As businesses grow with larger customers size and hire more employees, they face challenges to meet the customer demands in terms of scaling their systems and maintaining rapid product development with bigger teams. The businesses aim to scale systems linearly with additional computing and human resources. However, systems architecture such as monolithic or ball of mud makes scaling systems linearly onerous. Similarly, teams become less efficient as they grow their size and become silos. A general solution to solve scaling business or technical problems is to use divide & conquer and partition it into multiple sub-problems. A number of factors affect scalability of software architecture and organizations such as the interactions among system components or communication between teams. For example, the coordination, communication and data/knowledge coherence among the system components and teams become disproportionately expensive with the growth in size. The software systems and business management have developed a number of laws and principles that can used to evaluate constraints and trade offs related to the scalability challenges. Following is a list of a few laws from the technology and business domain for scaling software architectures and business organizations:
Amdhal’s Law
Amdahl’s Law is named after Gene Amdahl that is used to predict speed up of a task execution time when it’s scaled to run on multiple processors. It simply states that the maximum speed up will be limited by the serial fraction of the task execution as it will create resource contention:
Speed up (P, N) = 1 / [ (1 - P) + P / N ]
Where P is the fraction of task that can run in parallel on N processors. When N becomes large, P / N approaches 0 so speed up is restricted to 1 / (1 – P) where the serial fraction (1 – P) becomes a source of contention due to data coherence, state synchronization, memory access, I/O or other shared resources.
Amdahl’s law can also be described in terms of throughput using:
N / [ 1 + a (N - 1) ]
Where a is the serial fraction between 0 and 1. In parallel computing, a class of problems known as embarrassingly parallel workload where the parallel tasks have a little or no dependency among tasks so their value for a will be 0 because they don’t require any inter-task communication overhead.
Amdah’s law can be used to scale teams as an organization grows where the teams can be organized as small and cross-functional groups to parallelize the feature work for different product lines or business domains, however the maximum speed up will still be limited by the serial fraction of the work. The serial work can be: build and deployment pipelines; reviewing and merging changes; communication and coordination between teams; and dependencies for deliverables from other teams. Fred Brooks described in his book The Mythical Man-Month how adding people to a highly divisible task can reduce overall task duration but other tasks are not so easily divisible: while it takes one woman nine months to make one baby, “nine women can’t make a baby in one month”.
The theoretical speedup of the latency of the execution of a program according to Amdahl’s law (credit wikipedia).
Brooks’s Law
Brooks’s law was coined by Fred Brooks that states that adding manpower to a late software project makes it later due to ramp up time. As the size of team increases, the ramp up time for new employees also increases due to quadratic communication overhead among team members, e.g.
Number of communication channels = N x (N - 1) / 2
The challenge with adding more engineers to a project. Just moving from 3 developers to 4 doubles the number of lines of communication. pic.twitter.com/TkI2NcHVT2
The organizations can build small teams such as two-pizza/single-threaded teams where communication channels within each team does not explode and the cross-functional nature of the teams require less communication and dependencies from other teams. The Brook’s law can be equally applied to technology when designing distributed services or components so that each service is designed as a loosely coupled module around a business domain to minimize communication with other services and services only communicate using a well designed interfaces.
Universal Scalability Law
The Universal Scalability Law is used for capacity planning and was derived from Amdahl’s law by Dr. Neil Gunther. It describes relative capacity in terms of concurrency, contention and coherency:
C(N) = N / [1 + a(N – 1) + B.N (N – 1) ]
Where C(N) is the relative capacity, a is the serial fraction between 0 and 1 due to resource contention and B is delay for data coherency or consistency. As data coherency (B) is quadratic in N so it becomes more expensive as size of N increases, e.g. using a consensus algorithm such as Paxos is impractical to reach state consistency among large set of servers because it requires additional communication between all servers. Instead, large scale distributed storage services generally use sharding/partitioning and gossip protocol with a leader-based consensus algorithm to minimize peer to peer communication.
The Universal Scalability Law can be applied to scale teams similar to Amdahl’s law where a is modeled for serial work or dependency between teams and B is modeled for communication and consistent understanding among the team members. The cost of B can be minimized by building cross-functional small teams so that teams can make progress independently. You can also apply this model for any decision making progress by keeping the size of stake holders or decision makers small so that they can easily reach the agreement without grinding to halt.
The gossip protocols also applies to people and it can be used along with a writing culture, lunch & learn and osmotic communication to spread knowledge and learnings from one team to other teams.
Where L is the average number of items within the system or queue, A is the average arrival time of items and W is the average time an item spends in the system. The Little’s law and queuing theory can be used for capacity planning for computing servers and minimizing waiting time in the queue (L).
The Little’s law can be applied for predicting task completion rate in an agile process where L represents work-in-progress (WIP) for a sprint; A represents arrival and departure rate or throughput/capacity of tasks; W represents lead-time or an average amount of time in the system.
WIP = Throughput x Lead-Time
Lead-Time = WIP / Throughput
You can use this relationship to reduce the work in progress or lead time and improve throughput of tasks completion. Little’s law observes that you can accomplish more by keeping work-in-progress or inventory small. You will be able to better respond to unpredictable delays if you keep a buffer in your capacity and avoid 100% utilization.
King’s formula
The King’s formula expands Little’s law by adding utilization and variability for predicting wait time before serving of requests:
(credit wikipedia)
where T is the mean service time, m (1/T) is the service rate, A is the mean arrival rate, p = A/m is the utilization, ca is the coefficient of variation for arrivals and cs is the coefficient of variation for service times. The King’s formula shows that the queue sizes increases to infinity as you reach 100% utilization and you will have longer queues with greater variability of work. These insights can be applied to both technical and business processes so that you can build systems with a greater predictability of processing time, smaller wait time E(W) and higher throughput ?.
Note: See Erlang analysis for serving requests in a system without a queue where new requests are blocked or rejected if there is not sufficient capacity in the system.
Gustafson’s Law
Gustafson’s law improves Amdahl’s law with a keen observation that parallel computing enables solving larger problems by computations on very large data sets in a fixed amount of time. It is defined as:
S = s + p x N
S = (1 – s) x N
S = N + (1 – N) x s
where S is the theoretical speed up with parallelism, N is the number of processors, s is the serial fraction and p is the parallel part such that s + p = 1.
Gustafson’s law shows that limitations imposed by the sequential fraction of a program may be countered by increasing the total amount of computation. This allows solving bigger technical and business problems with a greater computing and human resources.
Conway’s Law
Conway’s law states that an organization that designs a system will produce a design whose structure is a copy of the organization’s communication structure. It means that the architecture of a system is derived from the team structures of an organization, however you can also use the architecture to derive the team structures. This allows defining building teams along the architecture boundaries so that each team is a small, cross functional and cohesive. A study by the Harvard Business School found that the often large co-located teams tended to produce more tightly-coupled and monolithic codebases whereas small distributed teams produce more modular codebases. These lessons can be applied to scaling teams and architecture so that teams and system modules are built around organizational boundaries and independent concerns to promote autonomy and reduce tight coupling.
Pareto Principle
The Pareto principle states that for many outcomes, roughly 80% of consequences come from 20% of causes. This principle shows up in numerous technical and business problems such as 20% of code has the 80% of errors; customers use 20% of functionality 80% of the time; 80% of optimization improvements comes from 20% of the effort, etc. It can also be used to identify hotspots or critical paths when scaling, as some microservices or teams may receive disproportionate demands. Though, scaling computing resources is relatively easy but scaling a team beyond an organization boundary is hard. You will have to apply other management tools such as prioritization, planning, metrics, automation and better communication to manage critical work.
Number of possible pair connections = N * (N – 1) / 2
Reed’s Law expanded this law and observed that the utility of large networks can scale exponentially with the size of the network.
Number of possible subgroups of a network = 2N – N – 1
This law explains the popularity of social networking services via viral communication. These laws can be applied to model information flow between teams or message exchange between services to avoid peer to peer communication with extremely large group of people or a set of nodes. A common alternative is to use a gossip protocol or designate a partition leader for each group that communicates with other leaders and then disseminate information to the group internally.
Dunbar Number
The Dunbar’s number is a suggested cognitive limit to the number of people with whom one can maintain stable social relationships. It has a commonly used value of 150 and can be used to limit direct communication connections within an organization.
Wirth’s Law and Parkinson’s Law
The Wirth’s Law is named after Niklaus Wirth who observed that the software is getting slower more rapidly than hardware is becoming faster. Over the last few decades, processors have become exponentially faster as a Moor’s Law but often that gain allows software developers to develop more complex software that consumes all gains of the speed. Another factor is that it allows software developers to use languages and tools that may not generate more efficient code so the code becomes bloated. There is a similar law in software development called Parkinson’s law that work expands to fill the time available for it. Though, you also have to watch for Hofstadter’s Law that states that “it always takes longer than you expect, even when you take into account Hofstadter’s Law”; and Brook’s Law, which states that “adding manpower to a late software project makes it later.”
The Wirth’s Law, named after Niklaus Wirth, posits that software tends to become slower at a rate that outpaces the speed at which hardware becomes faster. This observation reflects a trend where, despite significant advancements in processor speeds as predicted by Moor’s Law , software complexity increases correspondingly. Developers often leverage these hardware improvements to create more intricate and feature-rich software, which can negate the hardware gains. Additionally, the use of programming languages and tools that do not prioritize efficiency can lead to bloated code.
In the realm of software development, there are similar principles, such as Parkinson’s law, which suggests that work expands to fill the time allotted for its completion. This implies that given more time, software projects may become more complex or extended than initially necessary. Moreover, Hofstadter’s Law offers a cautionary perspective, stating, “It always takes longer than you expect, even when you take into account Hofstadter’s Law.” This highlights the often-unexpected delays in software development timelines. Brook’s Law further adds to these insights with the adage, “Adding manpower to a late software project makes it later.” These laws collectively emphasize that the demand upon a resource tends to expand to match the supply of the resource but adding resources later also poses challenges due to complexity in software development and project management.
Principle of Priority Inversion
In modern operating systems, the concept of priority inversion arises when a high-priority process needs resources or data from a low-priority process, but the low-priority process never gets a chance to execute due to its lower priority. This creates a deadlock or inefficiency where the high-priority process is blocked indefinitely. To avoid this, schedulers in modern operating systems adjust the priority of the lower-priority process to ensure it can complete its task and release the necessary resources, allowing the high-priority process to continue.
This same principle applies to organizational dynamics when scaling teams and projects. Imagine a high-priority initiative that requires collaboration from another team whose priorities do not align. Without proper coordination, the team working on the high-priority initiative may never get the support they need, leading to delays or blockages. Just as in operating systems, where a priority adjustment is needed to keep processes running smoothly, organizations must also ensure alignment across teams by managing a global list of priorities. A solution is to maintain a global prioritized list of projects that is visible to all teams. This ensures that the most critical initiatives are recognized and appropriately supported by every team, regardless of their individual workloads. This centralized prioritization ensures that teams working on essential projects can quickly receive the help or resources they need, avoiding bottlenecks or deadlock-like situations where progress stalls because of misaligned priorities.
Load Balancing (Round Robin, Least Connection)
Load balancing algorithms distribute tasks across multiple servers to optimize resource utilization and prevent any single server from becoming overwhelmed. Common strategies include round-robin (distributing tasks evenly across servers) and least connection (directing new tasks to the server with the fewest active connections).
Load balancing can be applied to distribute work among teams or individuals. For instance, round-robin can ensure that tasks are equally assigned to team members, while the least-connection principle can help assign tasks to those with the lightest workload, ensuring no one is overloaded. This leads to more efficient task management, better resource allocation, and balanced work distribution.
MapReduce
MapReduce splits a large task into smaller sub-tasks (map step) that can be processed in parallel, then aggregates the results (reduce step) to provide the final output. In a large project, teams or individuals can be assigned sub-tasks that they can work on independently. Once all the sub-tasks are complete, the results can be aggregated to deliver the final outcome. This fosters parallelism, reduces bottlenecks, and allows for scalable team collaboration, especially for large or complex projects.
Deadlock Prevention (Banker’s Algorithm)
The Banker’s Algorithm is used to prevent deadlocks by allocating resources in such a way that there is always a safe sequence of executing processes, avoiding circular wait conditions. In managing interdependent teams or tasks, it’s important to avoid deadlocks where teams wait on each other indefinitely. By proactively ensuring that resources (e.g., knowledge, tools, approvals) are available before committing teams to work, project managers can prevent deadlock scenarios. Prioritizing resource allocation and anticipating dependencies can ensure steady progress without one team stalling another.
Consensus Algorithms (Paxos, Raft)
Consensus algorithms ensure that distributed systems agree on a single data value or decision, despite potential failures. Paxos and Raft are used to maintain consistency across distributed nodes. In projects involving multiple stakeholders or teams, reaching consensus on decisions can be challenging, especially with different priorities and viewpoints. Consensus-building techniques, inspired by these algorithms, could involve ensuring that key stakeholders agree before any significant action is taken, much like how Paxos ensures agreement across distributed systems. This avoids misalignment and fosters collaboration and trust across teams.
Rate Limiting
Rate limiting controls the number of requests or operations that can be performed in a given timeframe to prevent overloading a system. This concept applies to managing expectations, particularly in teams with multiple incoming requests. Rate limiting can be applied to protect teams from being overwhelmed by too many requests at once. By limiting how many tasks or requests a team can handle at a time, project managers can ensure a sustainable work pace and prevent burnout, much like how rate limiting helps protect system stability.
Summary
Above laws offer strategies for optimizing both technical systems and team dynamics. Amdahl’s Law and the Universal Scalability Law highlight the challenges of parallelizing work, emphasizing the need to manage coordination and communication overhead as bottlenecks when scaling teams or systems. Brook’s and Metcalfe’s Laws reveal the exponential growth of communication paths, suggesting that effective team scaling requires managing these paths to avoid coordination paralysis. Little’s Law and Kingman’s Formula suggest limiting work in progress and preventing 100% resource utilization to ensure reliable throughput, while Conway’s Law underscores the alignment between team structures and system architecture. Teams and their responsibilities should mirror modular architectures, fostering autonomy and reducing cross-team dependencies.
The Pareto Principle can guide teams to make small but impactful changes in architecture or processes that yield significant productivity improvements. Wirth’s Law and Parkinson’s Law serve as reminders to prevent work bloat and unnecessary complexity by setting clear deadlines and objectives. Dunbar’s Number highlights the human cognitive limit in maintaining external relationships, suggesting that team dependencies should be kept minimal to maintain effective collaboration. The consensus algorithms used in distributed systems can be applied to decision-making and collaboration, ensuring alignment among teams. Error correction algorithms are useful for feedback loops, helping teams iteratively improve. Similarly, techniques like load balancing strategies can optimize task distribution and workload management across teams.
Before applying these laws, it is essential to have clear goals, metrics, and KPIs to measure baselines and improvements. Prematurely implementing these scalability strategies can exacerbate issues rather than resolve them. The focus should be on global optimization of the entire organization or system, rather than focusing on local optimizations that don’t align with broader goals.
Software is eating the world and today’s businesses demand shipping software features at a higher velocity to enable learning at a greater pace without compromising the quality. However, each new feature increases viscosity of existing code, which can add more complexity and technical debt so the time to market for new features becomes longer. Managing a sustainable pace for software delivery requires continuous improvements to the software development architecture and practices.
Software Architecture
The Software Architecture defines guiding principles and structure of the software systems. It also includes quality attribute such as performance, sustainability, security, scalability, and resiliency. The software architecture is then continuously updated through iterative software development process and feedback cycle from the the actual use in production environment. The software architecture decays if it’s ignored that results in a higher complexity and technical debt. In order to reduce technical debt, you can build a backlog of technical and architecture related changes so that you can prioritize along with the product development. In order to maintain consistent architecture throughout your organization, you can document the architecture principles to define high-level guidelines for best practices, documentation templates, review process and guidance for the architecture decisions.
Quality Attributes
Following are major quality attributes of the software architecture:
Availability — It defines percentage of time, the system is available, e.g. available-for-use-time / total-time. It is generally referred in percentiles such as P99.99, which indicates a down time of 52 minutes in a year. It can also be calculated in terms of as mean-time between failure (MTBF) and mean-time to recover (MTRR) using MTBF/(MTBF+MTRR). The availability will depend not only on the service that you are providing but also its dependent services, e.g. P-service * P-dep-service-1 * P-dep-service-2. You can improve availability with redundant services, which can be calculated as Max-availability - (100 - Service-availability) ** Redundancy-factor. In order to further improve availability, you can detect faults and use redundancy and state synchronization for fault recovery. The system should also handle exceptions gracefully so that it doesn’t crash or goes into a bad state.
Capacity — Capacity defines how the system scales by adding hardware resources.
Extensibility — Extensibility defines how the system meets future business requirements without significantly changing existing design and code.
Fault Tolerance — Fault tolerance prevents a single point of failure and allows the system to continue operating even when parts of the system fail.
Maintainability — Higher quality code allows building robust software with higher stability and availability. This improves software delivery due to modular and loosely coupled design.
Performance — It is defined in terms of latency of an operation under normal or peak load. A performance may degrade with consumptions of resources, which affects throughput and scalability of the system. You can measure user’s response-time, throughput and utilization of computational resources by stress testing the system. A number of tactics can be used to improve performance such as prioritization, reducing overhead, rate-limiting, asynchronicity, caching, etc. Performance testing can be integrated with continuous delivery process that use load and stress testing to measure performance metrics and resource utilization.
Resilience — Resilience accepts the fact that faults and failure will occur so instead system components resist them by retrying, restarting, limiting error propagation or other measures. A failure is when a system deviates from its expected behavior as a result of accidental fault, misconfigurations, transient network issues or programming error. Two metrics related to resilience are mean-time between failure (MTBF) and mean-time to recover (MTTR), however resilient systems pay more attention to recovery or a shorter MTTR for fast recovery.
Recovery — Recovery looks at system recover in relation with availability and resilience. Two metrics related to recovery are recovery point objective (RPO) and recovery time objective (RTO), where RPO determines data that can be lost in case of failure and RTO defines wait time for the system recovery.
Reliability — Reliability looks at the probability of failure or failure rate.
Reproducibility — Reproducibility uses version control for code, infrastructure, configuration so that you can track and audit changes easily.
Reusability — It encourages code reuse to improve reliability, productivity and cost savings from the duplicated effort.
Scalability — It defines ability of the system to handle increase in workload without performance degradation. It can be expressed in terms of vertical or horizontal scalability, where horizontal reduces impact of isolated failure and improves workload availability. Cloud computing offers elastic and auto-scaling features for adding additional hardware when higher request rate is detected by the load balancer.
Security — Security primarily looks at confidentiality, integrity, availability (CIA) and is critical in building distributed systems. Building secure systems depends on security practices such as a strong identity management, defense in depth, zero trust networks, auditing, ad protecting while data in motion or at rest. You can adopt DevSecOps that shifts security left to earlier in software development lifecycle with processes such as Security by Design (SbD), STRIDE (Spoofing, Tampering, Repudiation, Disclosure, Denial of Service, Elevation of privilege), PASTA (Process for Attack Simulation and Threat Analysis), VAST (Visual, Agile and Simple Threat), CAPEC (Common Attack pattern Enumeration and Classification), and OCTAGE (Operationally Critical Threat, and Vulnerability Evaluation).
Testability — It encourages building systems in a such way it’s easier to test them.
Usability — It defines user experience of user interface and information architecture.
Architecture Patterns
Following is a list of architecture patterns that help building a high quality software:
Asynchronicity
Synchronous services are difficult to scale and recover from failures because they require low-latency and can easily overwhelm the services. Messaging-based asynchronous communication based on point-to-point or publish/subscribe are more suitable for handling faults or high load. This improves resilience because service components can restart in case of failure while messages remain in the queue.
Admission Control
The admission control adds a authentication, authorization or validation check in front event queue so that service can handle the load and prevent overload when demand exceeds the server capacity.
Back Pressure
When a producer is generating workload faster than the server can process, it can result in long request queues. Back pressure signals clients that servers are overloaded and clients need to slow down. However, rogue clients may ignore these signals so servers often employ other tactics such as admission control, load shedding, rate limiting or throttling requests.
Big fleet in front of small fleet
You should look at all transitive dependencies when scaling a service with a large fleet of hosts so that you don’t drive a large network traffic that needs to invoke dependent services with a smaller fleet. You can use use load testing to find the bottlenecks and update SLAs for the dependent services so that they are aware of network load from your APIs.
Blast Radius
A blast radius defines impact of failure on overall system when an error occurs. In order to limit the blast radius, the system should eliminate a single point of failure, rolling deploy changes using canaries and stop cascading failures using circuit breakers, retry and timeout.
Bulkheads
Bulkheads isolate faults from one component to another, e.g. you may use different thread pool for different workloads or use multiple regions/availability-zones to isolate failures in a specific datacenter.
Caching
Caching can be implemented at a several layers to improve performance such as database-cache, application-cache, proxy/edge cache, pre-compute cache and client-side cache.
Circuit Breakers
The circuit breaker is defined as a state machine with three states: normal, checking and tripped. It can be used to detect persistent failures in a dependent service and trip its state to disable invocation of the service temporarily with some default behavior. It can be later changed to the checking state for detecting success, which changes its state to normal after a successful invocation of the dependent service.
CQRS / Event Sourcing
Command and Query Responsibility Segregation (CQRS) separates read and update operations in the database. It’s often implemented using event-sourcing that records changes in an append-only store for maintaining consistency and audit trails.
Default Values
Default values provide a simple way to provide limited or degraded behavior in case of failure in dependent configuration or control service.
Disaster Recovery
Disaster recovery (DR) enables business continuity in the event of large-scale failure of data centers. Based on cost, availability and RTO/RPO constraints, you can deploy services to multiple regions for hot site; only replicate data from one region to another region while keeping servers as standby for warm site; or use backup/restore for cold site. It is essential to periodically test and verify these DR procedures and processes.
Distributed Saga
Maintaining data consistency in a distributed system where data is stored in multiple databases can be hard and using 2-phase-commit may incur high complexity and performance. You can use distributed Saga for implementing long-running transactions. It maintains state of the transaction and applies compensating transactions in case of a failure.
