Introduction
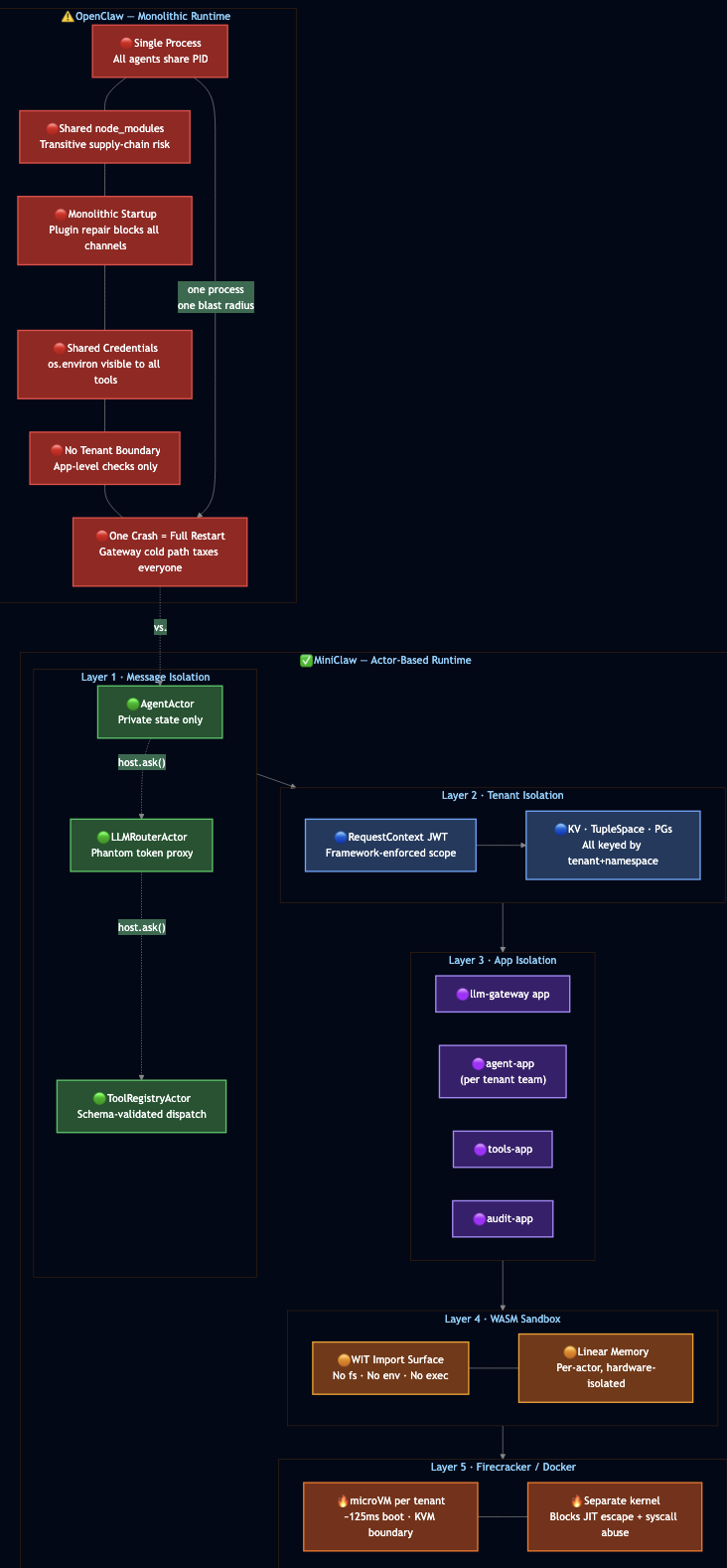
Most agent frameworks start simple: one process, one conversation loop, one tool registry, one memory store, and one pile of credentials. That simplicity is useful for demos, but dangerous for enterprise systems. If a prompt injection reaches a tool with broad permissions, the whole runtime becomes part of the blast radius (see https://arxiv.org/abs/2403.02691). If one tool call hangs or crashes, it can stall the agent loop. If memory and sessions are shared by convention instead of isolated by construction, tenant boundaries depend on every developer remembering every guardrail every time. Enterprise teams need a different foundation. They need agents that isolate state, limit blast radius, enforce tenant boundaries, and recover from failures without operator intervention. They need the same properties that telecom systems have delivered for four decades: per-process isolation, supervision trees, guardian processes, and location-transparent messaging.
This post shows how I built Mini OpenClaw as a proof of concept implementation that runs entirely on PlexSpaces, an actor-based distributed runtime inspired by Erlang/OTP. OpenClaw-style systems are useful because they give developers a programmable agent runtime: tools, memory, planning, execution, and orchestration. MiniClaw keeps that spirit, but changes the failure and security model. Instead of one runtime owning everything, each responsibility becomes an actor with its own state, permissions, lifecycle, and supervision boundary. MiniClaw deploys ten actors inside a WebAssembly + Firecracker sandbox to deliver a secure, fault-tolerant agent system. Every actor owns its state exclusively. Every message travels through explicit channels and every failure triggers a supervised restart instead of full-system crash.
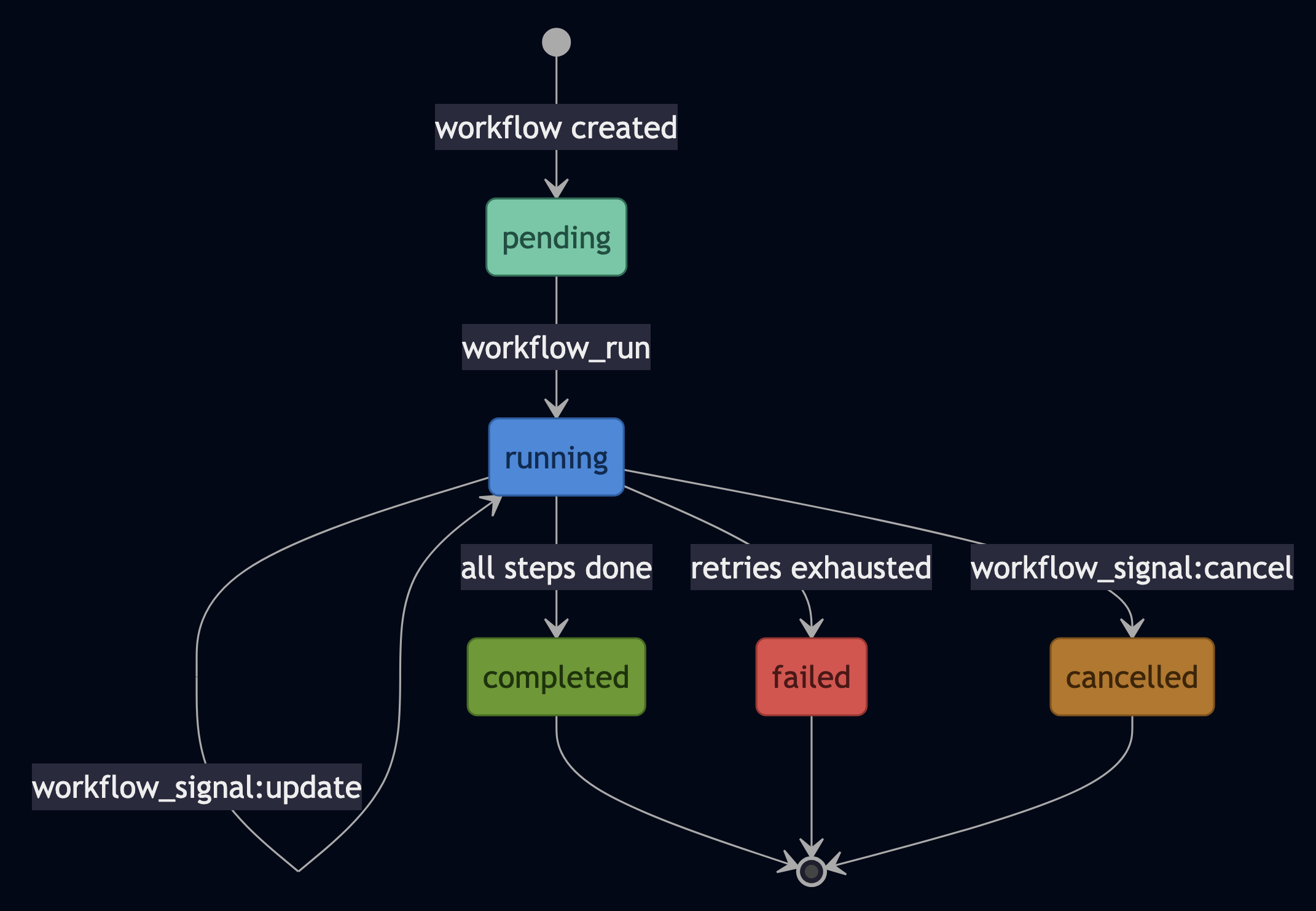
OpenClaw’s 2026.4.29 release triggered plugin dependency repair loops at startup and cold paths due to monolithic core owns too many responsibilities. MiniClaw starts from the opposite position: every responsibility is an actor from the beginning, with its own state, and its own explicit message contract.
Part 1: Agents and Actors Isomorphism
1.1 The Same Computational Model
An LLM agent has four things: state (conversation history, tool results), a processing loop (receive message, reason, act), communication (call tools, delegate to other agents), and failure modes (timeouts, hallucinations, rate limits). An actor has exactly the same structure. This is not a coincidence. Both actors and agents derive from the same computational model, isolated units of stateful computation that communicate by passing messages.
