1. Overview
Over the last few decades, the software systems has evolved from the mainframe and client-server models to distributed systems and service oriented architecture. In early 2000, Amazon and Netflix forged ahead the industry to adopt microservices by applying Conway’s law and self-organizing teams structure where a small 2-pizza team own entire lifecycle of the microservices including operational responsibilities. The microservice architecture with small, cross-functional and independent structure has helped team agility to develop, test and deploy microservices independently. However, the software systems are becoming increasingly complex with the Cambrian explosion of microservices and the ecosystem of microservices is reaching a boiling point where building new features, releasing the enhancements and operational load from maintaining high availability, scalability, resilience, security, observability, etc are slowing down the development teams and raising the artificial complexity as a result of mixing different concerns.
Following diagram shows difference between monolithic architecture and microservice architecture:
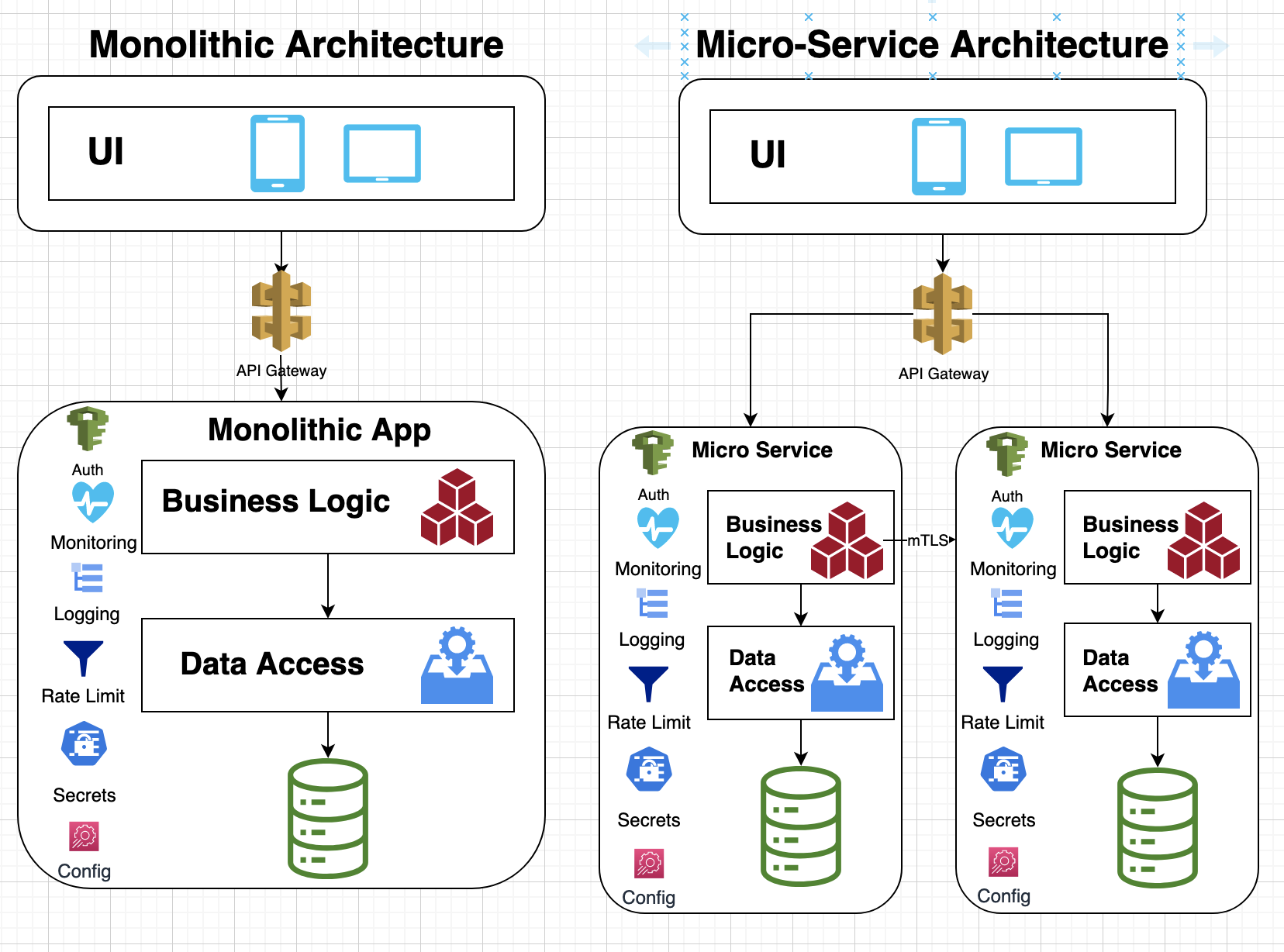
As you can see in above diagram, each microservice is responsible for managing a number of cross-cutting concerns such as AuthN/AuthZ, monitoring, rate-limit, configuration, secret-management, etc., which adds a scope of work for development of each service. Following sections dive into fundamental causes of the complexity that comes with the microservices and a path forward for evolving the development methodology to build these microservices more effectively.
2. Perils in Building Distributed Systems
Following is a list of major pitfalls faced by the development teams when building distributed systems and services:
2.1 Coordinating Feature Development
The feature development becomes more convoluted with increase in dependencies of downstream services and any large change in a single service often requires the API changes or additional capabilities from multiple dependent services. This creates numerous challenges such as prioritization of features development among different teams, coordinating release timelines and making progress in absence of the dependent functionalities in the development environment. This is often tackled with additional personnel for project management and managing dependencies with Gantt charts or other project management tools but it still leads to unexpected delays and miscommunication among team members about the deliverables.
2.2 Low-level Concurrency Controls
The development teams often use imperative languages and apply low-level abstractions to implement distributed services where each request is served by a native thread in a web server. Due to extensive overhead of native threads such as stack size limits, the web server becomes constrained with the maximum number of concurrent requests it can support. In addition, these native threads in the web server often share a common state, which must be protected with a mutex, semaphore or lock to avoid data corruption. These low-level and primitive abstractions couple business logic with the concurrency logic, which add accidental complexity when safeguarding the shared state or communicating between different threads. This problem worsens with the time as the code size increases that results in subtle concurrency related heisenbugs where these bugs may produce incorrect results in the production environment.
2.3 Security
Each microservice requires implementing authentication, authorization, secure communication, key management and other aspects of the security. The development teams generally have to support these security aspects for each service they own and they have to be on top of any security patches and security vulnerabilities. For example, a zero-day log4j vulnerability in December 2021 created a havoc in most organizations as multiple services were affected by the bug and needed a patch immediately. This resulted in large effort by each development team to patch their services and deploy the patched services as soon as possible. Worst, the development teams had to apply patches multiple times because initial bug fixes from the log4j team didn’t fully work, thus further multiplying the work by each development team. With growth of the dependency stack or bill of material for third party libraries in modern applications, the development teams face an overwhelming operational burden and enormous security risk to support their services safely.
2.4 Web Server
In general, each microservice requires a web server, which adds additional computing and administration overhead for deploying and running the service stack. The web server must be running all the time whether the service is receiving requests or not, thus wasting CPU, memory and storage resources needlessly.
2.5 Colocating Multiple Services
The development teams often start with a monolithic style applications that hosts multiple services on a single web server or with segregated application servers hosting multiple services on the same web server to lessen the development and deployment effort. The monolithic and service colocation architecture hinders speed, agility and extensibility as the code becomes complicated, harder to maintain and reasoned due to lack of isolation. In this style of deployment, computing resources can be entirely consumed by a single component or a bug in one service can crash the entire system. As each service may have unique runtime or usage characteristics, it’s also arduous to scale a single service, to plan service capacity or to isolate service failures in a colocated runtime environment.
2.6 Cross Cutting Concerns
Building distributed systems require managing a lot of horizontal concerns such as security, resilience, business continuity, and availability but coupling these common concerns with the business logic results in inconsistencies and higher complexity by different implementations in microservices. Mixing these different concerns with business logic in microservices means each development team will have to solve those concerns independently and any omission or divergence may cause miserable user experience, faulty results, poor protection against load spikes or a security breach in the system.
