I just finished reading “Tidy First?” by Kent Beck. I have been following Kent for a long time since early days of XUnit and Extreme programming in late 90s. Kent is one of few influential people who have changed the landscape of software development and I have discussed some of his work in previous blogs such as Tips from Implementation Patterns, Responsibility vs Accountability, Heuristics from “Code That Fits in Your Head”, etc. In this book, Kent describes the concept of Tidy to clean up messy code so that you can make changes easily. The concept of Tidying is very similar to “Refactoring”, and though Refactoring originally meant changing the structure without changing the behavior but it has lost that distinction and now applies to both structure and behavior changes. In addition, the question mark in the book title implies that you may choose to tidy your code based on cost and benefits from the changes. This book is also heavily influenced by Structured Design: Fundamentals of a Discipline of Computer Program and Systems Design by Edward Yourdon and Larry Constantine who introduced the concept of coupling and cohesion, which is very fundamental to the software design. I also read that book in late 80s when I first learned about the structured design and programming with concepts such as a single entry and a single exit, cohesion and coupling, etc.
The “Tidy First?” book is very light and concise, which assumes that you are already familiar with a lot of fundamental concepts of software design but following are a few essential lessons from the book:
1. Guard Clauses
This is part of the first section that describes techniques for tidying that suggests adding guard clauses to routines. The author does not mention structured programming directly and only gives an example of FORTRAN that frowned upon multiple returns because debugging with multiple returns in that environment was hard. Instead the author advocates early return to reduce nested conditional logic but cautions against overuse of too many early returns. This advice is also similar to the Replace Nested Conditional with Guard Clauses technique from the Refactoring book though the author does not references it.
2. Dead Code
The author advocates deleting dead code, which is no-brainer.
3. Normalize Symmetries
The author advocates a consistency especially when different parts of a system are grown organically that might solve same problem differently. For example, you might see different ways of lazy initialization in different parts of the system that can confuse readers.
4. New Interface, Old Implementation
When dealing with a complex interface or implementation, Kent suggests creating a new pass through interface that simplifies the interaction with the old implementation. The original Refactoring book by Martin Fowler also includes a number of similar patterns and techniques such as Composing Methods, Extract Method, Replace Method with Method Object, Extract Class, etc. but the author does not reference those in the book.
5. Reading Order
When working with a long file, you may be tempted to refactor it into multiple smaller modules but the author suggests reordering parts of the file so that it’s easy for a reader to understand it. The author again cautions against mixing behavior changes with structure changes to minimize risks associated with the tidying the code.
6. Cohesion Order
When extending an existing system requires changing several widely dispersed sports in the code, you may be tempted to refactor existing code to make code more cohesive. However, the author suggests just placing cohesive code next to each other first before larger refactoring and recommends decoupling only when:
cost((decoupling) + cost(change) < cost(coupling) + cost(change)
7. Move Declaration and Initialization Together
This is another no-brainer and unlike older languages that required explicit declaration of variables, most modern languages encourage declaration and initialization together.
8. Explaining Variables
Instead of using a complex expression upon initialization a struct or invoking a method, the author recommends using well named variables to extract the sub-expressions. This advice is similar to the Extract Variable technique from the Refactoring book though the author does not cite the source.
9. Explaining Constants
The advice of extracting constants dates back to the structured programming and design and Refactoring book also includes Replace Magic Number with Symbolic Constant for similar advice though the author does not cite those sources. However, the author does caution against adding coupling for constants, e.g., if you have ONE defined as 1 in a module, you don’t need to import that module just to reuse that constant.
10. Explicit Parameters
The author recommends passing explicit parameters instead of passing a map that may include a lot of unrelated properties. Similarly, instead of accessing environment variables deep in the code, extract them at the top-level and then pass them explicitly. This advice is similar to the Stamp coupling (data-structured coupling) that cautions against passing a composite data structure when a routine uses only parts of it though the author does not references it in the book.
Note: other forms of coupling defined in the structured design (not referenced in the book) includes content coupling (high – information hiding), common coupling (sharing global data), external coupling (same format/protocol), control coupling (passing flag to control the flow), and data coupling (sharing parameters).
11. Chunk Statement
This technique simply recommends adding a blank line between parts of the code that are closely related. Though, you may use other refactoring techniques such as Extract Method, Move Method or other techniques but tidying up is less costly.