# From examples/python/apps/miniclaw/agent.py
# An agent IS an actor same structure, same guarantees
# For readability, this POC keeps message history directly on the `AgentActor`.
# In a production deployment, I would usually run one actor instance per session or
# store history by `session_id` to avoid cross-session context mixing.
@actor
class AgentActor:
"""Core agent: receive user message, call LLM, execute tools, loop until end_turn."""
system_prompt: str = state(default="You are a helpful AI assistant with access to tools.")
messages: list = state(default_factory=list) # Conversation state
max_history: int = state(default=50) # Context window bound
total_chats: int = state(default=0) # Usage counter
agent_name: str = state(default="general-assistant")
@init_handler
def on_init(self, config: dict) -> None:
args = config.get("args", {})
self.agent_name = args.get("agent_name", self.agent_name)
self.system_prompt = args.get("system_prompt", self.system_prompt)
host.process_groups.join("svc:agent") # Announces itself for discovery
write_actor_info(self.actor_id, self.agent_name,
"Core agent loop with tool calling and session memory",
["chat", "tool_use", "memory"])
@handler("chat")
def chat(self, message: str = "", session_id: str = "") -> dict:
# Agent processing loop: receive message -> reason -> act
...The mapping is direct. Every agent concept has an actor primitive:
| Agent Concept | Actor Primitive | MiniClaw Implementation |
|---|---|---|
| Conversation history | Actor-private state | messages: list (serialized, isolated) |
| Tool calling | Inter-actor messaging | ask(tool_reg_id, "execute_tool", ...) |
| Agent delegation | Location-transparent Ask | ask(agent_id, "chat", ...) via process groups |
| Crash recovery | Supervisor restart + durability facet | State checkpointed to SQLite, restored on restart |
| Rate limiting | Per-actor circuit breaker state | circuit_open, consecutive_failures in actor state |
| Memory | Scoped KV + TupleSpace | Global/agent/session scopes via MemoryActor |
| Audit trail | Fire-and-forget GenEvent | host.send(audit_id, "log_event", ...) — non-blocking |
1.2 Four Behaviors Map to Four Agent Archetypes
PlexSpaces provides four actor behaviors. Each maps to a distinct agent archetype:
| Behavior | Agent Archetype | MiniClaw Actor | Decorator |
|---|---|---|---|
| GenServer | Tool executor, stateful helper | AgentActor, LLMRouterActor, ToolRegistryActor, MemoryActor, SessionManagerActor, TaskQueueActor, HealthMonitorActor | @actor |
| GenEvent | Audit logger, event publisher | AuditEventActor | @event_actor |
| GenStateMachine | State-machine agent, quality gate | AgentStateFSM | @fsm_actor(states=[...], initial="idle") |
| Workflow | Orchestrator, pipeline coordinator | OrchestratorActor | @workflow_actor |

Part 2: PlexSpaces Primitives
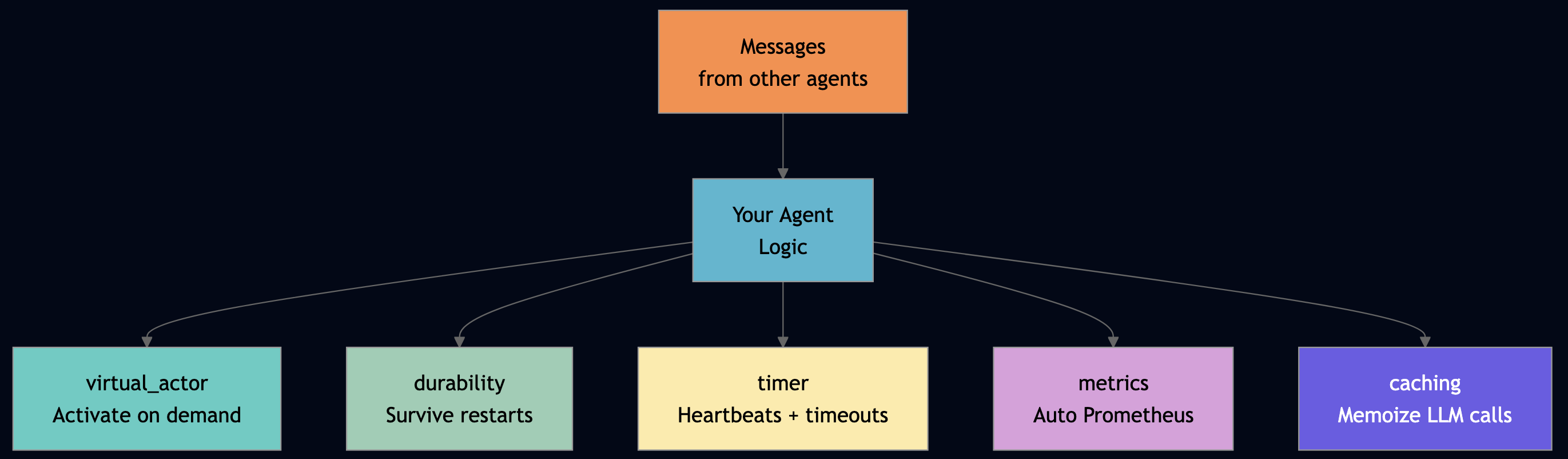
Before walking through each actor, it helps to see the five low-level primitives that every actor uses. These are the only operations available inside the WASM sandbox without filesystem or global state.
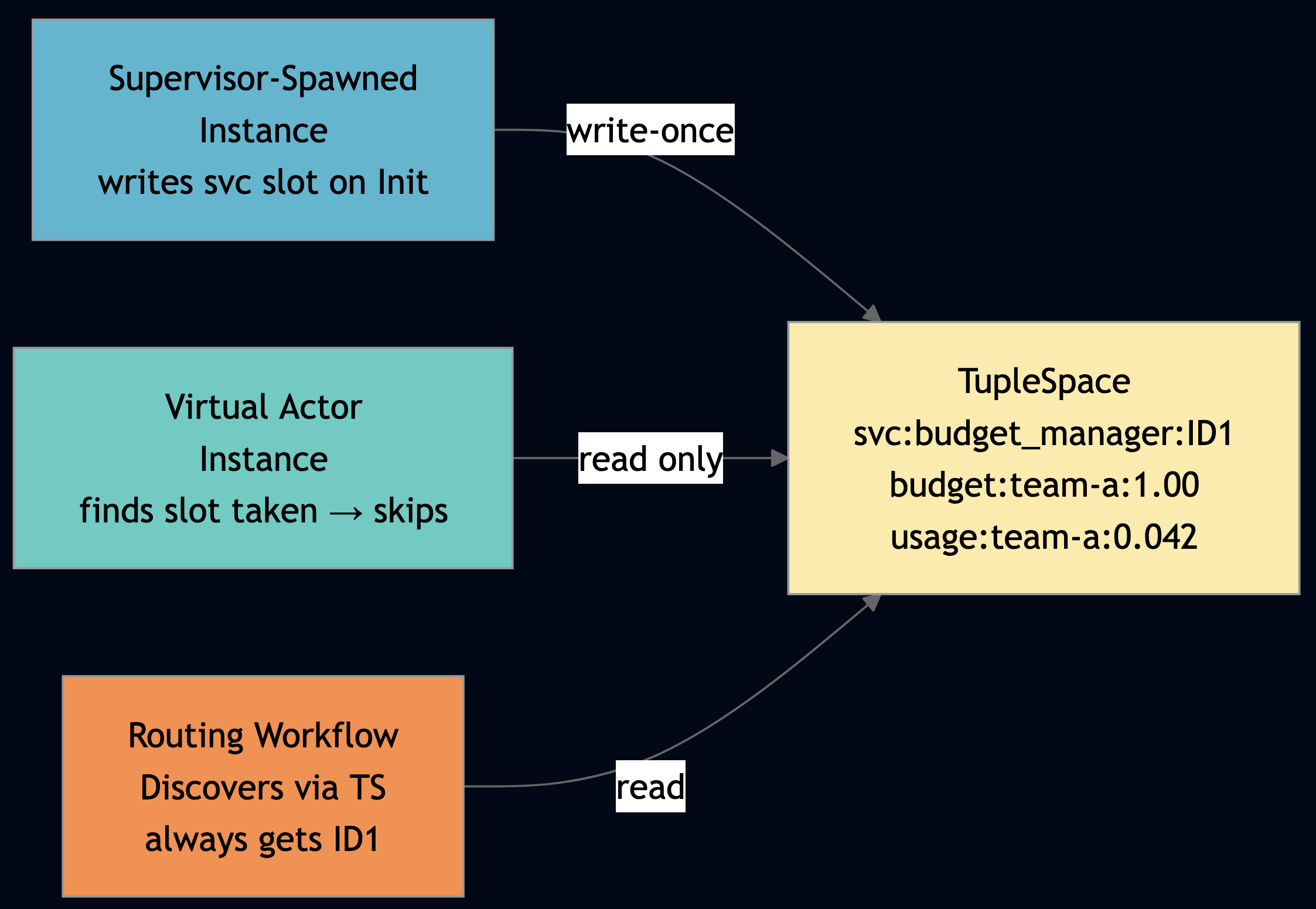
2.1 Process Groups and Object Registry for Location-Transparent Discovery
Every actor is registered in an actor-registry and can optionally join a named process group on @init_handler. Callers look up the first member with pg_first(), a one-liner that hides whether the target is local or on a remote node:
# From examples/python/apps/miniclaw/helpers.py
def pg_first(group: str) -> Tuple[Optional[str], Optional[str]]:
"""Return (actor_id, None) for the first member of a process group, or (None, error)."""
try:
members = host.process_groups.members(group)
if members:
return members[0], None
return None, f"no members in {group}"
except Exception as e:
return None, str(e)Every actor announces itself on startup:
@init_handler
def on_init(self, config: dict) -> None:
host.process_groups.join("svc:agent")
write_actor_info(self.actor_id, self.agent_name,
"Core agent loop with tool calling and session memory",
self.capabilities)The orchestrator discovers agents via pg_first("svc:agent"), it does not know the agent’s address, node, or port. The framework routes the message transparently.
2.2 Fire-and-Forget Audit with host.send, Never host.ask
The audit trail uses host.send() (fire-and-forget) rather than host.ask() (request-reply). This is a deliberate design choice: audit events must never add latency to the agent’s critical path.