2.7 Service Discovery
Though, microservices use various synchronous and asynchronous protocols for communicating with other services but they often store the endpoints of other services locally in the service configurations. This adds maintenance and operational burden for maintaining the endpoints for all dependent services in each development, test and production environment. In addition, services may not be able to apply certain containment or access control policies such as not invoking cross-region service to maintain lower latency or sustain a service for disaster recovery.
2.8 Architectural Quality Attributes
The architecture quality attributes include performance, availability sustainability, security, scalability, fault tolerance, performance, resilience, recovery and usability, etc. Each development team not only has to manage these attributes for each service but often requires coordination with other teams when scaling their services so that downstream services can handle additional load or meet the availability/reliability guarantees. Thus, the availability, fault tolerance, capacity management or other architectural concerns become tied with downstream services as an outage in any of those services directly affect upstream services. Thus, improving availability, scalability, fault tolerance or other architecture quality attributes often requires changes from the dependent services, which adds scope of the development work.
2.9 Superfluous Development Work
When a developing a microservice, a development team owns end-to-end development and release process that includes a full software development lifecycle support such as :
- maintaining build scripts for CI/CD pipelines
- building automation tools for integration/functional/load/canary tests
- defining access policies related to throttling/rate-limits
- implementing consistent error handling, idempotency behavior, contextual information across services
- adding alarms/metrics/monitoring/observability/notification/logs
- providing customized personal and system dashboards
- supporting data encryption and managing secret keys
- defining security policies related to AuthN/AuthZ/Permissons/ACL
- defining network policies related to VPN, firewall, load-balancer, network/gateway/routing configuration
- adding compression, caching, and any other common pre/post processing for services
As a result, any deviations or bugs in implementation of these processes or misconfiguration in underlying infrastructure can lead to conflicting user experience, security gaps and outages. Some organizations maintain lengthy checklists and hefty review processes for applying best practices before the software release but they often miss key learnings from other teams and slow down the development process due to cumbersome release process.
2.10 Yak shaving when developing and testing features
Due to enormous artificial complexity of microservices with abysmal dependency stack, the development teams have to spend inordinate amount of time in setting up a development environment when building a new feature. The feature development requires testing the features using unit tests with a mock behavior of dependent services and using integration tests with real dependent services in a local development environment. However, it’s not always possible to run complete stack locally and fully test the changes for new features, thus the developers are encumbered with finding alternative integration environment where other developers may also be testing their features. All this yak shaving makes the software development awfully tedious and error prone because developers can’t test their features in isolation with a high confidence. This means that development teams find bugs later in phases of the release process, which may require a rollback of feature changes and block additional releases until bugs are fixed in the main/release branch.
3. Path to the Enlightenment
Following are a few recommendations to remedy above pitfalls in the development of distributed systems and microservices:
3.1 Higher level of Development Abstraction
Instead of using low-level imperative languages or low-level concurrency controls, high-level abstractions can be applied to simplify the development of the microservices as follows:
3.1.1 Actor Model
The Actor model was first introduced in 1973 by Carl Hewitt and it provides a high-level abstraction for concurrent computation. An actor uses a mailbox or a queue to store incoming messages and processes one message at a time using local state in a single green thread or a coroutine. An actor can create other actors or send messages without using any lock-based synchronization and blocking. Actors are reactive so they cannot initiate any action on their own, instead they simply react to external stimuli in the form of message passing. Actors provide much better error handling where applications can define a hierarchy of actors with parent/child relationships and a child actor may crash when encountering system errors, which are monitored and supervised by parent actors for failure recovery.
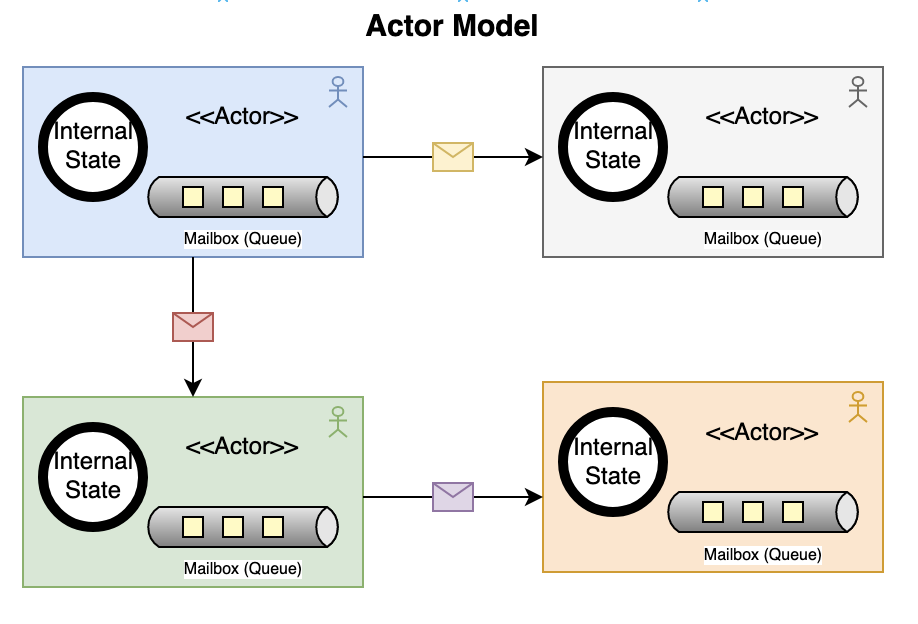
Actor model is supported natively in many languages such Erlang/Elixir, Scala, Swift and Pony and it’s available as a library in many other languages. In these languages, actors generally use green threads, coroutines or a preemptive scheduler to schedule actors with non-blocking I/O operations. As the actors incur much lower overhead compare to native threads, they can be used to implement microservices with much greater scalability and performance. In addition, message passing circumvents the need to guard the shared state as each actors only maintains a local state, which provides more robust and reliable implementation of microservices. Here is an example of actor model in Erlang language:
-module(sum).
-export([init/0, add/1, get/0]).
init() ->
Pid = spawn(fun() -> loop(0) end),
register(sumActor, Pid).
loop(N) ->
receive
{add, X} -> loop(N+X);
{Client, get} ->
Client ! N,
loop(N)
end.
add(X) ->
sumActor ! {add, X}.
get() ->
sumActor ! {self(), get},
receive Result -> Result end.In above example, an actor is spawned to run loop function, which uses a tail recursion to receive next message from the queue and then processes it based on the tag of the message such as add or get. The client code uses a symbol sumActor to send a message, which is registered with a local registry. As an actor only maintains local state, microservices may use use external data store and manage a state machine using orchestration based SAGA pattern to trigger next action.
3.1.2 Function as a service (FaaS) and Serverless Computing
Function as a service (FaaS) offers serverless computing to simplify managing physical resources. Cloud vendors offer APIs for AWS Lambda, Google Cloud Functions and Azure Functions to build serverless applications for scalable workloads. There are also open source support for FaaS computing such as OpenFaas and OpenWhisk on top of Kubernetes or OpenShift. These functions resemble actor model as each function is triggered based on an event and is designed with a single responsibility, idempotency and shared nothing principles that can be executed concurrently.
