard from the dashboards directory in the repository.
Advanced Features
Multi-Tenant Support
K8 Highlander supports multi-tenant deployments, where different teams or environments can have their own isolated leader election and workload management:
# Tenant A configuration
id: "controller-1"
tenant: "tenant-a"
namespace: "tenant-a"
# Tenant B configuration
id: "controller-2"
tenant: "tenant-b"
namespace: "tenant-b"
Each tenant has its own leader election process, so one controller can be the leader for tenant A while another is the leader for tenant B.
Multi-Cluster Deployment
For disaster recovery scenarios, K8 Highlander can be deployed across multiple Kubernetes clusters with a shared Redis or database:
If the primary cluster fails, a controller in the secondary cluster can become the leader and take over workload management.
Summary
K8 Highlander fills a critical gap in Kubernetes’ capabilities by providing reliable singleton workload management with automatic failover. It’s ideal for:
Legacy applications that don’t support horizontal scaling
Processes that need exclusive access to resources
Scheduled jobs that should run exactly once
Active/passive high-availability setups
The solution ensures high availability without sacrificing the “exactly one active” constraint that many applications require. By handling the complexity of leader election and workload management, K8 Highlander allows you to run stateful workloads in Kubernetes with confidence.
Where to Go from Here
Check out the GitHub repository for the latest code and documentation
Read the API Reference for detailed endpoint information
K8 Highlander is an open-source project with MIT license, and contributions are welcome! Feel free to submit issues, feature requests, or pull requests to help improve the project.
I became seriously interested in computers after learning about Microprocessor architecture during a special summer camp program at school that taught us about how computer systems work among other topics. I didn’t have easy access to computers at my school and I learned a bit more about programming on an Atari system. This hooked me to take some private lessons on programming languages and pursue computer science college studies in college and a career as a software developer spanning three decades.
My professional journey started mostly with mainframe systems and then I shifted more towards UNIX systems and then later to Linux environments. Along the way, I’ve witnessed entire technological ecosystems rise, thrive, and ultimately vanish like programming languages abandoned despite their elegance, operating systems forgotten despite their robustness, and frameworks discarded despite their innovation. I will dig through my personal experience with some of the archaic technologies that have largely disappeared or diminished in importance. I’ve deliberately omitted technologies I still use regularly to spotlight these digital artifacts. These extinct technologies shaped how we approach computing problems and contain the DNA of our current systems. They remind us that today’s indispensable technologies may someday join them in the digital graveyard.
Programming Languages
BASIC & GW-BASIC
I initially learned BASIC on an Atari system and later learned GW-BASIC, which introduced me to graphics programming on IBM XT computers running early DOS versions. The use of line numbers organizing program flow with GOTO and GOSUB statements seemed strange to me but its simplicity helped me to build create programs with sounds and graphics. Eventually, I moved to Microsoft QuickBASIC that had support for procedures and structured programming. This early taste of programming led me to pursue Computer Science in college. I sometimes worry about today’s beginners facing overwhelming complexity like networking, concurrency, and performance optimization just to build a simple web application. BASIC on the other hand was very accessible and rewarding for newcomers despite its limitations.
Pascal & Turbo Pascal
College introduced me to both C and Pascal through Borland’s Turbo compilers. I liked cleaner and more readable syntax of Pascal compared to C. At the time, C had best performance so Pascal couldn’t gain wide adoption and it has largely disappeared from mainstream development. Interestingly, career of Turbo Pascal’s author, Anders Hejlsberg was saved by Microsoft who went on to create C# and later TypeScript. This trajectory taught me that technical superiority alone doesn’t ensure survival.
FORTRAN
During a college internship at a physics laboratory, I learned about FORTRAN running on massive DEC-VAX/VMS systems, which was very popular among scientific computing at the time. While FORTRAN maintains a niche presence in scientific circles but DEC VAX/VMS systems have vanished entirely from the computing landscape. VMS systems were known for powerful, reliable and stable computing environments but DEC failed to adapt to the industry’s shift toward smaller, more cost-effective systems. The market ultimately embraced UNIX variants that offered comparable capabilities at lower price points with greater flexibility. This transition taught me an early lesson in how economic factors often trump technical superiority.