# From examples/python/apps/miniclaw/helpers.py
def fire_audit(event_type: str, detail: str) -> None:
"""Fire-and-forget audit event. Failures are logged, never raised."""
audit_id, err = pg_first("svc:audit")
if err or not audit_id:
host.debug(f"fire_audit: {err}")
return
try:
host.send(audit_id, "log_event", {
"op": "log_event",
"event_type": event_type,
"detail": detail,
"timestamp": host.now_ms(),
})
except Exception as e:
host.warn(f"fire_audit: send failed: {e}")Every actor calls fire_audit() after each meaningful operation. The audit actor receives the event asynchronously. If the audit actor is slow or temporarily down, callers are unaffected, they never wait for a response.
2.3 TupleSpace: Queryable Shared Coordination State
TupleSpace (host.ts) is the coordination layer. Unlike KV (point lookup by key), TupleSpace supports pattern queries like read all tuples matching a template with None wildcards:
# Write a memory tuple host.ts.write(["memory", "global", "user_name", "Alice"]) # Read all global memories — None matches any value in that position tuples = host.ts.read_all(["memory", "global", None, None]) # Read all audit events of a specific type events = host.ts.read_all(["audit", "tool_executed", None, None]) # Orchestrator checkpoints sub-task results for crash recovery host.ts.write(["orch_result", task_id, i, str(result)])
The write_actor_info helper uses TupleSpace to publish actor capabilities for external discovery without blocking callers:
# From examples/python/apps/miniclaw/helpers.py
def write_actor_info(actor_id: str, name: str, description: str, capabilities: list) -> None:
"""Write actor capability tuples to TupleSpace for discovery."""
try:
host.ts.write(["agent_card", actor_id, name, description])
for cap in capabilities:
host.ts.write(["agent_cap", cap, actor_id])
except Exception as e:
host.warn(f"write_actor_info: {e}")2.4 send_after for Scheduling Timers
The health monitor uses host.send_after() to schedule a self-message after every poll interval. No cron job, no external scheduler, the actor manages its own polling timeline:
@init_handler
def on_init(self, config: dict) -> None:
# Schedule first poll; each tick reschedules the next
host.send_after(self.poll_interval_ms, "poll_tick", {"op": "poll_tick"})
@handler("poll_tick", "cast")
def poll_tick(self) -> None:
# ... do poll work ...
# Re-arm: each tick schedules the next — no external scheduler needed
host.send_after(self.poll_interval_ms, "poll_tick", {"op": "poll_tick"})2.5 host.channel for Channel-Backed Durable Queues
The Channel primitive provides at-least-once message delivery with explicit ack/nack:
# Producer: send to channel
msg_id = host.channel.send("", _TASK_CHANNEL, task_type, task)
# Consumer: receive, process, then ack or nack
msg, ok, _ = host.channel.receive("", _TASK_CHANNEL, timeout_ms)
if ok:
host.channel.ack("", _TASK_CHANNEL, msg["msg_id"]) # commit
# OR
host.channel.nack("", _TASK_CHANNEL, msg["msg_id"], True) # requeue2.6 The Let-It-Crash Philosophy
Monolithic agent frameworks force developers to write defensive error handling around every tool call, every LLM request, and every memory access. MiniClaw takes the Erlang philosophy: let actors crash, and let guardians restart them in a clean state. A guardian supervisor watches its children. When one crashes, it applies a restart strategy. The other children continue running, unaffected without cascading failures and global error handlers.
# From examples/python/apps/miniclaw/app-config.toml [supervisor] strategy = "one_for_one" # Restart ONLY the crashed actor max_restarts = 10 # Allow up to 10 restarts max_restart_window_seconds = 60 # Within a 60-second window # If 10 crashes in 60s -> escalate to parent supervisor
PlexSpaces provides three restart strategies, each suited to different failure patterns:
| Strategy | Behavior | Agent Use Case |
|---|---|---|
one_for_one | Restart only the crashed actor | Independent tools: calculator crash does not affect weather |
rest_for_one | Restart crashed actor + all actors started after it | Pipeline stages: if retriever crashes, restart generator and validator too |
one_for_all | Restart all children when any crashes | Tightly coupled team: research + analysis + writing agents share context |
2.7 Monitors and Links
PlexSpaces provides two mechanisms for actors to watch each other (similar to Erlang):
- Monitors (
host.monitor()) provide one-way observation. The monitoring actor receives a__DOWN__message when the monitored actor stops.
- Links (
host.link()) provide bidirectional fate-sharing. If either linked actor crashes abnormally, the other receives an__EXIT__message.
# Monitor: one-way watch. ValidatorAgent watches workers.
monitor_ref = host.monitor(worker_id)
@handler("__DOWN__", "cast")
def on_down(self, monitor_ref: str = "", down_from: str = "", down_reason: str = "") -> None:
"""Monitored worker stopped. ValidatorAgent stays alive and compensates."""
self.failed_workers.append(down_from)
# Spawn replacement, redistribute work, alert operator
# Link: bidirectional fate-sharing. Coordinating agents share fate.
host.link(peer_id)
@handler("__EXIT__", "cast")
def on_exit(self, exit_from: str = "", exit_reason: str = "") -> None:
"""Linked peer died abnormally. Clean up shared resources."""
self.linked_peers.remove(exit_from)In MiniClaw, the guardian supervisor monitors all ten actors. If the LLMRouterActor crashes, the supervisor restarts it with a clean state. The AgentActor‘s in-flight request receives a timeout error while the MemoryActor, the AuditEventActor, and every other actor continues running without interruption.

The supervisor IS the guardian pattern from Erlang. Every MiniClaw actor runs under guardian supervision for crash recovery.
Part 3: WASM + Firecracker Sandbox
3.1 Defense in Depth
MiniClaw actors run inside three concentric isolation layers:
- Actor isolation: Each actor owns its state exclusively. No shared memory, no global variables, no cross-actor data access. Communication happens only through
host.ask()andhost.send(). - WASM + Firecracker sandbox: Each actor compiles to a WebAssembly module that runs inside a hardware-enforced memory sandbox. The WASM linear memory is isolated per actor instance. In production deployments, each WASM runtime itself runs inside a Firecracker microVM, a lightweight KVM-based hypervisor that boots in ~125ms and provides hardware-level memory and I/O isolation between tenants.
- Tenant isolation: Every PlexSpaces operation requires a
RequestContextwith explicit tenant and namespace identifiers via JWT authentication. The framework rejects cross-tenant access before the request reaches the actor.

3.2 What the Two-Layer Sandbox Prevents
| Attack Vector | Monolithic Framework | WASM Sandbox | WASM + Firecracker |
|---|---|---|---|
open("/etc/passwd") | Succeeds with full FS access | Blocked with no FS import in WIT | Blocked with separate VM filesystem |
os.environ["API_KEY"] | Succeeds with env vars shared | Blocked with no env access in WASM | Blocked with separate VM env |
| Read another actor’s memory | Succeeds with shared process | Blocked with WASM linear memory is per-instance | Separate VM address space |
| Escape WASM sandbox via JIT bug | Possible in theory | Partially mitigated | Blocked with hypervisor hardware boundary |
| Cross-tenant KV access | Possible if scoping misconfigured | Blocked with RequestContext enforced | Blocked with separate VM tenant |
The WIT (WebAssembly Interface Types) definition explicitly declares what the actor can access:
// From wit/plexspaces-actor/host.wit
// The actor can ONLY call these imports — nothing else
interface host {
send: func(to: string, msg-type: string, payload: payload) -> result<_, actor-error>;
ask: func(to: string, msg-type: string, payload: payload, timeout-ms: u64) -> result<payload, actor-error>;
kv-get: func(key: string) -> result<payload, actor-error>;
kv-put: func(key: string, value: payload) -> result<_, actor-error>;
http-fetch: func(link-name: string, method: string, path: string, request: payload) -> result<payload, actor-error>;
// No filesystem. No env vars. No raw network. No process exec.
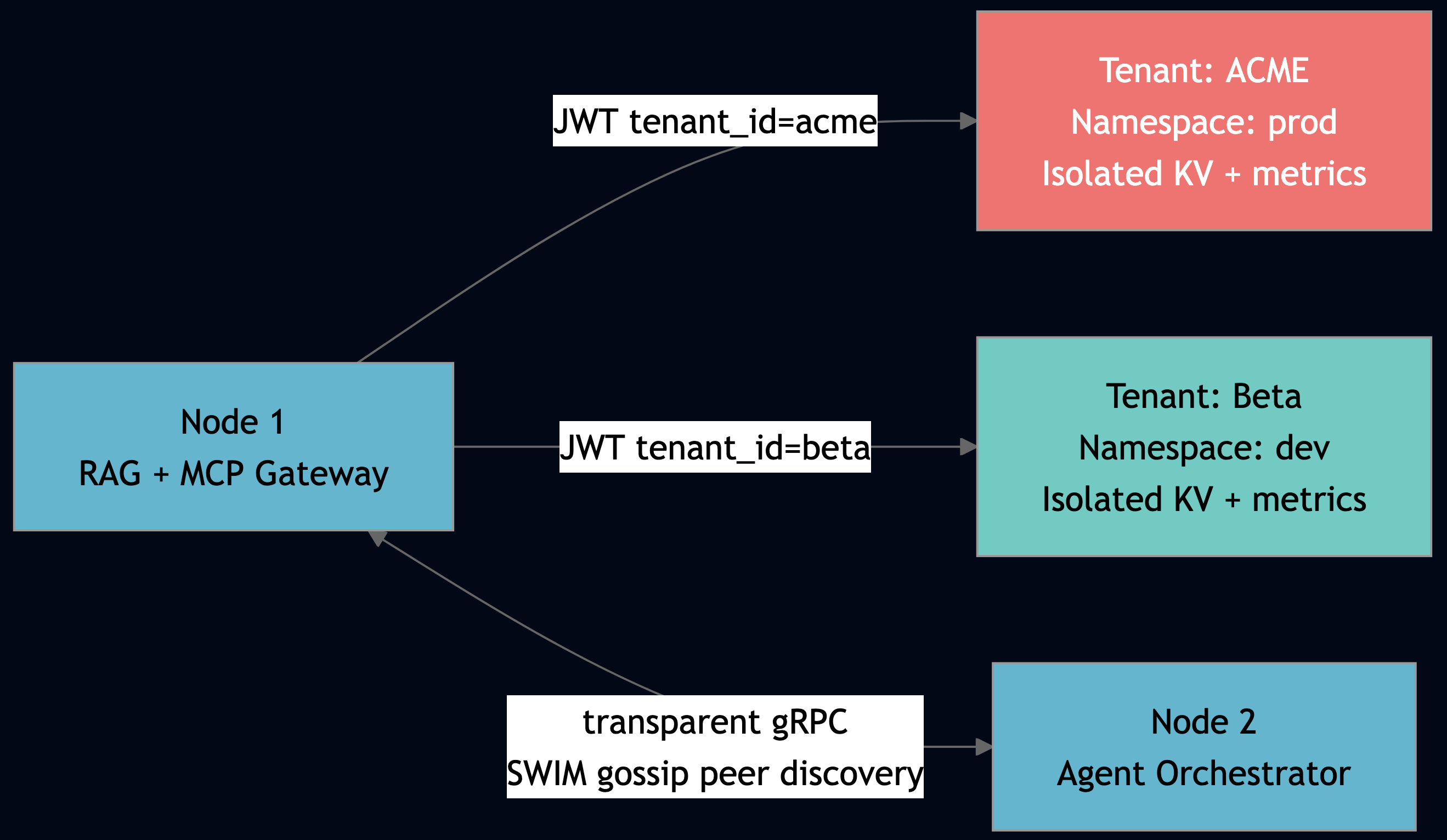
}3.3 Tenant Isolation by Construction
Every PlexSpaces operation propagates tenant context through the call chain. KV keys, TupleSpace tuples, object-registry and process groups are all scoped by tenant and namespace. A session created by tenant acme cannot be retrieved by tenant globex and the framework rejects the request before it reaches the actor.