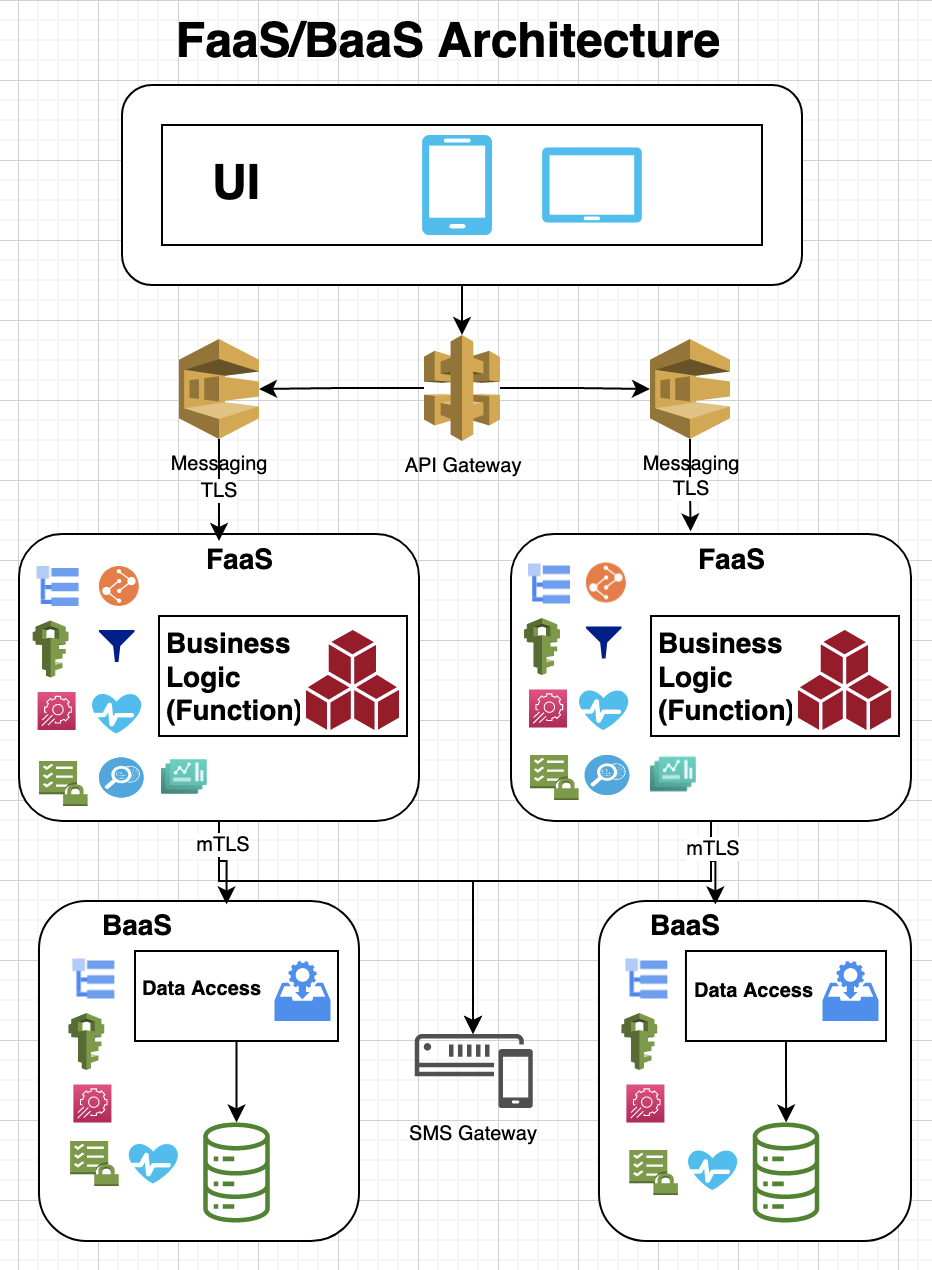
The FaaS and serverless computing can be used to develop microservices where business logic can be embedded within a serverless functions but any platform services such as storage, messaging, caching, SMS can be exposed via Backend as a Service (BaaS). The Backend as a Service (BaaS) adds additional business logic on top of Platform as a Service (PaaS).
3.1.3 Agent based computing
Microservices architecture decouples data access from the business logic and microservices fetch data from the data-store, which incurs a higher overhead if the business logic needs to fetch a lot of data for processing or filtering before generating results. As opposed, agent style computing allow migrating business logic remotely where data or computing resources reside, thus it can process data more efficiently. In a simplest example, an agent may behave like a stored procedure where a function is passed to a data store for executing a business logic, which is executed within the database but other kind of agents may support additional capabilities to gather data from different data stores or sources and then produces desired results after processing the data remotely.
3.2 Service and Schema Registry
The service registry allows microservices to register the endpoints so that other services can look up the endpoints for communication with them instead of storing the endpoints locally. This allows service registry to enforce any authorization and access policies for communication based on geographic location or other constraints. A service registry may also allow registering mock services for testing in a local development environment to facilitate feature development. In addition, the registry may store schema definitions for the API models so that services can validate requests/responses easily or support multiple versions of the API contracts.
3.3 API Router, Reverse-Proxy or Gateway
API router, reverse-proxy or an API gateway are common patterns with microservices for routing, monitoring, versioning, securing and throttling APIs. These patterns can also be used with FaaS architecture where an API gateway may provide these capabilities and eliminate the need to have a web server for each service function. Thus, API gateway or router can result in lowering computing cost for each service and reducing the complexity for maintaining non-functional capabilities or -ilities.
3.4 Virtualization
Virtualization abstracts computer hardware and uses a hypervisor to create multiple virtual computers with different operating systems and applications on top of a single physical computer.
3.4.1 Virtual Machines
The initial implementation of virtualization was based on Virtual Machines for building virtualized computing environments and emulating a physical computer. The virtual machines use a hypervisor to communicate with the physical computer.

3.4.2 Containers
Containers implement virtualization using host operating system instead of a hypervisor, thus provide more light-weight and faster provisioning of computing resources. The containers use platforms such as Docker and Kubernetes to execute applications and services, which are bundled into images based on Open Container Initiative (OCI) standard.
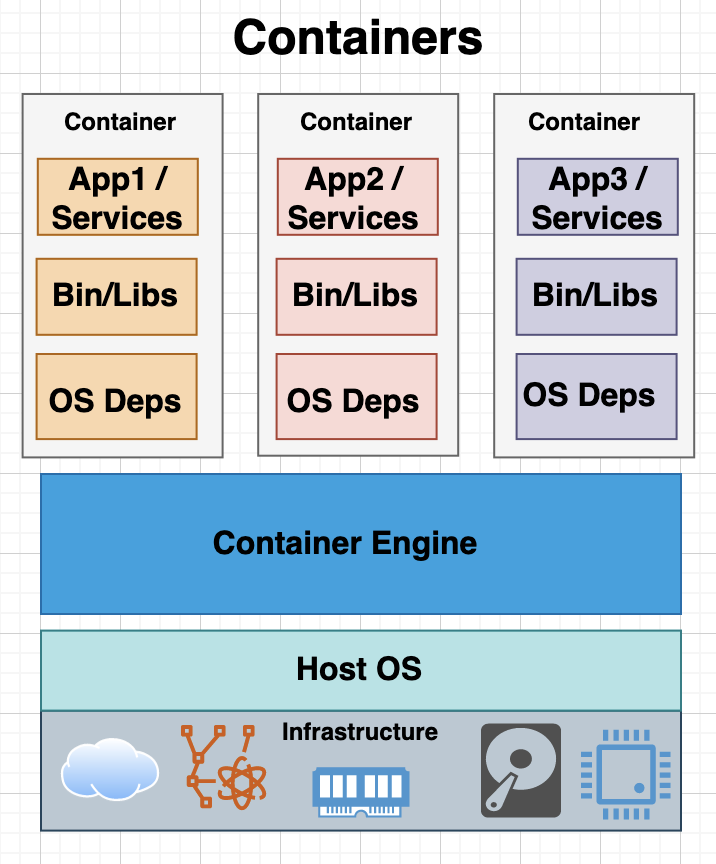
3.4.3 MicroVM
MicroVMs such as Firecracker and crosVM are based on kernel-based VM (KVM) and use hostOS acting as a hypervisor to provide isolation and security. As MicroVMs only include essential features for network, storage, throttling and metadata so they are quick to start and can scale to support multiple VMs with minimal overhead. A number of serverless platforms such as AWS Lambda, appfleet, containerd, Fly.io, Kata, Koyeb, OpenNebula, Qovery, UniK, and Weave FireKube have adopted Firecracker VM, which offers low overhead for starting a new virtual machine or executing a serverless workload.

