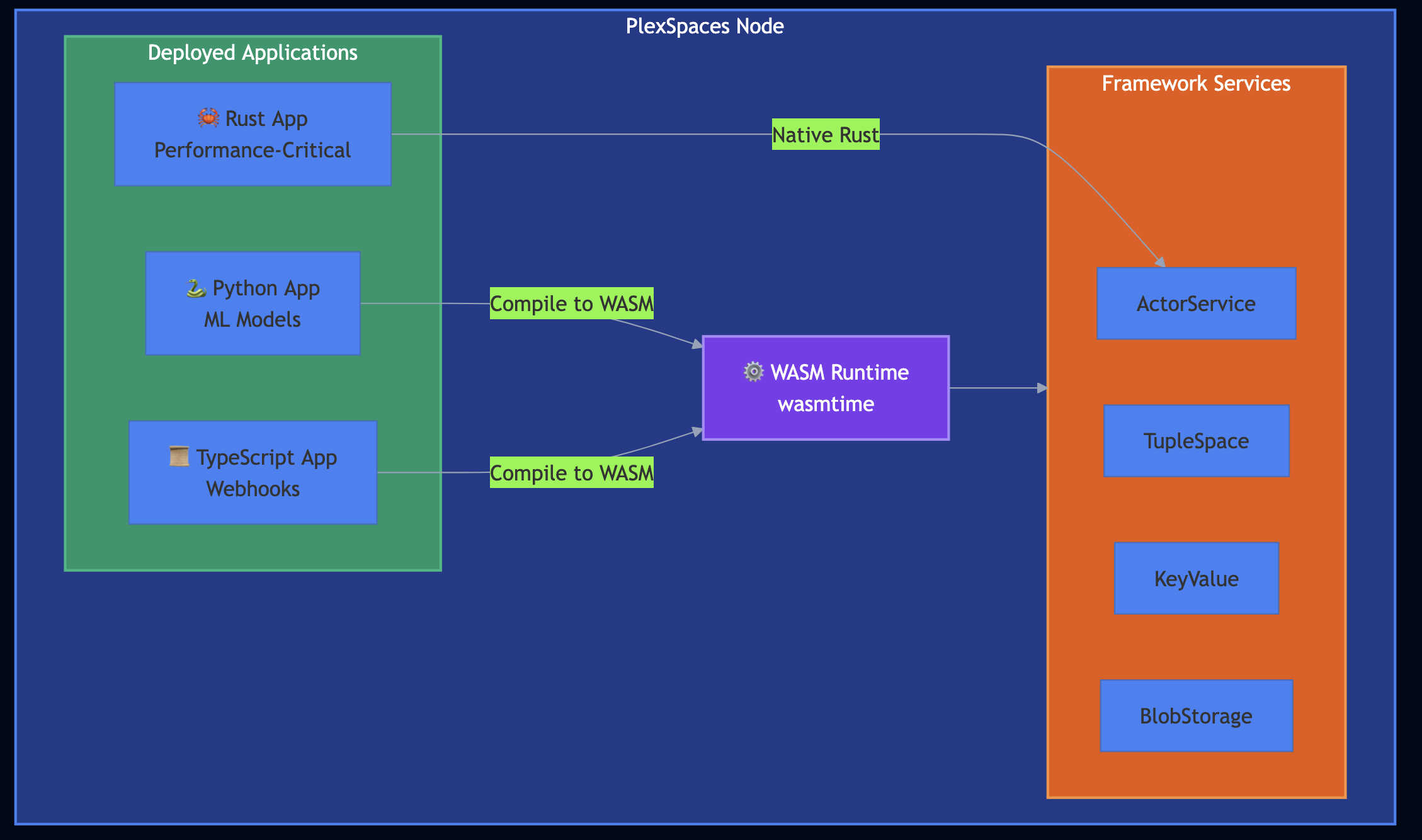
Over the years, I have watched distributed services evolve through phases I lived through personally such as CORBA, EJB, SOA, REST microservices, containers WebAssembly feels different. It compiles code from any language into a universal binary format, runs it in a sandboxed environment, and delivers near-native performance without containers or language-specific runtimes cluttering your production stack.
When I built PlexSpaces for serverless FaaS applications, I designed its polyglot layer on top of WebAssembly and the WASI Component Model. It allows you to write actors in Python, Rust, Go, or TypeScript, compile them to WASM, and deploy them to the same runtime. The framework handles persistence, fault tolerance, supervision, and scaling regardless of programming language. In this post, I’ll walk you through the core WebAssembly concepts, show how PlexSpaces leverages the Component Model for polyglot development, and demonstrate building, testing, and deploying applications in all four languages. I’ll also show a PlexSpaces Application Server model that lets you deploy entire application bundleslike deploying a WAR file to Tomcat, but with the fault-tolerance of Erlang/OTP built in.
WebAssembly Introduction
WebAssembly launched in 2017 as a browser technology. I ignored it for years — client-side JavaScript ecosystem drama wasn’t something I wanted to track. The server-side story changed everything.
How WebAssembly Executes Code
WebAssembly is a stack-based virtual machine that executes a compact binary instruction format. Every language that compiles to WASM follows the same pipeline:

The WASM binary format encodes typed functions, a linear memory model, and a set of imports and exports. The runtime validates the binary at load time, then executes it using either just-in-time (JIT) compilation or ahead-of-time (AOT) compilation to native machine code. Three properties make this execution model powerful for distributed systems:
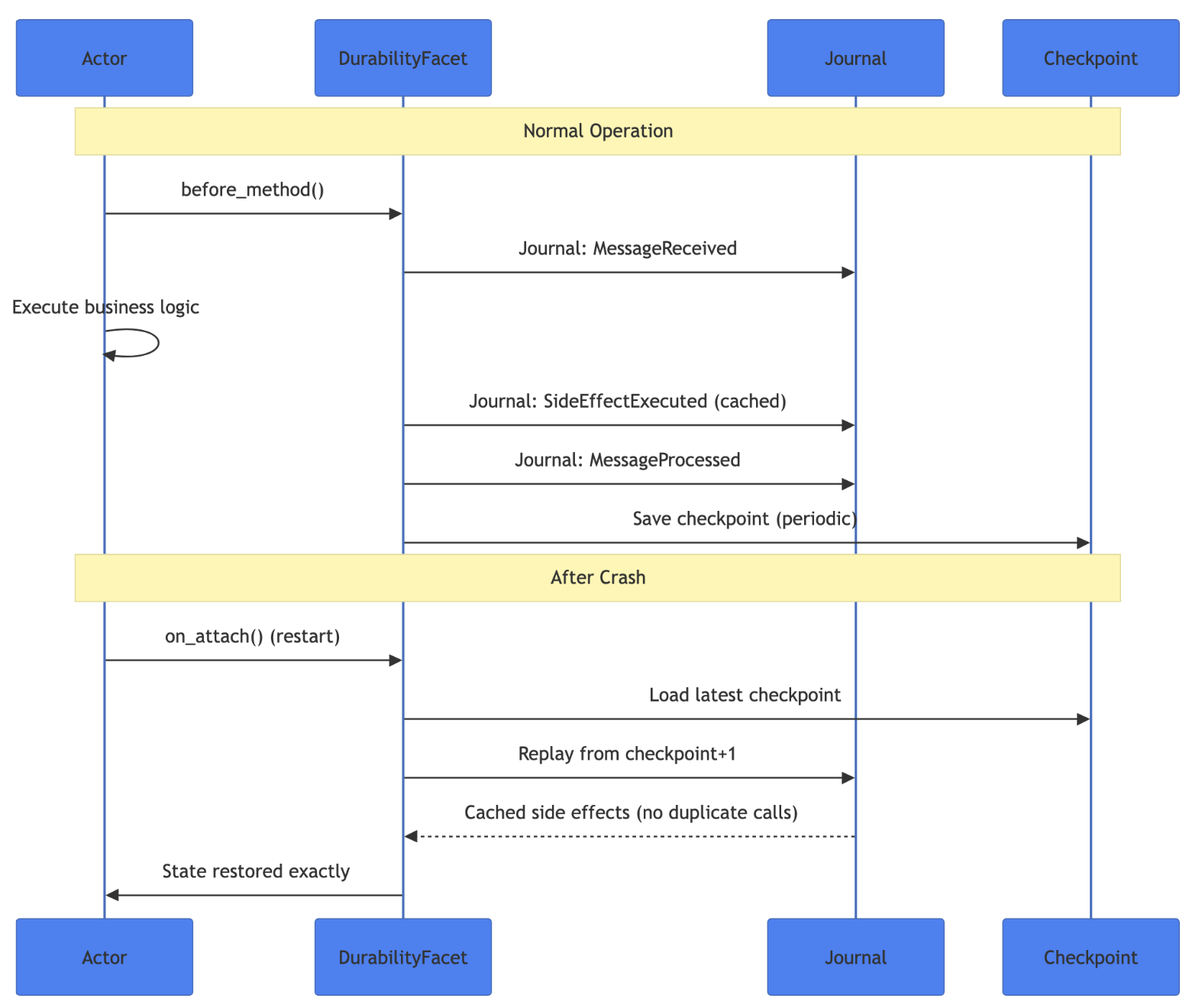
Deterministic execution. Given the same inputs, a WASM module produces the same outputs. This property underpins PlexSpaces’ durable execution, which replays journaled messages through the same WASM binary and arrives at the exact same state.
