Caching is often considered a “silver bullet” in software development due to its immediate and significant impact on the performance and scalability of applications. The benefits of caching include:
- Immediate Performance Gains: Caching can drastically reduce response times by storing frequently accessed data in memory, avoiding the need for slower database queries.
- Reduced Load on Backend Systems: By serving data from the cache particularly during traffic spikes, the load on backend services and databases is reduced, leading to better performance and potentially lower costs.
- Improved User Experience: Faster data retrieval leads to a smoother and more responsive user experience, which is crucial for customer satisfaction and retention.
- Scalability: Caching can help an application scale by handling increased load by distributing it across multiple cache instances without a proportional increase in backend resources.
- Availability: In cases of temporary outages or network issues, a cache can serve stale data, enhancing system availability.
However, implementing cache properly requires understanding many aspects such as caching strategies, caching locality, eviction policies and other challenges that are described below:
1. Caching Strategies
Following is a list of common caching strategies:
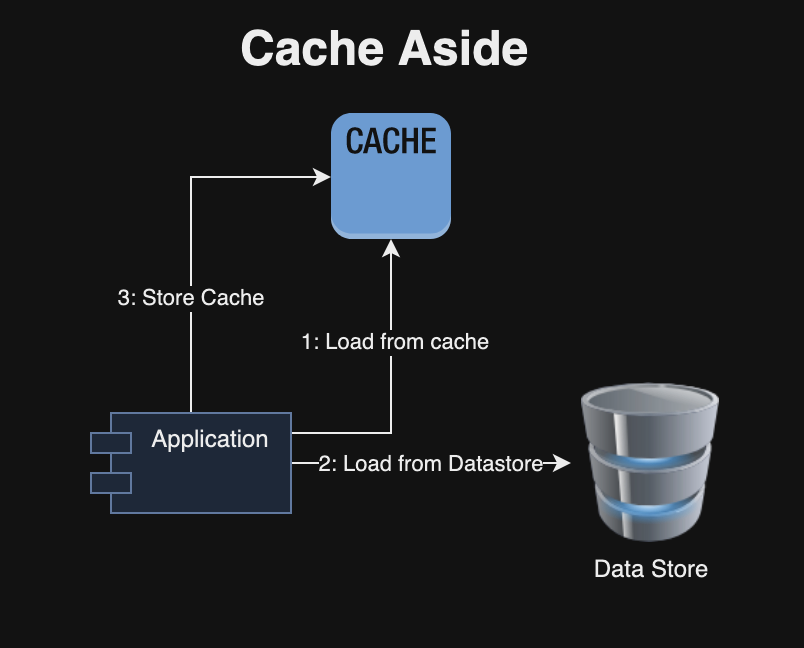
1.1 Cache Aside (Lazy Loading)
In a cache-aside strategy, data is loaded into the cache only when needed, in a lazy manner. Initially, the application checks the cache for the required data. In the event of a cache miss, it retrieves the data from the database or another data source and subsequently fills the cache with the response from the data server. This approach is relatively straightforward to implement and prevents unnecessary cache population. However, it places the responsibility of maintaining cache consistency on the application and results in increased latencies and cache misses during the initial access.
use std::collections::HashMap;
let mut cache = HashMap::new();
let key = "data_key";
if !cache.contains_key(key) {
let data = load_data_from_db(key); // Function to load data from the database
cache.insert(key, data);
}
let result = cache.get(key);
1.2 Read-Through Cache
In this strategy, the cache sits between the application and the data store. When a read occurs, if the data is not in the cache, it is retrieved from the data store and then returned to the application while also being stored in the cache. This approach simplifies application logic for cache management and cache consistency. However, initial reads may lead to higher latencies due to cache misses and cache may store unused data.

fn get_data(key: &str, cache: &mut HashMap<String, String>) -> String {
cache.entry(key.to_string()).or_insert_with(|| {
load_data_from_db(key) // Load from DB if not in cache
}).clone()
}
1.3 Write-Through Cache
In this strategy, data is written into the cache, which then updates the data store simultaneously. This ensures data consistency and provides higher efficiency for write-intensive applications. However, it may cause higher latency due to synchronously writing to both cache and the data store.