3.4.4 WebAssembly
The WebAssembly is a stack-based virtual machine that can run at the edge or in cloud. The applications written Go, C, Rust, AssemblyScript, etc. are compiled into WebAssembly binary and are then executed on a WebAssembly runtime such as extism, faasm, wasmtime, wamr, wasmr and wagi. The WebAssembly supports WebAssembly System Interface (WASI) standard, which provides access to the systems APIs for different operating systems similar to POSIX standard. There is also an active development of WebAssembly Component Model with proposals such as WebIDL bindings and Interface Types. This allows you to write microservices in any supported language, compile the code into WASM binary and then deploy in a managed platform with all support for security, traffic management, observability, etc.
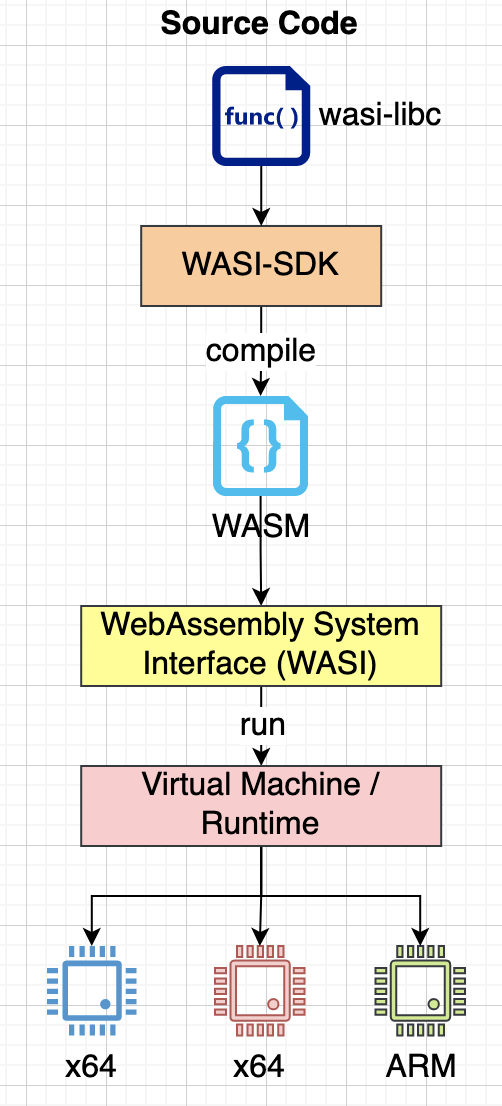
A number of WebAssembly platforms such as teaclave, wasmCloud, fermyon and Lunatic have also adopted Actor model to build a platform for writing distributed applications.
3.5 Instrumentation and Service Binding
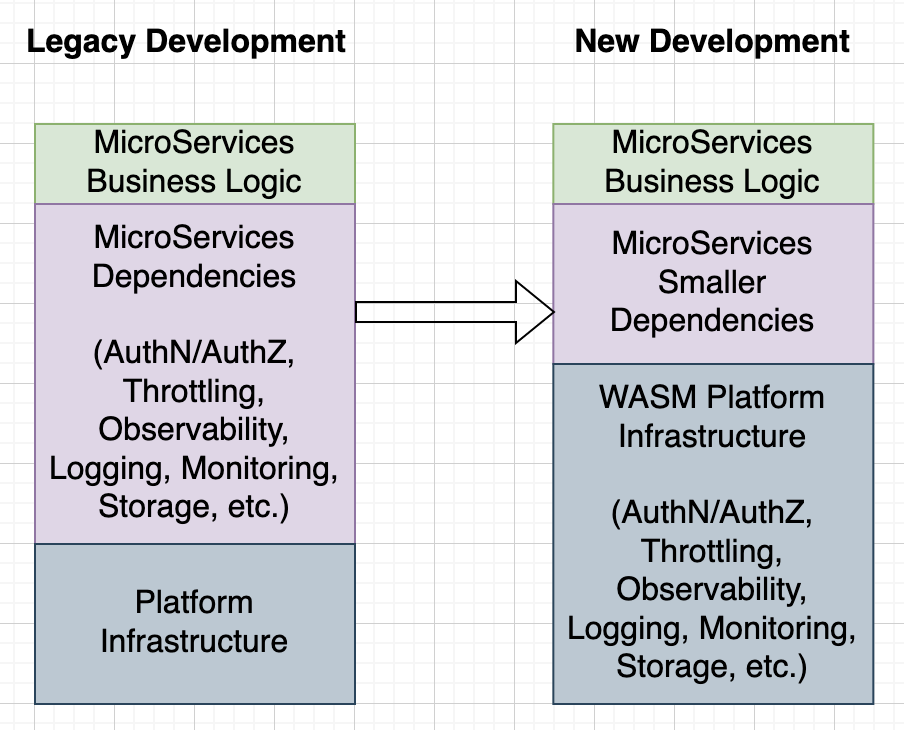
In order to reduce service code that deals specifically with non-functional capabilities such as authentication, authorization, logging, monitoring, etc., the business service can be instrumented to provide those capabilities at compile or deployment time. This means that the development team can largely focus on the business requirements and instrumentation takes care of adding metrics, failure reporting, diagnostics, monitoring, etc. without any development work. In addition, any external platform dependencies such as messaging service, orchestration, database, key/value store, caching can be injected into the service dynamically at runtime. The runtime can be configured to provide different implementation for the platform services, e.g. it may use a local Redis server for key/value store in a hosted environment or AWS/Azure’s implementation in a cloud environment.
When deploying services with WebAssembly support, the instrumentation may use WebAssembly libraries for extending the services to support authentication, rate-limiting, observability, monitoring, state management, and other non-functional capabilities, so that the development work can be shortened as shown below:
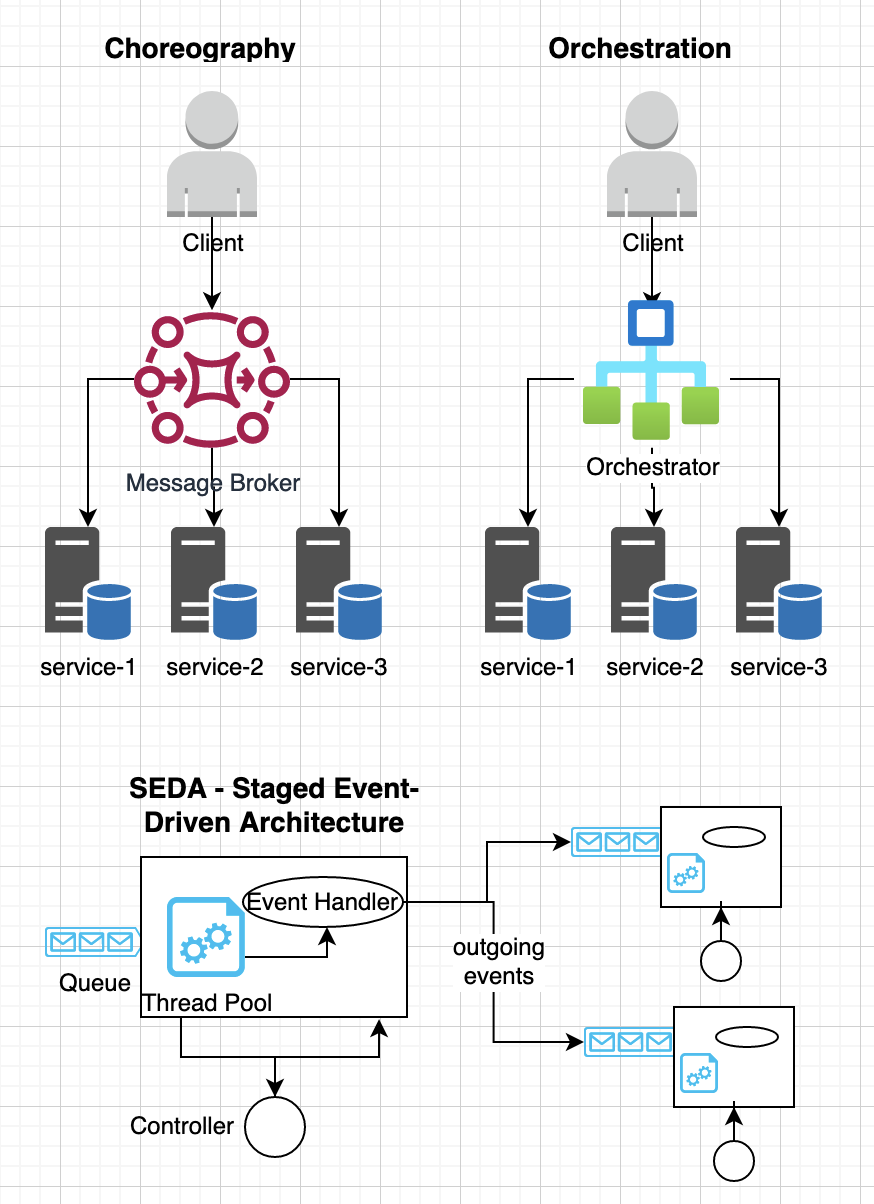
3.6 Orchestration and Choreography
The orchestration and choreography allows writing microservices that can be easily composed to provide a higher abstractions for business services. In orchestration design, a coordinator manages synchronous communication among different services whereas choreography uses event-driven architecture to communicate asynchronously. An actor model fits naturally with event based architecture for communicating with other actors and external services. However, orchestration services can be used to model complex business processes where a SAGA pattern is used to manage state transitions for different activities. Microservices may also use staged event-driven architecture (SEDA) to decompose complex event-driven services into a set of stages that are connected by different queues, which supports better modularity and code-reuse. SEDA allows enforcing admission control on each event queue and grants flexible scheduling for processing events based on adaptive workload controls and load shedding policies.
