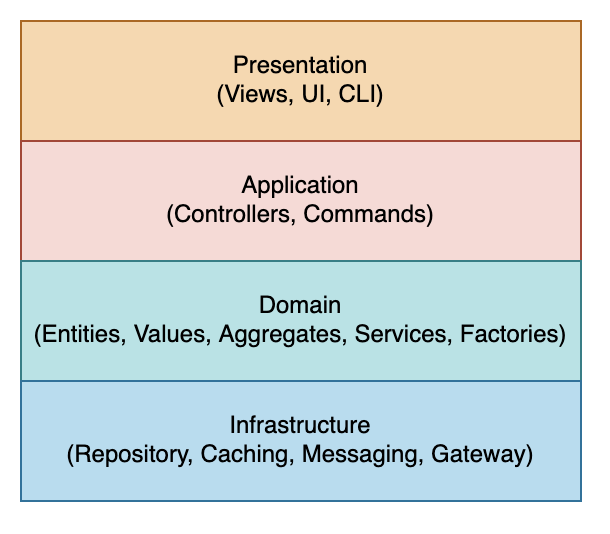
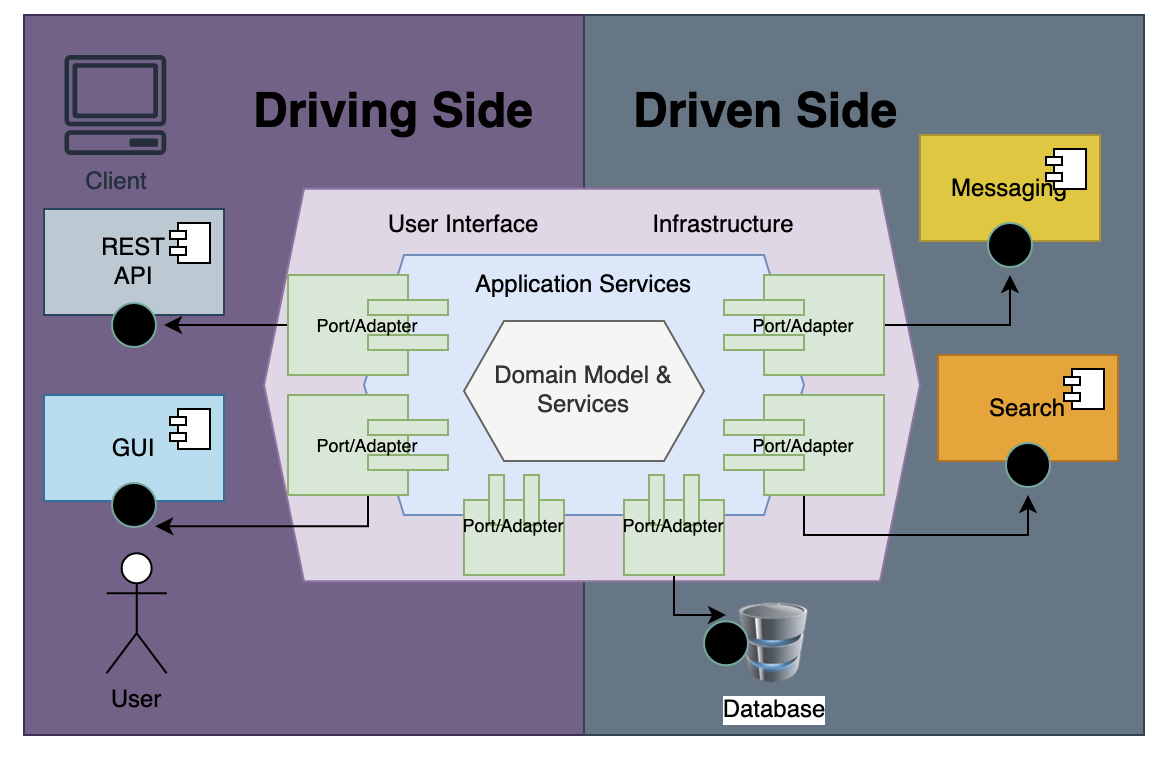
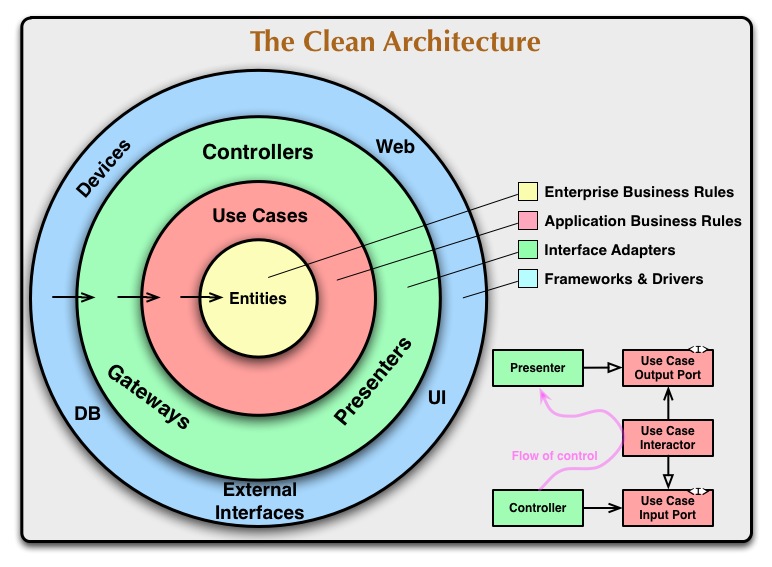
I recently read Olaf Zimmermann’s book “Patterns for API Design” that reviews theory and practice of API design patterns. These patterns built upon earlier work of Gregor Hohpe on Enterprise Integration Patterns and Martn Fowler’s Patterns of Enterprise Application Architecture. Following is summary of these API patterns from the book:
1. Application Programming Interface (API) Fundamentals
The first chapter defines the remote API fundamentals that defines contract for the desired behavior, communication protocol, network endpoints and policies regarding failures. The chapter also surveys history of remote APIs such as TCP/IP based FTP, RPC based DCE/CORBA/RMI/gRPC, queue/messaging based, REST style, and data streams/pipelines. The authors then examines cloud native applications (CNA) and a set of principles described in IDEAL that include Isolated State, Distribution, Elasticity, Automation and Loose Coupling. These traits are then summarized as:
- Fit for purpose
- Rightsized and modular
- Resilient and protected
- Controllable and adaptable
- Workfload-aware and resource-efficient
- Agile and tool-supported
The authors describes how service-oriented architecture originated and evolved into Microservices that has a single responsibility within a domain-specific business capability. Microservices facilitate software reuse but also bring new challenges that include fallacies of distributed computing, data consistency and state management. These APIs should be considered as products and they may form ecosystems. API business value, visibility and lifetime help make API successful by enabling rapid integration of systems with support of the autonomy and independent evolution of those systems. The API design may differ based on:
- One general vs many specialized endpoints
- Fine vs coarse-grained endpoint and operation scope
- Few operations carrying much data vs chatty interactions carrying little data
- Data currentness vs correctness
- Stable contracts vs fast changing ones
The authors reviews architecturally significant requirements such as understandability, information sharing vs hiding, amount of coupling, modifiability, performance & scalability, data parsimony, and security & privacy. The authors then describes developer experience as:
DX = function, stability, ease of use, and clarity
The developer experience includes quality attributes throughout the lifecycle of API such as development qualities, operational qualities and managerial qualities. The chapter ends with definition of a domain model for remote APIs that include communication participants, endpoints with contracts that describe operations, message structure, and API contract.
2. Lakeside Mutual Case Study
The chapter 2 introduces a fake Lakeside Mutual case study to illustrate API design. This chapter examines the user-stories and quality attributes for the case study, analsysis-level domain model and architecture overview. The architecture overviews describes system context and application architecture including service components. The chapter then describes an example of API specification using MDSL (Microservice Domain-Specific-Language).
