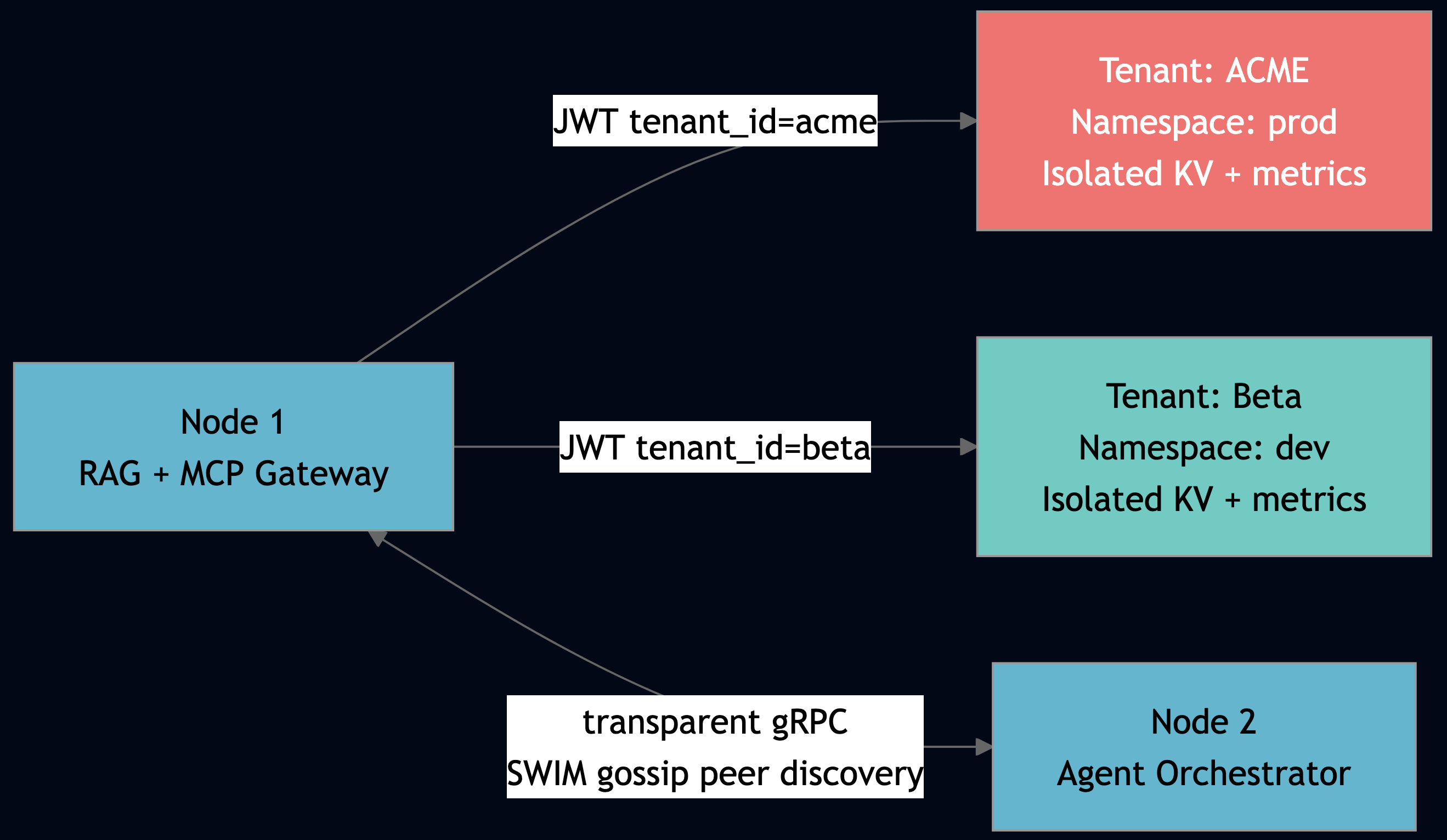
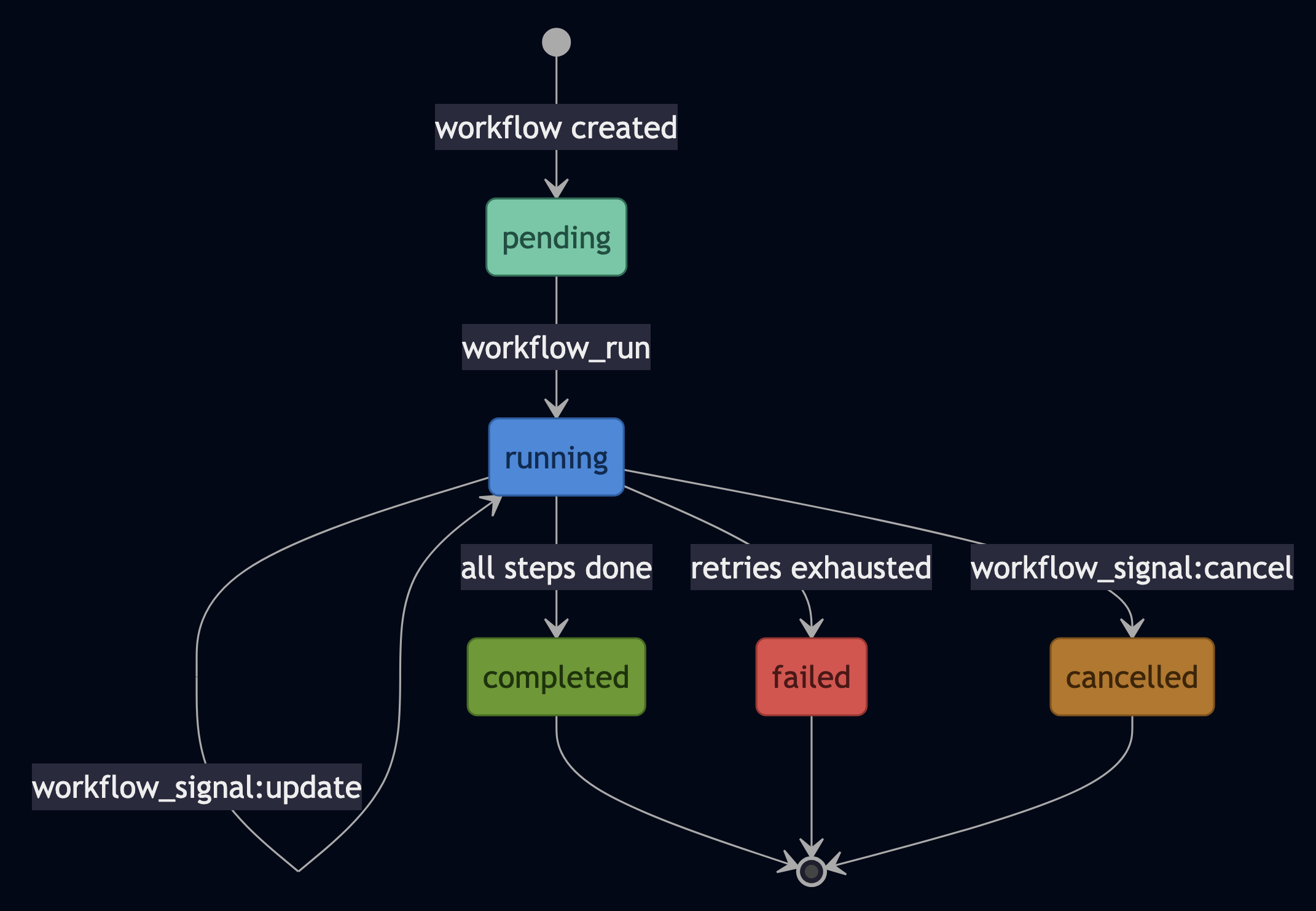
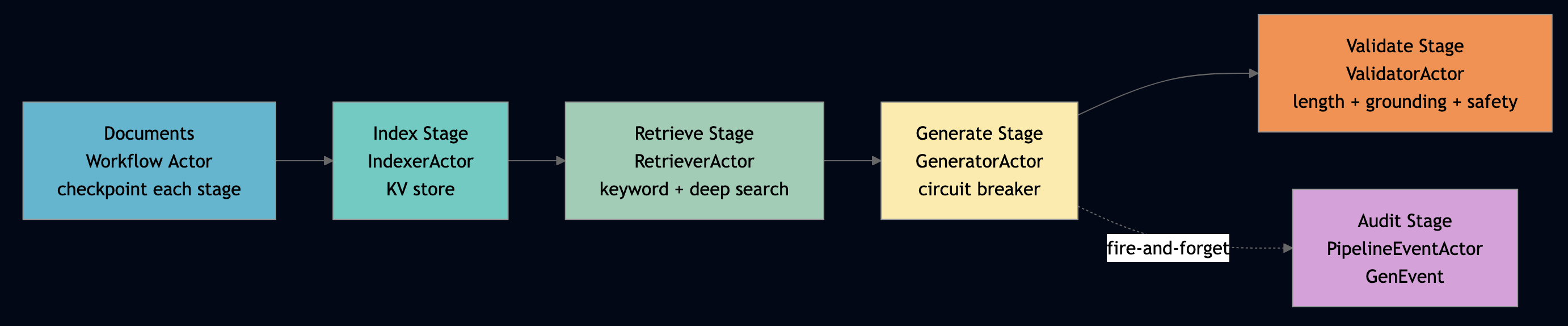
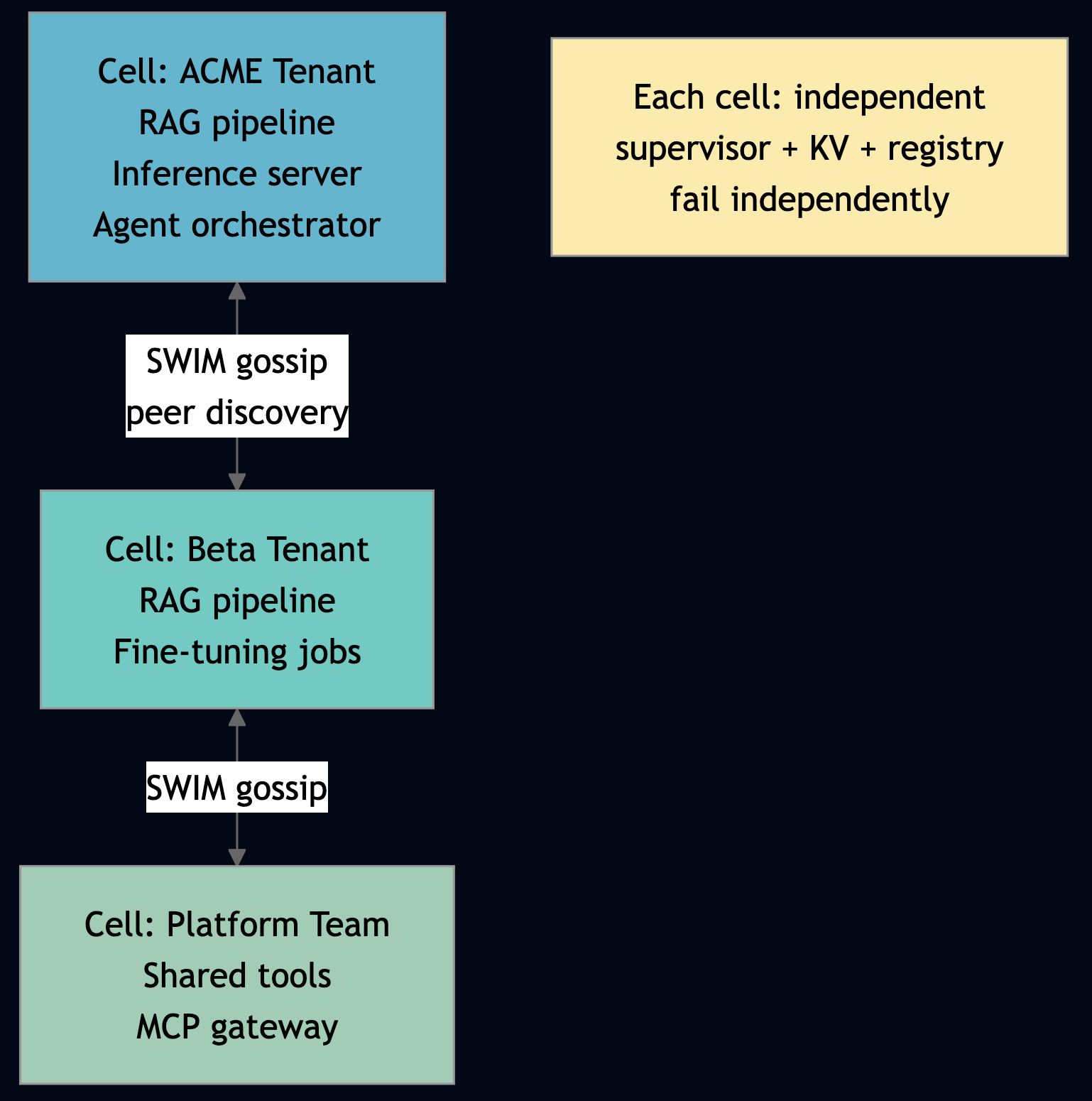
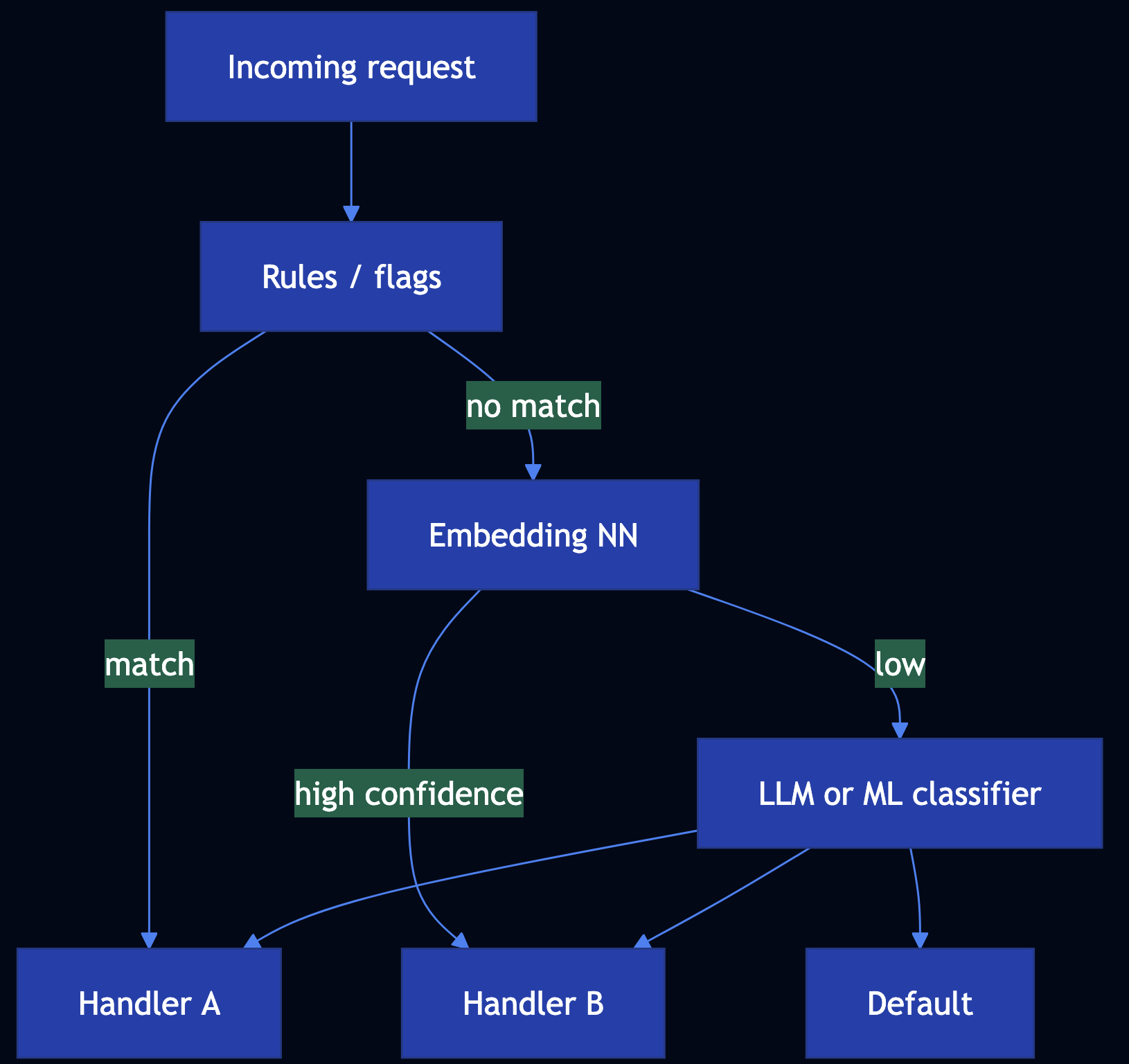
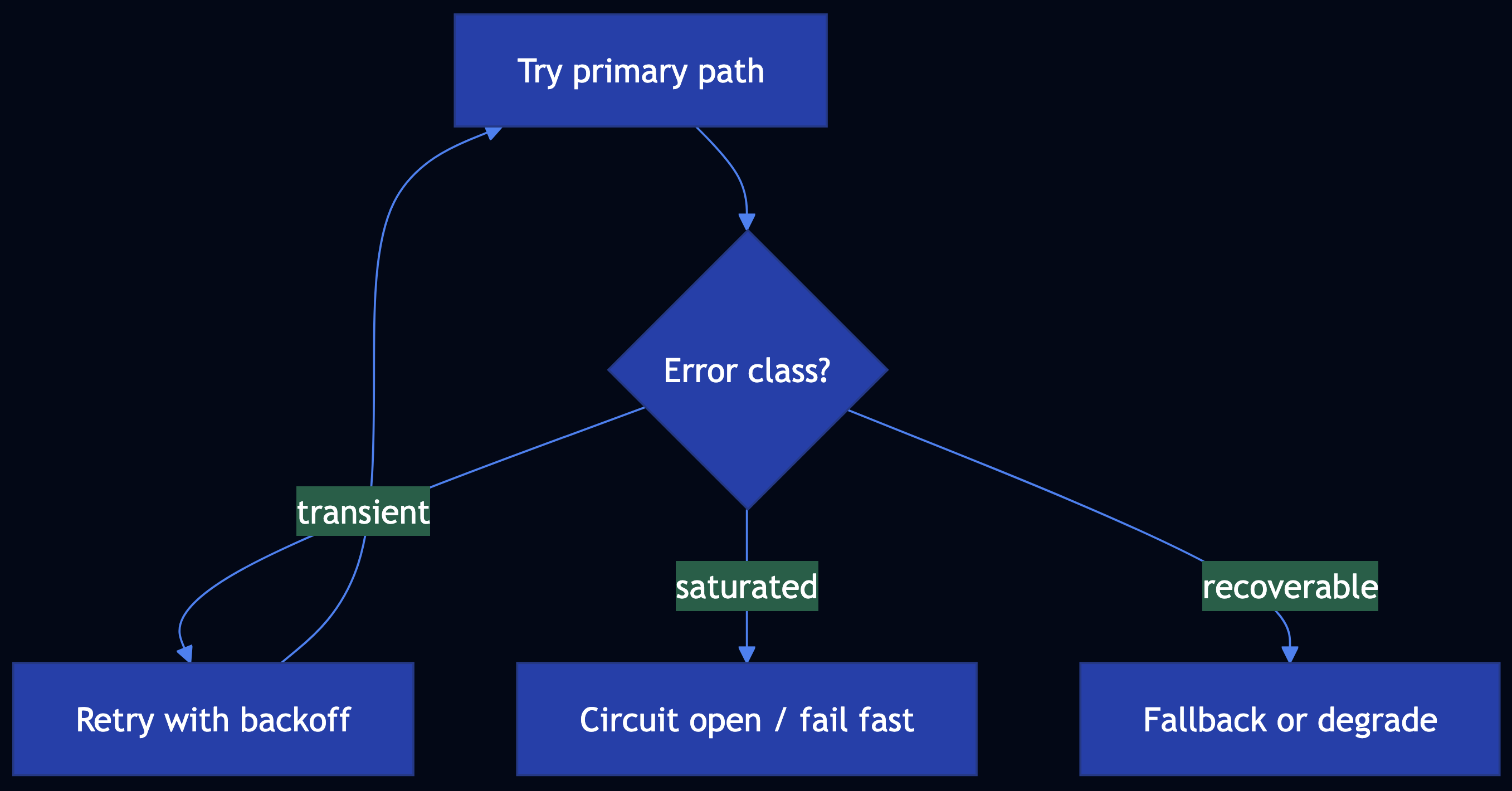
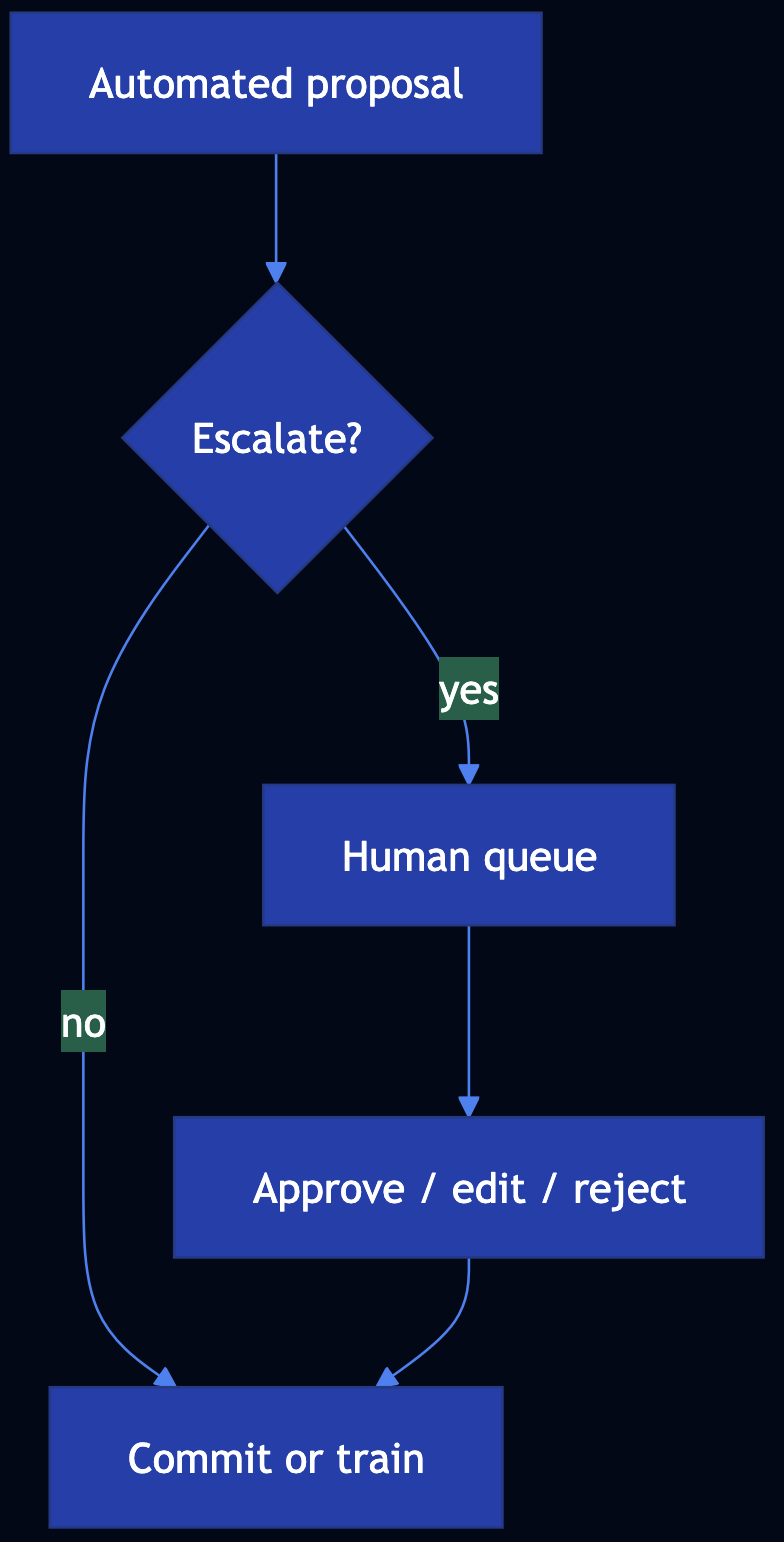
The Eternal Quest to Make Coding Simpler
I wrote my first program in BASIC on an Atari in the 1980s with line numbers, GOTOs, no debugger. Turbo Pascal changed everything: integrated editing, instant compilation, step-through debugging. Then Borland C++, then Visual Basic, then Eclipse, then IntelliJ. This pattern where new tool arrives, productivity jumps, complexity catches up has repeated itself every few years across my entire three-decade career.