Failing Fast
You can fail fast if the workload cannot serve the request due to unavailability of resources or dependent services. In some cases, you can queue requests, however it’s best to keep those queues short so that you are not spending resources to serve stale requests.
Function as a Service
Function as a service (FaaS) offers serverless computing to simplify managing physical resources. Cloud vendors offer APIs for AWS Lambda, Google Cloud Functions and Azure Functions to build serverless applications for scalable workloads. These functions can be easily scaled to handle load spikes, however you have to be careful scaling these functions so that any services that they depend on can support the workload. Each function should be designed with a single responsibility, idempotency and shared nothing principles that can be executed concurrently. The serverless applications generally use event-based architecture for triggering functions and as the serverless functions are more granular, they incur more communication overhead. In addition, chaining functions within the code can result in tightly coupled applications, instead use a state machine or a workflow to orchestrate the communication flow. There is also an open source support for FaaS based serverless computing such as OpenFaas and OpenWhisk on top of Kubernetes or OpenShift, which prevents locking into a specific cloud provider.
Graceful Degradation
Instead of failing a request when dependent components are unhealthy, a service may use circuit-breaker pattern to return a predefined or default response.
Health Checks
Health checks runs a dummy or synthetic transaction that performs the action without affecting real data to verify the system component and its dependencies.
Idempotency
Idempotent services completes API request only exactly once so resending same request due to retries has no side effect. Idempotent APIs typically uses a client-generated identifier or token and the idempotent service returns same response if duplicate request is received.
Layered Architecture
The layered architecture separates software into different concerns such as:
Presentation Layer
Business Logic Layer
Service Layer
Domain Model Layer
Data Access Layer
Load Balancer
Load balancer allows distributing traffic among groups of resources so that a single resource is not overloaded. These load balancers also monitors health of servers and you can setup a load balancer for each group of resources to ensure that requests are not routed to unhealthy or unavailable resources.
Load Shedding
Load shedding allows rejection the work at the edge when server side exceeds its capacity, e.g. a server may return HTTP 429 error to signal clients that they can retry at a slower rate.
Loosely coupled dependencies
Using queuing systems, streaming systems, and workflows isolate behavior of dependent components and increases resiliency with asynchronous communication.
MicroServices
Microservices evolved from service oriented architecture (SOA) and support both point to point protocols such as REST/gRPC and asynchronous protocols based on messaging/event bus. You can apply bounded-context of domain-driven design (DDD) to design loosely coupled services.
Model-View Controller
It decouples user interface from the data model and application functionality so that each component can be independently tested. Other variations of this pattern include model–view–presenter (MVP) and model–view–viewmodel (MVVM).
NoSQL
NoSQL database technology provide support for high availability and variable/write-heavy workloads that can be easily scaled with additional hardware. NoSQL optimizes CAP and PACELC tradeoffs of consistency, availability, partition tolerance and latency, A number of cloud vendors provide managed NoSQL database solutions, however they can create latency issues if services accessing these databases are not colocated.
No Single Point of Failure
In order to eliminate single-points of failures for providing high availability and failover, you can deploy redundant services to multiple regions and availability zones.
Ports and Adapters
Ports and Adapters (Hexagon) separates interface (ports) from implementation (adapters). The business logic is encapsulated in the Hexagon that is invoked by the implementation (adapters) when actors operate on capabilities offered by the interface (port).
Rate Limiting and Throttling
Rate-limiting defines the rate at which clients can access the services based on the license policy. The throttling can be used to restrict access as a result of unexpected increase in demand. For example, the server can return HTTP 429 to notify clients that they can backoff or retry at a slower rate.
Retries with Backoff and Jitter
A remote operation can be retried if it fails due to transient failure or a server overload, however each retry should use a capped exponential backoff so that retries don’t cause additional load on the server. In a layered architecture, retry should be performed at a single point to minimize multifold retries. Retries can use circuit-breakers and rate-limiting to throttle requests. In some cases, requests may timeout for clients but succeed on the server side so the APIs must be designed with idempotency so that they are safe to retry. In order to avoid retries at the same time, a small random jitter can be added with retries.
Rollbacks
The software should be designed with rollbacks in mind so that all code, database schema and configurations can be easily rolled back. A production environment might be running multiple versions of same service so care must be taken to design the APIs that are both backward and forward compatibles.
Stateless and Shared nothing
Shared nothing architecture helps building stateless and loosely decoupled services that can be easily horizontally scaled for providing high availability. This architecture allows recovering from isolated failures and support auto-scaling by shrinking or expanding resources based on the traffic patterns.
Startup dependencies
Upon start of services, they may need to connect to certain configuration or bootstrap services so care must be taken to avoid thundering herd problems that can overwhelm those dependent services in the event of a wide region outage.
Timeouts
Timeouts help building resilient systems by throttling invocation of external services and preventing the thundering herd problem. Timeouts can also be used when retrying a failed operation after a transient failure or a server overload. A timeout can also add a small jitter to randomly spread the load on the server. Jitter can also be applied to timers of scheduled jobs or delayed work.
Watchdogs and Alerts
A watchdogs monitors a system component for a specific action such as latency, traffic, errors, saturation and SLOs. It then send an alert based on the monitoring configuration that triggers an email, on-call paging or an escalation.
Virtualization and Containers
Virtualization allows abstracting computing resources using virtual machines or containers so that you don’t depend on physical implementation. A virtual machine is a complete operating system on top of hypervisors whereas container is an isolated, lightweight environment for running applications. Virtualization allows building immutable infrastructure that are specially design to meet application requirements and can be easily deployed on a variety of hardware resources.
Architecture Practices
Following are best practices for sustainable software delivery:
Automation
Automation builds pipelines for continuous integration, continuous testing and continuous delivery to improve speed and agility of the software delivery. Any kind of operation procedures for deployment and monitoring can be stored in version control and then automatically applied with CI/CD procedures. In addition, automated procedures can be defined to track failures based on key performance indicators and trigger recovery or repair for the erroneous components.
Automated Testing
Automated testing allows building software with a suite of unit, integration, functional, load and security tests that verify the behavior and ensures that it can meet production demand. These automated tests will run as part of CI/CD pipelines and will stop deployment if any of the tests fail. In order to run end-to-end and load tests, the deployment scripts will create a new environment and setup a tests data. These tests may replicate synthetic transactions based on production traffic and benchmark the performance metrics.
Capacity Planning
Using load testing, monitoring production traffic patterns and demand with workload utilization help forecast the resources needed for future growth. This can be further strengthened with a capacity model that calculates unit-price of resources and growth forecast so that you can automate addition or removal of resources based on demand.
Cloud Computing
Adopting cloud computing simplifies resource provisioning and its elasticity allows organizations to grow or shrink those resources based on the demand. You can also add automation to optimize utilization of the resources and reduce costs when allocating more resources.
Continuous Delivery
Continuous delivery automates production deployment of small and frequent changes by developers. Continuous delivery relies on continuous integration that runs automated tests and automated deployment without any manual interventions. During a software development process, a developer picks a feature, works on changes and then commits changes to the source control after peer code-review. The automated build system will run a pipeline to create a container image based on the commit and then deploy it to a test or QA environment. The test environment will run automated unit, integration and regression tests using a test data in the database. The code is then promoted to the main branch and the automated build system tags and build the image on the head commit of main-branch, which that is pushed to the container registry. The pre-prod environment pulls the image, restarts the pre-prod container and runs more comprehensive tests with a larger set of test data in the database including performance tests. You may need multiple stages of pre-prod deployment such as alpha, beta and gamma environments, where each environment may require deployment to a unique datacenter. After successful testing, the production systems are updated with the new image using rolling updates, blue/green deployments or canary deployments to minimize disruption to end users. The monitoring system watches for error rates at each stage of the deployment and automatically rollbacks changes if a problem occurs.
Deploy over Multiple Zones and Regions
In order to provide high availability, compliance and reduced latency, you can deploy to multiple availability zones and regions. Global load balancers can be used to route traffic based on geographic proximity to the closest region. This also helps implementing business continuity as applications can easily failover to another region with minimal data.
Service Mesh
In order to easily build distributed systems, a number of platforms based on service-mesh pattern have emerged to abstract a common set of problems such as network communication, security, observability, etc:
Dapr – Distributed Application Runtime
The Distributed Application Runtime (Dapr) provides a variety of communication protocols, encryption, observability and secret management for building secured and resilient distributed services.
Envoy
Envoy is a service proxy for building cloud native application with builtin support for networking protocols and observability.
Istio service mesh
Istio is built on top of Kubernetes and Envoy to build service mesh with builtin support for networking, traffic management, observability and security. A service mesh also addresses features such as A/B testing, canary deployments, rate limiting, access control, encryption, and end-to-end authentication.
Linkerd
Linkerd is a service mesh for Kubernetes and consists of control-plane and data-plane with builtin support for networking, observability and security. The control-plane allows controlling services and data-plane acts as a sidecar container that handles network traffic and communicate with the control-plane for configuration.
WebAssembly
The WebAssembly is a stack-based virtual machine that can run at the edge or in cloud. A number of WebAssembly platforms have adopted Actor model to build a platform for writing distributed applications such as wasmCloud and Lunatic.
Documentation
The architecture document defines goals and constraints of the software system and provides various perspectives such as use-cases, logical, data, processes, and physical deployment. It also includes non-functional or quality attributes such as performance, growth, scalability, etc. You can document these aspects using standards such as 4+1, C4, and ERD as well as document the broader enterprise architecture using methodologies like TOGAF, Zachman, and EA.
Incident management
Incident management defines process of root-cause analysis and actions that organization can take when an incident occurs affecting production environment. It defines best practices such as clear ownership, reducing time to detect/mitigate, blameless postmortems and prevention measures. The organization can then implement preventing measures and share lessons learned from all operational events and failures across teams. You can also use pre-mortem to identify potential areas that can be improved or mitigated. Another way to simulate potential problems is using chaos engineering or setting up game days to test the workloads for various scenarios and outage.
Infrastructure as Code
Infrastructure as code uses declarative language to define development, test and production environment, which is managed by the source code management software. These provisioning and configuration logic can be used by CI/CD pipelines to automatically deploy and test environments. Following is a list of frameworks for building infrastructure from code:
Azure Resource Manager
Azure cloud offer Azure Resource Manager (ARM) templates based on JSON format to declaratively define the infrastructure that you intend to deploy.
AWS Cloud Development Kit
The Cloud Development Kit (CDK) supports high-level programming languages to construct cloud resources on Amazon Web Services so that you can easily build cloud applications.
Hashicorp Terraform
Terraform uses HCL based configurations to describe computing resources that can be deployed to multiple cloud providers.
Monitoring
Monitoring measures key performance indicators (KPI) and service-level objectives (SLO) that are defined at the infrastructure, applications, services and end-to-end levels. These include both business and technical metrics such as number of errors, hot spots, call graphs, which are visible to the entire team for monitoring trends and reacting quickly to failures.
Multi-tenancy
If your system is consumed by a different groups or tenants of users, you will need to design your system and services so that it isolates data and computing resources for secure and reliable fashion. Each layer of the system can be designed to treat tenant context as a first-class construct, which is tied to the user identity. You can capture usage metrics per tenant to identify bottlenecks, estimate cost and analyze the resource utilization for capacity planning and growth projections. The operational dashboards can also use these metrics to construct tenant-based operational views and proactively respond to unexpected load.
Security Review
In order to minimize the security risk, the development teams can adopt shift-left on security and DevSecOps practices to closely collaborate with the InfoSec team and integrate security review into every phase of the software development lifecycle.
Version Control Systems
Version control systems such as Git or Mercurial help track code changes, configurations and scripts over time. You can adopt workflows such as gitflow or trunk-based development for check-in process. Other common practices include smaller commits, testing code and running static analysis or linters/profiling tools before checkin.
Summary
The software complexity is a major reason for missed deadlines and slow/buggy software. This complexity can be essential complexity within the business domain but it’s often result of accidental complexity as a result of technical debt, poor architecture and development practices. Another source of incidental complexity comes from distributed computing where you need handle security, rate-limiting, observability, etc. that needs to be applied consistently across the distributed systems. For example, virtualization helps building immutable infrastructures and adopting infrastructure as a code; functions as a service simplifies building micro-services; and distributed platforms such as Istio, Linkerd remove a lot of cruft such as security, observability, traffic management and communication protocols when building distributed systems. The goal of a good architecture is to simplify building, testing, deploying and operating a software. You need to continually improve the systems architecture and its practices to build sustainable software delivery pipelines that can meet both current and future demands of users.
User identity and authentication is commonly implemented using username and passwords (U/P). Despite wide adoption of password based authentication, they are considered the weakest link in the chain of secure access. The weak passwords and password reuse are common attack vectors for cyber-crimes. Most organizations enforce strong passwords but it burdens users to follow arbitrary rules for strong passwords and store them securely. Nevertheless, these strong passwords are still vulnerable to account takeover via phishing or social engineering attacks. Managing password also encumbers high cost of maintenance on service providers and help desk.
Simply put, passwords are broken. An alternative to password based authentication is passwordless authentication that verifies user credentials using biometric and asymmetric cryptography instead of passwords. A number of new industry standards are in development such as WebAuthn, FIDO2, NIST AAL, and Client to Authenticator Protocol (CTAP), etc. to implement passwordless authentication. Passwordless authentication can be further strengthened using multi-factor authentication (MFA) using one-time-passwords (OTP) and SMS. Passwordless authentication eliminates credential stuffing and phishing attacks for data breach [1].
The passwordless authentication can work with both centralized/federated systems as well as decentralized systems that may use decentralized identity. The decentralized identity uses decentralized identifiers (DIDs) developed by Decentralized Identity Foundation (DIF) and the W3C Credentials Community Group. This allows users to completely control their identity and data privacy so that users can choose which data can be shared with other applications and services. Following diagram shows progression of authentication from password-based to decentralized identity:
Drawbacks of Password based Authentication
Following are major drawbacks of password based authentication:
Inconsistent Password Rules
There aren’t industry standards for strong passwords and most organizations use internal standards for defining passwords such as length of password, use of special or alpha-numeric characters. In general, longer passwords with a mix of characters provide higher entropy and are more secure [NIST] but it mandates users to follow these arbitrary rules.
Too many passwords
An average user may need to create an account on hundreds of websites that encumber users to manage passwords for all those accounts.
Sharing same password
Due to the large number of accounts, users may share the same password for multiple websites. This poses a high security risk in the event of security breaches as reported by DBIR and it’s recommended not to share the same password with multiple websites.
Changing password
A user may need to change password after a security breach or on a regular basis, which adds unnecessary work for users.
Unsafe storage of passwords by service providers
Many organizations use internal standards for storing passwords such as storing passwords in plaintext, unsalted passwords or using weak hashing algorithms instead of standardized Argon2 algorithms. Such weak security measures lead to credential stuffing where stolen credentials are used to access other private data.
Costs of IT Support
The password-reset and forgot-password requests are one of the major costs of help-desk that consume up-to 50% of IT budget.
Mitigating Password Management
Following are a few remedies that can mitigate password management:
Password managers
As strong passwords or long passphrases are difficult to memorize, users often write them down that can be easily eavesdropped. It’s recommended to use password managers for storing passwords safely but often they come with their own set of security risks such as unsafe storage in memory, on local disk or in cloud [2, 3].
OAuth/OpenID standards
The OAuth/OpenIDConnect/SAML standards can be used to implement single-sign-on or social login that allow users to access a website or an application using the same credentials. However, it still poses a security risk if the account credentials are revealed and it weakens data privacy because users can be traced easily when the same account is used to access multiple websites.
Multi-Factor Authentication
The password authentication can use multi-factor authentication (MFA) to hardened security. It’s recommended not to use SMS or voice for MFA due to common attacks via SIM swapping/hacking, phishing, social engineering or loss of device. Instead, one-time passwords (OTPs) provide better alternatives that can be generated using a symmetric key and HOTP/TOTP schemes.
Long-term refresh tokens
Instead of frequent password prompts, some applications use long-term refresh tokens or cookies to extend user sessions. However, it’s recommended to use such a mechanism with other multi-factor authentication or PIN/passcodes.
Passwordless Authentication
Passwordless authentication addresses shortcomings of passwords because you diminish security risks associated with passwords. In addition, they provide better user experience, convenience and user productivity by eliminating friction with password management. Passwordless authentication also reduces IT overhead related with password reset and allows use of biometric on smartphones instead of using hard keys or smart cards.
Passwordless Standards
Following section defines industry standards for implementing passwordless authentication:
The Asymmetric password-authenticated key exchange (PAKE) protocols such as Secure Remote Password (SRP) allow authentication without exchanging passwords. However, it’s old and is susceptible to MITM attacks. Other recent standards such as CPace and OPAQUE provide better alternatives. OPAQUE uses an oblivious pseudorandom function (OPRF) where a random output can be generated without knowing the input.
Fast IDentity Online 2 (FIDO2)
FIDO2 is an open standard that uses asymmetric keys and physical devices to authenticate users. FIDO2 specification defines Client to Authenticate Protocol (CTAP) and Web Authentication (WebAuthn) protocols for communication and authentication. WebAuthn can work with roaming physical devices such as YubiKey as well as platform devices that may use built-in biometrics such as TouchID for authentication.
Decentralized Identity and Access Management
Decentralized or self-sovereign identity (SSI) allows users to own and control their identity. This provides passwordless authentication as well as decentralized authorization to control access to private data. The users use a local digital wallet to store credentials and authenticate their identity instead of using external identity providers.
Comparison
Following diagrams compare architecture of centralized, federated and decentralized authentication:
Centralized
In a centralized model, the user directly interacts with the website or application, e.g.
Federated
In a federated model, the user interacts with one or more identity providers using Security Assertion Markup Language (SAML), OAuth, or OpenID Connect (social login), e.g.
Decentralized
In a decentralized model, user establishes peer-to-peer relationships with the authenticating party, e.g.,
The issuers in decentralized identity can be organizations, universities or government agencies that generate and sign credentials. The holders are subjects of authentication that request verifiable-credentials from issuers and then hold them in digital wallet. The verifiers are independent entities that verifies claims and identity in verifiable-credentials using issuer’s digital signature.
Benefits
Following is a list of major benefits of decentralized or self-sovereign identity:
Reduced costs
User and access management such as account creation, login, logout, password reset, etc. incur major cost for service providers. Decentralized identity shifts the work on the client side where users can use a digital wallet to manage their identity and authentication.
Reduced liability
Storing private user data in the cloud is a liability and organizations often lack proper security and access control to protect it. With decentralized identity, user can control what data can be shared based on use-cases and it eliminates liability associated with centralized storage of private data.
Authorization
Decentralized identity can provide claims for authorization decisions using attribute-based access control or role-based access control. These claims can be cryptographically verified in real-time using zero-knowledge proofs (ZKP) to protect user data and privacy.
Sybil Attack
Decentralized identity facilitates generating new identities easily but they can be protected from Sybil or SPAM attacks where a user may create multiple identifiers to mimic multiple users. The service providers can use ID verification, referral, probationary periods or reputation systems to prevent such attacks.
Loyalty and rewards programs
As decentralized identity empowers users to control the data, they can choose to participate in various loyalty and reward programs by sharing specific data with other service providers.
Data privacy and security
Decentralized identity provides better privacy and security required by regulations such as Health Insurance Portability and Accountability Act (HIPAA), General Data Protection Regulation (GDPR), California Consumer Privacy Act (CCPA), etc. This also prevents identity theft and related cyber-crimes because user data is not stored in a cloud or centralized storage.
Key Building Blocks of Self-Sovereign Identity
Above diagram shows major building blocks of decentralized or self-sovereign identity as described below:
Verifiable Credentials
The verifiable credentials (VC) stores credentials and claims for a subject that can be verified using public key infrastructure. The VC may be stored using blockcerts, W3C or JSON-ld data models. It may store additional claims or attributes that can support data privacy using zero-knowledge proofs.
W3C Working Group defines decentralized identifier (DID) as a globally unique identifier similar to URL that uses peer-to-peer communication and decentralized public key infrastructure (DPKI).
The DID points to the associated document that contains metadata about the DID subject, e.g.
In the above example, plexobject is considered a DID method and the DID standards allow customized methods as defined by DID registries.
Public Keys/DID Registries
The public keys/DID registries allow lookup for public keys or decentralized identifiers (DID). A DID registry uses the DID method and protocol to interact with the remote client. Due to support of decentralized identities in blockchain, several implementations of DID registries use blockchains such as uPort, Sovrin, Veres, etc. If a decentralized identifier doesn’t need to be registered, other standards such as Peer DID Method Specification and Key Event Receipt Infrastructure can be used to directly interact with the peer device using DIDComm messaging protocol.
Digital Wallet
The keystore or digital wallet stores private keys, decentralized identifiers (DIDs), verifiable credentials, passwords, etc. The digital wallet uses a digital agent to provide access to internal data or generate new identities. In order to protect wallet data and recovery keys in case of loss of device or data corruption, it can create an encrypted backup in cloud or cold storage. Alternatively, digital wallet may use social recovery by sharding recovery key into multiple fragments using Shamir’s Secret Sharing that are then shared with trusted contacts.
Hardware security module
Hardware security module (HSM) is a physical computing device for storing digital keys and credentials cryptographically. It provides a security enclave for secure execution and preventing unauthorized access to private data.
Multiple Devices
As decentralized applications rely on peer to peer communication, digital wallets can use Decentralized Key Management System (DKMS), Key Event Receipt Infra- structure (KERI) and DIDComm messaging protocols to support multiple devices.
Push Notification
Decentralized identity may use push notifications to verify identity or receive alerts when a user is needed to permit an access.
Summary
The passwords are the bane of online experience and incur high cost of maintenance for service providers. Alternative user authentication mechanisms using passwordless, biometrics and asymmetric key exchange provide better user experience and stronger security. The decentralized identity further improves interoperability and data privacy where users can control who can access their private data and earn rewards for sharing their data. As modern mobile devices already have built-in support for HSM based security enclave, biometrics and push notifications, they provide a simple way to implement digital wallets and decentralized identity. This eliminates security breaches, identity theft and the need for data protection regulations and complex authentication protocols such as SAML/OIDC because data is cryptographically protected on local storage. Though open standards for passwordless authentication and decentralized identity are still in development, they show a bright future to build the next generation of applications that provide better data security, privacy, protection, end-to-end encryption, portability, instant payments and better user experience.