12. Extract Helper
In this technique, you extract a part of the code that has limited interaction with other code into a helper routine. In this case, the author does cite Extract Method from the Refactoring book. Another thing that you may consider that the author didn’t mention explicitly is to using one level of abstraction to facilitate reading code from top to bottom, which is cited in the Clean Code book.
13. One Pile
When dealing with a system where the code is split into many tiny pieces, the author recommends inlining the code into a single pile and then tidy it up. The author offers a few symptoms such as long, repeated argument lists; repeated cod with conditionals; poor naming of helper routines; shared mutable data structures for the code that can be tidy up. This technique is somewhat similar to Inline Class and Consolidate Duplicate Conditional Fragments techniques from the Refactoring book. In my experience, a lot of emphasis on unit testing to decoupling different parts of the system causes the code to split into tiny pieces but author does not go into specific reasons. Also, it may not be practical to create a single pile if there is a large complex code and author provides no practical examples for this technique.
14. Explaining Comments
This another common advice where the author suggests commenting only what wasn’t obvious from the code from the reader’s perspective. Other uses of comments can be a TODO when a code has a bug or requires changes for other limitations.
15. Delete Redundant Comments
This common advice probably could have combined with previous advice and suggests eliminating any comments that are obvious from the code.
16. Separate Tidying
This is part of the second part of the book that describes how tidying up fits into the software development lifecycle. When making changes to tidy up, you will have to consider how big are those changes, how many PRs you will need, and whether you should combine multiple PRs for structure. Ultimately, this requires some experimentation and customization based on your organization. Finally, author recommends omitting reviews for tidying PRs, which in my opinion is a bit risky unless you have fairly rigorous test harness. I have observed a trivial or innocuous change sometime can cause undefined behavior. For example, you might have removed dead-code but then find out later that some parts of the system still had some dependency on it.
17. Chaining
In this chapter, the author suggests tiny tidying steps and build upon various techniques for tidying up discussed in the first section such as guard clause, dead code, normalize symmetries, etc. The author is a bit apologetic for being anti-comment (or anti-documentation) as the agile movement specially extreme-programming does not explicitly calls for it but commenting (and documentation) is essential part for understanding the code.
18. Batch Size
This chapter focuses on how many batches of structure and behavior related PRs for tidy up should be made before integrating and deploying. This requires evaluating a tradeoff with various number of tidying per batch. For example, the cost and risk increases as the batch size grows due to merge conflicts, interactions with behavior changes, and more speculation due to additional cost.
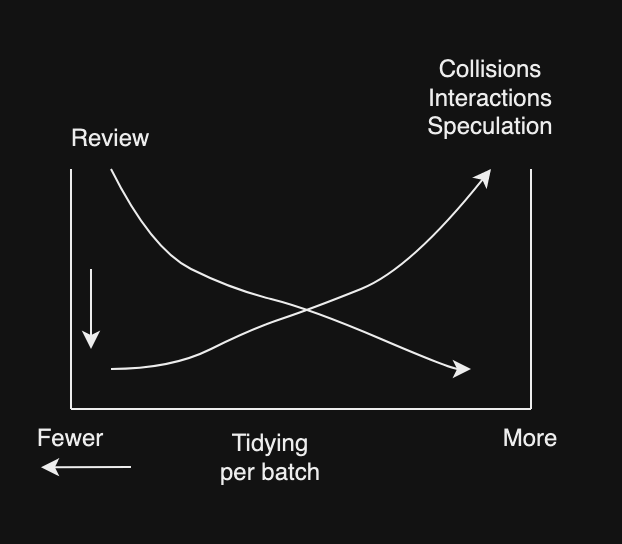
The author recommends smaller batches to reduce the cost of review to reduce the cost of tidying up but ultimately the teams will have to find the right balance.
19. Rhythm
The author suggests managing rhythm for tidying up in batches where each change takes a few minutes or an hour before enabling desired behavior changes. The author cites Pareto principle and argues that 80% of the changes will occur in 20% of the files so you may end up touching the same code for tidying up, which is why the author suggests tidying up in small increments.
20. Getting Untangled
When making behavior changes, you may see a lot of opportunities for tidy up with structure changes but it may result in combination of structure and behavior changes. In that case, you may be tempted to create a single PR for all changes, which can be error prone; split tidyings into separate PRs, which may add more work; discard your changes and start over with tidying first. Though, sunk cost fallacy may discourage last option but the author recommends experimenting with the last option.