In the early 1990s, 4GL tools promised to eliminate coding entirely. dBase, FoxPro, PowerBuilder — the pitch was always the same: “Business users can build their own applications.” Simple CRUD apps were easy. Real systems with business logic, error handling, and concurrent users turned out harder than writing code from scratch. UML consumed the next decade. I spent years with Rational Rose doing forward and backward engineering from class diagrams. The generated code was rigid scaffolding that fought you. Diagrams drifted from reality within weeks, because maintaining two representations of the same truth is inherently unsustainable.
The lesson I keep relearning: every attempt to separate “what to build” from “how to build it” through tooling alone produces rigid, brittle systems. The gap between specification and implementation is a thinking problem. Tools that hide it make things worse.
The AI Inflection Point
Around 2020, I started using GitHub Copilot for autocomplete. ChatGPT and Claude helped with isolated problems — boilerplate, algorithm refreshers. Useful but incremental. Then Claude Code arrived in early 2025, and everything changed. I’ve used it for 100% of my coding for over a year, not as autocomplete but as a full development partner: architecture, implementation, testing, debugging, deployment. The productivity gains are real. The failure modes are real too. Amazon AWS teams learned this the hard way, AI-generated code that looked right, passed superficial review, then caused production incidents. Their response was to tighten review policies significantly. I’ve seen the same pattern repeatedly: AI ships code that introduces subtle bugs in unfamiliar codebases, silently violates domain invariants, or creates architectural inconsistencies that compound over weeks. The problem isn’t that AI writes bad code. It writes locally correct code that doesn’t fit the bigger picture.
The Memento Problem
People compare AI coding agents to interns. That analogy breaks in one critical way: AI agents suffer from anterograde memory loss. Like the protagonist in Memento, every session starts from zero. An intern who made a mistake yesterday remembers it today. They build mental models of your codebase, internalize conventions through repetition. An AI agent? Session ends, memory gone. Tomorrow it will make the exact same architectural mistake, violate the same naming convention, choose the same wrong abstraction. It doesn’t learn from correction, it only learns from context provided in each session.
This is why rules, conventions, and structured knowledge aren’t optional nice-to-haves for AI-assisted development. They’re the equivalent of Leonard’s tattoos and photographs, which is the external memory system that makes coherent action possible despite the inability to form new long-term memories. I built these skills because I got tired of repeating the same corrections. Every session I found myself saying “no, we use Result types here, not exceptions” or “no, that should be a sum type” or “no, you need an idempotency token on that create endpoint.” The skills encode these corrections permanently so I stop repeating myself.
The Outsourcing Parallel
Every offshore engagement I’ve run hit the same wall: limited overlap hours, different definitions of ‘done,’ and a gap between what I envisioned and what arrived. Formal process wasn’t optional, it was the only thing that worked. What I learned: formal process wasn’t optional with outsourced teams. The teams that succeeded had detailed specs, explicit acceptance criteria, structured handoffs, and review gates. The teams that failed relied on “they’ll figure it out” and got back code that met the requirements on surface. This spawned CMM, RUP, Six Sigma — frameworks so heavy the documentation cost exceeded its value. Agile won because lightweight feedback loops beat upfront specification when communication bandwidth is high. Agile methodologies won because they recognized that lightweight, iterative feedback loops beat heavyweight upfront specification for teams with high-bandwidth communication.
AI agents resemble outsourced teams more than co-located colleagues. They have a narrow context window — like limited overlap hours across time zones. They lack shared understanding of your codebase. They produce locally correct work that misses the bigger picture. The lesson from outsourcing holds: formal process works when communication bandwidth is constrained. These skills apply that lesson with minimum ceremony — just enough structure to preserve conceptual integrity across sessions, without recreating the documentation burden that killed RUP.
Production agent systems need tiered memory: short-term (current session), medium-term (project conventions), and long-term (organizational knowledge). These skills are the middle tier, project-level knowledge that persists across sessions without requiring permanent documentation. They’re the bridge between ephemeral conversation and hard-coded policy.
Conceptual Integrity in the Age of AI
Fred Brooks wrote this in The Mythical Man-Month (1975). Martin Fowler recently reminded us it’s never been more relevant:
“I will contend that conceptual integrity is the most important consideration in system design. It is better to have a system omit certain anomalous features and improvements, but to reflect one set of design ideas, than to have one that contains many good but independent and uncoordinated ideas.”
This principle has never been more relevant. When an AI agent generates code, it produces locally correct solutions like the function works, the test passes, the API responds. But without conceptual integrity, each generated piece reflects a different design philosophy. One module uses exceptions, another uses Result types. One endpoint follows REST conventions, another doesn’t. One service uses the outbox pattern for events, another dual-writes to the database and message queue. Over time, the codebase becomes exactly what Brooks feared: “many good but independent and uncoordinated ideas.”
Code serves two purposes: machine instructions and conceptual modeling. AI commoditizes the first. The second, the model that captures how your domain actually works, remains yours to own. Generate code 10x faster without protecting that model, and you get systems 2x harder to maintain. Spec-driven development frameworks like OpenSpec and Spec-Kit push toward treating prompts as first-class delivery artifacts, versioned, reviewed, maintained alongside code. That’s the gap these skills fill. They encode conceptual integrity, design philosophy, conventions, quality standards into reusable artifacts that survive across sessions.
What You Own vs. What AI Owns
“We adopted AI coding but it hasn’t increased revenue.” Of course not. AI doesn’t solve what to build, it accelerates how to build it. You still need product/market fit, customer feedback, and domain expertise. More importantly: when AI causes a security incident or production outage, you can’t fire it. You’re accountable. Here’s the ownership boundary I enforce:
| You Own | AI Accelerates |
|---|---|
| What to build (product vision) | How to build it (implementation) |
| Why it matters (business context) | Boilerplate and mechanical translation |
| Quality standards and conventions | Applying those standards consistently |
| Architecture decisions | Exploring design alternatives quickly |
| Security posture | Checking against known vulnerability patterns |
| Production accountability | Monitoring, alerting, runbook generation |
| Domain knowledge | Translating that knowledge into code |
The skills encode this boundary explicitly: you drive the what and why; AI executes the how within guardrails you define. Every skill in the set reinforces this split.
Why Formalized SDLC Works Better with AI
I’ve worked in both worlds: big-company SDLC with architecture reviews, security reviews, production readiness checklists and startups where you discuss an idea over coffee and ship by afternoon. AI works better with the formalized approach. The reason is the same one that sank outsourcing arrangements with vague requirements: if you can’t state precisely what you want, the other party fills gaps with assumptions. Here’s why structure helps specifically with AI:
- Structure gives AI context. A well-written PRD tells the agent why it’s building something, what constraints matter, which edge cases to handle. Without this, AI fills gaps with assumptions from training data, which may not match your domain.
- Checkpoints catch drift early. When AI generates 800 lines in one session, reviewing it as a monolithic diff is overwhelming. I learned this the hard way. Now I break work into smaller tasks and enforce checkpoints every 5 files where build and test must pass before proceeding. Small, verified increments compound into reliable systems.
- Conventions reduce error surface. When you explicitly state “use Result types for errors, never exceptions” and “all IDs are ULIDs, never UUIDs” then AI follows them. Without explicit conventions, it defaults to whatever was most common in training data, which varies wildly by context.
- Smaller increments compound. AI excels at small, well-defined tasks with clear acceptance criteria. This isn’t new wisdom as vertical slicing and thin end-to-end increments have been SDLC best practice for decades. What’s good for human developers turns out to be good for AI too
- Sloppy codebases amplify AI mistakes. In clean, well-structured code with clear module boundaries, AI makes fewer errors. It can hold the relevant context. In sprawling, inconsistent codebases with 2000-line files and mixed conventions, AI hallucinates patterns, mixes styles, and creates subtle inconsistencies. Well-structured code isn’t just readable for humans, it’s how AI holds context without drifting.
The Skills: A Structured SDLC for AI-Assisted Development
Here’s the full lifecycle, with each phase mapped to a skill and the key lessons that shaped it:

Phase 1: Requirements Refinement (/ygs-refine-prd)
I’ve watched AI build the wrong thing fast more times than I can count. The root cause is always the same: vague requirements. When I tell an agent “build a notification system,” it picks a design based on training data patterns. When I tell it “build a notification system that MUST deliver within 500ms for P0 alerts, SHOULD batch P2 notifications into hourly digests, and MAY support user-defined routing rules” then it builds something specific and testable. The refine-prd skill forces this precision through structured questioning. It interviews me relentlessly: one question at a time, providing its recommended answer, waiting for my feedback before continuing. It challenges vague language: “fast means what: 100ms? 1 second? Faster than the current system?” It pushes me to define concrete scenarios with Given/When/Then acceptance criteria borrowed from OpenSpec.
Key lessons encoded:
- RFC 2119 keywords force commitment. Labeling requirements as MUST (P0), SHOULD (P1), or MAY (P2) prevents the “everything is critical” trap. I’ve seen projects fail because nobody ranked requirements, so the team optimized for P2 features while P0 requirements remained unmet.