fn write_data(key: &str, value: &str, cache: &mut HashMap<String, String>) {
cache.insert(key.to_string(), value.to_string());
write_data_to_db(key, value); // Simultaneously write to DB
}1.4 Write-Around Cache
In this strategy, data is written directly to the data store, bypassing the cache. This approach is used to prevent the cache from being flooded with write-intensive operations and provides higher performance for applications that require less frequent reads. However, it may result in higher read latencies due to cache misses.

fn write_data(key: &str, value: &str, cache: &mut HashMap<String, String>) {
// Write directly to DB, bypass cache
write_data_to_db(key, value);
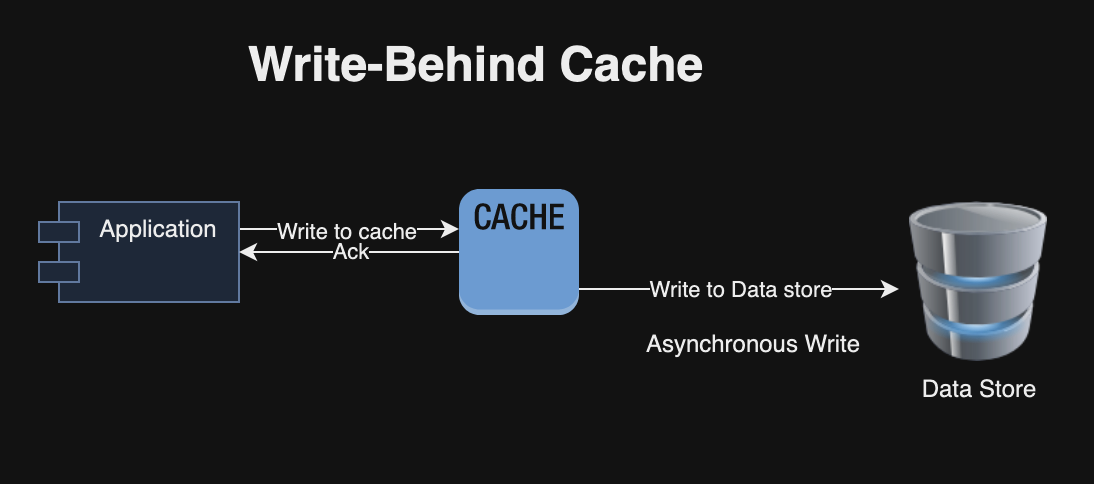
}1.5 Write-Back (Write-Behind) Cache
In this approach, data is first written to the cache and then, after a certain interval or condition, written to the data store. This reduces the latency of write operations and load on the data store. However, it may result in data loss if cache fails before the data is persisted in the data store. In addition, it adds more complexity to ensure data consistency and durability.
use std::collections::HashMap;
use std::thread;
use std::time::Duration;
fn write_data(key: &str, value: &str, cache: &mut HashMap<String, String>) {
cache.insert(key.to_string(), value.to_string());
// An example of asynchronous write to data store.
thread::spawn(move || {
thread::sleep(Duration::from_secs(5)); // Simulate delayed write
write_data_to_db(key, value);
});
}
1.6 Comparison of Caching Strategies
Following is comparison summary of above caching strategies:
- Performance: Write-back and write-through provide good performance for write operations but at the risk of data consistency (write-back) or increased latency (write-through). Cache-aside and read-through are generally better for read operations.
- Data Consistency: Read-through and write-through are strong in maintaining data consistency, as they ensure synchronization between the cache and the data store.
- Complexity: Cache-aside requires more application-level management, while read-through and write-through can simplify application logic but may require more sophisticated cache solutions.
- Use Case Suitability: The choosing right caching generally depends on the specific needs of the application, such as whether it is read or write-intensive, and the tolerance of data consistency versus performance.
2. Cache Eviction Strategies
Cache eviction strategies are crucial for managing cache memory, especially when the cache is full and new data needs to be stored. Here are some common cache eviction strategies:
2.1 Least Recently Used (LRU)
LRU removes the least recently accessed items first with assumption that items accessed recently are more likely to be accessed again. This is fairly simple and effective strategy but requires tracking access times and may not be suitable for some use-cases.