21. First, After, Later, Never
This chapter discusses tidying up with respect to a behavior change in the system. The author suggests Never when the code does not require changing the behavior or an old mantra “if it ain’t broke, don’t fix it.” The Later is generally a fantasy but basically you will have to estimate the work for tidying up. Another benefit is that you may want to learn about how the behavior evolves before tidying it up. The author suggests After when the code is messy and you will need to change the same code again soon so it will be cheaper to tidy now and cost of tidying is proportion to the cost of behavior change. The author suggests First when it will simplify making behavior change with immediate benefits as long as the cost can be amortized with future changes. These tradeoffs in this chapter are very similar to managing technical debt that most teams have to manage but the author does not use this term in the book.
22. Beneficially Relating Elements
This is part of third section of the book that discusses software design, cost of changes, trade-offs with investing in the structure of software, and principles for making changes. The author in this chapter defines software design as “beneficially relating elements,” where elements can be composed and have sub-elements such as atoms->molecules->crystals, and elements can have boundaries. The elements can have relations with other elements such as Invokes, Publishes, Listens, Refers, etc., and elements benefit each other in creating larger systems. The author gives an example of restructuring following code:
caller(): return box.width() * box.height()
into following for simplification:
caller(): return box.area() Box>>area() return width() * height()
23. Structure and Behavior
The author describes behavior in terms of input/output pairs and invariants that should be maintained, which in turn creates value for businesses. The software creates value in providing the current behavior and how it can be extended for future changes. The author shows how software can provide greater value by supporting options for extension. This holds specially true for volatile environment and author relates lessons from his Extreme Programming Explained book, which I read back in 2004:

The structure of the system doesn’t matter directly to its behavior but it creates options for allowing behavior changes easily.
24. Economics: Time Value and Optionality
In this chapter, the author shares how he learned about the nature of money through a series of finance-related projects. The major lessons included:
- A dollar today is worth more than a dollar tomorrow.
- In a chaotic situation, options are better than things.
These strategies may conflict at times when earning now reduces future options, thus these trade-offs must be carefully considered using Net present value (NPV) and Options from the finance world.
25. A Dollar Today > A Dollar Tomorrow
A dollar today is more valuable than a dollar tomorrow because you can’t spend future dollar or invest it. As the software behavior creates value and makes money now so it encourages tidy after over tidy first. However, when cost of tidy-first + behavior-change is less than the cost of behavior change without tidying, then tidy first. In a nutshell, economic value of a software system is the sum of the discounted future cash flows.
26. Options
As discounted future cash flows conflict with optionality, you will need to find a balance in a Goldilocks world. The author shares how he learned about options pricing when working with trading software on Wall Street. These lessons included:
- What behavior an I implement next has the value even before it’s implemented.
- The more behavior in the portfolio, the more value will be created with optionality.
- The more uncertain are the predictions of value are, the greater the value of the option is.
The author then defines basics of options, that allows you option to buy or sell based on underlying price, premium of the option, and duration of the option. Having worked in an options trading company myself, I understand the value of options in risk management though chapter does not cover those topics.
In terms of the software design with optionality:
- The more volatile the value of a potential behavior change, the better.
- The longer the development duration, the better.
- The cheaper the software cost in future, the better.
- The less design work to create an option, the better.
27. Options Versus Cash Flow
The discounted cash flow biases towards making money sooner and don’t tidy first and options on the other side biases towards spending money now to make more money later or tidy first/after/later. Author recommends tidy first when
cost(tidying) + cost(behavior-change after tidying) < cost(behavior-change without tidying)
Though, in some cases you may want to tidy firs even if the cost with tidy-first is a bit higher by amortizing the cost against other future changes.
28. Reversible Structure Changes
The structure changes are generally reversible but behavior changes are not easily reversible, thus require rigorous reviews and validation. Also, certain design changes such as extracting a service is not reversible and requires careful planning, testing and feature-flags, etc. At Amazon where I work, these kind of decisions are called “one-way doors” and “two-way doors” decisions, which are considered for any changes to the APIs and implementation.
29. Coupling
This book narrates insights from Structured Design: Fundamentals of a Discipline of Computer Program and Systems Design where authors of the book noticed that all expensive programs had one property in common: changing one element required changing other elements, which was termed as coupling. Coupling drives the cost of software and more elements are coupled, the higher the cost of change will be. In addition, some coupling can be cascading where each element triggers more changes for dependent elements. The author also refers to “connascence” to describe coupling from Meilir Page-Jones that includes (not referenced in the book):
- Static connascences such as Connascence of name (CoN), Connascence of type (CoT), Connascence of meaning (CoM) or connascence of convention (CoC), Connascence of position (CoP), Connascence of algorithm (CoA).