3.7 Automation, Continuous Deployment and Infrastructure as a code
Automation is a key to remove any drudgery work during the development process and consolidate common build processes such as continuous integration and deployment for improving the productivity of a development team. The development teams can employ continuous delivery to deploy small and frequent changes by developers. The continuous deployment often uses rolling updates, blue/green deployments or canary deployments to minimize disruption to end users. The monitoring system watches for error rates at each stage of the deployment and automatically rollbacks changes if a problem occurs.
Infrastructure as code (IaC) uses a declarative language to define development, test and production environment, which is managed by the source code management software. These provisioning and configuration logic can be used by CI/CD pipelines to automatically deploy and test environments. Many cloud vendors provide support for IaC such as Azure Resource Manager (ARM), AWS Cloud Development Kit (CDK), Hashicorp Terraform etc to deploy computing resources.
3.8 Proxy Patterns
Following sections shows implementing cross cutting concerns using proxy patterns for building microservices:
3.8.1 Sidecar Model
The sidecar model helps modularity and reusability where an application requires two containers: application container and sidebar container where sidebar container provides additional functionality such as adding SSL proxy for the service, observability, collecting metrics for the application container.
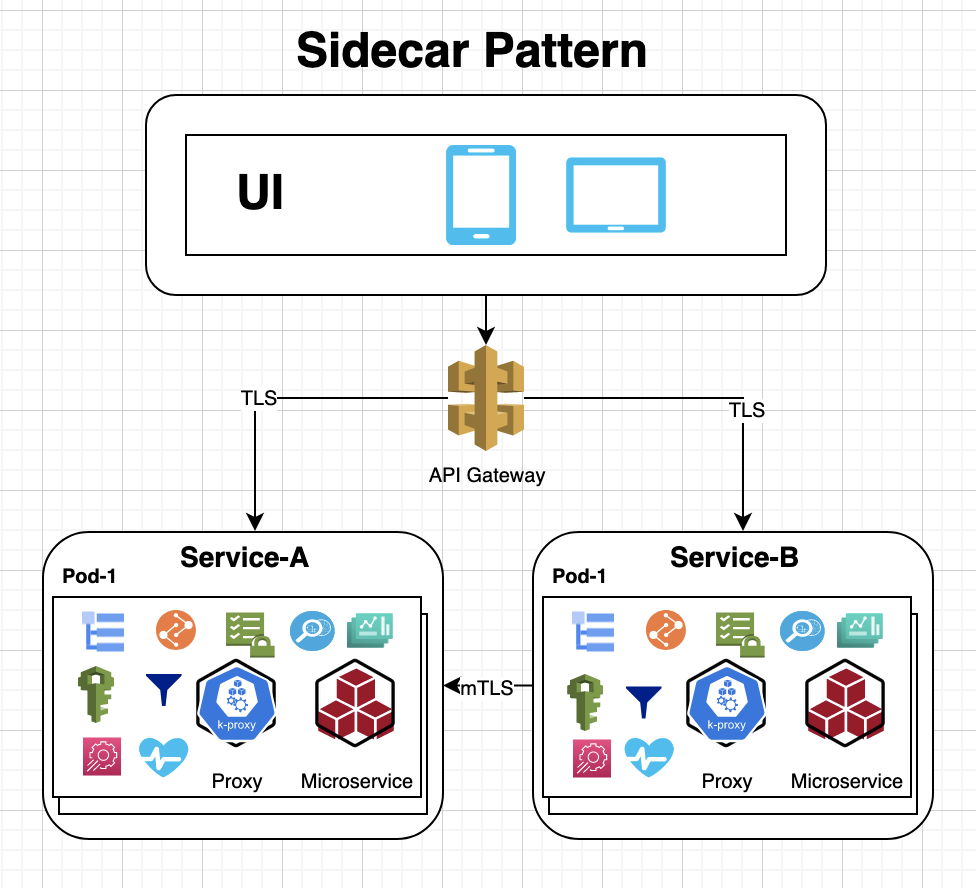
The Sidecar pattern generally uses another container to proxy off all traffic, which enforces security, access control, throttling before forwarding the incoming requests to the microservice.
3.8.2 Service Mesh
The service mesh uses a mesh of sidecar proxies to enable:
- Dynamic request routing for blue-green deployments, canaries, and A/B testing
- Load balancing based on latency, geographic locations or health checks
- Service discovery based on a version of the service in an environment
- TLS/mTLS encryption
- Authentication and Authorization
- Keys, certificates and secrets management
- Rate limiting and throttling
- State management and PubSub
- Observability, metrics, monitoring, logging
- Distributed tracing
- Traffic management and traffic splitting
- Circuit breaker and retries using libraries like Finagle, Stubby, and Hysterix to isolate unhealthy instances and gradually adding them back after successful health checks
- Error handling and fault tolerance
- Control plane to manage routing tables, service discovery, load balancer and other service configuration
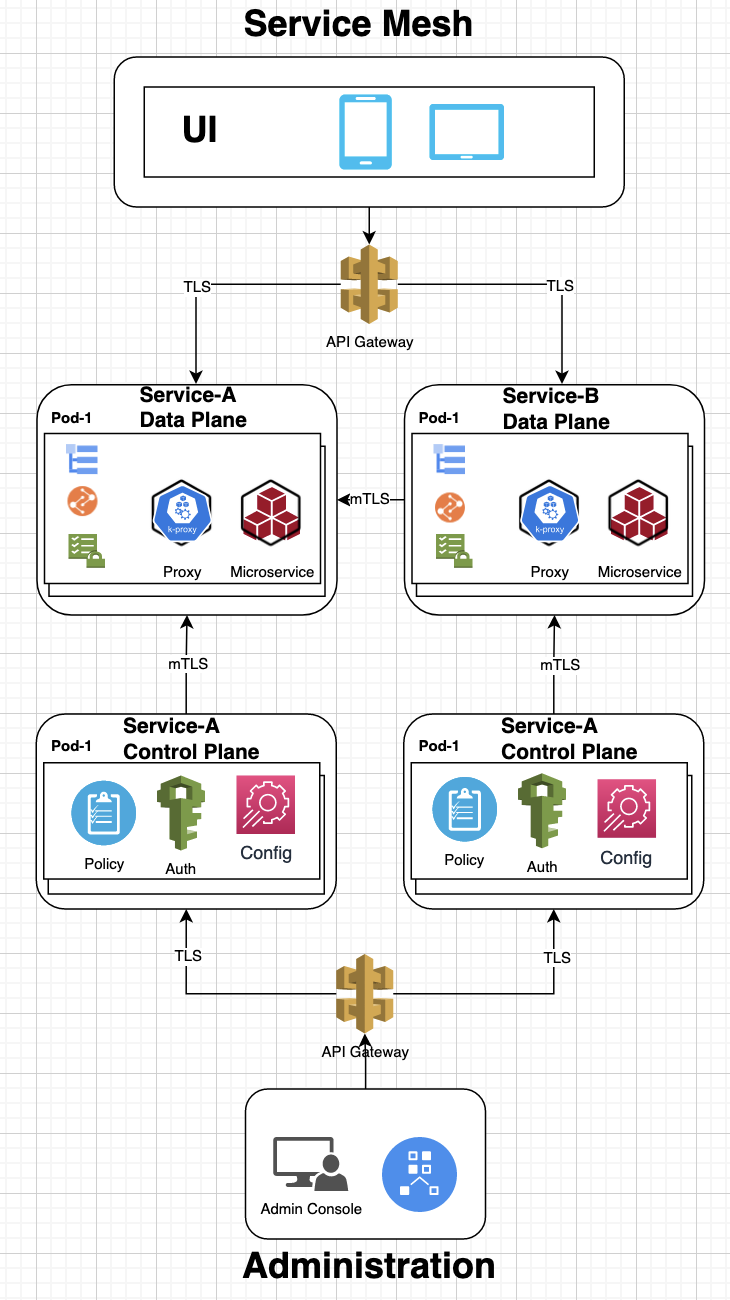
The service mesh pattern uses a data plane to host microservices and all incoming and outgoing requests go through a sidecar proxy that implements cross cutting concerns such as security, routing, throttling, etc. The control-plan in mesh network allows administrators to change the behavior of data plane proxies or configuration for data access. Popular service mesh frameworks include Consul, Distributed Application Runtime (Dapr), Envoy, Istio, Linkerd, Kong, Koyeb and Kuma for providing control-plane and data-plane with builtin support for networking, observability, traffic management and security. Dapr mesh network also supports Actor-model using the Orleans Virtual Actor pattern, which leverages the scalability and reliability guarantees of the underlying platform.