Web3 term was coined by Ethereum co-founder Gavin Wood to distinguish it from Web2 architecture. The Web2 architecture popularized interactive and interoperable applications, where Web3 architecture adds decentralization based on blockchain for protecting user data and privacy. I came across a number of recent posts [1, 2, 3, 4] lately that question the claims of Web3 architecture including a latest blog from Moxie. As a co-founder of Signal protocol and strong cryptography background, Moxie makes following observations:
People don’t want to run their own servers, and never will.
A protocol moves much more slowly than a platform.
NFT marketplace looks similar to centralized websites and databases instead of blockchain based distributed state.
The blockchain lack client/server interface for interacting with the data in a trustless fashion.
The dApp clients often communicate with centralized services such as Infura or Alchemy and lack client side validation.
Moxie identifies following security gaps in NFT use-cases:
Blockchain does not store data for NFT, instead it only points to URL and it lacked hash commitment for data located at the URL.
Crypto wallet such as MetaMask connects to central services such as Etherscan and OpenSea without client-side validation.
Moxie claims that innovations at centralized services such as OpenSea are outpacing standards such as ERC-721 similar to GMail compared to Email standards. He claims that decentralization has a little practical or pressing importance to the majority of people who just want to make money. In the end, he concludes:
We should accept the premise that people will not run their own servers by designing systems that can distribute trust without having to distribute infrastructure.
We should try to reduce the burden of building software because distributed systems add considerable complexity.
Moxie raises valid concerns regarding the need for thin clients that can validate blockchain data with trustless security as well as the use of message authentication code and metadata when creating or accessing NFT. However, he conflates Bitcoin, Ethereum, and Blockchain and there are existing standards such as Simplified payment verification that allows users to connect to Bitcoin blockchain without running full-node. Due to differences in Ethereum architecture, thin clients are difficult to operate on its platform but there are a number of alternatives such as Light Clients, Tendermint Light, Argent Wallet and Pockt Network. The NFT data can be stored Fleek or decentralized storage solutions such as IPFS, Skynet, Sia, Celestia, Arweave and Filecoin. Some blockchains such as Tezos and Avax also offer layer-1 solution for data storage. Despite the popularity of Opensea with its centralized access, a number of alternatives are being worked on such as OpenDao and NFTX. Further, NFT standards such as ERC-2981 and ERC-1155 are in work to support royalties and other enhancements.
When reviewing Signal app, I observed that Moxie advocated centralized cryptography and actively tried to stop other open source projects such as LibreSignal to use their servers. Moxie also declined collaboration with open messaging specifications such as Matrix. Centralized cryptography is an oxymoron as truly secure systems don’t require trust. The centralized messaging platforms such as WhatsApp impose forwarding limit, which require encryption of multiple messages using the same key. Despite open source development of Signal app, there is no guarantee that it uses the same code on its infrastructure (e.g. it stopped updating open source project for a year) or it doesn’t log metadata when delivering messages.
Though, Moxie‘s experience with centralized services within the blockchain ecosystem highlights a crucial area of work but a number of solutions are being worked on, admittedly with slow progress. However, his judgment is clouded by his prior position and beliefs where he prefers centralized cryptography and systems over decentralized and federated systems. In my previous blog, I have discussed the merits of decentralized messaging apps, which provide better support for data privacy, censorship, anonymity, deniability and confidentiality with trustless security. This is essential for building Web3 infrastructure and more work is needed to simplify development and adoption of decentralized computing and trustless security.
I recently read Sam Newman’s book on Monolithic to Microservices architecture. I had read his previous book on Building Microservices on related topic that focused more on design and implementation of microservices but there is some overlap of topics in these books.
Chapter 1 – Just Enough Microservices
The first chapter defines how microservices can be designed to be deployed independently by modeling around a business domain.
Benefits
The major benefits of microservices include:
Independent Deployability
Modeled Around a Business Domain
The author explains one of common reason for three-tier architecture with UI/Business-Logic/Database is so common is due to Conway’s law that predicates that system design mimics organization’s communication structure.
Own Their Own Data
In order to keep reduce coupling, author recommends against sharing data with microservices.
Problems
Though, microservices provide you isolation and flexibility but they also add complexity that comes with network communication such as higher latencies, distributed transactions, and handling network failures. Other problems include:
User Interface
The author also cautions against focusing only on the server side and leaving UI as monolithic.
Technology
The author also cautions against chasing shiny new technologies instead of leveraging what you already know.
Size
The size of a microservice depends on the context but just having a small-size should not be the primary concern.
Ownership
The microservices architecture allows strong ownership but it requires that they are designed around the business domain and product lines.
Monolith
The author explains monolithic apps where all code is packaged into a single process.
Modular Monolith
In modular monolith, the code can be broken into different modules and is for deployment.
Distributed Monolith
If boundaries of microservices are not loosely coupled, they can result in distributed monolith that has disadvantages of monolithic and microservices.
Challenges and Benefits of Monolith
The author explains that monolithic design is not necessarily a legacy but a choice that depends on the context.
Cohesion and Coupling
He uses cohesion and coupling when defining microservices where stable systems encourage high cohesion and low coupling that provides independent deployment and minimize chatty services.
Implementation Coupling
The implementation coupling may be caused by sharing domain or database.
Temporal Coupling
The temporal coupling using synchronous APIs to perform an operation.
Deployment Coupling
The deployment coupling adds risk of adding unchanged modules to the deployment.
Domain Coupling
The domain coupling is caused by sharing full domain object instead of events or reducing unrelated information.
Domain-Driven Design
The author reviews domain-driven design concepts such as aggregate and bounded context.
Aggregate
In DDD, an aggregate uses a state machine to manage lifecycle of a grouped object that can be used to design a microservice so that it handles the lifecycle and storage of those aggregates.
Bounded Context
Bounded context represents a boundary of business domain that may contain one or more aggregates. These concepts can be used to define service boundaries so that each service is cohesive with a well-defined interface.
Chapter 2 – Planning a Migration
The chapter two defines a migration path for micro-services by defining goals for the migration and why you should adopt a microservice architecture.
Why Might You Choose Microservices
Common reasons for such architecture includes:
improving autonomy
reduce time to market
scaling independently
improving robustness
scaling the number of developers while minimizing coordination
embracing new technologies
When Might Microservices Be a Bad Idea?
The author also describes scenarios when a microservice architecture is a bad idea such as:
when business domain is unclear
early adopting microservices in startups
customer-installed software.
Changing Organizations
The author describes some of ways organizations can be persuaded to adopt this architecture using Dr. John Kottler’s eight-step process:
establishing a sense of urgency
creating the guided coalition
developing a vision and strategy
communicating the change vision
empowering employees
generating short-term wins.
Importance of Incremental Migration
Incremental migration for microservice architecture is important so that you can release these services to the production and learn from the actual use.
Cost of Change
The author explains cost of change in terms of reversible and irreversible decisions commonly used at Amazon.
Domain Driven Design
The author goes over domain-driven design again and shows how bounded context can define boundaries of the microservices. You can use event storming to define a shared domain model where participants define first domain events and then group those domain events. You can then pick a context that has few in-bound dependencies to start with and using strangler fig pattern for incremental migration. The author also shows two-axis model for service decomposition by comparing benefit vs ease of decomposition.
Reorganizing Teams
The chapter then reviews team restructure so that you can reassign responsibilities towards cross-functional model who can fully own and operate specific microservices.
How Will You Know if the Transition is Working?
You can determine if the transition is working by:
having regular checkpoints
quantitative measures
Qualitative measures
Avoiding the sunk cost fallacy.
Chapter 3 – Splitting the Monolith
The chapter three describes how to split the monolith in small steps.
To change the Monolith or Not?
You will have to decide whether to move existing code as is or reimplement.
Refactoring the Monolith
A key blocker in breaking the monolith might be tightly coupled design that requires some refactoring before the migration. The next step in this process might be a modular monolith where you have a single unit of deployment but with statically linked modules.
Pattern: Stranger Fig Application
The Strangler Fig Application incrementally migrates existing code by moving modules to external microservices. In some cases those microservices may need to invoke other common behavior in the monolith.
HTTP Proxy
If the monolith is using an HTTP reverse proxy to intercept incoming calls, it can be extended to redirect requests for the new service. If the new service chooses to implement a new protocol, it may require other changes to the proxy layer that could add risk and goes against general recommendation of “Keep the pipes dumb, the endpoints smart.” One way to remediate is to create a layer for converting protocol from the legacy to the new format such as REST to gRPC.
Service Mesh
Instead of a centralized proxy, you can use service meshes such as Envoy that is deployed as a control-plane along with each service that acts as a proxy for communicating with the service.
Message Interception and Content-based Routing
If a monolith is using messaging, you can intercept messages and use a content-based router to send messages to the new service
Pattern: UI Composition
The UI composition looks at how user interface can be migrated from monolithic backend to microservice architecture.
Page Composition
The page-composition migrates one page at a time based on product verticals to ensure that old page links are replaced with the new URLs when they are changed. You can choose a low-risk vertical for UI migration to reduce the risk of breaking functionality.
Widget Composition
The widget composition reduces the UI migration risk by just replacing a single widget at a time. For example, you may use Edge-Side Includes (ESI) to define a template in the web page and a web server splices in this content. Though, this technique is less common these days due to browser can make requests to populate a widget. This technique was used by Orbitz to render UI modules from a central orchestration service but due to its monolithic design, it became a bottleneck for coordinating changes. The central orchestration service was then migrated to microservices incrementally.
Mobile Applications
These UI composition changes can also be applied to mobile apps, however mobile app is a monolith and whole application needs to be deployed. Some organizations such as Spotify allow dynamic changes from the server side.
Micro Frontends
Modern web browsers and standards such as Web Component specification to help build single page apps and micro frontends by using widget-based composition.
The UI composition is highly effective when migrating vertical slices and you have the ability to change the existing user interface.
Pattern: Branch by Abstraction
The “Branch by Abstraction” can be used with incremental migration using Strangler Fig when the functionality is deeply nested and other developers may be making changes to the same codebase. In order to prevent merge conflicts from large changes and to keep minimal disruption for developers, you create an abstraction for the functionality to be replaced. This abstraction can then be implemented by both existing code and new implementation. You can then switch over the abstraction to new implementation once you are done and clean up old implementation.
Step1: Create abstraction
Create an abstraction using “Extract Interface” refactoring.
Step2: Use abstraction
Refactor the existing clients to use the new abstraction point.
Step3: Create new implementation
Implement the abstraction to call the external service inside the monolith. You may simply return “Not Implemented” errors in the new implementation and deploy code into production as this new service isn’t actually being called.
Step4: Switch implementation
Once the new implementation is done, you can switch the abstraction to point to the new implementation. You may also use feature flags to toggle back and forth quickly.
Step5: Clean up
Once the new implementation is fully working, the old implementation can be removed and you may also remove the abstraction if needed.
Fallback Mechanism
A variation of the branch by abstraction pattern called verify branch by abstraction can be used to implement a live verification where if the new implementation fails, then the old implementation could be used instead.
Overall, branch by abstraction is a fairly general-purpose pattern and useful in most cases where you can change the existing code.
Pattern: Parallel Run
As the strangler fig pattern and branch by abstraction pattern allow both old and new implementations to coexist in production, you can use parallel runs to call both implementations and compare results. Typically, the old implementation is considered the source of truth until the new implementation can be verified (Examples: new pricing system, FTP upload).
N-Version Programming
Critical control systems such as air flight systems use redundant subsystems to interpret signals and then use quorum to find the results.
Verification Techniques
In addition to simply comparing results, you may also need to compare nonfunctional aspects such as latency and failure rate.
Using Spies
A spy is used with unit testing to stub a piece of functionality such as communication with an external service and verify the results (Examples: sending an email or remote notification). Spy is generally run as external process and you may use record/play to replay the events for testing. GitHub’s Scientist is a notable library for this pattern.
Dark Launching and Canary Releasing
The parallel run can be combined with canary release to test the new implementation before releasing to all users. Similarly, dark launching allows enabling the new implementation to only selected users (A/B testing).
Parallel run requires a lot of effort so care must be taken when it’s used.
Pattern: Decorating Collaborator
If you need to trigger some behavior inside the monolith, you can use decorating collaborator pattern to attach new functionality (Example: Loyalty Program – earn points on orders). You may use proxy to intercept the request and add new functionality. On the downside, this may require additional data, which adds more complexity and latency.
This is a simple and elegant approach but it works best the required information can be extracted from the request.
Pattern: Change Data Capture
This pattern allows reacting to changes made in a datastore instead of intercepting the calls. This underlying capture system is coupled with the monolithic datastore (Example: Issue Loyalty Cards – trigger on insert that calls Loyalty Card Printing service).
Implementing Change Data Capture
Database triggers
For example, defining triggers on relational database that calls a service when a record is inserted.
Transaction log pollers
The transactional logs from transactional databases can be inspected by external tools to capture data changes and then pass this data to message brokers or other services.
Batch delta copier
This simply scans the database on a regular schedule for the data that has changed and copies this data to the destination.
The change data capture has a lot of implementation challenges so its use must be kept to minimal.
Chapter 4 – Decomposing the Database
This chapter reviews patterns for managing a single shared database:
Pattern: The Shared Database
The implementation coupling is generally caused by the shared database because the ownership or usage of the database schema is not clear. This weakens the cohesion of business logic because the behavior is spread across multiple services. The author points that the only two situations where you may share the database are when using database for read-only static reference data or when a service is directly exposing a database to handle multiple consumers (Database as a service interface). Also, in some cases the work involved with splitting the database might be too large for incremental migration where you may use some coping patterns to manage the shared database.
Pattern: Database View
When sharing a database, you may define database views for different services to limit the data that is visible to the service.
The Database as a Public Contract
When sharing a database, it might be difficult who is reading or writing the data especially when different applications use the same credentials. This also prevent changing the database schema because some of the applications might not be actively maintained.
Views to Present
One way to change schema without breaking existing application is to define views that looks like old schema. The database view may also just project limited information to implement a form of information hiding. In some cases you may need a materialized view to improve performance. You should use this pattern only when existing monolithic schema can’t be decomposed.
Pattern: Database Wrapping Service
The database wrapping service hides the database behind a service. This can be used when the underlying schema can’t be broken down. This provides better support for customized projection and read/write than the database views.
Pattern: Database-as-a-Service Interface
In cases when you just need to query the database, you may create a dedicated reporting database that can be exposed as a read-only endpoint. A mapping engine can listen for changes in the internal database and then persist them in the reporting database for query purpose by internal/external consumers.
Implementing a Mapping Engine
You may use a change data capture system (Debezium), a batch process to copy the data or a message broker to listen for data events. This allows presenting data in different database technology and provides more flexibility than the database views.
Pattern: Aggregate Exposing Monolith
When a microservice needs a data inside the monolith database, you can expose a service endpoint to provide the access to the domain aggregate. This pattern allows exposing the information in a well defined interface and is safer than exposing the shared database despite additional work.
Pattern: Change Data Ownership
If the monolith needs to access the data in a shared database that should belong to the new microservice, then monolith can be updated to call the new service and treat it as a source of truth.
Database Synchronization
As a strangler fig pattern allows switching back to monolith if we find an issue in the microservice but it requires that the data between the monolith and the new service remains in sync. You may use database view and a shared database for short term until the migration is successfully completed. Alternatively, you may sync both databases via code but it requires some careful thoughts.
Pattern: Synchronize Data in Application
Migrating data from one database to another requires performing synchronization between two data sources.
Step 1: Bulk Synchronize Data
You may take a snapshot of the source data and import it into the new data source while the existing system is kept running. As the source data might be changed while the import process is running, a change data capture process can be implemented to import the changes since the import. You can then deploy new version of the application after this process.
Step 2: Synchronize on Write, Read from Old Schema
Once both databases are in sync, the new application writes all data to both databases while reading from the old database.
Step 3: Synchronize on Write, Read from New Schema
Once, you verify the reads from new database work, you can switch the application to switch the new database as a source of truth.
Pattern: Trace Write
This is a variation of the synchronize data in application pattern where the source of truth is moved incrementally and both sources are considered sources of truth during migration. For example, you may just migrate one domain aggregate at a time and other services may use either data source depending on the information they need.
Data Synchronization
If data is duplicated inconsistency, you may need to apply following options:
Write to one source – data to the other source of truths is synchronized after the write.
Send writes to both sources – The client makes a call to both sources or use an intermediary to broadcast the request.
Send writes to either source – the data is synchronized behind the scene.
The last option should be avoided as it requires two way synchronization. In other cases, there will be some delay in the data being consistent (eventual consistency).
Splitting Apart the Database
Physical versus Logical Database Separation
A physical database can host multiple logically separated schemas so migration to separate physical databases can be planned later to improve robustness and throughput/latency. A single physical database can become a single point of failure but it can be remedied by using multi-primary database modes.
Splitting the Database First, or the Code?
Split the Database First
This may cause multiple database calls instead of one action such as SELECT statement or break transactional integrity so you can detect performance problems earlier. However, it won’t yield much short-term benefits.
Pattern: Repository per bounded context
Breaking down the repositories along the boundaries of bounded context help understand dependencies and coupling between tables.
Pattern: Database per bounded context
This allows you to decompose database around the lines of bounded context so that each bounded context uses a distinct schema. This pattern can be applied in startups when the requirements may change drastically so you can keep multiple schemas while using monolithic architecture.
Split the Code First
This allows understanding data dependencies in the new service and benefit of independent deployment thus offering the short-term improvements.
Pattern: Monolith as data access layer
This allows creating an API in the monolith to provide access to the data.
Pattern: Multi-schema storage
When adding new tables while migrating from the monolith, add new tables to its own schema.
Split Database and Code Together
This split the code and data at once but it takes more effort.
Pattern: Split Table
This splits a single shared table into multiple tables based on boundaries of bounded contexts. However, this may break database transactions.
Pattern: Move Foreign-Key Relationship to Code
Moving the Join
Instead of using database join but in the new service, you will need to query the data from another service.
Database Consistency
As you can’t rely on the referential integrity enforced by the database with multiple schemas, you may need to enforce it in the application such as:
check before deletion or existence but it can be error prone.
handle deletion gracefully – such as not showing missing information and services may also subscribe to add/delete events for related data (recommended).
don’t allow deletion
Shared Static Data
Duplicate static reference data
This will result in some data inconsistencies.
Pattern: Dedicated reference data schema
However, you may need to share the physical database.
Pattern: Static reference data library
This may not be suitable when using different programming languages and you will have to support multiple versions of the library.
Pattern: Static reference data service
This will add another dependency but it can be cached at the client side with update events to sync the local cache.
Transactions
ACID Transactions
This will be hard with multiple schemas but you may use state such as PENDING/VERIFIED to manage atomicity.
Two-Phase Commits
This breaks transaction into voting and commit phases and rollback message is sent if any worker doesn’t vote for commit.
Distributed Transactions – just say No
Sagas
A saga or long-lived transactions use an algorithm that can coordinate multiple changes in state but avoid locking resources. It breaks down LLT into a sequence of transactions that can occur independently as a short-lived.
Saga Failure Modes
Saga provides backward and forward recovery where backward recovery reverts the failure by using compensating transactions. The forward recovery allows continuation from the failure by retrying it.
Note: The rollback will undo all previously executed transactions. You can move forward the steps that are most likely to fail to avoid triggering compensating transactions on large number of steps.
Implementing Sagas
orchestrated sags – You may use multiple orchestration to break down the saga using BPM or other tools.
Choreographed sagas – This broadcasts events using a message broker. However, the scope of saga transaction may not be apparently visible.
Chapter 5 – Growing Pains
More Services, More Pain
Ownership at Scale
Strong code ownership – large scale microservices
Weak code ownership
Collective code ownership
Breaking Changes
A change in a microservice may break backward compatibility or other changes for consumers. You can ensure that you don’t break contracts when making changes to the services by using explicit schemas and maintaining semantics. You may also support multiple versions of the service if you need to break backward compatibility and allow existing clients to migrate to the new version.
Reporting
A monolithic database simplifies reporting but with different schemas and databases, you may need to build a reporting database to aggregate data from different services.
Monitoring and Troubleshooting
A monolithic app is easier to monitor but with multiple microservices you will need to use log aggregation and define a correlation id with tracing tools to see a transaction events from different services.
Test in Production
You may use synthetic transactions to perform end-to-end testing in production.
Observability
You can gather information about the system by tracing, logs and other system events.
Local Developer Experience
When setting up a local environment, you may need to setup a large number of services that can slow down development process. You may need to stub out services or use tools such as Telepresence proxy to call remote services.
Running Too Many Things
You may use Kubernetes to manage the deployment and troubleshooting the microservices.
End-to-End Testing
A microservice architecture increases the scope of end-to-end testing and you have to debug false negative due to environmental issues. You can use following approaches for end-to-end testing:
Limit scope of functional automated tests
Use consumer-driven contracts
Use automated release remediation and progressive delivery
Continually refine your quality feedback cycles
Global versus Local Optimization
You may have to solve same problem with multiple services such as service deployment. You may need to evaluate problems as irreversible or reversible decisions and adopt a broader discussion for irreversible decisions.
Robustness and Resiliency
Distributed systems exhibit a variety of failures so you may need to run redundant services, use asynchronous communication or apply other patterns such as circuit breakers, retries, etc.
Orphaned Services
The orphaned services don’t have clear owners so you can’t immediately fix it if the service stops working. You may need a service registry or other tools to track the services, however some services may predate these tools.
I wrote about support of structured concurrency in Javascript/Typescript, Erlang/Elixir, Go, Rust, Kotlin and Swift last year (Part-I, Part-II, Part-III, Part-IV) but Swift language was still in development for async/await and actors support. The Swift 5.5 will finally have these new concurrency features available, which are described below:
Async/Await
As described in Part-IV, Swift APIs previously used completion handlers for asynchronous methods that suffered from:
Poor error handling because you could not use a single way to handle errors/exceptions instead separate callbacks for errors were needed
Difficult to cancel asynchronous operation or exit early after a timeout.