- Capabilities mapping reveals brownfield complexity. Categorizing changes as New/Modified/Removed surfaces the reality that most “new features” actually modify existing behavior, which is always harder than greenfield and needs different estimation.
- Non-goals prevent scope creep. Explicitly stating what you will NOT build is as important as defining what you will. Without non-goals, AI treats every tangent as in-scope.
This is where you own the what. The AI sharpens your thinking, but the product decisions stay yours.
Phase 2: Technical Design (/ygs-refine-trd)
Without a technical design document, AI makes architectural decisions implicitly and they’re often wrong. I watched an agent choose microservices for a problem that needed a single process with good module boundaries. Another time it introduced an event bus between components that were always co-located and synchronous. Both were “correct” patterns applied to wrong contexts. The refine-trd skill challenges my technical approach through structured questioning, then produces a design document with explicit trade-off analysis and requirements traceability with every design decision maps back to a PRD requirement with rationale. For larger efforts spanning multiple components, I use a comprehensive design doc template that I previously shared in my blog. It covers the full lifecycle: from problem statement through architecture, alternatives analysis, non-functional requirements, rollout plan, and inline ADRs recording every key decision with its rationale and reversibility. The most powerful design tool isn’t testing, it’s the type system. When I rebuilt a Rust observability pipeline around algebraic data types and explicit state machines, entire bug categories disappeared:
Making Invalid States Impossible
The most powerful design tool isn’t testing, it’s the type system. Restructuring a pipeline around algebraic data types and explicit state machines made entire bug categories impossible to write:
- Sum types enumerate valid states explicitly. I can’t accidentally process a
Pendingmessage as if it wereConfirmedbecause the compiler won’t let me. - Typestate pattern encodes valid transitions in the type system. A
Draftdocument can move toRevieworDeleted, but never directly toPublished. Invalid sequences are compile errors, not runtime bugs. - Parse, don’t validate transforms unstructured input at boundaries into strongly-typed domain objects. Once parsed, code trusts the types internally without defensive null checks scattered through business logic.
- Errors as values using
Result<T, E>types cannot be silently ignored. Compare this to exceptions that propagate invisibly through 14 stack frames before someone catches them with an empty catch block. - Functional core, imperative shell separates pure domain logic from I/O orchestration. The domain code is trivially testable because it has no side effects. The shell is thin and mechanical.
These principles matter enormously for AI-generated code because the compiler becomes your reviewer. When AI generates code within a well-typed system, category errors that would slip through human review become impossible to express.
Deep Modules Over Shallow
AI defaults to shallow modules, lots of small classes, each delegating to the next without adding value. A Philosophy of Software Design encourages modules with small interfaces and rich implementations. I’ve reviewed too many codebases where every class has an interface, every interface has one implementation, and understanding a feature requires bouncing through 15 files, each delegating to the next without adding value. The deletion test cuts through this: imagine deleting the module. If complexity vanishes, it was a pass-through and adding nothing but indirection. If complexity reappears across N callers, it was earning its keep. I apply this ruthlessly now. One adapter means a hypothetical seam. Two adapters means a real one. Don’t build seams speculatively.
Cognitive Load as Design Constraint
Three constraints keep AI-generated functions reviewable:
- Methods stay under 24 lines. Working memory holds 4-7 chunks, code exceeding this becomes unmanageable regardless of how “clean” it looks.
- No more than 7 concepts in a section. If I need a comment to explain what a block does, it should be a function with that name instead.
- Fractal decomposition. Each level hides details while allowing drill-down. The system is comprehensible at every zoom level.
AI agents benefit from these constraints more than humans do. A function under 24 lines fits entirely in the context window. A deep module with a small interface can be understood without reading its implementation. Clean structure gives AI less opportunity to hallucinate.
Phase 3: Architecture (/ygs-refine-architecture)
For changes spanning multiple components, I use architecture refinement to capture system-level decisions that no single PR review can validate. The skill interviews me about module boundaries, seam placement, data flow, and failure modes and challenging shallow designs and pushing for depth. Three hard lessons shape every distributed system I design:
- Transaction Boundaries Drive Architecture: I learned this lesson the expensive way: atomicity requirements dictate service boundaries, not the other way around. Teams that draw service boundaries first and then try to maintain consistency across them end up with distributed transactions, eventual consistency bugs, and data loss scenarios that take months to resolve.
- The dual-write problem is the #1 source of data inconsistency I’ve encountered in microservice architectures. Writing to a database and publishing an event in separate operations means either can succeed while the other fails — leaving your system in an inconsistent state. The outbox pattern solves this: write the event to an outbox table in the same database transaction, then relay it asynchronously. Simple, reliable, non-negotiable for any system I design now.
- For operations spanning multiple services, SAGA with explicit compensation replaces distributed transactions. Each step has a defined undo operation. When step 4 of 6 fails, steps 3, 2, and 1 execute their compensating actions. The key insight: design compensation logic before the happy path, because it’s always harder than you think.
Domain-driven design adds three more constraints that AI consistently gets wrong without explicit guidance:
- Bounded contexts draw ownership lines. Each microservice owns one context where one set of domain concepts with one consistent vocabulary. Cross-context communication happens through well-defined events, not shared databases.
- Ubiquitous language prevents the translation bugs I’ve seen kill projects. When the code says
Orderbut the domain expert meansReservation, every conversation introduces subtle misunderstandings that compound into wrong implementations. - Hexagonal architecture (ports and adapters) means dependencies point inward. Domain logic knows nothing about HTTP, databases, or message queues. This isn’t academic purity, it’s what makes the system testable without spinning up infrastructure.
Fault Tolerance Is Architecture, Not Code
Fault tolerance is an architecture decision, not an implementation detail. Bolt it on after the fact and you get a system that fails catastrophically under load:
- Circuit breakers prevent cascade failures. When a downstream service is unhealthy, stop sending it requests. I’ve seen a single slow database query bring down six upstream services because nobody implemented this.
- Retry with jitter uses exponential backoff plus randomization. Without jitter, all clients retry at the same moment after an outage resolves, creating a thundering herd that triggers another outage.
- Bulkhead isolation gives each dependency its own thread/connection pool. A slow payment provider shouldn’t exhaust your entire connection pool and take down order processing.
- Graceful degradation means deciding in advance what to show users when a dependency fails. Not an error page, a degraded experience.
- No hard startup dependencies. Services start even when dependencies are unavailable. They serve degraded responses and recover automatically when dependencies come back.

Phase 4: Estimation (/ygs-estimate)
Management wants dates. Engineers want to build. This tension has existed since the first software project went over schedule. I wrote about estimation practices years ago, and the core lessons haven’t changed: estimates are not commitments, decomposition reduces error, and teams consistently underestimate because they scope only the coding work. The estimate skill bridges the gap between “we need a date” and “it’ll be done when it’s done” with structured complexity-based estimation:
- T-shirt sizing at the feature level. Before diving into details, I size each major capability as XS through XL based on complexity, uncertainty, and integration surface. An XL (4-8 weeks, architectural change) signals that the feature itself needs decomposition before meaningful estimation is possible. Uncertainty multipliers compound: new technology × external dependency = 2x your initial guess.
- Story points at the task level. Using Fibonacci sequence (1, 2, 3, 5, 8, 13, 21) with planning poker when multiple people are involved. The power of Fibonacci isn’t magical, it’s that the gaps between numbers grow, forcing you to acknowledge increasing uncertainty rather than pretending you can distinguish between “7 days” and “8 days” of work.
- Three-point estimation for commitments:
Expected = (Best + 4×MostLikely + Worst) / 6
Present ranges, not single numbers. “3-4 weeks with a tail risk of 6 weeks if the external API integration is harder than expected” gives management real information to plan around.
Key lesson: capacity is never 100%. I’ve seen teams plan sprints assuming full developer availability and then wonder why they deliver 60%. The reality:
| Category | Typical Budget |
|---|---|
| Feature work | 50-60% |
| KTLO (maintenance, tech debt, bug fixes) | 20-30% |
| On-call / incidents | 5-15% |
| Vacation / holidays / sick | 10-15% |
| Meetings / reviews / planning | 5-10% |
Some teams I’ve worked with budget 40% for KTLO. If your system is old and fragile, that’s not pessimism, that’s realism. The skill asks the user what their team’s actual allocation is, because it varies enormously.
The most common estimation failure: forgetting everything that isn’t “writing code.” Engineers estimate the implementation and forget testing (20-40% of the work), deployment changes (IaC, Kubernetes manifests, feature flags), observability (metrics, dashboards, alerts, tracing), on-call runbooks and troubleshooting guides, data migration scripts, security review fixes, and documentation. My rule of thumb: if the estimate only covers writing code, double it to account for everything needed to ship to production safely.
Phase 5: Spike (/ygs-spike) — When You Don’t Know Enough
Not every feature goes straight from design to implementation. Some involve risky unknowns like a new database, an unfamiliar integration, an algorithm you’ve never tried at scale. The spike skill exists for these moments: a time-boxed experiment to answer a specific question before committing to a full design. The spike lives on a spike/ or fafo/ branch, deliberately relaxes production standards, and produces exactly one artifact: a findings doc with a clear verdict. What spikes are for:
- Performance validation: “Can our schema handle 10K writes/sec?” Write the hot path, add a benchmark harness, measure.
- Integration feasibility: “Does this library work with our auth stack?” Wire two systems together, make one end-to-end call work. Done.
- Algorithm proof: “Is this fast enough for real-time?” Implement the core loop, feed it representative data, measure latency at p99.
The spike skill enforces this discipline: define hypothesis up front, scope what’s allowed, build the minimum experiment, record findings with evidence, and recommend next steps. If the spike confirms feasibility, you proceed to full design with confidence. If it refutes your hypothesis, you’ve saved weeks of wasted implementation.
Phase 6: Work Breakdown Structure (/ygs-wbs)
AI excels at small, well-defined tasks. It struggles with large, ambiguous ones. The WBS skill hierarchically decomposes deliverables into vertical slices, thin end-to-end cuts through all layers, each independently demoable and verifiable. Like a traditional Work Breakdown Structure, it divides complex projects into manageable components at three levels: deliverables (major features), work packages (independently shippable units), and tasks (atomic implementation steps).
Key lessons from years of estimation and delivery:
- Vertical over horizontal. Each task cuts through UI, API, and database, not “build all the models, then all the APIs, then all the UI.” Horizontal slicing delays feedback. You don’t know if the feature works until the last layer is complete. Vertical slicing gives you a working thin slice from day one.
- Dependency ordering prevents blocked work. Data model tasks before API tasks before UI tasks. Shared utilities before their consumers. I sequence tasks so each one builds on verified, tested foundations.
- Scope signals trigger splits. When I see “and also…” or “and verify…” in a task description, that’s two tasks disguised as one. Exception: causally dependent steps (create migration + update model + update handlers for same entity) stay together.
- Size drives ceremony. Small tasks (1-3 files, <300 lines) get standard workflow. Large tasks (8+ files, 800+ lines) get flagged immediately for splitting. I’ve learned that tasks AI implements in one session should stay under 300 lines of change, beyond that, coherence degrades.
Phase 7: Implementation (/ygs-implement)
Without guardrails, AI will modify 30 files in one session, introduce subtle coupling between components that should be independent, and produce a diff too large to review meaningfully. I’ve had sessions where the agent touched 12 files to implement a feature that should have required 4, each extra file an “improvement” that wasn’t asked for. The implement skill enforces discipline:

Scope guardrails I enforce:
- 3+ unplanned files -> STOP. The agent reports the deviation and asks me to confirm expanded scope. This single rule has prevented more architectural drift than any other practice.