# Every API request carries tenant context — enforced at framework level # KV keys scoped: tenant-acme:prod:session:sess-001 # TupleSpace scoped: tenant-acme:prod:["memory", "global", "user_name", "Alice"] # Process groups: tenant-acme:prod:svc:llm_router
There is no internal() bypass for application code. Tenant boundaries are enforced by construction, not by convention.
Part 4: MiniClaw Architecture
MiniClaw decomposes the agent framework into ten actors. Every actor runs as a WebAssembly module inside the PlexSpaces runtime, discovers collaborators through object-registry or process groups, and persists state through the durability facet.

| Actor | Behavior | Responsibility | Security Property |
|---|---|---|---|
| LLMRouterActor | GenServer | Route LLM calls, circuit-break on failure | Real API keys never leave the actor (phantom token proxy) |
| ToolRegistryActor | GenServer | Register tools with schemas, execute in isolation | Schema validation prevents malformed tool inputs |
| AgentActor | GenServer | Core agent loop: message -> LLM -> tool -> repeat | Bounded iteration (max 5) prevents infinite loops |
| SessionManagerActor | GenServer | Map users to sessions, enforce tenant scope | Tenant-scoped KV keys prevent cross-tenant access |
| OrchestratorActor | Workflow | Decompose tasks, delegate, checkpoint progress | Durable checkpoints survive crashes |
| MemoryActor | GenServer | Scoped memory (global/agent/session) | KV + TupleSpace dual-write with tenant scoping |
| AuditEventActor | GenEvent | Immutable log of every actor operation | Fire-and-forget; senders never block on audit |
| AgentStateFSM | GenStateMachine | Lifecycle guard: idle -> processing -> tool_executing -> responding | Validates transitions; rejects illegal states |
| TaskQueueActor | GenServer | Durable task queue backed by Channel; enqueue/dequeue/ack/nack | At-least-once delivery; no external broker |
| HealthMonitorActor | GenServer | Periodic PG membership polling via send_after; writes health snapshots | Simple polling eliminates subscription races |
Part 5: Design Patterns Used in MiniClaw
The NanoClaw project introduced an important design philosophy: instead of reaching for external infrastructure when you hit a constraint, first ask whether the primitives you already have can solve the problem.
Pattern 1: Phantom Token / Credential Proxy
The constraint: Agents need to call an LLM provider, but callers should never see real API keys. Storing keys in the agent payload means any log line or bug report leaks credentials.
The actor solution: LLMRouterActor owns the credential store. It exposes a register_credential op that stores phantom_token -> real_api_key in its private KV namespace. Callers pass only the opaque token; the actor resolves the real key internally and discards it before building any response.
# Phantom token: real key stored in actor-private KV — never echoed to callers
@handler("register_credential")
def register_credential(self, phantom_token: str = "", api_key: str = "") -> dict:
if not phantom_token or not api_key:
return {"error": "phantom_token and api_key required"}
host.kv_put(f"cred:{phantom_token}", api_key) # Only this actor reads it
return {"status": "ok", "phantom_token": phantom_token} # api_key never returned
@handler("chat_completion")
def chat_completion(self, messages: list = None, tools: list = None,
phantom_token: str = "") -> dict:
resolved_key = host.kv_get(f"cred:{phantom_token}") if phantom_token else ""
# resolved_key used by real HTTP client; discarded here
# ... call LLM, build response ...
return {"status": "ok", "response": response} # resolved_key never in responseActor-private state means the real key is inaccessible from any other actor, any other tenant, and any logged payload. Even if a prompt injection tricks the agent into returning its full state, the real credential is not in the agent, it is in the router actor, which never echoes it back.

Pattern 2: Task Queue (TaskQueueActor)
The constraint: The orchestrator needs to enqueue work items for agents to process asynchronously but the environment already has the Channel primitive and no external message broker.
The actor solution: TaskQueueActor is a thin wrapper around host.channel. The Channel handles durability, at-least-once delivery, and redelivery on nack transparently:
# From examples/python/apps/miniclaw/infra.py
_TASK_CHANNEL = "tasks:pending"
@actor
class TaskQueueActor:
"""Thin actor wrapper around the host Channel primitive."""
enqueued: int = state(default=0)
completed: int = state(default=0)
failed: int = state(default=0)
@handler("enqueue")
def enqueue(self, task_type: str = "generic", payload: dict = None) -> dict:
task = {"task_type": task_type, "payload": payload or {}, "enqueued_at": host.now_ms()}
msg_id = host.channel.send("", _TASK_CHANNEL, task_type, task)
self.enqueued += 1
fire_audit("task_enqueued", f"msg_id={msg_id} type={task_type}")
return {"status": "ok", "msg_id": msg_id}
@handler("dequeue")
def dequeue(self, limit: int = 1, timeout_ms: int = 0) -> dict:
tasks = []
for _ in range(int(limit)):
msg, ok, _ = host.channel.receive("", _TASK_CHANNEL, int(timeout_ms))
if not ok:
break
tasks.append(msg)
return {"status": "ok", "tasks": tasks, "count": len(tasks)}
@handler("ack")
def ack(self, msg_id: str = "") -> dict:
host.channel.ack("", _TASK_CHANNEL, msg_id) # commits the delivery
self.completed += 1
return {"status": "ok", "msg_id": msg_id}
@handler("nack")
def nack(self, msg_id: str = "", requeue: bool = True) -> dict:
host.channel.nack("", _TASK_CHANNEL, msg_id, requeue) # requeue for redelivery
self.failed += 1
return {"status": "ok", "msg_id": msg_id, "requeue": requeue}PlexSpaces supports multiple providers for queues/channels such as Kafka, SQS, redis or backed by process-groups communication. The Channel primitive is built into the PlexSpaces host, durable, ordered, with explicit ack/nack semantics. If the consumer crashes mid-processing, the unacked message is redelivered on the next dequeue.
Pattern 3: Polling Over Events (HealthMonitorActor)
The constraint: We want to know the health of all service actors, but subscribing to process group membership change events introduces races: a join and a crash can arrive out of order, leaving stale membership in the subscriber’s view.
The actor solution: HealthMonitorActor never subscribes to anything. It polls every service group on a configurable interval using send_after to schedule its own next tick:
# From examples/python/apps/miniclaw/infra.py
_SERVICE_GROUPS = [
"svc:llm_router", "svc:tool_registry", "svc:agent",
"svc:session_manager", "svc:memory", "svc:audit",
"svc:agent_fsm", "svc:task_queue",
]
@actor
class HealthMonitorActor:
"""Polls process group membership on a fixed interval using send_after."""
poll_count: int = state(default=0)
last_poll_ms: int = state(default=0)
group_health: dict = state(default_factory=dict)
poll_interval_ms: int = state(default=5000)
@init_handler
def on_init(self, config: dict) -> None:
args = config.get("args", {})
if args.get("poll_interval_ms"):
iv = int(args["poll_interval_ms"])
self.poll_interval_ms = min(max(iv, 1000), 300_000)
host.process_groups.join("svc:health_monitor")
host.send_after(self.poll_interval_ms, "poll_tick", {"op": "poll_tick"})
@handler("poll_tick", "cast")
def poll_tick(self) -> None:
health = {}
for grp in _SERVICE_GROUPS:
try:
members = host.process_groups.members(grp)
health[grp] = len(members)
except Exception:
health[grp] = 0
self.group_health = health
self.poll_count += 1
self.last_poll_ms = host.now_ms()
import json
host.ts.write(["health_snapshot", self.last_poll_ms, json.dumps(health)])
# Re-arm: each tick schedules the next — no external scheduler needed
host.send_after(self.poll_interval_ms, "poll_tick", {"op": "poll_tick"})
@handler("get_health")
def get_health(self) -> dict:
degraded = [g for g, c in self.group_health.items() if c == 0]
return {
"status": "ok",
"group_health": self.group_health,
"healthy": len(self.group_health) - len(degraded),
"degraded": degraded,
}Polling is always correct as it converges to the true membership on every tick regardless of event order. get_health returns not just a count but a list of degraded groups, making it immediately actionable.