Requires a global reasoning of shared state in order to prevent race conditions.
Stack traces from the asynchronous thread don’t include the originating request so the code becomes hard to debug.
As Swift/Objective-C runtime uses native threads, creating a lot of background tasks results in expensive thread resources and may cause excessive context switching.
Nested use of completion handlers turn the code into a callback hell.
Following example shows poor use of control flow and deficient error handling when using completion handlers:
func fetchThumbnails(for ids: [String],
completion handler: @escaping ([String: UIImage]?, Error?) -> Void) {
guard let id = ids.first else { return handler([:], nil) }
let request = thumbnailURLRequest(for: id)
URLSession.shared.dataTask(with: request) { data, response, error in
guard let response = response,
let data = data else { return handler(nil, error) } // Poor error handling
UIImage(data: data)?.prepareThumbnail(of: thumbSize) { image in
guard let image = image else { return handler(nil, ThumbnailError()) }
}
fetchThumbnails(for: Arrays(ids.dropFirst()) { thumbnail, error in
// cannot use loop
...
}
}
}
Though, use of Promise libraries help a bit but it still suffers from dichotomy of control flow and error handling. Here is equivalent code using async/await:
func fetchThumbnails(for ids: [String]) async throws -> [String: UIImage] {
let thumbnails: [String: UIImage] = [:]
for id in ids {
let request = thumbnailURLRequest(for: id)
let (data, response) = try await URLSession.shared.dataTask(for: request)
try validateResponse(response)
guard let image = await UIImage(data: data)?.byPreparingThumbnail(ofSize: thumbSize) else { throw ThumbnailError()) }
thumbnails[id] = image
}
return thumbnails
}
As you can see, above code not only improves control flow and adds uniform error handling but it also enhances readability by removing the nested structure of completion handlers.
Tasks Hierarchy, Priority and Cancellation
When a new task is created using async/await, it inherits the priority and local values of the parent task, which are then passed to the entire hierarchy of child tasks from the parent task. When a parent task is cancelled, the Swift runtime automatically cancels all child tasks, however Swift uses cooperative cancellation so child tasks must check for cancellation state otherwise they may continue to execute, however the results from cancelled tasks are discarded.
Continuations and Scheduling
Swift previously used native threads to schedule background tasks, where new threads were automatically created when a thread is blocked or waiting for another resource. The new Swift runtime creates native threads based on the number of cores and background tasks use continuations to schedule the background task on the native threads. When a task is blocked, its state is saved on the heap and another task is scheduled for processing on the thread. The await syntax suspends current thread and releases control until the child task is completed. This cooperative scheduling requires runtime support for non-blocking I/O operations and system APIs so that native threads are not blocked and continue to work on other background tasks. This also limits background tasks from using semaphores and locks, which are discussed below.
In above example, when a thread is working on a background task “updateDatabase†that starts a child tasks “add†or “saveâ€, it saves the tasks as continuations on heap. However, if current task is suspended then the thread can work on other tasks as shown below:
Multiple Asynchronous Tasks
The async/await in Swift also allows scheduling multiple asynchronous tasks and then awaiting for them later, e.g.
struct MarketData {
let symbol: String
let price: Int
let volume: Int
}
struct HistoryData {
let symbol: String
let history: [Int]
func sum() -> Int {
history.reduce(0, +)
}
}
func fetchMarketData(symbol: String) async throws -> MarketData {
await withCheckedContinuation { c in
DispatchQueue.main.asyncAfter(deadline: .now() + 1) {
c.resume(with: .success(MarketData(symbol: symbol, price: 10, volume: 200)))
}
}
}
func fetchHistoryData(symbol: String) async throws -> HistoryData {
await withCheckedContinuation { c in
DispatchQueue.main.asyncAfter(deadline: .now() + 1) {
c.resume(with: .success(HistoryData(symbol: symbol, history: [5, 10, 15, 20])))
}
}
}
func getMovingAverage(symbol: String) async throws -> Int {
async let marketData = fetchMarketData(symbol: symbol)
async let historyData = fetchHistoryData(symbol: symbol)
let sum = try await marketData.price + historyData.sum()
return try await sum / (historyData.history.count+1)
}
The async let syntax is called concurrent binding where the child task executes in parallel to the parent task.
Task Groups
The task groups allow dispatching multiple background tasks that are executed concurrently in background and Swift automatically cancels all child tasks when a parent task is cancelled. Following example demonstrates use of group API:
func downloadImage(id: String) async throws -> UIImage {
await withCheckedContinuation { c in
DispatchQueue.main.asyncAfter(deadline: .now() + 1) {
c.resume(with: .success(UIImage(data: [])))
}
}
}
func downloadImages(ids: [String]) async throws -> [String: UIImage] {
var images: [String: UIImage] = [:]
try await withThrowingTaskGroup(of: (String, UIImage).self) { group in
for id in ids {
group.addTask(priority: .background) {
return (id, try await downloadImage(id: id))
}
}
for try await (id, image) in group {
images[id] = image
}
}
return images
}
As these features are still in development, Swift has recently changed group.async API to group.addTask. In above example, images are downloaded in parallel and then for try await loop gathers results.
Data Races
Swift compiler will warn you if you try to mutate a shared state from multiple background tasks. In above example, the asynchronous task returns a tuple of image-id and image instead of mutating shared dictionary. The parent task then mutates the dictionary using the results from the child task in for try await loop.
Cancellation
You can also cancel a background task using cancel API or cancel all child tasks of a group using group.cancelAll(), e.g.
group.cancelAll()
The Swift runtime automatically cancels all child tasks if any of the background task fails. You can store reference to a child task in an instance variable if you need to cancel a task in a different method, e.g.
As cancellation in Swift is cooperative, you must check cancellation state explicitly otherwise task will continue to execute but Swift will reject the results, e.g.
if Task.isCancelled {
return // return early
}
Timeout
The task or async/await APIs don’t directly support timeout so you must implement it manually similar to cooperative cancellation.
Semaphores and Locks
Swift does not recommend using Semaphores and Locks with background tasks because they are suspended when waiting for an external resource and can be later resumed on a different thread. Following example shows incorrect use of semaphores with background tasks:
func updateDatabase(_ asyncUpdateDatabase: @Sendable @escaping () async -> Void {
let semaphore = DispatchSemaphore(value: 0)
Task {
await asyncUpdateDatabase()
semaphore.signal()
}
semaphore.wait() // Do not use unsafe primitives to wait across task boundaries
}
TaskLocal
You can annotate certain properties with TaskLocal, which are stored in the context of Task and is available to the task and all of its children, e.g.
Above tasks and async/await APIs are based on structured concurrency where parent task is not completed until all child background tasks are done with their work. However, Swift allows launching detached tasks that can continue to execute in background without waiting for the results, e.g.
In above example, the getPersistentPosts method used completion-handler and persistPosts method provides a bridge so that you can use async/await syntax. The resume method can only called once for the continuation.
You may also save continuation in an instance variable when you need to resume in another method, e.g.
Following example shows implementation of WebCrawler using async/await described in Part I of the concurrency series:
import Foundation
struct Request {
let url: String
let depth: Int
let deadline: DispatchTime
}
enum CrawlError: Error {
case timeoutError(String)
}
let MAX_DEPTH = 4
let MAX_URLS = 11
let DOMAINS = [
"ab.com",
"bc.com",
"cd.com",
"de.com",
"ef.com",
"fg.com",
"gh.com",
"hi.com",
"ij.com",
"jk.com",
"kl.com",
"lm.com",
"mn.com",
"no.com",
"op.com",
"pq.com",
"qr.com",
"rs.com",
"st.com",
"tu.com",
"uv.com",
"vw.com",
"wx.com",
"xy.com",
"yz.com",
];
public func crawl(urls: [String], deadline: DispatchTime) async throws -> Int {
// Main scope of concurrency begin
// TODO add timeout using race, e.g. await Task.WhenAny(crawlTask, Task.Delay(deadline)) == crawlTask
return try await doCrawl(urls: urls, depth: 0, deadline: deadline)
// Main scope of concurrency end
}
public func crawlWithActors(urls: [String], deadline: DispatchTime) async throws -> Int {
// Main scope of concurrency begin
// TODO add timeout using race, e.g. await Task.WhenAny(crawlTask, Task.Delay(deadline)) == crawlTask
return try await doCrawlWithActors(urls: urls, depth: 0, deadline: deadline)
// Main scope of concurrency end
}
///////////////// PRIVATE METHODS ////////////////
func doCrawl(urls: [String], depth: Int, deadline: DispatchTime) async throws -> Int {
if depth >= MAX_DEPTH {
return 0
}
let requests = urls.map { Request(url: $0, depth: depth, deadline: deadline) }
var totalChildURLs = 0
try await withThrowingTaskGroup(of: (Request, Int).self) { group in
for req in requests {
group.addTask(priority: .background) {
return (req, try await handleRequest(req))
}
}
for try await (req, childURLs) in group {
if totalChildURLs % 10 == 0 {
print("received request \(req)")
}
totalChildURLs += childURLs
}
}
return totalChildURLs
}
func doCrawlWithActors(urls: [String], depth: Int, deadline: DispatchTime) async throws -> Int {
if depth >= MAX_DEPTH {
return 0
}
let requests = urls.map { Request(url: $0, depth: depth, deadline: deadline) }
var totalChildURLs = 0
let crawler = CrawlActor()
for req in requests {
let childURLs = try await crawler.handle(req)
totalChildURLs += childURLs
}
return totalChildURLs
}
func handleRequest(_ request: Request) async throws -> Int {
let contents = try await download(request.url)
let newContents = try await jsrender(request.url, contents)
if hasContentsChanged(request.url, newContents) && !isSpam(request.url, newContents) {
try await index(request.url, newContents)
let urls = try await parseURLs(request.url, newContents)
let childURLs = try await doCrawl(urls: urls, depth: request.depth + 1, deadline: request.deadline)
return childURLs + 1
} else {
return 0
}
}
func download(_ url: String) async throws -> String {
// TODO check robots.txt and throttle policies
// TODO add timeout for slow websites and linearize requests to the same domain to prevent denial of service attack
return randomString(100)
}
func jsrender(_ url: String, _ contents: String) async throws -> String {
// for SPA apps that use javascript for rendering contents
return contents
}
func index(_ url: String, _ contents: String) async throws {
// apply standardize, stem, ngram, etc for indexing
}
func parseURLs(_ url: String, _ contents: String) async throws -> [String] {
// tokenize contents and extract href/image/script urls
var urls = [String]()
for _ in 0..<MAX_URLS {
urls.append(randomUrl())
}
return urls
}
func hasContentsChanged(_ url: String, _ contents: String) -> Bool {
return true
}
func isSpam(_ url: String, _ contents: String) -> Bool {
return false
}
func randomUrl() -> String {
let number = Int.random(in: 0..<WebCrawler.DOMAINS.count)
return "https://" + WebCrawler.DOMAINS[number] + "/" + randomString(20)
}
func randomString(_ length: Int) -> String {
let letters = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
return String((0..<length).map{ _ in letters.randomElement()! })
}
The crawl method takes a list of URLs with timeout that invokes doCrawl, which crawls list of URLs in parallel and then waits for results using try await keyword. The doCrawl method recursively crawls child URLs up to MAX_DEPTH limit. The main crawl method defines boundary for concurrency and returns count of child URLs.
Following are major features of the structured concurrency in Swift:
Concurrency scope?—?The async/await defines scope of concurrency where all child background tasks must be completed before returning from the asynchronous function.
The async declared methods in above implementation shows asynchronous code can be easily composed.
Error handling?—?Async-await syntax uses normal try/catch syntax for error checking instead of specialized syntax of Promise or callback functions.
Swift runtime schedules asynchronous tasks on a fixed number of native threads and automatically suspends tasks when they wait for I/O or other resources.
Following are the major shortcomings in Swift for its support of structured concurrency:
The most glaring omission in above implementation is timeout, which is not supported in Swift’s implementation.
Swift runtime manages scheduling of tasks and you cannot pass your own execution dispatcher for scheduling background tasks.
Actors
Actor Model is a classic abstraction from 1970s for managing concurrency where an actor keeps its internal state private and uses message passing for interaction with its state and behavior. An actor can only work on one message at a time, thus it prevents any data races when accessing from multiple background tasks. I have previously written about actors and described them Part II of the concurrency series when covering Erlang and Elixir.
Instead of creating a background task using serial queue such as:
final class Counter {
private var queue = DispatchQueue(label: "counter.queue")
private var _count : Int = 0
var count: Int {
queue.sync {
_count
}
}
func incr() {
queue.async(flags: .barrier) {
self._count += 1
}
}
func decr() {
queue.async(flags: .barrier) {
self._count -= 1
}
}
}
The actor syntax simplifies such implementation and removes all boilerplate e.g.
actor Counter {
var count: Int = 0
func incr() {
count += 1
}
func decr() {
count -= 1
}
}
Above syntax protects direct access to the internal state and you must use await syntax to access the state or behavior, e.g.
Task {
let c = Counter()
await withTaskGroup(of: Void.self) { group in
for i in 0..<100 {
group.async {
await c.incr()
}
}
}
print("count \(await c.count)")
}
Priority Inversion Principle
The dispatch queue API applies priority inversion principle when a high priority task is behind low priority tasks, which bumps up the priority of low priority tasks ahead in the queue. The runtime environment then executes the high priority task after completing those low priority tasks. The actor API instead can choose high priority task directly from the actor’s queue without waiting for completion of the low priority tasks ahead in the queue.
Actor Reentrancy
If an actor invokes another actor or background task in its function, it may get suspended until the background task is completed. In the meantime, another client may invoke the actor and modify its state so you need to check assumptions when changing internal state. A continuation used for the background task may be scheduled on a different thread after resuming the work, you cannot rely on DispatchSemaphore, NSLock, NSRecursiveLock, etc. for synchronizations.
Following code from WWDC-2021 shows how reentrancy can be handled safely:
actor ImageDownloader {
private enum CacheEntry {
case inProgress(Task.Handle<Image, Error>)
case ready(Image)
}
private var cache: [URL: CacheEntry] = [:]
func downloadAndCache(from url: URL) async throws -> Image? {
if let cached = cache[url] {
switch cached {
case .ready(let image):
return image
case .inProgress(let handle):
return try await handle.get()
}
}
let handle = async {
try await downloadImage(from: url)
}
cache[url] = .inProgress(handle)
do {
let image = try await handle.get()
cache[url] = .ready(image)
return image
} catch {
cache[url] = nil
throw error
}
}
}
The ImageDownloader actor in above example downloads and caches the image and while it’s downloading an image. The actor will be suspended while it’s downloding the image but another client can reenter the downloadAndCache method and download the same image. Above code prevents duplicate requests and reuses existing request to serve multiple concurrent clients.
Actor Isolation
The actors in Swift prevent invoking methods directly but you can annotate methods with nonisolated if you need to call them directly but those methods cannot mutate state, e.g.
The actors requires that any data structure used in its internal state are thread safe and implement Sendable protocol such as:
Value types
Actors
Immutable classes
Synchronized classes
@Sendable Functions
struct Book: Sendable {
var title: String
var authors: [Author]
}
@MainActor
The UI apps require that all UI updates are performed on the main thread and previously you had to dispatch UI work to DispatchQueue.main queue. Swift now allows marking functions, classes or structs with a special annotations of @MainActor where the functions are automatically executed on the main thread, e.g.
Following example shows how a view-controller can be annotated with the @MainActor annotations:
@MainActor class MyViewController: UIViewController {
func onPress() .... // implicitly on main-thread
nonisolated func fetch() async {
...
In above example, all methods for MyViewController are executed on the main thread, however you can exclude certain methods via nonisolated keyword.
@globalActor
The @globalActor annotation defines a singleton global actor and @MainActor is a kind of global actor. You can also define your own global actor such as:
@globalActor
public struct GlobalSettings {
public actor SettingsActor {
func rememberPassword() -> Bool {
return UserDefaults.standard.bool(forKey: "rememberPassword")
}
}
public static let shared = SettingsActor()
}
...
let rememberPassword = await GlobalSettings.shared.rememberPassword()
Message Pattern Matching
As actors in Swift use methods to invoke operations on actor, they don’t support pattern matching similar to Erlang/Elixir, which offer selecting next message to process by comparing one or more fields in the message.
Local only
Unlike actors in Erlang or Elixir, actors in Swift can only communicate with other actors in the same process or application and they don’t support distributed communication to remote actors.
Actor Executor/Dispatcher
The actor protocol defines following property to access the executor:
var unownedExecutor: UnownedSerialExecutor
However, unownedExecutor is a read-only property that cannot be changed at this time.
Implementing WebCrawler Using Actors and Tasks
Following example shows implementation of WebCrawler using actors and tasks described in Part I of the concurrency series:
import Foundation
actor CrawlActor {
public func handle(_ request: Request) async throws -> Int {
let contents = try await download(request.url)
let newContents = try await jsrender(request.url, contents)
if hasContentsChanged(request.url, newContents) && !isSpam(request.url, newContents) {
try await index(request.url, newContents)
let urls = try await parseURLs(request.url, newContents)
let childURLs = try await doCrawlWithActors(urls: urls, depth: request.depth + 1, deadline: request.deadline)
return childURLs + 1
} else {
return 0
}
}
}
Above implementation uses actors for processing crawling requests but it shares other code for parsing and downloading web pages. As an actor provides a serialize access to its state and behavior, you can’t use a single actor to implement a highly concurrent web crawler. Instead, you may divide the web domain that needs to be crawled into a pool of actors that can share the work.
Performance Comparison
Following table from Part-IV summarizes runtime of various implementation of web crawler when crawling 19K URLs that resulted in about 76K messages to asynchronous methods/coroutines/actors discussed in this blog series:
Language
Design
Runtime (secs)
Typescript
Async/Await
0.638
Erlang
Spawning Process
4.636
Erlang
PMAP
4.698
Elixir
Spawning OTP Children
43.5
Elixir
Task async/await
187
Elixir
Worker-pool with queue
97
GO
Go-routine/channels
1.2
Rust
Async/Await
4.3
Kotlin
Async/Await
0.736
Kotlin
Coroutine
0.712
Swift
Async/Await
63
Swift
Actors/Async/Await
65
Note: The purpose of above results was not to run micro-benchmarks but to show rough cost of spawning thousands of asynchronous tasks.
Overall, Swift’s new features for structured concurrency including async/await and actors is a welcome addition to its platform. On the downside, Swift concurrency APIs lack support for timeouts, customized dispatcher/executors and micro benchmarks showed higher overhead than expected. However, on the positive side, the Swift runtime catches errors due to data races and the new async/await/actors syntax prevents bugs that were previously caused by incorrect use of completion handlers and error handling. This will help developers write more robust and responsive apps in the future.
A task is defined as a unit of work and a task scheduler is responsible for selecting best task for execution based on various criteria. The criteria for selecting best scheduling policy includes:
Maximize resource utilization such as CPU or Memory but not exceeding a certain limit such as 80%.
Maximize throughput such as tasks per seconds.
Minimize turnaround or wall time from task submission to the completion time.
Minimize waiting time in ready queue before executing the task.
Above criteria assumes that pending tasks will be stored in a bounded ready-queue before execution so that no new tasks will be stored when the queue reaches the maximum capacity. In this context, the task is more coarse grained and executes to the completion as compared to CPU scheduling that may use preemptive or cooperative scheduling with context switching to dispatch different processes for execution.
Following is a list of common scheduling algorithms:
First-Come First-Serve (FCFS)
This algorithm simply uses FIFO queue to process the tasks in the order they are queued. On the downside, a long-running task can block other tasks and yield very large average wait times in the queue.
Shortest Job-First (SJF)
This algorithm picks smallest job that needs to be done and then next smallest job. It results in best performance, however it may not be possible to predict runtime of a job before the execution. You may need to pass hints about the job runtime or use historical data to predict the job runtime with exponential average such as:
where alpha is between 0.0 and 1.0 and represents a weighting factor for the relative importance of recent data compared to older data, e.g. alpha with 0 value ignores previous actual time and 1.0 ignores past history of estimates.
Priority Scheduling
This algorithm picks highest priority job that needs to be done and then next highest priority job. It may result in starvation of low-priority tasks and they may wait indefinitely. You can fix this drawback by supporting aging where priority of old tasks is slowly bumped.
Earliest Deadline
This algorithm gives highest priority to the task with the earliest deadline, which is then used to pick the next task to execute. This scheduler improves resource utilization based on the estimated runtime and data requirements.
Speculative Scheduler
The speculative scheduler detects slow running task and starts another instance of the task as a backup to minimize the response time. This generally works for short jobs with homogeneous resources but it doesn’t guarantee complete reliability.
Multilevel Queues
This algorithm allows categorizing tasks and then dispatching the task to the queue based on the category, e.g. you may define distinct queues for small/medium/large tasks based on runtime or definer queues for interactive/background/system/batch tasks. In some cases, a task may need to be jumped from one queue to another based on runtime characteristics of the task and you can use aging and priority inversion to promote low-priority tasks.
Resource aware scheduler
This scheduler tracks provisioned resources and their utilization required by the tasks. The scheduler may simply allocate resources they need when scheduling the tasks or use admission-control algorithm to prevent certain tasks to start until the required resources are available.
Matchmaking scheduler
This scheduler uses affinity based scheduling so that it routes the tasks to workers or nodes where the data resides locally and provide greater data locality.
Delay scheduler
This scheduler waits until the data required by the task is available on the node or worker where task will run to improve data locality. However, in order to prevent starvation, it allows scheduling tasks to another worker or node.
Capacity scheduler
This scheduler shares system resources among tasks where tasks specify the required resources such as memory and CPU. The scheduler tracks resource utilization and allocates resources specified by the tasks.
Fair scheduler
This scheduler ensures that common resources such as CPU, memory, disk and I/O are shared fairly among different tasks.