Memory isolation. Each WASM instance gets its own linear memory. One module cannot read, write, or corrupt another module’s memory. No shared-memory race conditions and buffer overflows escaping the sandbox. The runtime enforces these boundaries at the hardware level.
Capability-based security. A WASM module starts with zero capabilities. It cannot access the filesystem, the network, or even a clock unless the host explicitly provides each capability through imported functions. PlexSpaces grants actors exactly the capabilities they need like messaging, key-value storage, tuple spaces.
The Component Model
Early WebAssembly only understood numbers. You passed integers and floats across the boundary, and that was it. The WebAssembly Component Model fixes this limitation by defining rich, typed interfaces that components use to communicate. You can think of it as an IDL (Interface Definition Language) for WASM but one that works across every language. The key building blocks:
- WIT (WebAssembly Interface Types): A language for defining typed function signatures across components. A function defined in WIT can accept strings, records, lists, variants, and enums. WIT bridges the type systems of Rust, Python, Go, and TypeScript into a single, shared contract.
- Components: Self-contained WASM modules that declare their imports (what they need from the host) and exports (what they provide). A Rust component and a Python component that implement the same WIT interface become interchangeable at the binary level.
- WASI (WebAssembly System Interface): The standardized API that gives WASM modules access to system resources like file I/O, networking, clocks, and random number generation within the sandbox. WASI Preview 2 shipped in 2024 with HTTP, filesystem, and socket support. WASI 0.3, released in February 2026, added native async support for concurrent I/O.
Wasm 3.0 and WasmGC
The WebAssembly ecosystem crossed a critical threshold. Wasm 3.0 became the W3C standard in 2025, standardizing nine production features in a single release:
- WasmGC: garbage collection support built into the runtime, eliminating the need for languages like Go, Python, and Java to ship their own GC inside the WASM binary. This shrinks binary sizes and improves performance for GC-dependent languages dramatically.
- Exception handling: structured try/catch at the WASM level, replacing the expensive setjmp/longjmp workarounds that inflated binaries.
- Tail calls: proper tail call optimization for functional programming patterns without stack overflow.
- SIMD (Single Instruction, Multiple Data): vector operations for parallel numeric computation, critical for ML inference and scientific workloads.
For PlexSpaces, WasmGC means Go and Python actors run faster with smaller binaries. SIMD means computational actors like n-body simulations, matrix multiplies, genomics pipelines that process data at near-native throughput inside the sandbox.
What This Means in Practice
You compile a Python actor and a Rust actor to WASM. Both implement the same WIT interface. The runtime loads them identically, calls the same exported functions, and provides the same host capabilities like messaging, key-value storage, tuple spaces, distributed locks. The Python actor handles ML inference; the Rust actor handles high-throughput event processing. They communicate through PlexSpaces message passing without knowing or caring which language sits on the other side.
This is not “Write Once, Run Anywhere” in the old Java sense. This is “Write in Whatever Language Fits, Run Together on the Same Runtime.”
How PlexSpaces Makes It Work
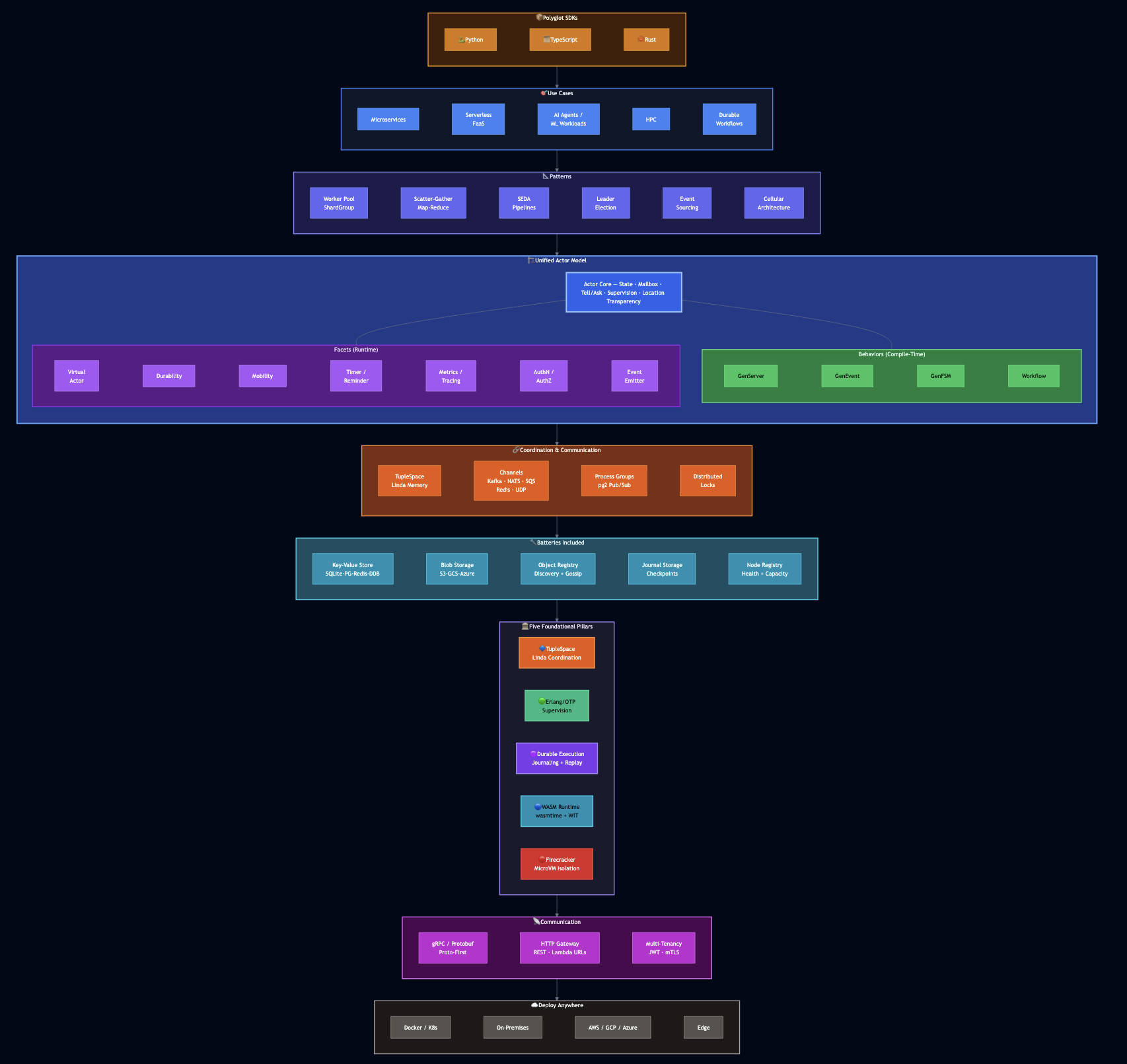
PlexSpaces is a unified distributed actor framework that combines patterns from Erlang/OTP, Orleans, Temporal, and modern serverless architectures into a single abstraction. I described the five foundational pillars in my earlier post: TupleSpace coordination, Erlang/OTP supervision, durable execution, WASM runtime, and Firecracker isolation. Here I focus on the WASM layer and how it enables polyglot development.