The Constraint-Aware Philosophy
These four patterns share a common thread: each one reaches for the primitives already available in the PlexSpaces sandbox before introducing external dependencies.
| Need | Naive Solution | NanoClaw Solution | Primitive Used |
|---|---|---|---|
| Protect API keys | Environment variables or secrets manager | Phantom token stored in actor-private KV | host.kv_put/kv_get |
| Async task queue | RabbitMQ / SQS | Channel-backed queue with ack/nack | host.channel.send/receive/ack/nack |
| Service health monitoring | Event subscription + fan-out | Periodic send_after poll + TupleSpace snapshot | host.send_after + host.process_groups.members() |
| Capability discovery | Service registry with TTL | Process groups + TupleSpace agent cards | host.process_groups.join/members() + host.ts.write/read_all |
The WASM sandbox is not a limitation to work around instead it is the guide for designing simpler, more auditable systems.
Part 6: The Agent Loop
6.1 The Loop in Code
The AgentActor drives the core agent loop. It receives a user message, calls the LLM, checks for tool requests, executes tools, feeds results back, and repeats with a hard cap of five iterations to prevent runaway loops.
# From examples/python/apps/miniclaw/agent.py
_MAX_ITER = 5
...
@handler("chat")
def chat(self, message: str = "", session_id: str = "") -> dict:
if not message:
return {"error": "message is required"}
self.messages.append({"role": "user", "content": message})
# Discover tools
tool_reg_id, _ = pg_first("svc:tool_registry")
tools = []
if tool_reg_id:
resp = ask(tool_reg_id, "list_tools", {})
if resp:
tools = resp.get("tools", [])
# Signal FSM: processing
fsm_id, _ = pg_first("svc:agent_fsm")
if fsm_id:
host.send(fsm_id, "transition", {"op": "transition", "to": "processing"})
final_response = ""
for i in range(_MAX_ITER):
llm_id, err = pg_first("svc:llm_router")
if err or not llm_id:
final_response = f"[no LLM] Processed: {message}"
break
llm_resp = ask(llm_id, "chat_completion", {"messages": [{"role": "system", "content": self.system_prompt}] + self.messages, "tools": tools}, 10000)
if not llm_resp or "error" in llm_resp:
final_response = f"LLM unavailable: {llm_resp}"
break
response = llm_resp.get("response", {})
stop_reason = response.get("stop_reason", "end_turn")
content = response.get("content", "")
assistant_msg = {"role": "assistant", "content": content, "stop_reason": stop_reason}
if response.get("tool_calls"):
assistant_msg["tool_calls"] = response["tool_calls"]
self.messages.append(assistant_msg)
if stop_reason == "end_turn":
final_response = content
break
if stop_reason == "tool_use":
if fsm_id:
host.send(fsm_id, "transition", {"op": "transition", "to": "tool_executing"})
for tc in response.get("tool_calls", []):
tc_name = tc.get("name", "")
tc_input = tc.get("input", {})
tool_output = {}
if tool_reg_id:
tool_output = ask(tool_reg_id, "execute_tool", {"name": tc_name, "input": tc_input}) or {}
self.messages.append({
"role": "tool",
"tool_call_id": tc.get("id", ""),
"content": str(tool_output),
})
fire_audit("tool_called", f"tool={tc_name} session={session_id}")
if fsm_id:
host.send(fsm_id, "transition", {"op": "transition", "to": "processing"})
final_response = f"Tool results applied (iteration {i + 1})"
else:
final_response = content
break
# FSM: responding ? idle
if fsm_id:
host.send(fsm_id, "transition", {"op": "transition", "to": "responding"})
host.send(fsm_id, "transition", {"op": "transition", "to": "idle"})
# Compact history if needed
if len(self.messages) > self.max_history:
keep = self.max_history // 2
self.messages = self.messages[:1] + self.messages[-keep:]
# Persist history in KV if session provided
if session_id:
import json
host.kv_put(f"session_history:{session_id}", json.dumps(self.messages))
self.total_chats += 1
fire_audit("agent_chat", f"session={session_id}")
return {
"status": "ok",
"response": final_response,
"session_id": session_id,
"messages_count": len(self.messages),
}The _MAX_ITER = 5 cap prevents runaway loops. In a monolithic framework, this cap requires global state or thread-local storage.

Part 7: Circuit Breakers and Immutable Audit Trails
7.1 LLM Router
The LLMRouterActor simulates an LLM with tool-call routing. In production, replace the simulation with a real API call via host.http_fetch() over a named service link:
# From examples/python/apps/miniclaw/llm_router.py
TOOL_CALL_TRIGGERS = ("weather", "search", "calculate", "lookup", "find")
# `LLMRouterActor` is a simulator in this POC. It demonstrates the routing
# boundary where production code would call OpenAI, Anthropic, Bedrock, Gemini, or
# an internal model endpoint through a named service link.
@actor
class LLMRouterActor:
"""Simulated LLM router with tool-calling capability."""
model: str = state(default="miniclaw-simulated-v1")
request_count: int = state(default=0)
@init_handler
def on_init(self, config: dict) -> None:
self.model = config.get("args", {}).get("model", self.model)
host.process_groups.join("svc:llm_router")
@handler("chat_completion")
def chat_completion(self, messages: list = None, tools: list = None) -> dict:
messages = messages or []
tools = tools or []
self.request_count += 1
user_msg = ""
for m in reversed(messages):
if m.get("role") == "user":
user_msg = str(m.get("content", "")).lower()
break
should_use_tool = tools and any(kw in user_msg for kw in TOOL_CALL_TRIGGERS)
if should_use_tool:
tool = tools[0] if tools else {}
tool_name = tool.get("name", "search") if isinstance(tool, dict) else "search"
response = {
"stop_reason": "tool_use",
"content": "",
"tool_calls": [{"id": f"tc_{self.request_count}", "name": tool_name,
"input": {"query": user_msg}}],
}
else:
response = {
"stop_reason": "end_turn",
"content": f"[{self.model}] Processed: {user_msg}",
"tool_calls": [],
}
return {"status": "ok", "response": response, "model": self.model}To add a circuit breaker for production LLM rate limits, extend the actor state with circuit_open and consecutive_failures. The actor IS the circuit breaker, and the durability facet ensures the circuit state survives restarts:
@actor
class LLMRouterActor:
model: str = state(default="gpt-4o")
circuit_open: bool = state(default=False)
consecutive_failures: int = state(default=0)
request_count: int = state(default=0)
@init_handler
def on_init(self, config: dict) -> None:
host.process_groups.join("svc:llm_router")
# Schedule circuit recovery timer
host.send_after(30_000, "timer_tick", {"op": "timer_tick"})
@handler("chat_completion")
def chat_completion(self, messages: list = None, tools: list = None) -> dict:
if self.circuit_open:
return {"error": "circuit_open", "circuit_open": True}
try:
# Production: real API call via host.http_fetch("llm-api", ...)
result = self._call_llm(messages, tools)
self.consecutive_failures = 0
self.request_count += 1
return result
except Exception as e:
self.consecutive_failures += 1
if self.consecutive_failures >= 3:
self.circuit_open = True
return {"error": str(e), "circuit_open": self.circuit_open}
@handler("timer_tick", "cast")
def timer_tick(self) -> None:
# Gradual recovery: decrement failure count by 1 each tick (30s).
# 3 failures -> 90s before circuit closes again. Prevents premature re-open.
if self.circuit_open and self.consecutive_failures > 0:
self.consecutive_failures -= 1
if self.consecutive_failures == 0:
self.circuit_open = False
host.send_after(30_000, "timer_tick", {"op": "timer_tick"})
7.2 Immutable Audit Trail
The AuditEventActor captures every agent action as a fire-and-forget event. Senders never block. Events flow into TupleSpace for append-only, queryable storage:
# From examples/python/apps/miniclaw/memory.py
@event_actor
class AuditEventActor:
"""GenEvent actor: fire-and-forget audit events stored in TupleSpace."""
event_count: int = state(default=0)
@init_handler
def on_init(self, config: dict) -> None:
host.process_groups.join("svc:audit")
@handler("log_event", "cast")
def log_event(self, event_type: str = "", detail: str = "", timestamp: int = 0) -> None:
ts = timestamp or host.now_ms()
try:
host.ts.write(["audit", event_type, ts, detail])
except Exception as e:
host.warn(f"AuditEvent: ts.write failed: {e}")
self.event_count += 1
@handler("get_stats")
def get_stats(self) -> dict:
return {"status": "ok", "event_count": self.event_count}Notice the "cast" annotation on log_event, this marks the handler as fire-and-forget. The sender (fire_audit() in helpers.py) calls host.send(), not host.ask() without blocking.