- Checkpoint every 5 files. Build and tests must pass before proceeding. Catches regressions early when they’re cheap to fix.
- Deviation tracking. When implementation differs from design: “Design said X, did Y because Z.” This documentation prevents the next session from reverting the deviation or making it worse.
Three testing rules I enforce regardless of who wrote the code:
- Stubs only at 3rd-party/OS boundaries: HTTP clients, system clocks, filesystem, randomness. Everything else uses real implementations.
- If you can’t test without mocking internal code, the design is wrong. This is a litmus test I apply relentlessly. Mocking internals means your modules are coupled. Fix the coupling, don’t paper over it with mocks.
- Test the public contract, not implementation details. Tests that verify internal method calls break every refactor. Tests that verify external behavior survive decades.
Four tidying rules that prevent AI from refactoring itself into bugs:
- Tidy first but only when it makes the next change cheaper. I’ve watched AI eagerly refactor things that don’t need refactoring, burning context and introducing bugs. The rule: cost(tidy) + cost(change after tidy) < cost(change without tidy). Otherwise, leave it.
- Guard clauses over nested conditionals. Early returns flatten code and make the happy path obvious.
- One pile first. Before splitting scattered code into elegant modules, consolidate it in one place. Understand the full picture before decomposing. AI tends to decompose prematurely, creating abstractions before understanding what varies.
- Tidy in separate commits from behavior changes. Never mix formatting with functionality. It makes review impossible and rollback dangerous.
Phase 8: Code Review (/ygs-code-review)
AI-generated code passes syntax checks and basic tests but can contain subtle logic errors, security holes, and design violations that only emerge under careful structured review. I don’t trust casual “looks good” scanning instead I use a two-pass approach with explicit criteria.
Pass 1 Critical issues (blocks merge):
- Logic errors. Off-by-one bugs, null handling, race conditions (TOCTOU, check-then-act, find-or-create without locks).
- Security holes. Injection (SQL, XSS, SSRF, path traversal), hardcoded secrets, missing auth checks.
- Data loss. Destructive operations without confirmation, missing transactions around multi-step mutations.
- Error swallowing. Empty catch blocks, ignored return values, Result types discarded with
.unwrap()or_ =. - Partial failure. What if the operation half-succeeds? I’ve seen update endpoints that modify 3 records in sequence, e.g., if #2 fails, #1 is already committed and the system is in an inconsistent state.
- Enum completeness. New enum values must be traced through ALL consumers. One unhandled match arm in a downstream service can cause silent data loss.
Pass 2 Design and maintainability:
- Immutability and state. Is mutable state minimized? Are invalid states representable? Should this use an explicit state machine instead of boolean flags?
- Type safety. Sum types for variants? Newtypes for semantically different IDs (UserId vs OrderId)? Parse-don’t-validate at boundaries?
- Command-Query Separation. Methods either change state OR return data, never both. Violations make code unpredictable and untestable.
- Interface design. Deep modules with small interfaces? Or shallow pass-throughs adding indirection without value?
- Performance. N+1 queries hiding inside loops, missing database indexes for common query patterns, O(n^2) operations on collections that grow.
- Proportionality. Is the complexity justified by data? I’ve reviewed PRs that introduced three new abstractions for a feature used by 12 people. Proportionality means the solution matches the problem’s actual scale.
Severity classification:
- MUST — Blocks merge (correctness, security, data loss)
- SHOULD — Strong recommendation (design, performance, testability)
- MAY — Suggestion (naming, style, minor optimization)
You don’t get the same understanding from reviewing as from writing, that tension is real. But structured multi-pass review with explicit criteria gets you closer than rubber-stamping ever could.
Phase 9: Security Review (/ygs-security-review)
AI doesn’t think adversarially. It generates happy-path code that works when used as intended. Attackers don’t use things as intended. I’ve seen AI-generated endpoints that validated input on the frontend but accepted anything on the backend, that logged full request bodies including passwords, that built SQL queries with string interpolation “because the ORM was too slow.” The security review skill forces red-team thinking for every changed endpoint.
Lessons from my previous post on building secure microservices:
- Injection vectors. I check for SQL injection (raw queries with interpolation), command injection (exec/system with user input), template injection (SSTI), XSS (unescaped user content in responses), SSRF (user-controlled URLs in server requests), and path traversal (user input in file paths).
- Authentication & authorization. Missing auth checks on new endpoints (AI doesn’t always copy the middleware pattern). Broken access control where user A can access user B’s resources by changing an ID in the URL. Privilege escalation through parameter manipulation.
- Data exposure. Sensitive data in logs (I’ve caught AI logging full request bodies including auth tokens). Secrets in error messages returned to clients. Debug information in production responses.
- Supply chain. Vulnerable or unpinned dependencies. Deserialization of untrusted data (pickle, YAML.load, eval). AI loves pulling in libraries without checking their security posture.
Red-team perspective: I ask these questions for every endpoint:
- What happens if someone sends 10,000 requests per second? (Rate limiting)
- What if they bypass the frontend entirely and craft raw API calls? (Server-side validation)
- What’s the blast radius if this component is fully compromised? (Lateral movement, data access)
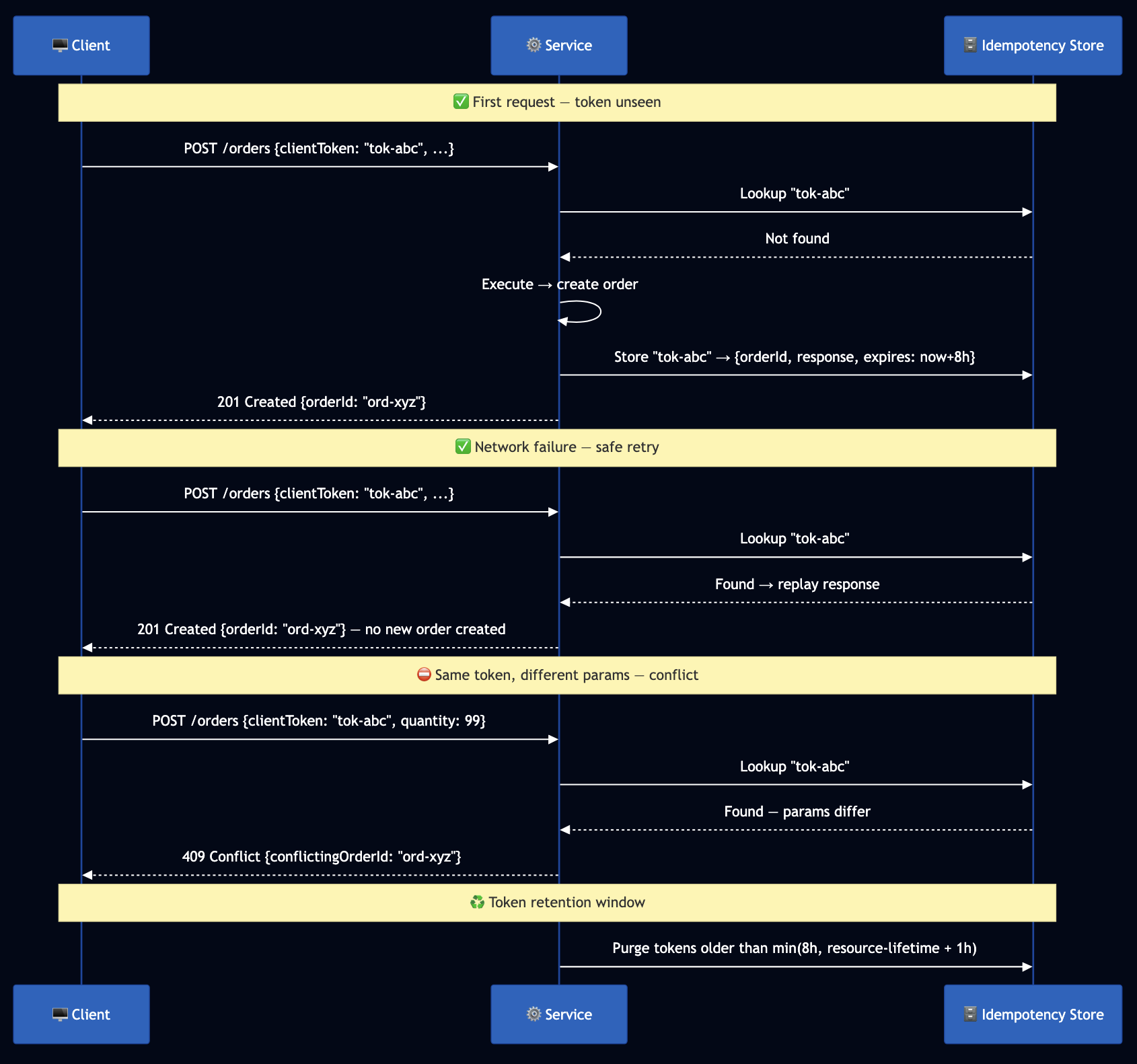
- What happens on double-submit within 100ms? (Idempotency)
- Is there defense in depth, or does one failed check expose everything? (Layered security)
The CIA triad applied to every data flow:
- Confidentiality: Encryption at rest and in transit, access controls at every hop, zero-trust between services
- Integrity: Cryptographic verification of artifacts, input validation at trust boundaries, tamper detection
- Availability: Redundancy, failover, rate limiting to prevent DoS, graceful degradation under attack
For systems with significant attack surface, I produce a formal STRIDE threat model, systematically enumerating threats per subsystem, classifying assets by sensitivity, identifying trust boundaries, and tracking mitigations to completion. The structured template ensures nothing falls through the cracks: every threat gets an owner, a mitigation plan, and a security test that verifies the fix.
Phase 10: SRE Review (/ygs-sre-review)
Code that works in development fails in production. AI has no intuition for this because it’s never been paged at 3am. It doesn’t know that a missing index causes 30-second queries under load, or that an unbounded list endpoint will OOM the service when it hits 10 million records. The SRE review skill forces failure-mode analysis from my production readiness experience:
For every changed component, I analyze:
- What happens when it fails? Crash, hang, corrupt data, or silent degradation? Each demands a different mitigation.
- Blast radius. Does failure cascade? A single unhealthy pod shouldn’t take down the cluster. Circuit breakers and bulkheads contain damage.
- Recovery path. Auto-recovers (best), requires restart (acceptable), requires manual intervention (document it), requires data repair (unacceptable without backups).
- Partial failure. What if step 3 of 5 succeeds but step 4 fails? Is the system in a consistent state? Are there compensating actions?
Observability because you can’t fix what you can’t see:
- Metrics: Latency percentiles (p50, p95, p99), error rates, throughput, saturation (CPU, memory, connections, disk).
- Logging: Structured with correlation IDs. Proper levels. No PII. Enough context to diagnose without reproducing.
- Tracing: Distributed tracing end-to-end. When a request touches 6 services, I need to see the full path without grepping logs across clusters.
- Alerting: Threshold-based AND anomaly detection. Every alert links to a runbook. If an alert fires and the responder doesn’t know what to do, the alert is useless.
Deployment safety:
- Canary releases: Deploy to 1% of traffic, monitor for 15 minutes, auto-rollback on metric breach. This catches issues that tests miss.
- Backward-compatible schema changes: Two-phase releases (add column -> deploy code that writes both -> migrate data -> remove old column -> deploy code that reads new). Never lock a production table.