2.2 First In, First Out (FIFO)
FIFO evicts the oldest items first, based on when they were added to the cache. This strategy is easy to implement and offers a fair strategy by assigning same lifetime to each item. However, it does not account for frequency or recency of the item in cache so it may lead to lower cache hit rate.2.3
2.3 Least Frequently Used (LFU)
LFU removes items that are used least frequently by counting how often an item is accessed. It is useful for use-cases where some items are accessed more frequently but requires tracking frequency of access.
2.4 Random Replacement (RR)
RR randomly selects a cache item to evict. This method is straightforward to implement but it may remove important frequently or recently used items, leading to a lower hit rate and unpredictability of cache performance.
2.5 Time To Live (TTL)
In this strategy, items are evicted based on a predetermined time-to-live. After an item has been in the cache for the specified duration, it is automatically evicted. It is useful for data that becomes stale after a certain period but it does not consider item’s access frequency or recency.
2.6 Most Recently Used (MRU)
It is opposite of LRU and evicts the most recently used items. It may be effective for certain use-cases but leads to poor performance for most common use-cases.
and does not require keeping track of access patterns.
2.7 Comparison of Cache Eviction Strategies
- Adaptability: LRU and LFU are generally more adaptable to different access patterns compared to FIFO or RR.
- Complexity vs. Performance: LFU and LRU tend to offer better cache performance but are more complex to implement. RR and FIFO are simpler but might not offer optimal performance.
- Specific Scenarios: The choosing right eviction strategy generally depends on the specific access patterns of the application.
3. Cache Consistency
Cache consistency refers to ensuring that all copies of data in various caches are the same as the source of truth. Keeping data consistent across all caches can incur significant overhead, especially in distributed environments. There is often a trade-off between consistency and latency; stronger consistency can lead to higher latency. Here is list of other concepts related to cache consistency:
3.1 Cache Coherence
Cache coherence is related to consistency but usually refers to maintaining a uniform state of cached data in a distributed system. Maintaining cache coherence can be complex and resource-intensive due to communication between nodes and requires proper concurrency control to handle concurrent read/write operations.
3.2 Cache Invalidation
Cache invalidation involves removing or marking data in the cache as outdated when the corresponding data in the source changes. Invalidation can become complicated if cached objects have dependencies or relationships. Other tradeoffs include deciding whether to invalidate cache entries that may lead to cache misses or update them in place, which may be more complex.
3.3 Managing Stale Data
Stale data occurs when cached data is out of sync with the source. Managing stale data involves strategies to minimize the time window during which stale data might be served. Different data might have different rates of change, requiring varied approaches to managing staleness.
3.4 Thundering Herd Problem
The thundering herd problem occurs when many clients try to access a cache item that has just expired or been invalidated, causing all of them to hit the backend system simultaneously. A variant of this problem is the cache stampede, where multiple processes attempt to regenerate the cache concurrently after a cache miss.
3.5 Comparison of Cache Consistency Approaches
- Write Strategies: Write-through vs. write-back caching impact consistency and performance differently. Write-through improves consistency but can be slower, while write-back is faster but risks data loss and consistency issues.
- TTL and Eviction Policies: Time-to-live (TTL) settings and eviction policies can help manage stale data but require careful tuning based on data access patterns.
- Distributed Caching Solutions: Technologies like distributed cache systems (e.g., Redis, Memcached) offer features to handle these challenges but come with their own complexities.
- Event-Driven Invalidation: Using event-driven architectures to trigger cache invalidation can be effective but requires a well-designed message system.
4. Cache Locality
Cache locality refers to how data is organized and accessed in a cache system, which can significantly impact the performance and scalability of applications. There are several types of cache locality, each with its own set of tradeoffs and considerations:
4.1 Local/On-Server Caching
Local caching refers to storing data in memory on the same server or process that is running the application. It allows fast access to data as it doesn’t involve network calls or external dependencies. However, the cache size is limited by the server’s memory capacity and it is difficult to maintain consistency in distributed systems since each instance has its own cache without shared state. Other drawbacks include coldstart due to empty cache on server restart and lack of BulkHeads barrier because it takes memory away from the application server, which may cause application failure.