Part 8: Tools as Actors with MCP-Style Isolation
8.1 Each Tool Gets Supervision, Metrics, and Fault Recovery
In MiniClaw, the ToolRegistryActor manages tool definitions and dispatches execution. Each tool handler runs within the actor’s sandboxed environment:
# From examples/python/apps/miniclaw/tool_registry.py
@actor
class ToolRegistryActor:
"""Registry of callable tools with simulated execution."""
tools: dict = state(default_factory=dict) # name -> tool spec
exec_count: int = state(default=0)
actor_id: str = state(default="")
@init_handler
def on_init(self, config: dict) -> None:
self.actor_id = config.get("actor_id", "")
self.tools = {t["name"]: t for t in _BUILTIN_TOOLS}
host.process_groups.join("svc:tool_registry")
host.info(f"ToolRegistryActor init actor_id={self.actor_id} tools={list(self.tools)}")
@handler("list_tools")
def list_tools(self) -> dict:
return {"status": "ok", "tools": list(self.tools.values()), "count": len(self.tools)}
@handler("register_tool")
def register_tool(self, name: str = "", description: str = "", input_schema: dict = None) -> dict:
if not name:
return {"error": "name is required"}
self.tools[name] = {"name": name, "description": description, "input_schema": input_schema or {}}
host.info(f"ToolRegistry: registered tool={name}")
return {"status": "ok", "name": name}
@handler("execute_tool")
def execute_tool(self, name: str = "", input: dict = None) -> dict:
input = input or {}
if name not in self.tools:
return {"error": f"unknown tool: {name}"}
self.exec_count += 1
host.info(f"ToolRegistry: executing tool={name} exec={self.exec_count}")
# Simulated responses per tool type
if name == "web_search":
return {"result": f"Search results for: {input.get('query', '')}"}
if name == "calculator":
expr = input.get("expression", "0")
try:
# Demo-only restricted evaluation.
# Production code should replace this with an AST-based evaluator or a sandboxed tool actor.
result = eval(expr, {"__builtins__": {}}) # noqa: S307
return {"result": str(result)}
except Exception:
return {"result": f"Could not evaluate: {expr}"}
if name == "weather":
location = input.get("location", "unknown")
return {"result": f"Weather in {location}: 22°C, partly cloudy"}
return {"result": f"[simulated] {name} output for input {input}"}
@handler("get_stats")
def get_stats(self) -> dict:
return {"status": "ok", "tool_count": len(self.tools), "exec_count": self.exec_count}
8.2 What Standalone MCP Servers Lack
| Capability | Standalone MCP | Tool-as-Actor (MiniClaw) |
|---|---|---|
| State persistence | In-memory only; lost on restart | Durability facet checkpoints to SQLite |
| Multi-tenant access | No built-in tenant scoping | RequestContext enforces tenant isolation |
| Metrics | Must add manually per tool | Per-actor invocation counts automatic |
| Fault tolerance | Process crash loses all state | Supervisor restarts; state restored from checkpoint |
| Sandbox | Process boundary only | WASM linear memory + optional Firecracker VM |
Part 9: Agent Lifecycle State Machine
9.1 Scoped Memory with KV + TupleSpace Dual-Write
MemoryActor writes every memory entry to both KV (for durable point-lookup) and TupleSpace (for queryable pattern-scan across a scope):
# From examples/python/apps/miniclaw/memory.py
@actor
class MemoryActor:
"""Scoped memory backed by KV (persistent) and TupleSpace (queryable)."""
memory_count: int = state(default=0)
@init_handler
def on_init(self, config: dict) -> None:
host.process_groups.join("svc:memory")
@handler("store_memory")
def store_memory(self, key: str = "", value: str = "",
scope: str = "global", agent_id: str = "", session_id: str = "") -> dict:
if not key:
return {"error": "key is required"}
scoped_key = _scoped_key(scope, agent_id, session_id, key)
host.kv_put(scoped_key, str(value)) # KV: durable point-lookup
host.ts.write(["memory", scope, key, str(value)]) # TupleSpace: queryable scan
self.memory_count += 1
fire_audit("memory_stored", f"scope={scope} key={key}")
return {"status": "ok", "key": key, "scope": scope}
@handler("recall_memory")
def recall_memory(self, key: str = "", scope: str = "global",
agent_id: str = "", session_id: str = "") -> dict:
scoped_key = _scoped_key(scope, agent_id, session_id, key)
value = host.kv_get(scoped_key)
return {"status": "ok", "key": key, "value": value, "found": bool(value)}
@handler("list_memories")
def list_memories(self, scope: str = "global") -> dict:
try:
tuples = host.ts.read_all(["memory", scope, None, None])
memories = [{"key": t[2], "value": t[3]} for t in tuples if len(t) >= 4]
except Exception:
memories = []
return {"status": "ok", "memories": memories, "scope": scope}
def _scoped_key(scope: str, agent_id: str, session_id: str, key: str) -> str:
if scope == "agent" and agent_id:
return f"mem:agent:{agent_id}:{key}"
if scope == "session" and session_id:
return f"mem:session:{session_id}:{key}"
return f"mem:global:{key}"The three scopes are not just naming conventions — they determine which memories survive across session boundaries:
| Scope | Persists across | Example |
|---|---|---|
global | Everything including sessions, agent restarts | User name, user preferences |
agent | Restarts of this specific agent | Agent-specific learned facts |
session | Only within a single session | “We were discussing X” context |
9.2 Session Management with KV with a Channel+User Index
SessionManagerActor stores session metadata in KV and maintains a secondary index that maps channel+user_id to session_id:
# From examples/python/apps/miniclaw/agent.py
@actor
class SessionManagerActor:
"""Manages agent session lifecycle backed by KV storage."""
active_sessions: int = state(default=0)
total_created: int = state(default=0)
session_ids: list = state(default_factory=list)
@handler("create_session")
def create_session(self, channel: str = "web", user_id: str = "anonymous",
agent_id: str = "agent") -> dict:
import json
session_id = f"sess-{channel}-{user_id}-{host.now_ms()}"
meta = {"session_id": session_id, "channel": channel, "user_id": user_id,
"agent_id": agent_id, "created_at": host.now_ms(), "status": "active"}
host.kv_put(f"session:{session_id}", json.dumps(meta))
host.kv_put(f"session_map:{channel}:{user_id}", session_id) # secondary index
self.session_ids.append(session_id)
self.active_sessions += 1
fire_audit("session_created", f"session_id={session_id} channel={channel} user_id={user_id}")
return {"status": "ok", "session_id": session_id}
@handler("get_session")
def get_session(self, session_id: str = "", channel: str = "", user_id: str = "") -> dict:
import json
if not session_id and channel and user_id:
# Natural key lookup via secondary index
session_id = host.kv_get(f"session_map:{channel}:{user_id}")
if not session_id:
return {"error": "session not found"}
raw = host.kv_get(f"session:{session_id}")
if not raw:
return {"error": "session not found", "session_id": session_id}
meta = json.loads(raw)
meta["status"] = "ok"
return metaThe secondary index means a chatbot can route an incoming webhook (which carries channel and user_id but not a session token) directly to the right session without a scan.
9.3 State Management
The AgentStateFSM tracks execution state through a finite state machine. It validates transitions at runtime and attempting idle -> responding is rejected. This catches bugs in the agent loop before they produce corrupt state.
# From examples/python/apps/miniclaw/memory.py
# Sole authoritative definition of the FSM.
# Adding a new state requires only adding it here.
_VALID_FSM_TRANSITIONS = {
"idle": {"processing", "tool_executing"},
"processing": {"tool_executing", "responding", "idle"},
"tool_executing": {"processing", "idle"},
"responding": {"idle"},
}
@fsm_actor(states=["idle", "processing", "tool_executing", "responding"], initial="idle")
class AgentStateFSM:
"""Agent lifecycle FSM: idle -> processing -> tool_executing -> responding -> idle."""
fsm_state: str = state(default="idle")
transition_count: int = state(default=0)
@init_handler
def on_init(self, config: dict) -> None:
host.process_groups.join("svc:agent_fsm")
@handler("transition")
def transition(self, to: str = "") -> dict:
allowed = _VALID_FSM_TRANSITIONS.get(self.fsm_state, set())
if to not in allowed:
host.debug(f"FSM: invalid transition {self.fsm_state} -> {to}")
return {"status": "ignored", "from": self.fsm_state, "to": to}
prev = self.fsm_state
self.fsm_state = to
self.transition_count += 1
host.debug(f"FSM: {prev} -> {to}")
return {"status": "ok", "from": prev, "to": to}
@handler("get_state")
def get_state(self) -> dict:
return {"status": "ok", "state": self.fsm_state, "transitions": self.transition_count}
Operators query the FSM to see what every agent does at any moment with full observability.
Part 10: Multi-Agent Orchestration with Durable Checkpoints
The OrchestratorActor decomposes complex tasks and delegates each sub-task to the AgentActor. It uses the Workflow behavior, which checkpoints progress after each step:
# From examples/python/apps/miniclaw/orchestrator.py
@workflow_actor
class OrchestratorActor:
"""Durable workflow: decompose task -> delegate to agents -> aggregate results."""
status: str = state(default="idle")
task_id: str = state(default="")
progress: int = state(default=0)
@init_handler
def on_init(self, config: dict) -> None:
host.info(f"OrchestratorActor init actor_id={config.get('actor_id', '')}")
@run_handler
def run(self, payload: dict = None) -> dict:
payload = payload or {}
task = payload.get("task", "explain how agents work")
task_id = payload.get("task_id", f"orch-{host.now_ms()}")
self.status = "running"
self.task_id = task_id
self.progress = 0
agent_id, err = pg_first("svc:agent")
if err or not agent_id:
self.status = "failed"
return {"error": "no agents in svc:agent", "task_id": task_id}
# Decompose: split on " and " for multi-step tasks
lower = task.lower()
idx = lower.find(" and ")
sub_tasks = [task[:idx].strip(), task[idx + 5:].strip()] if idx >= 0 else [task]
sub_results = []
for i, sub_task in enumerate(sub_tasks):
self.progress = (i + 1) * 100 // len(sub_tasks)
resp = ask(agent_id, "chat",
{"message": sub_task, "session_id": f"orch-{task_id}-{i}"}, 15000)
if not resp:
self.status = "failed"
return {"error": "sub-task failed", "task_id": task_id}
# Checkpoint sub-result to TupleSpace — survives orchestrator crash
host.ts.write(["orch_result", task_id, i, str(resp.get("response", ""))])
sub_results.append(resp)
summaries = [r.get("response", "") for r in sub_results if r.get("response")]
self.status = "completed"
self.progress = 100
fire_audit("orchestrator_completed", f"task_id={task_id} subtasks={len(sub_tasks)}")
return {
"status": "ok",
"task_id": task_id,
"result": " | ".join(summaries),
"sub_results": sub_results,
"sub_tasks": len(sub_tasks),
}
@signal_handler("cancel")
def cancel(self) -> None:
self.status = "cancelled"
host.info(f"Orchestrator cancelled task_id={self.task_id}")
@query_handler("status")
def query_status(self) -> dict:
return {"task_id": self.task_id, "status": self.status, "progress": self.progress}The @run_handler, @signal_handler, and @query_handler decorators map cleanly to the Workflow behavior’s three message types:
run: starts the workflow executionsignal: sends an out-of-band control message (e.g., cancellation mid-workflow)query: reads durable workflow state without blocking the running workflow
Part 11: Multi-App Deployments
In this example all ten actors share a single WASM binary via ACTOR_REGISTRY:
# From examples/python/apps/miniclaw/miniclaw_actor.py
ACTOR_REGISTRY = {
"llm_router": LLMRouterActor,
"tool_registry": ToolRegistryActor,
"agent": AgentActor,
"session_manager": SessionManagerActor,
"orchestrator": OrchestratorActor,
"memory": MemoryActor,
"audit_event": AuditEventActor,
"agent_fsm": AgentStateFSM,
"task_queue": TaskQueueActor,
"health_monitor": HealthMonitorActor,
}This is convenient for development and single-tenant deployments. For enterprise multi-tenant deployments, you can split actors into separate applications to achieve stronger isolation:
- llm-gateway/ – LLMRouterActor only for credential management isolated
- agent-app/ – AgentActor + SessionManagerActor one app per tenant team
- tools-app/ – ToolRegistryActor + MemoryActor hared tool catalog
- audit-app/ – AuditEventActor compliance isolation
- infra-app/ – TaskQueueActor + HealthMonitorActor
In the multi-app model, each application gets its own Firecracker microVM in production, providing hardware-level tenant isolation. Actors across applications discover each other via process groups or object registry and the code changes only in app-config.toml, not in the actor implementations.
