Introduction
I’ve been in software development for decades, and if there’s one lesson that’s been burned into my memory through countless production incidents, it’s this: innocuous-looking API changes have an uncanny ability to break everything. You’re getting alerts—an API change that sailed through testing is breaking production. Customer support is calling. You’re coordinating an emergency rollback, wondering how your tests missed this entirely.
The Problem We Keep Facing
Throughout my career, I’ve watched teams struggle with the same challenge: API evolution shouldn’t be a game of Russian roulette. Yet “safe” changes repeatedly pass tests only to break production. Unit testing doesn’t catch the subtle semantic changes that break client integrations. For years, I’ve been building tools to solve this. I created PlexMockServices for API mocking, then evolved it into api-mock-service with full mock and contract testing support. These tools have saved us from many production incidents. I have also written about various testing methodologies for validating APIs such as:
- Mocking and Fuzz Testing Distributed Micro Services with Record/Play, Templates and OpenAPI Specifications
- Property-based and Generative testing for Microservices
- Consumer-driven and Producer-generated Contract Testing for REST APIs
When gRPC and Protocol Buffers arrived, I thought we’d finally solved it. Tools like Buf excel at catching wire-level protocol changes—remove a field, Buf catches it. But here’s what I discovered: Buf and similar tools only see part of the picture.
The Blind Spots
Traditional static analysis tools understand syntax but not semantics. They catch structural changes but miss:
- Fields made required through validation rules—wire-compatible, but every client fails
- Fields that were “always” populated until you made them conditional
- Error messages that clients parse with regex
- Sort orders that changed, breaking customer dashboards
- Default values that shifted behavior
With enough users, all observable behaviors will be depended upon—that’s Hyrum’s Law. The challenge isn’t just detecting changes; it’s understanding their impact from every consumer’s perspective.
Enter Agentic AI
Over the past year, I’ve been experimenting with combining static analysis tools like Buf with the contextual understanding of Large Language Models. Not to replace traditional tools, but to augment them—to catch what they structurally cannot see. In this blog, I’ll show you how to build an intelligent API guardian using LangChain and LangGraph—an agentic AI system that:
- Orchestrates multiple tools (Git, Buf, LLMs) in coordinated workflows
- Understands not just what changed, but what it means
- Catches both wire-level and semantic breaking changes
- Explains why something breaks and how to fix it
- Makes autonomous deployment decisions based on comprehensive analysis
Let me show you how we built this system and how you can implement it for your APIs. Those emergency customer calls about broken integrations might just become a thing of the past.
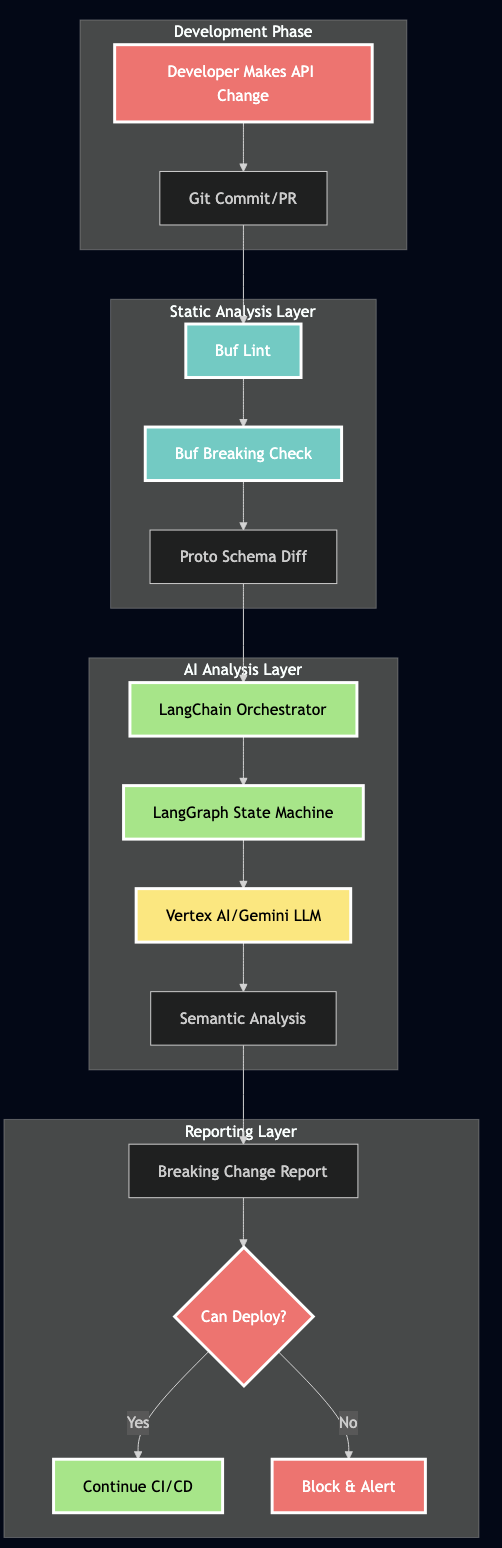
Architecture Overview: The Intelligent Pipeline
The key insight behind this approach is that no single tool can catch all breaking changes. Static analyzers like Buf excel at structural validation but can’t reason about semantics. LLMs understand context and business logic but lack the deterministic guarantees of rule-based systems. The solution? Combine them in an orchestrated pipeline where each component contributes its strengths.