3. API Decision Narratives
This chapter goes over the API design options and decisions where each decision includes criteria, alternative options and recommendations based on why-statement and architecture-decision-record format. The first pattern starts with Foundation API decisions and patterns that include:
3.1 API Visibility
This decision that is primarily managerial and organizational looks at the different visibility options such as Public API, Community API and Solution-Internal API.
3.2 API Integration
The chapter looks at the decision looks for the API integration types where an API can be integrated with backend horizontally or can be integrated with frontend and backend vertically. In the former option, backend exposes its services via a message-based remote backend integration API. In the latter option, the APIs are exposed via a message-based remote frontend integration API.
3.3 Documentation of API
The API designers need to decide if the API should have the documentation and if so, how should it be documented. For example, there are multiple standards such as OpenAPI specification (formerly known as Swagger), Web Application Description Language (WADL), Web Service Description Language and Microservice Domain-Specific Language (MDSL).
3.4 API Roles and Responsibilities
The API designers have to find an appropriate business granularity for the service and handle cohesion & coupling criteria. The drivers for this decision is to define the architectural role that an API endpoint should play and define the responsibility of each API operation. The role of an API endpoint can be Processing Resource for processing incoming commands or Information Holder Resource for storage and retrieval of data or metadata. The information holder roles can be further divided into operational/transactional short-lived data, master long-lived data for business transactions, reference long-lived data for looking up delivery status, zip codes, etc., link lookup resource to identify links to resources and data transfer resource to offer a shared data exchange between clients.
3.5 Defining Operation Responsibilities
The operation responsibilities include defining read-write characteristics of each API operation and can be categorized into Computing Function, State Creation Operation, State Transition Operation and Retrieval Operation. The Computation Function computes a result solely from the client input without reading or writing a server-side state. The State Creation Operation creates states with reliability on an write-only API endpoint. The State Transition Operation performs one or more activities, causing a server-side state change with considerations for network efficiency and data parsimony. The Retrieval Operation represents a read-only access operation to find the data.
3.6 Selecting Message Representation Patterns
The structural representation patterns deal with designing message representation structures with considerations for finding the optimal number of message parameters and semantic meaning and stereotypes of the representation elements. This structural representation needs to take four decisions: responsibility of message elements, structure of the parameter representation, exchange of context information required and meaning of stereotypes of message elements. The structure of parameter representation can be nested or flat with types: Atomic Parameter, Atomic Parameter List, Parameter Tree, and Parameter Forrest. The Atomic Parameter defines a single parameter or body element. The Atomic Parameter List aggregates multiple atomic parameters as list. The Parameter Tree defines a hierarchical structure with one or more child nodes. The Parameter Forest comprises two or more Parameter Trees. Security and privacy concerns such as data integrity and confidentiality as well as semantic proximity will determine choosing the right option for these structure types.
3.7 Element Stereotypes
The element stereotype patterns include Data Element and Metadata Element, Link Element, ID Element. Security and data privacy concerns drive Data Elements and Metadata Elements and messages may become larger if Metadata Elements are included. The unique ID Element is used to identify to API endpoints, operations, and message representation elements. The Link Element act as human and machine readable network accessible pointers to other endpoints and operations.
3.8 Governing API Quality
The quality of service (QoS) for API include reliability, performance, security and scalability. The themes of the decisions for quality governance include:
3.8.1 Identification and Authentication of the API Client
Identification, authentication and authorization are important for APIs security but they also enable measures for ensuring many other qualities.
3.8.2 API Key
The API Key identifies the client and additional signature made with the secret key, which are never transmitted. You may use OAuth 2.0, OpenID, Kerberos in combination with LDAP, CHAP, and EAP.
3.8.3 Pricing Plan
The pricing plan looks at the metering and charging for API consumption and its variants include Freemium Model, Flat-Rate Subscription, Usage-based Pricing and Market-based Pricing based on economic aspects.
3.8.4 Rate Limit
The Rate Limit safeguards against API clients that overuse the API.
3.8.5 Service Level Agreement
The service Level Agreement defines testable service-level objectives to establish a structured, quality-oriented agreement with the API product owner.
3.8.6 Error Report
The Error Report uses error codes in response message that indicate and classify the faults in a simple and machine-readable ways.