Plugins as Deployed Apps, Not Bundled Packages
OpenClaw’s post-mortem describes a painful middle state: too much moved toward plugins, while plugins were still bundled, repaired, and dependency-loaded in startup paths. This is the monolith decomposition trap: you split the code but not the process, so startup coupling survives the refactor.
PlexSpaces avoids this by treating plugins as deployed apps, not installed packages. A channel connector, or a third-party memory backend is a separate app that exposes one or more actors. The agent loop discovers them the same way it discovers any actor via pg_first("svc:telegram-connector") or on a remote node. Adding a new integration means deploying a new app, not modifying package.json.
| OpenClaw pattern | PlexSpaces equivalent | What changes |
|---|---|---|
| Bundled channel plugins in core | Channel app deployed separately | Startup failure in the channel app doesn’t touch the agent loop |
Shared node_modules dependency graph | Each app is its own WASM binary | Supply-chain compromise in one app’s deps can’t reach another app |
| Plugin repair at startup | Actor restarts via one_for_one supervisor | Only the failed actor restarts; the rest keep running |
| Hard to decompose after the fact | Actor boundaries are message contracts from day one | Moving an actor to its own app changes app-config.toml, not the actor code |
Part 12: Security Comparison Actor Framework vs. Monolithic
| Security Property | OpenClaw / Monolithic | MiniClaw / Actor-Based |
|---|---|---|
| State isolation | Shared memory; one agent reads another’s state | Per-actor private state; accessible only through messages |
| Privilege boundary | Single process; tools share agent’s full permissions | WASM sandbox; actor can only call WIT-declared imports |
| Sandbox depth | OS process boundary only | WASM linear memory + Firecracker microVM hardware boundary |
| Tenant separation | Application-level checks; misconfiguration = data leak | Framework-enforced RequestContext; no bypass possible |
| Tool execution | In-process; tool crash = agent crash | Separate actor; tool crash triggers supervised restart |
| Secret management | os.environ shared across all tools | Actor-scoped KV; WASM has no env var access |
| Audit trail | Optional; must add per tool | Built-in @event_actor; captures all operations by default |
| Prompt injection blast radius | Full system access: files, network, memory | Confined to single actor’s WIT capabilities |
| Circuit breaker | Must implement per integration | Built into LLMRouterActor; state survives restarts |
| Crash recovery | Process restart; lose all in-flight state | Actor restart; resume from durability checkpoint |
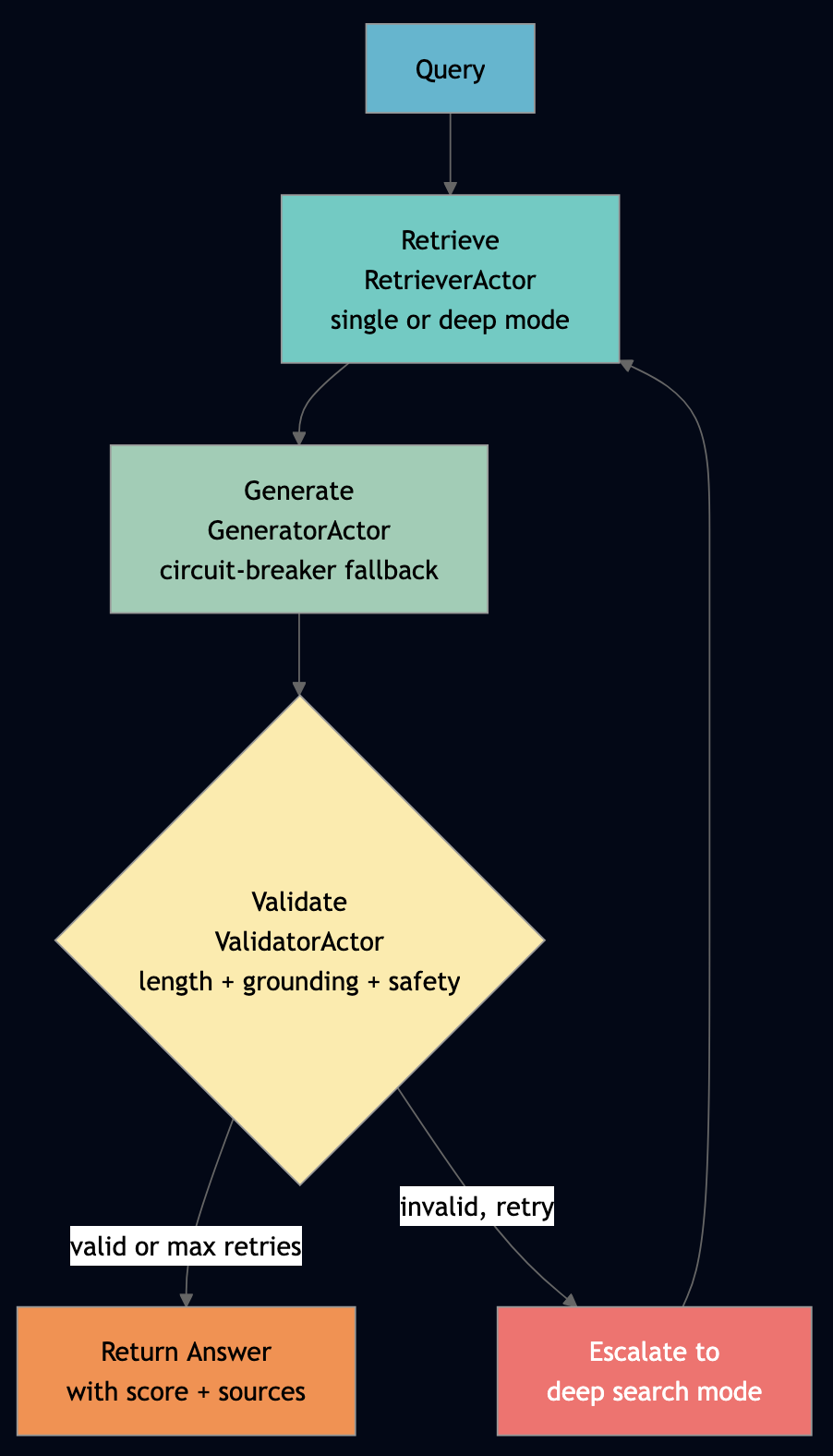
| Quality validation | Hope the LLM got it right | Reflection loop + three-check guardrails + LLM-as-Judge |
| Failure detection | Uncaught exceptions; manual health checks | Monitor/link primitives; __DOWN__/__EXIT__ messages |
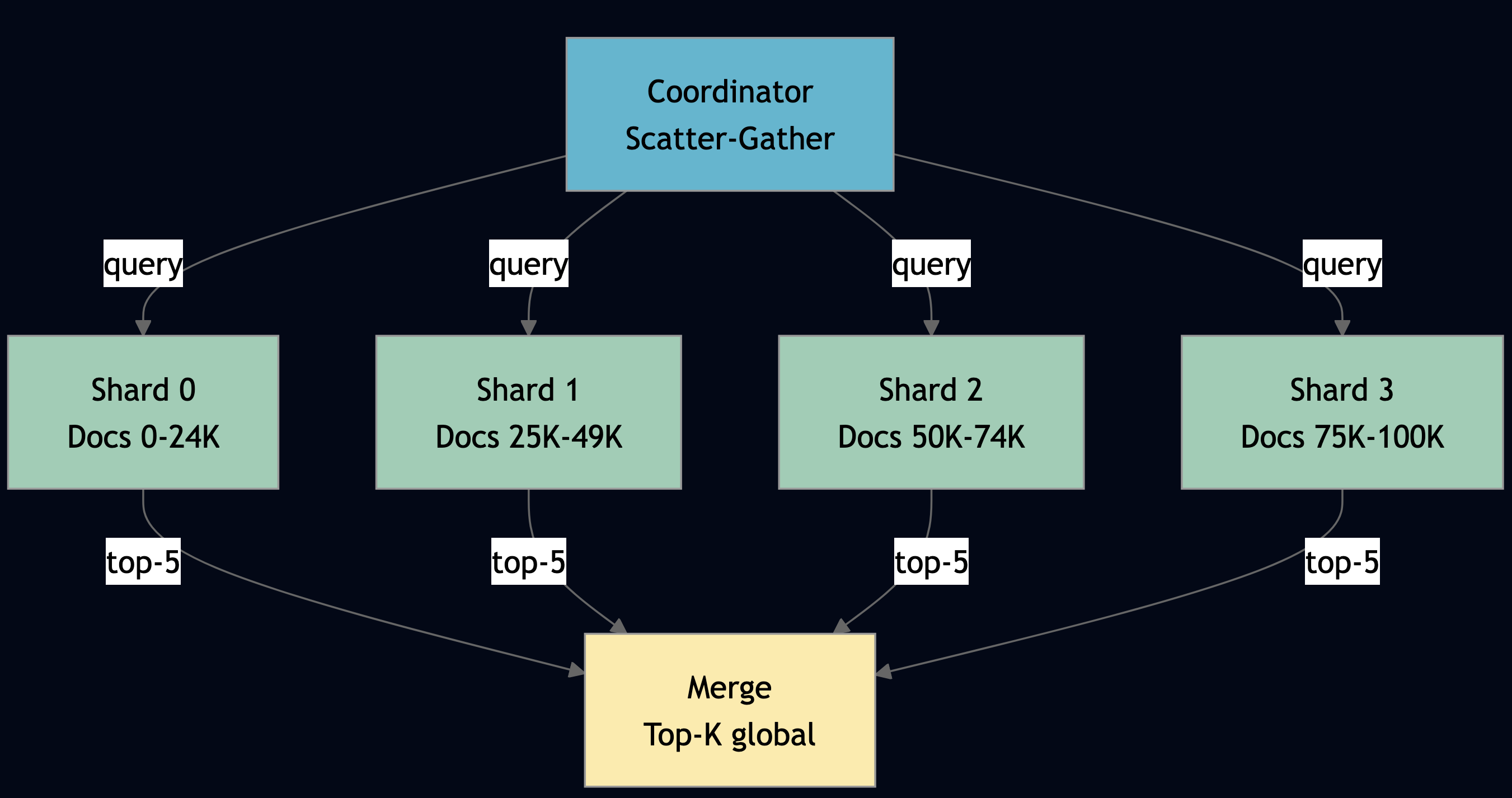
| Multi-tenant scaling | Shard by process; complex ops burden | Cellular architecture; independent failure domains |
Part 13: Running the Example
Build and Deploy
cd examples/python/apps/miniclaw ./build.sh # componentize-py -> WASM Component Model ./test.sh 8092 # Deploy to running node and run full test suite
What the Test Script Validates
The test script exercises all ten actors end-to-end:
# Step 3: LLM Router — simulated chat + tool routing
ask "llm_router" '{"op":"chat_completion","messages":[{"role":"user","content":"Hello!"}],"tools":[]}'
# Step 5: Agent chat — full loop including tool use
ask "agent" '{"op":"chat","message":"Search for the weather in Paris","session_id":"test-sess-1"}'
# Step 9: Agent FSM — validate state transitions
ask "agent_fsm" '{"op":"transition","to":"processing"}'
ask "agent_fsm" '{"op":"transition","to":"responding"}'
# Step 10: Orchestrator workflow — durable multi-agent task
ask "orchestrator" '{"op":"workflow_run","task":"explain AI agents","task_id":"test-orch-1"}' 60
ask "orchestrator" '{"op":"workflow_query:status"}'
# Step 8: Task Queue — Channel-backed enqueue/dequeue/ack
ask "task_queue" '{"op":"enqueue","task_type":"send_email","payload":{"to":"bob@example.com"}}'
ask "task_queue" '{"op":"dequeue","limit":1}'
ask "task_queue" '{"op":"ack","msg_id":"..."}'App Configuration
All ten actors are declared in app-config.toml. Each actor specifies its behavior_kind, role (used to select the right class from ACTOR_REGISTRY), and facets:
[[supervisor.children]]
name = "agent"
actor_type = "miniclaw_wasm"
role = "agent"
behavior_kind = "GenServer"
args = { role = "agent", agent_name = "general-assistant",
system_prompt = "You are a helpful AI assistant with access to tools." }
facets = [
{ type = "virtual_actor", priority = 100, config = { idle_timeout = "10m", activation_strategy = "eager" } },
{ type = "durability", priority = 90, config = { checkpoint_interval = 3 } }
]
[[supervisor.children]]
name = "orchestrator"
actor_type = "miniclaw_wasm"
role = "orchestrator"
behavior_kind = "Workflow" # Enables @run_handler, @signal_handler, @query_handler
args = { role = "orchestrator" }
facets = [
{ type = "virtual_actor", priority = 100, config = { idle_timeout = "10m", activation_strategy = "lazy" } },
{ type = "durability", priority = 90, config = { checkpoint_interval = 5 } }
]
[[supervisor.children]]
name = "agent_fsm"
actor_type = "miniclaw_wasm"
role = "agent_fsm"
behavior_kind = "GenFSM" # Enables @fsm_actor state machine behavior
args = { role = "agent_fsm" }
facets = [
{ type = "virtual_actor", priority = 100, config = { idle_timeout = "30m", activation_strategy = "lazy" } },
{ type = "durability", priority = 90, config = { checkpoint_interval = 1 } }