COBOL, CICS and Assembler
My professional career at a marketing firm began with COBOL, CICS, and Assembler on mainframe. JCL (Job Control Language) was used to submit the mainframe jobs that had unforgiving syntax where a misplaced comma could derail an entire batch job. I used COBOL for batch processing applications that primarily processed sequential ISAM files or the more advanced VSAM files with their B-Tree indexing for direct data access. These batch jobs often ran for hours or even days that created long feedback cycles where a single error could cause cascading delays and missed deadlines.
I used CICS for building interactive applications with their distinctive green-screen terminals. I had to use BMS (Basic Mapping Support) for designing the 3270 terminal screen layouts, which was notoriously finicky language. I built my own tool to convert plain text layouts into proper BMS syntax so that I didn’t have to debug syntax errors. The most challenging language that I had to use was mainframe Assembler, which was used for performance-critical system components. These programs were monolithic workhorses —thousands of lines of code in single routines with custom macros simulating higher-level programming constructs. Thanks to the exponential performance improvements in modern hardware, most developers rarely need to descend to this level of programming.
PERL
I first learned PERL in college and embraced it throughout the 1990s as a versatile tool for both system administration and general-purpose programming. Its killer feature—regular expressions—made it indispensable for text processing tasks that would have been painfully complex in other languages. At a large credit verification company, I leveraged PERL’s pattern-matching to automate massive codebase migrations, transforming thousands of lines of code from one library to another. Later, at a major airline, I used similar techniques to upgrade legacy systems to newer WebLogic APIs without manual rewrites.
In the web development arena, I used PERL to build early CGI applications and it was a key component of revolutionary LAMP stack (Linux, Apache, MySQL, PERL) before PHP/Python supplanted it. The CPAN repository was another groundbreaking innovation that allowed reusing shared libraries at scale. I used it along with Mason web templating system at a large online retailer in the mid 2000s and then migrated some of those applications to Java as PERL based systems were difficult to maintain. I found similar experience with other PERL codebases and I eventually moved to Python, which offered cleaner object-oriented design patterns and syntax. Its cultural impact—from the camel book to CPAN—influenced an entire generation of programmers, myself included.
4th Generation Languages
Early in my career, Fourth Generation Languages (4GLs) promised a dramatic boost productivity by providing a simple UI for managing the data. On mainframe systems, I used Focus and SAS for data queries and analytics, creating reports and processing data with a few lines of code. For desktop applications, I used a variety of 4GL environments including dBase III/IV, FoxPro, Paradox, and Visual Basic. These tools were remarkable for their time, offering “query by example” interfaces that allowed quickly build database applications with minimal coding. However, as data volumes grew, the limitations of these systems became painfully apparent. Eventually, I transitioned to object-oriented languages paired with enterprise relational databases that offered better scalability and maintainability. Nevertheless, these tools represent an important evolutionary step that influenced modern RAD (Rapid Application Development) approaches and low-code platforms that continue to evolve today.
Operating Systems
Mainframe Legacy
My career began at a marketing company working on IBM 360/390 mainframes running MVS (Multiple Virtual Storage). I used a combination of JCL, COBOL, CICS, and Assembler to build batch applications that processed millions of customer records. Working with JCL (Job Control Language) was particularly challenging due to its incredibly strict syntax where a single misplaced comma could cause an entire batch run to fail. The feedback cycle was painfully slow; submitting a job often meant waiting hours or even overnight for results. We had to use extensive “dry runs” of jobs to test the business logic —a precursor to what we now call unit testing. Despite these precautions, mistakes happened, and I witnessed firsthand how a simple programming error caused the company to mail catalogs to incorrect and duplicate addresses, costing millions in wasted printing and postage.
These systems also had their quirks: they used EBCDIC character encoding rather than the ASCII standard found in most other systems. They also stored data inefficiently—a contributing factor to the infamous Y2K crisis, as programs commonly stored years as two digits to save precious bytes of memory in an era when storage was extraordinarily expensive. Terminal response times were glacial by today’s standards—I often had to wait several seconds to see what I’d typed appear on screen. Yet despite their limitations, these mainframes offered remarkable reliability. While the UNIX systems I later worked with would frequently crash with core dumps (typically from memory errors in C programs), mainframe systems almost never went down. This stability, however, came partly from their simplicity—most applications were essentially glorified loops processing input files into output files without the complexity of modern systems.