3.8.7 Context Representation
The context representation uses Metadata Elements to carry contextual information in request and response messages. It can be used to cope with the diversity of protocols for distributed applications and transport security tokens and digital signatures.
3.8.8 Pagination
The pagination divides large response data into smaller chunks and its variants include Page-Based Pagination, Cursor-Based Pagination, Offset-Based Pagination, and Time-Based Pagination. It can optionally allow filtering capabilities and pagination structure can be defined as Atomic Parameter List, or Parameter Forest or Parameter Tree.
3.8.9 Wish List and Wish Template
A Wish List allows API clients to provide desired data elements of requested resource in the request. When response contains a nested data, Wish Template can be used to specify parameters in the request message that should be included in the corresponding response message.
3.8.10 Conditional Request
This pattern makes a Conditional Request by adding Metadata Elements to the request message and the API service processes the request only the condition specified by the metadata is met.
3.8.11 Request Bundle
Request Bundle is defined as a data container that assembles multiple requests with unique identifiers in a single request message.
3.8.12 Embedded Entity
This pattern embeds a Data Element in the request or response instead of link or identifier.
3.8.13 Linked Information Holder
Linked Information Holder adds a Link Element to message that points to the API endpoint that represent the linked element.
3.9 API Evolution
API Evolution patterns define governing rules balancing stability and compatibility with maintainability and extensibility such as:
3.9.1 Version Identifier
Version identifier is added as a Metadata Element to the endpoint address, protocol header or the message payload to indicate possibly incompatible changes to clients.
3.9.2 Semantic Versioning
Semantic Versioning introduces a hierarchical three-number versioning schema x.y.z, which allows API providers to denote level of changes as major, minor and patch versions.
3.9.3 Commissioning and Decommissioning
The variants for version introduction and decommissioning decision include Two in Production, Limited Lifetime Guarantee, and Aggressive Obsolescence.
3.9.4 Experimental Preview
Experimental Preview provides access to an API to receive early feedback from consumers without making any commitments about the functionality, stability and longevity.
4. Pattern Language Introduction
This chapter introduces a pattern language, basic scoping and structural patterns. Many of the patterns builds upon Enterprise Integration Patterns and Gof Design Patterns when defining structure of a message. This chapter categorizes patterns into Foundation patterns, Responsibility patterns, Structure patterns, Quality patterns and Evolution patterns. These patterns also follow Design Refinement Phases based on Unified Process:
- Inception – Foundation
- Elaboration – Responsibility and Quality
- Construction – Structure, Responsibility and Quality
- Transition – Foundation, Quality and Evolution
4.1 Foundations: API Visibility and Integration Types
These patterns deal with types of systems, subsystems and components as well as where should an API be accessible. The API integration types can be Frontend Integration and Backend Integration. The Frontend Integrations, also referred as vertical integrations are consumed by API clients in application frontends. The cloud-native applications and microservices-based system benefit with Backend Integration, sometimes called horizontal integration to access information or activity in other systems. The API visibility alternatives can be Public API, Community API and Solution-Internal API. Public API specifies endpoints, operations, message representation, quality of service and lifecycle model that can be accessed by unlimited or unknown number of API clients and can be controlled with API keys. You may apply other patterns such as Version Identifiers, Pricing Plan, Rate Limit and Service Level Agreement with Public APIs. The Community API are only available to a community that may consists of different organizations. The Solution-Internal API is also referred as Platform API that may be exposed in a single cloud provider offering.
4.2 Basic Structure Patterns
The structure patterns looks at the number of representation elements for request and response messages and decides how these elements should be grouped. These patterns include Atomic Parameter that describes plain data such as text and numbers; Atomic Parameter List that groups several elementary parameters; Parameter Trees that provide nested parameters; and Parameter Forest that groups multiple tree parameters.