Architecture at a Glance
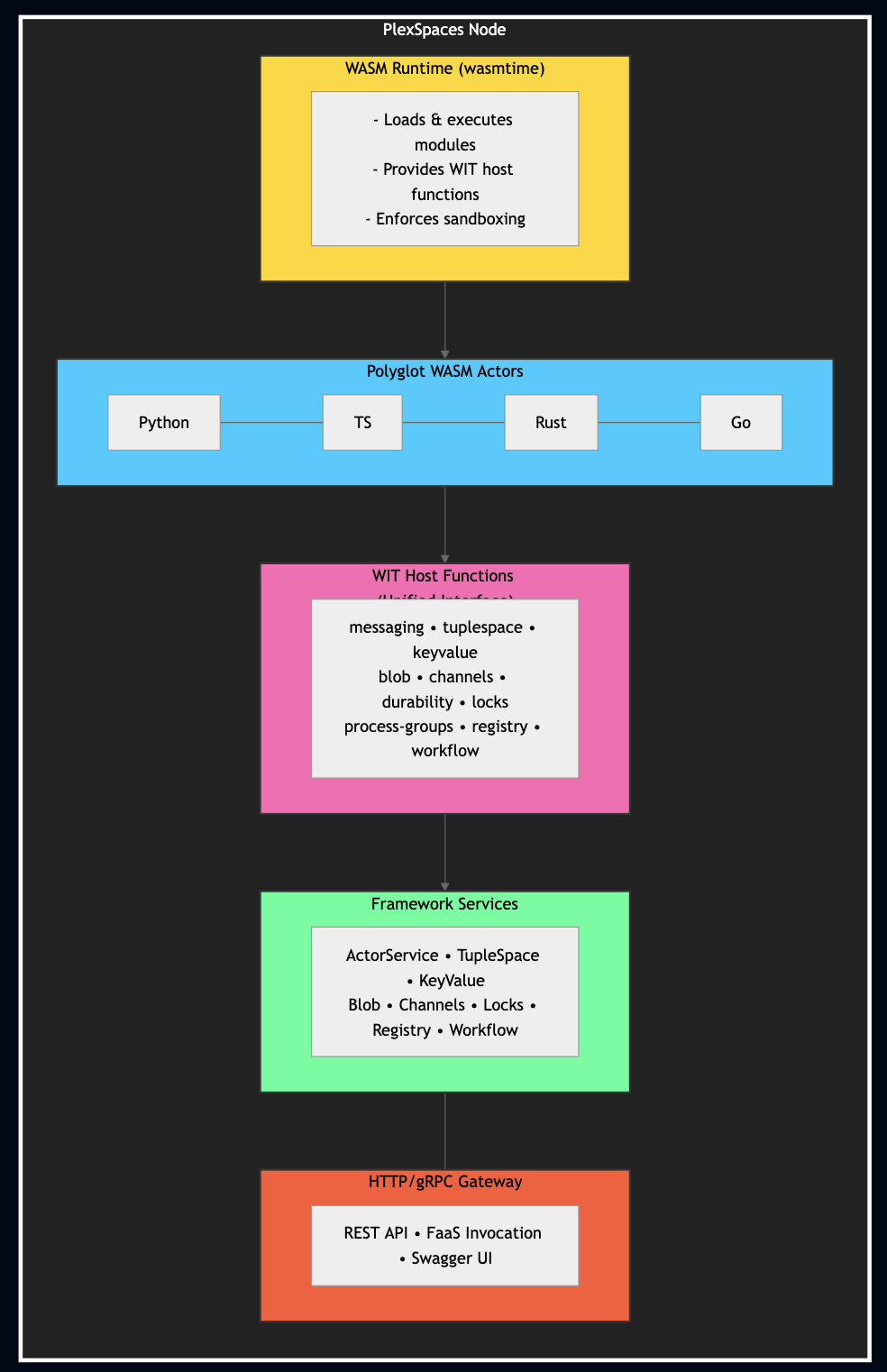
The WIT Contract for Actor
Every actor regardless of source language targets the same WIT world. Here is the simplified world that most polyglot actors use:
// wit/plexspaces-simple-actor/world.wit
package plexspaces:simple-actor@0.1.0;
interface actor {
// Initialize with JSON config string
init: func(config-json: string) -> string;
// Handle a message: route by msg-type, return JSON result
handle: func(from-actor: string, msg-type: string,
payload-json: string) -> string;
// Snapshot state for persistence
get-state: func() -> string;
// Restore state from snapshot
set-state: func(state-json: string) -> string;
}
interface host {
// Messaging
send: func(to: string, msg-type: string, payload-json: string) -> string;
ask: func(to: string, msg-type: string, payload-json: string,
timeout-ms: u64) -> string;
spawn: func(module-ref: string, actor-id: string,
init-config-json: string) -> string;
stop: func(actor-id: string) -> string;
self-id: func() -> string;
// Erlang/OTP-style linking and monitoring
link: func(actor-id: string) -> string;
monitor: func(actor-id: string) -> string;
// Timers
send-after: func(delay-ms: u64, msg-type: string,
payload-json: string) -> string;
// Process groups
pg-join: func(group-name: string) -> string;
pg-broadcast: func(group-name: string, msg-type: string,
payload-json: string) -> string;
// Key-value store
kv-get: func(key: string) -> string;
kv-put: func(key: string, value: string) -> string;
kv-delete: func(key: string) -> string;
kv-list: func(prefix: string) -> string;
// TupleSpace (Linda-style coordination)
ts-write: func(tuple-json: string) -> string;
ts-read: func(pattern-json: string) -> string;
ts-take: func(pattern-json: string) -> string;
ts-read-all: func(pattern-json: string) -> string;
// Distributed locks
lock-acquire: func(tenant-id: string, namespace: string,
holder-id: string, lock-name: string,
lease-duration-secs: u32, timeout-ms: u64) -> string;
lock-release: func(lock-id: string, tenant-id: string,
namespace: string, holder-id: string,
lock-version: string) -> string;
// Blob storage
blob-upload: func(blob-id: string, data: string,
content-type: string) -> string;
blob-download: func(blob-id: string) -> string;
// Logging and time
log: func(level: string, message: string);
now-ms: func() -> u64;
}
world actor-world {
import host;
export actor;
}The full-featured actor package adds dedicated WIT interfaces for workflows, channels, durability/journaling, registry/service discovery, HTTP client, and cron scheduling. PlexSpaces also defines specialized worlds that import only the capabilities each actor needs:
| WIT World | Imports | Use Case |
|---|---|---|
plexspaces-actor | All 13 interfaces | Full-featured actors needing every capability |
simple-actor | Messaging + Logging | Lightweight stateless workers |
durable-actor | Messaging + Durability | Actors with crash recovery and journaling |
coordination-actor | Messaging + TupleSpace | Actors coordinating through shared tuple space |
event-actor | Messaging + Channels | Event-driven actors using queues and topics |
This design keeps WASM binaries small. A simple actor that only needs messaging imports two interfaces not thirteen.