What I’ve built is an intelligent pipeline that layers multiple detection strategies:
- Buf provides fast, deterministic detection of wire-level protocol violations
- LangGraph orchestrates a stateful workflow that coordinates all the analysis steps
- LangChain manages the LLM interactions, handling prompts, retries, and structured output parsing
- Vertex AI/Gemini brings semantic understanding to analyze what changes actually mean for API consumers
Here’s how these components work together in practice:
Setting Up the Environment
Let’s walk through setting up this system step by step. We’ll use a sample Todo API project as our example.
Prerequisites
# Clone the sample repository git clone https://github.com/bhatti/todo-api-errors.git cd todo-api-errors/check-api-break-automation # Create Python virtual environment python3 -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activate # Install dependencies pip install -r requirements.txt
Installing Buf
Buf is essential for proto file analysis:
# macOS brew install bufbuild/buf/buf # Linux curl -sSL "https://github.com/bufbuild/buf/releases/latest/download/buf-Linux-x86_64" -o /usr/local/bin/buf chmod +x /usr/local/bin/buf # Verify installation buf --version
Configuring Google Cloud and Vertex AI
- Set up GCP Project:
# Install gcloud CLI if not already installed # Follow: https://cloud.google.com/sdk/docs/install # Authenticate gcloud auth application-default login # Set your project gcloud config set project YOUR_PROJECT_ID
- Enable Vertex AI API:
gcloud services enable aiplatform.googleapis.com
- Create Configuration File:
# Create .env file cat > .env << EOF GCP_PROJECT=your-project-id GCP_REGION=us-central1 VERTEX_AI_MODEL=gemini-2.0-flash-exp EOF
Implementation Deep Dive
The LangGraph State Machine
Our implementation uses LangGraph to create a deterministic workflow for analyzing API changes:
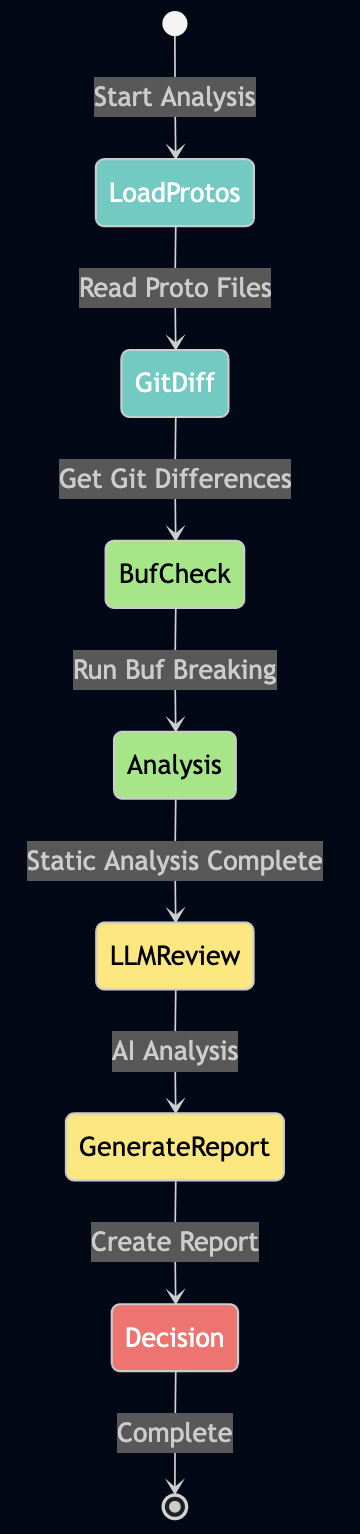
Here’s the core LangGraph implementation:
from langgraph.graph import StateGraph, MessagesState
from typing import TypedDict, List, Dict, Any
import logging
class CompatibilityState(TypedDict):
"""State for the compatibility checking workflow"""
workspace_path: str
proto_files: List[str]
git_diff: str
buf_results: Dict[str, Any]
ai_analysis: Dict[str, Any]
final_report: Dict[str, Any]
can_deploy: bool
class CompatibilityChecker:
def __init__(self, project_id: str, model_name: str = "gemini-2.0-flash-exp"):
self.logger = logging.getLogger(__name__)
self.project_id = project_id