UNIX Variants
Throughout my career, I worked extensively with numerous UNIX variants descended from both AT&T’s System V and UC Berkeley’s BSD lineages. At multiple companies, I deployed applications on Sun Microsystems hardware running SunOS (BSD-based) and later Solaris (System V-based). These systems, while expensive, provided the superior graphics capability, reliability and performance needed for mission-critical applications. I used SGI’s IRIX operating system running on impressive graphical workstations when working at a large physics lab. These systems processed massive datasets from physics experiments by leveraging non-uniform memory access (NUMA) and symmetric multi-processing (SMP) based architecture. IRIX was among the first mainstream 64-bit operating systems, pushing computational boundaries years before this became standard. They were used for visual effects in movies like Jurassic Park to life in 1993, which was amazing to watch. I also worked with IBM’s AIX on SP1/SP2 supercomputers at the physics lab, using Message Passing Interface (MPI) APIs to distribute processing across hundreds of nodes. This message-passing approach ultimately proved more scalable than shared-memory architectures, though modern systems incorporate both paradigms—today’s multi-core processors rely on the same NUMA/SMP concepts pioneered in these early UNIX variants.
On the down side, these systems were very expensive and Moore’s Law enabled commodity PC hardware running Linux to achieve comparable performance at a fraction of the price. I saw a lot of those large systems replaced with a farm of low-cost PCS based on Linux clusters that reduced infrastructure costs drastically. I was deeply passionate about UNIX and even spent most of my savings in the early ’90s on a high-end PowerPC system, which was result of a partnership between IBM, Motorola, Apple, and Sun. This machine could run multiple operating systems including Solaris and AIX, though I primarily used it for personal projects and learning.
DOS, OS/2, SCO and BeOS
For personal computing in the 1980s and early 1990s, I primarily used MS-DOS, even developing several shareware applications and games that I sold through bulletin board systems. DOS, with its command-line interface and conventional/expanded memory limitations taught me valuable lessons about resource optimization that remain relevant even in today. I preferred UNIX-like environments whenever possible so I installed SCO UNIX (based on Microsoft’s Xenix) on my personal computer. SCO was initially respected in the industry before it transformed into a patent troll with controversial patent lawsuits against Linux distributors. I also liked OS/2 and it was a technically superior operating system developed compared to Windows with its support of true pre-emptive multitasking. But it lost to Windows due to massive Microsoft’s market power similar to other innovative competitors like Borland, Novell, and Netscape.
Perhaps the most elegant of these alternative systems was BeOS, which I eagerly tested in the mid-1990s when it released in beta. It supported microkernel design and pervasive multithreading capabilities, and was a serious contender for Apple’s next-generation OS. However, Apple ultimately acquired NeXT instead, bringing Steve Jobs back and adopting NeXTSTEP as the foundation—another case where superior technology lost to business considerations and personal relationships.
Storage Media
My first PC had a modest 40MB hard drive and I relied heavily on floppy disks in both 5.25-inch and later 3.5-inch formats. They took a long time to copy data and made a lot of scratching sounds as both progress indicators and early warning systems for impending failures. In professional environments, I worked with SCSI drives that had better speed and reliability. I generally employed RAID configurations to protect against drive failures. For archiving and backup, I generally used tape drives that were also painfully slow but could store much more data. In mid-1990s, I switched to Iomega’s Zip drives from floppy disks for personal backups that could store up to 100MB compared to 1.44MB floppies. Similarly, I used CD-R and later CD-RW drives for storage that also had slow write speeds initially.
Network Protocols
In my early career, networking was fairly fragmented and I generally used Novell’s proprietary IPX (Internetwork Packet Exchange) protocol and Novell NetWare networks at work. It provided nice support of file sharing and printing service. On mainframe systems, I worked with Token Ring networks that offered more reliable deterministic performance. As the internet was based on TCP/IP, it eventually took over along with UNIX and Linux systems. For file sharing across these various systems, I relied on NFS (Network File System) in UNIX environments and later Samba to bridge the gap between UNIX and Windows systems that used SMB (Server Message Block) protocol. Both solutions were plagued with performance issues due to file locking issues. I spent countless hours troubleshooting “stale file handles” and unexpected disconnections that plagued these early networked file systems.