3.9 Cell-Based Architecture
A Cell-based Architecture (CBA) allows grouping business functions into single units called “cells”, which provides better scalability, modularity, composibility, disaster-recovery and governance for building microservices. It reduces the number of deployment units for microservices, thus simplifying the artificial complexity in building distributed systems.
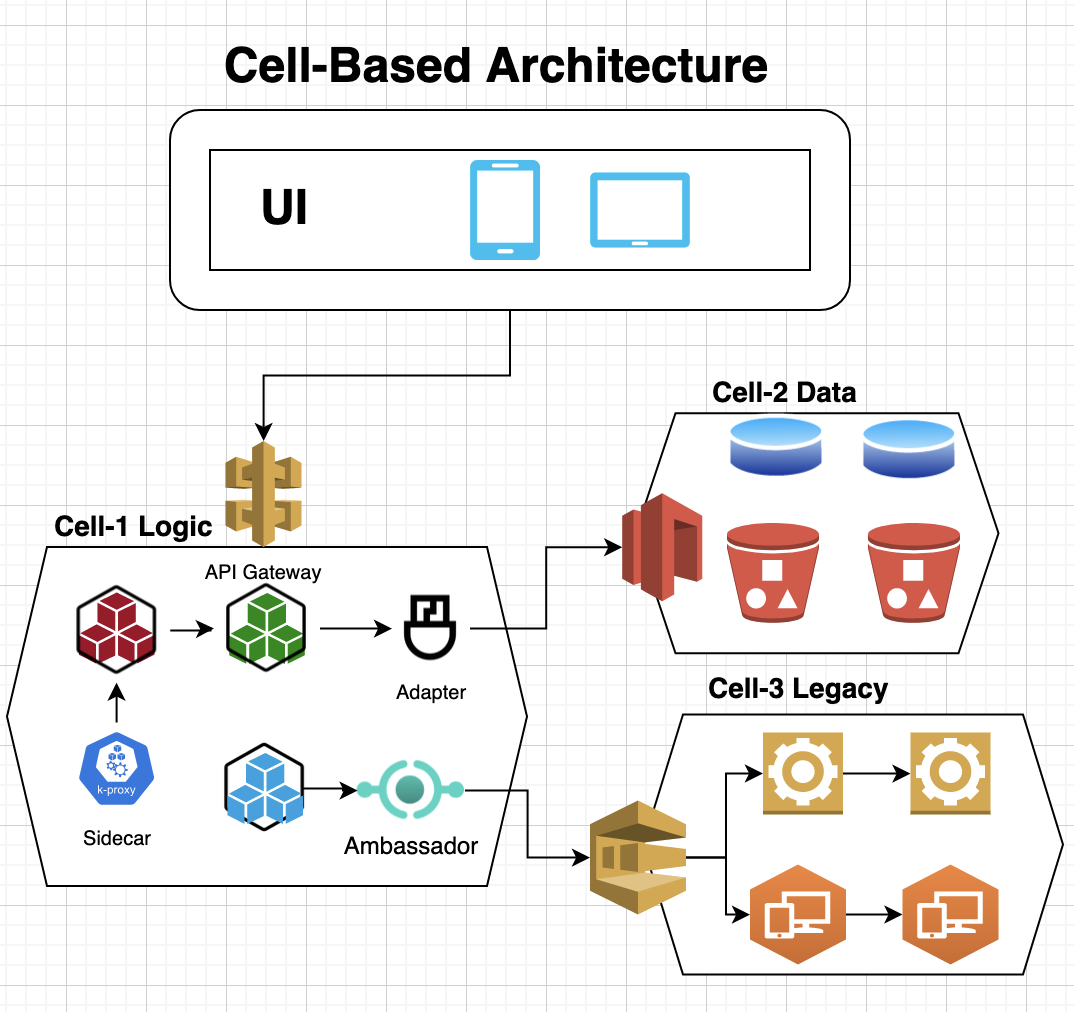
A cell is an immutable collection of components and services that is independently deployable, manageable, and observable. The components and services in a cell communicate with each other using local network protocols and other cells via network endpoints through a cell gateway or brokers. A cell defines an API interface as part of its definition, which provides better isolation, short radius blast and agility because releases can be rolled out cell by cell. However, in order to maintain the isolation, a cell should be either self contained for all service dependencies or dependent cells should be on the same region so that there is no cross region dependency.
3.10 12-Factor app
The 12-factor app is a set of best practices from Heroku for deploying applications and services in a virtualized environment. It recommends using declarative configuration for automation, enabling continuous deployment and other best practices. Though, these recommendations are a bit dated but most of them still holds except you may consider storing credentials or keys in a secret store or in an encrypted files instead of simply using environment variables.
4. New Software Development Workflow
The architecture patterns, virtual machines, WebAssembly and serverless computing described in above section can be used to simplify the development of microservices and easily support both functional and non-functional requirements of the business needs. Following sections describe how these patterns can be integrated with the software development lifecycle:
4.1 Development
4.1. Adopting WebAssembly as the Lingua Franca
WebAssembly along with its component model and WASI standard has been gaining support and many popular languages now can be compiled into wasm binary. Microservices can be developed in supported languages and ubiquitous WebAssembly support in production environment can reduce the development and maintenance drudgery for the application development teams. In addition, teams can leverage a number of serverless platforms that support WebAssembly such as extism, faasm, netlify, vercel, wasmcloud and wasmedge to reduce the operational load.
4.1.2 Instrumentation and Service Binding
The compiled WASM binary for microservices can be instrumented similar to aspects so that the generated code automatically supports horizontal concerns such as circuit breaker, diagnostics, failure reporting, metrics, monitoring, retries, tracing, etc. without any additional endeavor by the application developer.
In addition, the runtime can use service mesh features to bind external platform services such as event bus, data store, caching, service registry or dependent business services. This simplifies the development effort as development team can use the shared services for developing microservices instead of configuring and deploying infrastructure for each service. The shared infrastructure services support multi-tenancy and distinct namespaces for each microservice so that it can manage its state independently.