Language Toolchains
Each language uses a different compiler to produce WASM, but the output targets the same runtime:
| Language | Compiler | WASM Size | Performance | Best For |
|---|---|---|---|---|
| Rust | cargo (wasm32-wasip2) | 100KB-1MB | Excellent | Production, performance-critical paths |
| Go | tinygo | 2-5MB | Good | Balanced performance, fast iteration |
| TypeScript | jco componentize | 500KB-2MB | Good | Web integration, rapid development |
| Python | componentize-py | 30-40MB | Moderate | ML inference, data processing, prototyping |
Now let’s build something real in each language.
Getting Started
Before diving into the language examples, set up your development environment.
Prerequisites
- Rust 1.70+ (for building PlexSpaces itself)
- Docker (optional — for the fastest path to a running node)
- One or more WASM compilers for your target languages (see below)
Option 1: Docker Quickstart
Pull and run a PlexSpaces node in seconds:
# Pull the official image
docker pull plexobject/plexspaces:latest
# Run a single node with HTTP API on port 8001
docker run -d \
--name plexspaces-node \
-p 8000:8000 \
-p 8001:8001 \
-e PLEXSPACES_NODE_ID=node1 \
-e PLEXSPACES_DISABLE_AUTH=1 \
plexobject/plexspaces:latestThe node exposes a gRPC endpoint on port 8000 and an HTTP/REST gateway on port 8001 with interactive Swagger UI documentation.
Option 2: Build from Source
git clone https://github.com/bhatti/PlexSpaces.git cd PlexSpaces ./scripts/server.sh # Or use the Makefile step by step make build # Build all crates make test # Run all tests
Install Language Compilers
Install the WASM compiler for each language you plan to use:
# Rust (produces the smallest, fastest WASM) rustup target add wasm32-wasip2 # Go (pragmatic balance of performance and dev speed) # macOS: brew install tinygo # Also need wasm-tools for component creation: cargo install wasm-tools # TypeScript (rapid development, web ecosystem) npm install -g @bytecodealliance/jco # Python (ML, data processing, prototyping) pip install componentize-py # Optional: WASM binary optimizer (shrinks binaries further) cargo install wasm-opt
Start the Node and Deploy Your First Actor
# Start a PlexSpaces node (from source)
cargo run --release --bin plexspaces -- start \
--node-id dev-node \
--listen-addr 0.0.0.0:8000 \
--release-config release-config.toml
# Deploy a WASM actor (from any language)
curl -X POST http://localhost:8001/api/v1/applications/deploy \
-F "application_id=my-app" \
-F "name=my-actor" \
-F "version=1.0.0" \
-F "wasm_file=@my_actor.wasm"
# Send it a message
curl -X POST http://localhost:8001/api/v1/actors/my-app/ask \
-H "Content-Type: application/json" \
-d '{"message_type": "hello", "payload": {}}'Now let’s build real actors in each language.
Python: A Calculator Actor with the SDK
Python shines for rapid prototyping and data-heavy workloads. The PlexSpaces Python SDK uses decorators (@actor, @handler, state()) that eliminate boilerplate and let you focus on business logic.
The Actor Code
# calculator_actor.py
from plexspaces import actor, state, handler, init_handler
@actor
class Calculator:
"""Calculator actor implementing basic math operations."""
# Persistent state fields -- survive crashes via journaling
last_operation: str = state(default=None)
last_result: float = state(default=None)
history: list = state(default_factory=list)
@init_handler
def on_init(self, config: dict):
"""Initialize calculator with optional config."""
if "state" in config:
saved = config["state"]
self.last_operation = saved.get("last_operation")
self.last_result = saved.get("last_result")
self.history = saved.get("history", [])
@handler("add")
def add(self, operands: list = None) -> dict:
"""Add operands together."""
result = sum(operands or [])
self._record("add", operands, result)
return {"result": result, "operation": "add"}
@handler("subtract")
def subtract(self, operands: list = None) -> dict:
"""Subtract: first operand minus rest."""
if not operands or len(operands) < 2:
return {"error": "Subtract requires at least 2 operands"}
result = operands[0] - sum(operands[1:])
self._record("subtract", operands, result)
return {"result": result, "operation": "subtract"}
@handler("multiply")
def multiply(self, operands: list = None) -> dict:
"""Multiply all operands."""
result = 1
for op in (operands or []):
result *= op
self._record("multiply", operands, result)
return {"result": result, "operation": "multiply"}
@handler("divide")
def divide(self, operands: list = None) -> dict:
"""Divide first operand by second."""
if not operands or len(operands) < 2:
return {"error": "Divide requires 2 operands"}
if operands[1] == 0:
return {"error": "Division by zero"}
result = operands[0] / operands[1]
self._record("divide", operands, result)
return {"result": result, "operation": "divide"}
@handler("get_history")
def get_history(self) -> dict:
"""Return calculation history."""
return {"history": self.history}
@handler("call", "get_state")
def get_state_handler(self) -> dict:
"""Snapshot current state."""
return {
"last_operation": self.last_operation,
"last_result": self.last_result,
"history": self.history,
}
def _record(self, operation, operands, result):
self.last_operation = operation
self.last_result = result
self.history.append({
"operation": operation,
"operands": operands,
"result": result,
})Notice how the @actor decorator marks the class, state() declares persistent fields that survive crashes, and each @handler("operation") routes incoming messages to the right method. The SDK handles WIT serialization, state checkpointing, and all the plumbing underneath.
Build and Deploy
# Install the Python SDK
pip install -e "sdks/python/[dev]"
# Build WASM using the SDK CLI
plexspaces-py build calculator_actor.py \
-o calculator_actor.wasm \
--wit-dir wit/plexspaces-simple-actor
# Deploy the WASM module
curl -X POST http://localhost:8001/api/v1/applications/deploy \
-F "application_id=calculator-app" \
-F "name=calculator" \
-F "version=1.0.0" \
-F "wasm_file=@calculator_actor.wasm"Send a Request
curl -X POST http://localhost:8001/api/v1/actors/calculator-app/ask \
-H "Content-Type: application/json" \
-d '{"message_type": "add", "payload": {"operands": [10, 20, 30]}}'
# Response: {"result": 60, "operation": "add"}The actor processes the request, updates its persistent state, and returns the result. If the node crashes and restarts, the framework replays the journal and restores the calculator’s state .