Databases
My database journey began on mainframe systems with IBM’s VSAM (Virtual Storage Access Method), which wasn’t a true database but provided crucial B-Tree indexing for efficient file access. I also worked with IBM’s IMS, a hierarchical database that organized data in parent-child tree structures. The relational databases were truly revolutionary at the time and I embraced systems like IBM DB2, Oracle, and Microsoft SQL Server. In my college, I took a number of courses in theory of relational databases and appreciated its strong mathematical foundations. However, most of those relational databases were commercial and expensive and I looked at open source projects like MiniSQL but it lacked critical enterprise features like transaction support.
In mid 1990s, I saw object-oriented databases gained popularity along with object-oriented programming that promised to eliminate the “impedance mismatch” between object models and relational tables. I evaluated ObjectStore for some projects and ultimately deployed Versant to manage complex navigation data for traffic mapping systems—predecessors to today’s Google Maps services. These databases elegantly handled complex object relationships and inheritance hierarchies, but introduced their own challenges in querying, scaling, and integration with existing systems. The relational databases later absorbed object-oriented concepts like user-defined types, XML support, and JSON capabilities. Looking back, it taught me that systems built on strong theoretical foundations with incremental adaptation tend to outlast revolutionary approaches.
Security and Authentication
Early in my career, I worked as a UNIX system administrator and relied on /etc/passwd files for authentication that were world-readable, containing password hashes generated with the easily crackable crypt algorithm. For multi-system environments, I used NIS (Network Information Service) to centrally manage user accounts across server clusters. We also commonly used .rhosts files to allow password-less authentication between trusted systems. I later used Kerberos authentication systems to provide stronger single sign-on capabilities for enterprise environments. When working at a large airline, I used Netegrity SiteMinder to implement single sign-on based access. While consulting for a manufacturing company, I built SSO implementations using LDAP and Microsoft Active Directory across heterogeneous systems. The Java ecosystem brought its own authentication frameworks and I worked extensively with JAAS (Java Authentication and Authorization Service) and later Acegi Security before moving to SAML (Security Assertion Markup Language) and OAuth based authentication standards.
Applications & Development Tools
Desktop Applications (Pre-Web)
My early word processing was done in WordStar with its cryptic Ctrl-key commands, before moving to WordPerfect, which offered better formatting control. For technical documentation, I relied on FrameMaker that supported sophisticated layout for complex documents. For spreadsheets, I initially used VisiCalc, which was the original “killer app” on Apple II but later Lotus 1-2-3, which revolutionized common keyboard shortcuts that still exist in Excel today. When working for a marketing company, I used Lotus Notes, a collaboration tool that functioned as an email client, calendar, document management system, and application development platform. On UNIX workstations, I preferred text-based applications like elm and pine for email and lynx text browser when accessing remote machines on telnet.
Chat & Communication Tools
On early UNIX systems at work, I used the simple ‘talk’ command to chat with other users on the system. At home during the pre-internet era, I immersed myself in the Bulletin Board System (BBS) culture. I also hosted my own BBS, learning firsthand about the challenges of building and maintaining online communities. I used CompuServe for access to group forums and Internet Relay Chat (IRC) through painfully slow dial-up and later SLIP/PPP connections. My fascination with IRC led me to develop my own client application, PlexIRC, which I distributed as shareware. As graphical interfaces took over, I adopted ICQ and Yahoo Messenger for personal communications. These platforms introduced status indicators, avatars, and file transfers that we now take for granted. While AOL Instant Messenger dominated the American market, I deliberately avoided the AOL ecosystem, preferring more open alternatives. My professional interest gravitated toward Jabber, which later evolved into the XMPP protocol standard with its federated approach to messaging—allowing different servers to communicate like email. I later implemented XMPP-based messaging solutions for several organizations, appreciating its extensible framework and standardized approach.