self.model = self._initialize_llm(model_name)
self.workflow = self._build_workflow()
def _build_workflow(self) -> StateGraph:
"""Build the LangGraph workflow"""
workflow = StateGraph(CompatibilityState)
# Add nodes for each step
workflow.add_node("load_protos", self.load_proto_files)
workflow.add_node("get_diff", self.get_git_diff)
workflow.add_node("buf_check", self.run_buf_analysis)
workflow.add_node("ai_analysis", self.run_ai_analysis)
workflow.add_node("generate_report", self.generate_report)
# Define the flow
workflow.add_edge("load_protos", "get_diff")
workflow.add_edge("get_diff", "buf_check")
workflow.add_edge("buf_check", "ai_analysis")
workflow.add_edge("ai_analysis", "generate_report")
# Set entry point
workflow.set_entry_point("load_protos")
workflow.set_finish_point("generate_report")
return workflow.compile()Intelligent Prompt Engineering
The key to accurate breaking change detection lies in the prompt design. Here’s our approach:
def create_analysis_prompt(self, diff: str, buf_results: dict) -> str:
"""Create a comprehensive prompt for the LLM"""
return f"""
You are an API compatibility expert analyzing protobuf changes.
CONTEXT:
- This is a production API with existing consumers
- Breaking changes can cause service outages
- We follow semantic versioning principles
STATIC ANALYSIS RESULTS:
{json.dumps(buf_results, indent=2)}
GIT DIFF:
```
{diff}
```
ANALYZE THE FOLLOWING:
1. Wire-level breaking changes (trust buf results completely)
2. Semantic breaking changes:
- Required fields added without defaults
- Field removals (always breaking)
- Type changes that lose precision
- Enum value removals or reordering
3. Behavioral concerns:
- Fields that might be parsed by consumers
- Error message format changes
- Ordering or filtering logic changes
CRITICAL RULES:
- If buf reports breaking changes, mark them as is_breaking=true
- Field removal is ALWAYS breaking (severity: HIGH)
- Adding REQUIRED fields is breaking (severity: MEDIUM-HIGH)
- Be conservative - when in doubt, flag as potentially breaking
OUTPUT FORMAT:
Return a JSON object with this structure:
{{
"changes": [...],
"overall_severity": "NONE|LOW|MEDIUM|HIGH|CRITICAL",
"can_deploy": true|false,
"recommendations": [...]
}}
"""Real-World Example: When Buf Missed Half the Problem
Let me show you exactly why we need AI augmentation with a concrete example. I’m going to intentionally break a Todo API in two different ways to demonstrate the difference between what traditional tools catch versus what our AI-enhanced system detects.