TypeScript: A Bank Account with Durable State
TypeScript brings type safety and rapid development. The PlexSpaces TypeScript SDK uses an inheritance-based pattern: extend PlexSpacesActor, implement on<Operation>() handlers, and the SDK wires everything to WIT.
The Actor Code
// account_actor.ts
import { PlexSpacesActor } from "@plexspaces/sdk";
interface Transaction {
type: string;
amount: number;
balance_after: number;
}
interface BankAccountState {
account_id: string;
balance: number;
transactions: Transaction[];
}
export class BankAccountActor extends PlexSpacesActor<BankAccountState> {
getDefaultState(): BankAccountState {
return { account_id: "", balance: 0, transactions: [] };
}
protected override onInit(config: Record<string, unknown>): void {
this.state.account_id = String(config.account_id ?? "");
this.state.balance = 0;
this.state.transactions = [];
}
onDeposit(payload: Record<string, unknown>): Record<string, unknown> {
const amount = Number(payload.amount ?? 0);
if (amount <= 0) return { error: "invalid_amount" };
this.state.balance += amount;
this.state.transactions.push({
type: "deposit", amount, balance_after: this.state.balance,
});
return { status: "ok", balance: this.state.balance };
}
onWithdraw(payload: Record<string, unknown>): Record<string, unknown> {
const amount = Number(payload.amount ?? 0);
if (amount <= 0) return { error: "invalid_amount" };
if (amount > this.state.balance) {
return { error: "insufficient_funds", balance: this.state.balance };
}
this.state.balance -= amount;
this.state.transactions.push({
type: "withdraw", amount, balance_after: this.state.balance,
});
return { status: "ok", balance: this.state.balance };
}
onHistory(payload: Record<string, unknown>): Record<string, unknown> {
const count = Math.min(
Number(payload.count ?? 5), this.state.transactions.length
);
return { transactions: this.state.transactions.slice(-count) };
}
onReplay(): Record<string, unknown> {
let rebuilt = 0;
for (const tx of this.state.transactions) {
if (tx.type === "deposit") rebuilt += tx.amount;
else if (tx.type === "withdraw") rebuilt -= tx.amount;
}
return {
replayed: this.state.transactions.length,
rebuilt_balance: rebuilt,
current_balance: this.state.balance,
};
}
}
// WIT actor export -- bridges TypeScript class to the WIT interface
const instance = new BankAccountActor();
export const actor = {
init: (c: string) => instance.init(c),
handle: (from: string, msg: string, payload: string) =>
instance.handle(from, msg, payload),
getState: () => instance.getState(),
setState: (s: string) => instance.setState(s),
};The BankAccountActor manages deposits, withdrawals, and transaction history with full durability. The onReplay() handler rebuilds the balance from the transaction log, demonstrating event-sourcing patterns that the framework makes trivial.
Build and Deploy
The TypeScript build uses a three-step pipeline: compile TypeScript, bundle with esbuild, then create a WASM component with jco:
# Install dependencies (SDK is a file: dependency)
npm install
# Compile TypeScript -> JavaScript -> ESM bundle -> WASM component
npm run build # tsc + esbuild bundle
jco componentize actor_bundle.mjs \
--wit wit/plexspaces-simple-actor \
-o account_actor.wasm \
--disable all
# Deploy to PlexSpaces
curl -X POST http://localhost:8001/api/v1/applications/deploy \
-F "application_id=bank-app" \
-F "name=bank-account" \
-F "version=1.0.0" \
-F "wasm_file=@account_actor.wasm"Interact with the Accounts
# Deposit into Alice's account
curl -X POST http://localhost:8001/api/v1/actors/account-alice/ask \
-H "Content-Type: application/json" \
-d '{"message_type": "deposit", "payload": {"amount": 1000}}'
# Response: {"status": "ok", "balance": 1000}
# Withdraw from Alice's account
curl -X POST http://localhost:8001/api/v1/actors/account-alice/ask \
-H "Content-Type: application/json" \
-d '{"message_type": "withdraw", "payload": {"amount": 250}}'
# Response: {"status": "ok", "balance": 750}
# Check transaction history
curl -X POST http://localhost:8001/api/v1/actors/account-alice/ask \
-H "Content-Type: application/json" \
-d '{"message_type": "history", "payload": {"count": 10}}'Go: An Erlang OTP-Style Rate Limiter
Go delivers a pragmatic balance between performance and developer productivity. The PlexSpaces Go SDK uses an interface-based pattern: implement the Actor interface, embed BaseActor for automatic state serialization, and register your actor for WASM export via plexspaces.Register().
The Actor Code
This example implements a sliding-window rate limiter, the kind you find inside API gateways like NGINX, Kong, or Envoy. Each client gets an independent window with configurable limits:
// rate_limiter.go
package main
import (
"encoding/json"
"fmt"
"github.com/plexobject/plexspaces/sdks/go/plexspaces"
)
type SlidingWindowLimiter struct {
plexspaces.BaseActor
WindowSizeMs uint64 `json:"window_size_ms"`
MaxRequests int `json:"max_requests"`
Clients map[string]*ClientWindow `json:"clients"`
TotalChecks int `json:"total_checks"`
TotalAllowed int `json:"total_allowed"`
TotalDenied int `json:"total_denied"`
}
type ClientWindow struct {
Timestamps []uint64 `json:"timestamps"`
Allowed int `json:"allowed"`
Denied int `json:"denied"`
}
var host = plexspaces.NewHost()
func NewSlidingWindowLimiter() *SlidingWindowLimiter {
a := &SlidingWindowLimiter{
WindowSizeMs: 60000,
MaxRequests: 100,
Clients: make(map[string]*ClientWindow),
}
a.SetSelf(a) // enables automatic JSON state serialization
return a
}
func (s *SlidingWindowLimiter) Init(configJSON string) string {
var config struct {
ActorID string `json:"actor_id"`
Args map[string]any `json:"args"`
}
json.Unmarshal([]byte(configJSON), &config)
if args := config.Args; args != nil {
if v, ok := args["window_size_ms"]; ok {
s.WindowSizeMs = uint64(v.(float64))
}
if v, ok := args["max_requests"]; ok {
s.MaxRequests = int(v.(float64))
}
}
host.Info(fmt.Sprintf("RateLimiter: window=%dms, max=%d req/window",
s.WindowSizeMs, s.MaxRequests))
return ""
}
func (s *SlidingWindowLimiter) Handle(from, msgType, payloadJSON string) string {
switch msgType {
case "check_rate":
return s.checkRate(payloadJSON)
case "stats":
return s.getStats()
default:
data, _ := json.Marshal(map[string]any{"error": "unknown: " + msgType})
return string(data)
}
}
func (s *SlidingWindowLimiter) checkRate(payloadJSON string) string {
var req struct { ClientID string `json:"client_id"` }
json.Unmarshal([]byte(payloadJSON), &req)
window, exists := s.Clients[req.ClientID]
if !exists {
window = &ClientWindow{Timestamps: make([]uint64, 0)}
s.Clients[req.ClientID] = window
}
now := host.NowMs()
cutoff := now - s.WindowSizeMs
// Slide the window: remove expired timestamps
var active []uint64
for _, ts := range window.Timestamps {
if ts > cutoff { active = append(active, ts) }
}
window.Timestamps = active
// Check the limit
allowed := len(window.Timestamps) < s.MaxRequests
if allowed {
window.Timestamps = append(window.Timestamps, now)
window.Allowed++; s.TotalAllowed++
} else {
window.Denied++; s.TotalDenied++
}
s.TotalChecks++
remaining := s.MaxRequests - len(window.Timestamps)
if remaining < 0 { remaining = 0 }
data, _ := json.Marshal(map[string]any{
"allowed": allowed, "remaining": remaining,
"limit": s.MaxRequests, "client_id": req.ClientID,
})
return string(data)
}
// Register the actor for WASM export -- runs during _initialize,
// before the host calls any exported functions.