Development Environments
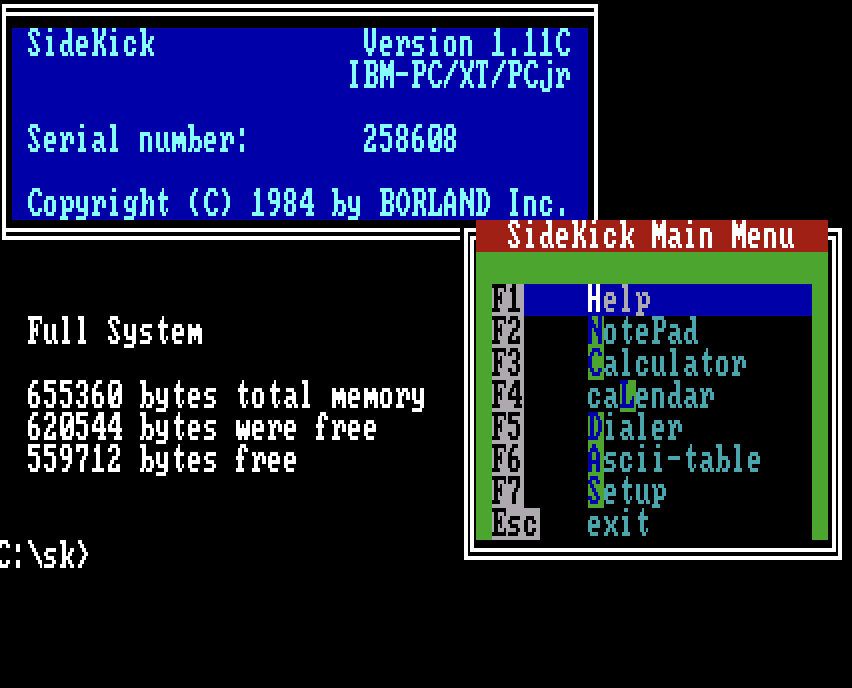
On UNIX systems, I briefly wrestled with ‘ed’—a line editor so primitive by today’s standards that its error message was simply a question mark. I quickly graduated to Vi, whose keyboard shortcuts became muscle memory that persists to this day through modern incarnations like Vim and NeoVim. In the DOS world, Borland Sidekick revolutionized my workflow as one of the first TSR (Terminate and Stay Resident) applications. With a quick keystroke, Sidekick would pop up a notepad, calculator, or calendar without exiting the primary application. For debugging and system maintenance, I used Norton Utilities that provided essential tools like disk recovery, defragmentation, and a powerful hex editor that saved countless hours when troubleshooting low-level issues. I learned about the IDE (Integrated Development Environment) through Borland’s groundbreaking products like Turbo Pascal and Turbo C that combined fast compilers with editing and debugging in a seamless package. These evolved into more sophisticated tools like Borland C++ with its application frameworks. For specialized work, I used Watcom C/C++ for its cross-platform capabilities and optimization features. As Java gained prominence, I adopted tools like JBuilder and Visual Cafe, which pioneered visual development for the platform. Eventually, I moved to Eclipse and later IntelliJ IDEA, alongside Visual Studio. Though, I still enable Vi mode on these IDEs due to its powerful editing capabilities without the need of mouse.
Web Technologies
I experienced the early internet ecosystem in college—navigating Gopher menus for document retrieval, searching with WAIS, and participating in Usenet newsgroups. Everything changed with the release of NCSA HTTPd server and the Mosaic browser. I used these revolutionary tools on Sun workstations in college and later at a high-energy physics laboratory on UNIX workstations. I left my cushy job to find web related projects and secured a consulting position at a financial institution building web access for credit card customers. I used C/C++ with CGI (Common Gateway Interface) to build dynamic web applications that connected legacy systems to this new interface. These early days of web development were like the Wild West—no established security practices, framework standards, or even consistent browser implementations existed. During a code review when working at a major credit card company, I discovered a shocking vulnerability: their web application stored usernames and passwords directly in cookies in plaintext, essentially exposing customer credentials to anyone with basic technical knowledge. These early web servers used a process-based concurrency model, spawning a new process for each request—inefficient by modern standards but there wasn’t much user traffic at the time. On the client side, I worked with the Netscape browser, while server implementations expanded to include Apache, Netscape Enterprise Server, and Microsoft’s IIS.
I also built my own Model-View-Controller architecture and templating system because there weren’t any established frameworks available. As Java gained traction, I migrated to JSP and the Struts framework, which formalized MVC patterns for web applications. This evolution continued as web servers evolved from process-based to thread-based concurrency models, and eventually to asynchronous I/O implementations in platforms like Nginx, dramatically improving scalability. Having witnessed the entire evolution—from hand-coded HTML to complex JavaScript frameworks—gives me a unique perspective on how rapidly this technology landscape has developed.