5. Define Endpoint Types and Operations
This chapter corresponds to Define phase of the Align-Define-Design-Refine (ADDR) process and describes high-level endpoint identification activities. The authors looks at user stories, event storming or other collaboration techniques to define API roles and responsibilities. The design of API contracts also have to define developer experience in terms of function, stability, ease of use, clarity. Other quality attributes that the API designer have to decide include: Accuracy for functional correctness including preconditions, invariants and postconditions; Distribution of control and autonomy between API client and provider; Scalability, performance and availability with Service Level Agreements for mission-critical APIs; Manageability for monitoring APIs; Consistency and atomicity for all-or-nothing semantics; Idempotence property; Auditability for risk management.
5.1 Endpoint Roles (aka Service Granularity)
The two general endpoint roles are Processing Resource and Information Holder Resource. The Processing Resource role allows remote clients to trigger an action and related design concerns include contract expressiveness and service granularity; learnability and manageability; semantic interoperability; response time; security and privacy; and compatibility and evolvability. Information Holder Resource exposes domain data in API and it may use Domain-driven design and object-oriented analysis and design to model the data. Other related concerns include quality attribute conflicts and trade-offs; security; data freshness vs consistency; and compliance with architectural design principles. Related patterns include:
- Operational Data Holder to create, read, update and delete its data often and fast.
- Master Data Holder to access master data that lives for long time, doesn’t change and will be referenced from many clients. The request and response messages of Master Data often take the form of Parameter Trees and master data update may come in the form of coarse-grained full updates or fine-grained partial updates.
- Reference Data Holder is used to lookup reference data that is long lived and is immutable for clients using API endpoints. Its desired qualities include Do not repeat yourself (DRY) and performance vs consistency trade-off for read access.
- Link Lookup Resource allows referring to other resources so that clients remain loosely coupled if API provider changes the destination of links. The design challenges include: coupling between clients and endpoints; dynamic endpoint references; centralization vs decentralization; message sizes, number of calls, resource use; dealing with broken links; and number of endpoints and API complexity.
- Data Transfer Resource allows exchanging data between participants without knowing each other, without being available at the same time. The design considerations include coupling (time and location dimensions); communication constraints; reliability; scalability; storage space efficiency; latency; and ownership management. You may introduce a shared storage endpoint with a State Creation Operation and Retrieval Operation. The pattern properties include coupling (time and location dimensions); communication constraints; reliability; scalability; storage space efficiency; latency; ownership management; access control; (lack of) coordination; optimistic locking; polling; and garbage collection.
5.2 Operation Responsibilities
The four operation responsibilities include:
- State Creation Operation to allow its clients that something has happened, e.g. to trigger instant or later processing. This design concerns include: coupling trade-offs (accuracy and expressiveness vs information parsimony); timing; consistency; and reliability. It may or may not have fire-and-forget semantics and idempotency may be needed for the transaction boundary. A popular variant of this pattern is Event Notification Operation, notifying the endpoint about an external event.
- Retrieval Operation to retrieve information and allow further client-side processing. The design issues include: veracity, variety, velocity and volume; workload management; network efficiency vs data parsimony.
- State Transition Operation to allow a client initiate a processing action that causes the provider-side application state to change. The design concerns include service granularity; consistency and auditability; dependencies on state changing being made beforehand; workload management; and network efficiency vs data parsimony. State Transition Operations are generally transactional supporting ACID behavior and may use ABAC for compliance and security controls.
- Computation Function to allow client invoke side-effect-free remote processing on the provider side based on the input parameters. The relevant design issues include reproducibility and trust; performance; and workload management. Its examples include a Transformation service, Validation service, and Long Running Computation.
6. Design Request and Response Message Representations
This chapter corresponds to Design phase of the Align-Define-Design-Refine (ADDR) process and examines structural patterns for requests and responses. The challenges when designing message representations include interoperability on protocol and message-content; latency; throughput and scalability; maintainability; and developer experience.
6.1 Data Element
The Data Element pattern allow exchanging application-level information between API clients and API providers without decoupling them. The competing force concerns include rich functionality vs ease of processing and performance; security and data privacy vs ease of configuration; and maintainability vs flexibility.
6.2 Metadata Element
Metadata Element pattern allows enriching messages with additional information so that receiver can interpret the message content correctly. The design concerns include interoperability; concerns; and ease of use vs runtime efficiency. The variants of this pattern include Control Metadata Element such as identifiers, flags, filter, ACL, API eys, etc; Aggregated Metadata Elements such as counters of Pagination and statistical information; Provenance Metadata Elements such as message/request IDs, creation date, version numbers, etc.