4.1.3 Adopting Actor Model for Microservices
As discussed above, the actor model offers a light-weight and highly concurrent model to implement a microservice APIs. The actors based microservices can be coded in any supported high-level language but then compiled into WebAssembly with a WASI support. A number of WebAssembly serverless platforms including Lunatic and wasmCloud already support Actor model while other platforms such as fermyon use http based request handlers, which are invoked for each request similar to actors based message passing. For example, here is a sample actor model in wasmCloud in Rust language though any language with wit-bindgen is supported as well:
#[derive(Debug, Default, Actor, HealthResponder)]
#[services(Actor, HttpServer)]
struct HelloActor {}
#[async_trait]
impl HttpServer for HelloActor {
async fn handle_request(
&self,
_ctx: &Context,
req: &HttpRequest,
) -> std::result::Result<HttpResponse, RpcError> {
let text=form_urlencoded::parse(req.query_string.as_bytes())
.find(|(n, _)| n == "name")
.map(|(_, v)| v.to_string())
.unwrap_or_else(|| "World".to_string());
Ok(HttpResponse {
body: format!("Hello {}", text).as_bytes().to_vec(),
..Default::default()
})
}
}The wasmCloud supports Contract-driven design and development (CDD) using Wasmcloud interfaces based on smithy IDL for building microservices and composable systems. There is also a pending work to support OpenFaas with wasmCloud to invoke functions on capability providers with appropriate privileges.
Following example demonstrates similar capability with fermyon, which can be deployed to Fermyon Cloud:
use anyhow::Result;
use spin_sdk::{
http::{Request, Response},
http_component,
};
#[http_component]
fn hello_rust(req: Request) -> Result<Response> {
println!("{:?}", req.headers());
Ok(http::Response::builder()
.status(200)
.header("foo", "bar")
.body(Some("Hello, Fermyon".into()))?)
}Following example shows how Dapr and WasmEdge work together to support lightweight WebAssembly-based microservices in a cloud-native environment:
fn main() -> std::io::Result<()> {
let port = std::env::var("PORT").unwrap_or(9005.to_string());
println!("new connection at {}", port);
let listener = TcpListener::bind(format!("127.0.0.1:{}", port))?;
loop {
let _ = handle_client(listener.accept()?.0);
}
}
fn handle_client(mut stream: TcpStream) -> std::io::Result<()> {
... ...
}
fn handle_http(req: Request<Vec<u8>>) -> bytecodec::Result<Response<String>> {
... ...
}The WasmEdge can also be used with other serverless platforms such as Vercel, Netlify, AWS Lambda, SecondState and Tencent.
4.1.4 Service Composition with Orchestration and Choreography
As described above, actors based microservices can be extended with the orchestration patterns such as SAGA and choreography/event driven architecture patterns such as SEDA to build composable services. These design patterns can be used to build loosely coupled and extensible systems where additional actors and components can be added without changing existing code.
4.2 Deployment and Runtime
4.2.1 Virtual Machines and Serverless Platform
Following diagram shows the evolution of virtualized environments for hosting applications, services, serverless functions and actors:
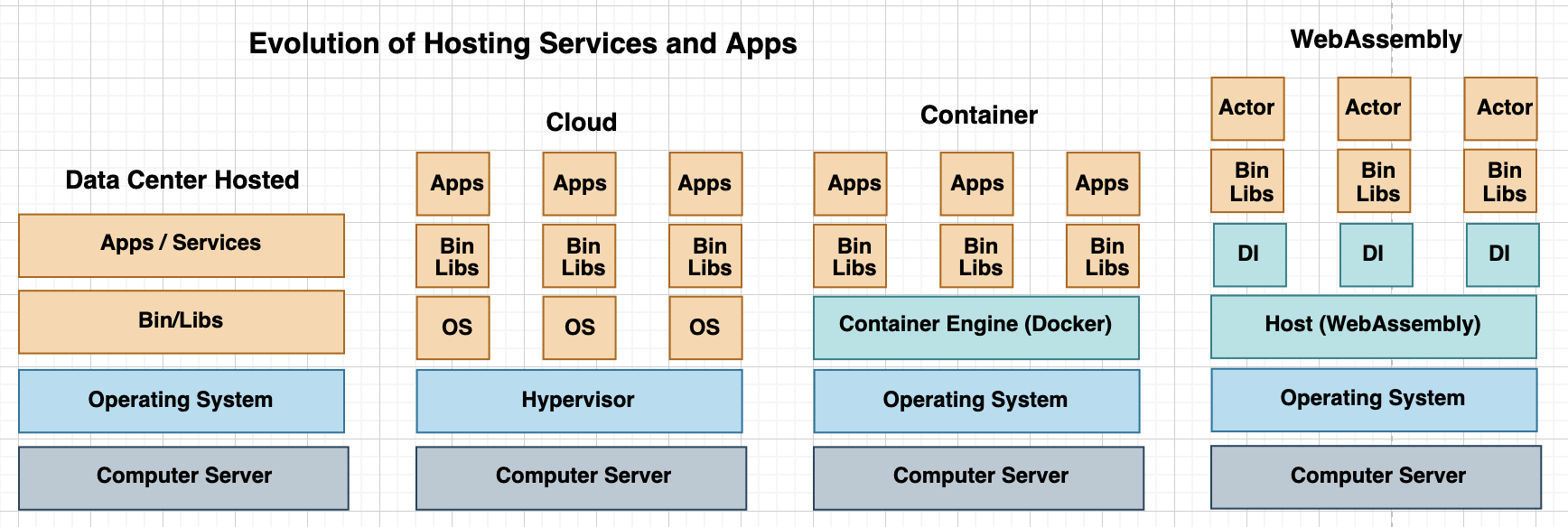
In this architecture, the microservices are compiled into wasm binary, instrumented and then deployed in a micro virtual machine.
4.2.2 Sidecar Proxy and Service Mesh
Though, the service code will be instrumented with additional support for error handling, metrics, alerts, monitoring, tracing, etc. before the deployment but we can further enforce access policies, rate limiting, key management, etc. using a sidecar proxy or service mesh patterns:
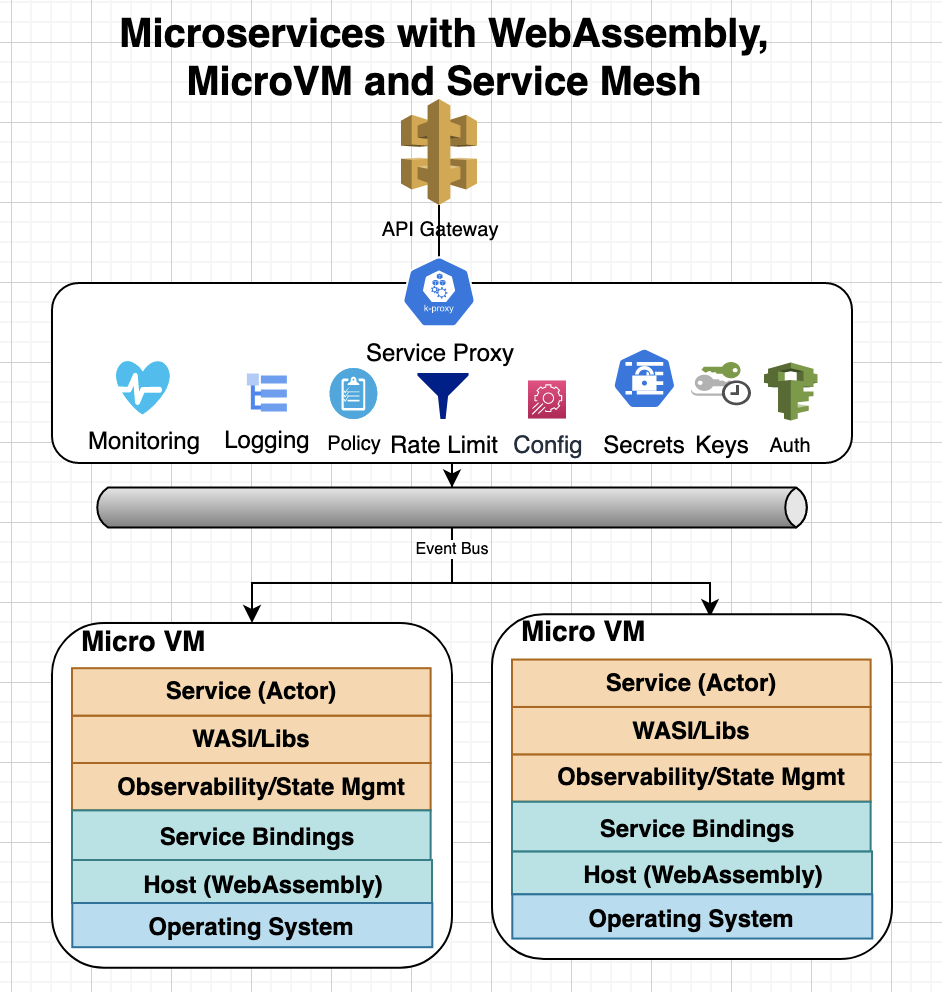
For example, WasmEdge can be integrated with Dapr service mesh for adding building blocks for state management, event bus, orchestration, observability, traffic routing, and bindings to external services. Similarly, wasmCloud can be extended with additional non-functional capabilities by implementing capability provider. wasmCloud also provides a lattice, self-healing mesh network for simplifying communication between actors and capability providers.