Distributed Systems Development
My journey with distributed systems began with Berkeley Sockets—the foundational API that enabled networked communication between applications. After briefly working with Sun’s RPC (Remote Procedure Call) APIs, I embraced Java’s Socket implementation and then its Remote Method Invocation (RMI) framework, which I used to implement remote services when working as a consultant for an enterprise client. RMI offered the revolutionary ability to invoke methods on remote objects as if they were local, handling network communication transparently and even dynamically loading remote classes. At a major travel booking company, I worked with Java’s JINI technology, which was inspired by Linda memory model and TupleSpace that I also studied during my postgraduate research. JINI extended RMI with service discovery and leasing mechanisms, creating a more robust foundation for distributed applications. I later used GigaSpaces, which expanded the JavaSpaces concept into a full in-memory data grid for session storage.
For personal projects, I explored Voyager, a mobile agent platform that simplified remote object interaction with dynamic proxies and mobile object capabilities. Despite its technical elegance, Voyager never achieved widespread adoption—a pattern I would see repeatedly with technically superior but commercially unsuccessful distributed technologies. While contracting for Intelligent Traffic Systems in the Midwest during the late 1990s, I implemented CORBA-based solutions that collected real-time traffic data from roadway sensors and distributed it to news agencies via a publish-subscribe model. CORBA promised language-neutral interoperability through its Interface Definition Language (IDL), but reality fell short—applications typically worked reliably only when using components from the same vendor. I had to implement custom interceptors to add the authentication and authorization capabilities CORBA lacked natively. Nevertheless, CORBA’s explicit interface definitions via IDL influenced later technologies like gRPC that we still use today. The Java Enterprise (J2EE) era brought Enterprise JavaBeans and I implemented these technologies using BEA WebLogic for another state highway system, and continued working with them at various travel, airline, and fintech companies. EJB’s fatal flaw was attempting to abstract away the distinction between local and remote method calls—encouraging developers to treat distributed objects like local ones. This led to catastrophic performance problems as applications made thousands of network calls for operations that should have been local.
I read Rod Johnson’s influential critique of EJB that eventually evolved into the Spring Framework, offering a more practical approach to Java enterprise development. Around the same time, I transitioned to simpler XML-over-HTTP designs before the industry standardized on SOAP and WSDL. The subsequent explosion of WS-* specifications (WS-Security, WS-Addressing, etc.) created such complexity that the diagram of their interdependencies resembled the Death Star. I eventually abandoned SOAP’s complexity for JSON over HTTP, implementing long-polling and Server-Sent Events (SSE) for real-time applications before adopting the REST architectural style that dominates today’s API landscape. Throughout these transitions, I integrated various messaging systems including IBM WebSphere MQ, JMS implementations, TIBCO Rendezvous, and Apache ActiveMQ to provide asynchronous communication capabilities. This journey through distributed systems technologies reflects a recurring pattern: the industry oscillating between complexity and simplicity, between comprehensive frameworks and minimal viable approaches. The technologies that endured longest were those that acknowledged and respected the fundamental challenges of distributed computing—network unreliability, latency, and the fallacies of distributed computing—rather than attempting to hide them behind leaky abstractions.
Client & Mobile Development
Terminal & Desktop GUI
My journey developing client applications began with CICS on mainframe systems—creating those distinctive green-screen interfaces for 3270 terminals once ubiquitous in banking and government environments. The 4th generation tools era introduced me to dBase and Paradox, which I used to build database-driven applications through their “query by example” interfaces, which allowed rapid development of forms and reports without extensive coding. For personal projects, I developed numerous DOS applications, games, and shareware using Borland Turbo C. As Windows gained prominence, I transitioned to building GUI applications using Borland C++ with OWL (Object Windows Library) and later Microsoft Foundation Classes (MFC), which abstracted the complex Windows API into an object-oriented framework. While working for a credit protection company, I developed UNIX-based client applications using OSF/Motif. Motif’s widget system and resource files offered sophisticated UI capabilities, though with considerable implementation complexity.
Web Clients
The web revolution transformed client development fundamentally. I quickly adopted HTML for financial and government projects, creating browser-based interfaces that eliminated client-side installation requirements. For richer interactive experiences, I embedded Flash elements into web applications—creating animations and interactive components beyond HTML’s capabilities at the time. Java’s introduction brought the promise of “write once, run anywhere,” which I embraced through Java applets that you could embed like Flash widgets. Later, Java Web Start offered a bridge between web distribution and desktop application capabilities, allowing applications to be launched from browsers while running outside their security sandbox. Using Java’s AWT and later Swing libraries, I built standalone applications including IRC and email clients. The client-side JavaScript revolution, catalyzed by Google’s demonstration of AJAX techniques, fundamentally changed web application architecture. I experimented with successive generations of JavaScript libraries—Prototype.js for DOM manipulation, Script.aculo.us for animations, YUI for more component sets, etc.