func init() {
plexspaces.Register(NewSlidingWindowLimiter())
}
func main() {}The Go SDK pattern uses plexspaces.NewHost() to access all host functions (messaging, KV, tuple space, etc.) and plexspaces.Register() in the init() function to wire the actor to the WASM export interface. The comparison to Erlang/OTP maps directly:
| Erlang/OTP | PlexSpaces Go |
|---|---|
gen_server:start_link/3 | Supervisor in app-config.toml |
handle_call/3 | Handle(from, msgType, payload) |
#state{} record | Go struct with JSON tags |
gen_server:call(Pid, Msg) | host.Ask(actorID, msgType, data) |
application:start/2 | app-config.toml |
Build and Deploy
The Go build uses a three-step TinyGo pipeline: compile to core WASM, embed WIT metadata, then create a WASM component with a WASI adapter:
# Step 1: Compile Go to core WASM
tinygo build -target=wasi -o rate_limiter_core.wasm .
# Step 2: Embed WIT metadata
wasm-tools component embed wit/plexspaces-simple-actor \
-w actor-world rate_limiter_core.wasm -o rate_limiter_embed.wasm
# Step 3: Create WASM component with WASI adapter
wasm-tools component new rate_limiter_embed.wasm \
--adapt wasi_snapshot_preview1.reactor.wasm \
-o rate_limiter.wasm
# Deploy
curl -X POST http://localhost:8001/api/v1/applications/deploy \
-F "application_id=rate-limiter-app" \
-F "name=rate-limiter" \
-F "version=1.0.0" \
-F "wasm_file=@rate_limiter.wasm"Each Go example includes a build.sh script that automates this pipeline and resolves the WASI adapter automatically.
Test Rate Limiting
# Check if a client request is allowed
curl -X POST http://localhost:8001/api/v1/actors/rate-limiter/ask \
-H "Content-Type: application/json" \
-d '{"message_type": "check_rate", "payload": {"client_id": "api-client-1"}}'
# Response: {"allowed": true, "remaining": 99, "limit": 100, "client_id": "api-client-1"}
# After 100 requests within the window:
# Response: {"allowed": false, "remaining": 0, "limit": 100, "client_id": "api-client-1"}Rust: A Calculator with Maximum Performance
Rust produces the smallest, fastest WASM binaries. When you need every microsecond like high-frequency trading, real-time event processing, computational pipelines. Rust actors deliver near-native performance with binary sizes under 1MB.
The Actor Code
This calculator uses #![no_std] to eliminate the standard library entirely, producing a tiny, self-contained WASM module:
// lib.rs
#![no_std]
extern crate alloc;
use alloc::vec::Vec;
use core::slice;
use serde::{Deserialize, Serialize};
#[derive(Debug, Clone, Serialize, Deserialize)]
#[serde(rename_all = "PascalCase")]
pub enum Operation { Add, Subtract, Multiply, Divide }
#[derive(Debug, Clone, Serialize, Deserialize)]
pub struct CalculatorState {
calculation_count: u64,
last_result: Option<f64>,
}
#[derive(Debug, Clone, Serialize, Deserialize)]
pub struct CalculationRequest {
operation: Operation,
operands: Vec<f64>,
}
static mut STATE: CalculatorState = CalculatorState {
calculation_count: 0, last_result: None,
};
/// Initialize actor with optional persisted state
#[no_mangle]
pub extern "C" fn init(state_ptr: *const u8, state_len: usize) -> i32 {
unsafe {
if state_len == 0 {
STATE = CalculatorState { calculation_count: 0, last_result: None };
return 0;
}
let state_bytes = slice::from_raw_parts(state_ptr, state_len);
match serde_json::from_slice::<CalculatorState>(state_bytes) {
Ok(state) => { STATE = state; 0 }
Err(_) => -1,
}
}
}
/// Handle incoming calculation requests
#[no_mangle]
pub extern "C" fn handle_message(
_from_ptr: *const u8, _from_len: usize,
type_ptr: *const u8, type_len: usize,
payload_ptr: *const u8, payload_len: usize,
) -> *const u8 {
unsafe {
let msg_type = core::str::from_utf8(
slice::from_raw_parts(type_ptr, type_len)
).unwrap_or("");
match msg_type {
"calculate" => {
let payload = slice::from_raw_parts(payload_ptr, payload_len);
if let Ok(req) = serde_json::from_slice::<CalculationRequest>(payload) {
if let Ok(result) = execute(&req) {
STATE.calculation_count += 1;
STATE.last_result = Some(result);
}
}
core::ptr::null()
}
_ => core::ptr::null(),
}
}
}
fn execute(req: &CalculationRequest) -> Result<f64, &'static str> {
let (a, b) = (req.operands[0], req.operands[1]);
match req.operation {
Operation::Add => Ok(a + b),
Operation::Subtract => Ok(a - b),
Operation::Multiply => Ok(a * b),
Operation::Divide => {
if b == 0.0 { Err("Division by zero") } else { Ok(a / b) }
}
}
}Build and Deploy
rustup target add wasm32-wasip2
cargo build --target wasm32-wasip2 --release
# Optimize the binary further
wasm-opt -Oz --strip-debug \
target/wasm32-wasip2/release/calculator_wasm_actor.wasm \
-o calculator_actor.wasm
# Deploy
curl -X POST http://localhost:8001/api/v1/applications/deploy \
-F "application_id=rust-calc" \
-F "name=calculator" \
-F "version=1.0.0" \
-F "wasm_file=@calculator_actor.wasm"The resulting binary? Under 200KB. Compare that to a Python actor at 30-40MB or even a TypeScript actor at 1-2MB. When you deploy hundreds of actors per node, those size differences translate directly into memory savings and faster cold starts.
Deploying Applications
One of the patterns I find most compelling that I feel the serverless world has completely neglected is the idea of deploying whole applications, not just individual functions. If you have used Tomcat or JBoss, you understand what I mean. You package your application, hand it to the server, and the server takes care of running it, managing the process lifecycle, enforcing security policies, routing requests, collecting metrics, and handling restarts. You focus on business logic; the server handles the infrastructure cross-cuts. PlexSpaces brings this same model to WASM actors, but with Erlang/OTP’s supervision philosophy underneath. I call this the PlexSpaces Application Server model.
The Application Manifest
Instead of deploying actors one by one via API calls, you define an application bundle — a single manifest that describes your entire application topology: which actors to run, how they supervise each other, what resources they need, and what security policies apply to them.
[supervisor] strategy = "one_for_one" max_restarts = 10 max_restart_window_seconds = 60 # ChatRoom actor (Durable Object: one per room) [[supervisor.children]] id = "chat-room" type = "worker" restart = "permanent" shutdown_timeout_seconds = 10 [supervisor.children.args] max_history = "100" # RateLimiter actor (Durable Object: per-user rate limiting) [[supervisor.children]] id = "rate-limiter" type = "worker" restart = "permanent" shutdown_timeout_seconds = 5 [supervisor.children.args] max_tokens = "5" refill_rate_ms = "1000"
The runtime validates every WASM module against its declared WIT world, starts the supervision tree from the root down, and begins enforcing all security and resource policies — before your first actor processes its first message. PlexSpaces takes care of most cross cutting concerns like auth token validation, rate limiting, structured logging, trace context propagation, circuit breakers so that you can focus on the business logic.