A number of messaging apps such as FB Messenger, Telegram, Matrix Element, Signal, Status.im, Threema, Whatsapp, etc. offer an end-to-end encryption messaging, however they all use proprietary APIs for message storage/relaying, contacts discovery, keys management, group-administration and other services. These centralized APIs can be used to extract metadata from messages, to build social graph from the contacts or to forge message order/acknowledgements or group membership with malicious access. Though, most of these apps support forward secrecy and post-compromise security (PCS) for pairwise communication but some discard PCS guarantees in groups communication and incur high cost for updating users’ keys with large groups. This paper reviews popular messaging apps for their capabilities and security profile. It explores industry standards for open messaging protocols that can be used to build a secured, decentralized and scalable messaging system with end-to-end encryption and post-compromise security guarantees for both pairwise and group communication. It then proposes an architecture with open standards and decentralized building blocks such as identity, keys management, storage and messaging protocol that can be used to build a trustless and secured messaging system. Lastly, this paper shows how this decentralized architecture can be used to build other high-level decentralized applications for communication, collaboration, payments, social platforms, etc.
Note: This paper only examines text messaging between two parties or among groups and other features such as public channels, bots, payments, WebRTC, audio and video chat are out of scope for this discussion.
Messaging Apps
Following section surveys popular messaging apps and evaluates their strengths and weaknesses:
Survey of Popular Messaging Apps
Briar
Briar is a decentralized messaging app with end-to-end encryption that is designed for activists, journalists and general public. It can sync messages via a variety of network protocols such as Bluetooth, Wi-Fi or Tor [51]. The messages are encrypted using Bramble Transport Protocol (BTP) that supports confidentiality, integrity, authenticity, and forward secrecy. BTP establishes a root key between two parties and derives a temporary key for encrypting communication. The temporary key is rotated periodically based on time periods. It supports group communication by defining a group as a label that can subscribe to a channel similar to Usenet.
Facebook Messenger
Facebook Messenger is a closed-source messaging app that uses Signal protocol for end-to-end encryption. Facebook uses centralized authentication and delivery services for message routing. Its privacy policies are quite appalling and per Apple’s privacy polices, it collects a lot of metadata from users such as [59]:
Purchase History
Other Financial Info
Precise Location
Coarse Location
Physical Address
Email Address
Name
Phone Number
Other User Contact Info
Contacts
Photos or Videos
Gameplay Content
Other User Content
Search History
Browsing History
User ID
Device ID
Product Interaction
Advertising Data
Other Usage Data
Crash Data
Performance Data
Other Diagnostic Data
Other Data Types
Browsing History
Health
Fitness
Payment Info
Photos or Videos
Audio Data
Gameplay Content
Customer Support
Other User Content
Search History
Sensitive Info
iMessage
Email address
Phone number Search history
Device ID
The IOS Messenger disables App Protection (ATS) that can lead to insecure network connections and uses audio, fetch, location, remote-notification and void modes in background. The Android Messenger apps uses smaller than 1024 bits for signing the app and allows dynamic code loading that can be used to inject malicious code. The Android app also uses addJavaScriptInterface() that allows calling native operations from Javascript that can be used for malicious access.
Session App
Session is an open source application that uses decentralized infrastructure for messaging using decentralized storage and onion routing protocol to send end-to-end encrypted messages. It originally used Signal protocol to provide end-to-end encryption for pairwise communication and Sender Keys for group communication. However, Session recently updated its messaging app to use Session protocol instead of Signal protocol that is backward compatible with Signal protocol and provides similar guarantees for end-to-end encryption. Session guarantees Perfect Forward Secrecy (PFS) and deniability, which are further strengthened by using anonymous accounts and disappearing messages. The new Session protocol uses a long-term shared key instead of sender-key for group communication that are shared via pairwise channels and are recreated when a user leaves the group. This also helps better support for multiple devices that shares user’s long-term keypair to a new device and duplicates sent messages into their own swarm [57].
Session reduces metadata collection by using X25519 public/private keypair as identity as opposed to using phone number and using decentralized network of nodes for routing messages, which use onion protocol to hide IP-addresses of users. Session uses a network of Loki Service Node based on Loki blockchain, which itself is based on the Cryptonote protocol [20]. It uses proof-of-stake to prevent against Sybil attack and rewards service-node providers with Loke cryptocurrency that helps create a sustainable network as opposed to public networks such as Tor or I2P. The storage provided by a subset of swarm nodes on this network can be used for storing encrypted-messages when recipients are offline or sharing encrypted attachments with other members of the group. As session app does not use any centralized services, it shares prekey bundles via friend request and adds additional metadata to each message for routing purpose. Also, it uses Loki Name Service (LNS) to map keypair based identity with a short text or username that can be used to share identity with friends [42, 57].
Mobile Clients
The IOS Session app uses CommonCrypto API, Sodium, Curve25519Kit and SessionProtocolKit frameworks for crypto/DR primitivies and includes fetch and remote-notification in background mode. The IOS app also stores sensitive encryption key data in Sqlite database, which is not protected with NSFileProtectionComplete or NSFileProtectionCompleteUntilFirstUserAuthentication flags.
Signal
Signal is an open source messaging app that uses Curve25519, HMAC-SHA256, X3DH and Double Ratchet algorithm to support end-to-end encryption and forward secrecy. It uses phone number as identity and Signal server generates a random password upon installation, which is sent to Signal server with each request. It supports both direct communication between two users and group communication with multiple members.
A group message in Signal is treated as a direct message but with 128-bit group-id. The Signal app sends a message for each member of the group to Signal server for delivery. The server forwards the message and acknowledges messages from sender. The recipient acknowledges receipt to Signal server. The acknowledgements do not use end-to-end encryption [5, 18, 32]. Signal doesn’t enforce any access control for group management and any user can add members and it does not allow any user to remove other members but a member can remove herself from the group. Due to lack of any access control and validation of group membership by invitee, a malicious user can add a member and eavesdrop messages if he acquires a member’s phone number and group id. The server acknowledges messages from sender and receivers acknowledges the receipt to server but these acknowledgements are susceptible to forging. As all messages are routed through Signal server containing plaintext metadata such as sender, receiver, timestamps, IP-addresses, etc, a malicious user with access to the server can change timestamps thus affecting message order or collect metadata about relationships among users [4, 18, 48, 83].
Signal app recently added a feature “Secured Value Recovery” to upload contact list without being accessible by Signal. Signal uses Intel SGX (Software Guard Extension) to enclave data processing. However, Signal uses a low-entropy 4-digit PIN for encryption that is susceptible to dictionary attacks. Also, SGX is vulnerable to “speculative execution” side channels attacks, which can allow an attacker to extract secrets from SGX [16, 17].
Signal also uses dark pattern to automatically opt users into this cloud backup by asking users to generate PIN code without explaining the ramifications of their actions [27, 30]. Though, Signal receives favorable coverage in tech world, but it suffers from WhatsApp envy and it tends to copy dubious features from WhatsApp instead of building a trustless security and federated delivery services like email for secured communication [52]. Instead, Moxie has actively tried to stop other open source projects such as LibreSignal to use their servers [60]. Moxie also has declined collaboration with open messaging specifications such as Matrix [63]. The open source nature of Signal is also questionable because their server code hasn’t been updated for almost a year and it’s unclear what changes they have added locally [78, 83].
Mobile Clients
The IOS Signal app uses audio, fetch, remote-notification and void modes in background. The Android Signal app uses smaller than 1024 bit key for signing the app and allows dynamic code loading that can lead to malicious code injection. The Android Manifest file does not protect broadcast receivers with permissions such as Signature/SignatureorSystem that can result in data leak.
Status.im
Status is an open source messaging platform and Web 3.0 browser based on Ethereum Network and Status Network Token (STN) utility crypto-token. Status supports confidentiality, authenticity, end-to-end encryption and forward secrecy. The end-to-end encryption is implented using Double Ratchet protocol and X3DH based prekeys. The cryptographic primitives include Curve25519, AES-256-GCM, KECCAK-256, SECP256K1, ECDSA, ECIES and AES-256-CTR with HMAC-SHA-256 [55]. Status uses Swarm for decentralized storage and Whisper for peer-to-peer communication. It has recently switched to Waku for peer-to-peer communication for better scalability, spam-resistance and support for libp2p. It uses a modified Signal protocol to suit decentralized infrastructure for end-to-end encryption and mobile app also supports payments and crypto asset wallet. The users are identified by SECP256k1 public key and STN token holders can regiser their usernames to Ehereum Name Service (ENS) to make readable and recoverable access point. As Status doesn’t use phone number or email for identity, it provides better privacy and protection against censorship. Status lacks self-destructing/disappearing messages, audio and video calls. As push notifications generally requires central services, Status supports notifications while the application is running but with Whisper V5 protocol it can store offline inbox, which can also be used for decentralized push notification [43, 44, 46].
Telegram
Telegram is a closed-source messaging app that was created by Pavel Durov. Telegram uses a in-house encryption protocol as opposed to Signal protocol in most other apps, thus it has not been vetted with comprehensive security analysis. It has been found to be lacking security and privacy that it claims, e.g. an investigation by Vice found that Telegram doesn’t enable end-to-end encryption by default. It also stores chat messages in cloud that can be spied by government or spy agencies. Telegram copies all contacts from your phone to their servers for matching other Telegram users. As all outgoing messages are routed through Telegram server, it collects metadata including IP-addresses, device profile, etc that can be used to track users. Telegram was also found to be exposing users’ locations when viewing nearby users [25, 26, 40]. Researches also have found “crime-pizza†vulnerability where attacker could alter the order of messages coming from a client to the telegram server in cloud [81]. Due to its use of customized encryption protocol and implementation, severe security bugs have been found in Telegram [62, 72, 81].
Mobile Clients
The IOS Telegram app does not use App Protection (ATS) that can lead to insecure network connections and uses deprecated and insecure methods unarchiveObjectWithData / unarchiveObjectWithFile for deserialization instead of decodeObjectForKey / decodeObjectOfClass. It uses audio, fetch, location, remote-notification and voip modes in background. The Android app uses hard coded API keys including Google Maps and Android Manifest file does not protect broadcast receivers with permissions such as Signature/SignatureorSystem that can result in data leak.
Threema
Threema started as closed-source but it open sourced its messaging app recently in December 2020 under AGPLv3. Threema messaging app uses federated servers to deliver messages and distribute user keys but they don’t provide relaying messages from server to another. Threema uses a variation of Signal protocol that uses Diffie-Hellman key exchanges (DHKEs) using Curve25519, implements end-to-end encryption using XSalsa20 cipher and validates integrity using Poly1305-AES MAC. Threema limits the maximum members in a group to 50 and allows only creator to manage group membership. All group communication uses same protocol as pairwise communication except group messages are not end-to-end acknowledged. However, all group communication reuses same DHKE of their long term public keys, thus it does not provide forward secrecy. Threema orders messages by received data similar to Signal and WhatsApp, which can be forged by someone with access to Threema server [18].
WhatsApp
WhatsApp is a closed source messaging app that uses Signal protocol for pairwise communication and uses variation of sender-keys for group communication. WhatsApp uses Noise Pipes based on 128-bit Curve25519, AES-GCM and SHA256 to protect communication between client and server [38]. WhatsApp uses libsignal-protocol-c library that uses Signal key exchange protocol based on X3DH and Double Ratchet algorithm to communicate among users [37]. A group contains a unique id, a set of admins and members with max limit of 256 members. Each user generates sender-key upon joining the group that are shared with other members using pairwise channels. The group communication does not provide future secrecy as sender-keys are reused for encrypting group communication. The group’s sender-keys are rotated when a member is removed otherwise a compromised member can passively read future messages [5]. WhatsApp uses centralized servers for all group management instead of using cryptography to protect integrity of group members. As a result, server may add a member to eavesdrop on the conversation [18, 32, 35]. All outgoing messages are routed through WhatsApp server that can collect metadata, forge acknowledgements or change order of the messages. WhatsApp uses a mobile phone to identify each user and supports multiple devices per user by connecting secondary devices via QR code. The incoming message is first received by primary device and it then shares message with secondary devices using pairwise channel. The secondary devices cannot receive messages if the primary device is offline [2, 18].
As Facebook now owns WhatsApp, it now mandates sharing all metadata with Facebook such as phone numbers, contacts, profile names, profile pictures, status messages, diagnostic data, etc from phone [22, 31]. Due to widespread use of WhatsApp, a lot security companies now provide hacking tools to governments to monitor journalists or activists as reported on [28, 29, 45, 47, 54]. Apple’s privacy policies for WhatsApp now includes all metadata collected by the app, which is now shared with Facebook [50].
Mobile Clients
The Android WhatsApp uses smaller than 1024 bit key to sign the app and hard codes API keys including Google Maps and Android Manifest file does not protect broadcast receivers with permissions such as Signature/SignatureorSystem that can result in data leak.
Strengths of aforementioned Messaging Apps
Following are major strengths of the messaging apps discussed above:
Ease of Use
WhatsApp is the gold standard for ease of use and simple messaging and other apps such as Signal, Telegram and Threema also offer similar user experience.
Scalability
The messaging apps such as WhatsApp have been scaled to send 100B+ messages/day. This is biggest strength of tech giants that owns these platforms because they have built huge data centers for supporting this scale of messaging. On the other hand, these tech giants also use this infrastructure to extract as much data as they can from users and store them for marketing purpose or surveillance.
Confidentiality and Data Integrity
All of the messaging apps discussed above provide end-to-end encryption and provide reasonable data integrity. Though closed source apps such as FB Messenger, WhatsApp and Telegram cannot be fully trusted because they use servers for group administration and collect a lot of metadata that hinders data privacy.
Rapid Development
The centralized and controlled server environment allows messaging providers such as FB Messenger, WhatsApp, Signal, Telegram to rapidly develop and deploy new features. This also keeps development cycle of server side and mobile app separate as server side can be easily updated without updating mobile apps.
Weaknesses of aforementioned Messaging Apps
Following are major drawbacks of the messaging apps discussed above:
Single Point of Failure
The centralized API used by above messaging apps become a single point of failure and messaging apps cannot function without these APIs [69].
Bug Fixes
The centralized API adds dependency on the provider for fixing any bugs or updates and despite using open sourcing their code they may not accept issues or fix bugs reported by their users [75].
Walled Gardens
The popular messaging apps such as WhatsApp, FB Messenger, Signal and Threema do not use standard protocols for messaging and you cannot easily create a new client to use their services [79].
Centralized Authentication
The messaging apps discussed above either use provider account for authentication or generate an account upon installation. This account is used to authenticate all requests for message routing, contacts discovery, acknowledgements, presence, notification and other operations. This design adds dependency on the central server for sending or receiving messages and you cannot use messaging when the centralized servers are not accessible [69].
Service outage
As messaging is now part of critical communication infrastructures and any disruption in availability of data centers of messaging providers affects millions of people who cannot connect with others [68].
I think the @signalapp apps DDoS'ed the server. Servers ran over capacity due to influx of users and started to return HTTP 508 which was not handled by the app and millions of apps started retrying the connection at once. Judging from recent commits in https://t.co/KD6kS2o9wt
The messaging apps discussed above use proprietary protocols and customized APIs to lock users into their platforms. The messaging apps with large user-base such as WhatsApp, Signal and Telegram use network effect to make it harder to interact with their system from third party clients or switch to another messaging system. These messaging platforms use network effect to prevent competition and grow larger and larger with time. This is true even for open-source messaging platforms such as Signal that does not collaborate with other open messaging specifications and prohibits use of its branding for setting up federated Signal servers or use its servers from other apps such as LibreSignal [52, 60, 63].
Phone or Email as Identity
Most of messaging apps discussed above use phone or email as identity that weakens security and privacy. The requirement of having a phone number before using end-to-end encryption burdens users who don’t have a phone number or who want to use other computing devices such as tablets for messaging. They also require sharing phone numbers with other users for messaging that infringes upon user’s privacy. The phone numbers are owned by telecommunication companies that can ban users or transfer control to malicious users via SIM swapping, social engineering or other attacks. Though, messaging apps such as WhatsApp or Signal send a warning when identity keys are changed but users rarely pay attention in practice. Both Signal and WhatsApp also supports “registration PIN lock” for account recovery that requires both phone number and registration PIN code to modify identity keys, thus reducing the efficacy of PIN locks. Most countries require identity card to obtain phone number that thwarts user privacy and can be used by governments to track whistleblowers or activists [19, 20, 54]. Recent Princeton study found that five major US carriers are vulnerable to SIM-swapping attacks to gain access to victim’s phone number [32, 33].
User Data and Privacy
Big tech companies control data and privacy policies for many of these messaging apps and often integrate messaging system with other parts of their platforms such as recent changes in WhatsApp privacy policies for sharing user data with Facebook. Other messaging apps such as Signal, which recently gained a large user-base that migrated off WhatsApp lacks proper policies regarding data privacy and improper use of their services [73]. Due to low hardware cost, this user data is often stored indefinitely and is not only used for ad tracking but is also shared with law enforcement or government agencies without informing users.
Metadata Collection
Though, end-to-end encryption guarantees confidentiality of message contents so that only recipient can see the contents but the message includes metadata related to sender, receiver and timestamps, which is needed for routing, delivering or ordering of the message. The messenger services can easily tap into this metadata, Geo-location via IP-addresses of requests because all messages are relayed through their servers. This data is a liability even when the messaging systems such as Signal are not actively collecting it because any malicious user or rogue employee may scrape or leak this data.
Lack of Trustless Security
The messaging apps with centralized APIs such as WhatsApp, Signal and Telegram require trust in the company for securing data and services, which breaks basic tenant of security because truly secure systems don’t require trust [52].
Usage Statistics
A number of messaging apps with centralized servers collect aggregate user statistics such as number of messages, type of messages, Geo-location, etc that can be used to censor activists, journalists or human right defenders [23, 54].
Message Acknowledgement
Messaging apps such as WhatsApp or Signal send acknowledgement when a message is sent or received, which is not secured by the end-to-end encryption. The results of security research showed how these messages can be intercepted or forged by someone with malicious access to the servers.
Censorship
Messaging apps such as WhatsApp and Signal use phone number as identity that can be used to censor or ban users from using the messaging apps. As these apps use centralized APIs for relaying all messages, these servers can refuse to send or receive messages based on metadata from the API request such as sender, receiver, or Geo-location via IP-address. Due to centralized APIs, governments can easily disable access to the messaging servers and some apps including Signal support proxy servers but it’s implemented in leaky fashion that can be easily traced [76].
Complexity and Attack Surface
In order to excel from with other messaging apps, messaging providers have added a variety of additional features that have increased the complexity of messaging system. This complexity has become a liability for user security and privacy because it has increased the attack surface. Major security companies such as NSO Group makes millions of dollars for selling zero-day exploits that are used to decrypt messages that are supposed to be guarded by end-to-end encryption. These exploits are often used to hack, persecute or kill journalists, activists or human rights defenders [18, 45, 47, 48, 54, 66].
Closed Source or Customized implementation
Though, some of messaging apps such as Session, Signal are open source but many other apps remain close-source. An end-to-end encryption can only be trusted if the implementation is fully source-code and properly audited by an independent third party. Though, a number of messaging apps use Signal protocol for end-to-end encryption but they use a customized encryption libraries, implementation of Signal protocol and messaging protocol for authentication, communication or group management. Despite availability of open source libraries such as libsodium for encryption, olm/megolm for double-ratchet implementation, MLS standard for group chat, they have gained very little adoption in these messaging apps. As a result, there is very little interoperability among these messaging apps.
Summary of Evaluation
Following table summarizes capabilities and characteristics of messaging apps discussed above:
Following section reviews open standards for providing encrypted communication between two parties or among multiple participants in a group conversation:
Pairwise Communication Protocols
Email and PGP
Email uses SMTP (Simple Mail Transfer Protocol) for sending outgoing messages that was defined by IETF in 1982. Phil Zimmerman defined PGP (Pretty Good Privacy) in 1991 to support confidentiality, authenticity and end-to-end encryption, which was later became IETF standard in 1997 as OpenPGP. Email also supports S/MIME standard that uses a centralized public key infrastructure as opposed to decentralized architecture of PGP. There has been very little adoption of these standards despite their long history and have difficult to use in practice. Email envelop includes a lot of metadata such as sender, recipient, timestamps that can be used for tracking communication. Also, Email/PGP lacks adoption of modern cryptography algorithms and does not support future secrecy or post-compromise security [23, 41].
XMPP
XMPP (eXtensible Message and Presence Protocol) is a chat protocol that became an IETF standard in 2004. XMPP uses XML streams to support asynchronous, end-to-end exchange of data. There is an ongoing work to add end-to-end encryption to XMPP [23].
Off-the-record protocol (OTR)
OTR protocol was released in 2004 as an extension to XMPP to provide end-to-end encryption, forward secrecy and deniability. OTR is designed for synchronous communication and requires both sender and receivers to be online and it does not work for group communication or when recipients are offline [23].
Matrix
Matrix.org is an open specification for decentralized communication using JSON. It uses Olm library that implements Signal protocol for providing end-to-end encryption between two users and uses MegOlm for group chat. The Olm/MegOlm libraries use Curve25519 for generating identity keys and prekeys, Ed25519 for signing keys before upload and 3DH/Double-Ratchet algorithms for asynchronous encrypted messages [23, 24]. Matrix also provides interoperability with other protocols and can be used as a bridge to support other messaging apps [36, 65].
Open Whisper System Signal Protocol
The Signal protocol was created by Moxie Marlinspike for Open Whisper System and TextSecure messaging app to provide end-to-end encryption so that only intended recipient can see the plaintext message. It was later adopted by Signal app, WhatsApp, Google Allo (defunct), FB Messenger and other messaging apps. The Signal Protocol uses a rachet system that changes the encryption key after each message for providing forward secrecy or post-compromise security.
This protocol requires each user to generate a long-term identity key-pair, a medium-term signed prekey pair and several ephemeral keys using Curve25519 algorithm. The public keys of these pairs are packed into prekey bundle and uploaded to a Key Exchange Server/Key Distribution Center for dissemination. The prekey bundle is downloaded by other users before sending a message, which is then used to build a new session key based on message sender and recipient keys using Extended Triple Diffie-Hellman (X3DH) key agreement protocol. This protocol can work with offline users where a third party server can store and forward the messages when the user is back online.