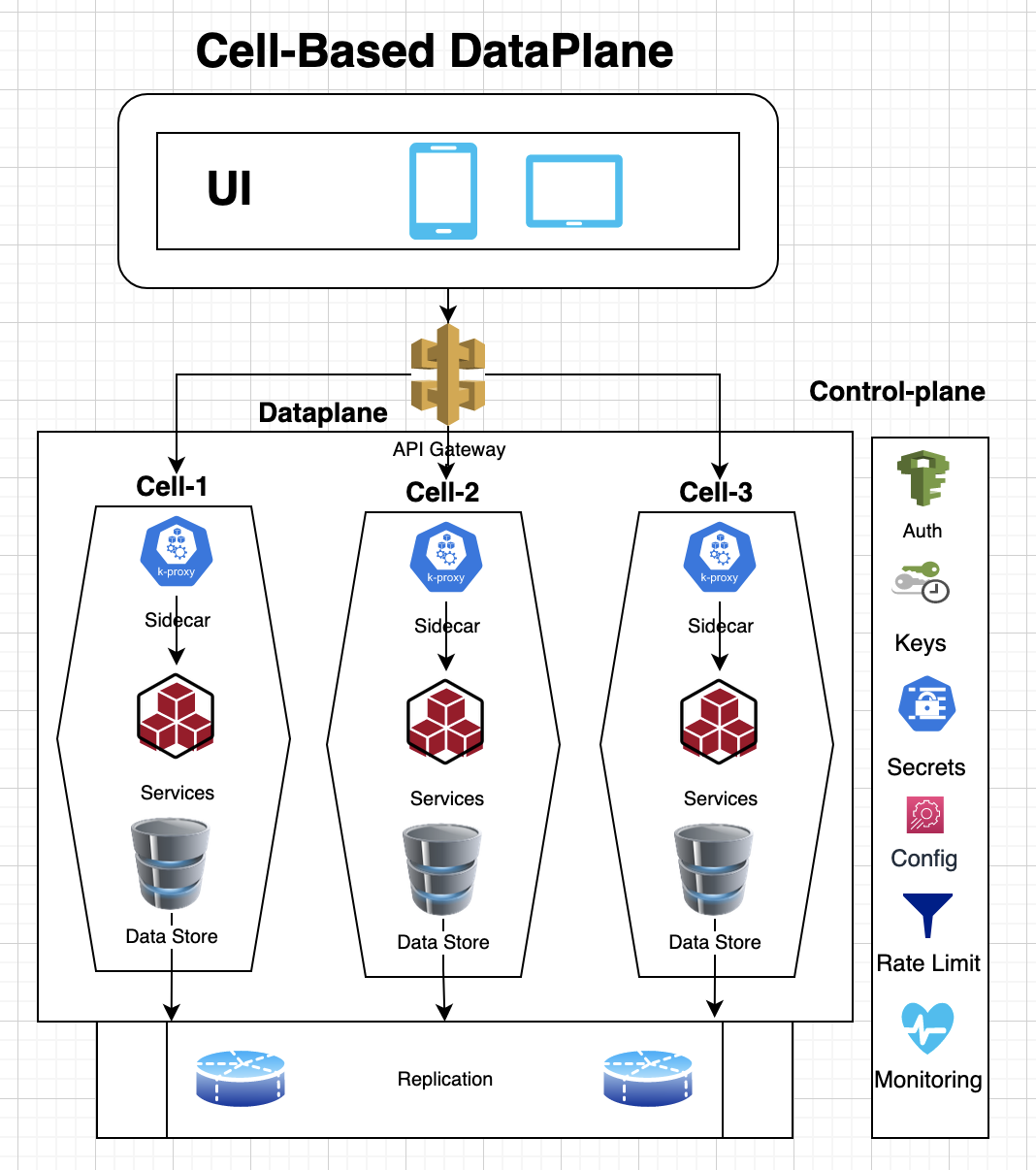
4.2.3 Cellular Deployment
As described above, Cell-based Architecture (CBA) provides better scalability, modularity, composibility and business continuity for building microservices. Following diagram shows how above design with virtual machines, service-mesh and WebAssembly can be extended to support cell-based architecture:

In above architecture, each cell deploys a set of related microservices for an application that persists state in a replicated data store and communicate with other cells with an event-bus. In this model, separate cells are employed to access data-plane services and control-plane services for configuration and administration purpose.
5. Conclusion
The transition of monolithic services towards microservices architecture over last many years has helped development teams to be more agile in building modular and reusable code. However, as teams are building a growing number new microservices, they are also tasked with supporting non-functional requirements for each service such as high availability, capacity planning, scalability, performance, recovery, resilience, security, observability, etc. In addition, each microservice may depend on numerous other microservices, thus a microservice becomes susceptible to scaling/availability limits or security breaches in any of the downstream services. Such tight coupling of horizontal concerns escalates complexity, development undertaking and operational load by each development team resulting in larger time to market for new features and larger risk for outages due to divergence in implementing non-functional concerns. Though, serverless computing, function as a service (Faas) and event-driven compute services have emerged to solve many of these problems but they remain limited in the range of capabilities they offer and lack a common standards across vendors. The advancements in micro virtual machines and containers have created a boon to the serverless platforms such as appfleet, containerd, Fly.io, Kata, Koyeb, OpenNebula, Qovery, UniK, and Weave FireKube. In addition, widespread adoption of WebAssembly along with its component model and WASI standard are helping these serverless platforms such as extism, faasm, netlify, vercel, wasmcloud and wasmedge to build more modular and reusable components. These serverless platforms allow the development teams to primarily focus on building business features and offload all non-functional concerns to the underlying platforms. Many of these serverless platforms also support service mesh and sidecar patterns so that they can bind platform and dependent services and automatically handle concerns such as throttling, security, state management, secrets, key management, etc. Though, cell-based architecture is still relatively new and is only supported by more matured serverless and cloud platforms, but it further raises scalability, modularity, composibility, business continuity and governance of microservices. As each cell is isolated, it adds agility to deploy code changes to a single cell and use canary tests to validate the changes before deploying code to all cells. Due to such isolated deployment, cell-based architecture reduces the blast radius if a bug is found during validation or other production issues are discovered. Finally, automating continuous deployment processes and applying Infrastructure as code (IaC) can simplify local development and deployment so that developers use the same infrastructure setup for local testing as the production environment. This means that the services can be deployed in any environment consistently, thus reduces any manual configuration or subtle bugs due to misconfigurations.
In summary, the development teams will greatly benefit from the architecture patterns, virtualized environments, WebAssembly and serverless platforms described above so that application developers are not burdened with maintaining horizontal concerns and instead they focus on building core product features, which will be the differentiating factors in the competing markets. These serverless and managed platform not only boosts developer productivity but also lowers the infrastructure cost, operational overhead, cruft development work and the time to market for releasing new features.