4.2 External Caching
External caching involves storing data on a separate server or service, such as Redis or Memcached. It can handle larger datasets as it’s not limited by the memory of a single server and offers shared state for multiple instances in distributed system. However, it is slower than local caching due to network latency and requires managing and maintaining separate caching infrastructure. Another drawback is that unavailability of external cache can result in higher load on the datastore and may cause cascading failure.
4.3 Inline Caching
Inline caching embeds caching logic directly in the application code, where data retrieval occurs. A key difference between inline and local caching is that local caching focuses on the cache being in the same physical or virtual server, while inline caching emphasizes the integration of cache logic directly within the application code. However, inline caching can make the application code more complex, tightly coupled and harder to maintain.
4.4 Side Caching
Side caching involves a separate service or layer that the application interacts with for cached data, often implemented as a microservice. It separates caching concerns from application logic. However, it requires managing an additional component. It differs from external caching as external caching is about a completely independent caching service that can be used by multiple different applications.
4.5 Combination of Local and External Cache
When dealing with the potential unavailability of an external cache, which can significantly affect the application’s availability and scalability as well as the load on the dependent datastore, a common approach is to integrate external caching with local caching. This strategy allows the application to fall back to serving data from the local cache, even if it might be stale, in case the external cache becomes unavailable. This requires setting maximum threshold for serving stale data besides setting expiration TTL for the item. Additionally, other remediation tactics such as load shedding and request throttling can be employed.
4.5 Comparison of Cache Locality
- Performance vs. Scalability: Local caching is faster but less scalable, while external caching scales better but introduces network latency.
- Complexity vs. Maintainability: Inline caching increases application complexity but offers precise control, whereas side caching simplifies the application but requires additional infrastructure management.
- Suitability: Local and inline caching are more suited to applications with specific, high-performance requirements and simpler architectures. In contrast, external and side caching are better for distributed, scalable systems and microservices architectures.
- Flexibility vs. Control: External and side caching provide more flexibility and are easier to scale and maintain. However, they offer less control over caching behavior compared to local and inline caching.
5. Monitoring, Metrics and Alarms
Monitoring a caching system effectively requires tracking various metrics to ensure optimal performance, detect failures, and identify any misbehavior or inefficiencies. Here are key metrics, monitoring practices, and alarm triggers that are typically used for caching systems:
5.1 Key Metrics for Caching Systems
- Hit Rate: The percentage of cache read operations that were served by the cache.
- Miss Rate: The percentage of cache read operations that required a fetch from the primary data store.
- Eviction Rate: The rate at which items are removed from the cache.
- Latency: Measures the time taken for cache read and write operations.
- Cache Size and Usage: Monitoring the total size of the cache and how much of it is being used helps in capacity planning and detecting memory leaks.
- Error Rates: The number of errors encountered during cache operations.
- Throughput: The number of read/write operations handled by the cache per unit of time.
- Load on Backend/Data Store: Measures the load on the primary data store, which can decrease with effective caching.
5.2 Monitoring and Alarm Triggers
By continuously monitoring, alerts can be configured for critical metrics thresholds, such as very low hit rates, high latency, or error rates exceeding a certain limit. These metrics help with capacity planning by observing high eviction rates along with a high utilization of cache size. Alarm can be triggered if error rates spike suddenly. Similarly, a significant drop in hit rate might indicate cache inefficiency or changing data access patterns.
6. Other Caching Considerations
In addition to the caching strategies, eviction policies, and data locality discussed earlier, there are several other important considerations that need special attention when designing and implementing a caching system:
6.1 Concurrency Control
A reliable caching approach requires handling simultaneous read and write operations in a multi-threaded or distributed environment while ensuring data integrity and avoiding data races.
6.2 Fault Tolerance and Recovery
The caching system should be resilient to failures and should be easy to recover from hardware or network failures without significant impact on the application.
6.3 Scalability
As demand increases, the caching system should scale appropriately. This could involve scaling out (adding more nodes) or scaling up (adding resources to existing nodes).
6.3 Security
When caching sensitive data, security aspects such as encryption, access control, and secure data transmission become critical.
6.4 Ongoing Maintenance
The caching system requires ongoing maintenance and tweaking based on monitoring cache hit rates, performance metrics, and operational health.
6.5 Cost-Effectiveness
The cost of implementing and maintaining the caching system should be weighed against the performance and scalability benefits it provides.