The Original Proto File
message Task {
string id = 1;
string title = 2;
string description = 3; // This field will be removed
bool completed = 4;
google.protobuf.Timestamp created_at = 5;
google.protobuf.Timestamp updated_at = 6;
repeated string tags = 7;
TaskPriority priority = 8;
string assignee_id = 9;
google.protobuf.Timestamp due_date = 10;
repeated Comment comments = 11;
}The Modified Proto File
message Task {
string id = 1;
string title = 2;
// REMOVED: string description = 3;
bool completed = 4;
google.protobuf.Timestamp created_at = 5;
google.protobuf.Timestamp updated_at = 6;
repeated string tags = 7;
TaskPriority priority = 8;
string assignee_id = 9;
google.protobuf.Timestamp due_date = 10;
repeated Comment comments = 11;
// NEW REQUIRED FIELD ADDED:
TaskMetadata metadata = 12 [(validate.rules).message.required = true];
}
message TaskMetadata {
string created_by = 1;
int64 version = 2;
map<string, string> labels = 3;
}What Buf Detected
When we ran buf breaking --against '.git#branch=main', Buf only detected one breaking change:
api/proto/todo/v1/todo.proto:83:3:Field "3" with name "description" on message "Task" was deleted.
Why did Buf miss the second breaking change? Because adding a field with [(validate.rules).message.required = true] is an application-level annotation, not a wire-protocol breaking change. Buf focuses on wire compatibility – it doesn’t understand application-level validation rules.
What Our AI-Enhanced System Detected
Here’s the actual output from our tool:
2025-10-14 18:29:11,388 - __main__ - INFO - Collecting git diffs... 2025-10-14 18:29:11,392 - __main__ - INFO - Analyzing with LLM... 2025-10-14 18:29:14,471 - __main__ - INFO - Generating final report... ================================================================================ API BACKWARD COMPATIBILITY REPORT ================================================================================ Timestamp: 2025-10-14T18:29:14.471705 Files Analyzed: api/proto/todo/v1/todo.proto Total Changes: 2 Breaking Changes: 2 Overall Severity: HIGH Can Deploy: NO DETECTED CHANGES: ---------------------------------------- 1. Removed field 'description' Location: api/proto/todo/v1/todo.proto:83 Category: field_removal Breaking: YES Severity: HIGH Recommendation: Consider providing a migration path for clients relying on this field. 2. Added required field 'metadata' Location: api/proto/todo/v1/todo.proto:136 Category: field_addition Breaking: YES Severity: HIGH Recommendation: Ensure all clients are updated to include this field before deployment. LLM ANALYSIS: ---------------------------------------- The changes include the removal of the 'description' field and the addition of a required 'metadata' field, both of which are breaking changes. ================================================================================ 2025-10-14 18:29:14,472 - __main__ - INFO - JSON report saved to results/non_breaking.json
The “Aha!” Moment
This is exactly the scenario I warned about in my presentation. Here’s what happened:
- Buf did its job – It caught the field removal. That’s wire-level breaking change detection working as designed.
- But Buf has blind spots – It completely missed the required field addition because
[(validate.rules).message.required = true]is an application-level annotation. To Buf, it’s just another optional field on the wire. - The AI understood context – Our LLM looked at that validation rule and immediately recognized: “Hey, this server is going to reject any request without this field. That’s going to break every existing client!”
Think about it – if we had only relied on Buf, we would have deployed thinking we fixed the one breaking change. Then boom – production down because no existing client sends the new metadata field. This is precisely why we need AI augmentation. It’s not about replacing Buf – it’s about catching what Buf structurally cannot see.
Beyond This Example
This pattern repeats across many scenarios that static analysis misses:
- Validation rules that make previously optional behavior mandatory
- Fields that were always populated but are now conditional
- Changes to default values that alter behavior
- Error message format changes (clients parse these!)