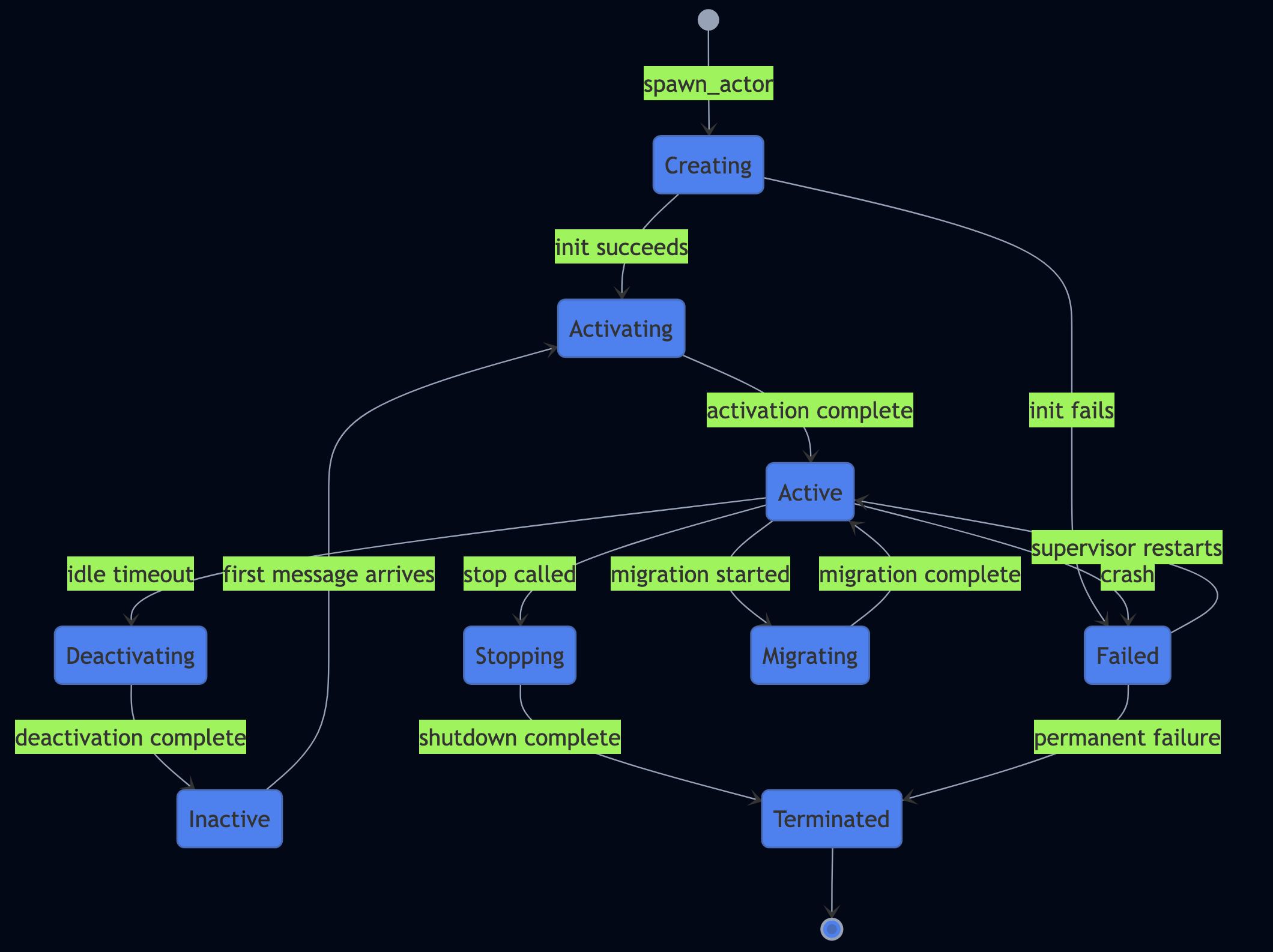
Supervision and restarts. The manifest’s supervision tree is live. If actor crashes, the supervisor restarts it according to the declared strategy. If it exceeds max_restarts within max_restart_window_seconds, the supervisor escalates to its parent. This is exactly how Erlang/OTP gen_server supervision works.
Comparing Deployment Models
| Capability | Traditional Microservices | AWS Lambda | PlexSpaces App Server |
|---|---|---|---|
| Deployment unit | Container image per service | Function zip per Lambda | Single .psa bundle for entire app |
| Supervision | Kubernetes restarts pods | None | Erlang-style supervision tree |
| Auth enforcement | API gateway / middleware | Custom authorizers | Runtime-level, declarative in manifest |
| Observability | Manual instrumentation | CloudWatch + X-Ray | Auto-instrumented, zero actor code |
| Resource limits | Container CPU/mem requests | Timeout + memory settings | Per-actor WASM-level enforcement |
| Multi-language | Per-container runtimes | Per-function runtimes | All actors in one WASM runtime |
| State | External (Redis/DB) | External | Built-in durable actor state |
| Cold start | Seconds | 100ms–10s | ~50?s (WASM) |
FaaS and Serverless
Here is where PlexSpaces bridges the worlds of actor systems and serverless platforms. Every actor you deploy in any language doubles as a serverless function that you invoke over plain HTTP. No client SDK required. No message queue setup. Just HTTP.
HTTP Invocation Model
PlexSpaces exposes a FaaS-style API that routes HTTP requests to actors using a simple URL pattern:
/api/v1/actors/{tenant}/{namespace}/{actor_type}The HTTP method determines the invocation pattern:
| HTTP Method | Pattern | Behavior |
|---|---|---|
| GET | Request-reply (ask) | Sends query params as payload, waits for response |
| POST | Unicast message (tell) | Sends JSON body, returns immediately |
| PUT | Unicast message (tell) | Same as POST, for update semantics |
| DELETE | Request-reply (ask) | Sends query params, waits for confirmation |
FaaS in Action
This Rust example shows a FaaS-style webhook handler that receives HTTP POST payloads and stores delivery history — the kind of thing you would build on AWS Lambda or Cloudflare Workers, but here using PlexSpaces SDK annotations:
// Using PlexSpaces Rust SDK annotations (like Python @actor, @handler)
#[gen_server_actor]
struct WebhookHandler {
deliveries: Vec<WebhookDelivery>,
total_received: u64,
}
#[plexspaces_handlers]
impl WebhookHandler {
#[handler("deliver")]
async fn deliver(&mut self, ctx: &ActorContext, msg: &Message)
-> Result<Value, BehaviorError>
{
let delivery = WebhookDelivery::new(
ulid::Ulid::new().to_string(), &msg.payload,
);
self.deliveries.push(delivery);
self.total_received += 1;
Ok(json!({ "status": "received", "total": self.total_received }))
}
#[handler("list")]
async fn list_deliveries(&self, _ctx: &ActorContext, _msg: &Message)
-> Result<Value, BehaviorError>
{
Ok(json!({ "deliveries": self.deliveries, "total": self.total_received }))
}
}Invoke this actor over HTTP — no SDK, no message queue, just curl:
# POST a webhook delivery (fire-and-forget)
curl -X POST http://localhost:8001/api/v1/actors/acme-corp/webhooks/webhook_handler \
-H "Content-Type: application/json" \
-d '{"event": "order.completed", "order_id": "ORD-12345"}'
# GET recent deliveries (request-reply)
curl "http://localhost:8001/api/v1/actors/acme-corp/webhooks/webhook_handler?action=list"Multi-Tenant Isolation
The URL path embeds tenant and namespace for built-in multi-tenant isolation. Tenant acme-corp cannot access tenant globex-inc‘s actors. The framework enforces this boundary at the routing layer with JWT-based authentication:
# Tenant A's rate limiter
curl -X POST http://localhost:8001/api/v1/actors/acme-corp/api/rate-limiter \
-d '{"client_id": "user-123"}'
# Tenant B's rate limiter -- completely isolated state
curl -X POST http://localhost:8001/api/v1/actors/globex-inc/api/rate-limiter \
-d '{"client_id": "user-456"}'How PlexSpaces Compares to Traditional FaaS
The critical difference: PlexSpaces actors retain state between invocations. Traditional FaaS platforms treat functions as stateless — you manage state externally in DynamoDB, Redis, or S3. PlexSpaces actors carry durable state inside the actor, persisted via journaling and checkpointing. This eliminates the “stateless function + external state store” tax that adds latency and complexity to every serverless application.