Embedded and Mobile Development
As Java had its roots in embedded/TV systems, it introduced a wearable smart Java ring with an embedded microchip that I used for some personal security applications. Though the Java Ring quickly disappeared from the market, its technological descendants like the iButton continued finding specialized applications in security and authentication systems. The mobile revolution began in earnest with the Palm Pilot—a breakthrough device featuring the innovative Graffiti handwriting recognition system that transformed how we interacted with portable computers. I embraced Palm development, creating applications for this pioneering platform and carrying a Palm device for years. As mobile technologies evolved, I explored the Wireless Application Protocol (WAP), which attempted to bring web content to the limited displays and bandwidth of early mobile phones but failed to gain widespread adoption. When Java introduced J2ME (Java 2 Micro Edition), I invested heavily in mastering this platform, attracted by its promise of cross-device compatibility across various feature phones. I developed applications targeting the constrained CLDC (Connected Limited Device Configuration) and MIDP (Mobile Information Device Profile) specifications.
The entire mobile landscape transformed dramatically when Apple introduced the first iPhone in 2007—a genuine paradigm shift that redefined our expectations for mobile devices. Recognizing this fundamental change, I learned iOS development using Objective-C with its message-passing syntax and manual memory management. This investment paid off when I developed an iOS application for a fintech company that significantly contributed to its acquisition by a larger trading firm. Early mobile development eerily mirrored my experiences with early desktop computing—working within severe hardware constraints that demanded careful resource management. Despite theoretical advances in programming abstractions, I found myself once again meticulously optimizing memory usage, minimizing disk operations, and carefully managing network bandwidth. This return to fundamental computing constraints reinforced my appreciation for efficiency-minded development practices that remain valuable even as hardware capabilities continue expanding.
Development Methodologies
My first corporate experience introduced me to Total Quality Management (TQM), with its focus on continuous improvement and customer satisfaction. This early exposure taught me a crucial lesson: methodology adoption depends more on organizational culture than on the framework itself. Despite new terminology and reorganized org charts, the company largely maintained its existing practices with superficial changes. Later, I worked with organizations implementing the Capability Maturity Model (CMM), which attempted to categorize development processes into five maturity levels. While this framework provided useful structure for improving chaotic environments, its documentation requirements and formal assessments often created bureaucratic overhead that impeded actual development. Similarly, the Rational Unified Process (RUP), which I used at several companies, offered comprehensive guidance but it turned into waterfall development model in many projects. The agile revolution emerged as a reaction against these heavyweight methodologies. I applied elements of Feature-Driven Development and Spiral methodologies when working at a major airline, focusing on iterative development and explicit risk management. I explored various agile approaches during this period—Crystal’s focus on team communication, Adaptive Software Development’s emphasis on change tolerance, and particularly Extreme Programming (XP), which introduced practices like test-driven development and pair programming that fundamentally changed how I approached code quality. Eventually, most organizations where I worked settled on customized implementations of Scrum and Kanban—frameworks that continue to dominate agile practice today.
Development Methodologies & Modeling
Earlier in my career, approaches like Rapid Application Development (RAD) and Joint Application Development (JAD) emphasized quick prototyping and intensive stakeholder workshops. These methodologies aligned with Computer-Aided Software Engineering (CASE) tools like Rational Rose and Visual Paradigm, which promised to transform software development through visual modeling and automated code generation. On larger projects, I spent months creating elaborate UML diagrams—use cases, class diagrams, sequence diagrams, and more. Some CASE tools I used could generate code frameworks from these models and even reverse-engineer models from existing code, promising a synchronized relationship between design and implementation. The reality proved disappointing; generated code was often rigid and difficult to maintain, while keeping models and code in sync became an exercise in frustration. The agile movement ultimately eclipsed both heavyweight methodologies and comprehensive CASE tools, emphasizing working software over comprehensive documentation.