- Response ordering changes (someone always depends on order)
- Rate limiting or throttling policy changes
- Authentication requirements that changed
Integrating with CI/CD
The tool can be integrated into your CI/CD pipeline:
# .github/workflows/api-compatibility.yml
name: API Compatibility Check
on:
pull_request:
paths:
- '**/*.proto'
jobs:
check-breaking-changes:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
with:
fetch-depth: 0 # Need full history for comparison
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: Install Buf
run: |
curl -sSL "https://github.com/bufbuild/buf/releases/latest/download/buf-Linux-x86_64" -o /usr/local/bin/buf
chmod +x /usr/local/bin/buf
- name: Install dependencies
run: |
pip install -r check-api-break-automation/requirements.txt
- name: Run compatibility check
env:
GCP_PROJECT: ${{ secrets.GCP_PROJECT }}
run: |
cd check-api-break-automation
python api_compatibility_checker.py \
--workspace .. \
--against origin/main \
--output results/pr-check.json
- name: Comment PR with results
if: always()
uses: actions/github-script@v6
with:
script: |
const fs = require('fs');
const results = JSON.parse(fs.readFileSync('check-api-break-automation/results/pr-check.json'));
const comment = `## ? API Compatibility Check Results
**Can Deploy**: ${results.can_deploy ? '? Yes' : '? No'}
**Severity**: ${results.overall_severity}
**Breaking Changes**: ${results.summary.total_breaking_changes}
${results.can_deploy ? '' : '### ?? Breaking Changes Detected\n' + results.recommendations.join('\n')}
`;
github.rest.issues.createComment({
issue_number: context.issue.number,
owner: context.repo.owner,
repo: context.repo.repo,
body: comment
});Advanced Features: RAG and MCP in Action
1. RAG (Retrieval-Augmented Generation): Learning from Past Mistakes
One of the most powerful aspects of our system is how it learns from history. Here’s how RAG actually works in our implementation:
from langchain.vectorstores import Chroma
from langchain.embeddings import VertexAIEmbeddings
from langchain.schema import Document
class BreakingChangeKnowledgeBase:
"""RAG system that learns from past breaking changes"""
def __init__(self, project_id: str):
self.embeddings = VertexAIEmbeddings(
model_name="textembedding-gecko@003",
project=project_id
)
# Store historical breaking changes in vector database
self.vector_store = Chroma(
collection_name="api_breaking_changes",
embedding_function=self.embeddings,
persist_directory="./knowledge_base"
)
def index_breaking_change(self, change_data: dict):
"""Store a breaking change incident for future reference"""
doc = Document(
page_content=f"""
Proto Change: {change_data['diff']}
Breaking Type: {change_data['type']}
Customer Impact: {change_data['impact']}
Resolution: {change_data['resolution']}
""",
metadata={
"severity": change_data['severity'],
"date": change_data['date'],
"service": change_data['service'],
"prevented": change_data.get('caught_before_prod', False)
}
)
self.vector_store.add_documents([doc])
def find_similar_changes(self, current_diff: str, k: int = 5):
"""Find similar past breaking changes"""
results = self.vector_store.similarity_search_with_score(
current_diff,
k=k,
filter={"severity": {"$in": ["HIGH", "CRITICAL"]}}
)
return results
# How it's used in the main checker:
class CompatibilityChecker:
def __init__(self, project_id: str):
self.knowledge_base = BreakingChangeKnowledgeBase(project_id)
def run_ai_analysis(self, state: dict):
"""Enhanced AI analysis using RAG"""
# Find similar past incidents
similar_incidents = self.knowledge_base.find_similar_changes(
state['git_diff']
)
# Build context from past incidents
historical_context = ""
if similar_incidents:
historical_context = "\n\nSIMILAR PAST INCIDENTS:\n"
for doc, score in similar_incidents:
if score > 0.8: # High similarity
historical_context += f"""
- Previous incident: {doc.metadata['date']}
Impact: {doc.page_content}
This suggests high risk of similar issues.
"""
# Include historical context in prompt
enhanced_prompt = f"""
{self.base_prompt}
{historical_context}
Based on historical patterns, pay special attention to similar past issues.