]The Isolation Ladder
Not every deployment needs a Firecracker VM, but every production agent system should reason explicitly about which isolation layer each component requires. MiniClaw provides a progression:
| Layer | Mechanism | What it contains |
|---|---|---|
| Message isolation | Actor private state; all access via host.ask/send | Cross-agent state reads; accidental coupling through shared memory |
| Tenant isolation | RequestContext JWT enforced by the framework | Cross-tenant KV, TupleSpace, and process group access |
| App isolation | Separate deployed apps; independent startup paths | Startup coupling; plugin dependency repair contagion across integrations |
| WASM isolation | WIT import surface; per-actor linear memory | Supply-chain attacks; filesystem, env, and exec access |
| Firecracker/Docker isolation | VM boundary per tenant | WASM JIT escape; cross-tenant kernel syscall surface |
The same actor code runs at every level. The app-config.toml determines which layers are active for a given deployment. Development runs message isolation only. A single-tenant production deployment adds WASM. A multi-tenant enterprise deployment adds Firecracker/Docker.
Conclusion
MiniClaw is not a finished enterprise agent platform. It is a small proof of concept that demonstrates a different foundation for one. The important lesson is not that every agent system needs these exact ten actors. The lesson is that agent runtimes benefit when isolation, supervision, explicit messaging, durable state, scoped memory, audit, and tenant boundaries are part of the architecture from the beginning. A monolithic agent loop is easy to start with, but hard to harden later. MiniClaw takes the opposite path: split the runtime into small actors, give each actor one responsibility, constrain what it can access, supervise it when it fails, and communicate only through explicit messages. Each actor owns one responsibility: routing LLM calls, managing tools, storing session metadata, persisting memory, recording audit events, coordinating workflows, or monitoring health.
MiniClaw is implemented with PlexSpaces that provides runtime primitives such as KV, TupleSpace, Channels, timers, workflows, GenEvent, and GenFSM. It allows better fault tolerance, observability, tenant-isolation, authentication, observability, rate limiting, circuit breaker, backpressure, sandboxed execution via WebAssembly and Firecracker. This POC demonstrates the shape of the solution:
AgentActormodels the bounded agent loop: user message -> LLM -> tool call -> repeat -> final response.LLMRouterActordefines the model boundary, using a simulator where production code would call OpenAI, Anthropic, Bedrock, Gemini, or an internal model.ToolRegistryActorcentralizes tool registration and dispatch.SessionManagerActorstores session metadata in KV.MemoryActordemonstrates global, agent, and session-scoped memory.AuditEventActorrecords non-blocking audit events through GenEvent-style fire-and-forget messaging.AgentStateFSMmakes lifecycle transitions explicit.TaskQueueActorshows durable background work through channels.HealthMonitorActorpolls service-group health using actor timers.OrchestratorActordemonstrates workflow-style task decomposition and result aggregation.
A production MiniClaw would harden the implementation with the following:
- strict tenant, user, session, and tool authorization on every message;
- safe eval like
asteval; the WASM sandbox reduces but does not eliminate the risk; - one actor instance per tenant/session or explicit session-partitioned state;
- add schema validation before tool execution;
- add idempotency to task queue processing;
- hardened tool execution with separate sandboxed tool actors for high-risk tools;
- real LLM provider integration with retries, budgets, timeouts, backoff, and circuit breakers;
- prompt-injection detection, output validation, and optional LLM-as-judge actors;
- stronger memory governance, including TTLs, redaction, encryption, and deletion semantics;
- structured audit trails with retention policies and tamper-resistant storage;
- crash-recovery tests, chaos testing, and cross-tenant isolation tests;
- deployment hardening for secrets, networking, service links, and Firecracker isolation.
For teams building enterprise AI agents, the real question is not whether they need isolation, auditability, tenant boundaries, tool governance, and failure recovery. They do. The question is whether they bolt those properties onto a monolithic agent process later, or start with a runtime where those properties are first-class primitives.
The full source, including the Go and Python implementations, is at github.com/bhatti/PlexSpaces.
References
- MiniClaw Python source:
examples/python/apps/miniclaw/ - MiniClaw Go source:
examples/go/apps/miniclaw/ - 20+ Production Patterns for Distributed AI Agents
- Building PlexSpaces: Decades of Distributed Systems Distilled
- Agentic AI for Personal Productivity
- Polyglot WebAssembly: Four Languages, One Runtime
- From Data Lakes to AI Inference: Scalable Data Pipelines
- Generative and Agentic AI Design Patterns
- Agentic AI for API Compatibility: Building Intelligent Guardians with LangChain and LangGraph
- Automated PII Detection: Building Privacy Guardians with LangChain and Vertex AI
- Pragmatic Agentic AI: How I Rebuilt Years of FinTech Infrastructure with ReAct, RAG, and Free Local Models
- Agentic AI for Personal Productivity: Building a Daily Minutes Assistant with RAG, MCP, and ReAct
- Building a Production-Grade Enterprise AI Platform with vLLM: A Complete Guide from the Trenches
- Building Production-Grade AI Agents with MCP & A2A: A Complete Guide from the Trenches