6.6 Integration with Existing Infrastructure
The caching solution requires integration the existing technology stack, thus it should not require extensive changes to current systems.
6.7 Capacity Planning
The caching solution proper planning regarding the size of the cache and hardware resources based on monitoring eviction rates, latency and operational health.
6.8 Cache Size
Cache size plays a critical role in the performance and scalability of applications. A larger cache can store more data, potentially increasing the likelihood of cache hits. However, this relationship plateaus after a certain point; beyond an optimal size, the returns in terms of hit rate improvement diminish. While a larger cache can reduce the number of costly trips to the primary data store but too large cache can increase lookup cost and consume more memory. Finding optimal cache size requires careful analysis of the specific use case, access patterns, and the nature of the data being cached.
6.9 Encryption
For sensitive data, caches may need to implement encryption, which can add overhead and complexity.
6.10 Data Volatility
Highly dynamic data might not benefit as much from caching or may require frequent invalidation, impacting cache hit rates.
6.11 Hardware
The underlying hardware (e.g., SSDs vs. HDDs, network speed) can significantly impact the performance of external caching solutions.
6.12 Bimodal Behavior
The performance of caching can vary significantly between hits and misses, leading to unpredictable performance (bimodal behavior).
6.13 Cache Warming
In order to avoid higher latency for first time due to cache misses, applications may populate the cache with data before it’s needed, which can add additional complexity especially determining what data to preload.
6.14 Positive and Negative Caching
Positive caching involves storing the results of successful query responses. On the other hand, negative caching involves storing the information about the non-existence or failure of a requested data. Negative caching can be useful if a client is misconfigured to access non-existing data, which may result in higher load on the data source. It is critical to set an appropriate TTL (time-to-live) for negative cache entries so that it doesn’t delay the visibility of new data; too short. In addition, negative caching requires timely cache invalidation to handle changes in data availability.
6.15 Asynchronous Cache Population and Background Refresh
Asynchronous cache population involves updating or populating the cache in a non-blocking manner. Instead of the user request waiting for the cache to be populated, the data is fetched and stored in the cache asynchronously. Background refresh periodically refreshing cached data in the background before it becomes stale or expires. This allows system to handle more requests as cache operations do not block user requests but it adds more complexity for managing the timing and conditions under which the cache is populated asynchronously.
6.16 Prefetching and Cache Warming
Prefetching involves loading data into the cache before it is actually requested, based on predicted future requests so that overall system efficiency is improved. Cache warming uses the process of pre-loading to populate the data immediately after the cache is created or cleared.
6.17 Data Format and Serialization
When using an external cache in a system that undergoes frequent updates, data format and serialization play a crucial role in ensuring compatibility, particularly for forward and backward-compatible changes. The choice of serialization format (e.g., JSON, XML, Protocol Buffers) can impact forward and backward compatibility. Incorrect handling of data formats can lead to corruption, especially if an older version of an application cannot recognize new fields or different data structures upon rollbacks. The caching system is recommended to include a version number in the cached data schema, testing for compatibility, clearing or versioning cache on rollbacks, and monitoring for errors.
6.18 Cache Stampede
This occurs when a popular cache item expires, and numerous concurrent requests are made for this data, causing a surge in database or backend load.
6.19 Memory Leaks
Improper management of cache size can lead to memory leaks, where the cache keeps growing and consumes all available memory.
6.20 Cache Poisoning
In cases where the caching mechanism is not well-secured, there’s a risk of cache poisoning, where incorrect or malicious data gets cached. This can lead to serving inappropriate content to users or even security breaches.
6.21 Soft and Hard TTL with Periodic Refresh
If a periodic background refresh meant to update a cache fails to retrieve data from the source, there’s a risk that the cache may become invalidated. However, there are scenarios where serving stale data is still preferable to having no data. In such cases, implementing two distinct TTL (Time To Live) configurations can be beneficial: a ‘soft’ TTL, upon which a refresh is triggered without invalidating the cache, and a ‘hard’ TTL, which is longer and marks the point at which the cache is actually invalidated.