DevOps Evolution
Version Control System
My introduction to version control came at a high-energy physics lab, where projects used primitive systems like RCS (Revision Control System) and SCCS (Source Code Control System). These early tools stored delta changes for each file and relied on exclusive locking mechanisms—only one developer could edit a file at a time. As development teams grew, most projects migrated to CVS (Concurrent Versions System), which built upon RCS foundations. CVS supported networked operations, allowing developers to commit changes from remote locations, and replaced exclusive locking with a more flexible concurrent model. However, CVS still operated at the file level rather than treating commits as project-wide transactions, leading to potential inconsistencies when only portions of related changes were committed. I continued using CVS for years until Subversion emerged as its logical successor. Subversion’s introduction of atomic commits to ensure that either all or none of a change would be committed. It also improved branching operations, directory management, and file metadata handling, addressing many of CVS’s limitations. While working at a travel company, I encountered AccuRev, which introduced the concept of “streams” instead of traditional branches. This approach modeled development as flowing through various stages. AccuRev proved particularly valuable for managing offshore development teams who needed to download large codebases over unreliable networks and its sophisticated change management reduced bandwidth requirements.
During my time at a large online retailer in the mid-2000s, I worked with Perforce, a system optimized for large-scale development with massive codebases and binary assets. Perforce’s performance with large files and sophisticated security model made it ideal for enterprise environments. I briefly used Mercurial for some projects, appreciating its simplified interface compared to early Git versions, before ultimately transitioning to Git as it became the industry standard. This evolution of version control parallels the increasing complexity of software development itself: from single developers working on isolated files to globally distributed teams collaborating on massive codebases.
Build Systems
I have been using Make probably throughout my career across various platforms and languages. Its declarative approach to defining dependencies and build rules established patterns that influence build tools to this day. After adopting Java ecosystem, I switched to Apache Ant, which used XML to define build tasks as an explicit sequence of operations. This offered greater flexibility and cross-platform consistency but at the cost of increasingly verbose build files as projects grew more complex. I used Ant extensively during Java’s enterprise ascendancy, customizing its tasks to handle deployment, testing, and reporting. I then adopted Maven that introduced revolutionary concepts such as convention-over-configuration philosophy with standardized project structures, dependency management capabilities connected to remote repositories to automatically resolve and download required libraries. Despite Maven’s transformative nature, its rigid conventions and complex XML configuration was a bit frustrating and I later switched to Gradle. Gradle offered Maven’s dependency management with a Groovy-based DSL that provided both the structure of declarative builds and the flexibility of programmatic customization.
The build process expanded beyond compilation when I implemented Continuous Integration using CruiseControl, an early CI server developed by ThoughtWorks. This system automatically triggered builds on code changes, ran tests, and reported results. Later, I worked extensively with Hudson, which offered a more user-friendly interface and plugin architecture for extending CI capabilities. When Oracle acquired Sun and attempted to trademark the Hudson name, the community rallied behind a fork called Jenkins, which rapidly became the dominant CI platform. I used Jenkins for years, creating complex pipelines that automated testing, deployment, and release processes across multiple projects and environments. Eventually, I transitioned to cloud-based CI/CD platforms that integrated more seamlessly with hosted repositories and containerized deployments.
Summary
As I look back across my three decades in technology, these obsolete systems and abandoned platforms aren’t just nostalgic relics—they tell a powerful story about innovation, market forces, and the unpredictable nature of technological evolution. The technologies I’ve described throughout this blog didn’t disappear because they were fundamentally flawed. Pascal offered cleaner syntax than C, BeOS was more elegant than Windows, and CORBA attempted to solve distributed computing problems we still grapple with today. Borland’s superior development tools lost to Microsoft’s ecosystem advantages. Object-oriented databases, despite solving real problems, couldn’t overcome the momentum of relational systems. Yet these extinct technologies left lasting imprints on our industry. Anders Hejlsberg, who created Turbo Pascal, went on to shape C# and TypeScript. The clean design principles of BeOS influenced aspects of modern operating systems. Ideas don’t die—they evolve and find new expressions in subsequent generations of technology.
Perhaps the most valuable lesson is about technological adaptability. Throughout my career, the skills that have remained relevant weren’t tied to specific languages or platforms, but rather to fundamental concepts: understanding data structures, recognizing patterns in system design, and knowing when complexity serves a purpose versus when it becomes a hurdle. The industry’s constant reinvention ensures that many of today’s dominant technologies will eventually face their own extinction event. By understanding the patterns of the past, we gain insight into which current technologies might have staying power. This digital archaeology isn’t just about honoring what came before—it’s about understanding the cyclical nature of our industry and preparing for what comes next.