| Capability | AWS Lambda | Cloudflare Workers | PlexSpaces FaaS |
|---|---|---|---|
| Cold start | 100ms-10s | ~5ms | ~50us (WASM) |
| State | External (DynamoDB) | External (KV/D1) | Built-in (durable actors) |
| Polyglot | Per-runtime images | JS/WASM only | Rust, Go, TS, Python on same runtime |
| Coordination | SQS/Step Functions | Durable Objects | TupleSpace, process groups, workflows |
| Supervision | None | None | Erlang-style supervision trees |
| Isolation | Container/Firecracker | V8 isolates | WASM sandbox + optional Firecracker |
PlexSpaces includes migration examples that show how to port existing Lambda functions, Step Functions workflows, Azure Durable Functions, Cloudflare Workers, and Orleans grains (See examples).
What WebAssembly Gives You
Let me address the obvious question: “Why not just use Docker?” Containers solve many problems well. But as Solomon Hykes, Docker’s creator, said in 2019 when WASI was first announced:
“If WASM+WASI existed in 2008, we wouldn’t have needed to create Docker. That’s how important it is. WebAssembly on the server is the future of computing. A standardized system interface was the missing link. Let’s hope WASI is up to the task!” — Solomon Hykes, March 2019
WebAssembly solves some problems better:
- Startup time. A WASM module instantiates in microseconds. A container takes seconds. When you auto-scale actors in response to load spikes, microsecond cold starts mean your users never notice.
- Memory footprint. A Rust WASM actor uses ~200KB. The equivalent Docker container starts at 50MB minimum (Alpine base image alone). On a single node, you run thousands of WASM actors where you might run dozens of containers.
- Security isolation. WASM sandboxing is capability-based. A module cannot access the filesystem, network, or memory outside its sandbox unless the host explicitly grants each capability through WASI. Containers share a kernel and rely on namespace isolation — a fundamentally larger attack surface.
- True polyglot. With containers, each language gets its own image, runtime, dependency tree, and deployment pipeline. With WASM, all languages produce the same artifact type, run on the same runtime, and share the same deployment pipeline.
- Composability. The Component Model lets you link WASM modules from different languages into a single process. No network calls. No serialization overhead. Direct function invocation across language boundaries. Try that with Docker.
PlexSpaces actually supports both: WASM sandboxing for lightweight actors and Firecracker microVMs for workloads that need full hardware-level isolation. You pick the isolation model per workload, and the framework handles the rest.
Where This Is Heading
The WASM Ecosystem Roadmap
The ecosystem moves fast. Here are the milestones that matter:
- Wasm 3.0 became the W3C standard in September 2025, standardizing nine production features including WasmGC, exception handling, tail calls, and SIMD
- WASI 0.3 shipped in February 2026 with native async support — actors can now handle concurrent I/O without blocking
- WASI 1.0 is on track for late 2026 or early 2027, providing the stability guarantees that enterprise adopters require
- Wasmtime leads the runtime ecosystem with full Component Model and WASI 0.2 support
- Wasmer 6.0 achieved ~95% of native speed on benchmarks
- Docker now runs WASM components alongside containers in Docker Desktop and Docker Engine
The FaaS-Actor Convergence
The most consequential trend is the convergence of serverless FaaS platforms and stateful actor systems. Today these exist as separate categories — AWS Lambda handles stateless functions, Temporal handles durable workflows, Orleans handles virtual actors, and Erlang/OTP handles fault-tolerant supervision. PlexSpaces unifies them into a single abstraction. This convergence accelerates along three axes:
- HTTP-native invocation. Every PlexSpaces actor is already a serverless function, callable over HTTP with automatic routing, multi-tenant isolation, and load balancing. As the WASM ecosystem matures, the cold start advantage (microseconds vs. seconds) makes WASM actors a compelling replacement for traditional Lambda functions, especially at the edge.
- Durable serverless. Traditional FaaS treats functions as stateless. PlexSpaces combines serverless invocation with durable execution — actors retain state, the framework journals every message, and crash recovery replays the journal to restore exact state. This eliminates the “Lambda + DynamoDB + Step Functions” stack that every non-trivial serverless application ends up building.
- Edge-native polyglot. WASM runs everywhere like cloud servers, edge nodes, IoT devices, even browsers. PlexSpaces actors compiled to WASM deploy to any environment that runs wasmtime. A Python ML model runs at the edge. A Rust event processor runs in the cloud. A TypeScript API actor runs in the CDN. All three communicate through the same framework, sharing state through tuple spaces and coordinating through process groups.
Get Started
PlexSpaces is open source. Clone the repository and start building:
git clone https://github.com/bhatti/PlexSpaces.git
cd PlexSpaces
# Quick setup (installs tools, builds, tests)
./scripts/setup.sh
# Or use Docker for the fastest path
docker pull plexobject/plexspaces:latest
docker run -d -p 8000:8000 -p 8001:8001 \
-e PLEXSPACES_NODE_ID=node1 \
plexobject/plexspaces:latest
# Explore the examples
ls examples/python/apps/ # calculator, bank_account, chat_room, nbody, ...
ls examples/typescript/apps/ # bank_account, migrating_cloudflare_workers, migrating_orleans
ls examples/go/apps/ # migrating_erlang_otp, migrating_cloudflare_workers, ...
ls examples/rust/apps/ # calculator, nbody, session_manager, ...
# Build and test everything
make allEach example includes its own app-config.toml, build.sh script, and test instructions. The examples/ directory also contains migration guides from 24+ frameworks like Erlang/OTP, Temporal, Ray, Cloudflare Workers, Orleans, Restate, Azure Durable Functions, AWS Step Functions, wasmCloud, Dapr, and more.
I spent decades wrestling with the same distributed systems problems under different names on different stacks (see my previous blog). Fault tolerance, state management, multi-language support, coordination, serverless invocation, scaling. These problems never change, only the acronyms do. WebAssembly makes the polyglot piece real. The Component Model makes it composable. The application server model makes it deployable in a way that finally lets you focus on what you actually came to write: business logic.
PlexSpaces is available at github.com/bhatti/PlexSpaces. Give it a try and let me know what you think.