- Feature flags: For anything risky, ship dark and enable gradually. This decouples deployment from release.
- Immutable infrastructure: No in-place patches. Every deployment is a fresh container from a verified image.
Testing pyramid from Google SRE practices:
| Layer | Proportion | What It Catches |
|---|---|---|
| Unit tests | 80% | Logic errors, edge cases, regressions — fast, isolated, deterministic |
| Integration tests | 15% | Component interactions, contract violations, real DB behavior |
| End-to-end tests | 5% | Critical user journeys, cross-service flows — expensive, flaky, essential |
| Chaos testing | Periodic | Failure recovery, cascade prevention, degradation behavior |
| Property-based | Where applicable | Invariant violations across random inputs, edge cases you didn’t imagine |
In my post about caching, I shared caching related production failures I’ve encountered repeatedly:
- Thundering herd after cache expiry. All clients hit the backend simultaneously. Stagger TTLs and use cache stampede prevention.
- Stale data during update failures. Serving old data is sometimes acceptable, sometimes catastrophic, know which case you’re in.
- Cache unavailability causing cascading failures. Test performance without cache during peak load. If your system can’t function without cache, cache is a hard dependency, not an optimization.
- Security: cache keys MUST respect authorization boundaries. I’ve seen cached responses served to unauthorized users because the cache key didn’t include tenant ID.
- Bimodal behavior: when the system behaves fundamentally differently with vs. without cache, you have two systems to understand and debug. Minimize this.
Phase 11: QA and UAT (/ygs-qa, /ygs-uat)
I separate QA from UAT because they catch different failure modes. Code can be functionally correct and still unusable. An API can return the right data and still violate the user’s mental model of how the workflow should behave.
QA (/ygs-qa) tests the system objectively:
- Functional correctness: Does core logic produce right results for valid inputs?
- Edge cases: Boundary values, empty inputs, maximum limits, null handling, Unicode, special characters
- Error paths: Invalid input, network failures, timeouts, partial failures — does the system degrade gracefully or crash?
- Regressions: Do existing features still work after the change? This is where AI causes the most subtle damage: fixing one thing while breaking something adjacent.
- Performance: Response times acceptable? No degradation under load? No memory leaks in long-running processes?
I score each category 0-10 and produce an overall health rating (0-50). This gives me a quantitative signal for ship readiness rather than a vague “looks good.”
UAT (/ygs-uat) tests from the customer’s perspective:
- Walk through actual user stories end-to-end. Not individual API calls, complete workflows as a user would experience them.
- Error messages must be helpful, not technical. “Connection refused to localhost:5432” is a developer error message. “We’re having trouble loading your data, please try again” is a user error message.
- Check the golden path AND the “what if the user does something weird” paths. What if they double-click? What if they navigate back mid-flow? What if they have 10,000 items instead of 10?
Both must pass before shipping. I’ve shipped code that was technically correct but confused every user who touched it.
Phase 12: Ship and Learn (/ygs-ship, /ygs-retro)
Sync (/ygs-sync) addresses a problem I’ve seen kill design docs across every team I’ve worked with: docs drift from reality within weeks. The OpenSPDD project formalizes this as bidirectional synchronization. When code changes during review or refactoring, the design documents must update to reflect actual implementation, not just planned implementation. Stale docs are worse than no docs because they actively mislead. The sync skill compares implementation against spec, identifies drift, and proposes updates with rationale (“Design said Strategy pattern; implementation uses simple switch because only 2 variants exist”).
Ship (/ygs-ship) enforces the pre-merge ceremony I’ve seen skipped too many times:
- All tests pass (not “most tests pass” ALL tests pass)
- Diff reviewed against base branch, no debug code, no .env files, no build artifacts
- Version bumped appropriately (patch for fixes, minor for features, major for breaking changes)
- Changelog updated so consumers know what changed
- PR created with clear description for the record
No shortcuts. The ceremony exists because every shortcut I’ve taken in 30 years has eventually cost more than the ceremony would have.
Retro (/ygs-retro) closes the feedback loop — and this is where learning happens:
- What went well: Practices to keep. Architectural decisions that paid off. Estimation accuracy.
- What didn’t: Missed estimates (why specifically?). Bugs that shipped (what review would have caught them?). Scope creep (where did it come from?).
- Patterns: Recurring issues across tasks reveal systemic problems. The same type of bug appearing three times isn’t bad luck — it’s a missing test category or a design flaw.
Five Whys with the Swiss Cheese model drives every retro:
- Why did the system fail? -> Direct cause
- Why was that possible? -> Missing guard
- Why wasn’t it prevented? -> Process gap
- Why wasn’t it detected? -> Monitoring gap
- Why wasn’t impact contained? -> Isolation gap
Multiple barriers had to fail simultaneously for the incident to reach customers. The fix is never “be more careful”, it’s always a structural change: a new test category, a new circuit breaker, a new alert threshold, a new deployment gate.
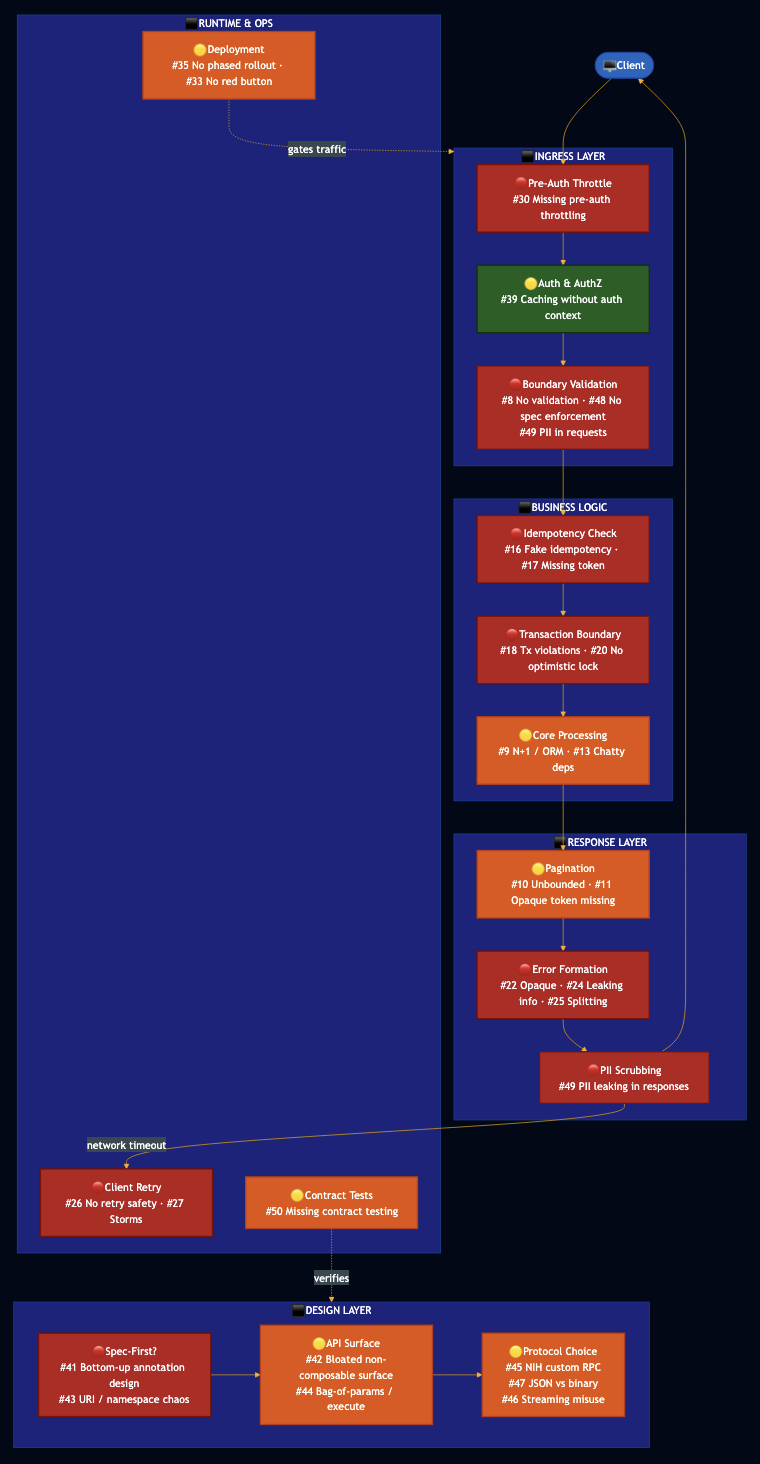
The Code-to-Production Pipeline
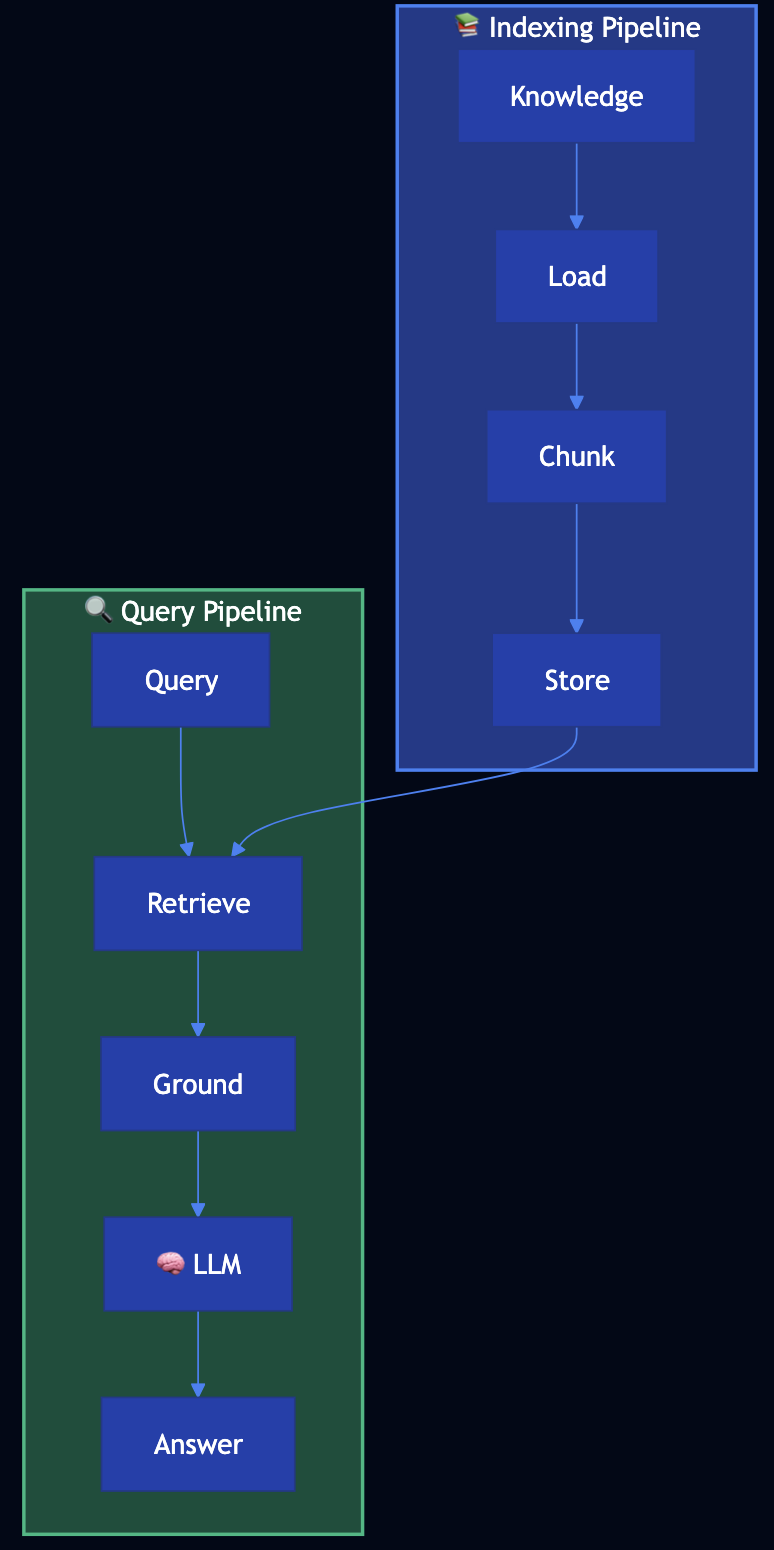
See my post on production readiness:

Beyond Vibe Coding: Specifications as the Missing Layer
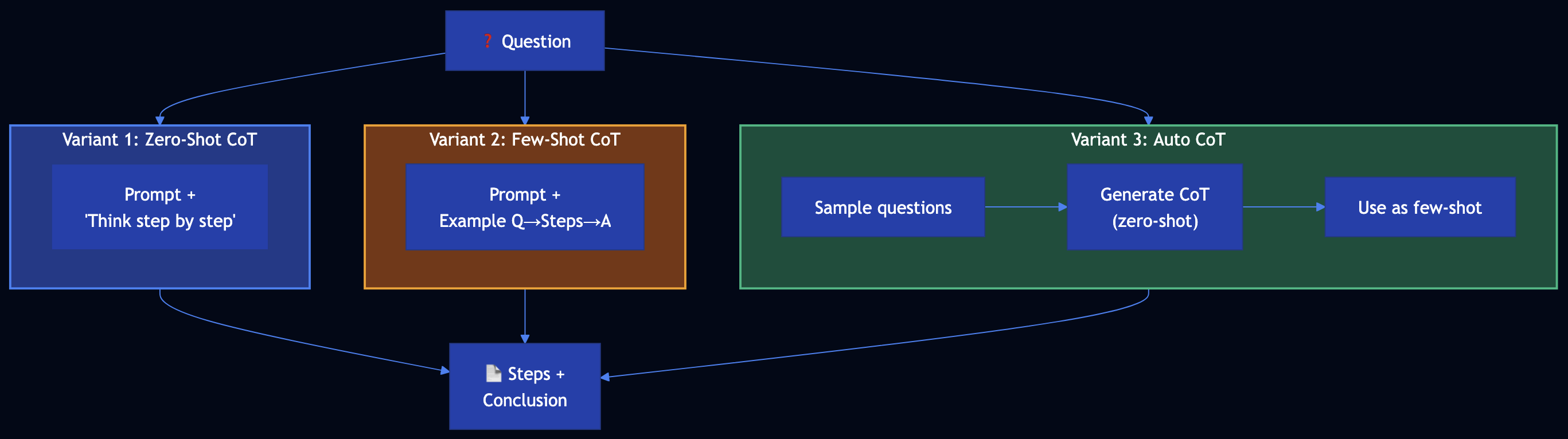
Most teams use AI in what I call vibe coding mode: describe what you want in natural language, generate code, iterate. It works for small problems. It fails for complex systems. I tested this boundary directly by combining TLA+ formal specifications with Claude. The insight: AI fails not because of intelligence limits, but because we give it vague specifications. “Create a task management API” produces guesses. A TLA+ spec defining valid state transitions, invariants, and concurrent scenarios produces code that satisfies those properties precisely. You don’t need TLA+ for every feature. But the spectrum matters:
- Vague natural language ? AI guesses, inconsistent edge case handling
- Structured requirements (RFC 2119 + Given/When/Then) ? AI follows rules, mostly correct
- Formal specifications (TLA+) ? AI implements verified properties, comprehensive test coverage from execution traces
Writing TLA+ properties reveals design flaws before implementation. I discovered that sequential task IDs create security vulnerabilities — a flaw that wouldn’t surface until production. The model checker found it automatically. The SDLC skills sit in the practical middle: structured enough to eliminate ambiguity, lightweight enough to use daily.
The REASONS Canvas: Structured Prompts as Design Contracts
The OpenSPDD project takes this further with a 7-dimension framework called the REASONS Canvas: Requirements, Entities, Approach, Structure, Operations, Norms, Safeguards. The distinction between a plan and a REASONS Canvas is the distinction between a suggestion and a contract. Plans describe intent; structured prompts define constraints that eliminate AI improvisation. I’ve incorporated the most valuable elements into these skills:
- Entities as an explicit TRD questioning dimension — forcing domain model clarity before implementation