6.3 ID Element
ID Element pattern helps identify elements of the Published Language using UUID or surrogate key when applying domain-driven design. The identification problems include effort vs stability; reliability for machines and humans; and security.
6.3 Link Element
Link Element is used to reference API endpoints and operations in request and response message payloads so that they can be called remotely.
6.4 API Key
API Key allows API provider to identify and authenticate clients and their requests. The design issues include establishing basic security; access control; avoiding the need to store or transmit user credentials; decoupling clients form their organizations; security vs ease of use; and performance.
6.5 Error Report
Error Report allows API provides inform its clients about communication and processing faults. The design concerns include expressiveness and target audience expectations; robustness and reliability; security and performance; interoperability and portability; and internationalization.
6.6 Context Representation
Context Representation allows API consumers and providers exchange context information without relying on any particular remoting protocols. The design considerations include interoperability and modifiability; dependency on evolving protocols; developer productivity (control vs convenience); diversity of clients and their requirements; end-to-end security; and logging and auditing on business domain level.
7. Refine Message Design for Quality
This chapter reviews API Quality patterns related to the Design and Refine phases of the Align-Define-Design-Refine (ADDR) process. The major challenges with API Quality include message sizes vs number of requests; information needs of individual clients; network bandwidth usage vs computation efforts; implementation complexity vs performance; statelessness vs performance; and ease of use vs legacy.
7.1 Message Granularity
The message granularity patterns deal with performance and scalability; modifiability and flexibility; data quality; data privacy; and data freshness vs consistency. These patterns include:
- Embedded Pattern allows placing Data Element in the request or response to avoid exchanging multiple messages.
- Linked Information Holder can be used to keep the message small when an API deals with multiple information elements that reference each other.
7.2 Client-Driven Message Content (aka Response Shaping)
These patterns deal with performance, scalability, and resource use; information needs of individual clients; loose coupling and interoperability; developer experience; security and data privacy; and test and maintenance effort. These patterns include:
- Pagination allows an API provider deliver large sequence of structured data without overwhelming clients. The design concerns include session awareness and isolation; and data set size and data access profile. The variants of this pattern include Page-Based Pagination, Cursor-Based Pagination, Time-Based Pagination and Offset-Based Pagination.
- Wish List allows an API client inform the API provider at runtime about the data it is interested in.
- Wish Template allows API client inform the API provider about nested data that it is interested in. For example, Wish Templates of GraphQL are the query and mutation schemas providing declarative descriptions of the client requirements.
7.3 Message Exchange Optimization (aka Conversation Efficiency)
These patterns provide balance competing forces for complexity of endpoint, client, and message payload design; and accuracy of reporting and billing. These patterns include:
- Conditional Request prevents unnecessary server-side processing and bandwidth usage by invoking API operation only when the condition is true. The design concerns include size of message; client workload; provider workload; and data currentness vs correctness. Its variants include Time-Based Conditional Request (e.g. If-Modified-Since HTTP header) and Fingerprint-Based Conditional Request (e.g. ETag and If-None-Match HTTP headers).
- Request Bundle works as a data container that assembles multiple independent requests in a single request message with unique request identifiers.
8. Evolve API
This chapter reviews API Evolution patterns related to the Refine phase of the Align-Define-Design-Refine (ADDR) process. The major challenges with API Evolution autonomy, loose coupling, extensibility, compatibility and sustainability. The patterns in this chapter include:
8.1 Versioning and Compatibility Management
These patterns include:
- Version Identifier allows an API provider indicate its current capabilities as well as existence of possibly incompatible changes to clients. The design concerns include accuracy vs exact identification; no accidental breakage of comparability; client-side impact; and traceability of API versions in use.
- Semantic versioning allow stakeholders compare API versions to detect incompatible changes. The design concerns include minimal effort to detect version incompatibility; clarity of change impact; clear separation of changes with different levels of impact and compatibility; manageability of API versions and related governance effort; and clarity with regard to evolution timeline. The common numbering scheme in Semantic Versioning include major version, minor version and patch version.