7. Production Outages
Due to complexity of managing caching systems, it can also lead to significant production issues and outages when not implemented or managed correctly. Here are some notable examples of outages or production issues caused by caching:
7.1 Public Outages
- In 2010, Facebook experienced a notable issue where an error in their caching layer caused the site to slow down significantly. This problem was due to cache stampede where a feedback loop created in their caching system, which led to an overload of one of their databases.
- In 2017, GitLab once faced an incident where a cache invalidation problem caused users to see wrong data. The issue occurred due to the caching of incorrect user data, leading to a significant breach of data privacy as users could view others’ private repositories.
- In 2014, Reddit has experienced several instances of downtime related to its caching layer. In one such instance, an issue with the caching system led to an outage where users couldn’t access the site.
- In 2014, Microsoft Azure’s storage service faced a significant outage, which was partly attributed to a caching bug introduced in an update. The bug affected the Azure Storage front-ends and led to widespread service disruptions.
7.2 Work Projects
Following are a few examples of caching related problems that I have experienced at work:
- Caching System Overload Leading to Downtime: In one of the cloud provider system at work, we experienced an outage because the caching infrastructure was not scaled to handle sudden spikes in traffic and the timeouts for connecting to the caching server was set too high. This led to high request latency and cascading failure that affected the entire application.
- Memory Leak in Caching Layer: When working at a retail trading organization that cached quotes used an embedded caching layer, which had a memory leak that led to server crash and was fixed by periodic server bounce because the root cause couldn’t be determined due to a huge monolithic application.
- Security and Encryption: Another system at work, we cached credentials in an external cache, which were stored without any encryption and exposed an attack vector to execute actions on behalf of customers. This was discovered during a different caching related issue and the system removed the use of external cache.
- Cache Poisoning with Delayed Visibility: In one of configuration system that employed caching with very high expiration time, an issue arose when an incorrect configuration was deployed. The error in the new configuration was not immediately noticed because the system continued to serve the previous, correct configuration from the cache due to its long expiration period.
- Rollbacks and Patches: In one of system, a critical update was released to correct erroneous graph data, but users continued to encounter the old graphs because the cached data could not be invalidated.
- BiModal Logic: Implementing an application-based caching strategy introduces the necessity to manage cache misses and cache hydration. This addition creates a bimodal complexity within the system, characterized by varying latency. Moreover, such a strategy can obscure issues like race conditions and data-store failures, making them harder to detect and resolve.
- Thundering Herd and Cache Stampede: In a number of systems, I have observed a variant of thundering herd and cache stampede problems where a server restart cleared all cache that caused cold cache problem, which then turns into thundering herd when clients start making requests.
- Unavailability of Caching servers: In several systems that depend on external caching, there have been instances of performance degradation observed when the caching servers either become unavailable or are unable to accommodate the demand from users.
- Stale Data: In one particular system, an application was using an deprecated client library for an external caching server. This older version of the library erroneously returned expired data, instead of properly expiring it in the cache. To address this issue, timestamps were added to the cached items, allowing the application to effectively identify and handle stale data.
- Load and Performance Testing: During load or performance testing, I’ve noticed that caching was not factored into the process, which obscured important metrics. Therefore, it’s critical to either account for the cache’s impact or disable it during testing, especially when the objective is to accurately measure requests to the underlying data source.
Summary
In summary, caching stands out as an effective method to enhance performance and scalability, yet it demands thoughtful strategy selection and an understanding of its complexities. The approach must navigate challenges such as maintaining data consistency and coherence, managing cache invalidation, handling the complexities of distributed systems, ensuring effective synchronization, and addressing issues related to stale data, warm-up periods, error management, and resource utilization. Tailoring caching strategies to fit the unique requirements and constraints of your application and infrastructure is crucial for its success.
Effective cache management, precise configuration, and rigorous testing are pivotal, particularly in expansive, distributed systems. These practices play a vital role in mitigating risks commonly associated with caching, such as memory leaks, configuration errors, overconsumption of resources, and synchronization hurdles. In short, caching should be considered as a solution only when other approaches are inadequate, and it should not be hastily implemented as a fix at the first sign of performance issues without a thorough understanding of the underlying cause. It’s crucial to meticulously evaluate the potential challenges mentioned previously before integrating a caching layer, to genuinely enhance the system’s efficiency, scalability, and reliability.