The Signal protocol uses AES-256 for encryption and HMAC-SHA256 for validating data integrity. The X3DH generates a shared secret key from X3DH, which is used to derive “root key” and “sending chain key”. These keys are used by Double Ratchet (DR) Algorithm, which is derived from Off-the-Record protocol. The DR algorithm derives a unique message key using a key derivation function (KDF) that is then used to send and receive encrypted messages. The outputs of the DH ratchet at each stage with some additional information to advance receiving key chain are attached to each encrypted message. The “sending chain key” is advanced when a message is sent and sender derives a new “sending chain key”. Similarly, receiver advances “receiving chain key” to generate new decryption key. The “root key” is advanced upon initialization session so that each message uses new ephemeral or ratchet key that guarantees forward-secrecy and post-compromise security. The first message also attaches sender’s prekey bundle so that receiver derive the complementary session [12, 13].
OMEMO
OMEMO is an extension of XMPP develped in 2015 to provide end-to-end encryptio using Signal protocol [23].
The Messaging Layer Security (MLS) Protocol
Messaging Layer Security (MLS) is a standard protocol being built by IETF working group for providing end to end encryption. It defines specification for security context in architecture document and specification for protocol itself in protocol document. Each user publishes init keys consisting of credentials and public keys ahead of time that are handled by delivery service. There are two types of messages: handshake messages, which are control messages for group membership with global order and application messages with text/multimedia contents.
Group Messaging Protocols
Group messaging with 3+ members require additional complexity with end-to-end encryption. Each messaging app uses its own protocol for group management and communication among members. Following are some solutions that are used in messaging apps:
mpOTR
The multi-party off-the-shelf messaging (mpOTR) [3] extends OTR for providing security and deniability. It uses a number of interactive rounds of communication where all parties have to be online, which doesn’t work in presence of unreliable or mobile networks [2].
Sender-keys with Signal Protocol
Sender-keys was developed by Signal protocol and is used by a number of messaging apps such as libSignal, Whatsapp, Google Allo (defunt), FB Messenger, Session and Keybase for group messaging but it’s no longer used by Signal app. A user generates the sender-key randomly, encrypts it for each user using the pair key and then sends it to that user. As this sender key is reused for group communication and is not refreshed or removed after each message, this protocol cannot guarantee forward-secrecy or PCS. This protocol allows messenger to send a message once to their delivery server that then fans out the message to each member of the group. These messaging apps regenerate sender-key when a membership is updated, which creates O(N^2) messages for a group of size N because each member has to create a new sender key and send it to other group members. However, a bad actor in the group can eavesdrop message communication until that member is removed and sender keys are refreshed [2, 5, 18].
Open Whisper System Signal Protocol
As Signal protocol uses sender-keys for group communication, it requires encrypting and sending message for each group member, which takes O(N^2) messages for a group with size N. Also, the double ratchet algorithm is very expensive in group chat because it requires each message has to generate new session keys for each other group member. Group messaging also adds more complexity to authentication, participant consistency for group membership and ordering of messages.
The Double-Rachet does not preserve forward-secrecy or post-compromise-security (PCS) in group messaging due to high computation and bandwidth overhead and Signal messenger instead uses sender-keys in group-communication that can compromise entire group without informing the users even if a single member is compromised. Regularly, rebroadcasting sender-keys over secure pairwise channel can prevent this attack but it doesn’t scale as group size increases [1, 2].
When sending a message to group, the Signal app sends a message for each message to their delivery API that then stores and forward the message to the recipients.
Asynchronous Ratcheting Trees (ART)
Asynchronous Ratcheting Trees (ART) offers confidentiality, authenticity, strong security (PCS) with better scalability as group size increases. The ART protocol trusts initiator and in order to support asynchronicity, it supports weaker security if members are offline similar to zero round-trip mode of TLS 1.3. It uses signature to authenticate initial group message and a MAC to authenticate subsequent updates. A tree-based group DH protocol is used to manage group members and a member updates personal keys in this tree structure to guarantee PCS [2].
The Messaging Layer Security (MLS) Protocol for Groups
The MLS protocol is an IETF standard for providing asynchronous end-to-end encrypted messaging. The MLS protocol provides more efficient key change for providing end-to-end encryption with forward security and PCS for group messaging where group size can scale up to thousands of members [4]. The MLS protocol uses a rachet tree, which is a left-balanced binary tree whose leaves represent a member and intermediate nodes carry a Diffie-Hellman public key and private key [5].
Each member retains a copy of the rachet tree with public keys but private keys are shared using the rachet-tree property:
If a member M is a descendant of intermediate node N, then M knows the private key of N.
The root is labeled with shared symmetric key known to all users. The sender keys are derived using key-derivation function (KDF) from the root node’s key and the private keys are distributed to copath nodes when a member is removed [2]. Unlike signal-protocol that results in O(N^2) messages after a membership change, MLS only costs O(N) for initially adding users and O(N log N) thereafter when keys are refreshed [7].
Each group in MLS is identified by a unique ID and it keeps a epoch number or a version to track changes to the membership. The epoch number is incremented upon each change to the membership, e.g.
The MLS protocol guarantees membership consistency by including group membership in shared key derivation during key negotiations. For example, a group operation includes group-identifier, epoch number that represents version and content-type to determine the ordering requirements [4].
Casual TreeKEM
Causal TreeKEM [7] uses CRDT (Conflict-free Replicated Data Type) to improve TreeKEM by eliminating the need for a linear order on changes to group membership. The CRDTs allow replication of mutable data among group of users with the guarantee that all users see the same state regardless of the order in which updates are received. This allows building collaborative applications with end-to-end encryption. The CRDTs requires casual order to support partial order for each sender but it doesn’t require linear order. However, users cannot delete old until they have received all concurrent state change messages, which diminishes guarantees of forward secrecy.
Essential Features and Design Goals of a New Messaging System
Based on evaluation of current landscape of messaging apps and lack of adoption of open standards and decentralized architecture, this section recommends essential features and design goals for a new messaging system that can address these limitations and provide better support for decentralization, trustless security, scalability of group conversation, minimization of data collection, censorship, etc. Following sections delineate these features and design goals:
Open Protocols and Standards
Internet was designed by ARPA in 1960s to replace centralized network switches with a network of nodes. Internet defined open protocols such as TCP/UDP/IP for network communication, RIP/BGP for routing, DNS for domain name lookup, TELNET/FTP for remote access, POP3/IMAP/SMTP for emails, IRC for chat, NNTP for usenet groups. Sir Tim Berner-Lee used similar design principles for world-wide-web when he designed HTTP protocols. These protocols were designed with decentralized architecture to withstand partial failure in case of attacks by atomic bomb. For example, DNS architecture is designed as a hierarchical tree where root level node manages DNS nodes for top-level-domains (TLD), secondary authoritative TLD DNS node maintains list of authoritative DNS nodes for each domain and lower level nodes maintains subdomains.
Similarly, SMTP for email delivery uses MX record in DNS to find Message transfer agent (MTA) server and delivers the message. In addition, SMTP uses a relay protocol when target MTA is not on the same network as sender to forward the message to another MTA that keeps forwarding the message until it reaches the target MTA.
The proposed messaging system will instead use open standards and protocols similar to Email/SMTP and HTTP(s) as advocated by Protocols, Not Platforms: A Technological Approach to Free Speech. Also, in absence of open standards, de-facto industry standards such as Signal protocol will be used.
Decentralized Architecture
Previous section discussed deficiencies of centralized messaging systems such as FB Messenger, WhatsApp, Signal, Telegram, etc. The proposed messaging system will use decentralized or federated servers similar to Email/SMTP design that can relay messages from one server to another or deliver messages to recipients.
Baran, P. (1964). On Distributed Communications, Memorandum RM-3420-PR.
The decentralized architecture may need peer-to-peer communication layer such as Tor or I2P used by Briar, libp2p used by Status.im app or a network of nodes and onion routing used by Session app.
Open Source
The proposed messaging system will use open source libraries such as libsodium for encryption, olm/megolm for double-ratchet implementation, MLS standard for group chat and matrix for bridging with existing messaging systems.
Asynchronicity
Asynchronicity feature requires that users are able to send messages, share keys or manage group members when other users are offline. The decentralized storage is used as a temporary queue to store encrypted messages that are yet to be delivered. Also, users may share large attachments or media files such as pictures/videos/audios, which can be stored on the decentralized storage and then a link to the attachments are shared with other users via secure messaging. This will be further protected by symmetric encryption and decentralized identity claims to provide safe access to the shared file. A number of decentralized storage services such as IPFS, Storj, Sia, Skynet, etc are already available that can be used to build decentralized messaging.
Secrecy and Confidentiality
The proposed messaging system will guarantee secrecy and confidentiality so that only recipient user can compute the plaintext of the message when communicating in one-to-one conversation or in a group conversation.
Authenticity with Decentralized Identity
The proposed messaging system will use decentralized identity and will allow participants to validate identity of other members of conversations.
Authentication, Deniability and Non-repudiation
Deniability or deniable authentication allows conversation participants to authenticate the origin of the message but prevents either party from proving the origin of the message to a third party post-conversation. Non-repudiation is opposite of deniability and it is a legal term that provides proof of the origin of data and integrity of the data. Centralized messengers such as FB Messenger uses Authentication to prevent impersonation or deniability but public/private keypair based authentication supports deniability and it is considered a feature in protocols such as OTR, mOTR and WhatsApp. One of the ways to provide deniability is to use ephemeral signature keys when messages are signed by medium-term signature keys [7].
Data Integrity
The data integrity guarantees that data is not tempered or modified during transmission and the messaging system will use Message Authentication Code (MAC) to validate message integrity and detect any modification to the message.
Forward Secrecy and Post-Compromise Security
Forward secrecy protects former messages from being read when long-term key information is exposed. Similarly, Post-compromise security guarantees that if adversary gets hold of keys, they cannot be used to decrypt messages indefinitely after the compromise is healed. The proposed messaging system will use Signal and Message Layer Security (MLS) protocols to guarantee forward secrecy and post-compromise security. These protocols use Diffie-Hellman Exchange to establish an pre-computed/ephemeral DH prekeys for each conversation. The forward secrecy for each message is achieved by additionally using deterministic key ratcheting that derives shared key using a chain of hash functions and deletes keys after the use [10].
Minimize Metadata Collection
The decentralized architecture will protect from collecting metadata from centralized servers but proposed messaging system will further reduce any exposure to metadata by using design principles from Session app such as using self-hosted infrastructure for storing attachments, using onion routing to hide IP-addresses of users in transport message-exchange layer and using public/private keypair for identity as opposed to phone number or email address [19].
Network Anonymity
The proposed messaging system may use P2P standards such as Tor or I2P to protect metadata or routing data. For example, Pond, Ricochet, Briar provides network anonymity by using Tor network but they don’t hide metadata such as sender, receiver, timestamp, etc. The Session app protects metadata such as IP-addresses of senders and receivers using onion network [19, 23].
Message Acknowledgement
The proposed messaging system will use end-to-end encrypted messages for acknowledgement so that they cannot be intercepted or forged by someone with access to centralized server [18].
Turn off Backup
In order to guarantee robust data privacy, the messaging app will turn off any backup of chat history offered by IOS or Android APIs.
Access Control for Group Administration
A member in a group will be able to perform following actions:
Create a group and invite others to join
Update personal keys
Request to join an existing group
Leave an existing group
Send a message to members of the group
Receive a message from another member in the group
The creator of group will automatically become admin of the group but additional admins may be added who can perform other actions such as:
Add member(s) to join an existing group
Remove member(s) from an existing group
Kick a member from an existing group
A group will define set of administrators who can update the membership and will be signed by the administrator’s group signature key. Further, a group secret or ticket will be used for proof of membership so that each member verifies the ticket and guest list of group [18].
Group Communication
The proposed messaging system will use Message Layer Security (MLS) protocol and Tree-KEM based ratchet trees to manage group keys in scalable fashion and to support large groups. This will provide better support forward-secrecy in a group conversation where keys can be refreshed with O(N Log N) messages as opposed to O(N^2) messages in Signal protocol.
Multiple Devices
A user can use multiple devices where each device is considered a new client. Though, a user can add new device but that device won’t be able to access message history. The multiple devices by same user can be represented by a sub-tree under the user-node in Tree-KEM. User can publish the public key of their sub-tree as an ephemeral prekey and hide actual identity of the device so that you cannot reveal the device that triggered the update [2].
Account Recovery
The messaging app will use 12-24 words mnemonic seed to generate long-term identity keypair similar to BIP39 standard to generate deterministic wallets for Bitcoin. Alternatively, the messaging system may implement social recovery similar to Argent wallet and the Loopring wallet [61].
Monetary Incentive
Decentralized architecture requires new infrastructure for peer-to-peer communication, decentralized identity, keys management, etc. Public peer-to-peer infrastructures are not designed to handle the needs of modern messaging throughput of 100B+ messages/day. In order to scale this infrastructure, the node-runners will require a monetary incentive to expand this infrastructure. For example, a number of blockchain based projects such as Sia, Storj, and Serto use crypto rewards for providing storage or network services.
Disappearing Messages
This feature will be implemented by the mobile messaging app to automatically delete old messages in order to bolster the security in case the phone is seized or stolen.
Contacts Discovery
As contacts on the phone are generally searchable by phone number or email so they can be readily used for connecting with others on the messaging system that use Phone number or email for identity. Decentralized messaging systems that use a local a public/private keypair for identity such as Status and Session cannot use these features. Instead, they rely on a different lookup service, e.g. Session uses Loki Name Service and Status uses Ethereum Name Service to register usernames that can be used to connect with friends.
Attachments/Multimedia Messages
Small attachments and multi-media files can be embedded with the messages using the same end-to-end encryption but large attachments and multimedia files can be shared via a decentralized storage system. The large files can be uploaded with symmetric encryption that will be available for a limited time and symmetric password can be shared via exchange of encrypted messages.
Compromise of User Devices
Due to its decentralized nature, this messaging system does not suffer any security risk if decentralized authentication is compromised. All user data and keys will be stored locally and if an attacker gets hold of user or group’s private keys, he may be able to send messages impersonating as the user. However, the attacker won’t be able to access future messages if user or group’s keys are refreshed and old keys are deleted from the device.
Data Privacy Regulations
This messaging system will provide better support for the data privacy regulations such as General Data Protection Regulations (GDPR) from the EU or the California Consumer Privacy Act that allow users to control their data and privacy.
Offline Members
As forward-secrecy and post-compromise-security rely on updating member keys, an offline member will be holding old keys and thus may be susceptible to compromise.
Proposed Messaging Architecture
The architecture for building a new messaging system is largely inspired by design philosophy of Internet that was designed as decentralized to withstand nuclear attack and by vision of Sir Tim Berners-Lee for using open protocols such as SMTP, FTP, HTTP(S). The data privacy architecture is influenced by Web 3.0 architecture for building decentralized applications (DApps) that keep user data private and securely communicate with other systems using encrypted channels in a trustless fashion. As the users use increasingly powerful devices with high-bandwidth network, this architecture leverages edge computing to bring computation closer to the user device where private data is securely stored as opposed to storing this data in cloud services. However, this does not preclude storing user-data remotely as long as it’s encrypted and the owner of data can control who can access it based on privacy preferences.
Following building blocks are defined for designing this messaging system based on open standards and decentralized architecture.
High level components
Decentralized Services
The proposed messaging architecture uses following decentralized services:
Decentralized Identity
The Decentralized Identity Foundation (DIF) and the W3C Credentials Community Group are standard bodies that are building open standards for decentralized identity such as Decentralized identifiers (DID) that use public/private keypair for generating user identities. The users hold their identities in their digital wallet that can be used to control access to personal data or identity hubs, form relationships with other entities and communicate with other users. The user identity contain a decentralized identifier (DID) that resemble Uniform Resource Identifier (URI) and specifies location of service that hosts DID document, which includes additional information for identity verification [8]. A user manages access control via private keys accessible only to the user. A user may also create multiple identities for different service providers using multiple DID based identifiers and user consent is required to access claims for providing granular access control [9].
Though, using this standard is not a strict requirement for this architecture but it will be beneficial to describe user identity in a self-describing format so that dependent services can handle identity consistently.
Decentralized Key Exchange Servers
The key-exchange servers are needed to store and disseminate public keys or prekey-bundles for each user based on their identities. Each user uploads their public keys/prekey bundles when they join and updates those prekey bundles periodically when new ephemeral keys are generated. However, such a service can be breached or a malicious directory service may impersonate a user so a public log such as Key Transparency may be needed that publishes the binding between identity and keys in a public log.
Decentralized Storage
Asynchronicity feature requires that users are able to send messages, share keys or manage group members when other users are offline. The decentralized storage will be used to store encrypted messages. Also, users may share large attachments or media files such as pictures/videos/audios, which can be stored on the decentralized storage and then a link to the attachments are shared with other users via secure messaging. This will be further protected by symmetric encryption and decentralized identity claims to provide safe access to the shared file. A number of decentralized storage services such as IPFS, Storj, Sia, Skynet, etc are already available that can be used to build decentralized messaging.
Federation and Peer to Peer Communication
A decentralized system may need a peer to peer communication such as libp2p or i2p for communication. Alternatively, it may just use a federated servers similar to Email/SMTP that can route a messages from one server to another or deliver the message to a local user.
Mobile App / Desktop Client
The mobile app or desktop client will use following components to provide secured messaging:
Encryption and MLS Libraries
The mobile app will use open source encryption libraries such as as libsodium for encryption, olm/megolm for double-ratchet implementation and MLS for group communication.
Digital Wallet for Keys
The digital wallet behaves as a registry of keys, which will be created after app installation and it will securely store key-pairs and key-bundles of user, contacts and groups. This wallet will be encrypted using user’s master password and a local device password, which is automatically generated. The wallet is updated when a user updates the ephemeral keys or other members update their key-bundles. In order to satisfy post compromise security, it removes old ephemeral keys and keys of deleted group member. The messaging app will use open standards such as BIP39/BIP43 to create deterministic identity using mnemonic seed of phrases and BIP32/BIP44 for hierarchical deterministic format for storing keys so that they can be easily exported to another device by the owner. Another benefit of using these standards is that this hierarchy allows storing crypto-keys for crypto-assets and using them for payments.
Group Management
This component provides group administration such as
Create a group and invite others to join
Join an existing group
Leave an existing group
Add member(s) to join an existing group
Remove member(s) from an existing group
Status / Presence
It’s hard to sync contacts with status and presence in a decentralized architecture because no single server maintains all contacts. However, this architecture may use a Gossip Protocol that periodically exchanges presence with a subset of contacts along with other list of contacts who are known to be online.
Local Push Notification
The push notification is also hard to implement in a decentralized architecture and decentralized messaging apps such as Session supports push notification in foreground mode. Alternatively, the mobile app can wake up periodically to poll for messages in background and use a local notification to notify users when new messages arrive. However, periodic waking up the app may drain phone battery if it’s run too often.
Local Authentication
A unique device password will be automatically generated upon installation and the user will then create a master password, which will be used for local authentication. The device and master password will be used to encrypt identity, signature and ephemeral keypairs in the digital wallet. The user will be required to authenticate locally before using the app to decrypt these keys, which in turn will be used to decrypt outgoing or incoming messages.
Local Delivery Service for Message Broadcast
The delivery service in this decentralized architecture will run locally on the client side to send outgoing messages. It will use the transport layer to send messages asynchronously that may use protocol-bridge to integrate with other messaging systems or use decentralized storage to store messages when recipients are offline. The delivery service interacts with local digital wallet to encrypt outgoing messages using Signal/MLS protocols. The delivery service routes both user-messages and meta-messages that include user-invitation, changes to group membership, etc. The local delivery service also receives incoming messages, decrypt them using double-ratchet algorithm and user’s private keys in the key registry. The incoming messages are then stored in local message store for direct access from the messaging app.
Transport Message-Exchange
The transport message-exchange is a network layer for sending or receiving messages. This component only handles encrypted outgoing and incoming messages without access to private keys. If message recipients are not online, it will use decentralized storage to store and forward messages. It may use protocol bridge to support other protocols such as email/SMTP, XMPP, Matrix, Gossip Protocol, P2P, etc. to synchronize message datasets directly [13, 14].
Protocol Bridge
This component will provide interoperability with other messaging protocols and may use Matrix protocol to bridge with other messaging apps [36, 65].
Local Message Store
The local message-store stores all outgoing and incoming messages that can be viewed by user in messaging app. The local message store keeps messages secured using symmetric encryption using user’s master password and device specific password. The messages will only be displayed after local authentication. The local message-store may subscribe to local delivery service to display new messages when they are received. The user may also specify retention policy for messages to archive or remove old messages.
Local Directory of Contacts
The local directory of contacts keeps metadata about contacts and groups such as name, avatar, etc.
Messaging Adapter
The messaging adapter abstracts core messaging functionality and provides high level APIs that UI can use to manage contacts, groups or send/receive messages.
Self-Destruct Button
In order to protect user’s private data when their phone is stolen or seized, the messaging app may allow users to delete all data that can be triggered remotely using a special poison message, self-destruct timer or poison PIN [39].
High-level Applications
Decentralized messaging with end-to-end encryption is an indispensable component for building decentralized applications. A message can be used to represent data, an event or a command that can be communicated with end-to-end encryption and validate integrity of messages using digital signatures based on public/private keypair. Following section describes a few examples of such decentralized applications that can be built on top of secure messaging:
Social platforms
The social platform such as Facebook, YouTube, Twitter are facing increasingly demands to address wide spread hatred, fake news and conspiracy theories on their platform. The Communications Decency Act, Section 230 protects these platforms from being liable due to user contents but tech companies face increasing pressure to police their contents. These problems were highlighted by Mike Masnick in his article Protocols, Not Platforms: A Technological Approach to Free Speech [6]. He advocated building protocols like Internet protocols such as SMTP, IRC, NNTP and HTTP as opposed to platforms controlled by tech giants. It would delegate responsibility of tolerating speech to end users and controlling contents to the end of network. For example, ActivityPub and OpenSocial are open specification for social network platforms and a number of decentralized social platforms are already growing such as Scuttlebutt, Gurlic, Mastodon, PeerTube, Serto, Fediverse, Pixelfed, WriteFreely, Plume, Funkwhale, etc.