- Norms and Safeguards — explicit negative constraints (“do NOT refactor existing structures unless requirements demand it”) that prevent AI from improvising
- Operations sequencing — implementation order based on dependency analysis, not arbitrary file ordering
- Bidirectional sync — the insight that design docs must stay accurate as code evolves, not just at initial creation
The key insight from SPDD’s design philosophy resonates: capability and control are separate dimensions. AI models keep getting smarter (capability improves), but that doesn’t automatically improve alignment with your specific intent (control).
Prompting Frameworks: Why Structure Beats Eloquence
Following prompting frameworks shaped how I designed every skill in this set:
- R.E.A.S.O.N. (Role, Environment, Action, Steps, Output, Negatives): The Negatives dimension is underappreciated. Telling AI what NOT to do eliminates entire categories of unwanted behavior more reliably than telling it what to do. Every skill includes explicit constraints: “do not refactor existing code,” “do not touch files outside task scope,” “do not fix without establishing root cause.”
- PRISM for reasoning models (Problem, Relevant Information, Success Measures): For newer reasoning models, step-by-step instructions can degrade performance. Define the problem, provide context, specify what success looks like, then let the model’s internal reasoning find the path. The refine skills work this way: instead of prescribing exact steps, they define dimensions to explore and quality criteria to meet.
- Context hygiene:Agent quality is roughly 75% model, 25% context. Long sessions degrade as context fills and compacts. The SDLC skills address this structurally: each phase is a separate invocation, artifacts persist as files (not conversation history), and small vertical-slice tasks complete within a single focused session. Since the agent can’t remember across sessions, encode everything important into files that do.
- Multi-Shot and Few-Shot Patterns: Providing examples of desired output format dramatically improves consistency. The skills encode this implicitly, e.g., the templates (PRD, TRD, design doc, threat model, task, ADR) serve as few-shot examples of the expected output structure. When the AI reads a template before generating, it produces output that matches the format without being told explicitly. The design doc template encodes the 9-section structure I’ve refined over years of writing design documents at scale: executive summary, background/problem statement, proposal with stakeholders, architecture with failure paths, alternatives considered, functional requirements traced to PRD, non-functional requirements (performance, security, operations, cost), rollout plan with phases, and a decision log recording ADRs inline. The threat model template follows STRIDE methodology with 13 sections: from defining security tenets and trust boundaries through systematic threat analysis grouped by subsystem, to security test plans and compliance checklists.
Model Selection: Match the Model to the Phase
Not every SDLC phase needs the same model. I’ve settled on a pattern that optimizes for both quality and cost:
Reasoning-heavy phases -> strongest model (Opus-class):
- Requirements refinement (
/ygs-refine-prd): Needs to challenge assumptions, find contradictions, explore implications - Technical design (
/ygs-refine-trd): Needs architectural reasoning, trade-off analysis, pattern recognition across the codebase - Architecture refinement (
/ygs-refine-architecture): System-level thinking, identifying failure modes, deep module analysis - Code review (
/ygs-code-review): Catching subtle logic errors, race conditions, partial failure scenarios - Security review (
/ygs-security-review): Adversarial thinking, attack path analysis, red-team perspective
Implementation phases -> fast model (Sonnet-class):
- Implementation (
/ygs-implement): Following well-defined specs, writing code within established patterns - Grooming (
/ygs-grooming): Mechanical decomposition of well-understood requirements - Ship (
/ygs-ship): Running tests, creating PRs, version bumping
Either works:
- Estimation (
/ygs-estimate): Benefits from reasoning for uncertainty analysis, but doesn’t require it - QA/UAT (
/ygs-qa,/ygs-uat): Testing scenarios benefit from creativity but are often mechanical - Sync (
/ygs-sync): Comparison is largely mechanical, but drift detection benefits from reasoning
The logic: design and review require judgment; implementation requires following instructions. A cheaper, faster model that faithfully executes a well-specified task often outperforms an expensive model given a vague one. This is why investing effort in the refinement phases (where you use the strongest model to produce precise specs) pays dividends in the implementation phase.

Industry Patterns for Model Routing
The practical takeaway: the quality of your specs determines how capable your implementation model needs to be. A well-specified task with clear acceptance criteria, explicit constraints, and defined negative boundaries (what NOT to do) can be implemented correctly by a fast model. A vague task requires a reasoning model to fill gaps, and it will fill them with assumptions from training data, not your domain knowledge.
Lessons from Agentic AI Design Patterns
I’ve catalogued 50 design patterns for generative and agentic AI across six categories — from content control and RAG to multi-agent orchestration. Several patterns directly inform how I structured these skills:
- Reflection pattern: Agents that evaluate and revise their own output produce better results than single-shot generation. The SDLC skills implement this as separate review phases: generate (implement) -> evaluate (code review) -> revise (fix findings). The review skills ARE the reflection pattern, externalized into a structured workflow.
- Prompt chaining over autonomy: Decomposing complex tasks into sequential, well-defined steps consistently outperforms giving an agent unbounded autonomy. The WBS skill does exactly this: hierarchically decomposes large features into small, sequential tasks with clear acceptance criteria. Each task is one link in the chain.
- Tool calling with clear contracts: Agents that invoke well-defined tools with explicit input/output contracts produce more reliable results than agents reasoning in open-ended conversation. The skills serve as “tools” for the AI coding agent — each one a well-defined workflow with clear inputs (what phase we’re in, what artifacts exist) and outputs (specific deliverables with completion status).
- Human-in-the-loop at decision points: The most reliable pattern across all my agent systems is autonomous execution for mechanical work with human checkpoints for judgment calls. The implementation skill embodies this: AI codes autonomously but STOPS at 3+ unplanned files, checkpoints every 5 files, and reports all deviations. You make the judgment calls; AI does the typing.
- Memory tiers for context management: Production agents need structured memory: short-term (current session), medium-term (project conventions), and long-term (organizational knowledge). These skills serve as the medium and long-term memory tiers — encoding patterns and standards that survive across sessions.

The operational lesson from building all these systems: production AI requires the same engineering discipline as any distributed system. Circuit breakers for external API calls. Cost tracking with hard limits. Observability with correlation IDs. Graceful degradation when dependencies fail. These aren’t optional — they’re what separates demos from systems that run in production without 3am pages. The same discipline applied to AI coding workflows is what these skills encode.