- Dynamic connascence such as Connascence of execution (CoE), Connascence of timing (CoT), Connascence of timing is when the timing of the execution of multiple components is important., Connascence of values (CoV), Connascence of identity (CoI)
Though, the author does not discuss other forms of coupling but it’s worth knowing common coupling in object-oriented systems such as Subclass-coupling, Dynamic coupling, Semantic coupling, Logical coupling, and Temporal coupling.
In summary, it’s essential to understand dependent changes before tidying up. One thing lacking in this chapter was use of tooling as a lot of static analysis and dependency management tools can be used to gather this kind of data.
30. Constantine’s Equivalence
In Structured Design: Fundamentals of a Discipline of Computer Program and Systems Design, the authors (Larry/Yourdon) postulated that the goal of software design is to minimize the cost of software as most of the software lifecycle goes into maintenance. Kent defines Constantine’s Equivalence as:
cost(software) ~= cost(change)
The author uses power law distribution (bell graph) to graph cost per time that grows slowly, then rapidly, then shrinks. In other words:
cost(change) ~= cost(big change)
cost(big change) ~= coupling
cost(software) ~= coupling
31. Coupling Versus Decoupling
You may choose not to remove coupling due to its cost as defined by discounted cash flow. In other cases, coupling does not become problem until now. Finally, having some coupling is just inevitable. For example, you may try to reduce coupling in one part of the software but it shifts towards other parts. This means that you should try to find a balance by evaluating trades off with cost of decoupling.
32. Cohesion
When decoupling, you may group sub-elements under the same containing element with more cohesion and move unrelated elements out of the group. When sub-elements are changed together, they benefit from cohesion with ease of change and analysis. On the other hand uncoupled elements can be put under their own submodules or sibling modules, which require careful consideration. Other factors that I have found to be useful, which are not mentioned in the book include analyzing interactions and direction of communication. For example, when two elements are more chatty then they should be closer together. Similarly, I learned from Large-Scale C++ Software Design back in 90s that software design should try to remove any cyclic dependency across modules, which generally requires extracting common behavior into a separate module.
33. Conclusion
In this chapter, the author summarizes that “tidy first” is impacted by cost of change, revenue it generates, how coupling can be reduced to make changes faster, and how it will add cohesion so that changes are in smaller scope. The author encourages tidying up the code but cautions against against doing too much. Instead, tidy up to enable the next behavior change. This book is part of a series and though this book focuses on individuals but subsequent series will examine the relationships between changers as shown below:
- Who? | When? | What? | How? | Why?
- You | Minutes-Hours | Tidying | SB diff | Coupling and Cohesion
- You/Team | Days to Weeks | Refactoring | Wkly plan | Power laws
- Stakeholders | Months to years| Arch. evolution | Dyn blnce | ?
Overall, this book addresses essential tradeoffs between quality and speed of software delivery that each team has to face. As this book was very concise, I felt it missed a number of related topics. For example, first section many of techniques and patterns that are better explained in other books such as Refactoring book. This book also does not cover testing and use of static analysis tools such as lint, clippy, findbugs, checkstyle, etc. that can help identify code smells, dead code, cyclic dependencies, cyclomatic complexity, etc. Another dimension of software development is non-functional requirements that addresses quality, scalability, reliability, security, etc. For example, in chapter 23, the author claims that if you can send 1,000 notifications, you can almost certainly send 100,000 notifications but this requires architectural support for scaling and isn’t always guaranteed. In addition, with scale you also have to deal with failures such as timeout, retries, unavailability, etc., which is of lesser issue at smaller scale. I also felt that the author avoided some of well-defined terms such as technical-debt and quality metrics that are commonly used when dealing with tidying or refactoring your code. The insight to compare “tidying your code” (or technical-debt) to options trading isn’t new. For example, Steve Freeman wrote blog entry, Bad code isn’t Technical Debt, it’s an unhedged Call Option in 2010 about this and Jay Fields expanded on it with types of technical-debt in 2011. Ultimately, the tradeoffs related to tidying your code depends on your organization. For instance, I have worked a number of startups where they want to be paid now otherwise they won’t exist to earn the dollar tomorrow as well as large financial and technology companies where the quality of the code in terms of structure and non-functional aspects are just as essential as the behavior change. Nevertheless, this tiny book encourages individual contributors to make incremental improvements to the code and I look forward to Kent’s next books in the series.