Source Code Management
The source code management systems such as Git or Mercurial were designed as distributed and decentralized architecture but commercial offerings such as Github, Atlassian, Gitlab hijacked them by packaging it with additional features such as code-reviews, release management, continuous integration, etc. However, as with any central control systems such services are subject to censorship, e.g.
@GitHubHelp , you blocked our entire company account after one employee opened his laptop while visiting is parents in Iran. We are completely blocked from deploying!
The decentralized identity, key management system and storage systems discussed in this paper can help revive original vision of these systems. As decentralized systems require smart clients or edge computing, many of additional features such as code-reviews can be built directly into the clients or other decentralized applications. The messaging protocol can be used to trigger an event for integration with other systems, e.g. when a source code is checked, it fires a message to the build system that kicks off build/integration, which in turn can send message(s) to developer group or other systems upon completion or failure.
Audio and Video Communication
A messaging app will be incomplete without audio and video communication but these features can be built on top of messaging protocols with end-to-end encryption.
Collaborative Tools
You can build communication / collaborative tools such as Google docs using a layer of Conflict-free Replicated Data Types (CRDTs) on top of end-to-end encryption [7].
Document Signing
The document signing features such as offered by DocuSign can be implemented using digital identities and signatures primitives used in secure messaging to sign documents safely and share these documents with other stake holders.
IoT Software/Firmware Upgrades
Despite widespread adoption of IoT devices, their software/firmware rarely use strong encryption for upgrades and can be susceptible to hacking. Instead, end-to-end encryption, signed messages by vendor and attachments can be used to securely upgrade software.
Health Privacy
The health privacy laws such as HIPAA can benefit from strong end-to-end encryption so that patients and doctors can safely communicate and share medical records.
Edge Computing
Modern consumer and IoT devices such as smart phones, tablets provide powerful processing and network capabilities that can be used to move computation closer to the devices where user data is stored safely. Edge computing will improve interaction with applications because data is available locally and will provide stronger security.
Conclusion
Secure and confidential messaging is an indispensable necessity to communicate with your family, friends and work colleagues safely. However, most popular messaging apps use centralized architecture to control access to their services. These messaging apps lack trustless security and truly secure systems don’t require trust. The tech companies running these services use network effect as a moat to prevent competition because people want to use the messaging platform that is used by their friends, thus these platforms get gigantic with time. Further, a number of messaging apps collect metadata that is integrated with other products for tracking users, marketing purpose or surveillance. This paper reviews open standards and open source libraries that can be used to build a decentralized messaging system that provides better support for data privacy, censorship, anonymity, deniability and confidentiality. It advocates using protocols rather than building platforms. Unfortunately, protocols are difficult to monetize and slow to adopt new changes so most messaging apps use centralized servers, proprietary APIs and security protocols. Using open standards and libraries will minimize security issues due to bad implementation or customized security protocols. It also helps interoperability so that users can choose any messaging app and securely communicate with their friends. Decentralized architecture prevents reliance on a single company that may cut off your access or disrupt the service due to outage. The open standards help build other decentralized applications such as communication, collaboration and payments on top of messaging. This architecture makes use of powerful devices in hands of most people to store private data instead of storing it in the cloud. Internet was built with decentralized protocols such as Email/SMTP and DNS that allows you to setup a federated server with your domain to process your requests or relay/delegate requests to other federated servers. The messaging apps such as Briar, Matrix, Session and Status already support decentralized architecture, however they have gained a little adaption due to lack of features such as VoIP and difficulty of use. This is why open standards and interoperability is critical because new messaging apps can be developed with better user experience and features. This will be challenging as decentralized systems are harder than centralized ones and security protocols or messaging standards such as Signal protocol or MLS are not specifically designed with decentralized architecture in mind. But the benefits of decentralized architecture outweigh these hardships. Just as you can choose your email provider whether it be GMail, Outlook, or other ISPs and choose any email client to read/write emails, open standards and decentralization empowers users to choose any messaging provider or client. In the end, decentralized messaging systems with end-to-end encryption provide trustless security, confidentiality, better protection of data privacy and a freedom to switch messaging providers or clients when trust of the service is broken such as recent changes to WhatsApp’s privacy policies.
References
Katriel Cohn-Gordon, Cas Cremers, and Luke Garratt. 2016. On post-compromise security. In Computer Security Foundations Symposium (CSF), 2016 IEEE 29th.IEEE, 164–178.
Ian Goldberg, Berkant Ustaoglu, Matthew Van Gundy, and Hao Chen. 2009. Multi-party off-the-record messaging. In ACM CCS 09. Ehab Al-Shaer, SomeshJha, and Angelos D. Keromytis, (Eds.) ACM Press, (Nov. 2009), 358–368.
Prince Mahajan, Srinath Setty, Sangmin Lee, Allen Clement, Lorenzo Alvisi, MikeDahlin, and Michael Walfish. Depot: Cloud storage with minimal trust.ACM Trans.Comput. Syst., 29(4):12:1–12:38, December 2011.
Joel Reardon, Alan Kligman, Brian Agala, Ian Goldberg, and David R. Cheriton.KleeQ : Asynchronous key management for dynamic ad-hoc networks. Tech report, 2007.
Paul R ?osler, Christian Mainka, and J ?org Schwenk. More is less: On the end-to-endsecurity of group chats in Signal, WhatsApp, and Threema. In2018 IEEE EuropeanSymposium on Security and Privacy (EuroSP), pages 415–429, April 2018. https://eprint.iacr.org/2017/713.pdf.
I recently wrote a series of blogs on structured concurrency (Part-I, Part-II, Part-III, Part-IV) and how it improves readability, concurrency-scope, composition and flow-control of concurrent code and adds better support for error-handling, cancellation, and timeout. I have been using GO on a number of projects over last few years and I will share a few concurrency patterns that I have used or seen in other projects such as gitlab-runner. I demonstrated in above series how structured concurrency considers GO statement harmful similar to GOTO in structured programming. Just as structured programming replaced GOTO with control-flow primitives such as single-entry/exit, if-then, loop, and functions calls; structured concurrency provides scope of concurrency where parent waits for all asynchronous code. I will show how common concurrency patterns in GO can take advantage of structured concurrency.
Asynchronous Tasks
The primary purpose of goroutines is to perform asynchronous tasks where you might be requesting a data from remote API or database, e.g. here is a sample code from gitlab-runner that uses goroutines to copy archive artifacts:
func (s *Client) Run(ctx context.Context, cmd Command) error {
...
waitCh := make(chan error)
go func() {
err := session.Wait()
if _, ok := err.(*ssh.ExitError); ok {
err = &ExitError{Inner: err}
}
waitCh <- err
}()
select {
case <-ctx.Done():
_ = session.Signal(ssh.SIGKILL)
_ = session.Close()
return <-waitCh
case err := <-waitCh:
return err
}
}
Here is a async/await based syntax based on async_await.go that performs similar task using structured concurrency:
Above code defines scope of concurrency and adds support for timeout while making the code easier to comprehend.
Note: due to lack of generics in GO, interface{} are used to accept different types that may be passed to asynchronous tasks.
Racing Asynchronous Tasks
A common use of goroutines is spawning multiple asynchronous tasks and takes result of first task that completes e.g. here is a sample code from gitlab-runner that uses goroutines to copy stdout and stderr:
stdoutErrCh := make(chan error)
go func() {
_, errCopy := stdcopy.StdCopy(output, output, hijacked.Reader)
stdoutErrCh <- errCopy
}()
// Write the input to the container and close its STDIN to get it to finish
stdinErrCh := make(chan error)
go func() {
_, errCopy := io.Copy(hijacked.Conn, input)
_ = hijacked.CloseWrite()
if errCopy != nil {
stdinErrCh <- errCopy
}
}()
// Wait until either:
// - the job is aborted/cancelled/deadline exceeded
// - stdin has an error
// - stdout returns an error or nil, indicating the stream has ended and
// the container has exited
select {
case <-ctx.Done():
err = errors.New("aborted")
case err = <-stdinErrCh:
case err = <-stdoutErrCh:
}
Above code creates stdoutErrCh channel to capture errors from stdout and stdinErrCh channel to capture errors from stderr and then waits for either to finish.
Here is equivalent code that uses structured concurrency with async/await primitives from async_racer.go:
Above code uses async/await syntax to define scope of concurrency and clarifies intent of the business logic without distraction of concurrency logic.
Performing cleanup when task is aborted or cancelled
If a goroutine spawns an external process for background work, you may need to kill that process in case goroutine task is cancelled or times out. For example, here is a sample code from gitlab-runner that calls KillAndWait function to terminate external process when context.Done() is invoked:
func (c *command) Run() error {
err := c.cmd.Start()
if err != nil {
return fmt.Errorf("failed to start command: %w", err)
}
go c.waitForCommand()
select {
case err = <-c.waitCh:
return err
case <-c.context.Done():
return newProcessKillWaiter(c.logger, c.gracefulKillTimeout, c.forceKillTimeout).
KillAndWait(c.cmd, c.waitCh)
}
}
In above, Run method starts a command in goroutine, waits for completion in another goroutine and then listens to response from waitCh and context.Done channels.
Here is how async/await structure from async_await.go can apply structured concurrency to above code:
GO channels are designed based on CSP rendezvous primitives where both sender and receiver have to wait to exchange messages. However, you can add buffering to make these channels as bounded queue (for back-pressure). Here is an example code from gitlab-runner that uses channels to stream log messages:
func (l *kubernetesLogProcessor) scan(ctx context.Context, logs io.Reader) (*bufio.Scanner, <-chan string) {
logsScanner := bufio.NewScanner(logs)
linesCh := make(chan string)
go func() {
defer close(linesCh)
// This goroutine will exit when the calling method closes the logs stream or the context is cancelled
for logsScanner.Scan() {
select {
case <-ctx.Done():
return
case linesCh <- logsScanner.Text():
}
}
}()
return logsScanner, linesCh
}
Above code creates a channel linesCh without any buffer and then creates a goroutine where logs are read and sent to linesCh channel. As I mentioned, above code will block sender until the receiver is ready to receive these log messages and you may lose log messages if receiver is slow and goroutine is killed before logs can be read. Though, structured concurrency cannot help in this case but we can simply use an event-bus or a local message-queue to stream these logs.
WaitGroup to wait for completion of goroutines
GO language supports sync.WaitGroup to wait for completion of goroutines but it’s redundant if you are also using channels to receive for reply. For example, here is a sample code from gitlab-runner that uses WaitGroup to wait for completion of groutines:
func (e *executor) waitForServices() {
...
// wait for all services to came up
if waitForServicesTimeout > 0 && len(e.services) > 0 {
wg := sync.WaitGroup{}
for _, service := range e.services {
wg.Add(1)
go func(service *types.Container) {
_ = e.waitForServiceContainer(service, time.Duration(waitForServicesTimeout)*time.Second)
wg.Done()
}(service)
}
wg.Wait()
}
}
Here is how above code can be replaced by async/await syntax from my async_await.go:
func (e *executor) waitForServices() {
...
// wait for all services to came up
if waitForServicesTimeout > 0 && len(e.services) > 0 {
ctx := context.Background()
timeout := time.Duration(waitForServicesTimeout)*time.Second
futures := make([]async.Awaiter, len(e.services))
handler := func(ctx context.Context, payload interface{}) (interface{}, error) {
return e.waitForServiceContainer(payload.(string)), nil
}
for i:=0; i<len(e.services); i++ {
futures[i] = async.Execute(ctx, handler, async.NoAbort, e.services[i])
}
async.AwaitAll(ctx, timeout, futures...)
}
}
Above code is not shorter than the original but it is more readable and eliminates subtle bugs where you might be using WaitGroup incorrectly, thus resulting in deadlock.
Fork-Join based Asynchronous Tasks
One common use of goroutines is to spawn multiple asynchronous tasks and wait for their completion similar to fork-join pattern, e.g. here is a sample code from gitlab-runner that uses goroutines to perform cleanup of multiple services and sends back result via a channel.
func (s *executor) cleanupServices() {
ch := make(chan serviceDeleteResponse)
var wg sync.WaitGroup
wg.Add(len(s.services))
for _, service := range s.services {
go s.deleteKubernetesService(service.ObjectMeta.Name, ch, &wg)
}
go func() {
wg.Wait()
close(ch)
}()
for res := range ch {
if res.err != nil {
s.Errorln(fmt.Sprintf("Error cleaning up the pod service %q: %v", res.serviceName, res.err))
}
}
}
func (s *executor) deleteKubernetesService(serviceName string, ch chan<- serviceDeleteResponse, wg *sync.WaitGroup) {
defer wg.Done()
err := s.kubeClient.CoreV1().
Services(s.configurationOverwrites.namespace).
Delete(serviceName, &metav1.DeleteOptions{})
ch <- serviceDeleteResponse{serviceName: serviceName, err: err}
}
The cleanupServices method above goes through a collection of services and then calls deleteKubernetesService in goroutine, which calls kubernetes API to remove given service. It waits for all background using WaitGroup and then receives any errors from error channel and logs them.
Here is how you can use async/await code from async_await.go that applies structured concurrency by abstracting low-level goroutines and channels:
func (s *executor) cleanupServices() {
ctx := context.Background()
timeout := time.Duration(5 * time.Second)
futures := make([]async.Awaiter, len(s.services))
handler := func(ctx context.Context, payload interface{}) (interface{}, error) {
serviceName := payload.(string)
err := s.kubeClient.CoreV1().
Services(s.configurationOverwrites.namespace).
Delete(serviceName, &metav1.DeleteOptions{})
return nil, err
}
for i:=0; i<len(s.services); i++ {
futures[i] = async.Execute(ctx, handler, async.NoAbort, s.services[i])
}
results := async.AwaitAll(ctx, timeout, futures...)
for res := range results {
if res.Err != nil {
s.Errorln(fmt.Sprintf("Error cleaning up the pod service %q: %v", res.serviceName, res.Err))
}
}
}
Above code uses structured concurrency by defining scope of asynchronous code in cleanupServices and adds better support for cancellation, timeout and error handling. Also, you don’t need to use WaitGroup to wait for completion anymore.
Polling Asynchronous Task
In some cases, you may need to poll a background task to check its status or wait for its completion, e.g. here is a sample code from gitlab-runner that waits for pod until it’s running:
func waitForPodRunning(
ctx context.Context,
c *kubernetes.Clientset,
pod *api.Pod,
out io.Writer,
config *common.KubernetesConfig,
) (api.PodPhase, error) {
pollInterval := config.GetPollInterval()
pollAttempts := config.GetPollAttempts()
for i := 0; i <= pollAttempts; i++ {
select {
case r := <-triggerPodPhaseCheck(c, pod, out):
if !r.done {
time.Sleep(time.Duration(pollInterval) * time.Second)
continue
}
return r.phase, r.err
case <-ctx.Done():
return api.PodUnknown, ctx.Err()
}
}
return api.PodUnknown, errors.New("timed out waiting for pod to start")
}
func triggerPodPhaseCheck(c *kubernetes.Clientset, pod *api.Pod, out io.Writer) <-chan podPhaseResponse {
errc := make(chan podPhaseResponse)
go func() {
defer close(errc)
errc <- getPodPhase(c, pod, out)
}()
return errc
}
The waitForPodRunning method above repeatedly calls triggerPodPhaseCheck, which creates a goroutine and then invokes kubernetes API to get pod status. It then returns pod status in a channel that waitForPodRunning listens to.
Here is equivalent code using async/await from async_polling.go:
Above code removes complexity due to manually polling and managing goroutines/channels.
Background Task with watchdog
Another concurrency pattern in GO involves starting a background task but then launch another background process to monitor the task or its runtime environment so that it can terminate background task if watchdog finds any errors. For example, here is a sample code from gitlab-runner that executes a command inside kubernetes pod and then it launches another goroutine to monitor pod status, i.e.,
func (s *executor) runWithAttach(cmd common.ExecutorCommand) error {
...
ctx, cancel := context.WithCancel(cmd.Context)
defer cancel()
containerName = ...
containerCommand = ...
...
podStatusCh := s.watchPodStatus(ctx)
select {
case err := <-s.runInContainer(containerName, containerCommand):
s.Debugln(fmt.Sprintf("Container %q exited with error: %v", containerName, err))
var terminatedError *commandTerminatedError
if err != nil && errors.As(err, &terminatedError) {
return &common.BuildError{Inner: err, ExitCode: terminatedError.exitCode}
}
return err
case err := <-podStatusCh:
return &common.BuildError{Inner: err}
case <-ctx.Done():
return fmt.Errorf("build aborted")
}
}
func (s *executor) watchPodStatus(ctx context.Context) <-chan error {
// Buffer of 1 in case the context is cancelled while the timer tick case is being executed
// and the consumer is no longer reading from the channel while we try to write to it
ch := make(chan error, 1)
go func() {
defer close(ch)
t := time.NewTicker(time.Duration(s.Config.Kubernetes.GetPollInterval()) * time.Second)
defer t.Stop()
for {
select {
case <-ctx.Done():
return
case <-t.C:
err := s.checkPodStatus()
if err != nil {
ch <- err
return
}
}
}
}()
return ch
}
func (s *executor) runInContainer(name string, command []string) <-chan error {
errCh := make(chan error, 1)
go func() {
defer close(errCh)
...
retryable := retry.New(retry.WithBuildLog(&attach, &s.BuildLogger))
err := retryable.Run()
if err != nil {
errCh <- err
}
exitStatus := <-s.remoteProcessTerminated
if *exitStatus.CommandExitCode == 0 {
errCh <- nil
return
}
errCh <- &commandTerminatedError{exitCode: *exitStatus.CommandExitCode}
}()
return errCh
}
In above code, runWithAttach calls watchPodStatus to monitor status of the pod in background goroutine and then executes command in runInContainer.
Above code removes extraneous complexity due to concurrent code embedded with functional code and makes it easier to comprehend with improved support of concurrency scope, error handling, timeout and cancellation.
Other accidental complexity in Gitlab-Runner
Besides concurrency, here are a few other design choices that adds accidental complexity in gitlab-runner:
Abstraction
The primary goal of gitlab-runner is to abstract executor framework so that it can use different platforms such as Docker, Kubernetes, SSH, Shell, etc to execute processes. However, it doesn’t define an interface for common behavior such as managing runtime containers or executing a command for these executors.
Adapter/Gateway pattern
A common pattern to abstract third party library or APIs is to use an adapter or gateway pattern but gitlab-runner mixes external APIs with internal executor logic. The kubernetes executor in gitlab-runner defines logic for both interacting with external Kubernetes server and managing Kubernetes Pod or executing processes inside those pods. For example, my initial intent for looking at the gitlab-runner was to adopt APIs for interacting with Kubernetes but I could not reuse any code as a library and instead I had to copy relevant code for my use-case.
Separation of Concerns
The gitlab-runner is not only riddled with concurrency related primitives such as goroutines and channels but it also mixes other aspects such as configuration, feature-flags, logging, monitoring, etc. For example, it uses configurations for defining containers, services, volumes for Kubernetes but it hard codes various internal configurations for build, helpers, monitoring containers instead of injecting them via external configuration. Similarly, it hard codes volumes for repo, cache, logging, etc. A common design pattern in building software is to use layers of abstractions or separation of concerns where each layer or a module is responsible for a single concern (single-responsibility principle). For example, you can divide executors into three layers: adapter-layer, middle-layer and high-level layer where adapter layer strictly interacts with underlying platform such as Kubernetes and no other layer needs to know internal types or APIs of Kubernetes. The middle layer uses adapter layer to delegate any executor specific behavior and defines methods to configure containers. The high-level layer is responsible for injecting dependent services, containers and configurations to execute jobs within the gitlab environment. I understand some of these abstractions might become leaky if there are significant differences among executors but such design allows broader reuse of lower-level layers in other contexts.
Summary
Though, modern scalable and performant applications demand concurrency but sprinkling low-level concurrency patterns all over your code adds significant accidental or extraneous complexity to your code. In this blog, I demonstrated how encapsulating concurrent code with library of structured concurrency patterns can simplify your code. Concurrency is hard especially with lower-level primitives such as WaitGroup, Mutex, goroutines, channels in GO. In addition, incorrect use of these concurrency primitives can lead to deadlocks or race conditions. Using a small library for abstracting common concurrency patterns can reduce probability of concurrency related bugs. Finally, due to lack of immutability, strong ownership, generics or scope of concurrency in GO, you still have to manage race conditions and analyze your code carefully for deadlocks but applying structured concurrency can help manage concurrent code better.
In this fourth part of the series on structured concurrency (Part-I, Part-II, Part-III, Swift-Followup), I will review Kotlin and Swift languages for writing concurrent applications and their support for structured concurrency:
Kotlin
Kotlin is a JVM language that was created by JetBrains with improved support of functional and object-oriented features such as extension functions, nested functions, data classes, lambda syntax, etc. Kotlin also uses optional types instead of null references similar to Rust and Swift to remove null-pointer errors. Kotlin provides native OS-threads similar to Java and coroutines with async/await syntax similar to Rust. Kotlin brings first-class support for structured concurrency with its support for concurrency scope, composition, error handling, timeout/cancellation and context for coroutines.
Structured Concurrency in Kotlin
Kotlin provides following primitives for concurrency support:
suspend functions
Kotlin adds suspend keyword to annotate a function that will be used by coroutine and it automatically adds continuation behavior when code is compiled so that instead of return value, it calls the continuation callback.
Launching coroutines
A coroutine can be launched using launch, async or runBlocking, which defines scope for structured concurrency. The lifetime of children coroutines is attached to this scope that can be used to cancel children coroutines. The async returns a Deferred (future) object that extends Job. You use await method on the Deferred instance to get the results.
Dispatcher
Kotlin defines CoroutineDispatcher to determine thread(s) for running the coroutine. Kotlin provides three types of dispatchers: Default – that are used for long-running asynchronous tasks; IO – that may use IO/network; and Main – that uses main thread (e.g. on Android UI).