"""
return self.llm.invoke(enhanced_prompt)2. Model Context Protocol (MCP) Integration
MCP allows our AI to interact with external tools seamlessly. Here’s the actual implementation:
# mcp_server.py - MCP server for API compatibility tools
from mcp.server import MCPServer
from mcp.tools import Tool, ToolResult
import subprocess
import json
class APICompatibilityMCPServer(MCPServer):
"""MCP server exposing API compatibility tools to AI agents"""
def __init__(self):
super().__init__("api-compatibility-checker")
self.register_tools()
def register_tools(self):
"""Register all available tools"""
@self.tool("buf_lint")
async def buf_lint(proto_path: str) -> ToolResult:
"""Run buf lint on proto files"""
result = subprocess.run(
["buf", "lint", proto_path],
capture_output=True,
text=True
)
return ToolResult(
success=result.returncode == 0,
output=result.stdout,
error=result.stderr
)
@self.tool("buf_breaking")
async def buf_breaking(proto_path: str, against: str = "main") -> ToolResult:
"""Check for breaking changes using buf"""
cmd = [
"buf", "breaking",
"--against", f".git#branch={against}",
"--path", proto_path
]
result = subprocess.run(cmd, capture_output=True, text=True)
# Parse breaking changes
breaking_changes = []
for line in result.stdout.splitlines():
if line.strip():
breaking_changes.append(self.parse_buf_output(line))
return ToolResult(
success=True,
data={
"has_breaking": len(breaking_changes) > 0,
"changes": breaking_changes,
"raw_output": result.stdout
}
)
@self.tool("check_consumer_contracts")
async def check_contracts(service: str, version: str) -> ToolResult:
"""Check if change breaks consumer contracts"""
# This connects to our contract testing system
contracts = self.load_consumer_contracts(service)
violations = []
for contract in contracts:
if not self.validate_contract(contract, version):
violations.append({
"consumer": contract["consumer"],
"expectation": contract["expectation"],
"impact": "Contract violation detected"
})
return ToolResult(
success=True,
data={
"total_consumers": len(contracts),
"violations": violations,
"safe_to_deploy": len(violations) == 0
}
)
@self.tool("generate_migration_guide")
async def generate_migration(breaking_changes: list) -> ToolResult:
"""Generate migration guide for breaking changes"""
guide = self.create_migration_steps(breaking_changes)
return ToolResult(
success=True,
data={"migration_guide": guide}
)
# How LangChain uses MCP tools:
from langchain.agents import create_mcp_agent
from langchain_mcp import MCPToolkit
# Initialize MCP toolkit
mcp_toolkit = MCPToolkit(
server_url="http://localhost:8080", # MCP server endpoint
available_tools=["buf_lint", "buf_breaking", "check_consumer_contracts"]
)
# Create agent with MCP tools
agent = create_mcp_agent(
llm=llm,
tools=mcp_toolkit.get_tools(),
system_prompt="""
You are an API compatibility expert. Use the available MCP tools to:
1. Run buf lint and breaking checks
2. Verify consumer contracts
3. Generate migration guides when needed
Always check consumer contracts after detecting breaking changes.
"""
)
# Usage in the main workflow
class CompatibilityChecker:
def __init__(self):
self.mcp_agent = agent
def comprehensive_check(self, proto_path: str):
"""Run comprehensive compatibility check using MCP tools"""
# Let the agent orchestrate the tools
result = self.mcp_agent.invoke({
"input": f"""
Analyze {proto_path} for breaking changes:
1. Run buf lint first
2. Check breaking changes against main branch
3. If breaking changes found, check consumer contracts
4. Generate migration guide if needed
"""
})
return result3. How RAG + MCP Work Together
Here’s the magic – combining RAG’s historical knowledge with MCP’s tool access:
class IntelligentAPIGuardian:
"""Combines RAG and MCP for comprehensive analysis"""
def analyze_change(self, proto_diff: str):
# Step 1: Use MCP to run all tools
mcp_results = self.mcp_agent.invoke({
"input": f"Analyze this diff: {proto_diff}"
})
# Step 2: Use RAG to find similar past incidents
historical_data = self.knowledge_base.find_similar_changes(proto_diff)
# Step 3: Combine insights
combined_analysis = self.llm.invoke(f"""
Current change analysis from tools:
{mcp_results}
Historical patterns from similar changes:
{historical_data}
Synthesize a comprehensive risk assessment considering both
current tool results and historical precedents.
If historical data shows issues that tools didn't catch,
flag them as "HISTORICAL_RISK" items.
""")
# Step 4: Store this analysis for future RAG queries
if combined_analysis['has_breaking_changes']:
self.knowledge_base.index_breaking_change({
'diff': proto_diff,
'type': combined_analysis['breaking_type'],
'impact': combined_analysis['impact'],
'resolution': combined_analysis['recommendations'],
'severity': combined_analysis['severity'],
'date': datetime.now(),
'caught_before_prod': True
})
return combined_analysisThe Power of This Combination:
- MCP gives us real-time tool access – running buf, checking contracts, generating migrations
- RAG gives us institutional memory – learning from every incident, getting smarter over time
- Together they catch issues that neither could find alone
For example, RAG might recall “last time we added a required field to Task, the mobile team’s app crashed because they cache responses for 24 hours” – something no static tool would know, but crucial for preventing an outage.