8.2 Life-Cycle Management Guarantees
These patterns include:
- Experimental Preview allows providers make the introduction of a new API or new API versions, less risky for their clients and obtain early adopter feedback without freezing the API design prematurely. The design considerations include innovation and new features; feedback; focus effort; early learning and security.
- Aggressive Obsolescence allows API providers reduce the effort for maintaining an entire API by removing unused or deprecated features. The design concerns include minimizing the maintenance effort; reducing forced changes to clients in a given time span as a consequence of API changes; repeating/acknowledging power dynamics; and commercial goals and constraints. The API version is marked as Release, Deprecate or Decommission in the lifecycle of Aggressive Obsolescence.
- Limited Lifetime Guarantee allows a provider let clients know for how long they can rely on the published version of an API. The design considerations include make client-side changes caused by API changes plannable; and limit the maintenance effort for supporting old clients.
- Two in Production allows a provider gradually update an API without breaking existing clients but also without maintaining a large number of API versions in production. The design concerns include allow the provider and the client to follow different life cycles; guarantee that API changes do not lead to undetected backward compatibility problems between clients and provider; ensure the ability to rollback if a new API version is designed badly; minimize changes to the client; minimize the maintenance effort for supporting clients relying on old API versions.
9. Document and Communicate API Contracts
This chapter does not correspond to any phase of the Align-Define-Design-Refine (ADDR) process. The challenges for Documenting APIs include interoperability; compliance; information hiding; economic aspects; performance and reliability; meter granularity; attractiveness from a consumer point of view. The patterns in the chapter include:
- API Description to share knowledge between API provider and its clients and related concerns include interoperability; consumability; information hiding; extensibility and evolvability.
- Pricing Plan to allow API provider meter API service consumption and charge for it. Its variants include Subscription-based Pricing, Usage-based Pricing, and Market-based Pricing.
- Rate Limit to allow API provider prevent API clients from excessive API usage with design considerations for economic aspects; performance; reliability; impact and severity of risks of API abuse; and client awareness.
- Service Level Agreement to allow API client learn about the specific quality-of-service characteristics of an API and its endpoint operations. The design concerns include business agility and vitality; attractiveness from the consumer point of view; availability; performance and scalability; security and privacy; government regulations and legal obligations; and cost-efficiency and business risks from a provider point of view.
10. Real-World Pattern Stories
This chapter examines API design and evolution in real-world business domains. The first case-study discusses large-scale process integration in Terravis, a Swiss Mortgage business had to adopt a new law for the digitization of Swiss land registry businesses. In the context dimensions defined by Philippe Krutchten, the Terravis platform was characterized in terms of system size, system criticality, system age, team distribution, rate of change, preexistence of stable architecture, governance and business model. Terravis applied role and status of API as well as other patterns such as Solution-Internal API, Community API, API Description, Service Level Agreements, Semantic Versioning, Error Report, Pricing Plan, Rate Limit, Context Representation, State Creation Operation, State Transition Operations, Pagination, etc. The other case-study showed how an internal system at the concrete column manufacturer SACAC had to integrate different existing software such as ERP and CAD systems. The chapter used the Philippe Krutchten’s project dimensions to describe the project. The key challenges included correctness of all calculations and the solution applied book’s guidelines for roles and status of API. The API used Solution-Internal, Frontend Integration, Backend Integration, State Creation Operations, State Transition Operations, Retrieval Operations, Computations Functions, etc.
11. Conclusion
The last chapter concludes with how the pattern language in the book helps integration architects, API developers and other roles involved with API design and evolution. The authors also suggest how APIs can be refactored to the patterns described in the book and use Microservice Domain Specific Language (MDSL) Tools for refactoring. The chapter also describes advancements in API protocols and standards such as HTTP/2, HTTP/3, and gRPC. OpenAPI Specification is the dominant API description language for HTTP-based APIs and AsyncAPI is gaining adoption for message-based APIs, which can also generate MDSL bindings.