Channels
Kotlin uses channels for communication between coroutines. It defines three types of channels: SendChannel, ReceiveChannel, and Channel. The channels can be rendezvous, buffered, unlimited or conflated where rendezvous channels and buffered channels behave like GO’s channels and suspend send or receive operation if other go-routine is not ready or buffer is full. The unlimited channel behave like queue and conflated channel overwrites previous value when new value is sent. The producer can close send channel to indicate end of work.
Using async/await in Kotlin
Following code shows how to use async/await to build the toy web crawler:
package concurrency
import concurrency.domain.Request
import concurrency.domain.Response
import concurrency.utils.CrawlerUtils
import kotlinx.coroutines.*
import org.slf4j.LoggerFactory
import java.util.concurrent.atomic.AtomicInteger
class CrawlerWithAsync(val maxDepth: Int, val timeout: Long) : Crawler {
private val logger = LoggerFactory.getLogger(CrawlerWithCoroutines::class.java)
val crawlerUtils = CrawlerUtils(maxDepth)
// public method for crawling a list of urls using async/await
override fun crawl(urls: List<String>): Response {
var res = Response()
// Boundary for concurrency and it will not return until all
// child URLs are crawled up to MAX_DEPTH limit.
runBlocking {
res.childURLs = crawl(urls, 0).childURLs
}
return res
}
suspend private fun crawl(urls: List<String>, depth: Int): Response {
var res = Response()
if (depth >= maxDepth) {
return res.failed("Max depth reached")
}
var size = AtomicInteger()
withTimeout(timeout) {
val jobs = mutableListOf<Deferred<Int>>()
for (u in urls) {
jobs.add(async {
val childURLs = crawlerUtils.handleCrawl(Request(u, depth))
// shared
size.addAndGet(crawl(childURLs, depth + 1).childURLs + 1)
})
}
for (j in jobs) {
j.await()
}
}
return res.completed(size.get())
}
}
In above example, CrawlerWithAsync class defines timeout parameter for crawler. The crawl function takes list of URLs to crawl and defines high-level scope of concurrency using runBlocking. The private crawl method is defined as suspend so that it can be used as continuation. It uses async with timeout to start background tasks and uses await to collect results. This method recursively calls handleCrawl to crawl child URLs.
Following unit tests show how to test above crawl method:
package concurrency
import org.junit.Test
import org.slf4j.LoggerFactory
import kotlin.test.assertEquals
class CrawlerAsynTest {
private val logger = LoggerFactory.getLogger(CrawlerWithCoroutinesTest::class.java)
val urls = listOf("a.com", "b.com", "c.com", "d.com", "e.com", "f.com",
"g.com", "h.com", "i.com", "j.com", "k.com", "l.com", "n.com")
@Test
fun testCrawl() {
val crawler = CrawlerWithAsync(4, 1000L)
val started = System.currentTimeMillis()
val res = crawler.crawl(urls);
val duration = System.currentTimeMillis() - started
logger.info("CrawlerAsync - crawled %d urls in %d milliseconds".format(res.childURLs, duration))
assertEquals(19032, res.childURLs)
}
@Test(expected = Exception::class)
fun testCrawlWithTimeout() {
val crawler = CrawlerWithAsync(1000, 100L)
crawler.crawl(urls);
}
}
Following are major benefits of using this approach to implement crawler and its support of structured concurrency:
The main crawl method defines high level scope of concurrency and it waits for the completion of child tasks.
Kotlin supports cancellation and timeout APIs and the crawl method will fail with timeout error if crawling exceeds the time limit.
The crawl method captures error from async response and returns so that client code can perform error handling.
The async syntax in Kotlin allows easy composition of asynchronous code.
Kotlin allows customized dispatcher for more control on the asynchronous behavior.
Following are shortcomings using this approach for structured concurrency and general design:
As Kotlin doesn’t enforce immutability by default, you will need synchronization to protect shared state.
Async/Await support is still new in Kotlin and lacks stability and proper documentation.
Above design creates a new coroutine for crawling each URL and it can strain expensive network and IO resources so it’s not practical for real-world implementation.
Using coroutines in Kotlin
Following code uses coroutine syntax to implement the web crawler:
package concurrency
import concurrency.domain.Request
import concurrency.domain.Response
import concurrency.utils.CrawlerUtils
import kotlinx.coroutines.coroutineScope
import kotlinx.coroutines.runBlocking
import kotlinx.coroutines.withTimeout
import org.slf4j.LoggerFactory
import java.util.concurrent.atomic.AtomicInteger
class CrawlerWithCoroutines(val maxDepth: Int, val timeout: Long) : Crawler {
private val logger = LoggerFactory.getLogger(CrawlerWithCoroutines::class.java)
val crawlerUtils = CrawlerUtils(maxDepth)
// public method for crawling a list of urls using coroutines
override fun crawl(urls: List<String>): Response {
var res = Response()
// Boundary for concurrency and it will not return until all
// child URLs are crawled up to MAX_DEPTH limit.
runBlocking {
res.childURLs = crawl(urls, 0).childURLs
}
return res
}
suspend private fun crawl(urls: List<String>, depth: Int): Response {
var res = Response()
if (depth >= maxDepth) {
return res.failed("Max depth reached")
}
var size = AtomicInteger()
withTimeout(timeout) {
for (u in urls) {
coroutineScope {
val childURLs = crawlerUtils.handleCrawl(Request(u, depth))
// shared
size.addAndGet(crawl(childURLs, depth + 1).childURLs + 1)
}
}
}
return res.completed(size.get())
}
}
Above example is similar to async/await but uses coroutine syntax and its behavior is similar to async/await implementation.
Following example shows how async coroutines can be cancelled:
package concurrency
import concurrency.domain.Request
import concurrency.domain.Response
import concurrency.utils.CrawlerUtils
import kotlinx.coroutines.Deferred
import kotlinx.coroutines.async
import kotlinx.coroutines.runBlocking
import kotlinx.coroutines.withTimeout
import org.slf4j.LoggerFactory
import java.util.concurrent.atomic.AtomicInteger
class CrawlerCancelable(val maxDepth: Int, val timeout: Long) : Crawler {
private val logger = LoggerFactory.getLogger(CrawlerWithCoroutines::class.java)
val crawlerUtils = CrawlerUtils(maxDepth)
// public method for crawling a list of urls to show cancel operation
// internal method will call cancel instead of await so this method will
// fail.
override fun crawl(urls: List<String>): Response {
var res = Response()
// Boundary for concurrency and it will not return until all
// child URLs are crawled up to MAX_DEPTH limit.
runBlocking {
res.childURLs = crawl(urls, 0).childURLs
}
return res
}
////////////////// Internal methods
suspend private fun crawl(urls: List<String>, depth: Int): Response {
var res = Response()
if (depth >= maxDepth) {
return res.failed("Max depth reached")
}
var size = AtomicInteger()
withTimeout(timeout) {
val jobs = mutableListOf<Deferred<Int>>()
for (u in urls) {
jobs.add(async {
val childURLs = crawlerUtils.handleCrawl(Request(u, depth))
// shared
size.addAndGet(crawl(childURLs, depth + 1).childURLs + 1)
})
}
for (j in jobs) {
j.cancel()
}
}
return res.completed(size.get())
}
}
Swift was developed by Apple to replace Objective-C and offer modern features such as closures, optionals instead of null-pointers (similar to Rust and Kotlin), optionals chaining, guards, value types, generics, protocols, algebraic data types, etc. It uses same runtime system as Objective-C and uses automatic-reference-counting (ARC) for memory management, grand-central-dispatch for concurrency and provides integration with Objective-C code and libraries.
Structured Concurrency in Swift
I discussed concurrency support in Objective-C in my old blog [1685] such as NSThread, NSOperationQueue, Grand Central Dispatch (GCD), etc and since then GCD has improved launching asynchronous tasks using background queues with timeout/cancellation support. However, much of the Objective-C and Swift code still suffers from callbacks and promises hell discussed in Part-I. Chris Lattner and Joe Groff wrote a proposal to add async/await and actor-model to Swift and provide first-class support for structured concurrency. As this work is still in progress, I wasn’t able to test it but here are major features of this proposal:
Coroutines
Swift will adapt coroutines as building blocks of concurrency and asynchronous code. It will add syntactic sugar for completion handlers using async or yield keywords.
Async/Await
Swift will provide async/await syntactic sugar on top of coroutines to mark asynchronous behavior. The async code will use continuations similar to Kotlin so that it suspends itself and schedules execution by controlling context. It will use Futures (similar to Deferred in Kotlin) to await for the results (or errors). This syntax will work with normal error handling in Swift so that errors from asynchronous code are automatically propagated to the calling function.
Actor model
Swift will adopt actor-model with value based messages (copy-on-write) to manage concurrent objects that can receive messages asynchronously and the actor can keep internal state and eliminate race conditions.
Kotlin and Swift are very similar in design and both have first-class support of structured concurrency such as concurrency scope, composition, error handling, cancellation/timeout, value types, etc. Both Kotlin and Swift use continuation for async behavior so that async keyword suspends the execution and passes control to the execution context so that it can be executed asynchronously and control is passed back at the end of execution.
Structured Concurrency Comparison
Following table summarizes support of structured concurrency discussed in this blog series:
Feature
Typescript (NodeJS)
Erlang
Elixir
GO
Rust
Kotlin
Swift
Structured scope
Built-in
manually
manually
manually
Built-in
Built-in
Built-in
Asynchronous Composition
Yes
No
No
No
Yes
Yes
Yes
Error Handling
Natively using Exceptions
Manually storing errors in Response
Manually storing errors in Response
Manually storing errors in Response
Manually using Result ADT
Natively using Exceptions
Natively using Exceptions
Cancellation
Cooperative Cancellation
Built-in Termination or Cooperative Cancellation
Built-in Termination or Cooperative Cancellation
Built-in Cancellation or Cooperative Cancellation
Built-in Cancellation or Cooperative Cancellation
Built-in Cancellation or Cooperative Cancellation
Built-in Cancellation or Cooperative Cancellation
Timeout
No
Yes
Yes
Yes
Yes
Yes
Yes
Customized Execution Context
No
No
No
No
No
Yes
Yes
Race Conditions
No due to NodeJS architecture
No due to Actor model
No due to Actor model
Possible due to shared state
No due to strong ownership
Possible due to shared state
Possible due to shared state
Value Types
No
Yes
Yes
Yes
Yes
Yes
Yes
Concurrency paradigms
Event loop
Actor model
Actor model
Go-routine, CSP channels
OS-Thread, coroutine
OS-Thread, coroutine, CSP channels
OS-Thread, GCD queues, coroutine, Actor model
Type Checking
Static
Dynamic
Dynamic
Static but lacks generics
Strongly static types with generics
Strongly static types with generics
Strongly static types with generics
Suspends Async code using Continuations
No
No
No
No
Yes
Yes
Yes
Zero-cost based abstraction ( async)
No
No
No
No
Yes
No
No
Memory Management
GC
GC (process-scoped)
GC (process-scoped)
GC
(Automated) Reference counting, Boxing
GC
Automated reference counting
Performance Comparison
Following table summarizes runtime of various implementation of web crawler when crawling 19K URLs that resulted in about 76K messages to asynchronous methods/coroutines/actors discussed in this blog series:
Language
Design
Runtime (secs)
Typescript
Async/Await
0.638
Erlang
Spawning Process
4.636
Erlang
PMAP
4.698
Elixir
Spawning OTP Children
43.5
Elixir
Task async/await
187
Elixir
Worker-pool with queue
97
GO
Go-routine/channels
1.2
Rust
Async/Await
4.3
Kotlin
Async/Await
0.736
Kotlin
Coroutine
0.712
Swift
Async/Await
63
Swift
Actors/Async/Await
65
Note: The purpose of above results was not to run micro-benchmarks but to show rough cost of spawning thousands of asynchronous tasks.
Summary
Overall, Typescript/NodeJS provides a simpler model for concurrency but lacks proper timeout/cancellation support and it’s not suitable for highly concurrent applications that require blocking APIs. The actor based concurrency model in Erlang/Elixir supports high-level of concurrency, error handling, cancellation and isolates process state to prevent race conditions but it lacks composing asynchronous behavior natively. Though, you can compose Erlang processes with parent-child hierarchy and easily start or stop these processes. GO supports concurrency via go-routines and channels with built-in cancellation and timeout APIs but GO statements are considered harmful by structured concurrency and it doesn’t protect against race conditions due to mutable state. Erlang and GO are the only languages that were designed from ground-up with support for actors and coroutines and their schedulers have strong support for asynchronous IO and non-blocking APIs. Erlang also offers process-scoped garbage collection to clean up related data easily as opposed to global GC in other languages. The async/await support in Rust is still immature and lacks proper support of cancellation but strong ownership properties of Rust eliminate race conditions and allows safe concurrency. Rust, Kotlin and Swift uses continuation for async/await that allows composition for multiple async/await chained together. For example, instead of using await (await download()).parse() in Javascript/Typescript/C#, you can use await download().parse(). The async/await changes are still new in Kotlin and lack stability whereas Swift has not yet released these changes as part of official release. As Kotlin, Rust, and Swift built coroutines or async/await on top of existing runtime and virtual machine, their green-thread schedulers are not as optimal as schedulers in Erlang or GO and may exhibit limitations on concurrency and scalability.
Finally, structured concurrency helps your code structure with improved data/control flow, concurrency scope, error handling, cancellation/timeout and composition but it won’t solve data races if multiple threads/coroutines access mutable shared data concurrently so you will need to rely on synchronization mechanisms to protect the critical section.
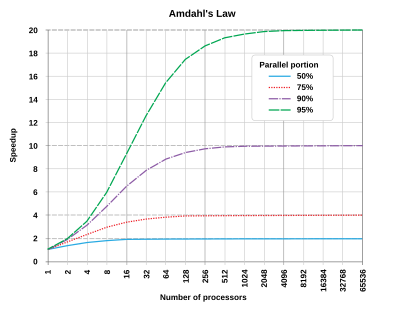


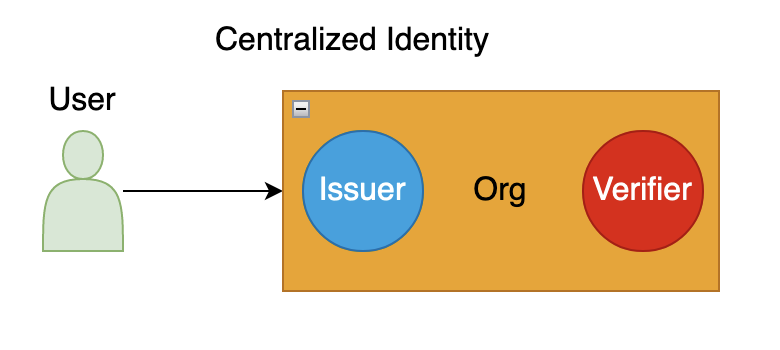

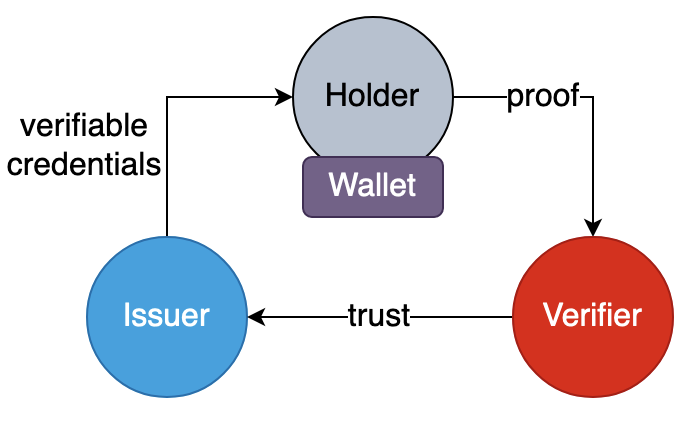
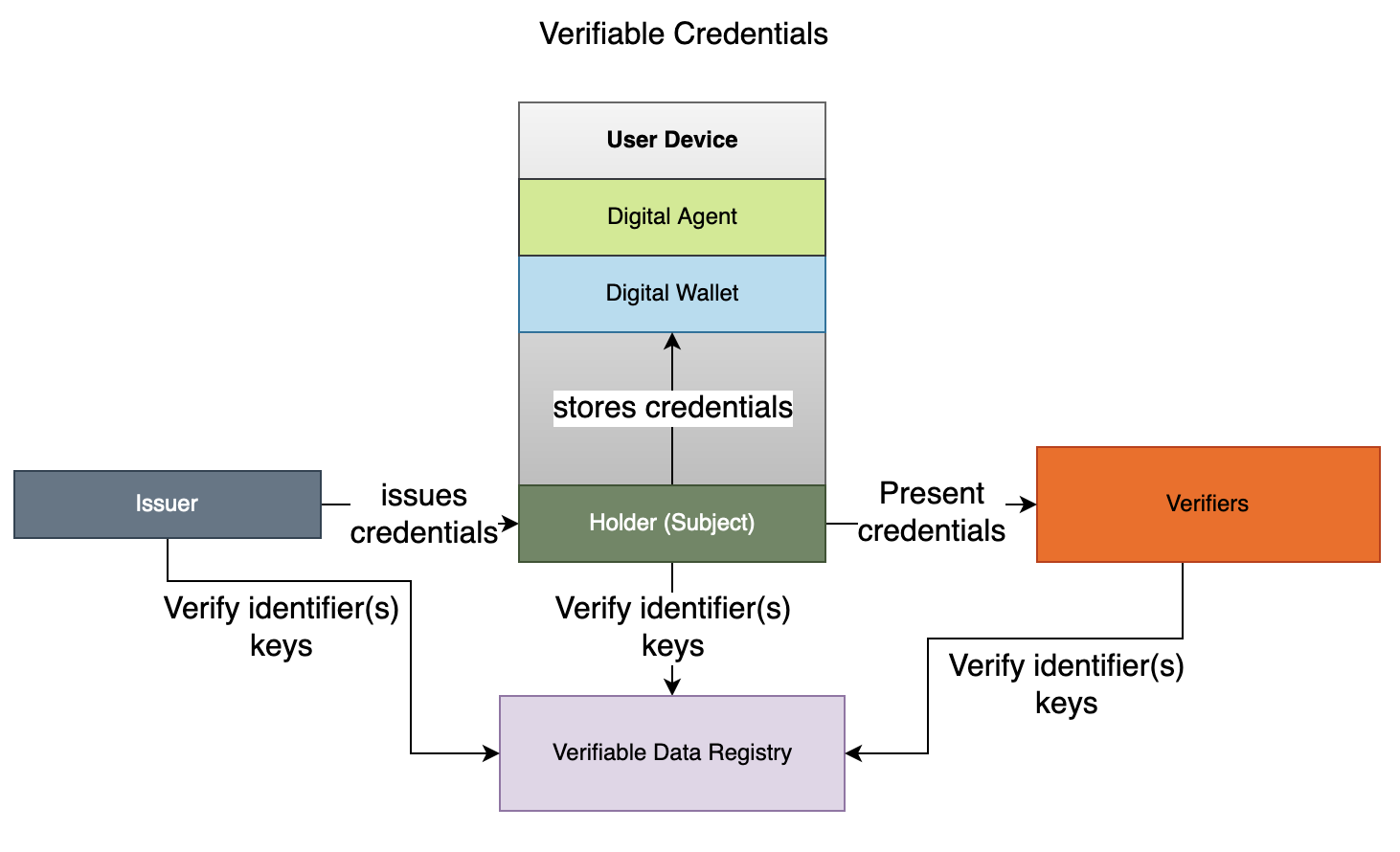
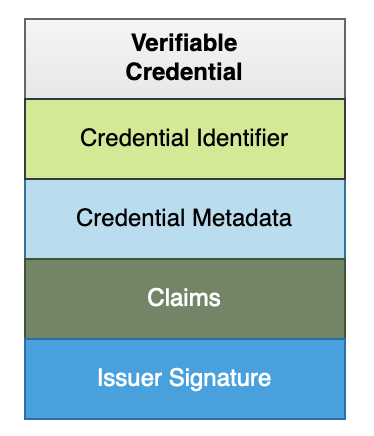
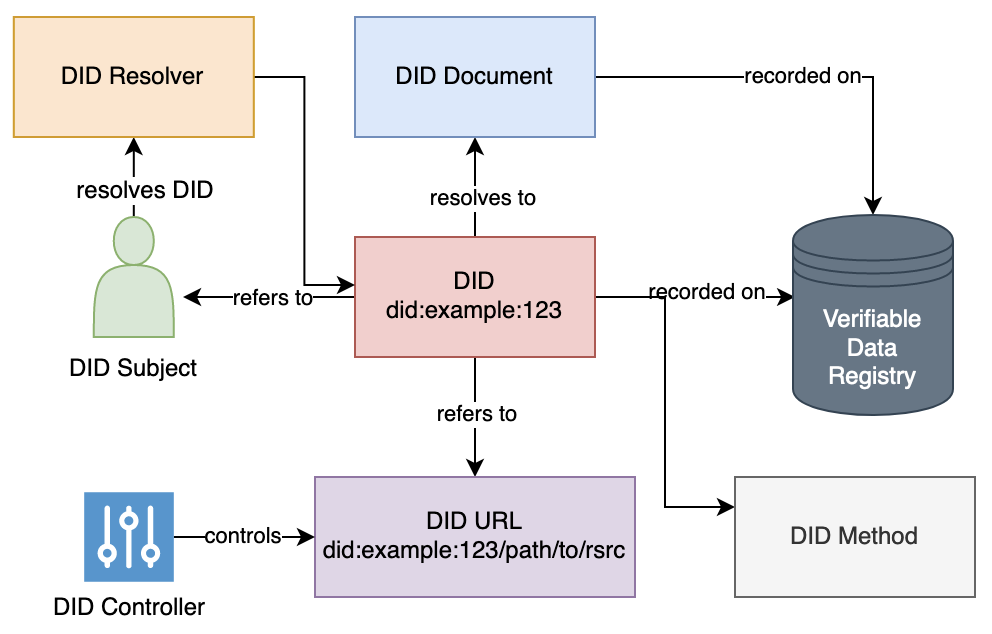






. On Distributed Communications, Memorandum RM-3420-PR.")
. On Distributed Communications, Memorandum RM-3420-PR.")