Testing the System
Here’s a complete walkthrough of testing the system:
# 1. First, verify your setup python test_simple.py # Output should show: # ? All core modules imported successfully # ? Proto file found # ? Proto modifier works - 12 test scenarios available # ? Buf integration initialized successfully # ? GCP_PROJECT configured: your-project-id # ? Vertex AI connection verified # 2. Make breaking changes to the proto file python proto_modifier.py ../api/proto/todo/v1/todo.proto \ --scenario remove_field python proto_modifier.py ../api/proto/todo/v1/todo.proto \ --scenario add_required_field # 3. Run the compatibility checker python api_compatibility_checker.py \ --workspace .. \ --against '.git#branch=main' \ --output results/breaking_changes.json # 4. Review the detailed report cat results/breaking_changes.json | jq '.'
Lessons Learned and Best Practices
- Combine Multiple Analysis Methods: Static analysis catches structure, AI catches semantics
- Use Conservative Defaults: When uncertain, flag as potentially breaking
- Provide Clear Explanations: Developers need to understand why something is breaking
- Version Your Prompts: Treat prompts as code – version and test them
- Monitor LLM Costs: Use caching and optimize prompt sizes
- Implement Gradual Rollout: Start with warnings before blocking deployments
- Build Team Trust Gradually: Don’t start by blocking deployments. Run in shadow mode first, report findings alongside Buf results, and let teams see the value before enforcement. Track false positives and tune your prompts based on real feedback.
- Document Your Prompts: Your prompt engineering is as critical as your code. Version control your prompts, document why certain instructions exist, and treat them as first-class artifacts that need testing and review.
The Power of Agentic AI
What makes this approach “agentic” rather than just AI-assisted?
- Autonomous Decision Making: The system doesn’t just flag issues – it makes decisions whether API changes can deployed
- Multi-Step Reasoning: It performs complex analysis chains without human intervention
- Tool Integration: It orchestrates multiple tools (Git, Buf, LLMs) to achieve its goal
- Contextual Understanding: It considers historical patterns and project-specific rules
- Actionable Output: It provides specific remediation steps, not just warnings
Future Enhancements
The roadmap for this tool includes:
- Multi-Protocol Support: Extend beyond protobuf/gRPC to OpenAPI and GraphQL
- Behavioral Testing: Integration with contract testing frameworks
- Auto-Migration Generation: Create migration scripts for breaking changes
- Client SDK Updates: Automatically update client libraries
- Performance Impact Analysis: Predict performance implications of changes
Known Limitations: This system excels at catching semantic and behavioral changes, but it’s not perfect. It can’t predict how undocumented client implementations behave, can’t catch changes in external dependencies your API relies on, and can’t guarantee zero false positives. Human judgment remains essential—especially for nuanced cases where breaking changes might be intentional and necessary.
Conclusion
Throughout my decades in software development, I’ve learned that API compatibility isn’t just about wire protocols and field numbers. It’s about understanding how our users actually depend on our APIs—all the documented behaviors, the undocumented quirks, and yes, even the bugs they’ve built workarounds for. Traditional static analysis tools like Buf are essential—they catch structural breaking changes with perfect precision. But as we’ve seen with the required field example, they can’t reason about semantic changes, business context, or application-level validation rules. That’s where AI augmentation transforms the game. By combining Buf’s deterministic analysis with an LLM’s contextual understanding through LangChain and LangGraph, we’re not just catching more bugs—we’re fundamentally changing how we think about API evolution.
The complete implementation, including all the code and configurations demonstrated in this article, is available at: https://github.com/bhatti/todo-api-errors. Fork it, experiment with it, break it, improve it.
Resources and References
- LangChain Documentation
- LangGraph Guide
- Buf Documentation
- Vertex AI/Gemini Models
- Protocol Buffers Best Practices
- API Versioning Strategies
Postel’s Law: “Be conservative in what you send, liberal in what you accept” – but with Agentic AI, we can be intelligent about both.
Hyrum’s Law: “With a sufficient number of users, all observable behaviors will be depended upon” – which is why we need AI to catch the subtle breaking changes that static analysis misses.