Why This Matters Now
Martin Fowler recently asked the fundamental question: can AI evade the tar pit, or will it struggle in the accumulated complexity that slows every software project? The answer: AI doesn’t escape the tar pit. It digs faster. Autonomous AI agents mostly mean ‘I don’t know what it’s going to do.’ Structured workflows beat autonomy for production code. Most AI coding benefits from structured workflows, not autonomous agents making unbounded decisions. Jessica Kerr’s insight about double feedback loops matches how I use these skills: one loop builds features; another improves the development process. The skills aren’t static, each post-mortem adds a check to security review, each escaped bug extends the code review criteria. The AI benefits from that evolution without needing to “learn” it.
The Paradox: Writing vs. Reviewing
When you review AI-generated code, you don’t build the same understanding as when you write it. Here’s the middle path that works for me:
- Own the design. Write the architecture docs yourself. Define the interfaces. Specify the state machines. Draw the data flow diagrams. This is where deep thinking happens — at the design level, not the implementation level.
- Delegate the implementation. Let AI fill in the mechanical details within your design constraints. The type system and test suite verify it got the details right.
- Review with structure. Multi-pass review with explicit criteria catches what casual reading misses. Two passes (critical then design) force different modes of attention.
- Learn through refinement. The structured questioning in refinement sessions forces you to think deeply about the problem space. You can’t answer “what happens when this fails halfway through?” without building real understanding.
The skills encode this approach: you think deeply during refinement, design, and review. AI accelerates the mechanical middle. The result maintains conceptual integrity because the design philosophy flows from structured artifacts that persist across sessions, not from the agent’s ephemeral training data biases. As Brooks said: conceptual integrity matters more than any individual feature. These skills are how I maintain it while leveraging AI for the implementation work that used to consume 80% of my time.
Getting Started
# Install git clone https://github.com/bhatti/you-got-skills.git ~/.claude/skills/you-got-skills # Start with an idea /ygs-refine-prd # Work through the lifecycle /ygs-refine-trd -> /ygs-estimate -> /ygs-spike (if risky) -> /ygs-wbs -> /ygs-implement -> /ygs-code-review -> /ygs-ship
The skills are pure markdown, no compilation, no dependencies, no telemetry. Read any skill in 30 seconds. Understand the full set in 10 minutes. Extend by adding a SKILL.md file in a new directory. Each skill stands alone. Use any subset in any order. Skip what doesn’t apply. The power isn’t in following a rigid process, it’s in having structured knowledge available when you need it, so the AI works with your standards instead of against them. The repository: github.com/bhatti/you-got-skills
Conclusion
The quest to make coding simpler is as old as coding itself. BASIC to 4GLs to UML to AI agents — every generation promises the same thing: focus on what, not how. Every generation delivers the same lesson: the thinking is the hard part, and you can’t automate it away. What’s different about AI coding agents is that they genuinely accelerate the how in ways previous tools never achieved. But acceleration without direction is faster wandering. Acceleration without conceptual integrity fragments your system’s design philosophy at speed.
These skills answer the question I kept returning to: how do you maintain conceptual integrity when the agent starts from zero every session? You encode your standards, conventions, and design philosophy into structured artifacts that survive across sessions. You own the what and the why. You let AI accelerate the how. You review everything through principles that have survived three decades of paradigm shifts. You own the what and the why. You let AI accelerate the how.
The skills discussed in this post are available at github.com/bhatti/you-got-skills. Built for Claude Code but the principles apply to any AI-assisted development workflow.
Related Blog posts:
| Topic | Key Insight |
|---|---|
| Functional Pipeline | Type system beats testing for correctness. Immutable data flows eliminate aliasing bugs. State machines make illegal transitions impossible. |
| API Design | 50 anti-patterns I now check automatically like Idempotency, Command-Query Separation, etc. |
| Production Readiness and Incidents | Failures are multi-cause; fixes must be structural |
| Domain Driven and Hexagonal Design | Bounded context, ubiquitous language, separation of concerns. |
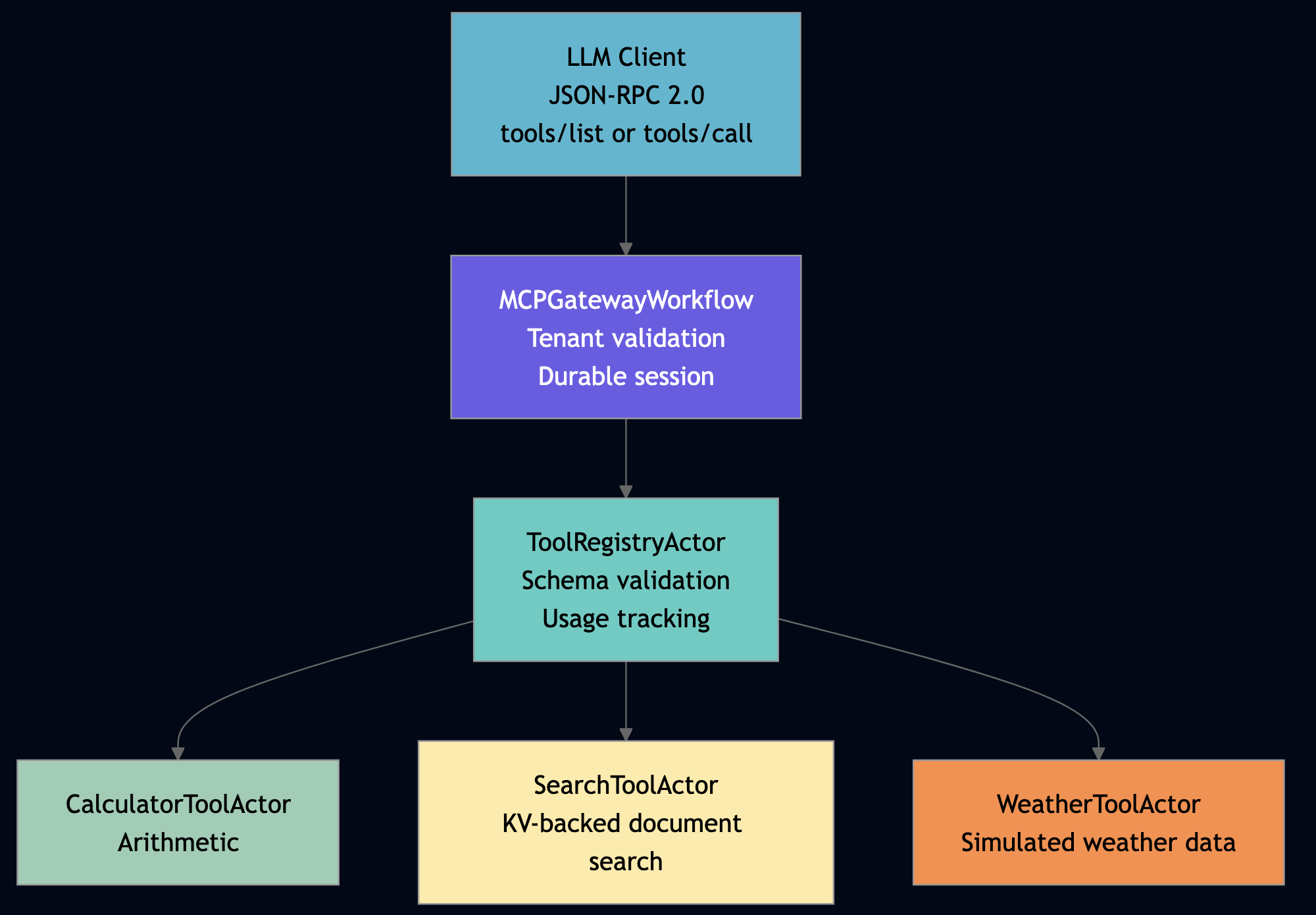
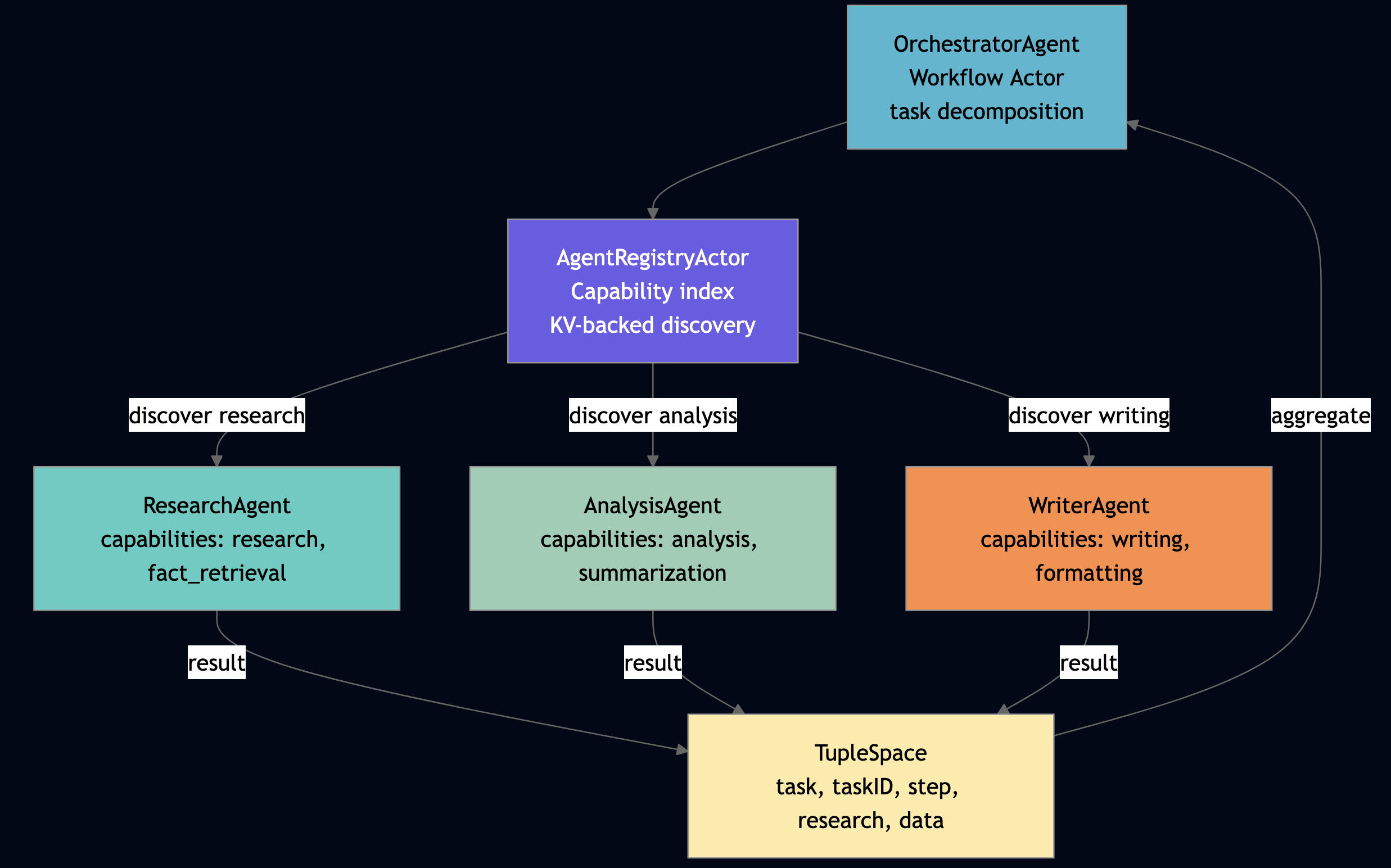
| Production AI Agents such as enterprise AI platforms with vLLM, multi-agent architectures with MCP and A2A, API compatibility checking, PII detection, and personal productivity. | The protocol is 10% of the work |